Erschöpfung des Datenbank-Verbindungspools: Tuning für Serverless
Erfahren Sie, warum der Datenbank-Verbindungs-Pool auch bei geringem Traffic erschöpfen kann und wie Sie Pooling für Serverless vs. lang laufende Server einstellen, um Ausfälle zu vermeiden.
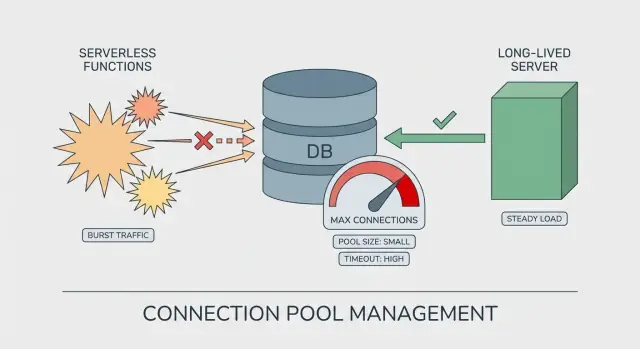
Wie sich eine Erschöpfung des Verbindungspools in Produktion zeigt
Erschöpfung des Verbindungspools heißt, dass Ihre App keine Datenbankverbindung bekommt, wenn sie eine braucht. Anfragen stauen sich, die App wartet und bricht dann nach einem Timeout ab. Für Benutzer sieht es so aus, als würde die Seite zufällig ausfallen.
Die meisten Teams bemerken es zuerst als „alles ist langsam“, obwohl CPU und Traffic normal aussehen. Seiten, die normalerweise in einer Sekunde laden, hängen 10 bis 30 Sekunden und schlagen dann fehl. Häufig trifft es sensible Abläufe zuerst: Login, Checkout, Formularspeicherung.
Benutzernahe Symptome sehen oft so aus:
- Seiten sind langsam und funktionieren nach einem Refresh manchmal wieder
- Zufällige 500-Fehler, die verschwinden und dann zurückkommen
- Logins schlagen fehl oder Sessions brechen ab
- Hintergrundjobs machen keinen Fortschritt mehr
- Mobile Apps timeouts bei einfachen Aktionen
Auf der Engineering-Seite ist das Muster spezifischer: Request-Queues wachsen, mehr Zeit wird mit Warten auf die Datenbank verbracht und Logs zeigen Fehler wie „timeout acquiring connection“. Auf der Datenbankseite können aktive Verbindungen nahe dem Limit sitzen oder kurzzeitig spikes zeigen.
Das Konfuse ist die Diskrepanz: der Traffic kann „leicht“ aussehen, während das System festhängt und wartet.
Eine häufige Ursache ist, dass wenige Anfragen Verbindungen länger halten als erwartet. Eine langsame Abfrage, eine offene Transaktion oder Code, der vergisst, einen Client freizugeben, kann den Pool blockieren. Danach können schon ein paar Benutzer einen Mini-Stau auslösen.
Warum das auch bei leichtem Traffic passiert
„Online-Benutzer“ ist nicht dasselbe wie „aktive DB-Verbindungen“. Die meisten Datenbanken erlauben weniger gleichzeitige Verbindungen, als man annimmt, und jede Verbindung kostet Speicher und CPU.
Bei Postgres ist max_connections oft konservativ gesetzt. Selbst ein Limit von 100 kann in der Praxis zu wenig sein, wenn jede Verbindung schwer ist. Admin-Tools, Hintergrundarbeiter, Migrationsskripte und Einmalskripte addieren sich, und so sind Verbindungen schneller verbraucht als gedacht.
Außerdem kann eine einzelne Anfrage die Datenbank mehrfach berühren: die Hauptabfrage, ein Analytics-Write, ein Session-Update und eventuell das Enqueue eines Jobs. Wenn das nicht sorgfältig gemanagt wird, erzeugt „leichter“ Traffic trotzdem viel gleichzeitige Arbeit.
Pool-Erschöpfung resultiert meist aus einem oder mehreren der folgenden Gründe:
- Verlorene Verbindungen nach Fehlern oder Timeouts, die nie in den Pool zurückkehren
- Langsame Abfragen, die Verbindungen länger halten und andere Anfragen in die Warteschlange zwingen
- Retries, die den Traffic multiplizieren (Client-Retries, Server-Retries, ORM-Retries)
- Hintergrundrauschen wie Bots, Cron-Jobs, Health-Checks, Queue-Polling
- Startaufgaben oder Migrationen, die zur ungünstigsten Zeit zusätzliche Verbindungen öffnen
Ein konkretes Beispiel: Sie haben 10 Benutzer, aber ein Endpoint läuft manchmal 4 Sekunden. Mit einem Pool von 10 kann ein kleiner Burst (durch Refreshes, Retries oder einen Bot) jede Verbindung belegen. Neue Anfragen warten, treffen auf das Pool-Timeout, schlagen fehl, retryen und verschlimmern den Spike.
Ausfälle bei „leichtem Traffic“ betreffen meist Verbindungslebenszeit und Gleichzeitigkeit, nicht die rohe Anzahl an Requests.
Serverless vs. lang laufende Server: der Unterschied beim Pooling
Bei einem lang laufenden Server (VM, Container, klassischer App-Server) bleibt der Prozess Stunden oder Tage aktiv. Der Datenbank-Pool wird über viele Anfragen wiederverwendet. Er „wärmt auf“, pendelt sich ein und man kann abschätzen, wie viele Verbindungen sich zu einem Zeitpunkt im Einsatz befinden.
Serverless ist anders. Ihr Code kann in vielen kurzlebigen Instanzen laufen. Jede Instanz kann ihren eigenen Pool eröffnen, selbst wenn sie nur wenige Anfragen bearbeitet. So zeigt sich Pool-Erschöpfung bei scheinbar leichtem Traffic: der Traffic verteilt sich auf mehr Instanzen als erwartet.
Warum Serverless Verbindungen multipliziert
Der Sprung kommt meist von Cold Starts und Skalierungsereignissen. Wenn die Plattform mehr Parallelität will, startet sie mehr Instanzen, und jede Instanz kann ihre eigenen DB-Verbindungen öffnen.
Eine Pool-Größe, die auf einem Server sicher erscheint, kann in Serverless riskant sein:
- Lang laufender Server: 1 Instanz x Pool 20 = ~20 Verbindungen
- Serverless-Burst: 30 Instanzen x Pool 20 = ~600 Verbindungen
Selbst wenn dieser Burst kurz ist, kann es ausreichen, Postgres-Limits, langsame Queries und Timeouts zu erreichen.
Eine einfache Denkweise
Auf lang laufenden Servern tun Sie das Pooling fürs wiederholte Nutzen und Durchsatz. In Serverless stellen Sie das Tuning auf Blast-Radius um: gehen Sie davon aus, dass viele Kopien Ihrer App gleichzeitig laufen können.
Zahlen, die Sie sammeln sollten, bevor Sie Einstellungen ändern
Raten führt oft dazu, dass kleine Probleme zu Produktionsvorfällen werden. Bevor Sie etwas anpassen, sammeln Sie ein paar Zahlen, damit Sie wissen, ob Ihnen Verbindungen fehlen, sie zu lange gehalten werden oder beides.
Starten Sie mit dem Datenbank-Limit. Finden Sie Postgres max_connections, und listen Sie auf, wer diese Verbindungen nutzt: Ihre App, Admin-Tools, Background-Jobs, Migrationen, BI-Tools, Read-Replicas. Viele Teams denken, sie hätten „100 Verbindungen“, obwohl 30 schon belegt sind.
Konzentrieren Sie sich dann auf Gleichzeitigkeit, nicht auf Tages- oder Nutzerzahlen. Eine Seite mit 200 Nutzern am Tag kann trotzdem auf 20 gleichzeitige Requests spike’n, wenn eine Seite mehrere API-Calls auslöst oder ein paar Leute gleichzeitig refreshen. Schauen Sie sich die Spitze der gleichzeitigen Requests in Ihren intensivsten 5–15 Minuten an und brechen Sie sie nach Instanz (oder Funktion bei Serverless) runter.
Die Abfragegeschwindigkeit ist genauso wichtig wie die Verbindungsanzahl. Ziehen Sie langsame Queries nach Gesamtzeit und nach p95/p99-Latenz. Ein paar 2–5 Sekunden-Abfragen können Verbindungen lange genug blockieren, um alles andere zu blockieren.
Signale, die meist „plötzliche“ Ausfälle erklären:
- Offen stehende Verbindungen vs. Postgres-Limit und wie schnell sie wachsen
- Wartezeit auf Verbindungen (Zeit, die auf eine freie Verbindung gewartet wird)
- Pool-Timeouts und Fehlerbursts (Frequenz und Zeitstempel)
- Request-Gleichzeitigkeit zum Zeitpunkt, an dem Fehler beginnen
- Ob Hintergrundarbeiter dieselbe DB und denselben Pool teilen
Ein schneller Realitätscheck: Wenn Ihr Pool-Acquire-Timeout 10 Sekunden ist und Sie eine End-to-End-API-Latenz von 12 Sekunden sehen, geben Nutzer „dem Server“ die Schuld, während die echte Verzögerung das Warten auf eine Verbindung ist.
Schritt-für-Schritt: Pooling für lang laufende Server einstellen
Auf lang laufenden Servern (VMs, Container, immer-on Pods) ist die größte Falle zu vergessen, dass jeder Prozess seinen eigenen Pool haben kann. Zehn Web-Worker mit Poolgröße 20 sind nicht 20 Verbindungen, das sind bis zu 200.
Starten Sie mit einem Ziel, das Kopfspielraum unter Ihrem DB-Limit lässt. Wenn Postgres 100 Verbindungen erlaubt, wollen Sie selten, dass Ihre App alle 100 beansprucht. Lassen Sie Platz für Migrationen, Admin-Sessions, Hintergrund-Tools und Deploys.
1) Setzen Sie eine Poolgröße, die zur realen Gleichzeitigkeit passt
Denken Sie in „wie viele Queries laufen gleichzeitig“, nicht „wie viele Nutzer“. Langsame Queries verlängern die Zeit, in der eine Connection ausgeliehen ist, was den benötigten Pool erhöht.
Ein praktischer Ansatz ist, ein gesamtes Verbindungsbudget für die gesamte App zu setzen (oft 60–80 % des DB-Limits) und es dann auf die Prozesse zu verteilen, die sich verbinden können. Starten Sie klein und erhöhen Sie nur, wenn Sie Queueing sehen und die DB noch Spielraum hat. Budgetieren Sie Job-Worker separat.
2) Fügen Sie Timeouts hinzu, die schnell fehlschlagen (und sich erholen)
Zwei Einstellungen verhindern stille Anhäufungen: Acquire-Timeout (wie lange eine Anfrage auf eine freie Verbindung wartet) und Idle-Timeout (wie lange eine ungenutzte Verbindung offen bleibt). Kurze Acquire-Timeouts verwandeln einen langsamen Zusammenbruch in einen sichtbaren, begrenzten Fehler, auf den Sie alerten können.
Wenn Sie wählen müssen: Ein kleinerer Pool mit klaren Timeouts ist sicherer als ein großer Pool, der die Datenbank überlastet.
3) Begrenzen Sie die Konkurenz oberhalb des Pools
Wenn Ihr Server 500 gleichzeitige Requests annehmen kann, Ihr gesamtes DB-Budget aber 60 Verbindungen beträgt, brauchen Sie eine Drossel: Worker-Anzahl, Request-Gleichzeitigkeit oder Parallelismus der Job-Runner.
Verifizieren Sie außerdem, dass Verbindungen immer zurückgegeben werden, auch auf Fehlerpfaden. Suchen Sie nach fehlenden finally-Blöcken, verlassenen Transaktionen oder langen ORM-Sessions.
Schritt-für-Schritt: Pooling für Serverless einstellen
Serverless ändert die Mathematik. Der Code mag gleich aussehen, aber die Plattform kann viele kurzlebige Instanzen gleichzeitig erzeugen.
1) Setzen Sie harte Caps pro Instanz
Machen Sie jede Instanz aus Sicht der Datenbank „klein“. In vielen Serverless-Setups wollen Sie keinen großen Pool in jeder Funktion.
Halten Sie es einfach:
- Begrenzen Sie die Poolgröße pro Instanz auf eine niedrige Zahl (oft 1–4)
- Verwenden Sie ein kurzes Acquire-Timeout, damit Requests schnell fehlschlagen statt sich aufzuschichten
- Verwenden Sie einen Idle-Timeout, damit ungenutzte Verbindungen schnell schließen
- Recyceln Sie den Pool über Invocation-Grenzen hinweg (einmal erstellen, außerhalb des Request-Handlers)
- Stellen Sie sicher, dass jede Abfrage die Verbindung freigibt, auch bei Fehlern
Sanity-Check: Wenn Postgres 100 Verbindungen erlaubt und die Plattform 50 Instanzen starten kann, versucht eine Poolgröße von 5 bis zu 250 Verbindungen — genug, um Produktion zu brechen.
2) Kontrollieren Sie die Gleichzeitigkeit, bevor Sie die DB berühren
Ihr bester „Pool“ ist oft ein Concurrency-Limit. Begrenzen Sie, wie viele Requests eine Service-Version gleichzeitig ausführt. Das verhindert, dass ein neuer Deploy, ein Retry-Sturm oder ein Burst von Background-Jobs die DB überschwemmt.
Achten Sie auf versteckte Parallelität: Batches mit Promise.all, Webhook-Handler, die fächern, Queue-Consumer, die mehrere Nachrichten gleichzeitig verarbeiten. Diese multiplizieren Verbindungen auch bei leichtem User-Traffic.
3) Verwenden Sie einen externen Pooler oder Managed Proxy, wenn möglich
Wenn Ihre Plattform einen DB-Proxy anbietet (oder Sie einen externen Pooler betreiben können), kann er das Serverless-Scale-Out auffangen und die DB-Verbindungen stabil halten. Wissen Sie aber die Limits: Auch der Proxy kann seine Kapazität erreichen oder Anfragen länger als Ihre Function-Timeouts in die Queue stellen.
Ein realistischer Fehlermodus ist „neuer Pool pro Request“ plus Retries. Zehn gleichzeitige Invocations können in Sekunden 30 Verbindungsversuche werden.
Schutzmechanismen, die kleine Probleme von Ausfällen fernhalten
Die meisten Pool-Erschöpfungsfälle beginnen als kleine Verlangsamung. Ein paar Requests warten länger, dann stapelt sich alles. Schutzmechanismen sorgen dafür, schnell zu fehlschlagen, zurückzufahren und die App nutzbar zu halten, während die DB sich erholt.
Definieren Sie klares Fehlerverhalten. Wenn eine Anfrage nicht schnell an eine Verbindung kommt, sollte sie abbrechen und einen klaren Fehler zurückgeben, statt so lange zu hängen, bis ein Upstream-Timeout greift. Kurze Pool-Timeouts schützen Ihre Worker, weil sie Threads freigeben und Ihre Service-Antwortfähigkeit erhalten.
Retries brauchen strikte Limits. Jeden fehlgeschlagenen Query zu wiederholen kann ein kurzes Problem in eine Stampede verwandeln. Behalten Sie Retries für sichere Operationen (idempotente Reads), fügen Sie Jitter (zufällige Verzögerung) hinzu und begrenzen Sie die Gesamtretry-Zeit.
Circuit-Breaker sind der nächste Schritt. Wenn wiederholt DB-Fehler auftreten, öffnen Sie den Breaker kurz und schlagen neue DB-abhängige Requests sofort fehl. Schnell zu fehlschlagen ist besser, als das ganze System in einen langsamen Zusammenbruch zu ziehen.
Graceful Degradation hält die Nutzer in Bewegung. Je nach Produkt kann das bedeuten: Read-Only-Modus bei Write-Fehlern, Ausliefern gecachter Ergebnisse für häufige Reads, temporäres Deaktivieren schwerer Features wie Reports oder eine freundliche „Versuchen Sie es in 30 Sekunden erneut“-Antwort für DB-only Endpoints.
Alerten Sie auf frühe Signale, nicht nur auf harte Fehler. Steigende Connection-Wartezeit, wachsende Queue-Tiefe und höhere p95-Latenzen erscheinen oft Minuten bevor „zu viele Verbindungen“ erreicht sind.
Häufige Fehler, die plötzliche Pool-Erschöpfung auslösen
Die meisten Vorfälle entstehen nicht durch riesigen Traffic. Sie entstehen, wenn ein paar kleine Entscheidungen zusammenspielen und Ihre Sicherheitsmarge entfernen.
Eine häufige Falle ist, den App-Pool auf das DB-Limit zu setzen. Wenn Postgres 100 Verbindungen erlaubt und Sie Ihren Pool auf 100 stellen, haben Sie keinen Spielraum mehr für Migrationen, Background-Worker, Admin-Tools oder eine zweite App-Kopie beim Deploy.
Serverless-Skalierung ist ein weiterer häufiger Auslöser. Wenn jede Function-Instanz ihren eigenen Pool erstellt, haben Sie nicht „einen Pool von 20“, sondern „20 mal N Instanzen“, was leichten Traffic in Sekunden in einen Verbindungssturm verwandeln kann.
Die Fehler, die am häufigsten plötzliche Ausfälle auslösen, sind:
- Als App-Pool die DB-Max zu verwenden, ohne Reserven zu lassen
- Für jede serverless-Instanz (oder pro Request) einen separaten Pool erzeugen
- Verbindungen bei Fehlerpfaden leaken (frühe Returns, Exceptions, abgebrochene Requests)
- Verbindungen zu lange halten (langsame Queries, fehlende Indexe, lange Transaktionen)
- Hintergrundrauschen die echten Benutzer konkurrieren lassen (Health-Checks, Cron-Jobs, Queue-Polls)
Ein realistisches Muster ist eine „idle“ App, bei der ein Health-Check jede paar Sekunden trifft, ein Cron-Job jede Minute läuft und eine Query 10 Sekunden dauert. Mit einem kleinen Pool können schon wenige Überschneidungen ihn füllen.
Schnelle Pre-Release-Checkliste
Viele Vorfälle, die als Pool-Erschöpfung etikettiert werden, fehlen eigentlich nur „letzte Meilen“-Checks: Limits sind unbekannt, Timeouts inkonsistent und Parallelität dem Zufall überlassen.
Notieren Sie zuerst die harte Obergrenze. Postgres hat ein max connection Limit, und Managed-Provider reservieren oft Verbindungen für Admin-Zwecke. Wenn Sie Ihr nutzbares Maximum nicht kennen, können Sie Pools nicht sicher dimensionieren.
Vor dem Release prüfen Sie:
- Ihr Verbindungsbudget:
max_connections, reservierte Verbindungen und das Ziel-Limit für die App - Pool-Größe und Timeouts mit Kopfspielraum, inklusive klarem Acquire-Timeout
- Konkurrez-Einstellungen (besonders in Serverless), damit ein Deploy keine Welle neuer Verbindungen erzeugen kann
- Die langsamsten Queries und die wichtigsten Fixes (Indexe und unbeabsichtigte N+1-Queries sind häufig)
- Sichtbarkeit: Dashboards und Alerts für Connection-Count, Connection-Wartezeit und Pool-Timeouts (nicht nur generische 500s)
Ein praktischer Test: Führen Sie einen kleinen Load-Test durch, der „leichten Traffic“ simuliert (ein paar Nutzer, die klicken), und beobachten Sie Pool-Wartezeit und aktive Verbindungen. Wenn eines von beiden stetig steigt, sind Sie bereits nahe an einem Vorfall.
Ein realistisches Beispiel: Ein Ausfall bei nur wenigen Nutzern
Ein kleines SaaS hatte einen ruhigen Dienstagnachmittag: sechs eingeloggte Personen, ein paar Dashboard-Views pro Minute. Dann berichteten Nutzer, dass Login ewig dreht und das Dashboard zufällige 500-Fehler wirft.
In den Logs war die App nicht im klassischen Sinne „down“. CPU war ok. Arbeitsspeicher war ok. Der echte Hinweis waren wiederholte Meldungen wie „timeout acquiring a client“ und „remaining connection slots are reserved“. Klassische Pool-Erschöpfung, obwohl der Traffic leicht aussah.
Zwei kleine Änderungen wurden zusammen ausgeliefert.
Erstens lief ein neuer Background-Job jede Minute, um eine Statistik-Tabelle zu aktualisieren. Zweitens wurde eine Dashboard-Abfrage langsamer wegen eines fehlenden Indexes. Diese Abfrage nahm 8–12 Sekunden, und der Job hielt die Connection währenddessen.
Dann wurde von einer einzelnen lang laufenden Server-Instanz auf Serverless umgestellt. Am Code änderte sich nichts Gefährlicheres, aber die Parallelität stieg über Nacht. Ein paar gleichzeitige Page-Loads plus ein paar gleichzeitige Job-Runs bedeuteten viel mehr gleichzeitige Verbindungsversuche. Jede Instanz hatte ihren eigenen Pool, also stieg die Gesamtzahl offener Verbindungen schnell.
Die Lösung war kein einzelner magischer Parameter, sondern eine Reihe kleiner Schutzmaßnahmen:
- Pro-Instanz-Poolgröße senken, damit jede Instanz nicht zu viele Verbindungen greift
- Concurrency begrenzen, damit die Plattform nicht unlimitierte parallele Arbeit erzeugt
- Pool-Timeouts verkürzen, damit Requests schnell fehlschlagen und sich erholen statt zu stapeln
- Die langsame Query optimieren (Index hinzufügen, unnötige Joins reduzieren)
Danach blieb die App stabil. Alerts auf „pool wait time“ und „active connections“ gaben dem Team Minuten früher Warnungen, bevor Nutzer es spürten.
Nächste Schritte: Pooling stabilisieren und eine zweite Meinung einholen
Wenn Sie gerade Pool-Erschöpfung bekämpft haben, fangen Sie nicht an, wahllos Zahlen zu ändern. Benennen Sie zuerst Ihr Betriebsmodell: Serverless (viele kurzlebige Instanzen), lang laufende Server (wenige stabile Prozesse) oder Hybrid. Pooling ist in jedem Fall eine andere Aufgabe.
Schreiben Sie ein einfaches Pool-Budget auf, das es unmöglich macht, dass Ihr App-Tier mehr Verbindungen verlangt, als Postgres sicher geben kann. Erfassen Sie drei Dinge: Ihre nutzbare Postgres-Obergrenze, Ihre maximale Instanzanzahl (oder Burst-Anzahl) und das Per-Instanz-Limit sowie Ihre „Stoppschilder“-Timeouts, damit Requests schnell fehlschlagen statt sich aufzuschichten.
Führen Sie dann einen fokussierten Lasttest durch, der die Realität nachbildet. Viele Teams testen hohen Durchsatz, verpassen aber das Muster, das Erschöpfung auslöst: kurze Bursts, langsame Queries und Retries. Beziehen Sie Login-/Signup-Flows, Ihre langsamste Seite und gleichzeitig laufende Hintergrundaufgaben ein.
Wenn Sie einen AI-generierten Codebestand geerbt haben, lohnt sich eine Überprüfung auf die üblichen Fallen: „connect per request“-Muster, fehlender Cleanup bei Fehlern und versteckte Retries, die die Gleichzeitigkeit multiplizieren. Für eine schnelle Plausibilitätsprüfung kann FixMyMess (fixmymess.ai) einen kostenlosen Code-Audit anbieten, der zeigt, wo Verbindungen erstellt, geleakt oder zu lange gehalten werden, damit Sie die Ursache beheben können, statt nur an Pool-Größen zu raten.
Wenn Marken oder Tools erwähnt werden (z. B. Lovable, Bolt, v0, Cursor, Replit), prüfen Sie deren spezifische Integrationen auf Muster, die Verbindungen multiplizieren.
Häufige Fragen
What does “connection pool exhaustion” actually mean?
Das bedeutet, dass Ihre App auf eine freie Datenbankverbindung wartet, aber keine verfügbar ist. Anfragen stauen sich, erreichen ein Acquire-Timeout und Benutzer sehen langsame Seiten, gefolgt von sporadischen Fehlern.
Why does pool exhaustion happen even when traffic looks light?
CPU und Traffic können normal aussehen, weil die App nicht mehr Arbeit macht, sondern hauptsächlich wartet. Ein paar Anfragen, die Verbindungen länger halten als erwartet, können den gesamten Pool blockieren, sodass selbst „leichter“ Traffic ins Stocken gerät.
What are the most common user-facing symptoms in production?
Achten Sie auf lange Hänger (oft 10–30 Sekunden), gefolgt von 500-Fehlern, Login-Problemen oder Hintergrundjobs, die nicht weiterlaufen. Ein Refresh kann kurzzeitig helfen, weil eine Verbindung frei wird, wonach das Problem wiederkehrt, wenn der Pool sich füllt.
How do connection leaks usually happen in real code?
Lecks entstehen, wenn Code eine Verbindung auscheckt, sie aber nicht auf allen Pfaden zurückgibt — besonders auf Fehlerpfaden. Unbehandelte Ausnahmen, frühe Returns, abgebrochene Requests und fehlende Cleanup-Logik sind übliche Ursachen.
Is the real issue “too many users,” or something else?
Denken Sie in Begriffen von Gleichzeitigkeit und der Zeit, die eine Verbindung gehalten wird. Ein Pool kann eine kleine Anzahl gleichzeitiger Queries handhaben; wenn Queries langsam sind oder Transaktionen offen bleiben, hält jede Anfrage eine Verbindung länger, und der Pool ist schneller erschöpft.
How is pooling different on serverless compared to long-lived servers?
Bei lang laufenden Servern wird ein Pool innerhalb eines stabilen Prozesses wiederverwendet, sodass die Gesamtzahl der Verbindungen besser vorhersehbar ist. In Serverless-Umgebungen können viele kurzlebige Instanzen gleichzeitig starten und jeweils eigene Pools öffnen, wodurch die Gesamtzahl der Verbindungen schnell multipliziert wird.
What numbers should I gather before changing pool settings?
Beginnen Sie mit dem Limit Ihrer Datenbank (z. B. Postgres max_connections) und ziehen Sie Verbindungen für Admin-Sessions, Migrations-Tools und Hintergrundarbeiter ab. Messen Sie dann Spitzen in gleichzeitigen Requests, Wartezeiten auf Verbindungen und welche Queries bei p95/p99 langsam sind — diese Zahlen erklären meist plötzliche Vorfälle.
What timeouts and guardrails prevent a slow meltdown?
Setzen Sie ein Acquire-Timeout, damit Anfragen schnell fehlschlagen statt sich aufzuschichten, und einen Idle-Timeout, damit ungenutzte Verbindungen zügig geschlossen werden. Drosseln Sie zudem Request- und Job-Konkurrenz, sodass Ihre App nicht mehr parallele Arbeit annimmt als Ihr Verbindungsbudget erlaubt.
What are the biggest mistakes that trigger pool exhaustion?
Vermeiden Sie, die App-Pool-Größe identisch mit dem DB-Max zu setzen — Reserven für Deploys, Migrations, Admin-Tools und Worker fehlen dann. Auch problematisch: für jede Anfrage einen neuen Pool erstellen, unkontrollierte Retries und langsame Queries in langen Transaktionen.
How do I quickly stabilize an AI-generated app that keeps exhausting the pool?
Prüfen Sie auf „connect per request“-Muster, fehlenden Cleanup bei Fehlern, versteckte Retries und langsame Queries, denn AI-generierte Prototypen enthalten diese Muster oft. Wenn Sie eine zweite Meinung wollen, kann FixMyMess (fixmymess.ai) den Code auditieren und zeigen, wo Verbindungen erstellt, geleakt oder zu lange gehalten werden, damit Sie die Ursache statt nur die Pool-Zahlen ändern.