Best Practices für API-Fehlerbehandlung — klare Fehlermeldungen für Nutzer
Lernen Sie Best Practices zur API-Fehlerbehandlung: einheitliche Fehlerformate, sichere Meldungen und eine einfache Methode, Serverfehler in klare UI-Zustände zu überführen.
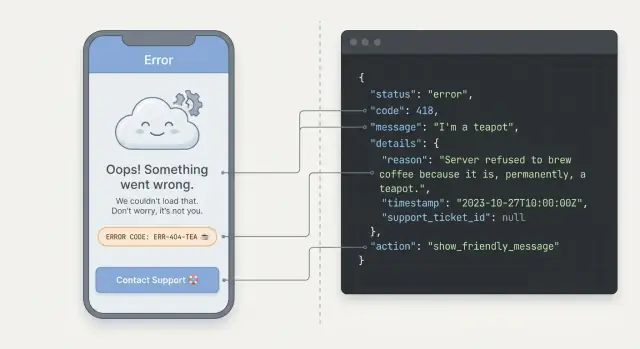
Warum unklare API-Fehler Nutzer frustrieren
Wenn eine App fehlschlägt, sehen Nutzer nicht „eine Ausnahme“. Sie sehen eine unterbrochene Aufgabe. Wenn die Meldung vage oder beängstigend ist, sorgen sie sich, Daten verloren zu haben, etwas falsch gemacht zu haben oder sogar gehackt worden zu sein. Die meisten werden nicht versuchen, das Problem zu debuggen. Sie verlassen die Seite, klicken wild auf den Button oder kontaktieren den Support.
Verwirrende Fehler wirken außerdem zufällig. Ein Bildschirm sagt „Etwas ist schiefgelaufen“, ein anderer zeigt einen langen Server-Stack-Trace und ein dritter liefert gar nichts zurück. Diese Inkonsistenz verunsichert, weil Nutzer nicht lernen, was sie erwarten können. Selbst wenn das Problem klein ist, wirkt die Erfahrung unzuverlässig.
Für Ihr Team erzeugen inkonsistente Fehler Lärm. Support-Tickets werden länger, weil Nutzer nicht beschreiben können, was genau passiert ist. Analytics füllt sich mit ungegliederten „unknown“-Fehlern. Entwickler verschwenden Zeit damit, Probleme zu reproduzieren, weil sich die Antwortstruktur zwischen Endpunkten ändert oder weil für alles ein 500-Status verwendet wird.
Wenn Fehler unklar sind, tun Nutzer in der Regel eines von drei Dingen: sie versuchen es wiederholt (was doppelte Anfragen und manchmal doppelte Belastungen verursachen kann), sie brechen den Ablauf ab (insbesondere Kasse, Anmeldung, Passwort-Reset) oder sie kontaktieren den Support mit Screenshots statt mit nützlichen Details.
Klare Fehlerbehandlung behebt das, indem drei Dinge standardisiert werden:
- Eine konsistente Fehlerstruktur (damit jeder Endpunkt auf dieselbe Weise fehlschlägt)
- Sichere Formulierungen (damit Nutzer einen klaren nächsten Schritt haben, ohne interne Details preiszugeben)
- Vorhersehbares UI-Verhalten (damit jeder Fehler einem bekannten Zustand wie „erneut versuchen“, „Eingabe korrigieren“ oder „erneut anmelden“ zugeordnet wird)
Was ein guter Fehler tun sollte (für Nutzer und Ihr Team)
Ein guter API-Fehler ist nicht nur „etwas ist schiefgegangen“. Er hilft einer echten Person, wieder handlungsfähig zu werden, und er hilft Ihrem Team, die Ursache schnell zu finden.
Für Nutzer braucht ein Fehler drei Dinge: was passiert ist (in einfachen Worten), was als Nächstes zu tun ist (ein klarer Schritt) und ob ihre Daten sicher sind. „Ihre Karte wurde abgelehnt. Versuchen Sie eine andere Karte oder rufen Sie Ihre Bank an. Es wurde keine Belastung vorgenommen.“ wirkt beruhigend und handlungsorientiert. „Zahlung fehlgeschlagen: 402“ tut das nicht.
Für Ihr Team sollte derselbe Fehler stabile Identifikatoren und nützlichen Kontext tragen. Das bedeutet meist eine kleine Menge an Fehlercodes, auf die Sie sich über Endpunkte hinweg verlassen können, sowie konsistente Felder, damit Logging, Alerts und UI-Handhabung nicht zusammenbrechen, wenn ein Endpunkt geändert wird. Wenn ein Nutzer ein Problem meldet, sollte der Support eine Fehler-ID aus der UI kopieren können und ein Entwickler den genauen Trace finden.
Was niemals in die UI gelangen darf
Manche Details sind fürs Debugging nützlich, aber unsicher (oder einfach verwirrend) für Nutzer. Halten Sie folgende Dinge aus nutzerorientierten Meldungen heraus:
- Geheimnisse (API-Keys, Tokens, Passwörter, Verbindungsstrings)
- Stack-Traces und interne Dateipfade
- Rohe SQL-Abfragen, Query-Parameter und komplette Request-Payloads
- Namen interner Services und Infrastruktur
- Detaillierte Validierungsregeln, die Angreifern helfen könnten, Eingaben zu erraten
Eine einfache Regel: Geben Sie sichere, benutzerfreundliche Meldungen zurück und behalten Sie die scharfen Details in Logs, verknüpft mit einem stabilen Code und einer Request-ID.
Wählen Sie einige UI-Zustände, die Sie überall unterstützen
Wenn jeder Bildschirm sein eigenes Fehlerverhalten erfindet, fühlen sich Nutzer verloren. Einigen Sie sich auf eine kleine Menge von UI-Zuständen, die jede Seite, jedes Modal und jedes Formular nutzen kann, und mappen Sie API-Fehler überall auf dieselbe Weise auf diese Zustände.
Für die meisten Apps reicht ein kurzes gemeinsames Vokabular: loading, success, empty, needs action (der Nutzer muss etwas ändern), try again (temporäres Problem) und blocked (er kann ohne Support oder einen anderen Plan nicht fortfahren).
Definieren Sie, was jeder Zustand in einfachen Worten bedeutet. Zum Beispiel bedeutet „empty“, dass die Anfrage erfolgreich war, aber nichts angezeigt wird, während „try again“ bedeutet, dass die Anfrage fehlgeschlagen ist und ein erneuter Versuch funktionieren könnte.
Entscheiden Sie, was retrybar ist und was nicht. Ein Timeout, Rate Limit oder Serverüberlastung ist oft retrybar. Fehlende Berechtigung, ungültige Eingabe oder ein abgelaufenes Konto sind normalerweise nicht retrybar, bis sich etwas ändert.
Eine kurze Regel hilft:
- Try again: temporär, sicher zu wiederholen
- Needs action: der Nutzer kann es beheben (bearbeiten, anmelden, E-Mail bestätigen)
- Blocked: der Nutzer kann es nicht allein beheben
Planen Sie auch Teil-Erfolge. Das passiert bei Massenaktionen: 8 Elemente wurden gespeichert und 2 schlugen fehl. Die UI sollte weiterhin zeigen, was erfolgreich war, dann klar aufzeigen, was Aktion benötigt, und dem Nutzer erlauben, nur die fehlgeschlagenen Elemente erneut zu versuchen.
Entwerfen Sie eine konsistente Fehlerstruktur (ein Format für alle Endpunkte)
Wenn jeder Endpunkt Fehler unterschiedlich zurückgibt, muss Ihre UI raten, was passiert ist. Eine einzige, vorhersehbare Fehlerstruktur ist eine der praktischsten Best Practices, weil sie Ihnen erlaubt, eine Reihe von UI-Regeln zu bauen und überall wiederzuverwenden.
Ein einfaches JSON-Format
Wählen Sie eine JSON-Struktur und geben Sie sie für alle Fehler zurück (Validierung, Auth, Rate Limits, Server-Bugs). Halten Sie sie klein, lassen Sie aber Platz für Details.
{
"error": {
"code": "AUTH_INVALID_CREDENTIALS",
"message": "Email or password is incorrect.",
"details": {
"fields": {
"email": "Not a valid email address"
}
},
"developerMessage": "User not found for email: [email protected]"
},
"requestId": "req_01HZX..."
}
Verwenden Sie stabile Fehlercodes und behandeln Sie den Message-Text nicht als Vertrag. Die UI sollte Codes auf den richtigen Zustand abbilden, während die Nachricht menschenfreundlich bleibt.
Es hilft oft, zwei Nachrichten zu haben: eine Nutzermeldung, die sicher angezeigt werden kann, und eine optionale Entwicklermeldung, die beim Debuggen hilft, aber ebenfalls keine Geheimnisse enthalten sollte.
Für Formulare reservieren Sie einen klaren Platz für Feldfehler, damit Sie spezifische Eingaben hervorheben können, ohne Text parsen zu müssen.
Ein paar Regeln, die später Chaos verhindern:
- Immer
error.codeundrequestIdeinbeziehen. error.messagesicher und einfach halten.- Feldspezifische Probleme unter
details.fieldsablegen. - Codes stabil halten, auch wenn sich die Formulierungen ändern.
- Niemals Stack-Traces oder Zugangsdaten leaken.
Sichere Fehlermeldungen, die Nutzer verstehen
Gute Fehler helfen Menschen, sich zu erholen. Schlechte Fehler führen dazu, dass sie dasselbe wiederholen oder den Ablauf abbrechen. Seien Sie konkret, was der Nutzer als Nächstes tun kann, ohne zu verraten, wie Ihr System intern funktioniert.
Eine sichere Meldung erklärt Ergebnis und nächsten Schritt, ohne Details wie Tabellenamen, Stack-Traces, Anbieterantworten, geheime Schlüssel oder ob eine E-Mail-Adresse im System existiert, zu offenbaren.
Halten Sie zwei Nachrichten bereit: eine für Nutzer, eine für Entwickler. Die Nutzermeldung sollte kurz und ruhig sein. Die interne kann den technischen Grund, den fehlerhaften Service und einen kompletten Trace enthalten (aber nur in Logs, nicht in der API-Antwort für Endnutzer).
Muster, die gut funktionieren:
- Sagen Sie in einfachen Worten, was passiert ist: „Wir konnten Ihre Änderungen nicht speichern.“
- Sagen Sie, was als Nächstes zu tun ist: „Versuchen Sie es in einer Minute erneut“ oder „Überprüfen Sie die markierten Felder.“
- Vermeiden Sie Schuldzuweisungen und Fachjargon: verzichten Sie auf „invalid payload“ und „unauthorized.“
- Verwenden Sie überall denselben Ton, damit Fehler vertraut wirken, nicht bedrohlich.
Fehlercodes können helfen, sollten aber wie Support-Handles behandelt werden, nicht wie Rätsel. Wenn es dem Support hilft, zeigen Sie einen kurzen stabilen Code (z. B. „Error: AUTH-102“) und halten Sie ihn über die Zeit konsistent.
Beispiel: Die Anmeldung schlägt fehl, weil die Datenbank einen Timeout hatte. Eine sichere Nutzermeldung wäre: „Wir konnten Ihr Konto gerade nicht erstellen. Bitte versuchen Sie es erneut.“ Ihre internen Logs können aufzeichnen: „DB timeout on users_insert, requestId=...".
Wenn Sie ein von AI generiertes Backend geerbt haben, fehlt diese Trennung oft. FixMyMess sieht häufig rohe Exceptions, die an Nutzer zurückgegeben werden. Eine der ersten Korrekturen ist, technische Details in Logs zu verschieben und die UI-Meldung klar und konsistent zu halten.
Server-Fehler auf UI-Zustände abbilden (eine einfache Tabelle)
Nutzer denken nicht in Statuscodes. Sie denken in Ergebnissen: „Ich kann das beheben“, „Ich muss mich erneut anmelden“ oder „Etwas ist ausgefallen.“ Wählen Sie eine kleine Menge UI-Zustände und ordnen Sie jeden Fehler einem davon zu.
Eine einfache Zuordnung, die Sie wiederverwenden können
Verwenden Sie dieselbe Zuordnung für Web, Mobile und Admin-Tools, damit das Verhalten konsistent bleibt.
| Was passiert ist | Typischer Code | UI-Zustand | Was die UI tun sollte |
|---|---|---|---|
| Fehlerhafte Anfrage (Ihre App hat etwas Falsches gesendet) | 400 | Fixable input | Heben Sie das Feld hervor oder zeigen Sie eine klare Meldung. Kein Retry vorschlagen. |
| Nicht eingeloggt / Session abgelaufen | 401 | Re-auth required | Zur Anmeldung weiterleiten, Arbeit des Nutzers wenn möglich behalten. |
| Eingeloggt, aber nicht berechtigt | 403 | No permission | Erklären, dass der Zugriff gesperrt ist, „Admin kontaktieren“ oder Konto wechseln anbieten. |
| Nicht gefunden | 404 | Missing resource | „Nicht gefunden“ zeigen und Navigation zurück anbieten. |
| Konflikt (existiert bereits, Versionskonflikt) | 409 | Resolve conflict | Refresh, umbenennen oder „erneut versuchen“ nach Sync anbieten. |
| Validierung fehlgeschlagen | 422 | Fixable input | Feldspezifische Meldungen anzeigen und Formularzustand erhalten. |
| Rate limit erreicht | 429 | Wait and retry | Sagen, kurz zu warten, Button kurz deaktivieren, dann erneut versuchen. |
| Serverfehler / Ausfall | 500 | Temporary failure | Entschuldigen, Retry erlauben und Support-Option zeigen. |
Netzwerkfehler und Timeouts sind getrennt von Server-Antworten. Behandeln Sie sie als „offline/instabile Verbindung“: den Nutzer auf dem gleichen Bildschirm halten, einen Retry-Button zeigen und vermeiden zu behaupten „Ihr Passwort ist falsch“, wenn die Anfrage nie abgeschlossen wurde.
Eine praktische Regel: Wenn der Nutzer es beheben kann, halten Sie ihn im Kontext (Formular bleibt ausgefüllt). Wenn er es nicht kann, wechseln Sie in einen sicheren Zustand (erneut anmelden, read-only oder Support kontaktieren).
Schritt für Schritt: konsistente Fehler einführen ohne kompletten Rewrite
Sie müssen nicht Ihre gesamte API neu bauen, um bessere Fehler zu bekommen. Fügen Sie eine dünne, konsistente Schicht um das Bestehende hinzu.
Beginnen Sie, indem Sie eine kleine Menge von Fehlercodes festlegen, die Sie überall unterstützen. Schreiben Sie kurze, klare Definitionen, damit Backend- und Frontend-Teams sie gleich interpretieren.
Führen Sie die Änderung an einer Stelle auf jeder Seite ein:
- Wählen Sie 8–15 Fehlercodes (z. B.
AUTH_REQUIRED,INVALID_INPUT,NOT_FOUND,RATE_LIMITED,CONFLICT,INTERNAL). Schreiben Sie, was jeder bedeutet und was der Nutzer sehen soll. - Fügen Sie einen serverseitigen Error-Formatter hinzu (Middleware/Filter), der dieselbe JSON-Struktur für jeden Endpunkt zurückgibt, auch bei unerwarteten Exceptions.
- Fügen Sie einen clientseitigen Error-Handler hinzu, der diese Struktur liest und in Ihre UI-Zustände mappt (inline Feldfehler, Banner, Toast, Vollseitenfehler).
- Migrieren Sie schrittweise: aktualisieren Sie zuerst die meistgenutzten Flows (Login, Signup, Checkout, Save). Den Rest lassen Sie, bis Sie ihn anfassen.
- Sperren Sie die Struktur mit einigen Tests, damit künftige Änderungen die Clients nicht brechen.
Ein praktischer Migrationsansatz ist, beide Formate kurzzeitig parallel zu unterstützen: Wenn ein Endpunkt bereits eigenes Fehler-JSON zurückgibt, leiten Sie es durch. Andernfalls wickeln Sie es in das neue Format. Das hält das Risiko niedrig.
Beispiel: Login zuerst reparieren. Der Server gibt keine rohen Stack-Traces mehr zurück, sondern einen stabilen Fehlercode mit einer sicheren Meldung. Der Client sieht INVALID_CREDENTIALS und zeigt eine Inlinemeldung beim Passwortfeld. Sieht er INTERNAL, zeigt er ein generisches Banner und bietet einen Retry an.
Das ist besonders nützlich in AI-generierten Codebasen, in denen jeder Endpunkt anders Fehler wirft. Ein zentraler Formatter und ein zentraler Mapper lassen die App schnell konsistent erscheinen.
Übliche Abläufe und wie Fehler in der UI präsentiert werden sollten
Nutzer erleben keinen „API-Fehler“. Sie erleben ein Formular, das sich nicht absendet, eine abgelaufene Session oder eine fehlgeschlagene Zahlung. Wenn Ihre UI jeden Fehler gleich behandelt, raten Nutzer, versuchen es blind erneut oder gehen weg.
Formulare: Validierung sollte lokal wirken
Wenn der Server sagt, eine Eingabe ist ungültig, zeigen Sie die Meldung direkt neben diesem Feld. Ein Banner oben wie „Etwas ist schiefgelaufen“ lässt Nutzer scannen und neu tippen.
Gute Muster:
- Markieren Sie das Feld, behalten Sie die Eingaben des Nutzers und fokussieren Sie das erste ungültige Feld.
- Verwenden Sie einfache Sprache wie „Passwort muss mindestens 12 Zeichen haben“ statt Codes.
- Gibt es einen allgemeinen Fehler (z. B. „E-Mail bereits vergeben“), zeigen Sie ihn in der Nähe des Absende-Buttons.
Auth: klar sein, was der Nutzer tun kann
Bei abgelaufenen Sessions legen Sie eine Regel fest und halten sich daran. Können Sie still im Hintergrund auffrischen, tun Sie das einmal und fahren Sie fort. Wenn nicht (Refresh fehlschlägt oder es eine sensible Aktion ist), zeigen Sie klar: „Bitte melden Sie sich erneut an.“ Vermeiden Sie, Nutzer auf eine leere Fehlerseite zu schicken.
Bei Zahlungen und Konflikten ist besondere Vorsicht nötig. Sagen Sie, was passiert ist und welche Aktion sicher ist: „Ihre Karte wurde nicht belastet. Bitte versuchen Sie es erneut.“ Bei Konflikten erklären Sie den nächsten Schritt: „Dieser Eintrag wurde woanders geändert. Aktualisieren Sie, um die neueste Version zu sehen.“
Datei-Uploads sollten eine klare Antwort geben: Was hat geklappt und was nicht? Zeigen Sie den Fortschritt, listen Sie erfolgreiche Dateien auf und bieten Sie einen einfachen Retry für fehlgeschlagene Dateien. Wenn ein Retry Duplikate erzeugen könnte, weisen Sie vorher darauf hin.
Beispiel: ein Login-Fehler, korrekt behandelt
Ein Nutzer öffnet Ihre App nach ein paar Tagen und versucht sich anzumelden. Sein gespeicherter Session-Token ist abgelaufen, der Server akzeptiert ihn nicht mehr. Das ist normal, aber die Erfahrung hängt davon ab, wie Sie das melden.
Hier eine einfache Antwort, die Best Practices folgt und sicher bleibt:
{
"error": {
"code": "AUTH_TOKEN_EXPIRED",
"message": "Your session expired. Please sign in again.",
"requestId": "req_7f3a1c9b2d"
}
}
Verwenden Sie einen klaren HTTP-Status (oft 401 Unauthorized für einen abgelaufenen oder fehlenden Token). Der code bleibt stabil für UI und Support. Die message ist menschenverständlich und offenbart nicht, welcher Teil der Auth fehlgeschlagen ist oder welche Library verwendet wird.
Auf der UI-Seite zeigen Sie einen ruhigen nächsten Schritt: „Ihre Sitzung ist abgelaufen. Melden Sie sich erneut an.“ Fügen Sie einen Button hinzu, der zurück zum Login führt. Zeigen Sie keine Stack-Traces, rohes JSON oder beängstigende Begriffe wie „invalid signature“. Wenn der Nutzer etwas bearbeitet hat, behalten Sie seine Arbeit und fordern nur beim Absenden eine erneute Auth an.
Für den Support zeigen Sie eine kleine Hilfsinformation oder eine Kopierfunktion mit der requestId (oder dem Fehlercode). Damit hat Ihr Team etwas Konkretes: „Bitte teilen Sie die Request-ID req_7f3a1c9b2d“, die sich mit den Logs abgleichen lässt.
Logging und Monitoring, die zu Ihren Fehlercodes passen
Wenn Ihre API einen klaren Fehlercode zurückgibt, die Logs das aber nicht tun, geht der Vorteil verloren. Die einfachste Regel ist, jedes Mal denselben error.code zu loggen, den Sie an den Client senden.
Ein guter Logeintrag ist klein, aber vollständig. Erfassen Sie genug, um zu debuggen, ohne sensible Daten zu dumpen:
error.codeund HTTP-Status (z. B.AUTH_INVALID_PASSWORD, 401)requestId(Correlation ID), damit Sie eine Anfrage von Anfang bis Ende verfolgen können- sichere Nutzerkontexte (userId, nicht E-Mail oder Tokens)
- der Bildschirm oder die Aktion (Route-Name, Endpoint, Methode)
- interne Details für Entwickler (Stack-Trace, Upstream-Error), nur serverseitig
Generieren Sie eine requestId am Edge (oder akzeptieren Sie eine vom Client) und geben Sie sie in der Antwort zurück. Wenn ein Fehler einen Nutzer blockiert, zeigen Sie eine kurze Meldung plus „Referenz-ID: X“, damit der Support den genauen Logeintrag schnell findet.
Monitoring besteht größtenteils aus Zählen und Gruppieren, sollte aber mit der UI übereinstimmen. Tracken Sie Fehler nach Code und nach Bildschirm, um Muster zu erkennen wie „PAYMENT_DECLINED tritt meist bei Checkout auf“ oder „RATE_LIMITED stieg nach einem Release an“.
Entscheiden Sie im Voraus, worauf Sie Alerts setzen, damit Notifications nicht zur Geräuschquelle werden:
- plötzliche Anstiege von 500-Fehlern (Serverausfälle)
- wiederholte Auth-Fehler (kann Bug oder Missbrauch sein)
- steigende Rate-Limit-Fehler (Kapazität oder Client-Bug)
- ein Fehlercode dominiert einen einzelnen Endpoint oder Bildschirm
Teams, die AI-generierte Backends reparieren, finden oft nicht passende Codes und fehlende Request-IDs. Das zuerst aufzuräumen macht spätere Fixes deutlich schneller.
Häufige Fehler und Fallen, die Sie vermeiden sollten
Viel schlechte UX kommt von kleinen Inkonsistenzen. Selbst wenn jeder Endpunkt für sich „korrekt“ ist, wirkt das Produkt zufällig, wenn Fehler unordentlich oder unsicher sind.
Häufige Fallen:
- Unterschiedliche Fehlerstrukturen von Endpunkt zu Endpunkt. Das Frontend wird zu einem Haufen Spezialfälle (
messagehier,errordort,errors[0]irgendwo anders). - Die Meldungstexte als „Code“ verwenden. Das funktioniert, bis jemand die Formulierung ändert (für Klarheit, Ton oder Übersetzung) — dann bricht Ihre UI-Logik.
- Stack-Traces, SQL-Snippets, interne IDs oder geheime Werte leaken. Nutzer können nichts damit anfangen, Angreifer schon.
- Jeden Fehler als Toast behandeln, der sagt „Etwas ist schiefgelaufen.“ Wenn der Nutzer es beheben kann, sagen Sie ihm wie. Wenn nicht, sagen Sie ihm, was zu tun ist.
- Unsichere Aktionen automatisch erneut versuchen. Das erneute Senden einer Leseoperation ist meist okay. Das automatische Wiederholen einer Schreiboperation kann Duplikate oder doppelte Belastungen erzeugen.
Teams stoßen oft in AI-generierten Backends auf solche Probleme. Bei FixMyMess sehen wir häufig Endpunkte, die mehrere Formate zurückgeben und versehentlich Geheimnisse in Fehlerausgaben offenlegen.
Schnelle Checkliste vor dem Release
Führen Sie das kurz vor einem Release durch — es fängt kleine Lücken ein, die zu aufgebrachten Tickets führen.
API-Ausgabe-Prüfungen
Stellen Sie sicher, dass jeder Endpunkt dieselbe „Fehlersprache“ spricht. Auch wenn die Ursache unterschiedlich ist, sollte die Antwort für den Client vertraut aussehen und sich leicht loggen lassen.
- Gibt jeder Endpunkt dieselbe Top-Level-Fehlerstruktur zurück (z. B.
error.code,error.message,requestId)? - Sind Fehlercodes stabil (ändern sich nicht nächste Woche) und in einfachen Worten dokumentiert?
- Gibt es immer eine sichere Nutzermeldung plus getrennte interne Details (in Logs), wenn nötig?
- Enthält jeder Fehler eine
requestId, damit der Support ihn schnell findet?
UI-Verhaltens-Prüfungen
Stellen Sie sicher, dass die App konsistent reagiert. Nutzer merken sich Muster.
- Mappt der Client Server-Fehler auf eine kleine Menge UI-Zustände (Validierung, Auth erforderlich, nicht gefunden, Konflikt, später erneut versuchen)?
- Vermeidet jede Meldung interne Details (Stack-Traces, SQL, Provider-Namen) und gibt einen klaren nächsten Schritt?
- Wenn ein Fehler handlungsfähig ist, zeigt die UI auf das Feld oder den Schritt, der korrigiert werden muss?
- Wenn er nicht handlungsfähig ist (Server down, Timeout), sagt die UI, dass es ein Problem auf Ihrer Seite ist, und bietet Retry an?
Wenn Ihr Projekt ein AI-generierter Prototyp ist, fehlen diese Basics oft oder sind inkonsistent. FixMyMess kann den Code auditieren und helfen, Fehlerbehandlung vorhersehbar zu machen, ohne alles neu zu schreiben.
Nächste Schritte (und wann Sie Hilfe beim Fixen brauchen)
Wählen Sie einen kritischen Flow und machen Sie ihn zuerst zur „Gold-Standard“-Implementierung. Login, Checkout oder Onboarding sind gute Kandidaten, weil sie Auth, Validierung und Drittanbieteraufrufe berühren.
Sammeln Sie vor Änderungen etwa 10 reale Fehlerbeispiele aus Produktion (oder aus Logs und Bug-Reports). Schreiben Sie sie so um, dass sie Ihrem neuen Standard entsprechen: gleiche Felder, gleiche Benennung, gleiche Detaillierung. Das gibt ein klares Ziel und verhindert endlose Debatten.
Ein praktikabler Weg, der oft funktioniert:
- Fügen Sie einen gemeinsamen serverseitigen Formatter hinzu, der jede geworfene Exception in Ihre Standardform bringt.
- Fügen Sie einen gemeinsamen clientseitigen Mapper hinzu, der diese Form in die UI-Zustände übersetzt (retry, Eingabe korrigieren, erneut anmelden, Support kontaktieren).
- Aktualisieren Sie nur den gewählten Flow komplett, inklusive Tests und ein paar simulierten Fehlern.
- Rollen Sie das Muster Endpoint für Endpoint aus, statt alles in einem Release zu reparieren.
- Halten Sie eine kurze Menge von Nachrichten-Regeln (was Nutzer sehen dürfen, was intern bleiben muss).
Wenn Ihre App von Tools wie Lovable, Bolt, v0, Cursor oder Replit generiert wurde, planen Sie extra Zeit ein. Diese Projekte haben oft inkonsistente Handler über Routen verteilt, doppelte Middleware und rohe Error-Objekte, die an den Client gelangen. Der schnellste Gewinn ist meist zentralisiertes Formatting und das Entfernen von Einzelantworten.
Holen Sie Hilfe, wenn Fehler mit tieferen Problemen verbunden sind: kaputte Auth-Flows, exponierte Geheimnisse, SQL-Injection-Risiken oder „läuft lokal, aber nicht in Produktion“-Logik. FixMyMess (fixmymess.ai) spezialisiert sich auf Diagnose und Reparatur AI-generierter Codebasen — inklusive Fehlerbehandlung, Security-Hardening und Deployment-Vorbereitung.
Wenn Sie diese Woche nur eines tun: machen Sie einen Flow konsistent und messbar. So verwandeln klare Fehler weniger Support-Tickets und ruhigere Nutzer.
Häufige Fragen
Was sollte jede API-Fehlermeldung enthalten?
Eine gute Grundausstattung ist ein stabiler Fehlercode, eine kurze, benutzerfreundliche Meldung und eine Request-ID. Der Code lässt die UI konsistent reagieren, die Meldung sagt dem Nutzer, was er als Nächstes tun soll, und die Request-ID hilft dem Support, den genauen Logeintrag zu finden.
Sollte ich mich auf HTTP-Statuscodes oder benutzerdefinierte Fehlercodes verlassen?
Behalte HTTP-Statuscodes sinnvoll bei, aber verlasse dich nicht ausschließlich auf sie. Nutze den Status für grobe Kategorien (Auth, Validierung, Serverfehler) und error.code für spezifische Fälle, damit die UI nicht raten muss.
Wie mache ich Fehler im gesamten App konsistent fühlbar?
Wähle eine kleine Menge an UI-Zuständen und mappe jeden Fehlercode auf einen davon. Wenn dasselbe Problem auf verschiedenen Bildschirmen auftritt, sollte die App überall gleich reagieren — mit derselben Tonalität und dem gleichen nächsten Schritt.
Wie schreibe ich Fehlermeldungen, die Nutzer tatsächlich verstehen?
Erkläre in einfacher Sprache, was passiert ist, sage dem Nutzer den nächsten Schritt und beruhige ihn, wenn nötig (z. B. ob eine Zahlung stattgefunden hat). Vermeide Fachjargon wie „unauthorized“ und vermeide Schuldzuweisungen gegenüber dem Nutzer.
Welche Details dürfen niemals in nutzergerichteten Fehlermeldungen erscheinen?
Zeige keine Stacktraces, internen Dateipfade, rohe SQL-Abfragen, Geheimnisse, Tokens oder detaillierte interne Servicenamen. Diese Informationen verwirren Nutzer und können ein Sicherheitsrisiko darstellen; behalte sie in den Server-Logs, verknüpft mit der Request-ID.
Was ist der beste Weg, Validierungsfehler in Formularen zu behandeln?
Behandle Validierung als „benötigt Aktion“ und zeige Fehlermeldungen direkt neben den jeweiligen Feldern. Lass das Formular ausgefüllt, fokussiere das erste ungültige Feld und vermeide generische Banner, die Nutzer zum Suchen zwingen.
Wie sollte meine App abgelaufene Sessions (401-Fehler) behandeln?
Bei abgelaufenen Sessions zeige eine klare Aufforderung, sich erneut anzumelden, und versuche, die Arbeit des Nutzers zu erhalten. Lege eine einheitliche Regel fest, damit Nutzer wissen, was sie erwarten können, und zeige keine technischen Texte wie Token- oder Signaturfehler.
Wie sollte ich Rate-Limits (429) und Wiederholungen behandeln?
Sage dem Nutzer, kurz zu warten und es erneut zu versuchen, und erwäge eine kurze Abkühlzeit in der UI, um schnelle Wiederholungen zu verhindern. Schlage kein Retry vor, wenn das Problem vom Nutzer behoben werden muss (z. B. ungültige Eingaben oder fehlende Berechtigung).
Wann ist es sicher, eine fehlgeschlagene Anfrage automatisch erneut zu versuchen?
Geh davon aus, dass Wiederholungen bei schreibenden Operationen Duplikate erzeugen können, sofern du nicht explizit Idempotenz implementiert hast. Wenn du die Sicherheit nicht garantieren kannst, führe keine automatische Wiederholung durch; zeige eine klare Option zum erneuten Senden und erkläre die Folgen.
Wie kann ich die Fehlerbehandlung verbessern, ohne meine gesamte API neu zu schreiben?
Füge einen serverseitigen Formatter hinzu, der jede Antwort in dieselbe Fehlerform bringt, und einen clientseitigen Handler, der Codes in UI-Zustände mappt. Wenn das Backend inkonsistent ist, kann FixMyMess schnell Ausnahmen finden und beheben, und so das Verhalten vorhersagbar machen.