Datenbereinigung nach einem hastigen Prototyp: Duplikate und Integritätsreparatur
Datenbereinigung nach einem hastigen Prototyp: Schritte zur Deduplizierung und Integritätsreparatur, um Duplikate zu finden, verwaiste Zeilen zu reparieren, Constraints durchzusetzen und mit Skripten zu validieren.
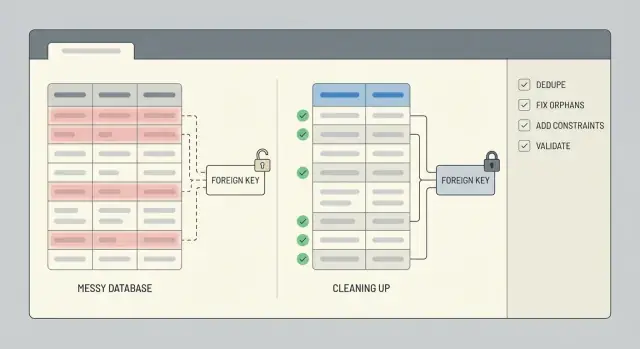
Was nach einem hastigen Prototyp meist kaputtgeht
Ein hastig gebauter Prototyp dient dazu, eine Idee zu beweisen, nicht Daten zu schützen. Regeln fehlen oft, Feldnamen ändern sich während der Entwicklung, und irgendwann „ändert jemand es eben in der Datenbank", um ein Problem zu umgehen. Wenn die App von einem KI-Tool generiert wurde, siehst du außerdem schnell kopierte Muster: überlappende Tabellen, IDs, die an einer Stelle als Text und an anderer als Zahl gespeichert sind, und Logik, die denselben Datensatz zweimal speichert.
Duplikate tauchen auf langweilige, aber teure Art auf: zwei Benutzerkonten mit derselben E‑Mail, aber unterschiedlicher Groß-/Kleinschreibung, mehrere „aktive" Abonnements für einen Kunden oder dieselbe Bestellung, die bei Klick und erneut bei Seiten-Refresh gespeichert wurde. Manchmal sind es keine exakten Treffer. Du siehst Near-Duplicates wie „Acme, Inc" vs. „ACME Inc." oder zwei Kontakte mit derselben Telefonnummer.
Gebrochene Beziehungen sind ebenso häufig. Du findest Bestellungen, die auf einen user_id zeigen, der nicht mehr existiert, Kommentare an einem gelöschten Post, oder Zeilen, die auf 0 oder einen leeren String verweisen, weil die App Eingaben nie validiert hat. Diese Waisen-Zeilen bringen die App nicht immer zum Absturz, sie verfälschen aber Summen, Dashboards und Exporte.
Nutzer erleben schlechte Daten als Login-Probleme, falsche Summen (doppelt gezählte Bestellungen, überhöhte Lagerbestände), fehlende Historie und UI-Seiten, die bei manchen Datensätzen funktionieren, bei anderen nicht.
Bereinige jetzt, wenn du anfangen willst, Geld zu verlangen, verlässliche Reports brauchst oder der Support Zeit damit verbringt, Datensätze manuell zu reparieren. Warten macht es schwieriger, weil jedes neue Feature zusätzliche Daten auf den Haufen schreibt.
Bevor du Daten anfasst: Snapshot, Scope und Rollback
Cleanup geht schief, wenn du Reihen änderst, bevor du weißt, was wichtig ist und wie du Änderungen rückgängig machst. Behandle das wie eine kontrollierte Operation, nicht wie einen Quick-Fix.
Beginne damit, die Teile der Datenbank zu scopen, die echte Menschen und Geld betreffen. Liste die Tabellen und die dazugehörigen Nutzerflüsse auf: Signups, Checkout, Abonnements, Veröffentlichung von Inhalten. Wenn du das überspringst, kannst du eine Tabelle deduplizieren und unbeabsichtigt einen nachgelagerten Flow kaputtmachen, der noch die alte Form erwartet.
Eine einfache Scope-Notiz reicht oft: users, sessions/auth-Tabellen, orders, payments, invoices, subscriptions und Kern-Content-Tabellen (posts, comments, files). Schreibe auch die Quelle der Wahrheit für jedes Schlüssel-Feld auf (z. B. ob du einer Zahlungsanbieter-ID mehr vertraust als einer E‑Mail).
Als Nächstes mache einen sicheren Snapshot und definiere Rollback, bevor du ein einziges UPDATE ausführst. Das Snapshot kann ein Datenbank-Backup, ein Point-in-Time-Restore oder ein exportierter Ausschnitt der betroffenen Tabellen sein. Rollback ist nicht "wir sind vorsichtig". Es ist ein schriftlicher Schritt: wie du wiederherstellst, wie lange es dauert und wer es machen kann.
Wenn möglich, führe das Cleanup zuerst auf einer Kopie aus. Ein aktueller Produktionsklon in Staging ist ideal, weil er reale Randfälle enthält, ohne Live-Daten zu riskieren. Ziehe erst in die Produktion, wenn deine Skripte wiederholbar sind und die Ergebnisse vorhersehbar sind.
Lege schließlich ein Zeitfenster fest. Wenn möglich, friere oder sperre risikoreiche Schreibvorgänge (neue Signups, Bestell-Erstellungen, Hintergrund-Sync-Jobs) während des Cleanups. Wenn du das nicht kannst, nimm einen Cutoff-Timestamp auf und begrenze Änderungen auf Datensätze, die vor diesem Zeitpunkt erstellt wurden.
Entscheide, was ein Duplikat ist (und welches du behältst)
Bevor du etwas löschst, sei konkret, was "Duplikat" für deine App bedeutet. In einem Prototyp können zwei Zeilen für eine Person identisch aussehen, aber trotzdem verschiedene reale Nutzer oder Events darstellen. Wenn du falsch rätst, wird Cleanup zu Datenverlust.
Wähle eine Quelle der Wahrheit für jede Entität. Bei Nutzern kann das der Datensatz sein, der an einen verifizierten Login gebunden ist, das älteste Konto oder das Konto, auf das am häufigsten in Bestellungen verwiesen wird. Bei Bestellungen ist es vielleicht die Zeile, die tatsächlich bezahlt wurde, nicht die, die während eines fehlgeschlagenen Checkouts angelegt wurde.
Schreibe einfache Merge-Regeln und halte dich daran. Entscheide, wie du Konflikte auflöst und wie du mit leeren Feldern umgehst. Ein paar Regeln decken die meisten Fälle ab:
- Wenn ein Datensatz einen Wert hat und der andere
NULL, behalte den Wert. - Wenn beide Werte haben, bevorzuge den verifizierten oder zuletzt aktualisierten Eintrag.
- Überschreibe nicht Audit-Felder, die dir wichtig sind (
created_at,signup_sourceund ähnliche Felder).
Bestimme außerdem den kanonischen Schlüssel, den du zur Identifikation von Duplikaten nutzen wirst. Häufige Optionen sind E‑Mail, ein external_id vom Auth-Provider, Telefonnummer oder ein Komposit wie (workspace_id, normalized_email). Vorsicht: Prototypen speichern E‑Mails oft mit unterschiedlicher Groß-/Kleinschreibung, zusätzlichen Leerzeichen oder Plus-Addressing-Varianten.
Edge-Cases bringen Teams leicht in Schwierigkeiten. Geteilte Postfächer (team@), Testaccounts, importierte CSVs mit Platzhalter-E‑Mails und von KI erzeugte Seed-Daten können legitime Wiederholungen erzeugen. Erfasse diese Ausnahmen im Voraus und führe eine kurze Liste von Mustern, die du vom Dedupe ausschließen willst.
Methoden zur Erkennung von Duplikaten
Beginne mit dem einfachsten Signal: zwei Zeilen, die denselben Key teilen. Auch wenn dein Prototyp nie einen echten Key definiert hat, hast du meist etwas Näherungsweise (E‑Mail, external_id, order_number oder eine natürliche Kombination wie user_id plus ein Tages-Created-At).
Ein schneller erster Schritt ist eine Zählung nach dem vermuteten Key, gefiltert auf Keys, die mehr als einmal auftreten:
SELECT email, COUNT(*) AS c
FROM users
GROUP BY email
HAVING COUNT(*) > 1
ORDER BY c DESC;
Suche danach nach Near-Duplicates. Normalisiere das Feld in der Abfrage, damit du Kollisionen siehst, die du sonst verpasst hättest:
SELECT LOWER(TRIM(email)) AS email_norm, COUNT(*) AS c
FROM users
GROUP BY LOWER(TRIM(email))
HAVING COUNT(*) > 1;
Prüfe auch Duplikate, die durch Retries entstehen. Wenn deine App dasselbe Event nach einem Timeout zweimal einfügt, siehst du möglicherweise mehrere Zeilen mit derselben event_id, provider_charge_id, idempotency_key oder (user_id + exact payload hash). Wenn diese Felder fehlen, sieht das Muster oft aus wie identische Zeilen, die Sekunden auseinander erstellt wurden.
Bevor du etwas löschst oder zusammenführst, baue eine kleine Review-Stichprobe. Wähle die Top-20-Duplikat-Gruppen und inspectiere sie manuell, damit du weißt, was "behalten" heißen soll. Hole komplette Duplicate-Sets zur Überprüfung, vergleiche Zeitstempel, prüfe, ob Child-Rows (orders, sessions, invoices) auf eines der Duplikate zeigen und notiere die Regel, die du anwenden wirst. Speichere die Abfrage, die deine Stichprobe erzeugte, damit du sie nach Änderungen erneut laufen lassen kannst.
Deduplizieren ohne wichtige Historie zu verlieren
Wenn andere Tabellen auf einen Datensatz zeigen, erzeugt Löschen in der Regel neue Probleme. Ein sicherer Weg ist, Duplikate zu mergen und alle Referenzen auf eine einzige Keeper-Zeile zu zeigen, damit die Historie verbunden bleibt.
Wähle für jede Duplikat-Gruppe einen Keeper, verschiebe Referenzen von den Verlierer-IDs auf die Keeper-ID und archive die Verlierer oder markiere sie inaktiv. So vermeidest du, dass Bestellungen, Rechnungen, Nachrichten und Berechtigungen plötzlich nicht mehr zugeordnet sind.
Wenn Duplikate unterschiedliche Werte haben, entscheide vorab, wie Konflikte gelöst werden. Halte es vorhersehbar: bevorzuge verifizierte Datensätze gegenüber unverifizierten, bevorzuge bezahlten/aktiven Status gegenüber gratis/inaktiv, behalte bei beiden plausiblen Werten den neuesten gültigen Wert und überschreibe niemals ein nicht-leeres Feld mit einem leeren.
Führe ein Audit-Trail, damit die Arbeit reversibel bleibt. Eine kleine Mapping-Tabelle wie dedupe_map(old_id, new_id, merged_at, reason) erlaubt es dir, Monate später zu beantworten "was ist mit diesem Nutzer passiert?" und beschleunigt Debugging enorm.
Vergiss die Daten um die Zeile herum nicht. Profile, Einstellungen, Mitgliedschaften, hochgeladene Dateien und Notizen leben oft in separaten Tabellen. Zeige diese Child-Rows zuerst um und achte auf Einzigartigkeitskonflikte (z. B. wenn zwei Einstellungen-Zeilen zu einer werden müssen).
Führe das Dedupe in Batches aus (z. B. 100 bis 1.000 Gruppen pro Lauf). Kleinere Batches reduzieren Lock-Zeiten, machen Fehler leichter isolierbar und geben dir die Möglichkeit, Ergebnisse zwischen den Läufen zu prüfen.
Waisenzeilen finden und reparieren
Ein Waisen-Datensatz ist eine Zeile, die auf etwas verweist, das nicht existiert. Meist ist es ein Kind mit einem parent_id, das keinen passenden Parent hat. Das tritt oft nach einem hastigen Prototyp auf, besonders wenn die App auf Transaktionen verzichtet hat oder Datensätze gelöscht wurden, ohne zugehörige Tabellen zu säubern.
Beginne mit der Messung des Problems. Ein einfacher LEFT JOIN zeigt, wie viele Child-Zeilen keinen Parent finden:
-- Example: orders should reference users
SELECT COUNT(*) AS orphan_orders
FROM orders o
LEFT JOIN users u ON u.id = o.user_id
WHERE u.id IS NULL;
-- Inspect a sample to understand patterns
SELECT o.*
FROM orders o
LEFT JOIN users u ON u.id = o.user_id
WHERE u.id IS NULL
LIMIT 50;
Wenn du Soft-Deletes nutzt, achte auf "versteckte Waisen": Der Parent existiert, ist aber logisch entfernt (z. B. users.deleted_at IS NOT NULL). Entscheide, ob diese weiterhin als gültig gelten sollen.
Sobald du weißt, womit du es zu tun hast, wähle einen Reparaturpfad basierend auf der Bedeutung der Daten:
- Den fehlenden Parent neu erstellen, wenn er wirklich beim Speichern versagt hat.
- Das Kind einem echten Parent neu zuweisen (häufig nach User-Dedupe).
- Das Waisen-Kind archivieren oder löschen, wenn es nicht vertrauenswürdig ist (Testdaten, partielle Writes).
- Nur dann einen "Unknown"- oder "System"-Parent anlegen, wenn die Produktlogik damit sauber umgehen kann.
Was immer du wählst, protokolliere jede Änderung, damit du sicher neu laufen kannst. Ein gutes Muster ist: Schreibe Änderungen in eine Staging-Tabelle (oder markiere Zeilen mit einer Batch-ID), führe Updates in kleinen Batches aus und logge Zähler vor und nach dem Lauf.
Integrität erzwingen mit Constraints (und den richtigen Indexen)
Nach der Bereinigung verhindern Constraints, dass derselbe Müll nächste Woche zurückkehrt. Füge Constraints nur hinzu, nachdem du gededupliziert und gebrochene Beziehungen repariert hast, sonst blockierst du deine eigenen Reparaturen.
Beginne mit Primary Keys. Stelle sicher, dass jede Tabelle einen hat, dass er wirklich eindeutig ist und niemals wiederverwendet wird. Wenn dein Prototyp bedeutungsvolle IDs nutzte (z. B. eine Nutzer-ID basierend auf einem E‑Mail-Hash), erwäge den Wechsel zu einer stabilen Surrogat-ID (Auto-Increment-Integer oder UUID) und behandle den bedeutungsvollen Wert als separates Unique-Feld.
Sichere dann die Identifier, auf die dein Business sich tatsächlich verlässt. Für viele Apps bedeutet das eine Unique-Constraint auf E‑Mail (oft case-insensitive) und auf alle external_id, die du von Zahlungsanbietern, CRM oder Auth-Systemen erhältst.
Fremdschlüssel verhindern Waisenzeilen. Wähle das Delete-Verhalten passend zur Realität: manchmal willst du Löschungen blockieren, manchmal cascaden, und manchmal die Historie behalten, indem du den Fremdschlüssel auf NULL setzt. Beispiel: Wenn dein MVP das Löschen eines Nutzers erlaubte, aber Bestellungen zurückließ, kannst du Löschen blockieren, wenn Bestellungen existieren, oder Bestellungen behalten und den Nutzer anonymisieren.
Check-Constraints fangen schlechte Werte früh. Halte sie einfach: Summen müssen >= 0 sein, Status muss in einer erlaubten Menge liegen, benötigte Zeitstempel dürfen nicht NULL sein und Menge (quantity) muss > 0 sein.
Füge schließlich die passenden Indexe hinzu, damit diese Regeln nicht alles verlangsamen. Unique-Constraints und Fremdschlüssel brauchen normalerweise unterstützende Indexe; es lohnt sich, Indexe an deine häufigsten Abfragen anzupassen (z. B. Bestellungen nach user_id).
Schritt-für-Schritt: Wiederholbare Cleanup-Skripte bauen
Chaotische Datenreparaturen gehen schief, wenn sie per Hand, als Einmal-Aktion oder ohne klare Reihenfolge gemacht werden. Behandle die Arbeit wie ein kleines Release: Wende Änderungen in einer Reihenfolge an, die du auf Staging und Produktion wiederholen kannst.
Eine einfache Skript-Struktur
Nutze geordnete Migrations- oder Skript-Dateien, die in denselben drei Phasen laufen: setup, backfill, enforce. Halte read-only-Erkennungsabfragen getrennt von Schreibschritten, damit du sehen kannst, was sich ändern wird, bevor etwas geschrieben wird.
Ein praktischer Flow, der in den meisten DBs funktioniert:
- 01-detect.sql (read-only): liste Duplikate, Waisen und schlechte Werte auf
- 02-setup.sql: füge Hilfstabellen/-spalten hinzu (z. B. eine Mapping-Tabelle old_id -> kept_id)
- 03-backfill.sql: weise Fremdschlüssel neu zu, merge Zeilen, archive das, was entfernt wird
- 04-enforce.sql: füge Unique-Constraints, Fremdschlüssel und benötigte Indexe hinzu
- 05-validate.sql (read-only): Checks, die beweisen, dass das Cleanup funktioniert hat
Mach Schreibskripte idempotent (sicher mehrfach ausführbar). Nutze klare Guards wie WHERE NOT EXISTS (...), prüfe auf Existenz von Spalten/Constraints und bevorzuge Upserts in Mapping-Tabellen. Kapsle riskante Updates, wenn möglich, in Transaktionen und fail schnell, wenn erwartete Präbedingungen nicht erfüllt sind (z. B. wenn eine Duplikat-Gruppe zwei „aktive" Zeilen enthält).
Was bei jedem Lauf aufgezeichnet werden sollte
Logge, was sich geändert hat, damit du Ergebnisse erklären und spätere Regressionen entdecken kannst. Mindestens solltest du pro Schritt zählen: zusammengeführte Zeilen, neu zugewiesene Zeilen, archivierte Zeilen und ungelöste Zeilen.
Ein hilfreiches Muster sind Rückgabewerte mit Zählern aus jedem Schreibschritt:
-- Example: reassign child rows to the kept parent
UPDATE orders o
SET user_id = m.kept_user_id
FROM user_merge_map m
WHERE o.user_id = m.duplicate_user_id;
-- Example: archive duplicates (guarded)
INSERT INTO users_archived
SELECT u.*
FROM users u
JOIN user_merge_map m ON u.id = m.duplicate_user_id
WHERE NOT EXISTS (
SELECT 1 FROM users_archived a WHERE a.id = u.id
);
Speichere Skripte in der Versionskontrolle mit einem kurzen Runbook (Inputs, Reihenfolge, erwartete Laufzeit, Rollback-Notizen).
Ergebnisse mit schnellen Checks und wiederholbaren Tests validieren
Die Arbeit ist nicht fertig, bis du beweisen kannst, dass die Datenbank sicherer ist als vorher. Schreibe ein paar Vorher-Nachher-Zahlen auf, die du jedes Mal vergleichen kannst, wenn du das Cleanup neu ausführst.
Verfolge Metriken, die zeigen, ob das Problem wirklich kleiner wurde: Gesamtanzahl Zeilen, distinct Business-Keys, Duplikat-Gruppen und Waisen-Zahlen. Speichere diese Zahlen in einer kleinen Textdatei oder Tabelle, damit du später Regressionen erkennst.
Hier ein paar Abfragen, die du nach jeder Korrektur erneut laufen lassen kannst:
-- Row counts (sanity)
SELECT COUNT(*) AS users_total FROM users;
-- Distinct keys (did dedupe work?)
SELECT COUNT(DISTINCT email) AS users_distinct_email FROM users;
-- Duplicate groups (should trend to 0)
SELECT email, COUNT(*)
FROM users
GROUP BY email
HAVING COUNT(*) > 1;
-- Orphans (child rows without a parent)
SELECT COUNT(*) AS orphan_orders
FROM orders o
LEFT JOIN users u ON u.id = o.user_id
WHERE u.id IS NULL;
Zahlen helfen, ersetzen aber nicht reales Verhalten. Validere ein paar kritische Flows so, wie die App benutzt wird: kann ein Nutzer sich anmelden, kann eine Bestellung geladen werden, stimmt die Rechnungssumme noch mit den Order-Items überein. Spot-checke dann 10–20 reale Datensätze Ende-zu-Ende.
Um zu verhindern, dass es wieder passiert, füge leichte automatisierte Checks hinzu, die du nach jedem Deploy laufen lassen kannst: ein Skript, das Metriken ausführt und fehlschlägt, wenn Duplikate oder Waisen steigen, ein Constraint-Check (Unique-Keys, Foreign-Keys) in CI oder als Release-Checklist, und ein täglicher Job, der neue Verstöße meldet, bevor sie wachsen.
Wenn schlechte Daten weiterhin hereinkommen können (alte Import-Jobs, lockere API-Validierung), plane fortlaufendes Cleanup: sichere die Quelle, dann behalte die Checks laufen.
Warum Duplikate und Waisen immer wiederkommen
Duplikate und Waisen sind selten nur ein einmaliger Zufall. Wenn deine App weiterhin solche erzeugt, kauft Cleanup nur Zeit, solange du die Ursachen in Code und Workflow nicht behebst.
Ein häufiger Auslöser sind Retries. Ein Background-Job time-outed, retried und fügt dieselbe "create order"- oder "send invite"-Zeile nochmal ein, weil kein Idempotency-Key vorhanden ist. Der Job hat genau das getan, wozu er aufgefordert wurde. Er hat es nur zweimal getan.
Asynchrone Flows können sich auch gegenseitig in die Quere kommen. Beispiel: Ein Signup-Flow legt in einer Anfrage einen Nutzer an und in einer anderen das Profil. Läuft die Profil-Anfrage zuerst oder der Nutzer-Insert schlägt fehl, entsteht ein verwaistes Profil. Fehlende Transaktionen verschlimmern das Problem, weil halbfertige Arbeiten committed werden können.
Menschliche Aktionen zählen auch. Schnelle Admin-Änderungen oder "fix it in the database"-Momente umgehen oft die Validierungen, die die App normalerweise ausführt, besonders wenn keine Constraints schlechte Writes stoppen. Importe sind ein weiterer Pfad: Die CSV hat E‑Mails mit verschiedenem Case, Telefonnummern mit zusätzlichen Zeichen oder externe IDs, die nicht konsistent sind — derselbe Mensch landet so als mehrere Datensätze in der DB.
Schutzmaßnahmen, die Rückfälle verhindern
Ziele einige Änderungen an, die schlechte Daten an der Quelle blockieren:
- Mach Create-Operationen idempotent (speichere eine Request- oder Event-Key und ignoriere Wiederholungen).
- Kapsle mehrstufige Writes in eine Transaktion, damit sie zusammen gelingen oder zusammen fehlschlagen.
- Normalisiere Identifier vor dem Schreiben (E‑Mail lowercasing, Telefonformatierung, getrimmte IDs).
- Sperre Admin-Pfade so, dass sie dieselbe Validierung wie die App nutzen, nicht direkte Updates.
- Füge Constraints plus Monitoring hinzu, damit Fehler sichtbar werden und schnell behoben werden.
Wenn du ein geerbtes, AI-gebautes MVP hast, sind diese Probleme typisch. Die Datenbank ist meist nicht die Wurzel; lockere Schreibpfade sind es.
Beispiel: Nutzer und Bestellungen nach einem AI-erstellten MVP bereinigen
Ein häufiger Fall ist ein KI-erstellter Signup-Flow, der bei jedem Retry eine neue Nutzerzeile anlegt. Wenn dieselbe Person dreimal auf "Sign up" tippt, hast du vielleicht drei Accounts mit derselben E‑Mail, aber verschiedenen IDs und partiellen Profildaten.
Dazu kommt ein zweites Problem: Nach einer Schemaänderung wurden einige Nutzer gelöscht (oder gemerged), ohne zugehörige Tabellen zu aktualisieren. Bestellungen zeigen weiterhin auf die alte user_id, sodass du verwaiste Bestellungen hast, die keinem realen Nutzer mehr zugeordnet sind.
Ein praktischer Weg, das ohne Raten zu reparieren:
- Wähle für jede E‑Mail einen kanonischen Nutzer (z. B. den mit
verified = trueoder das frühestecreated_at). - Erstelle eine ID-Mapping-Tabelle, die
old_user_id->canonical_user_iddokumentiert. - Aktualisiere Bestellungen, indem du über die Mapping-Tabelle joinst, sodass jede Bestellung auf die kanonische
user_idzeigt. - Lösche (oder archive) erst dann die zusätzlichen Nutzerzeilen.
- Füge Schutzmaßnahmen hinzu, damit sich das Problem nicht wieder bildet.
Deine Mapping-Tabelle kann so einfach sein wie (old_user_id, canonical_user_id), gefüllt durch eine Abfrage, die nach E‑Mail gruppiert und den Gewinner wählt. Nach dem Update führe Schnell-Checks aus: Zähle Nutzer pro E‑Mail, zähle Bestellungen mit fehlendem Nutzer und spot-checke ein paar Kunden mit hohem Wert.
Zum Schluss Integrität einziehen. Füge eine Unique-Constraint auf E‑Mail hinzu und einen Fremdschlüssel von orders.user_id nach users.id. Wenn du Angst vor Schreibunterbrechungen hast, füge die Constraints nach dem Cleanup hinzu und teste vorher auf einer Produktionskopie.
Schnelle Checkliste und nächste Schritte
Zwei Dinge zählen am Ende: die aktuellen Daten sind korrekt und es ist schwer, denselben Mist wieder hereinzubringen. Halte Notizen, damit jemand anders die Arbeit später wiederholen kann.
Checkliste für das Cleanup selbst:
- Ein frisches Snapshot existiert und du weißt, wie man es wiederherstellt.
- Duplikat-Regeln sind aufgeschrieben (Matching-Felder, Tie-Breaker, was behalten wird).
- Erkennungsabfragen wurden ausgeführt und mit Zeitstempeln und Zählern gespeichert.
- Änderungen sind geloggt (Vorher/Nachher-IDs, Merges, Deletes und manuelle Entscheidungen).
- Cleanup-Skripte laufen auf einer Kopie der Produktion und liefern dieselben Ergebnisse.
Nachdem die Daten gut aussehen, sorge dafür, dass sie so bleiben:
- Fremdschlüssel und Unique-Constraints sind hinzugefügt (oder geplant) und durch passende Indexe unterstützt.
- Validierungs-Checks bestehen (Zeilenzahlen, referentielle Integrität, Schlüsseldeduplizierung, kritische Summen).
- Rollback ist auf einer Staging-Kopie end-to-end getestet.
- Monitoring hat einen klaren Besitzer (Alerts, Wochenbericht oder Release-Gate).
Wenn du ein gebrochenes, AI-generiertes Prototype geerbt hast und einen schnellen, sicheren Weg in Produktion brauchst, konzentriert sich FixMyMess (fixmymess.ai) darauf, den Codebase zu diagnostizieren, Logik- und Datenintegritätsprobleme zu reparieren und die App so zu härten, dass dieselben Probleme nicht wieder auftreten.
Häufige Fragen
When should I stop building features and clean up the database?
Wenn deine App Zahlungen annehmen soll, du verlässliche Reports brauchst oder der Support Datensätze manuell repariert — dann jetzt bereinigen. Je länger du wartest, desto mehr neue Features und Retries legen zusätzliches, chaotisches Datenmaterial auf den Haufen.
What’s the safest first step before I run any UPDATE statements?
Mache zuerst ein Snapshot, das sich schnell zurückspielen lässt, und schreibe Scope und Rollback auf, bevor du Updates ausführst. Wenn möglich, teste das komplette Cleanup zuerst auf einer aktuellen Produktionskopie in Staging, um reale Randfälle zu sehen ohne Live-Daten zu riskieren.
How do I decide what counts as a duplicate user?
Definiere Duplikate über einen klaren Business-Key und eine Regel, welches Datensatz bleibt. Ein üblicher Default ist: "dieselbe normalisierte E‑Mail gehört zu einem Nutzer" — behalte den Datensatz, der verifiziert ist oder die wichtigste Historie (z. B. bezahlte Bestellungen) referenziert.
How can I find near-duplicates like email casing or extra spaces?
Normalisiere das Feld in deinen Erkennungsabfragen (z. B. Trim + Lowercase für E‑Mails), damit du Kollisionen findest, die du sonst übersiehst. Prüfe dann manuell eine kleine Stichprobe der größten Duplikat-Gruppen, um sicherzugehen, dass deine Regeln zum echten Verhalten passen.
Is it better to delete duplicates or merge them?
Lösche nicht sofort, wenn andere Tabellen auf den Datensatz zeigen — das bricht leicht Historie. Merge statt löschen: wähle eine Keeper-ID, zeige alle Fremdschlüssel auf diese ID um und archive oder deaktiviere dann die Duplikate.
What is an orphaned row, and why does it matter?
Ein Waisen-Datensatz ist ein Kind, das auf ein nicht vorhandenes Parent verweist, z. B. eine Bestellung ohne passenden Nutzer. Er stürzt die App nicht immer ab, verfälscht aber Summen, Exporte und erzeugt Supporträtsel.
How do I fix orphaned orders or comments without guessing?
Zähle und sampel Orphans zuerst mit einem LEFT JOIN, um Muster zu verstehen. Dann wähle einen Reparaturpfad: Parent neu erstellen, Kind einem echten Parent neu zuweisen (häufig nach Dedupe), oder das Kind archivieren/löschen, wenn es unzuverlässig ist.
What constraints should I add to prevent this mess from coming back?
Füge Constraints erst nach der Bereinigung hinzu, sonst blockierst du deine Arbeit. Baseline: eindeutige Constraints auf echte Identifier (normalisierte E‑Mail, Provider-IDs) und Fremdschlüssel für Beziehungen, die nicht zerbrechen dürfen.
How do I make my cleanup scripts safe to run more than once?
Trenne Lese-Erkennungen von Schreibschritten und baue Schutzmechanismen ein, damit ein erneuter Lauf nichts doppelt zusammenführt. Guards wie WHERE NOT EXISTS (...), idempotente Upserts und eine Mapping-Tabelle alter → neuer IDs helfen sehr.
How do I validate the cleanup worked and the app won’t regress?
Vergleiche Vorher-Nachher-Zahlen für Duplikate und Waisen und prüfe kritische Flows Ende-zu-Ende (Login, Checkout). Automatisiere leichte Checks nach jedem Deploy: Metriken laufen lassen, Constraints prüfen in CI oder als Release-Check, und täglich neue Verstöße melden.