API-Timeouts und Wiederholungen: sinnvolle Grenzen für Drittanbieteraufrufe
API-Timeouts und Retries verhindern, dass langsame Drittanbieter Ihre App einfrieren. Setzen Sie sinnvolle Timeouts, exponentielles Backoff, Retry-Grenzen und sichere Defaults.
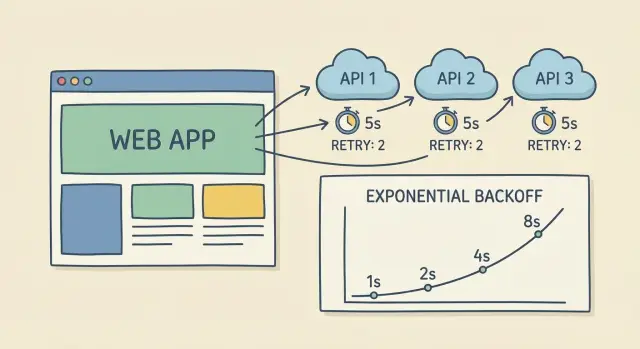
Warum langsame Drittanbieter-APIs Ihre App einfrieren können
Ein Drittanbieter-Aufruf wirkt klein — bis jede Anfrage davon abhängt. Wenn dieser Anbieter langsamer wird, fängt Ihre App an zu warten. Nutzer sehen endlose Lade-Indikatoren. Hintergrund-Jobs werden nicht fertig. Nichts „stürzt ab“, aber alles fühlt sich blockiert an.
Die meisten Apps haben begrenzte Kapazität: eine feste Anzahl Web-Threads, Serverless-Concurrency-Slots oder Queue-Worker. Wenn eine Anfrage an einem langsamen Anbieter hängt, hält sie diese Kapazität fest. Ein paar langsame Aufrufe können in einen Stau ausarten, sodass neue Arbeit gar nicht mehr starten kann.
Hängende Anfragen zeigen sich oft so:
- Web-Requests hängen, bis der Browser abbricht, obwohl Ihre Server als „up“ erscheinen.
- Worker bleiben beschäftigt, schließen Jobs aber nicht ab, die Queue wächst weiter.
- Ein Endpunkt belegt die meisten Threads (oder DB-Verbindungen), weil er auf einen externen Aufruf wartet.
- Retries feuern blind und wiederholen denselben langsamen Aufruf und vergrößern das Backlog.
Timeouts und Retries sollen eines erreichen: schnell fehlschlagen, sicher erneut versuchen und sauber wiederherstellen. Ein klares Timeout verhindert, dass ein langsamer Anbieter das ganze System einfriert. Konservative Retries helfen, sich von kurzen Störungen zu erholen, ohne einen selbstverschuldeten Ausfall zu erzeugen.
Das überrascht viele, weil HTTP-Client-Defaults oft zu nachsichtig sind. Manche sind auf sehr lange Timeouts gesetzt, andere warten effektiv ewig, wenn Sie nicht sowohl Connect- als auch Read-Timeout definieren. Viele KI-generierte Prototypen liefern diese Defaults aus, sodass das System genau das macht, was ihm gesagt wurde: weiter warten.
Betrachten Sie jeden Drittanbieter-Aufruf als potenziellen Flaschenhals, dann können Sie die App so gestalten, dass sie sauber degradieren kann: eine hilfreiche Meldung zeigen, die Aufgabe für später in die Queue legen oder auf eine Fallback-Option umschalten — statt alles zu blockieren.
Wichtige Begriffe: Timeouts, Retries, Backoff und Limits
Wenn Sie Drittanbieter-Integrationen zuverlässig betreiben wollen, klären Sie vier Basics: wie lange Sie warten, ob Sie erneut versuchen, wie Sie Versuche staffeln und wann Sie aufgeben.
Timeouts (die verschiedenen "Uhren")
Ein Timeout ist eine harte Regel: „Wenn wir nach X Sekunden keinen Fortschritt sehen, stoppen wir und geben die Kontrolle an die App zurück.“ Häufige Typen sind:
- Connect-Timeout: wie lange Sie warten, um eine Verbindung zu öffnen (DNS, Handshake, Netzwerkpfad). Fängt tote Netze schnell ab.
- Read-Timeout: wie lange Sie nach Daten warten, nachdem die Verbindung offen ist. Hier verletzen langsame Anbieter Sie oft.
- Gesamt-/Request-Timeout: die maximale Zeit für den gesamten Aufruf, von Anfang bis Ende. Das ist Ihr letzter Sicherheitsgurt.
Ohne Timeouts kann ein einzelner langsamer Anbieter Server-Threads oder Queue-Worker binden, bis alles zurückstaut.
Retries (erneut versuchen) vs. Timeouts (stoppen)
Ein Retry ist ein neuer Versuch nach einem Fehler. Retries sind kein Ersatz für Timeouts. Retries ohne Timeouts können schlimmer sein als gar keine Retries, weil Sie mehrere hängende Anfragen statt nur einer anhäufen.
Retries helfen bei temporären Problemen: kurzen Timeouts, 502/503-Fehlern und Netzwerkgestörten. Sie sind riskant bei „echten“ Fehlern wie falschen Zugangsdaten oder ungültigen Anfragen, wo Wiederholung nicht hilft.
Backoff und Jitter (klüger warten)
Backoff heißt, dass Sie zwischen den Retries immer länger warten (z. B. 1s, dann 2s, dann 4s). Jitter fügt eine kleine zufällige Verzögerung hinzu, damit viele Clients nicht exakt gleichzeitig erneut anfragen und den Anbieter wieder überlasten.
Retry-Limits (wann Sie aufgeben)
Ein Retry-Limit begrenzt die Versuche. „Aufgeben“ sollte ein sauberer Zustand sein: zeigen Sie eine Meldung wie „Der Dienst ist gerade langsam, bitte versuchen Sie es später erneut“, bewahren Sie den Nutzerzustand (Warenkorb, Entwurf, Formulardaten) und loggen Sie den Fehler für die Nachverfolgung, statt endlos zu drehen.
Sinnvolle Timeout-Werte wählen
Timeouts sind keine eine Zahl für alles. Wählen Sie sie pro Anbieter und Aufruftyp, basierend darauf, was für Nutzer akzeptabel ist und was Ihr System tolerieren kann, wenn ein Anbieter langsam ist.
Ein praktischer Anfang ist, „Kann ich verbinden?“ vom „Bekomme ich eine Antwort?“ zu trennen. Viele HTTP-Clients erlauben, beides zu setzen.
Typische Startbereiche:
- Connect-Timeout: 0,2 bis 1s für die meisten öffentlichen APIs, bis zu 2s wenn gelegentliche Netzschwankungen erwartet werden.
- Read-/Response-Timeout: 2 bis 10s für typische Anfragen; 15 bis 30s nur für bekannte lang laufende Endpunkte (Reports, Exporte).
- Schreibende Aufrufe (charge erstellen, Bestellung anlegen): Timeouts moderat halten (oft 5 bis 10s) und auf sichere Retry-Regeln bauen statt ewig zu warten.
- Polling/Statuschecks: kurze Timeouts (2 bis 5s) und weniger Retries.
Nutzerseitige Anfragen sollten strenger sein als Hintergrund-Jobs. Wenn die Checkout-Seite wartet, begrenzen Sie Drittanbieter-Aufrufe auf 3–5 Sekunden und zeigen eine klare Fallback-Meldung. Ein nächtlicher Sync im Hintergrund darf länger warten, braucht aber trotzdem Limits, damit sich keine hängen bleibenden Worker ansammeln.
Setzen Sie außerdem eine Gesamtdauer für die gesamte Operation, inklusive Retries. Beispiel: „Versuche insgesamt bis zu 20 Sekunden, dann fehlschlagen.“ Ohne das können Retries einen 5-Sekunden-Aufruf still und heimlich in ein 2-Minuten-Problem verwandeln.
Halten Sie Ihre Annahmen schriftlich, damit die nächste Person nicht raten muss:
- Typische Latenz des Anbieters (p50 und p95)
- Ihre UX-Toleranz (wie lange wartet ein Nutzer, bevor er abbricht)
- Maximale gesamte Zeit inklusive Retries
- Welche Endpunkte langsamer sein dürfen und warum
Wann retryen (und wann nicht)
Retries sind für Probleme gedacht, die sich vermutlich von selbst lösen. Wenn die Anfrage falsch ist, verschwendet ein Retry nur Zeit und kann einen Ausfall verschlimmern.
Retries machen in der Regel Sinn bei transienten Fehlern: Verbindungsabbrüchen, DNS-Aussetzern oder Timeouts. Sie können auch bei Rate-Limiting (HTTP 429) und einigen Server-Fehlern (5xx) sinnvoll sein, weil der Anbieter überlastet sein könnte.
Eine einfache Faustregel:
- Retry bei Netzwerkfehlern, Timeouts, 429 und ausgewählten 5xx (z. B. 502/503/504).
- Nicht retryen bei den meisten 4xx (z. B. 400, 401/403, 404), solange sich nichts ändert.
Retry-Afterbeachten, wenn die API diesen Header sendet.- Früh abbrechen, wenn eine klare permanente Fehlermeldung kommt.
Seien Sie vorsichtig bei Requests mit „unbekanntem Ergebnis“. Wenn Sie nach dem Senden einer Kartenabbuchung timeouten, kann ein Retry Duplikate erzeugen, es sei denn, Sie nutzen Idempotenzschlüssel oder einen Bestell-Token.
Ein praktikabler Ansatz trennt zwei Muster:
- Einen schnellen Retry für kleine Aussetzer (ein schneller Versuch nach ~100–200 ms).
- Eine kurze Backoff-Sequenz bei Throttling oder teilweisen Ausfällen (ein paar Versuche mit steigenden Verzögerungen).
So bleibt die App reaktionsschnell und erholt sich trotzdem, wenn der Anbieter einen Moment braucht.
Exponentielles Backoff mit Jitter, einfach erklärt
Wenn ein API-Aufruf fehlschlägt oder timeoutet, macht sofortiges Wiederholen das Problem oft größer. Exponentielles Backoff heißt: erst kurz warten, dann deutlich länger bei jedem weiteren Versuch. Es verringert den Druck auf den Anbieter und gibt dem Dienst Zeit zur Erholung.
Eine einfache Abfolge (mit einer Deckelung, damit es nicht ewig dauert):
- Versuch 1: warte 0,25s
- Versuch 2: warte 0,5s
- Versuch 3: warte 1s
- Versuch 4: warte 2s (hier deckeln)
Jitter fügt eine kleine Zufallskomponente hinzu. Ohne Jitter retryen tausende Clients exakt gleichzeitig (z. B. genau eine Sekunde später) und erzeugen einen weiteren Ansturm. Mit Jitter wartet ein Client vielleicht 0,8s, ein anderer 1,3s — Retries verteilen sich.
Zwei Leitplanken sind wichtig:
- Begrenzen Sie die maximale Verzögerung (oft 2–5 Sekunden).
- Halten Sie die Anzahl der Versuche klein und vorhersehbar, meist 2–4 Retries.
So bleibt die Worst-Case-Wartezeit überschaubar und Sie verhindern verdeckte Warteschlangen an hängender Arbeit.
Retries sicher machen: Idempotenz und Duplikat-Vermeidung
Retries können bei Netzstörungen retten, aber sie können auch Chaos erzeugen. Wiederholen Sie eine nicht-idempotente Aktion (z. B. „Karte belasten“ oder „Bestellung anlegen“), kann derselbe Klick zweimal ausgeführt werden. So entstehen doppelte Abbuchungen, doppelte Konten oder zwei Sendungen.
Eine einfache Regel: Retryen Sie nur Aufrufe, die sicher wiederholbar sind. Reads (GET) sind in der Regel sicher. Writes (POST, die etwas anlegen oder belasten) brauchen Schutz, bevor Sie Retries erlauben.
Idempotenz-Schlüssel verwenden, wenn der Anbieter sie unterstützt
Viele Payment-, Messaging- und Bestell-APIs erlauben ein Idempotency-Key-Feld. Generieren Sie einen eindeutigen Schlüssel für die Nutzeraktion (z. B. einen Checkout-Versuch) und verwenden Sie ihn bei jedem Retry. Der Anbieter liefert dann dasselbe Ergebnis zurück, statt die Aktion erneut auszuführen.
Speichern Sie diesen Schlüssel zusammen mit der Antwort und halten Sie ihn stabil, auch wenn der Nutzer die Seite neu lädt.
Eigene Dedupe-Logik, wenn der Anbieter nichts anbietet
Wenn es keine Idempotenz-Funktion gibt, können Sie Duplikate selbst verhindern. Halten Sie es einfach:
- Legen Sie vor dem Aufruf einen „Request-Record“ mit einer eindeutigen
request_idan. - Erzwingen Sie eine Unique-Constraint (z. B.
user_id + cart_id + action_type). - Speichern Sie die Anbieter-Antwort (Erfolg oder Fehler) und geben Sie sie bei Retries wieder zurück.
- Legen Sie ein kurzes TTL-Fenster fest, damit legitime spätere Käufe nicht blockiert werden.
- Loggen Sie eine stabile Request-ID, damit der Support den Ablauf End-to-End nachverfolgen kann.
Beispiel: Beim Checkout timeouted der erste Charge-Request, der Anbieter verarbeitet ihn später trotzdem. Ohne Idempotenz oder Dedupe könnten Sie doppelt belasten. Mit einer stabilen request_id können Sie sicher retryen und trotzdem ein einziges Endergebnis zeigen.
Laufende Fehler stoppen: Limits, Circuit Breaker und Fallbacks
Retries helfen bei kurzen Aussetzern. Wenn ein Anbieter down oder sehr langsam ist, können Retries aus einem kleinen Problem eine Flut hängender Anfragen machen. Das Ziel ist nicht „nie ausfallen“, sondern „kontrolliert ausfallen“, damit Ihre App nutzbar bleibt.
Harte Grenzen für jeden Aufruf
Jeder ausgehende Aufruf braucht Limits, die das Leiden schnell beenden. Halten Sie die Liste der Limits kurz und setzen Sie sie konsequent durch:
- Max. Versuche (z. B. insgesamt 3 Versuche)
- Max. verstrichene Zeit (z. B. nach 10 Sekunden insgesamt stoppen)
- Max. gleichzeitige Aufrufe (vermeiden Sie, dass 500 Requests auf einmal warten)
- Eine klare Definition dessen, was retrybar ist (nur Fehler, von denen Sie erwarten, dass sie sich erholen)
Diese Limits verhindern, dass ein langsamer Anbieter Ihren Web-Server einfriert, Jobs zurückstaut oder Rate-Limits aufbraucht.
Circuit Breaker verwenden, wenn ein Anbieter ausfällt
Ein Circuit Breaker heißt: wenn zu viele Aufrufe in kurzem Fenster fehlschlagen, pausieren Sie die Aufrufe für eine Weile. Während der Pause geben Sie sofort eine kontrollierte Antwort statt Timeouts abzuwarten. Nach einer Abkühlzeit erlauben Sie wenige Testaufrufe, um zu prüfen, ob der Anbieter wieder funktioniert.
Das isoliert einen Anbieter-Ausfall von Ihrer Kern-Anwendung. Nutzer können sich weiterhin einloggen, browsen und Fortschritte speichern, auch wenn eine Integration ungesund ist.
Fallbacks, die Nutzer weitermachen lassen
Fallbacks können so einfach sein wie gecachte Daten, eine „versuchen Sie es in einer Minute erneut“-Meldung oder ein degradierter Modus, der ein nicht-kritisches Feature überspringt.
Beispiel: Wenn Versandkosten beim Checkout timeouten, zeigen Sie einen Standard-Tarif oder erlauben Sie die Bestellung und bestätigen den Versand später per E-Mail.
Schritt-für-Schritt: Timeouts und Retries in eine bestehende App einbauen
Beginnen Sie damit, Verhalten konsistent zu machen. Wenn jede:r Entwickler:in Timeouts unterschiedlich setzt (oder vergisst), kann ein langsamer Anbieter trotzdem die ganze App blockieren.
1) HTTP-Defaults zentralisieren
Erstellen Sie einen gemeinsamen HTTP-Client (oder Wrapper) und leiten Sie alle ausgehenden Aufrufe darüber. Geben Sie ihm sichere Defaults: Connect-Timeout, Response-Timeout und eine harte Obergrenze für die gesamte Zeit (inkl. Retries). Loggen Sie jede Anfrage mit Anbieternamen, um Muster zu erkennen.
Fügen Sie dann eine kleine Provider-spezifische Policy-Schicht hinzu. Payments, Email, Maps und AI-Modelle verhalten sich unterschiedlich; dieselben Retry-Regeln passen selten überall.
2) Per-Provider-Overrides einrichten
Definieren Sie für jeden Anbieter:
- Timeouts (kurz für schnelle Endpunkte, nur länger, wo nötig)
- Retry-Regeln (welche Statuscodes und Netzwerkfehler zählen)
- Retry-Limits (max. Versuche und max. Gesamtzeit)
- Umgang mit Rate-Limits (429 und
Retry-Afterbeachten, mit begrenzter Anzahl an Retries)
Halten Sie Retries konservativ. Ein kaputter Anbieter soll schnell fehlschlagen und Ihre App freigeben.
3) Messen, was Ihre Nutzer fühlen
Tracken Sie einige Metriken regelmäßig: Timeout-Rate, Retries pro Anfrage, Erfolg-nach-Retry und Gesamt-Latenz (inkl. Warten). Wenn Retries „funktionieren“, aber 8 Sekunden zur Checkout-Zeit hinzufügen, fühlt der Nutzer sich trotzdem schlecht.
4) In Staging mit erzwungener Langsamkeit testen
Simulieren Sie langsame Antworten und flaky Verbindungen. Lassen Sie einen Provider-Aufruf in Staging 10 Sekunden schlafen und prüfen Sie, dass Ihre App nach 2 Sekunden timeoutet, mit Backoff retryt und dann am Limit stoppt. Testen Sie auch Teil-Ausfälle, z. B. jeder dritte Request schlägt fehl.
Häufige Fehler, die zu hängenden Requests führen
Hängende Anfragen entstehen meist aus einem Grund: es gibt keine klare Grenze, wie lange die App weiter versuchen wird. Wenn ein Anbieter langsam wird, sitzen Worker herum und das Backlog wächst, bis die ganze App blockiert ist.
Typische Muster, die leise Stapelbildung erzeugen:
- Zu hohe Retry-Anzahlen, die praktisch unendlich sind.
- Sofortige Retries ohne Pause, besonders unter Last.
- Keine Gesamtfrist, sodass Nutzer immer länger warten, während Ihre Server gebunden sind.
- Retryen permanenter Fehler (API-Key falsch, fehlende Berechtigungen, ungültige Payload) statt die Anfrage zu korrigieren.
- Ignorieren von Rate-Limits (429), was oft zu noch härterem Throttling führt.
Ein nützliches Modell: Retries sind für vorübergehende Probleme, nicht für permanente. "Sicher" sieht oft so aus: 2–3 zusätzliche Versuche, exponentielles Backoff mit Jitter und eine harte Obergrenze für die ganze Operation (z. B. „nach 10 Sekunden insgesamt stoppen“). Bei 429 behandeln Sie die angegebene Wartezeit des Anbieters als Teil des Vertrags.
Ein realistisches Beispiel: Ein Anbieter wird beim Checkout langsam
Stellen Sie sich einen Checkout-Flow mit drei Drittanbieter-Aufrufen vor: ein Payment-API zum Belasten der Karte, ein Versand-API für Live-Raten und ein E-Mail-Anbieter für die Rechnung.
Eines Nachmittags wird der Versand-Anbieter langsam. Ihre App fragt Raten an, die Anfrage hängt 25–30 Sekunden. Der Kunde starrt auf einen Spinner. Hält Ihr Server diese Anfrage offen, binden Sie Worker-Threads und bauen weitere Checkouts dahinter auf. Ein langsamer Anbieter kann die ganze Seite kaputt erscheinen lassen.
Ein sicherer Ablauf:
- Payments: kurzes Timeout; nicht automatisch retryen nach einem Charge-Versuch, außer Sie können die Sicherheit beweisen.
- Versandraten: schnell timeouten (z. B. 2–3s), wenige Retries mit Backoff, dann aufhören.
- Fallback: Wenn Versand weiterhin langsam ist, Standardrate anzeigen oder Bestellung zulassen und Versand später bestätigen.
- Nutzermeldung: „Wir konnten die Live-Raten nicht laden. Sie können die Bestellung trotzdem abschicken; wir bestätigen den Versand per E-Mail.“
Wichtig ist, wo Retries passieren. Auf der Checkout-Seite halten Sie Timeouts eng, damit der Kunde schnell eine Antwort bekommt. Nachdem die Bestellung erstellt ist, können Hintergrund-Retries länger laufen (immer noch mit strikten Limits), um die endgültige Rate zu holen und die Bestellung nachträglich zu aktualisieren, ohne den Nutzer zu blockieren.
Schnell-Checklist vor dem Release
Machen Sie einen Durchgang über jeden Drittanbieter-Aufruf (Payments, Email, Maps, Auth, Versand, AI-Provider). Das Ziel ist einfach: Ein langsamer Anbieter darf Ihre App nicht einfrieren, und ein kurzer Ausfall darf keine Berge hängender Anfragen erzeugen.
Stellen Sie sicher, dass jeder Aufruf hat:
- Ein kurzes Connect-Timeout
- Ein angemessenes Read-Timeout
- Eine Gesamtfrist für die gesamte Operation (inkl. Retries)
Für Retries:
- Nur bei transienten Fehlern retryen (Timeouts, temporäre Netzwerkfehler, klare 429/5xx)
- Exponentielles Backoff plus Jitter verwenden
- Max. Versuche und max. Gesamtzeit überall durchsetzen (HTTP-Client, Job-Queue, Background-Worker)
Machen Sie Retries sicher. Wenn eine Operation Duplikate erzeugen kann (Abbuchungen, Bestellungen, Kontoerstellung), fügen Sie Idempotenz-Schlüssel oder Dedupe-Mechanismen hinzu, bevor Sie Retries aktivieren.
Monitoring sollte pro Anbieter zeigen, was passiert: Timeout-Rate, Retry-Rate und durchschnittliche Latenz. So erkennen Sie Probleme früh, bevor sie zu Nutzer-gefühlsmäßigen Freezes werden.
Nächste Schritte: Integrationen stabilisieren ohne Overengineering
Finden Sie zuerst die Aufrufe, die ewig hängen können. Suchen Sie nach Requests ohne explizites Timeout, Hintergrund-Jobs, die „bis zum Erfolg“ retryen, und Workern, die nie aufgeben. Das sind die Kandidaten, die leise aufstauen und aus einem kleinen Anbieter-Problem einen Ausfall machen.
Wählen Sie ein oder zwei kritische Drittanbieter-APIs und vervollständigen Sie das Muster End-to-End, bevor Sie alles anpacken. Kritisch bedeutet meist: Geldflüsse, Anmeldung, Messaging oder alles, was eine Nutzeraktion blockiert. Implementieren Sie ein klares Timeout, eine Retry-Policy mit Backoff und ein hartes Retry-Limit. Fügen Sie einfaches Logging hinzu, damit Sie beantworten können: Wie oft haben wir retryt, wie lange haben wir gewartet und haben wir irgendwann Erfolg gehabt?
Wenn etwas schiefgeht, zählt Geschwindigkeit mehr als perfektes Tooling. Schreiben Sie ein kleines Incident-Playbook: wie man einen Anbieter temporär abschaltet (Feature-Flag oder Config-Toggle), was den Nutzern angezeigt wird, was man zuerst checkt (Anbieter-Status, Error-Rates, Queue-Tiefe) und wann man wieder einschaltet.
Wenn Sie einen KI-generierten Codebestand mit unsicheren Defaults geerbt haben, kann FixMyMess (fixmymess.ai) ein kostenloses Code-Audit durchführen, fehlende Timeouts, unkontrollierte Retries und fragile Integrationen aufzeigen und dabei helfen, den Prototyp in produktionsreife Software mit menschlich geprüften Fixes zu verwandeln.
Häufige Fragen
Why can a single slow third-party API make my whole app feel frozen?
Ihre Anwendung hat nur begrenzte Kapazität (Web-Threads, Serverless-Slots oder Worker). Wartet eine Anfrage ohne striktes Timeout auf eine langsame Drittanbieter-API, bindet sie diese Kapazität und neue Arbeit kann nicht starten — deshalb fühlt sich alles „eingefroren“ an, obwohl nichts abstürzt.
What timeouts should I set for most third-party API calls?
Setzen Sie ein kurzes Connect-Timeout, ein separates Read-/Response-Timeout und eine Gesamtdauer für die Anfrage. Ein typischer Startpunkt ist ~0,2–1s für den Verbindungsaufbau und 2–10s für die Antwort, und passen Sie das pro Anbieter an, je nachdem, was Ihre Nutzer tolerieren.
What’s the difference between a timeout and a retry?
Ein Timeout beendet das Warten und gibt die Kontrolle an die App zurück. Ein Retry ist ein neuer Versuch nach einem Fehler. Beides ist meist nötig: Timeouts verhindern stehende Arbeit, und eine kleine Anzahl an Retries hilft, kurze Aussetzer zu überbrücken.
Which errors should I retry, and which should I avoid retrying?
Retryen Sie nur Fehler, die wahrscheinlich vorübergehend sind, z. B. Timeouts, Netzwerkprobleme, 429-Rate-Limits und bestimmte 5xx-Fehler. Vermeiden Sie Retries für die meisten 4xx-Fehler (z. B. ungültige Anfrage oder falsche Zugangsdaten), da Wiederholungen nichts verbessern.
How do I do backoff and jitter without making things worse?
Verwenden Sie exponentielles Backoff und fügen Sie Jitter hinzu, damit viele Clients nicht exakt gleichzeitig erneut anfragen. Halten Sie es klein und vorhersagbar (z. B. 2–4 Retries mit einer gedeckelten Verzögerung), damit Sie keine langen Wartezeiten oder Backlogs erzeugen.
Why can retries cause double charges or duplicate orders?
Weil ein Retry eine schreibende Aktion wiederholen kann, wenn die erste Anfrage doch erfolgreich war, aber die Antwort verloren ging. Ohne Idempotenz oder Dedupe kann das zu doppelten Abbuchungen, doppelten Bestellungen oder mehrfachen Nachrichten führen.
Should timeouts be different for web requests vs. background jobs?
Für Nutzerinteraktionen wie Checkout sollten Timeouts eng sein und eine klare Fallback-Meldung angezeigt werden, wenn ein Anbieter langsam ist. Background-Jobs dürfen länger warten, müssen aber trotzdem strikte Grenzen haben, damit Worker nicht blockieren und die Queue nicht wächst.
When should I add a circuit breaker?
Ein Circuit Breaker sperrt Aufrufe für eine kurze Zeit, wenn viele Fehler in kurzer Zeit auftreten, und liefert stattdessen sofort eine kontrollierte Antwort. Nach einer Abkühlzeit werden vereinzelt Testaufrufe zugelassen, um zu prüfen, ob der Anbieter wieder gesund ist.
Why do AI-generated prototypes often ship with unsafe HTTP defaults?
Viele HTTP-Clients haben zu großzügige Standardwerte oder warten effektiv unbegrenzt, wenn weder Connect- noch Read-Timeout gesetzt sind. Viele KI-generierte Prototypen übernehmen diese Defaults, sodass die Anwendung genau das tut, was konfiguriert wurde: weiter warten.
What’s the fastest way to add sane timeouts and retries to an existing app?
Zentralisieren Sie ausgehende HTTP-Aufrufe hinter einem gemeinsamen Client mit sicheren Defaults. Wenn Sie unsicher sind, wo Timeouts und Retries fehlen, kann FixMyMess (fixmymess.ai) ein kostenloses Code-Audit durchführen und die Integrationen schnell mit menschlich geprüften Änderungen reparieren.