Reliable counters under concurrency: stop drifting metrics
Learn how to keep reliable counters under concurrency using atomic updates, idempotency keys, and batch writes so metrics stay accurate in production.
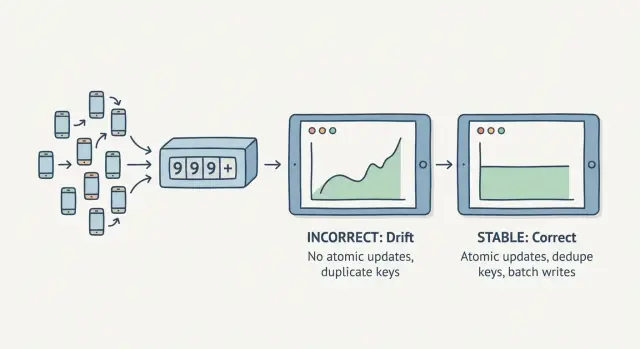
Why counters drift when traffic arrives at the same time
A counter drifts when you can’t trust it to stay consistent. You refresh a dashboard and the total changes even though nothing new happened. Or the number jumps after a short spike. This is hard to catch in testing because it usually needs real concurrency.
Drift often looks like this:
- The same report shows different totals on each refresh.
- Counts jump after a burst of traffic or a deploy.
- Totals in one place (database) don’t match another (analytics).
The usual cause is a race condition: many requests try to update the same number at the same time. If your code does “read the current value, add 1, write it back,” two requests can both read 10, both add 1, and both write 11. One increment disappears.
That’s why it often shows up only after launch. On a laptop or quiet staging environment, requests arrive one-by-one. After a campaign, a popular feature, or background jobs running in parallel, those updates collide.
There’s also a tradeoff between accuracy and freshness. Updating a counter on every request can be accurate, but only if the update is truly safe under concurrency. Many teams choose near real time instead: collect events quickly, then update totals in small batches every few seconds. The number looks slightly delayed, but it’s usually steadier and easier to make correct.
A simple example: two users hit “Buy” at the same second. If both requests compute and write the new total separately, your purchases counter can undercount even though both orders succeeded.
Pick the right metric type before you code
A lot of “counter problems” are really “definition problems.” If you choose the wrong metric type, fixing the increment won’t make your analytics stable.
When someone says they want “a counter,” they usually mean one of these:
- Counter: how many times something happened (page views, button clicks)
- Sum: total amount across events (revenue, minutes watched)
- Unique count: how many distinct users/items did something (unique signups, unique purchasers)
- Rate: a ratio over time (signups per hour, conversion rate)
A plain +1 is often fine for low-stakes, high-volume events like page views. A little noise from duplicates usually doesn’t matter.
But the moment money, user state, or messaging is involved, you need a tighter definition of “truth.” Signups, purchases, password reset emails, invites, and “trial started” events get retried more than people expect (clients, background jobs, payment providers). Counting retries as new events is how dashboards become inflated.
A practical way to decide is to pick your source of truth:
- Append-only events: store each event once, then compute totals from events.
- Stored totals: keep a running number and update it as events happen.
Event logs are easier to audit and recompute. Stored totals are faster to read, but only work if updates are correct and duplicates are blocked.
Example: a checkout receives payment_succeeded twice because the first webhook response timed out. If your “purchases” metric is a simple counter, it jumps by 2. If your truth is “one purchase per payment_id,” you measure unique payment IDs, not raw webhook deliveries.
Atomic updates: the safest way to increment
When you need reliable counters under concurrency, use atomic updates. “Atomic” means the change happens as a single operation: it applies once, or not at all. No partial state, no two requests overwriting each other.
The classic bug is read-modify-write: read 100, add 1 in app code, write 101. Two requests can both read 100 and both write 101.
Atomic updates do the increment inside the database or store, where it can be applied safely even when many requests arrive at once:
UPDATE counters
SET value = value + 1
WHERE name = 'signups';
INCR signups
A quick sanity check: if your app reads the counter value just to increment it, you’re probably back in read-modify-write territory.
Atomic increments aren’t free. If a single row/key is updated constantly (a “hot key” like a global pageviews counter), you can run into:
- Lock contention or slower updates
- Higher latency during spikes
- Replication lag if you read from replicas
- Timeouts that trigger retries
Dedupe keys: stop double counting from retries and replays
Idempotency means submitting the same action twice has the same effect as submitting it once. For counters, it’s the difference between “mostly right” and trustworthy.
Duplicates are common:
- A user double-clicks “Pay now.”
- A mobile client loses connection and retries.
- A webhook provider re-sends after a 500.
- A queue re-delivers a job.
A dedupe key is usually an event_id that uniquely identifies the real-world event you’re counting. It can come from a provider webhook ID, a client-generated UUID, a server-generated ID, or a truly-unique deterministic key like order_id + event_type.
Once you have event_id, store it and refuse to count the same one twice. The basic rule is: insert the event_id first, then increment, or do both in one transaction.
Common storage options:
- A database table of processed events with a UNIQUE constraint on
event_id - A UNIQUE index on your analytics/events table
- A cache (like Redis) with a TTL for short-lived dedupe windows
Example: a purchase webhook arrives, your handler times out, and the provider replays it. Without dedupe, you record two purchases and increment revenue twice. With a unique event_id, the second attempt becomes a no-op.
Batch writes: fewer database hits, steadier analytics
Under load, single-row writes can pile up. That increases lock time, slows responses, and raises the chance of timeouts or partial failures. Batching cuts database round trips and can make analytics steadier.
A simple mental model: capture events quickly, then write summaries in fewer, larger updates. Common approaches include buffering then flushing every N seconds, queueing events and aggregating in workers, scheduled rollups (hourly/daily), or a hybrid (small real-time counters plus periodic backfills).
The tradeoff is freshness. Your dashboard might lag by seconds or minutes, but you’ll usually see fewer failed writes and fewer spikes caused by retry storms.
Pick the batch window based on what the metric is used for:
- Seconds: live feeds, rate limiting, “active now” widgets
- Tens of seconds: marketing dashboards and signup funnels
- Minutes: revenue and most admin reporting
- Hours/days: finance-grade reporting and audits
A safe pattern for counters and analytics
Treat every increment as the result of a specific event. The counter is just a summary.
A pattern that holds up under load:
-
Name the event and choose a stable unique id. Use something that stays the same across retries (for example:
order_id,payment_intent_id, or a generatedevent_idpassed through the flow). -
Record the event (or a lightweight dedupe row) first. Store the id in an
eventsordedupetable with a unique constraint. -
Increment with an atomic update. Use a single statement increment, not “read, add, write.” If you can, keep the event write and counter update in one transaction.
-
Make retries safe. If the dedupe insert fails because the key already exists, treat it as success and skip the increment.
-
Batch when it makes sense, without breaking the rules. Buffer increments and flush periodically, but only after the event/dedupe record is safely stored.
Example: a user clicks “Buy,” your server creates a purchase_completed event with dedupe key order_123. If the payment provider retries the webhook, the second insert hits the unique constraint and you don’t add a second purchase.
Retries, timeouts, and message queues without inflating counts
Many systems deliver events with an “at-least-once” guarantee. Plain English: the same message can show up twice.
Timeouts are the sneakiest version. A client calls your API, waits, times out, and retries. But the server may have finished and committed the counter update. Now you have two “successful” attempts for one real action.
The rule: only retry work that is idempotent.
A practical queue pattern:
- The API creates an event with a unique
event_id(for example,purchase-<order_id>) and enqueues it. - A worker processes the event and writes two things in one transaction: (1) mark
event_idas processed, (2) increment the counter. - If the message is redelivered, the worker sees
event_idalready processed and skips the increment.
For incident debugging, keep logs boring and consistent:
event_id- timestamps (received and committed)
- source (API, queue, cron)
- outcome (processed, skipped as duplicate, failed)
- retry count
Common mistakes that cause drifting metrics
These problems repeat across products.
Mistake 1: Read then write increments
Two requests can read the same value and write the same new value. Use a database atomic increment so the update happens in one operation.
Mistake 2: Counting before the action truly succeeds
If you increment when a request starts, you’ll overcount when the action later fails (declined payment, failed email send, rolled-back transaction). Count after you have a real success signal.
Mistake 3: Dedupe keys without enforcement
A dedupe key only works if you enforce uniqueness at the database level (unique constraint/index). Without it, duplicates still slip through under retries and parallel workers.
Mistake 4: Batch writes that lose data
Batching reduces load, but in-memory buffers can disappear on restarts. Make flush behavior explicit: time-based flush, size-based flush, and a shutdown flush.
Mistake 5: Broken day boundaries in rollups
Daily metrics drift when services disagree on time zones or day boundaries. Pick one standard (often UTC), store timestamps consistently, and keep raw events long enough to recompute rollups.
Quick checks to verify your counters are trustworthy
If you can’t explain an increment, you can’t prove it’s correct. Even a simple raw events table is enough to do spot checks.
A fast sanity scan:
- Can you trace each increment to an
event_idstored with the raw event? - Do you enforce uniqueness for dedupe keys (unique index/constraint)?
- Are counters updated with atomic updates (single statement), not read-modify-write in app code?
- Do you reconcile totals against raw events (even a daily spot check)?
- Do you alert on sudden resets or unusually large jumps?
A practical test: pick one metric like “new signups,” pull 50 recent event_ids, and verify each one maps to exactly one increment. Then replay the same request/message a few times and confirm the counter doesn’t move.
Example: fixing signup and purchase counters in a real app
A small subscription app tracks signups, purchases, and “welcome email sent.” For weeks the dashboard looks fine. Then traffic grows and support starts hearing “I got charged twice” or “I clicked once.” Totals creep away from payment reports.
What’s happening: double-clicks, client retries after timeouts, and replayed payment webhooks. If your code increments first and asks questions later, metrics drift.
A stable fix combines three moves:
- Dedupe per action:
signup:<user_id>,purchase:<payment_event_id>,email:<message_id>, stored with a unique constraint. - Atomic increments: replace read-modify-write with a single database increment.
- Batch high-volume updates: keep real-time where you need it, batch where you don’t.
A simple rollout plan:
- Replay the same webhook payload 5-10 times in staging and confirm counters don’t move after the first.
- Ship behind a feature flag and enable for a small slice of traffic.
- Run a reconciliation job to compare raw events vs counters and backfill differences.
- Monitor “dedupe hits” to confirm retries are being caught.
Next steps: stabilize metrics without rewriting everything
You usually don’t need a full rebuild. You need a clear map of where counts are created, where retries can happen, and where duplicates sneak in.
Start with a basic inventory:
- Where each counter lives (database, cache, analytics tool)
- Where events originate (endpoints, background jobs, webhooks)
- Every retry path (client retries, queue retries, webhook redelivery)
- How you identify an event (
event_id,request_id,order_id) - Where writes happen (one place vs many)
Then fix in this order:
- Stop double counting (dedupe keys and idempotent handling on the hottest paths)
- Make increments atomic
- Improve performance (batching, async processing)
- Add ongoing checks (reconcile raw events vs counters, alert on weird jumps)
If you inherited an AI-generated codebase, assume counter logic was copy-pasted and implemented slightly differently in multiple places. Unifying those paths into one shared function or service is often the fastest way to make fixes stick.
If you want a second set of eyes, FixMyMess (fixmymess.ai) focuses on diagnosing and repairing issues like non-atomic updates, missing idempotency, and replay-sensitive webhooks in AI-generated apps. A free code audit can quickly highlight the few spots that cause the most drift under real traffic.