Datenbank-Transaktionen für atomare Schreibvorgänge: halb gespeicherte Daten verhindern
Lerne, wie Datenbank-Transaktionen für atomare Schreibvorgänge halb gespeicherte Datensätze verhindern — mit einfachen Schritten, Rollback-Handling und schnellen Checks für sicherere Apps.
Was „halb gespeicherte“ Datensätze sind und warum sie entstehen
Ein „halb gespeicherter“ Datensatz taucht auf, wenn eine Benutzeraktion mehrere Datenbankänderungen erfordert, aber nur einige davon erfolgreich sind. Der Benutzer denkt, die Aufgabe sei abgeschlossen, aber die Datenbank enthält nun eine teilweise abgeschlossene Version davon.
Beispiel: Ein Checkout sollte (1) eine Bestellung anlegen, (2) den Bestand reservieren und (3) einen Zahlungsversuch aufzeichnen. Wird die Bestellzeile angelegt, das Inventory-Update schlägt aber fehl, hast du eine Bestellung, die nicht versendet werden kann. Wird der Bestand reserviert, aber die Zahlungszeile fehlt, sieht der Support verschwundenen Lagerbestand ohne Umsätze.
Diese Art von Inkonsistenz erzeugt Bugs, die zufällig erscheinen:
- fehlende Zeilen (eine Bestellung existiert, aber keine Bestellpositionen)
- nicht übereinstimmende Summen (Rechnungsbetrag passt nicht zu den Positionen)
- verwaiste Datensätze (eine Zahlung verweist auf eine Bestellung, die nie angelegt wurde)
- duplizierte Datensätze (ein Retry erzeugt eine zweite Bestellung)
- „hängende“ Zustände (Status sagt „bezahlt“, aber nichts anderes stimmt überein)
Nutzer erleben das als verwirrende, kritische Fehler: eine Anmeldung, die „Willkommen" anzeigt, später aber keine Anmeldung erlaubt, eine Bestellbestätigung mit leerer Bestellung oder eine Zahlung, die erfolgreich aussieht, aber kein Abonnement anlegt.
Halb gespeicherte Daten entstehen meist, wenn Code mehrere Inserts und Updates separat ausführt, ohne sie als eine Einheit zu behandeln. Ein Netzwerkfehler, ein Servercrash, ein Validierungsfehler oder ein Timeout in der Mitte reicht, um frühe Schritte zu committen und spätere Schritte zu überspringen.
Das passiert besonders oft in AI-generierten Prototypen, weil dort der Happy Path im Vordergrund steht. Randfälle wie partielle Fehler, Retries und Aufräumarbeiten fehlen häufig, sodass Aktionen, die atomar sein sollten, als Kette unabhängiger Queries ohne klaren Rollback-Plan implementiert werden.
Wann du eine Transaktion verwenden solltest (und wann nicht)
Verwende eine Transaktion, wenn eine Benutzeraktion Daten an mehr als einer Stelle erstellt oder ändert und ein „halb erledigt“ nicht akzeptabel ist. Das Ziel ist einfach: Entweder werden alle zugehörigen Änderungen gespeichert, oder keine davon.
Transaktionen eignen sich gut, wenn Datensätze voneinander abhängen, etwa beim Anlegen eines Bestellkopfs und seiner Positionen. Wenn die Bestellung gespeichert wird, die Positionen aber nicht, hat deine App einen Datensatz, der real wirkt, aber nicht erfüllbar ist.
Sie sind auch das richtige Werkzeug, wenn Änderungen zusammen scheitern müssen, weil Geld oder Limits betroffen sind: Lagerbestände, Kontostände, Gutschriften und Kontingente. Passiert ein Update ohne das andere, kannst du überverkaufen, doppelt belasten oder Nutzer Limits überschreiten lassen.
Eine praktische Regel: Wenn du mehrere Tabellen im Rahmen eines Ergebnisses berührst, gehe zuerst davon aus, dass du eine Transaktion brauchst.
Wenn ein Workflow Services überschreitet (Datenbank-Schreibvorgang plus E-Mail-Versand oder Kartenzahlung), solltest du externe Seiteneffekte außerhalb der Transaktion halten. Speichere den Zustand, commite, und starte dann E-Mail- oder Zahlungs-Schritte so, dass sie sicher erneut ausgeführt werden können.
Anzeichen, dass du wahrscheinlich Transaktionen (oder engere) brauchst, sind wiederkehrende Aufräumscripte nach Fehlern, Support-Tickets wie „Ich sehe es auf einem Bildschirm, aber nicht auf dem anderen“, Dashboards, die sich widersprechen, weil Zeilen fehlen, und Code, in dem Speichervorgänge über viele Helfer verteilt sind.
Wann du keine Transaktion verwenden solltest: für lange, langsame Arbeiten (Dateiverarbeitung, große Batch-Jobs, Warten auf Drittanbieter-APIs). Eine zu lange offene Transaktion kann andere Nutzer blockieren und Timeouts wahrscheinlicher machen.
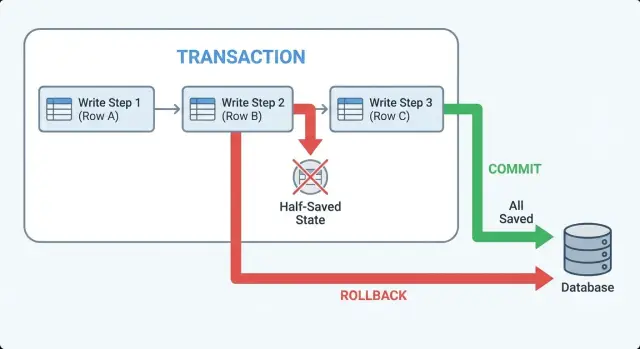
Transaktionen in einfachen Worten: Commit, Rollback, atomar
Eine Transaktion ist eine Sicherheitsumhüllung für eine Reihe von Datenbankschreibvorgängen. Sie verwandelt „speichere diese 3 Dinge" in eine einzige Alles-oder-nichts-Aktion.
„Atomar" bedeutet, entweder wird jede Änderung in der Gruppe gespeichert, oder keine von ihnen. Es gibt keinen Zwischenzustand, in dem einige Zeilen existieren und andere nicht.
Stell dir einen Checkout vor, bei dem du (1) eine Bestellung anlegst, (2) Bestand reservierst und (3) einen Zahlungsversuch aufzeichnest. Ohne Transaktion kann ein Crash zwischen den Schritten dazu führen, dass du eine Bestellung ohne reservierte Positionen hast oder reservierten Bestand ohne Bestellung. Mit einer Transaktion behandelt die Datenbank diese Schritte als eine Einheit.
Das sind Begriffe, die du im Code und in Logs sehen wirst:
- Begin: starte die Transaktion. Änderungen sind vorübergehend bis zum Ende.
- Commit: mache sie permanent. Alle Änderungen landen auf einmal.
- Rollback: mache sie rückgängig. Die Datenbank verwirft alles seit Begin.
Commit und Rollback sind die beiden sauberen Enden. Kann deine App frühzeitig enden (Fehler, Timeout, Validierungsfehler), willst du im Code klar zeigen, welches Ende passiert.
Ein Satz zur Isolation
Isolation bedeutet, dass deine Transaktion vor Überraschungen geschützt ist, die andere gleichzeitige Schreibende verursachen, sodass du nicht auf Daten liest oder schreibst, die sich unter dir ändern.
Wenn du nur eine Regel behältst: gruppiere verwandte Inserts und Updates, die zusammen erfolgreich sein müssen, und lasse Seiteneffekte (E-Mails, Webhooks, Background-Jobs) erst nach dem Commit passieren.
Schritt für Schritt: eine mehrstufige Schreiboperation in einer Transaktion zusammenfassen
Halb gespeicherte Daten entstehen, wenn ein früher Schritt erfolgreich ist (z. B. eine Zeile anlegen) und ein späterer Schritt fehlschlägt (z. B. ein Kontostandsupdate). Die Lösung ist, die gesamte Menge an Änderungen als eine Arbeitseinheit zu behandeln.
Beginne damit, die Grenze festzulegen: alles, was zusammen wahr sein muss, kommt in die Transaktion. Beispiel: „Bestellung erstellen + Bestand reservieren + Zahlungsabsicht aufzeichnen" sollte entweder komplett passieren oder gar nicht.
Ein verlässlicher Ablauf sieht so aus:
- Beginne eine Transaktion vor dem ersten Insert/Update der Arbeitseinheit.
- Führe Statements in sicherer Reihenfolge aus (Eltern zuerst, dann Kinder, dann berechnete Updates).
- Prüfe nach jedem kritischen Statement, dass du erwartete Ergebnisse bekommst (Anzahl der betroffenen Zeilen, zurückgegebene id, Constraints).
- Wenn ein Schritt fehlschlägt, stoppe sofort und rolle zurück.
- Committe nur, wenn jeder Schritt erfolgreich war, und gib dann eine klare Erfolgsantwort zurück.
So sieht die Form in Pseudocode aus:
BEGIN;
-- 1) Create parent
INSERT INTO orders(...) VALUES(...) RETURNING id;
-- 2) Create children
INSERT INTO order_items(order_id, ...) VALUES (...);
-- 3) Update derived state
UPDATE inventory SET reserved = reserved + 1 WHERE sku = ? AND available > 0;
COMMIT;
Zwei Details entscheiden über Erfolg oder Misserfolg dieses Musters.
Erstens: Verschlucke keine Fehler. Wenn Schritt 3 0 Zeilen aktualisiert, behandle das als Fehler, wirf einen Fehler und rolle zurück.
Zweitens: Sende keine Erfolgsantwort, bevor der Commit abgeschlossen ist. „OK" vor dem Commit ist die Ursache dafür, dass teilweise Arbeit als „Erfolg" entweicht.
Wenn du AI-generierten Code geerbt hast, achte auf falsche Transaktionen, bei denen jede Query ihre eigene Verbindung öffnet. Der Code kann transaktional aussehen, während die Queries tatsächlich in verschiedenen Sessions laufen.
Fehlerbehandlung: explizite Rollback-Pfade und klare Fehler
Halb gespeicherte Daten entstehen oft dadurch, dass Fehler als „Problem von jemand anderem" behandelt werden. Entscheide vorher, was als Fehler gilt, und mache jeden Fehlerpfad im Code offensichtlich.
Rolle nicht nur bei Crashes zurück. Rolle auch bei Ausnahmen (Timeouts, Constraint-Fehler, Deadlocks), fehlgeschlagenen Prüfungen (ein Update beeinflusst 0 Zeilen, obwohl 1 erwartet wurde), Validierung, die vom aktuellen Zustand abhängt ("Nutzer hat bereits ein aktives Abo"), oder abhängigen Schreibvorgängen, die unerwartete Werte zurückgeben.
Mache dann Rollback explizit. Vermeide Muster wie „catch und ignore" oder false zurückgeben ohne Aufräumen. Eine einfache Struktur hält dich ehrlich:
begin transaction
try:
write A
write B
verify row counts
commit
return success
except error:
rollback
log safe context
return clear failure
finally:
close connection
Klare Fehler sind wichtig. Der Aufrufer sollte wissen, was als Nächstes zu tun ist ("bitte erneut versuchen" vs. "ungültige Eingabe"), aber die Nachricht sollte keine sensiblen Informationen wie SQL-Text, Tokens oder Umgebungsvariablen preisgeben. Ein praktischer Ansatz ist ein kurzer Grund plus eine interne Fehler-ID, die du in Logs nachschlagen kannst.
Lass eine Transaktion niemals offen. Offene Transaktionen können Zeilen sperren, andere Nutzer blockieren und spätere Anfragen auf seltsame Weise scheitern lassen. Committe oder rolle immer zurück, und schließe die Verbindung (oder gib sie an den Pool zurück) in einem finally-Block.
Logge genug, um das Problem reproduzieren zu können, ohne private Daten auszuwerfen: Operationsname (Signup, Checkout), relevante IDs, Zeilenanzahlen und Fehlertyp. Ein häufiger Fehler in AI-generiertem Code ist, Fehler zu fangen, „Erfolg" zurückzugeben und die Datenbank zwischen zwei Realitäten zu trennen.
Retries und Idempotenz: sicher bleiben bei Timeouts
Timeouts schaffen eine heikle Situation: der Client gibt auf, aber der Server kann die Arbeit noch beenden und committen. Wenn der Client erneut anfragt, kannst du dieselbe Bestellung zweimal anlegen, Zugriff doppelt gewähren oder doppelt belasten.
Transaktionen sorgen dafür, dass jeder Versuch Alles-oder-nichts ist, aber sie verhindern nicht, dass derselbe Versuch erneut ausgeführt wird. Genau dafür ist Idempotenz da.
Idempotenz bedeutet, dass dieselbe Anfrage, wiederholt, dasselbe Ergebnis erzeugt. Ein übliches Muster ist, einen Idempotency-Key (eine zufällige ID vom Client) zu verlangen und zusammen mit dem Endergebnis zu speichern. Bei einem Retry schaust du diesen Key nach und gibst das ursprüngliche Ergebnis zurück, anstatt den Flow erneut auszuführen.
Praktische Wege, Retries sicher zu machen:
- Füge Unique-Constraints hinzu, die echten Geschäftsregeln entsprechen (ein Profil pro Nutzer, eine Mitgliedschaft pro Nutzer pro Workspace).
- Speichere den Idempotency-Key mit einem Unique-Index und speichere die erstellte Datensatz-ID dazu.
- Verwende Upsert, wenn es zur Geschäftsregel passt (erstelle, wenn nicht vorhanden, sonst nutze den bestehenden Eintrag).
- Behandle „Unique constraint violation" als normales Retry-Ergebnis: hole die bestehende Zeile und gib sie zurück.
- Mache externe Seiteneffekte (Zahlungen, E-Mails) ebenfalls idempotent.
Beispiel: Eine Checkout-Anfrage timeouts kurz nach dem Commit, aber bevor die Antwort den Browser erreicht. Der Retry kommt. Mit einem Unique-Constraint auf (user_id, cart_id) und einem Idempotency-Key, der mit der payment_intent_id gespeichert ist, liefert die zweite Anfrage dieselbe Bestellung und erzeugt keine zweite Belastung.
Design-Tipps: Transaktionen klein halten und Seiteneffekte trennen
Transaktionen funktionieren am besten, wenn sie eine klare Geschäftsaktion abdecken. Platziere die wichtigen Geschäftsregeln an der Grenze: validiere, was wahr sein muss, schreibe die zugehörigen Zeilen, dann committe.
Lange Transaktionen schaden, weil sie Locks offen halten. Andere Requests stauen sich dahinter, und Timeouts werden wahrscheinlicher. Mach nur das Minimum, das nötig ist, um die Datenbank konsistent zu halten, und steig dann aus.
Halte die Transaktion fokussiert
Ein häufiger Fehler ist, die Transaktion wie ein allgemeines "try/catch" für alles Mögliche zu nutzen. Halte nicht zusammenhängende Arbeit außerhalb.
Faustregeln:
- Packe nur Reads und Writes, die zusammen erfolgreich sein müssen, in die Transaktion.
- Vermeide es, externe Services zu rufen, während die Transaktion offen ist.
- Vermeide langsame Queries oder große Batch-Updates in derselben Transaktion wie nutzernahe Writes.
- Halte den Codepfad einfach zu verstehen (ein Einstiegspunkt, ein Commit).
Trenne Seiteneffekte von Datenänderungen
Seiteneffekte wie E-Mails verschicken, Karten belasten, Dateien erstellen oder Bilder hochladen sind keine Datenbankarbeit. Wenn du sie innerhalb der Transaktion ausführst, riskierst du, eine Bestätigung zu senden und dann die Daten zurückzurollen.
Ein sichereres Muster: schreibe die Daten, committe, und löse dann Seiteneffekte aus.
Wenn du starke Zuverlässigkeit brauchst, schreibe einen Outbox-Eintrag als Teil derselben Transaktion (zum Beispiel: "sende Willkommensmail an Nutzer 123"). Nach dem Commit liest ein Worker die Outbox und führt den Seiteneffekt aus. Scheitert das, kann er erneut versuchen, ohne deine Kerndaten zu beschädigen.
Häufige Fehler, die weiterhin halb gespeicherte Daten verursachen
Viele halb gespeicherte Bugs entstehen nicht durch fehlende Transaktionen. Sie passieren, wenn eine Transaktion so verwendet wird, dass die Alles-oder-nichts-Garantie stillschweigend gebrochen wird.
Ein klassischer Fehler ist, den „Haupt"-Datensatz zu speichern, zu committen und erst danach erforderliche zugehörige Zeilen zu erstellen (Audit-Log, Profilzeile, Join-Table-Eintrag). Wenn der zweite Schritt fehlschlägt, hast du einen Datensatz, der in einer Tabelle gültig aussieht, aber seine nötigen Partner vermisst.
Ein weiteres Problem ist Fehlerbehandlung, die Aufräumen überspringt. Eine Transaktion kann korrekt geöffnet werden, aber ein Pfad kehrt früh zurück (oder wirft innerhalb eines Callbacks), ohne zu rollbacken. Je nach Stack kann das die Verbindung in einem schlechten Zustand lassen oder zu unerwarteten Commits führen.
Fehlerbilder, die häufig in AI-generiertem Code auftreten:
- Fehler fangen, loggen und dennoch „Erfolg" zurückgeben.
- Einen Drittanbieter-Aufruf (E-Mail, Payments, File Upload) während die Transaktion offen ist, sodass ein langsames Netzwerk Locks hält.
- Verschiedene DB-Clients mischen, sodass ein Write auf einer anderen Verbindung läuft und nicht Teil derselben Transaktion ist.
- Retry ohne Idempotenz, was nach einem Timeout Duplikate erzeugt.
Beispiel: Ein Signup-Flow fügt in users ein, dann in user_profiles, dann in org_members. Wenn das Insert in user_profiles fehlschlägt, aber das Insert in users bereits committet ist, blockiert die nächste Anmeldung wegen „E-Mail existiert bereits" und der Nutzer steckt in der Schwebe.
Zwei praktische Regeln verhindern vieles davon: halte die Transaktion auf Datenbankarbeit beschränkt und mache jeden Exit-Pfad explizit. Brauchst du einen externen Call, committe zuerst, führe dann den Call aus und falls er fehlschlägt, notiere einen separaten „retry erforderlich"-Status.
Kurze Checks, bevor du auslieferst
Bevor du ein Feature ausrollst, das mehrstufige Inserts und Updates macht, schreibe die „Unit of work" in einem Satz. Beispiel: „Erstelle eine Bestellung, reserviere Bestand und zeichne eine Zahlungsabsicht auf." Kannst du das nicht klar sagen, sind deine Transaktionsgrenzen wahrscheinlich unscharf.
Ein schneller Sanity-Test ist: Verfolge die Connection. Jede Query, die zusammen erfolgreich oder fehlgeschlagen sein muss, muss auf derselben DB-Session/Connection laufen. Das ist ein häufiger Fehler in AI-generierten Codes: ein Helfer verwendet eine Connection aus dem Pool, ein anderer öffnet eine neue — so deckt die Transaktion nur einen Teil der Arbeit ab.
Eine kurze Pre-Ship-Checkliste:
- Definiere die Unit of Work in einem Satz und packe nur diese in eine einzelne Transaktion.
- Verifiziere, dass jeder zugehörige Write dieselbe Connection/Session von Begin bis Commit nutzt.
- Mach Fehlerpfade langweilig: bei jedem Fehler rollback, gib eine klare Fehlermeldung zurück und stoppe.
- Füge Constraints hinzu, die Retries sicher machen (Unique-Keys für „eine pro Nutzer"-Datensätze, Idempotency-Keys für Anfragen).
- Halte Seiteneffekte aus der Transaktion: E-Mails, Webhooks und Dateiuploads erst nach Commit (oder in die Queue).
Mach danach einen „break it"-Lauf: erzwinge einen Fehler in Schritt 2 von 3 (zum Beispiel eine Constraint-Verletzung in der dritten Tabelle). Nachdem die Anfrage fehlschlägt, prüfe die Datenbank. Du solltest null neue Zeilen sehen, nicht „einige Zeilen mit fehlenden Teilen".
Beispiel: Signup-Flow, der in 3 Tabellen schreibt
Stell dir ein Signup vor, das drei Zeilen schreiben muss:
users(email, password hash)profiles(user_id, display_name)subscriptions(user_id, plan)
Wenn du diese als drei getrennte Writes machst, kannst du halb gespeicherte Daten bekommen. Zum Beispiel wird die users-Zeile erstellt, aber profiles schlägt fehl, weil display_name zu lang ist oder ein Pflichtfeld fehlt. Jetzt hast du ein echtes Konto, das das Onboarding nicht abschließen kann, und spätere Versuche schlagen fehl, weil die E-Mail schon belegt ist.
Wie es ohne Transaktion aussieht
Ein übliches AI-generiertes Muster ist: insert user, dann insert profile, dann insert subscription — jeder mit einem eigenen Aufruf. Wenn Schritt 2 fehlschlägt, wurde Schritt 1 bereits committet. Du brauchst nun Cleanup-Code (lösche den Nutzer) und musst entscheiden, was passiert, wenn dieses Cleanup ebenfalls fehlschlägt.
Derselbe Flow mit Transaktion und explizitem Rollback
Bei atomaren Writes behandelst du die drei Writes als eine Einheit: Entweder existieren alle drei, oder keine.
BEGIN;
INSERT INTO users (email, password_hash)
VALUES (:email, :hash)
RETURNING id INTO :user_id;
INSERT INTO profiles (user_id, display_name)
VALUES (:user_id, :display_name);
INSERT INTO subscriptions (user_id, plan)
VALUES (:user_id, :plan);
COMMIT;
-- If any statement fails, ROLLBACK;
Zwei Regeln machen das verlässlich:
- Sende dem Nutzer Erfolg nur, nachdem
COMMITerfolgreich war. - Wenn etwas wirft, fange es,
ROLLBACKund gib eine klare Fehlermeldung zurück.
Post-Commit-Aktionen wie Willkommensmails sollten nach dem Commit stattfinden (oder in eine Queue geschrieben werden), damit du niemanden für ein Konto emailst, das nie wirklich gespeichert wurde.
Zum Testen: Füge absichtlich einen Fehler in der Mitte ein (z. B. ein ungültiges display_name) und bestätige, dass die Datenbank nach dem fehlgeschlagenen Request keine Zeilen für diese E-Mail enthält.
Nächste Schritte: Transaction-Bugs in AI-erstellten Apps beheben
Wenn du eine App geerbt hast, die von Tools wie Lovable, Bolt, v0, Cursor oder Replit erstellt wurde, deuten halb gespeicherte Datensätze meist auf fehlende oder unvollständige Transaktionsgrenzen hin. Im Happy-Path-Testing sieht alles oft gut aus, bricht aber unter Realtraffic, Timeouts oder einem unerwarteten Null-Wert zusammen.
Häufige Zeichen, dass der Code keine richtige Transaktion hat (oder sie nur halb benutzt):
- Ein API-Call schreibt in mehrere Tabellen, aber jeder Write passiert in separaten Funktionen mit eigenen DB-Calls.
- Fehler werden gefangen und geloggt, aber der Code läuft weiter und gibt Erfolg zurück.
- Background-Jobs, E-Mails oder Payment-Calls passieren mitten in DB-Writes.
- Ein Retry erzeugt doppelte Zeilen, weil Idempotenz fehlt.
- Du siehst verwaiste Zeilen (ein Profil ohne User oder eine Bestellung ohne Positionen).
Beim Code-Audit frag nicht nur „nutzen wir Transaktionen?" Frage, wo sie starten und enden und was bei einem Fehler passiert. Ein gutes Audit sollte Risiken für Datenintegrität (Foreign Keys, Constraints, partielle Writes) markieren und zusammenhängende Probleme in AI-erstellten Codebasen wie fehlerhafte Auth-Flows, exponierte Secrets und SQL-Injection-Risiken aufzeigen.
Ob refactor oder neu bauen: Refactor, wenn das Datenmodell solide ist und der Flow hauptsächlich eine klare Transaktionsgrenze plus saubere Fehlerbehandlung vermisst. Rebuild, wenn der Workflow verknotet ist, Tabellen nicht zum Produkt passen oder jeder Fix neue Randfälle erzeugt.
Wenn du aktuell halb gespeicherte Daten in einer AI-generierten Codebasis siehst, konzentriert sich FixMyMess (fixmymess.ai) darauf, den Code zu diagnostizieren, Logik zu reparieren, Security zu verstärken, riskante Bereiche zu refactoren und die App bereit für den Einsatz zu machen. Ihr kostenloses Code-Audit ist ein praktischer Weg, genau den Endpunkt zu finden, an dem Atomicität bricht, und welche Rollback-Strategie am sichersten ist.