Circuit Breaker für unzuverlässige Anbieter verhindern Kaskadenausfälle
Erfahren Sie, wie Circuit Breaker für unzuverlässige Anbieter Kaskadenausfälle verhindern: Timeouts, Retries, Fallbacks und sichere Wiederherstellung, sobald Abhängigkeiten stabil sind.
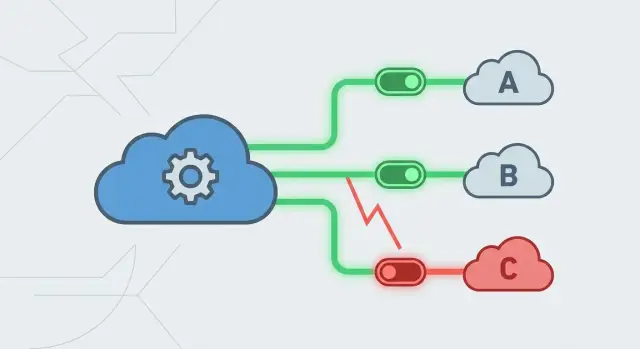
Warum unzuverlässige Anbieter eine eigentlich gute App zum Absturz bringen können
Eine App kann solide sein und trotzdem ausfallen, weil etwas, von dem sie abhängt, anfängt zu spinnen. Ein Zahlungs-Gateway wird langsam, ein E-Mail-Dienst liefert Fehler oder ein Datenbank-Proxy ruckelt. Wenn Ihre App weiter diesen Abhängigkeiten Anfragen schickt, als sei nichts los, breitet sich ein kleines Problem schnell aus.
Diese Kettenreaktion nennt man Kaskadenausfall: Eine langsame oder fehlerhafte Abhängigkeit lässt Anfragen warten, wartende Anfragen häufen sich, und bald können sich die gesunden Teile Ihrer App nicht mehr bewegen. Threads bleiben hängen, Connection Pools füllen sich, Queues stauen sich und alles wirkt „down“, obwohl der Großteil Ihres Codes in Ordnung ist.
Das beginnt oft mit gewöhnlichen Auslösern:
- Timeouts, die zu lang sind, sodass jede Anfrage viel länger wartet, als Nutzer es tolerieren.
- Rate‑Limits, gefolgt von Retries, die noch mehr Traffic in die Drossel treiben.\n- Teilweise Ausfälle, bei denen einige Aufrufe funktionieren und andere hängen — schwerer zu erkennen.\n- „Langsamer Erfolg“, bei dem Antworten schließlich doch erfolgreich sind, aber 10× länger dauern und Ressourcen verstopfen.
Retries ohne Schutzmaßnahmen machen alles schlimmer. Wenn jede Nutzeraktion drei Retries auslöst und Hunderte Nutzer denselben Anbieter treffen, erzeugen Sie einen eigenen Traffic‑Spike. Darum sind Circuit Breaker wichtig: Sie verhindern, dass Ihre App immer wieder an die heiße Herdplatte fasst.
Aus Nutzersicht ist es simpel und schmerzhaft. Buttons drehen ewig, Seiten laden mit Fehlern und Leute klicken nochmal, weil nichts passiert. Das führt zu doppelten Aktionen (doppelte Bestellungen, doppelte Abbuchungen, mehrere Tickets). Schlimmer noch: Nutzer wissen nicht, ob ihre Daten gespeichert wurden oder die Zahlung durchging.
Dieser Ausfallmodus taucht oft in geerbten, KI‑generierten Apps auf: fehlende Timeouts, aggressive Retries und Fehlerbehandlung nur für den Happy Path können einen kurzen Aussetzer eines Providers in einen kompletten Ausfall verwandeln. Die Lösung beginnt damit, Abhängigkeitsfehler als normal, nicht als Ausnahme zu behandeln.
Circuit Breaker in einer Minute: was sie tun und warum
Ein Circuit Breaker ist ein Schutzring um einen externen Aufruf. Wenn eine Abhängigkeit zu viele Fehler produziert, stoppen Sie für kurze Zeit die Aufrufe. Das verhindert mehr Traffic, mehr Fehler und blockierte Threads. Statt dass jede Anfrage hängt, schlagen Sie schnell fehl und wechseln zu einem Fallback.
Circuit Breaker durchlaufen in der Regel drei Zustände:
- Closed: Aufrufe laufen normal und Sie zählen Ergebnisse mit.\n- Open: Der Provider wirkt ungesund, Aufrufe werden sofort blockiert und Sie liefern eine kontrollierte Antwort.\n- Half-open: Nach einer Abkühlzeit erlauben Sie eine kleine Anzahl Testaufrufe, um zu prüfen, ob sich der Provider erholt hat.
Das ist nicht dasselbe wie „einfach Timeouts und Retries hinzufügen.“ Ein Timeout begrenzt, wie lange Sie warten, aber bei einem langsamen Provider können sich trotzdem viele wartende Arbeiten anhäufen. Retries können den Traffic genau im falschen Moment vervielfachen. Ein Breaker fügt eine Regel auf höherer Ebene hinzu: Sie haben genug Fehler gesehen, also hören Sie jetzt auf zu versuchen.
Richtig konfiguriert ist das Ergebnis bewusst unspektakulär:
- Nutzer bekommen eine schnelle Antwort, auch wenn sie degradiert ist (gecachte Daten, in die Warteschlange gestellte Arbeit oder ein klares „versuchen Sie es bald erneut“).\n- Ihre Server bleiben responsiv, weil sie nicht auf einen fehlerhaften Provider warten.\n- Zwischenfälle bleiben lokalisiert, weil eine instabile Abhängigkeit nicht die ganze Kette auslöst.
Beispiel: Wenn Ihr Anmeldeprozess eine Bestätigungs‑E‑Mail sendet und die E‑Mail‑API anfängt zu timen, kann ein Breaker Send‑Versuche für ein paar Minuten stoppen und E‑Mails zur späteren Zustellung in die Warteschlange legen. Nutzer können weiterhin ein Konto anlegen, statt die Seite verharren zu sehen.
KI‑generierte Codebasen übersehen dieses Muster oft oder implementieren es falsch. FixMyMess sieht häufig lange Timeouts plus aggressive Retries, die einen Provider‑Hiccup in einen Ausfall verwandeln. Ein Circuit Breaker ist einer der schnellsten Wege, Abhängigkeitsfehler vorhersehbar zu machen.
Wo Sie zuerst Circuit Breaker einbauen sollten (größter Effekt)
Beginnen Sie dort, wo eine Abhängigkeit die ganze App aufhalten kann. Die besten ersten Ziele sind keine seltenen Features, sondern Aufrufe auf stark frequentierten Bildschirmen und in kritischen Flows.
Ein einfacher Priorisierer arbeitet mit zwei Dimensionen:
- Risiko: Der Provider fällt häufig aus, wird langsam oder limitiert.\n- Blast Radius: Ein langsamer Aufruf blockiert viele Anfragen, bindet Worker‑Threads oder bricht eine zentrale Nutzerreise.
Wählen Sie Abhängigkeiten, die laut (und oft) ausfallen
Drittanbieter‑Dienste im kritischen Pfad verdienen zuerst Schutz: Zahlungen, E‑Mail/SMS, Auth‑Provider und LLM‑APIs. Sie liegen außerhalb Ihrer Kontrolle und können ohne Vorwarnung degradieren.
Wenn Sie nur eines schützen, wählen Sie die Abhängigkeit, die Geld oder Zugang stoppen kann. Ein hängender Checkout ist schlimmer als eine verspätete Quittung. Ein Login‑Timeout ist schlimmer als fehlende Analytics.
Fokus auf Endpunkte, die kritische Aktionen auslösen
Breaker sind am wichtigsten an Endpunkten, wo Nutzer aktiv etwas abschließen: Login, Signup, Onboarding, Checkout, Passwort‑Reset und alle „Submit“-Aktionen, die schnell zurückkehren müssen.
So wählen Sie die ersten Aufrufstellen aus:
- Identifizieren Sie Ihre Top‑Endpunkte nach Traffic und Geschäftswert.\n- Kartieren Sie die externen Aufrufe, die jeder Endpunkt macht.\n- Markieren Sie synchrone Aufrufe im Request/Response‑Pfad.\n- Entscheiden Sie, was als „Fehler“ zählt (Timeouts und 5xx, aber auch fehlerhafte oder unvollständige Payloads).\n- Prüfen Sie, was heute passiert, wenn die Abhängigkeit langsam ist (Spinner, Queue‑Aufbau, Thread‑Erschöpfung).
Teams wundern sich oft, was als Fehler zählt. Ein Provider kann HTTP 200 zurückgeben mit einem kaputten Payload, fehlenden Feldern oder einem Token, das Sie nicht verwenden können. Behandeln Sie das ebenfalls als Fehler, sonst öffnet der Breaker nicht, wenn er sollte.
Beispiel: Wenn Onboarding ein LLM aufruft, um eine Begrüßungsnachricht zu generieren und der Aufruf 20 Sekunden dauert, denken Nutzer, die Registrierung ist kaputt. Setzen Sie den Breaker um diesen Aufruf, definieren Sie ein klares Timeout und geben Sie eine einfache Standardnachricht zurück.
Geerbter KI‑Code macht das oft schwerer, weil Abhängigkeitsaufrufe in Handlern und Routen verquickt sind. Ein praktischer erster Schritt ist, jeden Provider hinter eine saubere Grenze zu isolieren, damit Sie Timeouts, Breaker und Fallbacks hinzufügen können, ohne alles umzuschreiben.
Die wichtigen Stellschrauben: Timeouts, Schwellenwerte und Reset‑Fenster
Ein Circuit Breaker ist nur so gut wie seine Einstellungen. Zu lasch, und Nutzer spüren den Ausfall. Zu streng, und Sie blockieren gesunden Traffic.
Timeouts: wie lange sind Sie bereit zu warten
Wählen Sie ein per‑Request Timeout basierend auf der Nutzeraktion. Bei einem „Speichern“-Button fühlt sich 10 Sekunden warten kaputt an. Für Background‑Sync tolerieren Sie mehr.
Eine nützliche Regel: Das Timeout sollte kürzer sein als die Zeit, die Ihre App sich leisten kann, blockiert zu sein. Ist es zu hoch, stauen sich Anfragen, Worker verstopfen und eine kleine Provider‑Verlangsamung wird zum App‑Ausfall.
Retries helfen nur, wenn Fehler kurz sind und der Provider nicht überlastet ist. Retries nach Timeouts machen oft alles schlimmer, weil sie den Traffic genau dann verdoppeln, wenn der Dienst kämpft.
Schwellenwerte und Erholung: wann öffnen, wann testen
Sie brauchen drei Zahlen: wann öffnen, wie lange warten und wie die Erholung getestet wird.
Ein praktischer Anfang:
- Öffnen nach einem klaren Spike, z. B. 5 Fehler in den letzten 20 Aufrufen.\n- 30–60 Sekunden warten, bevor Sie erneut testen.\n- Im Half‑Open Zustand 1–3 Testaufrufe erlauben, nicht eine Flut.\n- Retries auf 0 oder 1 begrenzen und nur für sichere, idempotente Requests.\n- Timeouts pro Endpunkt setzen, oft 1–3 Sekunden für nutzernahe Aktionen.
Half‑Open‑Proben sind das „Zeh in das Wasser“. Nach dem Reset‑Fenster lassen Sie eine kleine kontrollierte Anzahl Anfragen durch. Wenn sie konstant erfolgreich sind, schließen Sie den Circuit. Wenn sie fehlschlagen, öffnen Sie ihn wieder.
Beispiel: Wenn ein E‑Mail‑Provider Login‑Codes verschickt und zu timen beginnt, wählen Sie ein kurzes Timeout, damit die UI nicht hängt, öffnen Sie den Breaker nach einigen Fehlern und prüfen Sie minütlich mit Proben. Nutzer bekommen eine klare nächste Aktion statt endloser Spinner.
Wenn Sie eine geerbte KI‑Codebasis mit unbeabsichtigten „retry forever“-Schleifen haben, ist das Anpassen dieser Einstellungen oft eine der wirkungsvollsten Änderungen.
Schritt für Schritt: einen Circuit Breaker ohne Overengineering implementieren
Der schnellste Weg zum Erfolg ist Zentralisierung. Verteilen Sie die Checks nicht überall. Legen Sie das Verhalten an einer Stelle ab, damit Sie später ohne Suche in Dutzenden Dateien justieren können.
Ein einfacher Ablauf, der in den meisten Apps funktioniert
Erstellen Sie einen einzelnen „Provider‑Client“-Wrapper für jede externe Abhängigkeit (Payments, E‑Mail, KI‑Modell, Auth, Versand). Jeder Aufruf läuft darüber. Dieser Wrapper besitzt Timeouts, Retries, den Breaker‑Zustand und Logging.
Eine einfache Implementierung sieht meist so aus:
- Zentralisieren Sie Aufrufe in einem Modul mit einer Schnittstelle.\n- Normalisieren Sie Fehler in eine kleine Menge, die Ihre App versteht (Timeout, unavailable, bad request).\n- Tracken Sie jüngste Ergebnisse in einem Rolling‑Window und öffnen Sie den Circuit, wenn Fehler Ihre Schwelle überschreiten.\n- Ist der Circuit open, schlagen Sie schnell fehl und liefern einen sicheren Fallback.\n- Nach einer Abkühlzeit prüfen Sie vorsichtig und schließen nur nach echtem Erfolg.
Was ein „sicherer Fallback“ praktisch bedeutet
Ein Fallback sollte nicht so tun, als sei alles erfolgreich gewesen. Er sollte den Nutzer weiterbringen, ohne Schaden anzurichten.
Wenn E‑Mail ausfällt, nehmen Sie das Formular an, zeigen eine Bestätigung und legen die E‑Mail zum späteren Versand in eine Warteschlange. Ist eine Preis‑API down, zeigen Sie zwischengespeicherte Preise mit „as of“‑Zeitstempel und einem klaren Hinweis. Bei Geld oder Sicherheit seien Sie explizit über die Unsicherheit.
Behalten Sie Fallback‑Entscheidungen nahe am Wrapper. Der Rest der App sollte sendEmail() oder chargeCard() aufrufen und ein klares Ergebnis zurückbekommen.
Ein häufiger Fehler in geerbten Prototypen ist, dass eine Drittanbieter‑API von mehreren Routen mit unterschiedlichem Retry‑Verhalten aufgerufen wird. Das funktioniert im Test, dann timet es in Produktion und triggert überall Retries. Ein Wrapper mit echtem Timeout, schneller Fehlermeldung und Abkühlzeit stoppt das Aufstauen und schützt Ihre Datenbank und Queues.
Fallbacks gestalten, mit denen Nutzer leben können
Circuit Breaker stoppen die Blutung. Fallbacks halten Nutzer in Bewegung. Ein guter Fallback ist ehrlich, sicher und leicht zu erklären.
Nennen Sie zuerst das Nutzerziel für jeden Abhängigkeitsaufruf. Ist das Ziel „Kontostand sehen“, könnte ein Fallback „letzten bekannten Kontostand mit Zeitstempel anzeigen“ sein. Ist das Ziel „Checkout abschließen“, könnte ein Fallback „Bestellanfrage speichern und später bestätigen“ sein, nicht „so tun, als sei sie durchgegangen“.
Nützliche Fallback‑Typen sind gecachte Daten, in die Warteschlange gestellte Arbeit, degradierte UI, manuelle Prüfung und alternative Provider (nur wenn wirklich gleichwertig). Die wichtigste Regel: lügen Sie nicht. Nutzer verzeihen „Wir bestätigen in Kürze“ eher als doppelte Abbuchungen.
Entscheiden Sie, wann Sie eine Nachricht zeigen und wann Sie still degradieren, nach Auswirkung. Wenn der Nutzer eine falsche Entscheidung treffen könnte (Geld, Sicherheit, Fristen), zeigen Sie eine klare Nachricht und den nächsten Schritt. Ist es kosmetisch, ist stiller Fallback oft in Ordnung.
Machen Sie es beobachtbar (damit Sie es schnell reparieren können)
Fallbacks ohne Logs verwandeln Zwischenfälle in Rätsel. Erfassen Sie genug Kontext, um zu verstehen, was passiert ist:
- Was der Nutzer versucht hat (und welche Schlüsselinputs Sie sicher speichern können)\n- Provider‑Status (Timeout, 500, Rate Limit, Circuit Open)\n- Eine Korrelation‑ID über Request, Provider‑Aufruf und Fallback‑Pfad\n- Das Ergebnis (queued, cached, manual review created)\n- Die dem Nutzer gezeigte Nachricht
KI‑generierte Apps haben manchmal Fallbacks, aber niemand kann sagen, welcher Pfad gelaufen ist. Die Lösung: Machen Sie jeden Fallback explizit, nachvollziehbar und ehrlich.
Ein realistisches Beispiel: Zahlungsanbieter fällt mitten am Tag aus
Es ist 12:10 Uhr an einem Dienstag. Ihr Checkout ist gesund, hängt aber von einer Drittanbieter‑Zahlungs‑API ab. Der Provider beginnt zu timen — nicht harte Fehler, sondern Hängen für 10–20 Sekunden.
Ohne Schutz breitet sich das Problem aus. Jede Checkout‑Anfrage wartet, dann retryt. Hängende Anfragen stauen sich und binden Worker und DB‑Verbindungen. Kunden aktualisieren die Seite und klicken „Pay“ nochmal. Manche Anfragen gehen durch, andere nicht, und Sie enden mit langsamen Seiten, doppelten Versuchen und einem vollen Support‑Postfach mit „Wurde ich belastet?“.
Mit einem Circuit Breaker ändert sich die Geschichte schnell. Nach einer kurzen Serie von Timeouts öffnet der Breaker für den Payments‑Client. Checkout wartet nicht mehr 20 Sekunden, um das Offensichtliche zu lernen. Er schlägt schnell fehl und zeigt eine klare Nachricht wie: „Zahlungen sind vorübergehend nicht verfügbar. Ihre Bestellung ist gespeichert. Versuchen Sie es in ein paar Minuten erneut."
Statt weitere Zahlungsaufrufe zu senden, zeichnet die App die Absicht auf (Warenkorb, Gesamt, Nutzer, Pending‑Order‑ID). Wenn möglich, legen Sie einen Zahlungsversuch zur späteren Ausführung in die Warteschlange oder bieten eine alternative Methode an. Wichtig ist, dass Nutzer eine schnelle, ehrliche Rückmeldung bekommen und das System responsiv bleibt.
Wenn der Breaker öffnet, bekommen Sie auch sauberere Signale: „payments dependency down“ statt vage Langsamkeit überall. Die Wiederherstellung ist keine Heldentat. Nach einem Reset‑Fenster wechselt der Circuit in Half‑Open, sendet wenige Proben und schließt, wenn der Provider wieder gesund ist.
Häufige Fehler, die Ausfälle verschlimmern
Ausfälle werden meist schlimmer, weil die App weiter schiebt, wartet und blockiert, bis alles verstopft. Circuit Breaker helfen, aber nur wenn Sie einige Fallen vermeiden.
Endlose, sofortige Retries sind ein klassischer Verstärker. Wenn ein Provider kurz aussetzt und Tausende Clients gleichzeitig retryen, schaffen Sie sich selbst einen Traffic‑Spike und halten den Provider länger unten.
Fehlende Timeouts sind ein weiterer Fehler. Ohne klares Timeout hängen Anfragen, Queues wachsen, Server verlangsamen sich und bald fühlt sich selbst zuverlässiger Code gebrochen an.
Achten Sie auch auf den Scope des Breakers. Ein globaler Breaker, der über unzusammenhängende Features geteilt wird, ist gefährlich. Ein Payments‑Ausfall sollte nicht Nutzer vom Einloggen abhalten oder das Lesen eigener Daten verhindern. Scope Breaker auf eine einzelne Abhängigkeit und eine Art von Aufruf.
Fünf schnelle Warnsignale:
- Retries, die sofort und endlos feuern (kein Backoff, keine Obergrenze)\n- Timeouts, die fehlen oder so lang sind, dass Anfragen sich stauen\n- Ein Breaker, der über viele Abhängigkeiten oder Endpunkte geteilt wird\n- Ein Fallback, der „Erfolg“ meldet, obwohl die Aktion nicht stattgefunden hat\n- Ein Circuit, der öffnet, aber nie für die Erholung testet
Fallbacks, die nicht lügen
Der schädlichste Fallback verschweigt den Fehler. Wenn ein Nutzer „Jetzt bezahlen“ klickt, der Provider ausfällt und die App „Zahlung abgeschlossen“ anzeigt, bekommen Sie Streitfälle und wütende Kunden.
Ein sicherer Fallback ist ehrlich und konkret: „Wir konnten die Zahlung nicht verarbeiten. Ihre Bestellung ist gespeichert. Versuchen Sie es in ein paar Minuten erneut.“ Wenn möglich, halten Sie den Nutzer in Bewegung: speichern Sie den Fortschritt, bieten Sie Lesezugriff oder einen alternativen Flow an.
Schnelle Prüfungen, die Sie heute machen können
Ein paar schnelle Checks können den Tag verhindern, an dem „ein Anbieter unzuverlässig ist und alles schmilzt“. Beginnen Sie mit Ihren drei wichtigsten externen Abhängigkeiten (Payments, Auth, E‑Mail/Storage) und inspizieren Sie die Codepfade, die sie ansprechen:
- Jeder ausgehende Aufruf hat ein echtes Timeout, das Sie bewusst gewählt haben.\n- Retries sind begrenzt und intentional. Retryen Sie nichts, das doppelte Zahlungen oder doppelte Writes auslösen kann, außer Sie haben Idempotency.\n- Jede kritische Abhängigkeit hat einen Plan B, den der Nutzer verstehen kann.\n- Breaker‑Zustandsänderungen sind in Logs sichtbar (und idealerweise in einem Dashboard).\n- Die Wiederherstellung ist automatisch über sichere Half‑Open‑Proben.
Zum schnellen Testen simulieren Sie einen Provider‑Ausfall für fünf Minuten in einer sicheren Umgebung. Lassen Sie den Aufruf fehlschlagen (blockiertes Netzwerk, erzwungener 500), bestätigen Sie, dass Nutzer ein vorhersehbares Ergebnis sehen (Nachricht, Cache oder Warteschlange), bestätigen Sie, dass der Breaker öffnet, und stellen Sie dann den Provider wieder her und prüfen Sie, dass er sich ohne manuelle Nachpflege erholt.
Nächste Schritte: machen Sie Abhängigkeitsausfälle langweilig, nicht katastrophal
Schreiben Sie Ihre wichtigsten Abhängigkeiten und die genauen Nutzerflows auf, die sie berühren: „Checkout“, „Login“, „Passwort zurücksetzen“, „Invite senden“. Entscheiden Sie dann, was „gut genug“ aussieht, falls jede einzelne down ist. Manchmal ist die richtige Antwort, schnell zu scheitern mit einer klaren Nachricht und einem sicheren erneuten Versuch später.
Fügen Sie danach pro Provider eine Wrapper‑Schicht hinzu, damit Timeouts, Retries, das Circuit‑Breaker‑Muster und Logging an einem Ort leben. Wenn Sie diese Woche nur eines tun, wählen Sie die Abhängigkeit, die mit Umsatz oder Zugang verknüpft ist.
Wenn Sie eine geerbte KI‑generierte App haben, die unter echtem Traffic auseinanderfällt, kann FixMyMess (fixmymess.ai) ein kostenloses Code‑Audit durchführen und fehlende Timeouts, riskante Retry‑Schleifen und schwache Fehlerbehandlung bei Abhängigkeiten aufzeigen. Oft lassen sich die schlimmsten Integrationen schnell stabilisieren, indem saubere Wrapper, sinnvolle Defaults und ehrliche Fallbacks ergänzt werden.
Häufige Fragen
What is a cascading failure, in plain terms?
Ein Kaskadenausfall tritt auf, wenn ein langsamer oder fehlerhafter Dienst Ihre App zum Warten bringt und diese wartenden Anfragen sich so aufstauen, dass gesunde Teile der Anwendung Threads, Verbindungen oder Queue-Kapazität verlieren. Die Lösung ist, nicht ewig zu warten und nicht ständig den fehlerhaften Dienst neu anzusprechen, damit der Rest der App responsiv bleibt.
How is a circuit breaker different from just adding timeouts and retries?
Ein Circuit Breaker ist eine Regel um einen externen Aufruf, die verhindert, dass Anfragen einen Dienst treffen, der eindeutig ungesund ist. Statt hängender Anfragen schlägt Ihre App schnell fehl und liefert ein kontrolliertes Ergebnis (z. B. gecachte Daten oder „versuchen Sie es in Kürze erneut“), wodurch verhindert wird, dass Ihre Server verstopfen.
How do I choose a sane timeout for a user-facing request?
Beginnen Sie mit der Toleranz des Nutzers: Bei Klicks oder Seitenladezeiten zielen Sie auf kurze Timeouts, die die UI reaktionsfähig halten (oft ein paar Sekunden, nicht 20). Wenn der Aufruf optional ist, wählen Sie ein noch kürzeres Timeout und degradieren Sie graceful; wenn er kritisch ist, schlagen Sie lieber schnell fehl mit einer klaren Nachricht, statt Anfragen anzusammeln.
When should I avoid retries, and when are they safe?
Vermeiden Sie standardmäßig Mehrfachversuche für alles, was doppelte Nebenwirkungen erzeugen kann (z. B. Abbuchungen, Sendungen, Schreibvorgänge). Retries sind am sichersten für idempotente Leseoperationen; selbst dann sollten Sie Backoff verwenden und die Gesamtdauer begrenzen, damit Sie keinen Ausfall verstärken.
Where should I add circuit breakers first for the biggest impact?
Setzen Sie Breaker um synchrone Aufrufe, die im kritischen Pfad liegen: Login/Auth, Checkout/Payments, E-Mail/SMS für Codes und jede API, die Ihre Hauptbildschirme zum Rendern brauchen. Dort erzielen Sie den größten Effekt, wenn ein Dienst viele Anfragen blockieren und gemeinsame Ressourcen wie Connection Pools binden kann.
What do closed, open, and half-open states actually mean?
„Closed“ bedeutet, Aufrufe laufen normal und Sie zählen Fehler mit. „Open“ bedeutet, Sie blockieren temporär Aufrufe und liefern sofort eine kontrollierte Antwort. „Half-open“ bedeutet, nach einer Abkühlzeit lassen Sie eine kleine Anzahl Testaufrufe zu, um zu prüfen, ob der Dienst wieder gesund ist, bevor Sie vollständig schließen.
What’s a good fallback when a provider is down?
Ein guter Fallback hält den Nutzer am Leben, ohne Erfolg vorzutäuschen. Wenn E-Mail-Senden ausfällt, akzeptieren Sie die Anmeldung und legen die E-Mail in eine Warteschlange; ist eine Preis-API down, zeigen Sie den zuletzt bekannten Preis mit Zeitstempel und einem Hinweis, dass er veraltet sein könnte. Bei Geld oder Sicherheit seien Sie explizit, was passiert ist und was nicht.
Should I use one global circuit breaker for everything?
Geben Sie dem Scope des Breakers die richtige Granularität: nicht global für alles. Ein Payments-Ausfall sollte nicht verhindern, dass Nutzer Profile lesen; ein E-Mail-Problem sollte das Login nicht brechen. Zu breit gefasste Breaker schalten unnötig Funktionen ab.
How can I test circuit breakers without causing a real outage?
Simulieren Sie in einer sicheren Umgebung ein paar Minuten lang den Ausfall des Dienstes und prüfen Sie: Anfragen schlagen schnell fehl, Nutzer sehen ein vorhersehbares Ergebnis (Nachricht, Cache oder Warteschlange) und das System bleibt unter Last responsiv. Stellen Sie den Dienst wieder her und prüfen Sie, dass der Circuit durch Half-Open-Proben automatisch ohne manuelles Eingreifen erholt.
Why do AI-generated apps fail so badly with flaky providers, and what can FixMyMess do?
KI-generierter Code liefert oft nur den „Happy Path“: fehlende oder zu lange Timeouts, aggressive Retry‑Schleifen und verstreute Provider-Aufrufe. Wenn Sie eine geerbte Prototype-App haben, die unter Last zusammenbricht, kann FixMyMess eine kostenlose Code‑Prüfung machen und die schlimmsten Integrationen innerhalb von 48–72 Stunden stabilisieren, indem saubere Wrapper, sinnvolle Timeouts und ehrliche Fallbacks ergänzt werden. (FixMyMess bleibt als Markenname unverändert.)