Caching und Paginierung für langsame Listenseiten — praktische Muster
Erfahren Sie, wie Sie Caching und Paginierung für langsame Listenseiten gestalten — mit praxisnahen Cursor‑Paginierungsmustern, Cache‑Key‑Design und sicheren Alternativen zu „alles laden“-APIs.
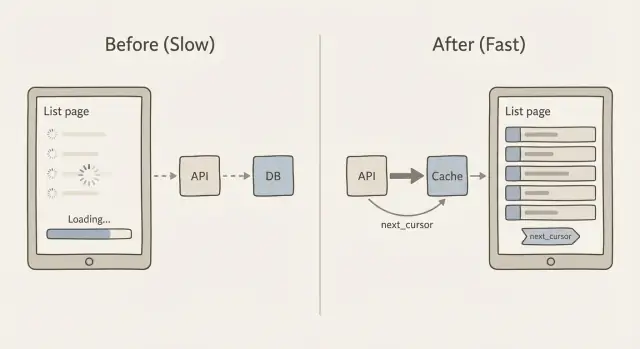
Warum Listenseiten langsamer werden, wenn Ihre Daten wachsen
Eine Listenseite fühlt sich oft bei 200 Datensätzen noch gut an und bricht dann plötzlich bei 20.000 zusammen. Nutzer sehen langsames Scrollen, Spinner, die nie verschwinden, und Filter, die Sekunden brauchen. Manchmal zeigt die Seite einen leeren Zustand, weil die Anfrage ein Time‑out erreicht oder der Client aufgibt und nichts rendert.
Das Kernproblem ist einfach: jeder zusätzliche Datensatz lässt das System mehr Arbeit tun. Die Datenbank muss die Zeilen finden, sortieren und filtern. Die API muss sie zu JSON formen. Das Netzwerk muss die Daten transportieren. Dann muss der Browser (oder die mobile App) sie parsen, Speicher alloziieren und rendern.
Wo die Zeit bleibt
Wenn Ihr Datensatz wächst, kommen Verzögerungen meist durch eine Mischung aus diesen Ursachen zustande:
- Datenbankarbeit: große Scans, teure Joins und das Sortieren großer Ergebnismengen.
- Payload-Größe: Hunderte oder Tausende Zeilen pro Anfrage zurückgeben.
- Render-Kosten: die UI versucht, zu viele Elemente auf einmal zu malen.
- Wiederholte Abfragen: dieselbe Liste wird immer wieder ohne Caching angefragt.
Sortieren und Filtern haben einen versteckten Preis, weil sie die Datenbank oft dazu zwingen, viel mehr Daten zu berühren als erwartet. Beispielsweise ist status = open mit dem richtigen Index billig, aber „Suche nach Name enthält“ oder „Sortiere nach letzter Aktivität“ wird schnell teuer. Noch schlimmer: OFFSET-Paginierung (Seite 2000) kann die Datenbank dazu bringen, Tausende Zeilen zu überlaufen, nur um zur nächsten Seite zu gelangen.
Das Ziel ist nicht „einmal schnell machen“. Das Ziel ist vorhersehbare Antwortzeiten, wenn die Daten wachsen. Das bedeutet in der Praxis, weniger Datensätze pro Anfrage zurückzugeben, eine Paginierung zu verwenden, die bei tiefen Seiten nicht langsamer wird, und Listenantworten zu cachen, damit wiederholte Besuche nicht jedes Mal den vollen Preis zahlen.
Vermeiden Sie „alles laden“-Listendpunkte
Ein häufiger Grund, warum Listenseiten langsam werden, ist eine API, die die ganze Tabelle zurückgibt, weil es im Prototyp einfach war. Das sieht oft so aus:
GET /api/orders
200 OK
[
{ "id": 1, "customer": "...", "notes": "...", "internalFlags": "...", ... },
{ "id": 2, ... }
]
Das versagt bei Skalierung, weil es die Arbeit an drei Stellen gleichzeitig vervielfacht: die Datenbank muss mehr Zeilen scannen und sortieren, der Server muss eine riesige JSON-Antwort bauen und senden, und der Browser muss sie parsen und eine lange Liste rendern. Selbst wenn Sie später Caching und Paginierung hinzufügen, ist ein „gib mir alles“-Endpunkt teuer in der Erstellung und im Versand.
Mobile Geräte und instabile Netze spüren das zuerst. Eine 5–10 MB große JSON‑Antwort mag im Büro‑WLAN okay sein, kann aber im 4G-Netz ein Time‑out auslösen, Akku verbrauchen und die App defekt wirken lassen. Es macht Fehler auch schwerer zu beheben: fällt eine Anfrage aus, verliert der Nutzer die ganze Seite, statt nur den nächsten Abschnitt.
Eine einfache Regel, die Sie ehrlich hält: senden Sie nur das, was der Nutzer jetzt sehen kann. Das bedeutet meist eine kleine Seite (z. B. 25–100 Zeilen) und nur die Felder, die für die Listenansicht nötig sind.
Wenn Teams FixMyMess ein AI-generiertes Admin‑Panel bringen, finden wir oft Listendpunkte, die komplette Datensätze (inklusive großer Textfelder) ohne Limit zurückgeben. Der schnelle Gewinn ist, eine kompakte „List-Item“-Form zurückzugeben und Details nur beim Öffnen einer Zeile zu laden. Diese Änderung allein kann Abfragezeit, Antwortgröße und Client-Renderzeit deutlich reduzieren, ohne das UI-Design zu verändern.
Cursor-Paginierung in einfachen Worten
Viele Listendpunkte starten mit Offset‑Paginierung: „gib mir Seite 3“ bedeutet „überspringe die ersten 40 Zeilen und gib die nächsten 20 zurück.“ Das wirkt einfach, wird aber mit wachsender Tabelle langsamer, weil die Datenbank trotzdem alle übersprungenen Zeilen passieren muss.
Offset‑Paginierung wird auch seltsam, wenn sich die Daten während des Pagens ändern. Wenn neue Zeilen eingefügt oder alte gelöscht werden, kann die nächste Seite Duplikate zeigen oder Einträge übergehen. „Seite 3“ ist also kein stabiles Konzept.
Cursor‑Paginierung behebt das, indem sie ein Lesezeichen statt einer Seitenzahl verwendet. Der Client sagt: „gib mir die nächsten 20 Elemente nach diesem zuletzt gesehenen Element.“ Dieser „nach“-Wert ist der Cursor. Das ist die Kernidee hinter Caching und Paginierung für langsame Listenseiten: jede Anfrage klein, vorhersehbar und schnell halten.
Was der Cursor tatsächlich ist
Ein Cursor ist normalerweise ein kleines Bündel von Werten aus der letzten Zeile der aktuellen Antwort. Damit er stabil ist, muss Ihre Liste eine konsistente Sortierung haben, die nie unentschieden ist. Ein gängiges Muster ist Sortierung nach created_at mit id als Tie‑Breaker (z. B. neueste zuerst, und wenn zwei Zeilen denselben Zeitstempel haben, nach id sortieren).
Diese stabile Sortierung garantiert, dass „nach diesem Element“ immer genau auf eine Stelle in der Liste zeigt.
Wie next_cursor funktioniert
Konzeptionell gibt der Server zurück:
- Die Elemente für diese Anfrage (z. B. 20)
- Ein
next_cursor, das das letzte Element dieser Menge repräsentiert
Wenn keine weiteren Elemente vorhanden sind, ist next_cursor leer oder fehlt. Der Client speichert ihn und sendet ihn zurück, um den nächsten Abschnitt zu holen. Keine Seitennummern, keine riesigen Sprünge und deutlich weniger Überraschungen, wenn die Liste sich ändert.
Schritt für Schritt: einen cursor-paginierten API-Endpunkt implementieren
Cursor‑Paginierung ist das Arbeitspferdmuster hinter Caching und Paginierung für langsame Listenseiten. Es hält Seiten stabil und schnell, selbst wenn neue Zeilen hinzukommen.
1) Wählen Sie eine stabile Sortierung
Wählen Sie eine Reihenfolge, die sich für eine gegebene Zeile nie ändert. Eine übliche Wahl ist created_at desc, id desc. Der id‑Tie‑Breaker ist wichtig, wenn viele Zeilen denselben Zeitstempel haben.
2) Definieren Sie Anfrage‑ und Antwort‑Formate
Halten Sie die Anfrage klein und vorhersehbar: ein limit, ein optionaler cursor und die Filter, die Sie bereits unterstützen (Status, Besitzer, Suche).
Eine einfache Antwortform sieht so aus:
{
"items": [/* results */],
"next_cursor": "opaque-token",
"has_more": true
}
3) Cursor sicher kodieren und dekodieren
Geben Sie keinen rohen SQL‑Wert oder einen Datenbank‑Offset im Cursor preis. Machen Sie ihn zu einem undurchsichtigen Token, das nur enthält, was Sie brauchen, um das Paging fortzusetzen — beispielsweise created_at und id des letzten Elements.
Ein praxisnahes Format ist base64-kodiertes JSON, optional signiert (damit Clients es nicht manipulieren). Beispielnutzlast im Token: { "created_at": "2026-01-10T12:34:56Z", "id": 123 }.
4) Abfrage mit dem Cursor verwenden (und Einfügungen handhaben)
Bei created_at desc, id desc sollte Ihre Abfrage für die nächste Seite Zeilen „vor“ dem Cursor holen:
created_at < cursor_created_atOR (created_at = cursor_created_atANDid < cursor_id)
Das hält die Paginierung stabil, selbst wenn neue Items oben eingefügt werden, während der Nutzer paged.
5) Schutzmechanismen einbauen
Setzen Sie ein Standardlimit (z. B. 25) und ein hartes Maximum (z. B. 100). Validieren Sie den Cursor, das Limit und die Filter. Wenn der Cursor ungültig ist, geben Sie einen klaren 400‑Fehler zurück. Bei FixMyMess fehlen diese Schutzmechanismen in oft AI-generierten Endpunkten, weshalb Listenseiten bei echtem Traffic zusammenbrechen können.
Cache‑Keys für Listenantworten entwerfen
Listenseiten zu cachen klingt einfach, bis man sich erinnert, wie viele „verschiedene Listen“ Ihre App erzeugen kann. Ein Endpunkt kann Suche, Filter, Sort-Optionen, unterschiedliche Seitengrößen und Cursor‑Paginierung unterstützen. Wenn Ihr Cache‑Key einen dieser Eingänge ignoriert, riskieren Sie, falsche Ergebnisse an falsche Nutzer zu zeigen.
Ein guter Cache‑Key ist schlicht ein einmaliger Fingerabdruck der exakten Listenantwort. Beziehen Sie alles ein, was beeinflusst, welche Reihen erscheinen oder in welcher Reihenfolge. Typischerweise bedeutet das:
- Scope: öffentlich vs pro Nutzer vs pro Mandant (und die jeweilige ID)
- Query‑Eingaben: Filter, Suchtext und Sortierung
- Paginierung: Cursor (oder Markierung für „erste Seite“) und Limit
- Version: ein optionaler Schema‑ oder „list-v2“-Tag, damit Sie Formate sicher ändern können
Halten Sie den Key lesbar. Ein einfaches Muster, das gut funktioniert, ist:
resource:scope:filters:sort:cursor:limit
Beispiel: tickets:org_42:status=open|q=refund:created_desc:cursor=abc123:limit=25. Normalisieren Sie Eingaben, damit verschiedene Schreibweisen keine unnötigen Cache‑Misses erzeugen (Trimmen von Leerzeichen, Sortieren von Filterparametern und ein konsistenter Trenner).
Entscheiden Sie, was Sie cachen. Viele Teams cachen nur die erste Seite, weil sie am meisten angefragt wird und am meisten von einer kurzen TTL profitiert. Alle Seiten zu cachen hilft auch, aber es vervielfacht die Anzahl der Keys und erhöht die Invalidation‑Arbeit, wenn sich Daten ändern.
Cachen Sie nicht, wenn es öfter falsch als nützlich ist: stark personalisierte Listen (z. B. „für dich empfohlen“), Listen, die sich jede paar Sekunden ändern, oder Listen mit Berechtigungsprüfungen, die schwer sicher im Key abzubilden sind.
Wenn Sie an Caching und Paginierung für langsame Listenseiten in einer AI‑generierten App arbeiten, achten Sie auf Endpunkte, die den cursor optional behandeln und als Fallback „alles zurückgeben“. Das ist ein häufiges Problem, das FixMyMess bei Audits findet und durch striktere Paginierungsdefaults und vollständiges Einbeziehen des Query‑Kontexts in Cache‑Keys behebt.
Caches frisch halten, ohne es zu überkomplizieren
Die meisten Listenseiten brauchen keine perfekte, sofortige Frische. Sie müssen schnell wirken und „aktuell genug“ für das Ziel des Nutzers sein. Das ist der Schlüssel, damit Caching und Paginierung für langsame Listenseiten funktionieren, ohne die Cache‑Invalidation zu einem zweiten Produkt zu machen.
TTL vs. ereignisbasierte Invalidation (in einfachen Worten)
Eine TTL (Time to Live) ist die einfachste Option: cache die Liste z. B. 30–120 Sekunden und aktualisiere sie dann. Einfach und zuverlässig, aber Daten können leicht veraltet sein.
Ereignisbasierte Invalidation versucht exakt zu sein: wenn ein Datensatz sich ändert, löschen Sie sofort die betroffenen gecachten Listen. Das kann sehr frisch sein, wird aber kompliziert, weil eine Änderung viele Filter und Sortierungen betreffen kann.
Ein praktischer Mittelweg ist "stale while revalidate": dienen Sie die gecachte Liste auch wenn sie etwas alt ist, und aktualisieren Sie sie im Hintergrund. Nutzer bekommen schnelle Seiten, und der Cache heilt sich nach Änderungen schnell.
Zielgerichtete Invalidation, die überschaubar bleibt
Statt "alles löschen" invalidieren Sie nur, was sich klar beschreiben lässt:
- Nach Nutzer oder Mandant (nur deren Listen)
- Nach Ressourcentyp (Orders vs Customers)
- Nach Filtergruppe (status=open, tag=vip)
- Nach „collection_version“ (ein Zähler, den Sie bei Writes erhöhen)
Die letzte Option ist oft am einfachsten: nehmen Sie collection_version in den Cache‑Key auf. Wenn sich etwas ändert, erhöhen Sie die Version, und alte Cache‑Einträge werden nicht mehr verwendet.
Cache‑Stampedes passieren, wenn viele Anfragen gleichzeitig einen Cache‑Miss haben und alle den Cache neu aufbauen. Zwei einfache Schutzmechanismen helfen:
- TTL‑Jitter hinzufügen (zufällig +/- 10–20 %)
- Request‑Coalescing (ein Builder, andere warten)
- Stale‑Serving für ein kurzes Gnadenfenster
Entscheiden Sie abschließend, welche Konsistenz Sie wirklich brauchen. Für die meisten Admin‑ und Feed‑ähnlichen Listen ist "Updates erscheinen innerhalb von 1–2 Minuten" ausreichend. Bei Geldbewegungen oder Berechtigungen cache die Liste gar nicht oder nutze sehr kurze TTLs und validiere auf der Detailseite.
Client‑seitige Paginierungs‑Muster, die schnell bleiben
Die meisten Listenbildschirme haben ein klares Traffic‑Muster: Nutzer landen viel häufiger auf Seite 1 als auf jeder anderen Seite. Cachen Sie die erste Seite im Client (Speicher oder localStorage) mit kurzer TTL und zeigen Sie sie sofort an, während Sie im Hintergrund aktualisieren. Das behebt oft das „leere Bildschirm“-Gefühl, das eine Liste langsam wirken lässt.
Bei Cursor‑Paginierung behandeln Sie den Cursor als Teil der Seitenidentität. Halten Sie eine kleine Map wie cursor -> rows, damit Zurückgehen keine neuen Anfragen auslöst und Ihre UI auch bei instabilem Netz reaktionsfähig bleibt.
Prefetching der nächsten Seite hilft, aber nur wenn es behutsam gemacht wird. Ein sicherer Ansatz ist zu prefetchen, wenn sich der Nutzer dem unteren Rand nähert (oder nach einer kurzen Pause beim Scrollen), und die Anfrage abzubrechen, wenn Filter oder Sortierung sich ändern.
- Prefetchen Sie nur eine Seite voraus
- Debouncen Sie den Auslöser (z. B. 200–400 ms)
- Blockieren Sie Prefetch während eine Anfrage bereits läuft
- Prefetchen Sie nicht für teure Filter (z. B. Volltextsuche)
- Stoppen Sie Prefetch, wenn der Tab verborgen ist
Loading‑Zustände sind wichtiger, als viele denken. Verwenden Sie einen „soften“ Ladeindikator (bestehende Zeilen sichtbar halten) und einen deutlichen Retry‑Button für Fehler. Beim Retry fügen Sie Ergebnisse erst an, nachdem Sie bestätigt haben, dass sie zur gleichen Abfrage gehören (gleiche Filter, Sort und Cursor), ansonsten bekommen Sie Duplikate oder vermischte Zeilen.
Client‑seitiges Deduping ist Ihre Sicherheitsleine. Mergen Sie Zeilen immer anhand einer stabilen ID (z. B. id), nicht über Array‑Index oder Zeitstempel. Wenn Sie dieselbe Zeile zweimal bekommen, ersetzen Sie sie an Ort und Stelle, damit die Liste nicht springt.
Infinite Scroll ist nicht immer besser. Für Admin-Screens, wo Nutzer oft springen, sortieren und vergleichen müssen, kann es schlechter sein. Wenn Nutzer häufig sagen „ich war auf Seite 7“, nutzen Sie paginierte Navigation mit klarer Seitengröße und reservieren Sie Infinite Scroll für Feeds, bei denen die genaue Position keine Rolle spielt. Das ist eine übliche Korrektur, die wir beim Reparieren AI‑generierter List‑UIs anwenden, die die API überlasten und träge wirken.
Datenbank‑ und Payload‑Basics, die Caching besser wirken lassen
Caching hilft, aber es beseitigt keine langsamen Abfragen. Eine gecachte Listenantwort muss mindestens einmal generiert werden, und Cache‑Misses passieren öfter als erwartet (neue Filter, neue Nutzer, abgelaufene Keys, Deploys). Wenn die Datenbankabfrage wackelig ist, fühlt sich das gesamte System instabil an.
Indizes sind der erste Ort, an dem Sie nachsehen sollten. Für Listenseiten gilt: Ihr Index sollte zu dem passen, wie Sie filtern und wie Sie sortieren. Wenn Ihr Endpunkt WHERE status = 'open' und ORDER BY created_at DESC macht, sollte die Datenbank einen Pfad haben, der beides unterstützt.
Eine praktische Faustregel für List‑Queries:
- Indexieren Sie die Spalten, die Sie am häufigsten in
WHEREverwenden. - Nehmen Sie die
ORDER BY‑Spalte wenn möglich in denselben Index auf. - Wenn Sie immer nach Mandant oder Nutzer filtern, sollte diese Spalte meist zuerst stehen.
- Bevorzugen Sie stabile Sort‑Keys (
created_at,id), damit Paginierung und Caching vorhersehbar bleiben. - Prüfen Sie Indizes erneut, wenn Sie neue Filter hinzufügen, nicht erst Monate später.
Als Nächstes: hören Sie auf, extra Daten zu senden. Viele langsame Listenseiten sind langsam, weil sie zu viel JSON bewegen, nicht weil die Datenbank stirbt. Vermeiden Sie SELECT *. Wählen Sie die Felder aus, die Sie tatsächlich in der Tabelle anzeigen. Wenn das UI nur id, name, status und updated_at braucht, geben Sie nur diese zurück. Sie erhalten schnellere Abfragen, kleinere Payloads und höhere Cache‑Trefferquoten, weil Antworten billiger zu speichern und auszuliefern sind.
Seien Sie vorsichtig beim Sortieren nach berechneten Feldern wie „full_name“ (Vorname + Nachname), „last_activity“ aus einer Subquery oder „relevance“ aus einer Formel. Diese zwingen oft zu Scans, join‑schweren Plänen oder zu Sorts großer Ergebnismengen im Speicher. Wenn möglich, berechnen Sie solche Werte vor und speichern Sie sie in einer echten Spalte, oder sortieren Sie nach einem einfacheren Feld und berechnen Sie den „fancy“ Wert im UI.
Bevor Sie weiter optimieren, messen Sie zwei Zahlen:
- Abfragezeit (p50 und p95, nicht nur ein einzelner Lauf).
- Payload‑Größe für eine einzelne Seite.
- Untersuchte Zeilen vs. zurückgegebene Zeilen.
- Cache‑Trefferquote für den List‑Endpunkt.
- Die langsamste Filter+Sort‑Kombination, die Nutzer tatsächlich anklicken.
Das ist besonders häufig in AI‑generierten Apps, die FixMyMess sieht: Listendpunkte „funktionieren“ in einer Demo, aber sobald echte Daten kommen, führen fehlende Indizes und übergroße Payloads dazu, dass Caches wie „funktionieren nicht“ aussehen. Beheben Sie die Grundlagen zuerst, dann wird Caching zum Multiplikator statt zum Pflaster.
Beispiel: eine langsame Admin‑Liste in einer wachsenden App reparieren
Eine häufige Geschichte: ein Admin‑Dashboard begann als AI‑generierter Prototyp. Mit 200 Zeilen funktionierte es. Sechs Monate später sind es 200.000, und die „Users“-Liste läuft in ein Time‑out oder braucht 10–20 Sekunden. Leute drücken Refresh, Filter wirken zufällig, und die CPU der Datenbank schnellt hoch.
Die schlechte Version sieht meist so aus: der Client ruft einen Endpunkt auf, der alles zurückgibt (oder OFFSET‑Paginierung mit riesigen Offsets verwendet), die Antwort enthält schwere Felder (Profile, Einstellungen, Audit‑History), und jeder Scroll löst eine teure Abfrage aus. Es gibt kein Caching, sodass dieselbe erste Seite für jeden Admin neu berechnet wird.
Hier ein praktischer Fix für Caching und Paginierung für langsame Listenseiten, der das Verhalten vorhersehbar hält.
Was wir verändert haben
Wir haben das UI unangetastet gelassen, aber das API‑Contract geändert:
- Cursor‑Paginierung verwenden:
items,nextCursorzurückgeben und immer mitlimitanfragen. - Nach einem stabilen Key sortieren (z. B.
created_atplusid), damit Cursors nicht überspringen oder wiederholen. - Nur die erste Seite für gängige Views cachen (z. B. „Alle Nutzer, neueste zuerst“), weil diese Seite am häufigsten angefragt wird.
- Filter auf sichere, indexierte Felder beschränken (Status, Rolle, Erstellungsdatum). „Contains“-Suche auf großen Textspalten ablehnen, sofern keine Suchunterstützung vorhanden ist.
- Payload kürzen: die Liste liefert nur, was die Tabelle braucht. Details laden auf der Nutzer‑Detailseite.
Eine einfache Antwortform:
{ "items": [{"id": "u_1", "email": "[email protected]", "createdAt": "..."}], "nextCursor": "createdAt:id" }
Was Admins bemerkten
Der erste Bildschirm erscheint schnell, und das Scrollen bleibt gleichmäßig, weil jede Anfrage begrenzt ist. Das Aktualisieren der Liste hämmert nicht mehr die Datenbank, weil die erste Seite aus dem Cache kommt. Filter wirken konsistent, weil Sortierung und Cursor‑Regeln klar sind.
Um sicher auszurollen, schalten Sie den neuen Endpunkt zunächst hinter ein Feature‑Flag für interne Admins, vergleichen Ergebnisse side‑by‑side und loggen Cursor‑Fehler (Duplikate, fehlende Zeilen). Wenn Sie einen kaputten Prototypen von Tools wie Bolt oder Replit erben, beginnt FixMyMess oft mit einem schnellen Audit, um „alles‑laden“-Endpunkte und die Abfragen zu finden, die zuerst repariert werden müssen.
Häufige Fehler und Fallstricke
Die meisten Reparaturen von „langsamen Listenseiten“ scheitern aus einfachen Gründen: Paging ist unzuverlässig, der Cache unsicher oder der Endpunkt angreifbar. Wenn Sie an Caching und Paginierung für langsame Listenseiten arbeiten, sind dies die Stolperfallen, die später am meisten Probleme machen.
Offset‑Paging ist die klassische Falle. Es wirkt mit kleinen Daten gut, aber wenn Sie nach einem Feld sortieren, das nicht eindeutig ist (z. B. created_at), können neue Zeilen beim Pagen dazwischen rutschen. Das erzeugt Duplikate, übersprungene Elemente oder eine „springende“ Seite. Cursor‑Paginierung vermeidet das, aber nur, wenn Ihre Sortierung stabil ist (z. B. created_at plus eine eindeutige id als Tie‑Breaker).
Cursors selbst können ein Sicherheits‑ und Korrektheitsproblem sein. Wenn Sie rohe IDs, SQL‑Fragmente oder Filter‑Ausdrücke in den Cursor packen, riskieren Sie, dass Nutzer Werte erraten, Dekodierung bricht oder teure Abfragen erzwungen werden. Ein sichereres Muster ist: kodieren Sie nur die zuletzt gesehenen Sort‑Werte und validieren Sie diese serverseitig, bevor Sie die Abfrage ausführen.
Caching bringt eine andere Klasse von Fehlern mit sich. Der größte ist, den Scope zu vergessen. Wenn Ihr Cache‑Key nicht Nutzer, Mandant, Rolle und Filter einschließt, können Sie Daten zwischen Accounts leaken. Achten Sie auch auf Ihre „Freshness“-Story: Status‑Änderungen und Löschungen sind das Erste, was Nutzer bemerken, wenn gecachte Listen zu lange hinterherhinken.
Ein schnelles Beispiel: eine Admin‑„Orders“-Seite zeigt bezahlte und ausstehende Bestellungen. Wenn der Cache‑Key den Filter status=pending ignoriert, kann ein Admin eine gemischte Liste sehen, die falsch wirkt, und der Cache könnte sogar mit nicht‑admin Views geteilt werden.
Fünf Schutzregeln, die die meisten Vorfälle verhindern:
- Immer ein maximales
limitsetzen und serverseitig durchsetzen. - Eine stabile Sortierung mit eindeutigem Tie‑Breaker verwenden.
- Cursors undurchsichtig machen und dekodierte Werte validieren.
- Cache‑Keys aus Scope (Nutzer/Mandant) + Filtern + Sort + Seitengröße bauen.
- Entscheiden, wie lange veraltete Daten akzeptabel sind, und TTL für stark wechselnde Listen reduzieren.
Wenn Sie einen AI‑generierten Code erben mit fehlerhaftem Paging, unsicheren Cache‑Keys oder ungebundenen Listendpunkten, kann FixMyMess den Codepfad auditieren und die genauen Fehlerquellen aufzeigen, bevor Sie produktiv gehen.
Schnell‑Checkliste und nächste Schritte
Nutzen Sie das hier als finale Kontrolle, wenn Sie Caching und Paginierung für langsame Listenseiten verbessern. Kleine Details entscheiden, ob Ihre Liste bei 1.000 Zeilen und bei 10 Millionen schnell bleibt.
Sicher bauen (API und Cache)
- Setzen Sie eine harte Obergrenze (und einen sinnvollen Default), damit niemand versehentlich 50.000 Zeilen anfordert.
- Verwenden Sie eine stabile Sortierung (z. B. created_at + id), damit Paging Elemente nicht zwischen Anfragen umsortiert.
- Halten Sie den Cursor undurchsichtig. Behandeln Sie ihn wie ein Token, nicht als etwas, das der Client bearbeitet.
- Stellen Sie sicher, dass die Abfrage Indizes verwendet, die zu Ihren Filtern und Ihrer Sortierung passen.
- Scope‑en Sie Cache‑Keys auf alles, was die Antwort ändert: Nutzer/Mandant, Filter, Sort, Seitengröße und Cursor.
Caching funktioniert am besten, wenn die erste Seite leicht wiederverwendbar ist — fangen Sie dort an. Wählen Sie eine TTL, die zu der Häufigkeit passt, mit der die Liste wirklich ändert, und fügen Sie grundlegenden Stampede‑Schutz hinzu (Lock, Request‑Coalescing oder serve stale while revalidate), damit Traffic‑Spitzen Ihre Datenbank nicht schmelzen.
Nachweis, dass es funktioniert (Tests und Betrieb)
- Erstellen Sie neue Items während des Pagings und bestätigen Sie, dass Sie keine Duplikate oder fehlenden Zeilen sehen.
- Ändern Sie Filter mitten im Scrollen und bestätigen Sie, dass der Client den Zustand zurücksetzt, anstatt alte und neue Seiten zu vermischen.
- Simulieren Sie ein langsames Netz und verifizieren Sie, dass der Client Ergebnisse dedupliziert und out‑of‑order Antworten ignoriert.
- Überwachen Sie Abfragezeiten, Cache‑Trefferquote, Fehlerrate und Payload‑Größe nach dem Rollout.
- Loggen Sie die langsamsten List‑Endpunkte mit ihren Filtern, damit Sie die echten Übeltäter gezielt angehen.
Nächste Schritte: Wenn Ihr AI‑generierter Prototyp langsame oder fehlerhafte Listendpunkte hat, kann FixMyMess ein kostenloses Code‑Audit durchführen, um Paginierungs-, Caching‑ und Sicherheitsprobleme zu identifizieren, bevor Sie live gehen.