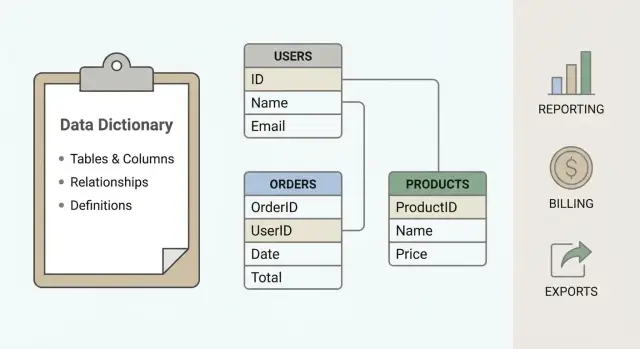
Data dictionary for a prototype database that avoids breakages
Learn how to create a data dictionary for a prototype database so table and column changes do not break reporting, billing, or exports.
Why prototypes break reporting and billing so easily
Prototype databases change fast. You add a column to get something working, rename a field so the UI reads better, or switch a data type to patch a bug. The app still runs, so it feels safe.
Reporting, billing, and exports are less forgiving. They rely on quiet assumptions: what an amount includes, which timestamp defines a month, what a status really means. When those assumptions change without anyone noticing, the numbers drift and nothing throws an error.
A common failure looks like this: a report sums amount, but a quick fix changes amount from “price before tax” to “price after discounts.” Totals still add up, but they mean something different. Billing goes out wrong, revenue charts stop matching, and it takes weeks to find the cause because the database is doing exactly what you asked.
Prototypes are fragile because column meaning is often unclear. Names like status, type, value, or total can hide different ideas in different places. One table’s status means “invoice sent,” another means “payment received,” and a third means “subscription active.” Add AI-generated code and you often get inconsistent naming, duplicate fields, and logic spread across multiple tables.
Most breakages come from small, “obvious” edits:
- renaming columns that dashboards or exports depend on
- reusing a column for a new purpose instead of creating a new one
- mixing units (cents vs dollars, UTC vs local time)
- changing how nulls or defaults behave
- backfilling data without matching the original rules
A data dictionary is the simplest guardrail against this. It’s a plain-language note for each table and column: what it represents, where it comes from, and how it should be used. The goal isn’t perfect documentation. It’s being able to change the schema without changing what your business numbers mean.
What a data dictionary is (and what it is not)
A data dictionary is a plain-English map of your database. It focuses on meaning and rules, not just structure.
The important shift is moving from “what it stores” to “what it means.” A column named amount might store a number, but the meaning could be “subtotal in cents, before tax, in the customer’s billing currency, excluding refunds.” Without that meaning written down, two people will use the same field in two different ways and totals won’t match.
What it should include
Keep it small, but complete enough that a new person can make a safe change:
- a description for every table and column (business meaning, not just type)
- rules and constraints (required vs optional, allowed values, rounding, time zone)
- ownership (who decides what it means and who approves changes)
- sources and destinations (where data comes from and where it’s used)
- notes on sensitive data (PII, tokens, retention expectations)
What it is not
A data dictionary is not an ER diagram, a list of SQL queries, or a dump of auto-generated schema comments. Those can help, but they usually explain shape, not meaning.
It’s also not a one-time task. It needs to move with your schema.
Where it should live
Put it somewhere people will actually update it: a doc, a shared spreadsheet, or a wiki page. The tool matters less than consistency. Pick one place, one format, and one owner.
Treat it like part of the change. If you add a column, rename one, or change how a value is calculated, update the dictionary the same day.
Start from the outputs people rely on
A prototype database is easiest to document from the outside in: start with what the business depends on today. Tables can change weekly, but invoices, dashboards, exports, and customer emails tend to become “truth” in people’s heads.
First, identify who gets hurt when numbers change:
- finance cares about totals, taxes, and refunds
- ops cares about fulfillment and delivery status
- product cares about what the app does in edge cases
- analytics cares about definitions and time windows
- support cares about what customers see and what agents can explain
Then pick a few business-critical outputs and treat each one like a contract, written in plain words. Examples:
- “Invoice total = sum(line items) + tax - discounts.”
- “Monthly active users excludes internal accounts.”
Those sentences become anchors for your table and column definitions.
Don’t guess. Collect a few real artifacts your team already trusts:
- a recent paid invoice or receipt
- one CSV export a customer or teammate actually uses
- a dashboard screenshot that people treat as “source of truth”
- a support email template that includes numbers (trial ending, amount due)
- a sample API response used by another system
Choose a small first scope: the 5-10 tables that feed money and core metrics. If you can trace “Subtotal,” “Tax,” and “Total” on an invoice back to the exact query that calculates them, you’ve found your starting set.
What to document for each table and column
Start with what your database already knows, then add the human meaning that prevents “small” fixes from breaking reporting, billing, or exports.
For each table
Write a one-sentence purpose that removes ambiguity.
Example: invoices stores one row per customer invoice, not per payment attempt.
That one line saves hours later when someone joins the wrong table or assumes the wrong grain.
For each column
Capture two layers:
- Schema facts: type, nullable, default, and whether it’s unique or indexed.
- Plain-English meaning: what it represents, plus 2-3 example values.
Then add the rules that keep numbers stable:
- Data rules: allowed values, units, rounding, and time zone assumptions.
- Lineage: where it comes from, who writes it, and when it updates.
- Privacy notes: whether it contains PII and what must never be exported.
Data rules are where prototypes hide the worst landmines:
- If you have
amount, say dollars or cents, currency, and rounding. - If you have
created_at, state the time zone and whether the app or database sets it. - If you have
status, list allowed values and what each value means.
Lineage matters even more in messy prototypes. A column might be written by a background job, a webhook, or a client-side form. If nobody can answer “what creates this value?”, reports will drift.
Finally, flag privacy clearly. Mark email, address, IP, and any tokens or secrets, and note what should never appear in exports.
A simple data dictionary template you can reuse
Pick a format you’ll actually maintain. For small prototypes, one spreadsheet is enough: either one tab per table, or a single tab where rows are grouped by table name.
A useful data dictionary helps you answer two questions quickly:
- What does this field mean?
- What will break if it changes?
Template (copy/paste)
Use the same set of columns for every table, even if some cells are blank at first:
Table:
| Column | Type | Null? | Description | Example | Key/Relation | Used by (report/billing/export) | Owner | Notes / Warnings |
|--------|------|-------|-------------|---------|--------------|----------------------------------|-------|------------------|
| id | uuid | no | Primary identifier for this row | 8f... | PK | internal joins | Eng | DO NOT CHANGE format |
In “Key/Relation,” write simple join hints, not essays. Example: “FK -> users.id (many invoices belong to one user).”
If a relationship is only implied in code (common in AI-generated prototypes), still document it as “logical FK” so the next person doesn’t miss it.
Add warnings only where they matter. If a column feeds invoice totals, taxes, revenue reports, or a customer-facing export, label it clearly (for example, “feeds invoice totals - don’t change name/type without updating exports”).
Naming rules that prevent confusion
You don’t need a huge style guide. A few consistent conventions prevent most schema drift:
- pick singular or plural table names and stick to it
- choose one primary key format (
idor<table>_id) and keep it consistent - name foreign keys
<referenced_table>_id(example:customer_id) - store money in integer cents where possible (example:
amount_cents) and document rounding - standardize timestamps (
created_at,updated_at) and document the time zone
Build the first version in one afternoon
You don’t need a perfect doc. You need something that stops you from breaking money and metrics.
1) Export the schema you already have
List every table and column as they exist today. Most databases and ORMs can produce this quickly (admin UI, schema file, SQL dump). Paste it into a spreadsheet or doc, one row per column.
Do a quick triage and mark the tables that touch:
- invoices, payments, subscriptions, discounts, refunds
- metrics dashboards and weekly reports
- any CSV export or integration that leaves your system
If you’re unsure, search the code for “invoice”, “total”, “export”, “report”, and “balance” and note which tables those queries hit.
2) Fill in meaning and rules, starting with money
Write definitions for the fields that drive totals and status changes. Start with currency and time because small misunderstandings create big problems.
Focus first on:
- amount fields (currency, tax included or not, cents vs decimals)
- status fields (allowed values and exact meaning)
- timestamps (what event it represents and the time zone)
- foreign keys (what the relationship means in real life)
- identifiers (what is user-facing vs internal-only)
Put the rule next to the column, not in a separate “rules” section.
Examples:
- “
invoice.status = paidonly after payment is captured, not when attempted.” - “
line_item.amount_centsexcludes discounts;discount_centsis separate.”
Then validate it with one non-technical person who depends on the numbers (finance or ops). Walk through a real scenario: “If a customer gets refunded, which columns change, and which report should still match?” Adjust wording until they agree.
Keep a tiny change log (date, what changed, why) and assign a review owner.
Tie columns to metrics, invoices, and exports
A dictionary is most valuable when it protects the outputs people rely on. Every key metric, invoice line, and export column should point back to the exact fields that produce it.
For each “can’t be wrong” output (MRR, paid invoices, outstanding balance, active subscribers, customer exports), capture:
- what it means (one sentence a non-technical teammate would agree with)
- the time rule (invoice date vs paid date, and which time zone)
- the filters (status values included, test accounts excluded)
- dependencies (table.column list, including join keys)
- the “source of truth” when values disagree
Be explicit when the schema offers two competing sources. If reporting could use either payments.amount or invoices.paid_amount, decide which wins and write down whether the other is derived (can be recalculated) or authoritative (must not be overwritten).
Document edge cases that often cause mismatches:
- refunds as negative payments vs separate refund rows
- partial payments and multiple payments per invoice
- canceled subscriptions that still bill through period end
- backdated invoices or migrated historical data
- duplicate customers created by “magic” sign-up flows
You don’t need to paste SQL everywhere. Recording the logic in words is usually enough:
- “Sum payments where status is
succeeded, grouped by invoice month, excluding refunds, usingpaid_at.”
Common mistakes that lead to expensive surprises
Prototype databases “work” because the app is forgiving. The surprise comes later, when a small change breaks a report, an invoice total, or a CSV export a customer depends on.
Renaming without checking downstream usage
The app might still run, but finance sheets, BI dashboards, and export scripts can still be looking for the old name.
Vague money fields
A column called amount can mean cents or dollars, net or gross, before tax or after tax, refunds included or not. If nobody writes that down, you’ll end up arguing about “why totals don’t match.”
Mixed timestamps
Prototypes often mix created_at, paid_at, fulfilled_at, and “when the job finished” in the same chart. If one report groups by creation time and another groups by payment time, month-end numbers can swing.
Inconsistent ID types
If customer_id is a string in one table and an integer in another, joins fail, duplicates appear, and exports miss rows.
“Status” turning into a junk drawer
New values get added during crunch time, and nobody documents what they mean. Later, someone filters for the wrong set of statuses and silently changes a metric.
If you want a quick set of smells to flag before shipping a change:
- a column name changed but reports/exports weren’t checked
- money fields don’t specify currency and whether they include tax
- multiple timestamps exist but only one is used “because it was there”
- IDs don’t share the same type across tables
- status values aren’t listed with plain-English meaning
Quick checklist before you change the database
Before you rename a column or “just add one more field,” pause and verify the parts that keep cash and reporting correct.
- Billing tables have owners. If a table affects invoices, payments, subscriptions, discounts, or refunds, someone is responsible for what it means and when it should change.
- Every money column is unambiguous. Document currency, precision (cents?), and whether it’s net or gross. Note whether it includes tax, fees, or credits.
- Every time field states the event and time zone. “created_at” can mean when the row was inserted, when the user clicked “Pay,” or when money settled. Pick one meaning and document it.
- Main joins are called out. List the “golden path” joins used in reporting (for example: invoices -> invoice_items -> customers).
- Exports spell out contracts. If an export expects ISO dates, integer cents, or specific column names, write that down so a refactor doesn’t break downstream tools.
Keep a simple change log that answers:
- what changed (schema and definition)
- who changed it and when
- why it changed, and what outputs to re-check
A small example: renaming paid_at to paid_on might look harmless, but it can break an accounting export or shift “paid today” metrics if the new field starts storing a different event time.
Example: fixing a messy billing schema without breaking totals
A common prototype problem: an AI-built app has invoices and a transactions table, but nobody can say what each field means. You see columns like amount, total, fee, status, type, notes, and meta. Reporting looks fine until you “clean up” the schema and invoice totals, taxes, or refunds stop matching what customers paid.
Start small: focus only on billing. Pick one invoice you know is correct (the amount the customer paid matches your payment processor). Trace how the UI total was calculated, then write down the meaning of each column involved.
Clarify what really drives totals
Be explicit about the source of truth and sign conventions:
transactions.gross_amount_cents: full charge before discounts and refunds (document currency and rounding).transactions.tax_cents: tax portion, and whether it’s included in gross or added on top.transactions.discount_cents: discounts applied at charge time, not after.transactions.refund_cents: refunds recorded as positive cents (or negative rows). Choose one rule and document it.invoices.total_cents: define the formula (gross - discount - refunds + tax) and the exact rows it sums.
Once those meanings are written down, a “small refactor” like renaming amount to total can’t happen casually. If someone changes types (cents to dollars), switches sign conventions, or filters by a different status, you can immediately see what reports and invoices will change.
Document one export end to end
Pick one CSV export that finance or an agency actually uses. Write down expected columns, formats, and assumptions. Example:
invoice_number(string)issued_at(ISO date)subtotal_cents(integer)tax_cents(integer)total_cents(integer)- whether refunds appear as separate rows
This is where hidden breakages show up. Downstream tools often expect cents, stable column names, and consistent refund handling. A dictionary forces you to keep those contracts intact.
If the schema is messy or unsafe to touch (unclear joins, inconsistent currencies, sensitive values in the wrong places), pause the refactor and get a plan before changing anything.
Next steps: keep it updated, and get help when the prototype fights back
A data dictionary only protects you if it stays current. The simplest rule works well: no schema change ships until the dictionary entry is updated.
Keep definitions friendly for non-technical teammates. Aim for one sentence, one meaning. If a column means two things depending on the screen or workflow, assume reporting or billing is already inconsistent.
Add a lightweight review for high-risk changes
You don’t need a big process, but you do need a pause button for anything that touches money or core metrics.
Before merging a change that affects billing or reporting, confirm:
- the dictionary entry was updated (table, column, meaning, example)
- dependent reports/exports/invoice calculations were identified
- old values are handled (migration plan or default behavior)
- someone owns the definition (a name, not “engineering”)
If you inherited an AI-generated prototype and you’re not sure what’s safe to change, a short audit can save days of back-and-forth. FixMyMess (fixmymess.ai) does codebase diagnosis and repairs for AI-built apps, and offers a free code audit to map issues in billing, reporting, and database logic before you touch production data.
FAQ
Where should I start if my prototype database is already messy?
Start with the outputs that people treat as truth: invoices, payment receipts, a key dashboard, and any CSV export someone uses weekly. Pick the 5–10 tables that feed those outputs and document them first, then expand as needed.
What makes a data dictionary different from a schema or ER diagram?
A data dictionary explains what each table and column means in business terms, not just its SQL type. It should also capture the rules that keep numbers stable, like units, rounding, time zone, allowed status values, and what reports or exports depend on the field.
How do I document money fields so billing totals don’t drift?
Write the meaning in one sentence and make it unambiguous, for example: “amount_cents is the subtotal in cents, before tax, excluding refunds, in the invoice currency.” Add one or two example values and note whether it’s net or gross, and whether it includes discounts or tax.
What’s the simplest way to document timestamps so reports match month-end?
Pick one timestamp per concept and say what event it represents and what time zone it uses, for example “when payment was captured in UTC.” If you have multiple timestamps, note which one reporting should use for month grouping so you don’t mix “created” time with “paid” time.
How do I stop “status” fields from becoming ambiguous over time?
List the allowed values and define each one in plain language, including when it is set and what it implies for reporting. If different tables use status with different meanings, rename or clarify them in the dictionary so filters don’t silently change metrics.
What should I write for each table to avoid join mistakes?
For each table, write the “grain” in one line, like “one row per invoice” or “one row per payment attempt.” That single sentence prevents bad joins and double-counting, which is one of the fastest ways reporting breaks in prototypes.
Where should the data dictionary live so it stays updated?
Use whatever place your team will actually edit: a shared doc, a spreadsheet, or a wiki page. The key is having one location, one consistent template, and one person responsible for approving meaning changes to billing and reporting fields.
How do I keep the dictionary from going stale after a few weeks?
Treat the dictionary update as part of the change itself: if a column is added, renamed, or its meaning changes, update the entry the same day. Also note what downstream outputs depend on it, so you can re-check the right invoices, reports, or exports immediately.
What should I do before renaming a column that dashboards or exports use?
Don’t reuse the old column for a new meaning; create a new column and document both during the transition. If you must rename or change a type, first list every report, export, and invoice calculation that uses it, then migrate with a clear mapping so old and new values stay comparable.
Can FixMyMess help if my AI-built app’s billing and reporting are already unreliable?
Yes. FixMyMess can audit an AI-generated codebase to map billing and reporting logic, identify risky schema assumptions, and recommend safe fixes before you touch production data. If you need speed, they can repair and harden the app (or rebuild key parts) with human verification, and most projects are completed in 48–72 hours after the free code audit.