Audit-Logs für Admin-Aktionen, die Streitfälle schnell klären
Audit-Logs für Admin-Aktionen zeigen, wer was, wann und warum geändert hat. Erfahren Sie, welche Felder wichtig sind, wie Sie Diffs sicher erfassen und wie Sie Logs durchsuchbar machen, damit Streitfälle schnell beigelegt werden.
Warum Admin- und Support-Audit-Logs wichtig sind
Wenn sich in einer App etwas ändert und niemand erklären kann, warum, wird Support zur Rateshow. Kund:innen fühlen sich beschuldigt, Teammitglieder stehen unter Verdacht, und kleine Probleme werden zu langen Threads und langsamer Vorfallbehebung.
Admin- und Support-Aktionen sind die Handlungen hinter den Kulissen, die die Nutzererfahrung ändern können, ohne dass der Nutzer etwas getan hat. Ein Support-Agent setzt ein Passwort zurück. Ein Admin ändert einen Plan. Jemand entfernt Inhalte. Diese Aktionen sind oft notwendig, verursachen aber die meisten Streitigkeiten, weil sie außerhalb der Sicht passieren.
Streitfälle klingen meist so:
- „Ich habe diese Rückerstattung nie angefordert, warum wurde sie ausgestellt?“
- „Mein Konto wurde deaktiviert — wer war das und welche Regel wurde ausgelöst?“
- „Unser Abo wurde herabgestuft und Features sind über Nacht verschwunden.“
- „Ein Beitrag wurde entfernt, aber wir müssen Grund und Zeitpunkt nachweisen.“
- „Der Support hat meine E‑Mail geändert und jetzt kann ich mich nicht mehr einloggen.“
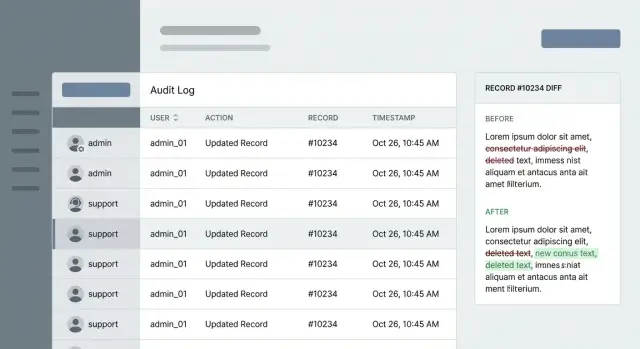
In solchen Momenten geht es beim Audit-Log nicht um „mehr Daten“. Es geht um eine klare Antwort. Ein guter Eintrag zeigt, wer was an welchem Datensatz getan hat und wann. Ein großartiger Eintrag zeigt außerdem, was sich geändert hat (ein Diff) und genug Kontext, um zu erklären, warum es passiert ist (Ticket‑ID, Grundcode, interne Notiz).
Das ist noch wichtiger für Teams, die schnell ausliefern oder KI-generierten Code übernehmen. Wenn die Logik unordentlich ist, kann die App sich anders verhalten, als erwartet, und trotzdem benötigt man eine zuverlässige Spur. Bei FixMyMess sehen wir oft Prototypen, die mit Tools wie Cursor oder Replit gebaut wurden, wo Admin-Panels halb funktionieren und kritische Aktionen gar nicht protokolliert werden — genau dann werden Streitigkeiten schmerzhaft.
Gute Logs schlichten Streitigkeiten schnell, verkürzen Untersuchungen und schützen sowohl Kunden als auch Ihr Team mit Fakten statt Meinungen.
Was ein Audit-Log-Eintrag enthalten sollte
Ein Audit-Log ist in einem Streit nur dann nützlich, wenn jeder Eintrag fünf Fragen klar beantwortet: wer hat es getan, was ist passiert, was war betroffen, wann ist es passiert und woher kam es. Fehlt eine dieser Angaben, sind Sie wieder beim Raten.
Beginnen Sie mit dem Akteur. Speichern Sie einen stabilen Identifikator (User-ID, Admin-ID oder Service-Account-ID) und die Berechtigungen, die die Person zum Zeitpunkt hatte (Rolle). Wenn Support Benutzer*innen impersonifizieren kann, protokollieren Sie das explizit: ausgeführt von Admin X while impersonating user Y. Ohne das können Sie nicht unterscheiden, ob die Änderung vom Kunden oder vom Personal in dessen Namen vorgenommen wurde.
Erfassen Sie Aktion und Ziel zusammen. „Kunden-E-Mail aktualisiert“ ist besser als nur „update“, aber verlassen Sie sich nicht nur auf Freitext. Verwenden Sie einen strukturierten Aktionsnamen (create, update, delete, export, password reset, login override) und das genaue berührte Objekt. Fügen Sie Tenant/Workspace hinzu, damit Konten getrennt bleiben.
Für Zeit: speichern Sie einen präzisen Zeitstempel in UTC und formatieren Sie ihn nur zur Anzeige in lokaler Zeit. Bei Streitfällen können Minuten entscheidend sein und UTC vermeidet Verwirrung durch Sommerzeit.
Fügen Sie genug Kontext hinzu, um das Event Ende‑zu‑Ende nachzuverfolgen. Eine solide Basis ist: Einstiegspunkt (UI-Screen-Name oder API-Endpoint), Request‑ID (und Session‑ID falls vorhanden), Quell‑IP und User‑Agent (wenn passend), Ergebnis (Erfolg/Fehler mit Code) und ein Support‑Grund oder Ticket-Referenz.
Beispiel: Ein Kunde sagt „Support hat meinen Plan ohne Rückfrage geändert.“ Ein starker Eintrag zeigt die Admin‑ID, ob Impersonation verwendet wurde, eine Aktion wie plan_update, den Ziel‑Workspace, einen UTC‑Zeitstempel und eine Request‑ID, der Sie zur genauen Screen‑ oder API‑Anfrage folgen können. Das ist der Unterschied zwischen einer vagen Geschichte und einem Log, das den Fall in Minuten klärt.
Diffs erfassen, ohne sensible Daten zu leaken
Ein Diff ist die einfachste Art, Streit zu beenden, weil es Vorher‑ und Nachher‑Werte für jedes geänderte Feld zeigt. Ziel ist Klarheit, ohne das Log zur zweiten Datenbank voller privater Daten zu machen.
Loggen Sie nur, was sich geändert hat. Wenn ein Admin einen Kunden-Datensatz bearbeitet, protokollieren Sie eine kleine Nutzlast wie role: user -> admin und status: trial -> active, nicht das komplette Profil. So bleiben Einträge lesbar, Suchen schneller und das Risiko unbeabsichtigter Exposition geringer.
Empfindliche Felder brauchen besondere Behandlung. Rohwerte für Passwörter, Zugriffstoken, vollständige Kartennummern oder private Notizen sollten in der Regel nicht in Logs stehen. Eine nützliche Regel: Wenn Sie es nicht in einen Support-Chat kopieren würden, setzen Sie es nicht ins Audit-Log.
Gängige Ansätze sind Maskierung (z. B. ****@gmail.com), Hashing (eine Einweg-Fingerprint), ein einfaches „changed“-Flag (z. B. password: changed), vollständige Redaktion oder das Auslagern sensibler Details in einen separaten Speicher mit engerem Zugriff und kürzerer Aufbewahrung.
Diffs sind mit Intentionsangaben noch hilfreicher. Fügen Sie einen Grundcode hinzu (z. B. customer_request, fraud_review, bug_fix, policy_exception) und eine kurze Notiz. Bei einem späteren Streit zählt das „Warum“ genauso sehr wie das „Was“.
Erfassen Sie außerdem verwandte IDs, damit Sie die Geschichte rekonstruieren können: Ticket‑ID, Conversation‑ID, Bestell‑ID, Refund‑ID und den Primärschlüssel des Datensatzes.
Beispiel: Ein Kunde behauptet, Support habe seinen Plan ohne Erlaubnis hochgestuft. Ihr Eintrag sollte plan: basic -> pro, die Agent‑Identität, den Zeitstempel, Grundcode customer_request und eine Ticket‑ID zeigen, die mit der Konversation übereinstimmt, in der die Anfrage erfolgte. Wenn Sie chaotischen, KI-generierten Code geerbt haben, der zu viel (oder gar nichts) loggt, beginnt FixMyMess oft damit, sichere Diffs und strikte Redaktionsregeln hinzuzufügen, sodass Logs Streitigkeiten lösen anstatt neue Risiken zu schaffen.
Wie Sie Logs gestalten, denen Sie später vertrauen können
Vertrauenswürdige Logs sind weniger eine Frage schicker Dashboards als langweiliger Regeln, die nie gebrochen werden. Wenn Admin- und Support-Logs Streitfälle entscheiden sollen, brauchen Sie Einträge, die schwer zu fälschen, leicht lesbar und über alle Codepfade hinweg konsistent sind.
Behandeln Sie jeden Eintrag als append-only. Bearbeiten Sie alte Events nicht, wenn sich etwas ändert oder ein Agent einen Fehler macht. Schreiben Sie ein neues Event, das das vorherige korrigiert, damit die Historie vollständig bleibt.
Verwenden Sie überall eine einheitliche Event-Form, auch über Teams und Services hinweg. Wenn Support, Admins, Background‑Jobs und API‑Calls unterschiedliche Felder produzieren, beantworten die Logs unter Druck keine einfachen Fragen mehr.
Ein praktisches Basisschema:
- who: User‑ID, Rolle und etwaige acting‑as‑Info
- what: Aktionsname (z. B.
user.password_reset) - where: Datensatztyp und Datensatz‑ID
- when: Server‑Timestamp (UTC)
- context: Request‑Correlation‑ID, Quelle (UI/Admin‑Panel/API‑Key/Background‑Job) und IP/Device falls passend
Correlation‑IDs verwandeln „wir denken, es war ungefähr 15 Uhr“ in Beweis. Generieren Sie eine pro Anfrage, geben Sie sie durch interne Aufrufe weiter und hängen Sie sie an das Audit‑Event. Wenn eine Aktion drei Tabellen berührt, erlaubt dieselbe Correlation‑ID, diese Events zu einer einzigen Support‑Interaktion oder Klicksitzung zu verbinden.
Protokollieren Sie die Quelle immer mit. „Admin changed plan“ reicht nicht, wenn die eigentliche Frage ist, ob es aus dem Admin‑UI, einem API‑Key einer Agentur oder einem nächtlichen Job kam.
Planen Sie Aufbewahrung früh. Entscheiden Sie, wie lange Sie Events für Streitfälle benötigen, wie groß die Logs werden dürfen und wo sie liegen. Teams, die zu FixMyMess kommen, entdecken oft, dass ihr KI-generierter Prototyp kritische Aktionen nie protokolliert oder die Historie zu früh gelöscht hat, was die Verifikation unmöglich macht, wenn ein Kunde eine Abbuchung anfechtet.
Logs durchsuchbar machen für echte Support-Arbeit
Suche ist der Unterschied zwischen „wir denken, das ist passiert“ und „hier ist der genaue Moment der Änderung“. Gestalten Sie Suche so, wie Support arbeitet: Finden Sie einen Kunden, engen Sie den Datensatz ein und bestätigen Sie dann die genaue Änderung.
Halten Sie Aktionsnamen kurz und konsistent. Eine enge Taxonomie (denken Sie in Dutzenden, nicht Hunderten) macht Filter nutzbar und vermeidet das „alles ist individuell“-Chaos, in dem schnell gebaute Apps oft landen. Wenn Sie mehr Details brauchen, packen Sie sie in strukturierte Felder, nicht in einen neuen Aktionsnamen.
Normalisieren Sie die Basics, damit jedes Event auf die gleiche Weise gefiltert werden kann.
Die Felder, die Suche wirklich funktionieren lassen
Mindestens sollte jedes Event enthalten:
- action (z. B.
user.password_reset,billing.refund_issued) - actor_id und actor_role (admin, support, system)
- record_type und record_id (immer vorhanden, immer gleich formatiert)
- created_at (Serverzeit)
- request_id (um zusammengehörige Events zu gruppieren)
Fügen Sie dann ein kleines Set sicherer „Support‑Kontext“-Felder hinzu, die beim Suchen helfen: Kunden‑E‑Mail (oder eine gehashte/normalisierte Version), Bestellnummer, Workspace/Org‑Name und Ticket‑ oder Conversation‑ID. Bewahren Sie diese als separate Felder auf, nicht versteckt in einem Satz.
Vermeiden Sie laute Events. Page‑Views, Screen‑Opens und „Liste geladen“-Logs vergraben das Signal. Audit‑Logs sollten sich auf Aktionen konzentrieren, die Zustand ändern, Zugriff gewähren oder sensible Daten offenlegen.
Machen Sie jeden Eintrag lesbar, ohne die Struktur zu verlieren: ein klarer Satz für Menschen plus strukturierte Felder für Filter. „Support agent updated billing email“ ist hilfreich, sollte aber dennoch record_type=workspace, record_id=... und eine Diff‑Zusammenfassung enthalten, die beweist, was sich änderte.
Schritt für Schritt: Admin‑Action‑Logging in eine App einbauen
Ein praktischer Workflow
Listen Sie auf, was Admins und Support heute tatsächlich tun, nicht nur, was Sie sich wünschen. Übersetzen Sie jede Fähigkeit in einen klaren Aktionsnamen, damit das Log wie eine Chronik statt wie eine Schublade voller Sachen liest.
Ein einfacher Workflow:
- Inventarisieren Sie Admin/Support-Aktionen (refund, password reset, plan change, profile edit, role grant) und mappen Sie jede auf ein Event.
- Markieren Sie Hochrisiko‑Datensätze, die immer protokollieren müssen (Auth, Billing, Permissions, Account‑Ownership).
- Definieren Sie erforderlichen Kontext: Akteur, Ziel‑Datensatz, Zeitstempel, Grund und ein sicheres Diff.
- Implementieren Sie Logging in der Service‑Layer (wo die Business-Regeln laufen), nicht verteilt auf UI‑Buttons.
- Führen Sie einen „Dispute Test“ durch, der rekonstruiert, wer was und warum nur mithilfe der Logs.
Nachdem Sie Events gemappt haben, entscheiden Sie, was in Ihrer App „target“ bedeutet. Ein gutes Muster ist target_type (Subscription), target_id (sub_123) und optionale verwandte IDs (wie user_id). Das macht spätere Suchen deutlich einfacher.
Wo Teams meist feststecken
Hochrisiko heißt nicht selten. Es heißt, eine Änderung hier kann Geld kosten, jemanden aussperren oder einen Support‑Streit auslösen. Wenn Sie unsicher sind, beginnen Sie mit einer kurzen Liste: Auth‑Einstellungen, Billing/Invoices, Rollen/Berechtigungen, E‑Mail/Telefon‑Änderungen und alles, was Zugriff beeinflusst.
Fordern Sie einen menschlichen Grund für sensible Aktionen, auch wenn er kurz ist. „Kunde bestätigte neue E‑Mail telefonisch“ ist viel nützlicher als „updated“.
Führen Sie einen Fake‑Disput durch, bevor Sie ausliefern. Tun Sie so, als sagt ein Kunde „Support hat meinen Plan ohne Anfrage herabgestuft.“ Können Sie ein Event ziehen, das zeigt: welcher Admin, welcher Datensatz, das Vorher/Nachher‑Diff (Plan: Pro -> Basic), die Grundnotiz und der Zeitstempel? Wenn nicht, fügen Sie die fehlenden Felder jetzt hinzu.
Wenn Sie eine KI-generierte Codebasis reparieren, reduziert Logging in der Service‑Layer oft „fehlende Events“, wenn UI‑Code geändert wird. Das ist häufig eine der ersten Korrekturen, die Teams wie FixMyMess durchführen, wenn Prototypen produktreif gemacht werden.
Hochriskante Aktionen, die immer geloggt werden sollten
Wenn Sie nur wenige Dinge loggen, protokollieren Sie Aktionen, die Geld, Zugriff oder Vertrauen verändern. Das sind die Momente, die zu Streitigkeiten führen: „Ich habe das nie geändert“, „Support hat auf meine Daten zugegriffen“ oder „Jemand hat seine eigenen Rechte erhöht.“
Aktionen mit Always‑On‑Logging
Konzentrieren Sie sich auf Ereignisse, die mächtig, schwer rückgängig zu machen oder sensibel sind. Ein einfacher Test: Würde ein Nutzer sich über einen Eintrag auf einem Kontoauszug, Screenshot oder Compliance‑Bericht aufregen? Dann gehört es ins Log.
Priorisieren Sie:
- Sensitive Datenzugriffe (Exporte, Downloads, „volle Karte anzeigen“, Öffnen ganzer Profile mit privaten Details).
- Rollen‑ und Berechtigungsänderungen (Rollen‑Updates, Gruppenmitgliedschaften, API‑Keys, SSO‑Einstellungen, Admin‑Flags).
- Impersonation (Start, Ende und jede Aktion während der Impersonation, beide Identitäten protokollieren).
- Massenaktionen (Mass‑Refunds, Bulk‑Deletes, Migrationen, Batch‑Edits), inklusive Anzahl und Referenzen zu betroffenen IDs.
- Fehlgeschlagene eingeschränkte Versuche (abgelehnte Berechtigungsprüfungen, ungültige Admin‑Tokens, blockierte Exporte) mit Rate‑Limits, um Noise zu vermeiden.
Kurzes Beispiel, wie das Streitentscheidet
Ein Kunde sagt: „Support hat meine Rechnungen heruntergeladen und meinen Plan geändert.“ Wenn Ihre Logs sowohl „Export invoices“ (Read) als auch „Plan changed“ (Write) erfassen, können Sie schnell zeigen, wer es war, wann, aus welcher Sitzung und ob es während einer Impersonation geschah.
Hier versagen viele KI-generierte Prototypen in der Produktion: Sie loggen nur erfolgreiche Schreibvorgänge und überspringen sensible Reads. Plattformen wie FixMyMess beginnen oft mit dem Hinzufügen dieser hochriskanten Events, weil sie mit geringem Aufwand den größten Vertrauens- und Support‑Gewinn bringen.
Halten Sie jedes Event verständlich: ein klarer Aktionsname, die betroffenen Datensätze und genug Kontext, um zu erklären, warum es geschah, ohne Geheimnisse preiszugeben.
Häufige Fehler, die Audit‑Logs unzuverlässig machen
Die meisten Streitfälle entstehen nicht, weil keine Logs existieren, sondern weil die Logs vage, unvollständig oder später nicht vertrauenswürdig sind. Eine gute Audit‑Spur sollte wie Beweismaterial lesbar sein: klar, spezifisch und schwer zu manipulieren.
Ein häufiger Fehler ist das Protokollieren eines generischen Events wie „updated user“ ohne feldgenaue Details. Wenn ein Kunde sagt „Support hat meinen Plan geändert“, müssen Sie genau sehen, was sich änderte (Alter Wert, Neuer Wert), nicht nur, dass „etwas“ passiert ist. Ohne Diffs entgeht Ihnen auch das Erkennen von Mustern wie wiederholtem Umschalten oder versehentlichen Überschreibungen.
Ein anderer Fehler ist, Geheimnisse und persönliche Daten in der Spur zu dumpen. Tokens, Passwörter, Session‑Cookies, API‑Keys oder rohe Zahlungsdaten sollten nie in Logs landen. Speichern Sie redigierte Werte oder Referenzen stattdessen und vermerken Sie, dass ein sensibles Feld geändert wurde, ohne den Wert zu speichern.
Fehler bei der Zuordnung von Akteuren treten häufiger auf, als Teams erwarten. Background‑Jobs, Webhooks und Skripte laufen oft als „system“, selbst wenn ein Mensch sie ausgelöst hat. Das macht die Spur in echten Support‑Fällen viel weniger nützlich.
Reliability‑Killer:
- Events können nachträglich bearbeitet oder gelöscht werden.
- Der Akteur fehlt (oder ist immer „system“) bei automatisierten Flows.
- Datensatz‑IDs sind nicht stabil, sodass Suchen Rauschen liefern.
- Aktionsnamen sind inkonsistent, sodass Filter die halbe Geschichte verpassen.
- Diffs sind unvollständig oder zweideutig (vorher/nachher fehlt).
Beispiel: Ein Gründer bestreitet eine Rückerstattungsänderung. Ihr Log sollte den Refund‑Status‑Diff, das Admin‑Konto, das geklickt hat, das Ticket/den Grund und die Datensatz‑ID zeigen. Bei Audits von kaputten KI-generierten Apps sehen wir häufig genau diese Lücken: „es wurde aktualisiert“ ohne den Nachweis, den Sie brauchen.
Schnelle Checkliste zur Streitbeilegung mit Logs
Wenn ein Kunde sagt: „Ich habe das nie geändert“ oder „Ihr Team hat mein Konto kaputt gemacht“, ist das Ziel simpel: bauen Sie eine klare Timeline, die beide Seiten verstehen. Gute Logs lassen Sie drei Fragen schnell beantworten: wer, was und wann.
Starten Sie breit, dann verengen Sie, bis Sie ein konkretes Event mit seinem genauen Diff haben.
Ein schneller Weg zur Wahrheit
- Finden Sie die Kundin/den Kunden über einen stabilen Identifikator (Customer‑ID, Account‑ID, Ticket‑ID) und prüfen Sie, ob Sie den richtigen Datensatz betrachten.
- Filtern Sie nach Aktionstyp (password reset, refund, plan change) und Akteur (konkreter Admin, Support‑Agent, automatischer Job).
- Öffnen Sie die Änderungsdetails und lesen Sie das Diff, nicht nur die Zusammenfassung.
- Verwenden Sie die Correlation/Request‑ID, um zu sehen, was im selben Flow sonst noch passierte. Streitfälle entstehen oft durch Nebeneffekte, nicht durch den ursprünglichen Klick.
- Schreiben Sie das Ergebnis in klaren Worten und, falls nötig, fügen Sie ein Follow‑Up‑Event hinzu, das die Lösung protokolliert.
Kleines Beispiel
Ein Kunde meldet Downgrade ohne Zustimmung. Das Log zeigt, dass ein Agent den Plan geändert hat, aber dieselbe Correlation‑ID enthält Sekunden zuvor einen fehlgeschlagenen Zahlungs‑Retry. Das Diff zeigt, dass eine Downgrade‑Regel automatisch nach dem Retry ausgelöst wurde. Das klärt meist den Streit und zeigt, was zu beheben ist: UI‑Klarheit, schärfere Berechtigungen oder Regelanpassung.
Wenn Sie eine KI‑generierte App übernommen haben, ist dies oft eine der ersten Ergänzungen während des Cleanups. Teams wie FixMyMess sehen häufig mächtige „Admin‑Aktionen“, die ohne Spur passieren, was jede Beschwerde zur Rateshow macht.
Beispiel: Eine Support‑Änderung vom Complaint bis zum Beweis zurückverfolgen
Eine Kundin schreibt: „Mein Abo wurde gekündigt und ich habe das nicht gemacht.“ Hier stoppen Admin‑ und Support‑Logs das Raten. Sie wollen eine saubere Spur, die zeigt, wer das Konto berührt hat, was sich änderte und warum.
Starten Sie beim Kunden‑Datensatz und filtern Sie Events um den Zeitpunkt, an dem das Problem auffiel. In einer guten Spur finden Sie schnell eine Impersonation (oder „login as user“) gefolgt von einem Subscription‑Update.
So könnte diese Spur aussehen, wenn sie gut funktioniert:
2026-01-16 09:41:03Z actor=support:maya action=impersonate_user target=user:1842
context: ticket=SUP-10488 reason="Asked to check billing page error"
2026-01-16 09:43:19Z actor=support:maya action=subscription_update target=sub:7711
source=ui request_id=8f3c... ip=203.0.113.24
diff:
status: active -> canceled
cancel_at_period_end: false -> true
context: ticket=SUP-10488 note="Customer requested cancel at renewal"
Zwei Details lösen Streitfälle schnell: das Diff (was sich änderte) und der Kontext (Ticket‑ID, Grund und kurze Notiz). Zeitstempel und Akteur klären, ob es sich um eine Support‑Aktion oder den Kunden handelte.
Bestätigen Sie die Quelle, damit Sie nicht das falsche System beschuldigen:
- UI‑Aktion: es gibt einen internen User‑Akteur plus Session/Request‑ID.
- API‑Key: der Akteur ist ein Key oder eine Integration, oft mit Key‑ID.
- Automatischer Job: der Akteur ist ein Job‑Name mit Schedule/Run‑ID.
Wenn die Änderung falsch war, stellen Sie sie sofort wieder her (z. B. Subscription wieder auf active setzen) und protokollieren Sie die Korrektur als eigenes Event mit einer Notiz wie „Reverted cancel, customer did not consent.“ Dieser finale Eintrag verhindert, dass der Streit später wieder aufkommt.
Nächste Schritte: klein anfangen, dann die Spur verengen
Starten Sie mit einem minimalen Umfang, den Sie im nächsten Sprint ausliefern können. Wählen Sie die Admin‑ und Support‑Aktionen, die am häufigsten zu Streitigkeiten und Rückbuchungen führen, und loggen Sie diese zuerst. Wenn Sie nur eines tun, sorgen Sie dafür, dass Sie beantworten können: wer hat es getan, was hat sich geändert, welcher Datensatz und wann.
Eine praktische Methode, Lücken zu finden, ist ein kurzer Dispute‑Drill. Nehmen Sie ein reales Ticket (oder erfinden Sie eins) und versuchen Sie zu beweisen, was passiert ist, nur mit Ihren Logs. Zum Beispiel: „Ein Kunde sagt, sein Plan wurde ohne Erlaubnis herabgestuft.“ Sehen Sie die betroffene Person, den Akteur, die Vorher/Nachher‑Werte und den Ticket‑Kontext? Wenn nicht, notieren Sie, was fehlt, und fügen Sie es hinzu.
Sobald die Grundlagen funktionieren, fügen Sie Schutzmaßnahmen hinzu, damit die Spur sicher und nützlich bleibt: maskieren oder weglassen sensibler Felder (Passwörter, Tokens, vollständige Kartendaten), Aufbewahrung gemäß Support‑ und Rechtsanforderungen, Zugriffsbeschränkungen auf Logs (und Aufzeichnung von Zugriffen auf die Logs) und Alerts für hochriskante Aktionen wie Rollenänderungen, Rückerstattungen und Auth‑Resets.
Wenn Ihr Codebase von KI‑Tools generiert wurde, ist inkonsistentes Logging üblich: Aktionen passieren an mehreren Orten, Auth‑Checks unterscheiden sich zwischen Routen und „system“‑Änderungen lassen sich schwer von menschlichen unterscheiden. Ein fokussiertes Audit kann hier die schnellste Lösung sein.
FixMyMess (fixmymess.ai) bietet eine kostenlose Code‑Prüfung an, um fehlendes Audit‑Logging, gebrochene Auth‑Spuren und Sicherheitslücken zu identifizieren, besonders bei KI‑generierten Prototypen, die produktionsreifes Verhalten brauchen.
Häufige Fragen
What problem do admin and support audit logs actually solve?
Ein Audit-Log verwandelt einen Streit in eine überprüfbare Chronologie. Statt zu spekulieren, können Sie auf einen Eintrag zeigen, der zeigt, wer gehandelt hat, was geändert wurde, welcher Datensatz betroffen war und wann das passierte.
Which admin/support actions should I log first?
Protokollieren Sie jede Aktion, die Geld, Zugriff oder Vertrauen ändert. Beginnen Sie mit Passwort-Resets, E-Mail-Änderungen, Rollen-/Berechtigungsänderungen, Plan-Up-/Downgrades, Rückerstattungen, Kündigungen, Impersonation und Exporten sensibler Daten.
What fields should every audit log entry include?
Ein nützlicher Eintrag beantwortet fünf Dinge: Schauspieler, Aktion, Ziel-Datensatz, Zeitstempel und Kontextquelle. Praktisch heißt das: eine stabile Akteur-ID und Rolle, ein strukturiertes Aktionsnamen, Datensatztyp und -ID, UTC-Zeit sowie Anfrage-/Sitzungsdetails und eine Support- oder Ticket-Referenz.
How do I name actions so logs stay searchable?
Verwenden Sie eine kleine, konsistente Taxonomie wie billing.refund_issued oder user.password_reset. Details gehören in strukturierte Felder (Diff, Grundcode, Ticket-ID), damit Filter zuverlässig bleiben und Sie nicht Hunderte ähnlicher Aktionsnamen bekommen.
Should I store diffs (before/after values) in audit logs?
Sparen Sie Feld-für-Feld-Diffs nur für die tatsächlich geänderten Felder. Diffs sollten klein und spezifisch sein (z. B. plan: basic -> pro), damit Sie beweisen können, was sich änderte, ohne ganze Datensätze ins Log zu kippen.
How do I log changes without leaking sensitive data?
Speichern Sie keine Rohwerte für Geheimnisse oder hochsensible Daten wie Passwörter, Tokens, vollständige Zahlungsdaten oder private Notizen. Bevorzugen Sie Redaktion, Maskierung, Hashing oder ein einfaches Markenzeichen wie „changed“ und loggen Sie die Tatsache der Änderung zusammen mit Wer/Wann/Wo.
Why should audit log timestamps be stored in UTC?
UTC verhindert Verwirrung durch Sommerzeit und Zeitzonen, was besonders wichtig ist, wenn Minuten zählen. Speichern Sie den Zeitstempel in UTC und konvertieren Sie nur für die Anzeige in lokale Zeit.
How should I log support impersonation (“log in as user”)?
Impersonation muss explizit und nachvollziehbar sein. Protokollieren Sie Start und Ende der Impersonation, und für jede Aktion währenddessen halten Sie beide Identitäten fest: das Support-Mitglied und das Benutzerkonto, in dessen Namen gehandelt wurde.
How do I make audit logs trustworthy and hard to tamper with?
Machen Sie Logs append-only und behandeln Sie sie wie Beweismittel. Wenn etwas falsch war, schreiben Sie ein neues korrektives Event, das auf das Original verweist. Beschränken Sie den Zugriff auf Logs und protokollieren Sie auch Zugriffe auf die Logs.
My app was built with AI tools and logging is a mess—can this be fixed quickly?
Ja. Es ist typisch, dass KI-erzeugte Prototypen kritisches Logging vermissen oder inkonsistent protokollieren. Eine pragmatische Lösung ist Logging in der Service-Schicht zu implementieren, das Event-Shape zu standardisieren und sichere Diffs mit Redaktionsregeln hinzuzufügen; FixMyMess kann schnell prüfen, was fehlt und es patchen.