Circuit breakers for flaky providers to prevent cascading failures
Learn how circuit breakers for flaky providers prevent cascading failures using timeouts, retries, fallbacks, and safe recovery when dependencies stabilize.
Why flaky providers can take down an otherwise good app
An app can be solid and still fall over because something it relies on starts acting up. A payment gateway slows down, an email service returns errors, or a database proxy hiccups. If your app keeps calling that dependency as if nothing is wrong, a small issue spreads fast.
That chain reaction is a cascading failure: one slow or failing dependency makes requests wait, waiting requests pile up, and soon the healthy parts of your app can’t breathe. Threads get stuck, connection pools fill, queues back up, and everything feels “down” even when most of your code is fine.
This often starts with ordinary triggers:
- Timeouts that are too long, so every request waits far longer than users will tolerate.
- Rate limits, followed by retries that push even more traffic into the throttle.
- Partial outages where some calls work and others hang, which is harder to spot.
- “Slow success” where responses eventually succeed but take 10x longer and clog resources.
Retries without guardrails make it worse. If each user action triggers three retries and you have hundreds of users hitting the same provider, you can create your own traffic spike. That’s why circuit breakers matter: they stop your app from touching the hot stove over and over.
From the user’s point of view, it’s simple and painful. Buttons spin forever, pages refresh into errors, and people click again because nothing seems to happen. That leads to duplicate actions (double orders, double charges, multiple tickets). Worse, users can’t tell whether their data saved or a payment went through.
This failure mode shows up a lot in inherited AI-generated apps: missing timeouts, aggressive retries, and “happy path only” error handling can turn a provider blip into a full outage. The fix starts by treating dependency failure as normal, not exceptional.
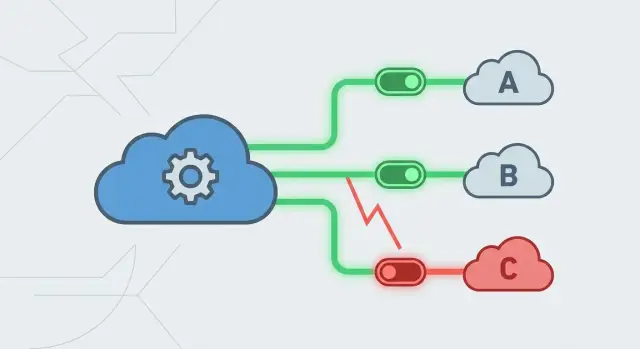
Circuit breakers in one minute: what they do and why
A circuit breaker is a guardrail around an external call. When a dependency starts failing, you stop calling it for a short time. That prevents more traffic, more errors, and more blocked threads. Instead of every request hanging, you fail fast and switch to a fallback.
Circuit breakers usually move through three states:
- Closed: calls flow normally, and you track outcomes.
- Open: the provider looks unhealthy, so calls are blocked immediately and you return a controlled response.
- Half-open: after a cooldown, you allow a small number of test calls to see if the provider recovered.
This is not the same as “add retries and timeouts.” A timeout limits how long you wait, but you can still pile up a lot of waiting work when a provider is slow. Retries can multiply traffic at exactly the wrong moment. A breaker adds a higher-level rule: you’ve seen enough failures, so stop trying for now.
When it’s set up well, the outcome is intentionally boring:
- Users get a quick answer, even if it’s degraded (cached data, queued work, or a clear “try again soon”).
- Your servers stay responsive because they aren’t stuck waiting on a failing provider.
- Incidents stay contained because one shaky dependency doesn’t trigger a chain reaction.
Example: if your sign-up flow sends a confirmation email and the email API starts timing out, a breaker can stop send attempts for a few minutes and queue emails for later. Users can still create an account instead of watching the page spin and fail.
AI-generated codebases often miss this pattern or wire it incorrectly. FixMyMess commonly sees long timeouts plus aggressive retries, which turns a provider hiccup into an outage. A circuit breaker is one of the fastest ways to make dependency failures predictable.
Where to add circuit breakers first (highest impact spots)
Start where one dependency can stall the whole app. The best first targets aren’t “rare features.” They’re calls on high-traffic screens and critical flows.
A simple way to prioritize is to think in two dimensions:
- Risk: the provider fails, slows down, or rate-limits often.
- Blast radius: one slow call blocks many requests, ties up worker threads, or breaks a core user journey.
Pick dependencies that fail loudly (and often)
Third-party services on the critical path deserve protection first: payments, email/SMS, authentication providers, and LLM APIs. They’re outside your control and can degrade without warning.
If you only protect one thing, choose the dependency that can stop money or access. A checkout that hangs is worse than a delayed receipt. A login timeout is worse than missing analytics.
Focus on endpoints tied to critical actions
Breakers matter most on endpoints where users are actively trying to complete something: login, signup, onboarding, checkout, password reset, and any “submit” action that must return quickly.
To pick the first few call sites, do this:
- Identify your top endpoints by traffic and business impact.
- Map the external calls each endpoint makes.
- Flag synchronous calls inside the request/response path.
- Decide what “failure” means (timeouts and 5xx, but also bad or incomplete payloads).
- Confirm what happens today when the dependency is slow (spinners, queue buildup, thread exhaustion).
Teams often get surprised by what counts as failure. A provider can return HTTP 200 with a broken payload, missing fields, or a token you can’t use. Treat those as failures too, or the breaker won’t open when it should.
Example: if onboarding calls an LLM to generate a welcome message and that call takes 20 seconds, users assume signup is broken. Put the breaker around that call, set a clear timeout, and return a simple default message.
Inherited AI-generated code can make this harder because dependency calls are tangled into handlers and routes. One practical first move is to isolate each provider behind a clean boundary so you can add timeouts, breakers, and fallbacks without rewriting everything.
The knobs that matter: timeouts, thresholds, and reset windows
A circuit breaker is only as good as its settings. Too loose, and users still feel the outage. Too strict, and you block healthy traffic.
Timeouts: decide how long you’re willing to wait
Pick a per-request timeout based on what the user is doing. For a “Save” button, waiting 10 seconds feels broken. For background sync, you can tolerate more.
A useful rule: the timeout should be shorter than the amount of time your app can afford to be stuck. If it’s too high, requests pile up, workers clog, and a small provider slowdown becomes an app outage.
Retries can help only when failures are brief and the provider isn’t overloaded. Retrying after timeouts often makes things worse because it doubles traffic right when the dependency is struggling.
Thresholds and recovery: when to open, when to test
You need three numbers: when to open, how long to wait, and how to test recovery.
A practical starting point:
- Open after a clear spike, for example 5 failures in the last 20 calls.
- Wait 30 to 60 seconds before testing again.
- In half-open, allow 1 to 3 probe calls, not a flood.
- Keep retries to 0 or 1, and only for safe, idempotent requests.
- Set timeouts per endpoint, often 1 to 3 seconds for user-facing actions.
Half-open probes are the “toe in the water.” After the reset window, you let a small, controlled number of requests through. If they succeed consistently, you close the circuit. If they fail, you open it again.
Example: if an email provider sends login codes and starts timing out, use a short timeout so the UI doesn’t hang, open the breaker after a few failures, and probe every minute. Users get a clear next step instead of endless spinners.
If you inherited an AI-generated codebase with accidental “retry forever” loops, fixing these settings is often one of the highest-leverage changes you can make.
Step by step: implementing a circuit breaker without overengineering
The quickest way to get value is to keep it centralized. Don’t scatter checks everywhere. Put the behavior in one place so you can tune it later without hunting through dozens of files.
A simple flow that works in most apps
Create a single “provider client” wrapper for each external dependency (payments, email, AI model, auth, shipping). Every call goes through it. That wrapper owns timeouts, retries, breaker state, and logging.
A straightforward implementation usually looks like this:
- Centralize calls in one module with one interface.
- Normalize errors into a small set your app understands (timeout, unavailable, bad request).
- Track recent outcomes in a rolling window and open the circuit when failures cross your threshold.
- When open, fail fast and return a safe fallback.
- After a cooldown, probe carefully and only close after real success.
What “safe fallback” means in practice
A fallback shouldn’t pretend everything worked. It should keep the user moving without making things worse.
If email is failing, accept the form submission, show confirmation, and queue the email for later. If a pricing API is down, show cached prices with an “as of” timestamp and a clear note if they might be outdated. If a call is tied to money or security, be explicit about uncertainty.
Keep fallback decisions close to the wrapper. The rest of the app should call sendEmail() or chargeCard() and get a clear result back.
A common failure in inherited prototypes is a third-party API being called from multiple routes with different retry behavior. It works in testing, then times out in production and triggers retries everywhere. A wrapper with a real timeout, fast failure, and cooldown stops the pileup and protects your database and queues.
Designing fallbacks users can live with
Circuit breakers stop the bleeding. Fallbacks keep users moving. A good fallback is honest, safe, and easy to explain.
Start by naming the user goal for each dependency call. If the goal is “see my balance,” a fallback might be “show last known balance with a timestamp.” If the goal is “finish checkout,” a fallback might be “save the order request and confirm later,” not “pretend it went through.”
Useful fallback types include cached data, queued work, degraded UI, manual review, and alternate providers (only when truly equivalent). The rule that matters most: don’t lie. People forgive “We’ll confirm shortly” far more than they forgive double charges.
Decide when to show a message versus silently degrading based on impact. If the user might make a wrong decision (money, security, deadlines), show a clear message and next step. If it’s cosmetic, silent fallback can be fine.
Make it observable (so you can fix it fast)
Fallbacks without logs turn incidents into guesswork. Capture enough context to understand what happened:
- What the user tried to do (and key inputs you can safely store)
- Provider status (timeout, 500, rate limit, circuit open)
- A correlation ID across request, provider call, and fallback path
- The outcome (queued, cached, manual review created)
- The user-facing message shown
AI-generated apps sometimes have fallbacks, but nobody can tell which path ran. The fix is simple: make every fallback explicit, traceable, and truthful.
A realistic example: payments provider starts failing mid-day
It’s 12:10 pm on a Tuesday. Your checkout is healthy, but it depends on a third-party payments API. The provider starts timing out. Not hard failing, just hanging for 10 to 20 seconds.
Without protection, the problem spreads. Each checkout request waits, then retries. Stuck requests pile up, tying up workers and database connections. Customers refresh and click “Pay” again. Some requests go through, others don’t, and you end up with slow pages, duplicate attempts, and a support inbox full of “Was I charged?”
With a circuit breaker, the story changes quickly. After a short run of timeouts, the breaker opens for the payments client. Checkout stops waiting 20 seconds to learn the obvious. It fails fast and shows a clear message like: “Payments are temporarily unavailable. Your order is saved. Try again in a few minutes.”
Instead of firing more payment calls, the app records intent (cart, total, user, pending order ID). If you can, queue a payment attempt for later or offer an alternate method. The key is that users get a quick, honest result, and the system stays responsive.
When the breaker opens, you also get cleaner signals: “payments dependency down” instead of vague slowness everywhere. Recovery isn’t hero work. After a reset window, the breaker moves to half-open, sends a small number of probes, then closes if the provider is healthy again.
Common mistakes that make outages worse
Outages usually get worse because the app keeps pushing, waiting, and blocking until everything backs up. Circuit breakers help, but only if you avoid a few traps.
Immediate, endless retries are a classic amplifier. If a provider hiccups and thousands of clients retry at once, you create your own traffic spike and keep the provider down longer.
Missing timeouts are another. Without a clear timeout, requests hang, queues grow, servers slow down, and soon even healthy parts of the app feel broken.
Also watch out for breaker scope. One global breaker shared across unrelated features is a footgun. A payments outage shouldn’t block users from logging in or reading their own data. Scope breakers to a single dependency and a single kind of call.
Five quick red flags:
- Retries that fire instantly and endlessly (no backoff, no cap)
- Timeouts that are missing or so long that requests pile up
- One breaker shared across many dependencies or endpoints
- A fallback that reports “success” when the action didn’t happen
- A circuit that opens but never probes for recovery
Fallbacks that don’t lie
The most damaging fallback hides failure. If a user clicks “Pay now,” the provider fails, and the app shows “Payment complete,” you’ll get disputes and angry customers.
A safer fallback is honest and specific: “We couldn’t process the payment. Your order is saved. Try again in a few minutes.” When possible, keep the user moving: save progress, offer read-only access, or provide an alternate flow.
Quick checks you can do today
A few fast checks can prevent the “one provider is flaky, everything melts” day.
Start with your top three external dependencies (payments, auth, email/storage) and inspect the code paths that hit them:
- Every outbound call has a real timeout you chose on purpose.
- Retries are capped and intentional. Don’t retry anything that can cause double charges or duplicate writes unless you have idempotency in place.
- Each critical dependency has a plan B that the user can understand.
- Breaker state changes are visible in logs (and ideally a dashboard).
- Recovery is automatic via safe half-open probes.
To test quickly, simulate a provider failure for five minutes in a safe environment. Make the call fail (blocked network, forced 500), confirm users get a predictable outcome (message, cache, or queued work), confirm the breaker opens, then restore the provider and verify it recovers without manual babysitting.
Next steps: make dependency failures boring, not catastrophic
Write down your top dependencies and the exact user flows they touch: “Checkout,” “Log in,” “Password reset,” “Send invite.” Then decide what “good enough” looks like if each one is down. Sometimes the right answer is simply failing fast with a clear message and a safe retry later.
After that, add one wrapper layer per provider so timeouts, retries, the circuit breaker pattern, and logging live in one place. If you only do one this week, pick the dependency tied to revenue or access.
If you’re inheriting an AI-generated app that falls apart under real traffic, FixMyMess (fixmymess.ai) can run a free code audit and pinpoint missing timeouts, risky retry loops, and weak dependency failure handling. It’s often possible to stabilize the worst provider integrations quickly by adding clean wrappers, sane defaults, and honest fallbacks.
FAQ
What is a cascading failure, in plain terms?
A cascading failure happens when one slow or failing dependency makes your app wait, and those waiting requests pile up until healthy parts run out of threads, connections, or queue capacity. The fix is to stop waiting forever and stop repeatedly calling the failing service so the rest of the app can stay responsive.
How is a circuit breaker different from just adding timeouts and retries?
A circuit breaker is a rule around an external call that stops requests from hitting a dependency when it’s clearly unhealthy. Instead of hanging, your app fails fast and returns a controlled result (like cached data or “try again soon”), which prevents your servers from getting clogged.
How do I choose a sane timeout for a user-facing request?
Start with user tolerance: for a button click or page load, aim for a short timeout that keeps the UI feeling responsive (often a couple of seconds, not 20). If the call is optional, make the timeout even shorter and degrade gracefully; if it’s truly critical, fail fast with a clear message instead of letting requests pile up.
When should I avoid retries, and when are they safe?
Default to no retries (or at most one) for anything that can create duplicate side effects, like charges, sends, or writes. Retries are safest for idempotent reads, and even then you should add backoff and keep the total wait bounded so you don’t amplify an outage.
Where should I add circuit breakers first for the biggest impact?
Put breakers around synchronous calls that sit on the critical path: login/auth checks, checkout/payments, email/SMS for codes, and any API your main screens must call to render. You’ll get the biggest impact where one dependency can block lots of requests and tie up shared resources like connection pools.
What do closed, open, and half-open states actually mean?
“Closed” means calls flow normally while you track failures. “Open” means you temporarily block calls and immediately return a controlled response. “Half-open” means after a cooldown you allow a small number of probe calls to see if the dependency is healthy again before fully closing the circuit.
What’s a good fallback when a provider is down?
A good fallback keeps the user moving without pretending success. For example, if email sending is down, accept the signup and queue the email; if a pricing API is down, show the last known value with a clear note that it may be outdated. For money or security, be explicit about what did and did not happen.
Should I use one global circuit breaker for everything?
Make the breaker scope match the dependency and the type of call, not your whole app. A payments outage shouldn’t block reading profile data, and an email failure shouldn’t break login. If you scope too broadly, one flaky provider can unnecessarily disable unrelated features.
How can I test circuit breakers without causing a real outage?
Simulate the dependency failing for a few minutes in a safe environment and verify three things: requests fail fast, users see a predictable outcome, and the system stays responsive under load. Then restore the dependency and confirm the circuit moves through half-open probes and recovers automatically without manual intervention.
Why do AI-generated apps fail so badly with flaky providers, and what can FixMyMess do?
AI-generated code often ships with “happy path only” handling: long or missing timeouts, aggressive retry loops, and provider calls scattered across routes. If you’re non-technical and inherited a prototype that melts down under real traffic, FixMyMess can run a free code audit and quickly stabilize the worst integrations by adding clean provider wrappers, sane timeouts, and honest fallbacks, often within 48–72 hours.