Blue-Green-Deployment für kleine Apps: Sichere Umschaltungen und Rollbacks
Lerne Blue-Green-Deployment für kleine Apps mit zwei Umgebungen: sichere Umschaltungen, schnelle Rollbacks und praxisnahe Hinweise zu Datenbanken und Sessions.
Warum auch kleine Apps durch riskante Deploys Probleme kriegen
Kleine Apps gehen aus banalen Gründen down. Ein Deploy liefert eine winzige Änderung, und plötzlich funktioniert der Login für alle nicht mehr. Oder ein Hintergrundjob läuft doppelt und schreibt doppelte Zeilen. Oder eine Konfig zeigt auf die falsche Datenbank und Nutzer sehen eine Stunde lang Fehler.
Solche Ausfälle fühlen sich unfair an, weil die App ja nicht „groß“ ist. Aber das Risiko ist in kleinen Teams oft höher: weniger Augen auf Änderungen, weniger Zeit fürs Testen und niemand auf Rufbereitschaft, der alles stehen und liegen lässt, um Produktion zu reparieren.
Die schlimmsten Deploys brechen Dinge, die lokal schwer zu erkennen sind. Authentifizierung und Sessions können fehlschlagen, weil Cookies ungültig werden, Callbacks falsch konfiguriert sind oder Tokens abgelehnt werden. Daten werden riskant, wenn Migrationen Tabellen sperren oder Code neue Felder beschreibt, bevor sie existieren. Laufzeit-Einstellungen schlagen zu, wenn Secrets fehlen, Umgebungsvariablen falsch sind oder Netzwerkrichtlinien von der Dev-Umgebung abweichen. Und selbst wenn in einem ruhigen Test alles funktioniert, kann echter Traffic einen Endpoint umwerfen, der in Entwicklung harmlos aussah.
Blue-Green-Deployment senkt dieses Risiko, ohne Releases in eine große Zeremonie zu verwandeln.
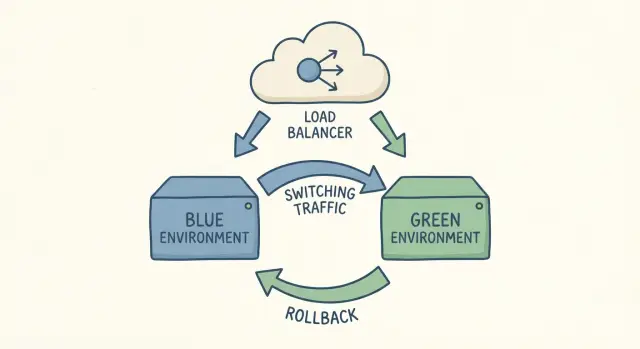
Wenn Leute „zwei Umgebungen“ sagen, meinen sie zwei vollständige Kopien deiner App-Konfiguration, die gleichzeitig laufen: eine ist live (blue), die andere ist die neue Version, die du veröffentlichen willst (green). Beide sollten dieselbe Art von Server, dieselben Abhängigkeiten und produktionsähnliche Einstellungen nutzen. Wichtig ist, dass nur eine von ihnen echten Nutzertraffic erhält.
Ein Cutover ist einfach das Umschalten des Traffics von blue auf green. Wenn etwas schiefgeht, schaltest du zurück. Das ist die ganze Idee.
Dabei geht es nicht um schweren Prozess. Es geht darum, dir einen sicheren Ort zu verschaffen, um praktische Fragen zu beantworten, bevor Nutzer den Preis zahlen: funktioniert der Login noch, laden wichtige Seiten, verhalten sich Hintergrundjobs richtig, und kannst du schnell zurückrollen, wenn du etwas übersehen hast?
Ein typisches Szenario bei kleinen Apps ist eine „schnelle“ Änderung unter Zeitdruck. Sie funktioniert bei dir, bricht aber für Nutzer, weil Produktion andere Cookies, Domains oder Secrets hat. Mit green in Bereitschaft kannst du diese produktionsspezifischen Details zuerst testen und dann den Traffic umschalten, wenn du sicher bist.
Wenn dein Codebasis AI-generiert und schon fragil ist, steigt das Risiko. Teams übernehmen oft kaputte Authentifizierung, exponierte Secrets und verworrene Logik, die sich unter echtem Traffic anders verhält. Blue-Green repariert schlechten Code nicht von selbst, kann aber verhindern, dass ein schlechter Deploy zu einer langen Störung wird.
Blue-Green einfach erklärt
Blue-Green-Deployment ist die einfache Idee, zwei sofort einsetzbare Kopien deiner App bereitzuhalten.
Blue ist das, worauf Nutzer gerade sind. Es ist die aktuelle Live-Version, die echten Traffic bedient. Green ist die neue Version, die du veröffentlichen möchtest. Du baust sie, konfigurierst sie und testest sie, während blue weiter Nutzer bedient.
Wenn du mit green zufrieden bist, machst du einen kontrollierten Traffic-Switch, sodass Nutzer statt blue nun green treffen. Dieser Switch passiert in der Regel an einer Stelle: einer Load-Balancer- oder Reverse-Proxy-Regel, einem Plattform-Swap, wenn dein Host das unterstützt, einer Router-Einstellung im Container-Gateway oder (weniger ideal) per DNS. DNS funktioniert, aber Caching macht das Timing unvorhersehbar.
Der große Gewinn ist Geschwindigkeit und Vertrauen. Wenn nach dem Cutover etwas schiefgeht, ist ein Rollback oft einfach das Zurückschalten auf blue. Du musst die alte Version nicht unter Druck neu bauen. Sie ist bereits da und funktioniert bereits.
Stell dir ein simples SaaS mit Login, Billing und einem Dashboard vor. Du deployst green mit einem neuen Dashboard-Layout, machst einen Smoke-Test auf echter Infrastruktur und schaltest dann um. Melden Kunden kaputte Charts, schaltest du in Minuten zurück zu blue, während du green reparierst.
Blue-Green löst nicht alles. Zwei Bereiche bringen Teams am häufigsten in Schwierigkeiten:
Datenbankänderungen: wenn green eine neue Tabelle oder geänderte Spalten braucht, musst du planen, damit sowohl blue als auch green sicher während der Übergangsphase laufen können.
Sessions und Logins: werden Sessions im Speicher jeder Instanz gehalten, bekommen Nutzer beim Umschalten möglicherweise einen Logout. Gemeinsamer Session-Speicher (oder stateless Auth) verhindert das.
Wann Blue-Green gut passt (und wann nicht)
Blue-Green funktioniert am besten, wenn du sicherere Releases möchtest, aber keine komplizierten Release-Tools. Du hältst zwei produktionsähnliche Umgebungen, testest die neue mit echten Einstellungen und schaltest dann den Traffic um.
Es passt gut, wenn deine App größtenteils stateless ist und Änderungen leicht End-to-End zu testen sind. Das umfasst oft einfache Web-Apps, APIs mit kurzen unabhängigen Requests, interne Tools mit bekanntem Nutzerkreis und frühe SaaS-Produkte, die häufig kleine Änderungen ausliefern. Es hilft auch, wenn du es dir leisten kannst, während des Release-Fensters zwei Kopien zu betreiben.
Ein einfaches Beispiel: Ein kleines SaaS hat eine Next.js-App und eine API. Du deployst die neue Version auf green, führst einen schnellen Smoke-Test durch (Login, Item anlegen, Export), und schaltest dann den Traffic. Wenn etwas komisch wirkt, schaltest du in Minuten zurück.
Es ist kein guter Fit, wenn der schwierigste Teil deines Releases die Datenbank ist oder wenn Arbeiten sich nicht sicher auf mehrere Umgebungen duplizieren lassen. Warnsignale sind häufige Schema-Operationen, die Tabellen sperren, lang laufende Jobs, die nicht pausiert oder dupliziert werden können, viel In-Memory-State wie WebSockets oder custom Session-Storage, sowie Drittanbieter-Nebenwirkungen (Zahlungen, E-Mails), die du nicht ohne Weiteres neu abspielen kannst. Es funktioniert auch schlecht, wenn das Team keine schriftliche Cutover- und Rollback-Checkliste hat.
Es kostet: Du zahlst für zwei Kopien während Releases. Für kleine Apps kann das noch günstig sein, aber plane verdoppelte Compute-Kosten plus eventuell duplizierte Services (Queues, Caches), falls nötig.
Tooling ist weniger wichtig als Team-Gewohnheiten. Eine kurze Checkliste (wer schaltet Traffic, was zu prüfen ist, was Rollback auslöst) verhindert Panik.
Was du brauchst, bevor du es ausprobierst
Blue-Green funktioniert am besten, wenn du blue und green als zwei separate, vollständige Kopien der Produktion behandelst. Wenn die Basics nicht stimmen, kannst du zwar umschalten, weißt aber nicht, welche Seite wirklich gesund ist, und Rollback kann chaotisch werden.
Starte mit der Konfiguration. Blue und green sollten denselben Code laufen haben, dürfen aber nicht aus Versehen falsche Secrets teilen. Halte Umgebungsvariablen klar getrennt und mache es einfach zu prüfen, welche Umgebung gerade genutzt wird. Ein häufiger Fehler ist, green auf die falsche Datenbank zu zeigen, falsche OAuth-Callbacks zu haben oder einen Test-Zahlungsschlüssel zu verwenden.
Minimaler Setup-Checklist
Vor deinem ersten Cutover solltest du diese Fragen mit „ja“ beantworten können:
- Separate Konfigurationen für blue und green (Env Vars, Secrets, Drittanbieter-Keys) mit klarer Benennung und einfacher Möglichkeit zu verifizieren, was geladen ist.
- Ein reproduzierbares Build-Artefakt, das promoted wird (build einmal, deploy oft). Baue nicht neu für green.
- Ein Health-Check, der mehr beweist als „der Server läuft“ (inklusive kritischer Abhängigkeiten wie DB und Cache).
- Basis-Monitoring für das, was Nutzer fühlen (Fehlerrate und Latenz) plus ein oder zwei Schlüsselaktionen (Signup, Checkout, Datei-Upload).
- Logs, die du unter Stress lesen kannst (Request-IDs, nützliche Fehler, und eine Möglichkeit, blue vs green zu vergleichen).
Health-Checks verdienen besondere Aufmerksamkeit. Ein „200 OK“-Endpoint reicht für einen Load Balancer, aber du willst ein tieferes Signal vor dem Cutover. Kann die App z. B. die Datenbank erreichen, eine Zeile lesen und eine leichte Schreibaktion durchführen? Wenn du keine sicheren Writes testen kannst, verifiziere zumindest, dass die App sich verbinden und eine einfache Abfrage ausführen kann.
Halte Releases langweilig. Der größte Vorteil von Blue-Green ist das Vertrauen, dass du genau das umschaltest, was du vorher getestet hast. Wenn dein Build zwischen den Umgebungen wechselt, testest du das eine und lieferst etwas anderes aus.
Schritt-für-Schritt: ein einfaches Blue-Green-Runbook
Blue-Green funktioniert am besten als kurze, wiederholbare Checkliste. Es geht nicht um Raffinesse, sondern um langweilige Sicherheit.
1) Wähle, wie du Traffic umschaltest
Wähle eine Cutover-Methode und bleib dabei:
- Load Balancer- oder Reverse-Proxy-Switch
- Plattform-Swap (falls dein Host das unterstützt)
- DNS-Änderung (funktioniert, aber Caching macht das Timing unberechenbar)
Entscheide vorher, wer Zugriff hat, wie lange es dauert und wie man es rückgängig macht.
2) Deploye green, sodass es zu blue passt
Deploye die neue Version auf green mit derselben „Form“ wie blue: dieselben Services (Queue, Cache, Storage), denselben Ansatz für Secret-Management, dieselbe Background-Worker-Konfiguration und vergleichbare Laufzeit-Einstellungen. Werte können unterschiedlich sein, aber die Struktur sollte konsistent sein.
Die meisten Blue-Green-Fehlschläge passieren, weil green nicht wirklich produktionsähnlich ist. Green zeigt auf eine andere DB, ein fehlendes Secret macht Auth erst nach dem Switch kaputt oder ein Job-Runner ist nicht korrekt angebunden.
3) Verifiziere green, bevor Nutzer sie treffen
Führe schnelle Smoke-Tests gegen green mit einem echten Account (oder einem staging-sicheren) durch. Halte es einfach und konzentriere dich auf das, was Umsatz und Vertrauen bricht:
- Ein- und Ausloggen
- Laden einiger wichtiger Seiten
- Anlegen und Aktualisieren eines echten Datensatzes
- Auslösen eines Hintergrundjobs (E-Mail, Webhook, Bericht)
- Logs nach neuen Fehlern scannen
Wenn deine App Caches oder Worker nutzt, starte sie früh und lass sie warm laufen. Ein typisches Muster ist: „es funktionierte im Test“, bricht aber zusammen, sobald Caches kalt sind und Worker echte Queues verarbeiten.
4) Cutover und genau beobachten
Schalte den Traffic kontrolliert um. Wenn dein Setup schrittweisen Traffic erlaubt (z. B. zuerst 10 %), nutze das. Wenn es alles-oder-nichts ist, mach es in einem ruhigen Fenster.
Für die nächsten 10–30 Minuten beobachte ein kurzes Set an Signalen: Fehlerrate, Latenz, Login-Erfolg, Checkout oder deine Schlüsselaktion und DB-Last. Lege vorher fest, bei welchen Zahlen du „Stop und zurückschalten“ auslöst.
Datenbankänderungen ohne verlorene Writes
Das Schwierigste an Blue-Green ist oft nicht das Umschalten, sondern die Datenbank.
Das Kernrisiko ist einfach: für eine Weile können zwei Versionen deiner App live sein. Wenn beide dieselbe DB nutzen, aber unterschiedliche Tabellen oder Spalten erwarten, kann eine Version Fehler werfen. Schlimmer: sie kann Daten schreiben, die die andere Version nicht lesen kann, oder Felder auf unerwartete Weise überschreiben.
Ein sichereres Muster ist, Datenbankänderungen zuerst abwärtskompatibel zu machen. Füge Dinge hinzu, bevor du sie entfernst. Halte alten Code funktionsfähig, während die neue Version ausgerollt wird.
Nutze den „expand then contract“-Ansatz
Die meisten kleinen Apps vermeiden Downtime, indem sie Schema-Arbeiten in kleinere Schritte aufteilen:
- Expand: neue Spalten oder Tabellen hinzufügen, die alten beibehalten.
- Write with overlap: die neue Version so aktualisieren, dass sie in den neuen Bereich schreibt, dabei aber kompatibel liest.
- Contract: nach dem Cutover und einer sicheren Wartezeit alte Spalten, Tabellen oder Codepfade entfernen.
Beispiel: Du willst users.fullname in users.display_name umbenennen. Lösche fullname nicht während des Switches. Füge display_name hinzu, deploye Code, der beide Felder schreibt (oder eines schreibt und das andere backfillt), und säubere später.
Trenne Deploy von destruktiven Migrationen
Versuche nicht, "drop column", "rewrite table" oder "backfill 50 Millionen Zeilen" genau im Moment des Traffic-Switches durchzuziehen. Führe langsame oder riskante Arbeiten vorher aus, während die aktuelle Version noch Nutzer bedient. Wenn eine Migration Minuten dauert oder Zeilen sperrt, behandle sie als Pre-Migration und mache sie so, dass der alte Code weiterlaufen kann.
Während des Cutovers prüfe die Kompatibilität in beide Richtungen: kann der alte Code Zeilen lesen, die die neue Version geschrieben hat, und umgekehrt. Dort zeigen sich versteckte Annahmen wie hartkodierte Spaltenlisten, fehlende Null-Behandlung oder unsichere Defaults.
Sessions und Auth: Nutzer eingeloggt halten beim Umschalten
Der schnellste Weg, einen sicheren Cutover in ein Support-Desaster zu verwandeln, ist, alle auszuloggen. Sessions brechen in der Regel, weil sich etwas zwischen blue und green verändert hat: ein Cookie-Name, ein Session-Signier-Schlüssel, ein Token-Format oder sogar die Domain/Subdomain.
Halte die Identitätsregeln auf beiden Seiten identisch
Behandle während des Cutovers diese Dinge als geteilte Verträge, die sich nicht ändern dürfen:
- Session-Signier- und Verschlüsselungs-Schlüssel (Cookie-Secrets, JWT-Signing-Keys, CSRF-Secrets)
- Cookie-Einstellungen (Name, Domain, Path, Secure, HttpOnly, SameSite)
- Token- und Session-Formate (Claims, Ablaufregeln, Serialisierung)
- Auth-Callbacks und Redirect-URLs (bei OAuth)
Wenn du Schlüssel rotieren musst, mach es überlappend. Green sollte sowohl alten als auch neuen Schlüssel zur Verifikation akzeptieren, während nur neue Sessions mit dem neuen Schlüssel ausgestellt werden. Bestehende Nutzer bleiben eingeloggt, neue Logins erhalten den sichereren Schlüssel.
Bevorzuge stateless Auth (aber halte Kompatibilität)
Wenn deine App kurze Access-Tokens plus einen Refresh-Flow nutzt, werden Cutovers einfacher, weil der Server keine Sessions speichern muss. Wichtig ist Kompatibilität: green muss Tokens akzeptieren, die blue ausgestellt hat, bis sie natürlich ablaufen. Vermeide Claim- oder Audience-Änderungen im selben Release.
Wenn du serverseitige Sessions nutzt, teile den Session-Store. Blue und green sollten in denselben Backend-Store schreiben und lesen (oft Redis oder eine DB-Tabelle). Haben beide Umgebungen eigene Session-Stores, sehen Nutzer beim Umschalten auf green „fremd“ aus, obwohl ihr Cookie korrekt ist.
Checkout- und lange Formulare sind häufige Schmerzpunkte. Jemand ist mitten im Zahlungsvorgang, der Cutover passiert und die nächste Anfrage landet auf green. Mach das sicher, indem du Warenkorb- und Bestellzustand in der Datenbank speicherst (nicht nur im Speicher), Idempotenz für Zahlungsaktionen nutzt und Formular-Submits gegen Wiederholungen robust machst. Wenn möglich, schalte Traffic schrittweise und lass blue laufende Requests beenden, bevor du vollständig umschaltest.
Schnell zurückrollen, ohne alles schlimmer zu machen
Bei Blue-Green bedeutet Rollback meist nicht, Code-Änderungen rückgängig zu machen, sondern den Produktionstraffic zurück auf die vorherige Umgebung zu schalten. Wenn das Routing sauber ist, geht das schnell.
Ziel ist Geschwindigkeit und Sicherheit. Bestimme einen Besitzer für die Entscheidung und eine eindeutige Aktion, die den Traffic umschaltet (ein Button, ein Kommando, ein Runbook-Schritt). Wenn jeder seine eigene „Schnelllösung“ hat, verzögern und verkomplizieren sich Rollbacks.
Lege Rollback-Trigger vor dem Cutover fest. Übliche Trigger sind plötzliche Anstiege von 5xx/Timeouts, Login- oder Signup-Fehler, Zahlungsfehler, klare Datenintegritätsprobleme (fehlende Bestellungen, Duplikate, seltsame Summen) oder ein Latenzsprung, der die App unbrauchbar macht.
Das Problem bleibt die Datenbank. Sobald green Schreibvorgänge empfängt, ist ein Zurück zu blue nur sicher, wenn blue die neue Datenform lesen kann. Wenn dein Release eine Migration enthielt, die eine Spalte entfernte, Felder umbenannte oder Constraints änderte, könnte blue abstürzen oder stillschweigend falsch funktionieren. So wird ein Rollback zur großen Störung.
Eine praktische Regel: Halte DB-Änderungen für ein kurzes Fenster abwärtskompatibel. Füge neue Spalten zuerst hinzu, behalte alte, deploye Code, der beides kann, und entferne alte Felder, nachdem sich die Lage geklärt hat.
Setze ein Entscheidungsfenster. Beispiel: „Wenn wir in den ersten 10–20 Minuten kritische Fehler sehen, schalten wir zurück. Danach fixen wir vorwärts, es sei denn, es gibt Datenverlust.“ Das verhindert endlose Debatten, während Nutzer betroffen sind.
Eine einfache Rollback-Sequenz:
- Incident-Owner benennen und andere Änderungen einfrieren
- Traffic zurück auf die vorherige Umgebung schalten
- Logins, Zahlungen und Kern-User-Flows verifizieren
Häufige Fehler, die Ausfälle verursachen
Blue-Green klingt simpel, aber die meisten Ausfälle passieren in den langweiligen Lücken zwischen „zwei Umgebungen“ und „Traffic umgeschaltet“.
Ein großer Fehler ist, blue und green wie zwei verschiedene Apps zu behandeln. Das beginnt klein: eine fehlende Umgebungsvariable, ein nur an einer Stelle rotiertes Secret oder ein Feature-Flag, das anders gesetzt ist. Dann passiert der Cutover und Zahlungen oder E-Mails funktionieren nicht. Blue und Green sollten dasselbe Build und dieselbe Konfigurationsstruktur haben, mit nur minimalen Unterschieden (wie Farbe und Hostnames).
Ein anderer häufiger Fehler betrifft Hintergrundarbeit. Web-Traffic kann sauber umgeschaltet werden, während der Job-Runner noch auf die alte Umgebung zeigt oder beide Umgebungen denselben geplanten Task ausführen. Das kann doppelte Rechnungen, doppelte Benachrichtigungen oder konkurrierende Cleanup-Jobs verursachen.
Datenbankänderungen sind der Punkt, an dem die meisten Teams sich verletzen. Teams führen genau dann eine brechende Migration durch, wenn sie den Traffic switchen. Wenn green das neue Schema nutzt und blue noch die alte Form schreibt (oder umgekehrt), verlierst du schnell Writes oder korrumpierst Daten. Das sicherere Muster: zuerst kompatible Änderungen, deployen, umschalten, und alte Spalten später entfernen.
Lokal testen reicht nicht. Blue-Green scheitert an produktionsähnlichen Details: echte Auth-Provider, echte Cookies, echte Caches, echte Timeouts und echte Last. Testest du green nur auf deinem Laptop, testest du nicht das, was du den Nutzern auslieferst.
Schließlich zögern Teams während eines Incidents, weil sie keine „Stop-the-line“-Regel definiert haben. Entscheide vorher, was sofortiges Zurückschalten auslöst: ein starker Fehleranstieg, Login-Ausfälle über einer Schwelle, eine kaputte Schlüssel-Flow (Signup, Checkout, Passwort-Reset), Anstieg von DB-Fehlern (Deadlocks, Timeouts), doppelte Hintergrundarbeit oder einfach, dass du das Problem in ein paar Minuten nicht erklären kannst.
Kurze Checkliste und nächste Schritte
Blue-Green funktioniert am besten, wenn jedes Release eine kurze Routine ist, die die paar Dinge abfängt, die Nutzern am meisten wehtun: kaputtes Login, fehlgeschlagene Writes und Verlangsamungen direkt nach dem Switch.
Bevor du Traffic anfasst, mach einen Pre-Deploy-Check: bestätige Health-Checks in der neuen Umgebung (inkl. kritischer Abhängigkeiten), verifiziere, dass Env Vars und Secrets aus der richtigen Quelle geladen sind, prüfe Migrationen auf Sicherheit (zuerst additive Änderungen, keine überraschenden Löschungen) und stelle sicher, dass Logs und Monitoring funktionieren.
Direkt nach dem Cutover teste wie ein echter Nutzer. Für viele kleine Apps bedeutet das: registrieren oder einloggen, einen Datensatz anlegen oder aktualisieren und eine Kernaktion mit Geld- oder Messaging-Fluss abschließen (Checkout, Zahlung, Einladung senden, Entwurf speichern).
Nach den ersten Minuten hör auf zu klicken und beobachte Signale. Achte auf Änderungen, nicht auf perfekte Zahlen: ein plötzlicher Anstieg von Fehlern, ein Latenzspike oder ein Rückstau in Queues.
Lege Rollback-Regeln fest, bevor du sie brauchst. Ein Rollback ist nicht nur ein Schalter, es ist auch eine Datenentscheidung: wer darf zurückrollen, was genau ist die Umschaltaktion und wie lange dauert sie, was passiert mit Writes nach dem Cutover, wie handhabst du Sessions und wann hörst du auf zurückzuschalten und fängst an, vorwärts zu fixen.
Wenn du eine AI-generierte App geerbt hast und Deploys ständig scheitern, betrachte das als Problem der Codequalität, nicht nur als Prozessfrage. Teams bei FixMyMess (fixmymess.ai) führen Codebasis-Diagnosen, Logik-Reparatur, Security-Hardening und Deployment-Vorbereitung für AI-generierte Prototypen durch, sodass Blue-Green-Cutovers und Rollbacks planbar statt stressig werden.
Häufige Fragen
What is blue-green deployment in simple terms?
Blue-Green-Deployment bedeutet, zwei vollständige, einsatzbereite Umgebungen bereitzuhalten. Eine (blue) bedient aktuell echte Nutzer, während du die neue Version in der anderen (green) deployst und testest. Bist du zufrieden, schaltest du den Traffic auf green; wenn etwas kaputtgeht, schaltest du zurück auf blue.
Why do small apps get so much downtime from “small” deploys?
Kleine Apps haben oft weniger Prüfungen vor einem Release: weniger Testzeit, weniger Reviewer und langsamere Incident-Reaktionen. Ein winziger Konfigurationsfehler oder eine Änderung an der Auth kann die ganze App lahmlegen. Blue-Green gibt dir einen sicheren Schritt, um die neue Version auf echter Infrastruktur zu testen, ohne viel bürokratischen Aufwand.
What’s the best way to switch traffic between blue and green?
Am schnellsten und einfachsten ist ein Umschalten am Load Balancer oder Reverse Proxy, weil es schnell und umkehrbar ist. Wenn dein Host einen Plattform-Swap unterstützt, ist das noch einfacher. DNS kann funktionieren, ist aber schwerer vorhersehbar wegen Caching.
What should I test on green before I cut over?
Führe einen kurzen Smoke-Test durch, der das widerspiegelt, was deinen Nutzern am wichtigsten ist: Login, einige Schlüssel-Seiten, ein Create/Update-Vorgang und ein Hintergrundjob oder Side-Effect, auf den du angewiesen bist. Vergewissere dich, dass dieselben Secrets und Umgebungsvariablen wie in Produktion geladen sind. Beobachte danach Fehler und Latenz, damit du bei Bedarf schnell zurückschalten kannst.
How do I avoid green pointing at the wrong database or secrets?
Behandle Konfiguration als Hauptrisiko. Mach sichtbar, in welcher Umgebung du dich befindest, halte blue- und green-Konfigurationen getrennt und prüfe besonders kritische Punkte wie Datenbank-Endpunkte, OAuth-Callback-URLs, Cookie-Domains und Zahlungsschlüssel. Die meisten schmerzhaften Cutovers sind keine Code-Bugs, sondern falsche Einstellungen.
How do I prevent users from getting logged out during the switch?
Halte Session- und Auth-Regeln während des Cutovers identisch, besonders Cookie-Einstellungen und Signier-/Verschlüsselungs-Schlüssel. Bei serverseitigen Sessions nutze einen gemeinsamen Session-Store, damit beide Umgebungen dieselben Sessions erkennen. Wenn du Schlüssel rotieren musst, mach es überlappend: green sollte alte und neue Schlüssel zur Verifikation akzeptieren, während nur neue Sessions mit dem neuen Schlüssel ausgestellt werden.
How do I handle database migrations without losing writes?
Geh davon aus, dass blue und green für eine Weile gegen dieselbe Datenbank schreiben könnten. Deine Schema-Änderungen müssen also abwärtskompatibel sein. Füge zuerst neue Spalten oder Tabellen hinzu, deploye Code, der beide Formen verarbeiten kann, und entferne alte Felder später. Vermeide destruktive Migrationen genau zum Zeitpunkt des Traffic-Switches.
When should I roll back vs fix forward?
Rollback bedeutet normalerweise nicht, Code zurückzurollen, sondern den Traffic wieder auf die vorherige Umgebung zu schalten (von green zurück zu blue). Lege Rollback-Trigger vorher fest — z. B. Login- oder Zahlungsfehler, starke Anstiege von 5xx-Fehlern oder klare Datenintegritätsprobleme. Sei vorsichtig, wenn green bereits Schreibvorgänge im neuen Format ausgeführt hat, das blue nicht lesen kann.
How do I stop background jobs from running twice in blue and green?
Wenn derselbe geplante Job in beiden Umgebungen läuft, entstehen Duplikate wie doppelte Rechnungen oder wiederholte Benachrichtigungen. Vor dem Cutover vergewissere dich, dass nur ein Satz Worker/Scheduler die „einmaligen“ oder periodischen Tasks ausführt. Nach dem Cutover prüfe, dass Queues, Cron-Jobs und Webhook-Processor dorthin zeigen, wo du sie erwartest.
Does blue-green help if my app is AI-generated and already unstable?
AI-generierter Code hat oft fragile Auth, verworrene Logik und inkonsistente Konfigurations-Handling, was das Verhalten in Produktion unvorhersehbar macht. Blue-Green begrenzt die Blast-Region, behebt aber keine grundlegenden Probleme wie unsichere Migrationen, hardcodierte Secrets oder unzuverlässige Session-Logik. Wenn Deploys ständig fehlschlagen, lohnt sich eine gezielte Codebasis-Diagnose und Aufräumarbeit.