CI/CD für geerbten Prototyp-Code: ein einfaches Pipeline-Blueprint
CI/CD für geerbten Prototyp-Code einfach gemacht: ein praktisches Pipeline-Blueprint mit Linting, Tests, Build-Checks, Preview-Deploys und sichereren Produktions-Releases.
Warum geerbte Prototypen einen anderen CI/CD-Ansatz brauchen
Geerbter Prototyp-Code ist meist eine Mischung aus schnellen Experimenten, kopierten Snippets und halb fertigen Features. Er hat oft eine schwache Struktur, unklare Verantwortlichkeiten und "temporäre" Abkürzungen, die dauerhaft geworden sind. Wenn KI-Tools beim Erstellen geholfen haben, sehen Sie außerdem inkonsistente Muster, fehlende Fehlerbehandlung und Logik, die erst dann Probleme macht, wenn echte Nutzer Randfälle treffen.
Deshalb läuft es auf einem Laptop, aber bricht in Produktion auseinander. Die ursprüngliche Einrichtung kann von versteckten lokalen Dateien, einer bestimmten Laufzeitversion, einer vorgefertigten Datenbank oder Umgebungsvariablen abhängen, die niemand dokumentiert hat. Ein Teamkollege startet es mit einem aufgeheizten Cache; ein anderer installiert frisch und sieht nur einen leeren Bildschirm. Produktion bringt strengere Sicherheit, andere Netzwerkbedingungen und echtes Datenvolumen mit sich – das deckt Probleme wie kaputte Authentifizierung, exponierte Secrets und fragile Datenbankabfragen auf.
Ein besserer CI/CD-Ansatz bedeutet hier nicht perfekte Ingenieursarbeit am ersten Tag. Es geht um weniger Feuerwehreinsätze. Eine einfache Pipeline fängt häufige Fehler früh ab, macht Releases reproduzierbar und gibt Ihnen einen sichereren Weg, Dinge zu ändern, ohne vorher das komplette System umzuschreiben.
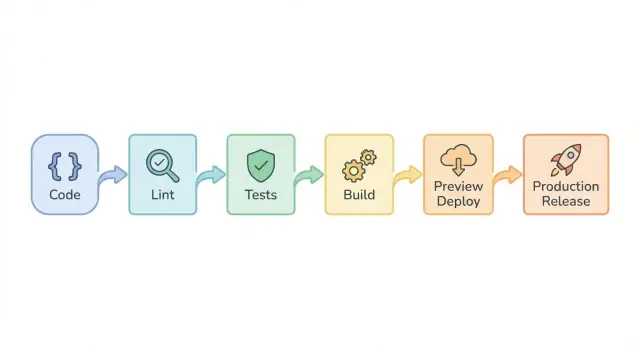
Dieses Blueprint konzentriert sich auf praktische Leitplanken: grundlegendes Linting, eine kleine Testmenge, verlässliche Builds, Deploy-Previews zur Prüfung und sichere Produktions-Releases mit Rückrollmöglichkeit.
Wenn die Basis stark gebrochen ist (z. B. verstrickte Auth, unsichere Query-Muster oder Sicherheitslücken wie SQL-Injection), bringt Ihnen zuerst eine kurze Diagnose und gezielte Reparaturen mehr. Danach hilft CI/CD, dass dieselben Probleme nicht wieder auftreten.
Ziel festlegen: was „sicher genug zum Ausliefern" bedeutet
Geerbte Prototypen versagen auf unvorhersehbare Weise. Das Ziel Ihrer Pipeline ist nicht Perfektion. Es ist schnelleres Feedback, weniger fehlerhafte Deploys und Releases, die Sie wiederholen können, ohne den Atem anzuhalten.
Schreiben Sie auf, was „sicher genug" für Ihre App in diesem Monat bedeutet, nicht Ihre Traumversion in sechs Monaten. Ein praktisches Anfangsversprechen ist simpel: Jede Änderung durchläuft dieselben Checks, jedes Mal. Keine "kurzen Hotfixs" als Ausnahme, denn Ausnahmen werden zur neuen Norm.
Eine Definition, die das Team wiederholen kann
Eine Änderung ist „fertig", wenn zwei Dinge zutreffen:
- Die Pipeline ist grün.
- Sie erzeugt etwas, das Sie tatsächlich deployen können (ein auslieferbares Artefakt), nicht nur Code, der auf einem Laptop kompiliert.
Wenn Checks grün sind, Sie aber nicht deployen können, ist die Pipeline nicht fertig.
Halten Sie die Definition kurz. Für die meisten Teams reicht es zu verlangen: Linting und ein grundlegendes Testset, ein sauberer Build in CI, ein Preview- oder Staging-Deploy zur Prüfung und ein Produktions-Release, das denselben Pfad mit einem expliziten Genehmigungsschritt folgt.
Was Sie absichtlich aufschieben sollten
Alles am ersten Tag reparieren zu wollen ist der schnellste Weg, CI/CD wieder aufzugeben. Es ist in Ordnung, vollständige Testabdeckung und große Refactorings aufzuschieben, während Sie verlässliche Tore einrichten.
Wenn der Login manchmal bricht, beginnen Sie nicht mit dem kompletten Neuaufbau der Authentifizierung. Definieren Sie „sicher genug" so: Login hat einen automatisierten Smoke-Test, Secrets sind nicht exponiert und der Build produziert ein releasbares Artefakt. Sobald Releases nicht mehr fehlschlagen, können Sie die Abdeckung erweitern und refactoren mit weniger Risiko.
Repo vorbereiten: Branches, Umgebungen und Secrets
Bevor Sie CI/CD verkabeln, machen Sie das Repo vorhersehbar. Die meisten Prototyp-Probleme kommen von mysteriösen Einstellungen: Branches, denen niemand vertraut, Umgebungsvariablen in Chatlogs und versehentlich committete Secrets.
Halten Sie Branches langweilig
In der Regel brauchen Sie nur einen langlebigen Branch plus kurzlebige Arbeits-Branches:
mainist immer deploybar.- Änderungen passieren in kurzen Feature-Branches, die schnell wieder zusammengeführt werden.
Vermeiden Sie Mega-Branches (z. B. einen lang laufenden dev), die über Wochen auseinanderdriften. Taggen Sie Releases auf main, damit Sie auf einen bekannten guten Punkt zurückrollen können.
Machen Sie Umgebungen und Secrets explizit
Wählen Sie eine einzige Quelle der Wahrheit für Konfiguration. Ein einfaches Muster ist: lokal nutzt man eine Beispiel-env-Datei, CI nutzt den Secret-Store der CI, und Produktion nutzt die Umgebungssettings des Hosters. Wichtig ist Konsistenz: dieselben Variablennamen existieren überall.
Mindestens erforderlich:
- Führen Sie eine dokumentierte Liste der benötigten Env-Vars (was sie tun, sichere Defaults).
- Behalten Sie eine
.env.examplemit nur Namen, niemals echte Werte. - Entfernen Sie committete Secrets und rotieren Sie alles, was exponiert wurde.
- Halten Sie Keys und URLs aus dem Code heraus.
Ein nützlicher Reality-Check: Wenn ein neuer Teamkollege die App nicht starten kann, ohne nach „der richtigen .env" zu fragen, wird Ihre Pipeline auch fragil sein.
Fügen Sie außerdem eine kurze README-Notiz mit Copy-Paste-Kommandos hinzu, um lint, tests und einen Build lokal zu starten. Wenn es lokal umständlich ist, wird es in CI schlimmer.
Quality Gates, die die meisten Probleme früh erkennen
Prototyp-Code bricht oft auf vorhersehbare Weise: unordentliche Formatierung, versteckte Laufzeitannahmen und „funktioniert auf meiner Maschine"-Installationen. Quality Gates sind die Checks, die Ihre Pipeline bei jeder Änderung laufen lässt, damit Probleme Minuten nach einem Commit sichtbar werden, nicht bei einem nächtlichen Deploy.
Beginnen Sie mit einem Formatter und einem Linter und machen Sie diese nicht optional. Konsistenz ist wichtiger als Perfektion. Automatisierte Checks stoppen Stil-Debatten und verhindern, dass Kleinigkeiten echte Bugs verbergen.
Fügen Sie leichte Type-Checks hinzu, wo sie passen. Sie brauchen keine komplette Umstellung, um Nutzen zu erzielen. Selbst einfache Typüberprüfungen fangen falsche Argumente, fehlende Felder und unsicheres Null-Handling ab, bevor sie zu Produktionsfehlern werden.
Für Tests halten Sie die Messlatte realistisch. Definieren Sie eine Mindestmenge, die immer bestehen muss, auch wenn der Rest der Suite noch wächst. Ein praktisches Minimum deckt oft die Abläufe ab, die Ihnen am meisten Zeit kosten:
- Login und Session-Handling (inkl. Logout)
- Ein Kern-"Happy Path" für das Hauptfeature
- Ein kritischer API-Endpunkt (oder Background Job), der einen echten DB-Aufruf macht
- Grundlegende Berechtigungsprüfungen (Nutzer sehen keine Daten anderer Nutzer)
- Ein Smoke-Test, dass die App ohne Fehler startet
Machen Sie Builds reproduzierbar. Pinne die Laufzeitversion (Node, Python etc.), nutzen Sie Lockfiles und führen Sie saubere Installationen in CI aus. So testen Sie genau das, was Sie später ausliefern.
Schritt-für-Schritt-Pipeline-Blueprint (lint -> test -> build)
Das Ziel der Pipeline ist schnell zu fehlschlagen und zu sagen, was zu reparieren ist.
Führen Sie sie bei jedem Pull Request aus, halten Sie sie konsistent und schnell genug, damit niemand versucht, sie zu umgehen.
Eine einfache Reihenfolge, die funktioniert
-
Formatieren und Linten zuerst. Auto-Formatting reduziert laute Diffs. Linting fängt einfache Probleme früh (unbenutzte Variablen, falsche Imports, unsichere Muster) und hilft, den Code lesbar zu halten, während Sie ihn reparieren.
-
Tests mit klarem Output ausführen. Machen Sie Fehler deutlich: welcher Test fehlgeschlagen ist, die Fehlermeldung und wo es passiert ist. Reviewer sollten nicht in Logs graben müssen.
-
Build wie in Produktion. Nutzen Sie denselben Build-Befehl und dieselbe Laufzeitversion, die Sie in Produktion erwarten. Verwenden Sie dieselbe Form der Umgebungsvariablen (aber niemals echte Secrets). Dieser Schritt fängt fehlende Assets, falsche Konfiguration und „funktioniert auf meinem Rechner"-Überraschungen.
-
Fügen Sie einen schnellen Security-Check hinzu. Leichtgewichtig: Dependency-Scan auf bekannte Verwundbarkeiten und Scan auf versehentlich committete Secrets. KI-unterstützt erstellter Code neigt besonders zu hartkodierten Token oder Beispiel-Credentials.
-
Publish Build-Artefakte. Speichern Sie Build-Outputs (und Test-Reports), sodass Deploy-Schritte sie wiederverwenden statt neu zu bauen.
Deploy-Previews: Änderungen prüfen ohne Produktion zu riskieren
Ein Deploy-Preview ist eine temporäre Kopie Ihrer App, die genau den Code aus einem einzelnen Pull Request ausführt. Sie verhält sich wie das echte Produkt, ist aber isoliert. Das hilft nicht-technischen Reviewern, weil sie echte Abläufe anklicken können, ohne etwas installieren zu müssen.
Previews sind einer der schnellsten Wege, „funktioniert auf meinem Rechner"-Probleme zu finden. Sie zeigen auch UI-Probleme, kaputte Redirects, fehlende Env-Vars und langsame Seiten, bevor etwas in Produktion geht.
Erstellen Sie standardmäßig Previews für jeden PR. Überspringen Sie sie nur, wenn sie keinen Mehrwert liefern (z. B. nur Doku-Änderungen). Konsistenz ist wichtig: Reviewer lernen, dass jede Änderung einen sicheren Ort zur Prüfung hat.
Machen Sie Previews realistisch (ohne Produktion zu kopieren)
Wenn Previews mit einer leeren Datenbank starten, sehen viele Seiten kaputt aus, obwohl der Code in Ordnung ist. Planen Sie einfache Seed-Daten im Voraus:
- Erstellen Sie eine kleine Menge Fake-User und Beispiel-Datensätze beim Deploy.
- Fügen Sie ein deutlich sichtbares „Demo-Modus"-Banner hinzu.
- Stellen Sie ein oder zwei vorgefertigte Test-Accounts für Reviews bereit (niemals echte Konten).
Halten Sie Previews sicher
Preview-Umgebungen dürfen niemals echte Kundendaten oder Produktions-Secrets nutzen. Behandeln Sie sie wie eine öffentliche Sandbox.
Gute Defaults: separate Preview-Keys und Datenbanken, Deaktivierung zerstörerischer Jobs (Billing, E-Mails, Webhooks) und automatische Ablauffristen für Previews.
Sichere Produktions-Releases: Genehmigungen, Rollbacks und Monitoring
Ein sicherer Release-Prozess macht versteckte Risiken sichtbar und einfach rückgängigbar.
Machen Sie jedes Produktions-Release nachvollziehbar. Nutzen Sie Versionstags (z. B. v1.8.0), damit Sie beantworten können: Welcher Code läuft gerade, wer hat ihn genehmigt und was hat sich seit dem letzten Release geändert.
Sogar in kleinen Teams fügen Sie vor Produktion einen manuellen Genehmigungsschritt hinzu. CI kann Checks ausführen, aber ein Mensch sollte bestätigen, dass das Preview richtig aussieht, die Release-Notes prüfen und sicherstellen, dass es einen Rollback-Plan gibt. In geerbten Codebasen kann eine kleine Änderung einen kritischen Ablauf zerstören.
Rollbacks sollten schnell und langweilig sein. Bevor Sie einen brauchen, stellen Sie sicher, dass Sie den vorherigen Tag mit einer Aktion redeployen können, Datenbank-Änderungen sicher handhaben (oder riskante Migrationen während Releases vermeiden), Umgebungssettings ohne Rätsel wiederherstellen und den Erfolg mit einem schnellen Smoke-Check bestätigen.
Für extra Sicherheit nutzen Sie progressive Rollouts (Canary oder prozentuale Freigabe). Release an einen kleinen Traffic-Slice, beobachten Sie Probleme und rollen Sie dann für alle aus. Springen die Fehler hoch, stoppen oder rollen Sie zurück, während die meisten Nutzer unbeeinträchtigt bleiben.
Nach einem Release beobachten Sie wenige Signale, die zeigen, ob die App nutzbar ist:
- Server- und Frontend-Errors (Spitzen, neue Fehlertypen)
- Erfolgsrate von Login und Signup
- Zahlungen oder Checkout-Abschlüsse (falls relevant)
- Performance (lange Seiten, Timeouts)
- Wichtige Background-Jobs (E-Mails, Webhooks, Queues)
Wenn Tests fehlen oder flakig sind: ein praktikabler Weg nach vorn
Geerbte Prototypen haben oft keine Tests oder Tests, die „manchmal" fehlschlagen. Sie brauchen trotzdem Vertrauen, aber auch Fortschritt. Das Ziel sind verlässliche Signale, denen Sie trauen können.
Flakiger Test oder echter Bug?
Ein flakiger Test fällt oft an unterschiedlichen Stellen ohne Code-Änderung aus. Ein echter Bug fällt hingegen immer gleich, bis er behoben ist.
Schnelle Möglichkeiten es zu unterscheiden:
- Führen Sie denselben Commit 3–5 Mal erneut aus. Zufällige Grüns deuten auf Flakiness hin.
- Schauen Sie sich den Fehler an. Timeouts, "Element nicht gefunden" und Netzwerkprobleme deuten oft auf Flakiness.
- Achten Sie auf geteilten Zustand: reihenfolgenabhängige Tests, wiederverwendete Datenbanken, gecachte Sessions.
- Vergleichen Sie Lokal vs. CI. Nur in CI auftretende Fehler deuten oft auf Timing-Probleme oder fehlende Konfiguration.
Ignorieren Sie Flakiness nicht. Quarantänisieren Sie den Test (markieren Sie ihn als nicht-blockierend) und legen Sie eine Aufgabe an, ihn zu reparieren, damit die Pipeline nützlich bleibt.
Noch keine Tests? Beginnen Sie mit Smoke-Tests
Wenn Sie bei Null starten, beginnen Sie mit einer kleinen Smoke-Suite, die die wichtigsten Pfade schützt:
- App startet und die Startseite lädt
- Login funktioniert (Happy Path)
- Eine kritische Create/Read-Action funktioniert
- Ausgeloggte Nutzer können keine private Seite erreichen
- Eine API-Health-Check gibt 200 zurück
Halten Sie diese schnell (ein paar Minuten) und blockierend.
Um Stabilität zu gewinnen, ohne alle zu verlangsamen, teilen Sie Tests in Stufen: Smoke-Tests blockieren Merges; längere End-to-End-Tests laufen zeitgesteuert oder vor Releases. Begrenzen Sie Retries auf eins und behandeln Sie "Retry bestanden" als Warnung, nicht als Erfolg.
Für Coverage setzen Sie ein Ziel, das langsam wächst: Starten Sie mit 10–20 % im Kernlogikbereich und erhöhen Sie es mit der Zeit.
Häufige Fehler, die CI/CD schmerzhaft machen
Der schnellste Weg zu einer Pipeline, der niemand vertraut, ist, sie am ersten Tag "perfekt" machen zu wollen. Bei geerbtem Code (vor allem KI-geschriebenem) zielen Sie auf wiederholbaren Fortschritt, nicht auf eine Wand aus roten Checks, die jeder zu ignorieren lernt.
Eine Falle ist, Quality Gates so streng zu machen, dass jeder Lauf wegen kleiner Stilfragen fehlschlägt. Linting ist nützlich, aber wenn es die Arbeit blockiert, umgehen Leute CI oder mergen ohne Fix. Beginnen Sie mit Regeln, die echte Bugs fangen, und verschärfen Sie sie mit der Zeit.
Ein weiterer Fehler ist automatisches Deploy auf Produktion bei jedem Merge ohne Pause-Knopf. Das verwandelt einen kleinen Fehler in einen kundenrelevanten Vorfall. Halten Sie Produktion langweilig: Genehmigung vor Release, klarer Rollback-Plan und eine Möglichkeit, ein Release zu stoppen.
Preview-Deploys können auch nach hinten losgehen. Ein Preview, das Ihre Produktionsdatenbank liest oder Produktions-API-Keys nutzt, ist nicht "sicher" – es ist Produktion mit weniger Augen darauf. Nutzen Sie separate Preview-Credentials und eine Preview-Datenbank (oder gemockte Services), damit Reviews keine Daten oder Geld riskieren.
Weitere häufige Pain-Punkte:
- In CI bauen und in Produktion anders bauen (andere Laufzeit, Env-Vars, Flags).
- Abhängigkeiten aufschieben, bis eine Security-Lücke ein rushed Upgrade erzwingt.
- Basis-Checks überspringen, weil "es auf meinem Rechner funktioniert hat."
Schnell-Checkliste: Ist Ihre Pipeline vertrauenswürdig?
Eine Pipeline ist vertrauenswürdig, wenn sie jedes Mal zwei Fragen beantwortet: "Haben wir etwas kaputt gemacht?" und "Können wir schnell zurückrollen, wenn doch?"
Suchen Sie nach diesen Mindestsignalen:
- Linting und Formatting laufen automatisch bei jeder Änderung und schlagen schnell fehl.
- Tests laufen verlässlich und dauern in vertretbarer Zeit.
- Der Build ist reproduzierbar und erzeugt ein deploybares Artefakt.
- Preview-Deploys sind isoliert (keine echten Kundendaten, keine Produktions-Secrets).
- Produktions-Releases benötigen explizite Genehmigung und haben einen schriftlichen Rollback-Plan.
Wenn Sie diese Woche nur eine Sache tun können: Machen Sie Previews sicher. Nutzen Sie eine Testdatenbank, gefälschte Payment-Keys und gestubte E-Mails, damit Reviewer klicken können, ohne echte Nachrichten zu senden oder echte Datensätze zu berühren.
Konzentrieren Sie sich danach auf die erste Stunde nach einem Release:
- Error-Tracking ist aktiv und Sie wissen, wo Sie schauen müssen.
- Alerts existieren für Spitzen in 500ern, Login-Fehlern und langsamen Requests.
- Ein schneller Health-Check bestätigt Kernabläufe (Sign-in, Erstellen eines Datensatzes, Speichern, Logout).
- Logs sind durchsuchbar und enthalten keine Secrets.
- Jemand ist zugewiesen, es zu beobachten.
Beispiel: Einen wackeligen, KI-gebauten Prototyp in eine releasbare App verwandeln
Sie übernehmen einen Prototyp, gebaut in Lovable (oder Bolt/v0), der in einer Demo funktionierte, dann aber beim Deploy versagt. Logins brechen, Umgebungsvariablen sind hartkodiert und der Build läuft auf einem Laptop, aber nicht in CI. Genau hier stoppt eine einfache Pipeline das Raten und macht Änderungen sicherer.
Die erste Woche sollte bewusst klein und langweilig sein. Sie wollen nicht alles perfekt machen. Sie wollen, dass jede Änderung sichtbar, testbar und reversibel wird.
Ein praktischer Wochenplan:
- Tag 1: Saubere Installation und ein einziger "one command"-Build in CI
- Tag 2: Linting/Format-Checks hinzufügen und bei offensichtlichen Fehlern fehlschlagen lassen
- Tag 3: 2–5 Smoke-Tests für kritische Pfade (Login, ein wichtiger API-Route, eine Hauptseite)
- Tag 4: Deploy-Previews für jeden Pull Request aktivieren
- Tag 5: Ein einfacher Release-Gate (manuelle Genehmigung) für Produktion
Deploy-Previews verändern die Gesprächsführung mit Stakeholdern. Anstatt "Ich glaube, es ist gefixt" senden Sie ein Preview und die Genehmigung wird zu einem klaren Ja/Nein.
Wenn Previews tiefere Probleme aufdecken wie kaputte Authentifizierung, exponierte Secrets, unsichere DB-Queries oder Architektur, die Änderungen riskant macht, pausieren Sie Pipeline-Arbeit und beheben zuerst die Grundlagen.
Wenn Sie ein zu chaotisches, KI-generiertes Codebase geerbt haben, hilft ein fokussiertes Audit- und Reparatur-Paket. FixMyMess (fixmymess.ai) beginnt mit einem kostenlosen Code-Audit und übernimmt dann gezielte Fixes wie Logikreparatur, Security-Härtung, Refactoring und Deployment-Prep, damit Ihre Pipeline etwas Solides zu schützen hat.