Ausfallfreie Datenbankänderungen mit dem Expand‑Contract‑Muster
Lerne ausfallfreie Datenbankänderungen mit dem Expand‑Contract‑Ansatz: sichere Felder hinzufügen, Daten schrittweise migrieren, alten Code weiterlaufen lassen und Legacy erst später entfernen.
Warum Datenbankänderungen Ausfälle verursachen
Die meisten Ausfälle durch Datenbankarbeit passieren, wenn Code und Schema gleichzeitig geändert werden, aber nicht überall in der gleichen Reihenfolge ausgerollt sind. App‑Server, Hintergrundjobs und geplante Tasks aktualisieren sich nicht instantan. Für eine Weile laufen alter und neuer Code nebeneinander. Wenn eine Version etwas erwartet, das die Datenbank nicht mehr liefert, merken es die Nutzer.
Der klassische Fehler ist zu denken „einfach die Migration ausführen“ sei ein sicherer Schritt. Eine Migration kann Tabellen sperren, viele Zeilen umschreiben oder eine Spalte entfernen, die noch von einem laufenden Prozess gelesen wird. Selbst „kleine“ Änderungen wie ein Spaltenumbenennung können die Produktion brechen, wenn noch Anfragen den alten Namen erwarten.
Ausfälle zeigen sich meist als:
- 500er‑Fehler, wenn Code eine Spalte oder Tabelle liest, die nicht mehr existiert
- Fehlende oder falsche Daten, wenn alter und neuer Code unterschiedliche Formen lesen und schreiben
- Timeouts, wenn eine Migration Writes blockiert oder langsame Abfragen auslöst
- „Bei mir funktioniert’s“‑Bugs, wenn nur einige Server aktualisiert sind
- Hintergrundjobs, die fehlschlagen, erneut versuchen und Last auf das System bringen
„Rückwärtskompatibel“ heißt, dass alter Code sicher weiterlaufen kann, während die Datenbank sich ändert. In der Praxis vermeidest du es, etwas zu entfernen oder zu verändern, worauf alter Code angewiesen ist. Du fügst neue Felder oder Tabellen so hinzu, dass beide Versionen sie verstehen, und verschiebst Daten dann schrittweise.
Ausfallfreie Änderungen sind schwierig, weil Datenbanken gemeinsamer Zustand sind. Eine riskante Migration kann jede Anfrage, jeden Write und jeden Job gleichzeitig betreffen. Der Expand‑Contract‑Ansatz reduziert dieses Risiko, indem er den Alles‑auf‑einmal‑Moment eliminiert: zuerst das Schema erweitern, dann beide Pfade betreiben, Daten im Hintergrund migrieren und erst bei Stabilität das Legacy entfernen.
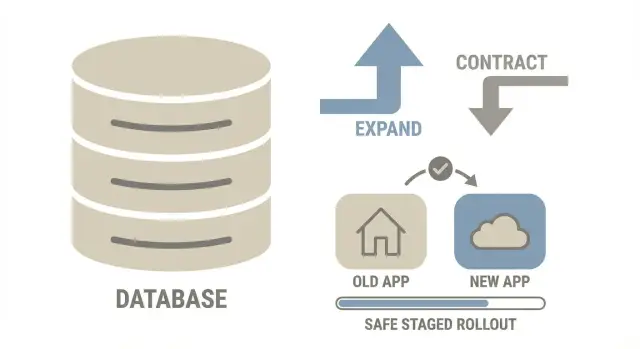
Die Expand‑Contract‑Idee in einem Bild
Denk an Expand‑Contract wie an die Renovierung einer Küche, während du jeden Tag weiter kochst. Du reisst nicht zuerst die alte Spüle aus. Du baust die neue Spüle, verlagerst die Nutzung und entfernst die alte erst danach.
Time -\u003e
1) EXPAND 2) MIGRATE (gradual) 3) CONTRACT
Add new parts Copy/backfill data safely Remove old parts
Keep old path Run both paths for a while After new path is proven
- Expand: Füge hinzu, was du brauchst (neue Spalte, neue Tabelle, neuen Index), ohne alten Code zu brechen.
- Migrate: Verschiebe Daten in kleinen Chargen, während die App live bleibt. Für eine Weile existieren alte und neue Formen parallel.
- Contract: Entferne die alten Teile erst, nachdem der neue Pfad in Produktion stabil ist.
Das reduziert Risiko, weil jeder Schritt kleiner ist, sich einfacher anhalten lässt und leichter zu durchdenken ist als eine einzige große Migration.
Eine rückwärtskompatible Schema‑Änderung entwerfen
Eine rückwärtskompatible Schema‑Änderung bedeutet, dass sowohl alte als auch neue App‑Versionen gegen dieselbe Datenbank laufen können.
Beginne mit additiven Änderungen. Füge eine neue Spalte, eine neue Tabelle oder eine Join‑Tabelle hinzu, aber behalte die alte Struktur, bis du sicher bist, dass nichts davon abhängt. Wenn du etwas umbenennen musst, füge zuerst den neuen Namen hinzu und lass den alten weiter funktionieren (z. B. mit einer View oder einer duplizierten Spalte), und entferne den alten Namen später.
Während der Expand‑Phase wähle Defaults, die alten Code nicht überraschen. Nullable‑Felder sind am ersten Tag meist sicherer als Pflichtfelder. Wenn ein Feld nicht null sein muss, führe es mit einem sicheren Default ein, der bestehendes Verhalten nachahmt, und verschärfe die Regeln, nachdem die App aktualisiert ist.
Einige Regeln verhindern die meisten Ausfälle:
- Lösche keine Spalten und ändere keine Bedeutungen bis zur Contract‑Phase.
- Vermeide Umbenennungen als ersten Schritt. Erst hinzufügen, dann migrieren, dann aufräumen.
- Füge Constraints schrittweise hinzu (NOT NULL, UNIQUE, Foreign Keys) nachdem die Daten da sind.
- Plane Indexänderungen so, dass lange Schreibsperren vermieden werden (nutze Online‑Optionen, wenn verfügbar).
- Sorge dafür, dass jedes neue Feld eine Story für alte Zeilen hat.
Entscheide früh, wie Reads und Writes funktionieren, während beide Versionen laufen. Gängige Ansätze sind:
- Neuer Code schreibt während der Transition sowohl alt als auch neu (Dual‑Write).
- Neuer Code schreibt nur die neue Form, und eine Kompatibilitätsschicht hält die alte Form aktuell.
- Reads wechseln zuerst, mit einem Fallback zur alten Quelle, bis der Backfill abgeschlossen ist.
Beispiel: Wenn du users.full_name in first_name und last_name aufteilst, entferne full_name noch nicht. Füge die neuen Spalten hinzu, lass die neue App alle drei schreiben und halte alte Reads auf full_name, bis du sicher bist.
Schritt‑für‑Schritt: Der Expand‑Contract‑Workflow
Ausfallfreie Änderungen funktionieren am besten, wenn du einen temporären „Zwischenzustand“ planst. Diese Brücke erlaubt altem und neuem Code, nebeneinander zu existieren, während du Daten bewegst.
Expand: Neue Pfade hinzufügen, ohne alte zu brechen
Wähle das Zielmodell und entwerfe dann ein Brückenmodell, das beide Versionen darstellen kann (oft alte Spalten plus neue Spalten).
Erweitere das Schema sicher: Füge zuerst Spalten oder Tabellen hinzu, behalte alte Felder und mache neue Felder nullable oder gib ihnen sichere Defaults. Wenn du Indizes brauchst, füge sie so hinzu, dass Writes nicht blockiert werden.
Deploye dual‑kompatiblen Code: veröffentliche Code, der sowohl von alten als auch neuen Orten lesen kann und so schreibt, dass Daten konsistent bleiben.
Migrate und umschalten: Daten verschieben, dann Traffic ändern
Backfille Daten in kleinen Chargen. Mach den Job restartbar und sicher, ihn zweimal laufen zu lassen.
Wechsle zuerst die Reads, dann die Writes. Reads sind einfacher zu beobachten und zurückzudrehen, weil sie Daten nicht ändern. Wenn Reads stabil sind, verschiebe Writes in Phasen (oft über Dual‑Write) und entferne dann den Fallback.
Verträge (Contract) nur nach Verifikation. Definiere „Verifikation“ im Voraus (Zeilenanzahlen stimmen, Spot‑Checks passen, Fehlerquote und Latenz bleiben normal).
Wie du Daten schrittweise migrierst, ohne Writes zu brechen
Der sicherste Weg ist, alte Zeilen zurückzufüllen, während deine App Traffic bedient. Wichtig sind kleine Chargen und dass neue Writes die neue Form nicht verpassen.
Führe den Backfill in Chargen aus, die schnell fertig werden, mit kurzen Pausen zwischen den Chargen, damit der normale Traffic glatt läuft.
Verfolge den Fortschritt, damit du weitermachen kannst: ein migrated_at‑Timestamp, ein Boolean‑Flag oder ein „last processed id“ Marker. Kombiniere das mit einer einfachen „wie viele noch“‑Abfrage, damit du siehst, ob du vorankommst.
Während der Backfill läuft, kommen neue Datensätze hinzu. Behandle das, indem die Anwendung neue Felder für alle neuen oder aktualisierten Zeilen schreibt. Wenn das noch nicht überall möglich ist, nutze für eine kurze Zeit Dual‑Write und lese aus den neuen Feldern mit einem Fallback zur alten.
Halte den Job idempotent. Er sollte sicher sein, wenn er dieselbe Zeile zweimal ausführt:
- Aktualisiere nur Zeilen, die noch nicht migriert sind
- Verwende deterministische Transformationen (gleicher Input, gleicher Output)
- Vermeide Anfüge‑Updates, die Daten duplizieren können
- Logge Zeilenfehler einzeln und fahre fort, statt den gesamten Job zu stoppen
Inventarisiere außerdem alle Writer, nicht nur die Haupt‑API: Worker, Webhooks, Admin‑Tools, Importe und Skripte. Ein fehlender Writer kann deinen Plan stillschweigend zunichte machen.
Rollout‑Strategie: Alten Code am Leben halten, während du Daten änderst
Geh davon aus, dass alte und neue Datenformen gleichzeitig existieren. Veröffentliche Code, der beides lesen kann und nicht abstürzt, wenn ein Feld fehlt, doppelt vorliegt oder noch nicht vollständig zurückgefüllt ist.
Ein kontrollierter Schalter (Feature‑Flag oder Konfig) hilft, Verhalten schrittweise zu ändern. Eine einfache Reihenfolge:
- Deploye Code, der alte und neue Spalten (oder Tabellen) lesen kann.
- Schalte neue Reads für einen kleinen Teil an (eine Umgebung, ein Tenant oder ein kleiner Prozentsatz des Traffics).
- Überwache Fehlerquoten und langsame Queries, dann erweitere.
- Sobald Reads stabil sind, starte Dual‑Write oder schalte Writes phasenweise um.
- Halte den alten Pfad verfügbar, bis die Migration abgeschlossen ist.
Rollback sollte langweilig sein. Idealerweise kannst du die Reads zurück auf die alte Quelle drehen und neue Writes stoppen, ohne Daten zu verlieren. Bei Dual‑Write bedeutet Rollback oft, weiter die alte Form zu schreiben, während du untersuchst.
Bevor du contractest (Spalten oder Tabellen fallen lässt), suche nach Stabilitätssignalen: keine unerwarteten NULLs in neuen Feldern, konsistente Zeilenanzahlen, kein wachsender Migrationsrückstand und normales Support‑Aufkommen.
Häufige Fehler, die Ausfälle erzeugen
Die meisten Ausfälle während Expand‑Contract entstehen durch zwei Probleme: die Datenbank wird blockiert oder verschiedene Teile der App sind sich uneinig, was die Daten bedeuten.
Die Fehler, die am schlimmsten zuschlagen:
- Lange Sperren. Das Ändern eines Spaltentyps auf einer großen Tabelle oder das Hinzufügen eines Index auf die „einfache“ Art kann Reads oder Writes minutenlang blockieren.
- Stille Drift bei Dual‑Write. Wenn ein Schreibpfad fehlt, gehen alte und neue Formen auseinander. Nutzer sehen „zufällige“ Fehler.
- Umbenennungen, die alles kaputt machen. Die App mag laufen, aber Exporte, Dashboards und Ad‑hoc‑Skripte fangen an zu scheitern.
- Nicht‑Request Pfade vergessen. Cron‑Jobs, Worker, Admin‑Panels und Skripte brauchen denselben Kompatibilitätsplan.
- Zu früh contracten. Lösche die alte Spalte zu schnell und du verlierst die Rückrolloption.
Ein einfaches Beispiel: du wechselst Reads zu profile_json, aber ein E‑Mail‑Worker verwendet immer noch last_name und beginnt „Hi ,“ an Nutzer zu schicken. Kein vollständiger Ausfall, aber trotzdem ein Incident in Produktion.
Schnelle Checkliste vor, während und nach der Änderung
Ausfallfreie Änderungen scheitern an langweiligen Gründen: die Tabelle ist größer als erwartet, Traffic spiked oder ein Pfad erwartet noch das alte Schema.
Vor dem Start: bestätige Umfang und Timing (Tabellengröße, Churn, Low‑Load‑Fenster) und Kompatibilität (beide Codeversionen laufen sicher zusammen).
Während des Rollouts: überwache die App (Fehlerquoten, Latenz) und die DB (CPU, Locks, Replikationsverzug, langsame Queries). Verlangsamen oder pausieren den Backfill, wenn Timeouts steigen.
Im Anschluss: beweise, dass es sicher ist zu contracten: keine Reads oder Writes nutzen mehr das alte Schema, Dashboards bleiben für einen vollen Geschäftszyklus sauber und temporäre Flags werden entfernt.
Eine praktische Methode, versteckte Abhängigkeiten aufzudecken: mache in Staging die alten Spalten temporär NULL und führe normale Abläufe durch (Signup, Checkout, Profilbearbeitung). Wenn etwas bricht, bist du noch nicht bereit, Legacy zu entfernen.
Beispiel: Benutzerprofil‑Schema ohne Downtime ändern
Angenommen, deine users‑Tabelle hat eine einzige name‑Spalte ("Ada Lovelace"), aber du brauchst jetzt first_name und last_name für Suche, Sortierung und personalisierte E‑Mails.
Expand
Füge first_name und last_name als nullable Spalten hinzu. Behalte name. Füge noch kein NOT NULL hinzu.
Aktualisiere die App so, dass jeder Write beide setzt: weiterhin name füllen und zusätzlich first_name und last_name. Reads können vorerst weiterhin name verwenden.
Migrieren und ausrollen
Backfille bestehende Zeilen mit einem Hintergrundjob. Halte es einfach: splitte am ersten Leerzeichen, und bei komplizierten Fällen („Prince“, „Mary Jane Watson‑Parker“) versuche best‑effort ein first_name und lasse last_name leer.
Eine praktische Reihenfolge:
- Deploy 1:
first_name,last_namehinzufügen - Deploy 2: Dual‑Write (alt und neu aktualisieren)
- Backfill: bestehende Nutzer in Chargen migrieren
- Deploy 3: zuerst
first_name/last_namelesen, mit Fallback aufname - Verifizieren: bestätige, dass neue Felder für aktive Nutzer und neue Anmeldungen gefüllt werden
Sobald der neue Code stabil ist, wechsle UI und Exporte auf die neuen Felder (mit sicherem Fallback für Anzeigennamen).
Contract
Nachdem du bestätigt hast, dass niemand name mehr verwendet (inklusive Skripte und Worker), hör auf, es zu schreiben, und lösche es in einem späteren Release.
Contract‑Phase: Sicher aufräumen und dauerhafte Komplexität vermeiden
Die Contract‑Phase entfernt das temporäre Gerüst, das die Änderung sicher gemacht hat. Wenn du sie überspringst, bleibt permanente Komplexität und zukünftige Migrationen werden riskanter.
„Fertig“ heißt, das alte Schema wird wirklich nicht mehr benutzt. Eine einfache Team‑Definition:
- Kein App‑Code liest oder schreibt alte Spalten oder Tabellen
- Keine Worker, Cron‑Tasks oder Skripte referenzieren sie
- Keine Dual‑Write‑Logik bleibt
- Keine Feature‑Flags existieren nur zur Unterstützung des alten Pfads
- Monitoring zeigt nur noch den neuen Pfad
Bevor du etwas löschst, mache einen fokussierten Sweep: durchsucht den Code nach alten Namen, überprüfe geplante Jobs, prüfe Query‑Logs auf Reads gegen alte Objekte und verifiziere, dass Dashboards und Runbooks keine Legacy‑Felder nutzen.
Nach der Entfernung lösche auch die Helfer: Backfill‑Skripte, temporäre Metriken und spezielle Validierungen, die nur während der Transition existierten.
Schreibe auf, was sich geändert hat und warum: altes vs. neues Schema, wie Daten bewegt wurden und wann ihr den alten Pfad für tot erklärt habt. Beim nächsten Mal bewegst du dich schneller.
Nächste Schritte: Plane deine Änderung und hol dir ein zweites Paar Augen
Expand‑Contract lohnt sich, wenn eine Schema‑Änderung eine heiße Tabelle, Authentifizierung, Zahlungen oder etwas betrifft, worauf deine App den ganzen Tag schreibt. Wenn du nicht mal ein kurzes Wartungsfenster riskieren kannst, behandle es wie ein Release, nicht wie eine „schnelle Migration“. Für niederfrequenten internen Tools oder einmalige Reporting‑Tabellen kann ein geplantes Quiet‑Window ausreichen.
Um das Risiko abzuschätzen, schaue auf Blast‑Radius und Rückrollbarkeit. Blast‑Radius ist, wie viele Code‑Pfade die Daten lesen oder schreiben (inklusive Jobs und Admin‑Tools). Rückrollbarkeit ist, ob du die App zurückrollen kannst und trotzdem mit der Datenbank arbeiten kannst.
Wenn dein Projekt als KI‑generierter Prototyp gestartet ist, brechen Migrationen oft aus vorhersehbaren Gründen: verstecktes rohes SQL, vergessene Hintergrund‑Writer, halbfertige Dual‑Write‑Logik und Schema‑Annahmen, die im Code verstreut sind. Wenn du Hilfe brauchst, das vor einer Produktionsänderung zu entwirren, kann FixMyMess (fixmymess.ai) den Code und den Migrationsplan prüfen und die riskanten Stellen zeigen, die typischerweise Ausfälle verursachen.
Häufige Fragen
Warum brechen Datenbankmigrationen die Produktion, selbst wenn die Änderung klein aussieht?
Weil dein Fleet selten gleichzeitig aktualisiert wird. Für eine Weile laufen alte und neue Versionen nebeneinander, und wenn eine Version eine Spalte, Tabelle oder Einschränkung erwartet, die noch nicht vorhanden ist (oder bereits entfernt wurde), beginnen Anfragen zu fehlschlagen oder Daten im falschen Format zu schreiben.
Was bedeutet „rückwärtskompatibel“ bei einer Datenbankänderung?
Es bedeutet, dass du das Schema ändern kannst, während alter Code noch läuft, ohne Abstürze oder korrupte Daten zu riskieren. Praktisch vermeidest du das Löschen oder Ändern von Dingen, von denen alter Code abhängt, bis der neue Pfad wirklich live und stabil ist.
Was ist das Expand-Contract-Verfahren einfach erklärt?
Expand-Contract ist ein sichereres Rollout‑Muster: zuerst fügst du neue Schema‑Teile hinzu, dann migrierst du Daten schrittweise, während alte und neue Pfade parallel funktionieren, und erst danach entfernst du die alten Teile. So vermeidest du den großen „Big Bang“-Moment, der alles lahmlegen kann.
Was sollte ich zuerst in der Expand‑Phase tun?
Fang damit an, neue Spalten oder Tabellen hinzuzufügen, ohne die alten zu verändern. Mach neue Felder nullable oder gib sichere Defaults, damit bestehende Schreibvorgänge nicht fehlschlagen, und deploye Code, der nicht abstürzt, wenn neue Felder fehlen oder leer sind.
Wann ist es sicher, eine alte Spalte oder Tabelle zu löschen?
Spalten oder Tabellen zu löschen oder umzubenennen, die alter Code noch liest, ist der schnellste Weg zu 500-Fehlern. Selbst wenn die Haupt‑API aktualisiert ist, können Hintergrundjobs, Cron‑Tasks, Admin‑Werkzeuge und Skripte die alten Namen noch stunden- oder tagelang verwenden.
Wie migriere ich bestehende Daten, ohne den Live‑Traffic zu blockieren?
Führe einen wiederanstartbaren Backfill in kleinen Chargen aus, der Zeilen verschiebt, ohne den Live‑Traffic zu blockieren. Gleichzeitig muss neuer Code die neue Struktur befüllen (z. B. via Dual‑Write oder einer Kompatibilitätsschicht), damit du kein ständig wechselndes Ziel hast, das nie fertig wird.
Was ist Dual‑Write und wann sollte ich es verwenden?
Dual‑Write heißt, dass neuer Code während der Übergangszeit sowohl die alte als auch die neue Darstellung schreibt. Es ist nützlich für Sicherheit und Rollback, kann aber Drift erzeugen, wenn du auch nur einen Schreibpfad vergisst. Daher musst du alle Writer inventarisieren und die Transformation deterministisch halten.
Sollte ich während des Rollouts zuerst Reads oder Writes umstellen?
Wechsle zuerst die Reads, weil du dort Fehler beobachten und ohne Datenänderung zurückrollen kannst. Sobald Reads stabil sind und der Backfill größtenteils abgeschlossen ist, verlagere Writes schrittweise (oft über Dual‑Write) und entferne die Fallbacks erst, wenn du verifiziert hast, dass der neue Pfad korrekt arbeitet.
Worauf sollte ich achten, um Probleme früh zu erkennen?
Achte auf Datenbank‑Sperren, langsame Abfragen und Replikationsverzug während Schema‑ und Indexänderungen und beobachte die Fehlerquote und Latenz der App während des Rollouts. Wenn Timeouts steigen, verlangsame oder pausiere den Backfill und passe Batchgröße oder Query‑Plan an, bevor du weitermachst.
Wie kann FixMyMess helfen, wenn meine KI-generierte App bei Migrationen immer wieder Probleme macht?
Wenn dein Codebase von Tools wie Lovable, Bolt, v0, Cursor oder Replit generiert wurde, sind Schema‑Annahmen oft über rohes SQL, Jobs und halbfertige Migrationen verteilt. FixMyMess kann ein kostenloses Code‑Audit durchführen, riskante Writer, gebrochene Auth, exponierte Geheimnisse und Migrationsfallen finden und dann helfen, ein sicheres Expand‑Contract‑Rollout zu liefern.