Versehehnlichen Datenverlust bei Updates mit PATCH-Semantik verhindern
Vermeide versehentlichen Datenverlust bei Updates durch PATCH-Semantik, Feld-Allowlists und klare Defaults, damit fehlende Felder nie überschrieben werden.
Warum Replace-ähnliche Updates versehentlich Daten löschen
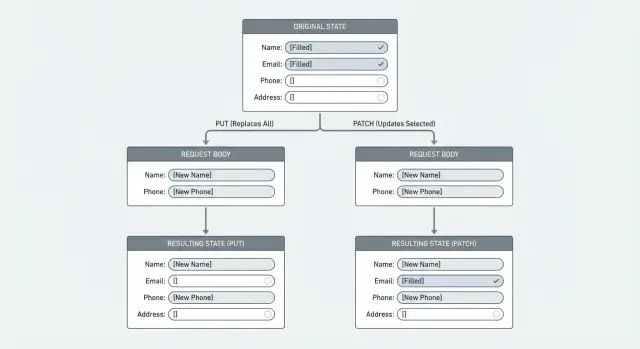
Ein Replace-Update sagt dem Server: „Behandle diesen Request-Body als den vollständigen neuen Datensatz.“ Was immer du sendest, wird zur neuen Wahrheit, und alles, was du nicht einschließt, gilt als nicht mehr vorhanden. So verschwinden Felder.
Das passiert meist, wenn ein Endpoint wie PUT (vollständiger Ersatz) arbeitet, auch wenn alle ihn „Update“ nennen. Der Client sendet eine partielle Nutzlast, das Backend mappt sie aufs Modell und speichert. Wenn ein Feld fehlt, setzen manche Codepfade es auf einen leeren Wert (""), null oder eine Standardeinstellung. Das Ergebnis sieht aus wie ein stilles Löschen.
Beispiel: Ein Benutzer ändert nur seinen Anzeigenamen. Das Formular sendet { "displayName": "Sam" }. Wenn dein Server das ganze Profil ersetzt, können Felder wie phone, address oder marketingOptIn plötzlich null oder false werden, obwohl der Nutzer sie nie angetastet hat.
Das tritt oft auf, wenn Clients nicht (oder nicht vollständig) den kompletten Datensatz senden, z. B.:
- Webformulare, die nur sichtbare Eingaben senden
- Mobile Apps, die nur „geänderte Felder“ schicken, um Bandbreite zu sparen
- Admin-Oberflächen, in denen manche Felder hinter Tabs oder Berechtigungen versteckt sind
Im Test fällt das leicht durch: Ein Test aktualisiert ein Feld und prüft, dass es geändert wurde, aber bestätigt nicht, dass alle anderen Felder gleich geblieben sind. Nutzer merken das später, wenn eine Adresse verschwindet, eine Benachrichtigungseinstellung zurückgesetzt ist oder eine Integration nicht mehr funktioniert.
Der erste Schritt ist, Endpunkte zu finden, bei denen „Update“ wirklich „Replace“ bedeutet.
PUT vs PATCH: was sich ändert und was bleibt
PUT und PATCH beantworten unterschiedliche Fragen.
PUT heißt: „Hier ist die gesamte Ressource. Ersetze, was du hast, damit.“ Wenn der Server PUT als echten Ersatz behandelt, kann alles, was der Client nicht einschließt, entfernt oder zurückgesetzt werden.
PATCH heißt: „Hier sind bestimmte Änderungen. Wende sie auf das bereits Vorhandene an.“ Es ist für partielle Bearbeitungen gedacht, bei denen der Client nur die Felder sendet, die er ändern möchte.
Das ist wichtig, weil sich viele Clients wie Edit-Formulare verhalten. Eine Mobile-App könnte nur { "displayName": "Mina" } senden. Erwartet dein Endpoint ein komplettes Objekt (PUT), aber erhält nur ein Partial, kannst du Felder wie bio, photoUrl oder timezone löschen.
Eine einfache Regel, die die meisten Überraschungen verhindert, ist zu definieren, was „fehlt“ bedeutet:
- Fehlendes Feld: den gespeicherten Wert beibehalten.
- Vorhanden mit Wert: aktualisieren.
- Vorhanden mit
null: löschen, aber nur wenn das explizit erlaubt ist.
Wenn du PUT verwendest, behandle fehlende Felder nicht als „lösche sie“. Behandle fehlende Felder als Fehler, sodass Clients eine vollständige Repräsentation senden müssen.
Wann Full Replace (PUT) sinnvoll ist
Full Replacement kann funktionieren, wenn der Client wirklich das gesamte Dokument besitzt und jedes Mal zuverlässig alle Felder senden kann. Zum Beispiel ein internes Admin-Tool, das einen kleinen Einstellungs-Datensatz bearbeitet, oder ein Sync-Prozess, der immer einen vollständigen Snapshot hat.
Wenn du das nicht garantieren kannst (die meisten öffentlichen APIs können das nicht), verwende für Bearbeitungen PATCH und dokumentiere die Regeln, damit Clients nicht raten.
Wähle und dokumentiere deine Update-Regeln
Die meisten Bugs mit gelöschten Feldern entstehen durch ein Team-Mismatch: der Server denkt „replace“, während der Client „nur geänderte Felder“ sendet. Bevor du Code änderst, entscheide, was jeder Endpoint bedeutet.
Für jeden Update-Endpoint definiere:
- Update-Modus: replace oder patch
- Fehlende Felder: ignorieren oder ablehnen
- Explizites
null: erlaubt zum Löschen oder ablehnen - Ownership: welche Felder der Client bearbeiten darf vs server-eigene Felder
- Validierung: was bei jedem Update geprüft wird
Die Unterscheidung „fehlt vs null“ ist der Punkt, an dem Teams sich verbrennen. Wenn der Client phone weglässt, willst du normalerweise, dass es unverändert bleibt. Wenn der Client "phone": null sendet, kann das „löschen“ bedeuten, aber nur wenn du das erlauben möchtest.
Konsistenz zwischen Web, Mobile und Admin-Tools ist wichtig. Verschiedene Clients senden oft unterschiedliche Payload-Formen, und ein replace-ähnlicher Client kann Daten löschen, die ein anderer Client angelegt hat.
Ein schneller Check: Nimm ein Feld (z. B. timezone) und beschreibe, was passiert bei (1) fehlend, (2) null, und (3) leerer String. Kann das Team das schnell beantworten, sind die Regeln klar genug.
Verwende Feld-Allowlists, um zu steuern, was aktualisiert werden darf
Eine Feld-Allowlist bedeutet, dass der Server nur Änderungen an bestimmten, benannten Feldern akzeptiert. Alles andere wird blockiert oder abgelehnt.
Das hilft auf zwei Arten:
- Es verhindert versehentliche Schreibvorgänge an Feldern, die die UI nie ändern wollte.
- Es stoppt Clients daran, sensible, server-eigene Felder zu aktualisieren.
Server-eigene Felder sollten fast nie über einen normalen „Profil/Settings“-Endpoint schreibbar sein, zum Beispiel:
- role oder permissions
- account status flags
- billing totals
createdAt/updatedAt- interne Flags wie
isAdminoderriskScore
Lehne unbekannte Felder ab, anstatt sie still zu speichern. Stilles Akzeptieren verbirgt Tippfehler, veraltete Clients und unerwartete Payload-Formen.
Verschachtelte Allowlists für komplexe Objekte
Wenn du verschachtelte Objekte wie address oder settings akzeptierst, wende dieselbe Regel innerhalb dieser Objekte an. Allowliste den Top-Level-Key und dann die verschachtelten Keys. So bleibt settings.theme editierbar, während etwas Unsicheres wie settings.isAdmin blockiert wird.
Schritt für Schritt: sichere partielle Updates umsetzen
Ein sicheres partielles Update bedeutet „wende diese Änderungen an“, nicht „ersetze den Datensatz“. Das zuverlässigste Muster ist: lade das Bestehende, wende nur das an, was der Client geschickt hat (und ändern darf), validiere und speichere.
Ein praktischer Implementierungsablauf
Eine wiederholbare Sequenz sieht so aus:
- Lade den aktuellen Datensatz aus der Datenbank (und verifiziere Benutzer-/Mandantenbesitz).
- Baue ein
changes-Objekt aus dem Request-Body mithilfe einer Allowlist. - Validere die Änderungen (Typen, Formate, Längenbegrenzungen, Enums).
- Wende nur Felder an, die im Request vorhanden sind. Schreibe keine Defaults für fehlende Felder.
- Speichere und gib dann den aktualisierten Datensatz zurück, damit der Client erneut synchronisieren kann.
Das vermeidet den häufigen Fehlerfall, bei dem der Client zwei Felder sendet und der Server zehn andere mit leeren Werten überschreibt.
Logging ohne Datenleck
Wenn etwas schiefgeht, willst du Sichtbarkeit, ohne sensible Werte zu speichern. Logge Metadaten wie:
- record id (und user/tenant id)
- welche Feldnamen sich geändert haben
- Validierungsfehler
Logge „updated: displayName, avatarUrl“, nicht den tatsächlichen Anzeigenamen.
Fehlendes, null und Defaults ohne Überraschungen handhaben
Die meisten „meine Daten wurden gelöscht“-Bugs beruhen auf einer Verwirrung: Der Server kann nicht zwischen „Benutzer hat das nicht angetastet“ und „Benutzer will das löschen“ unterscheiden.
Behandle die Nutzlast wie Anweisungen:
- Fehlend bedeutet „beibehalten“.
nullbedeutet „löschen“, aber nur für Felder, bei denen Löschen sinnvoll ist.
Entscheide auch, wie du mit leeren Werten umgehst. Ein leerer String ist nicht dasselbe wie fehlend, und ein leeres Array ist nicht dasselbe wie null. Wenn ein Nutzer alle Tags löscht, sollte "tags": [] die Tags auf keine setzen. Wenn der Client "tags": null sendet, entscheide, ob das „Tags entfernen“ oder „ungültige Eingabe“ bedeutet, und halte dich daran.
Vermeide es, Create-Time-Defaults während Updates anzuwenden. Defaults gehören in Create-Flows. In Update-Flows werden Defaults oft destruktiv.
Schütze vor verlorenen Updates und Race Conditions
Selbst mit PATCH-Semantik können sich zwei Änderungen gegenseitig überschreiben. Das Risiko ist Zeit.
Beispiel: Ein Nutzer öffnet „Profil bearbeiten“ auf Laptop und Telefon. Das Telefon ändert displayName und speichert. Der Laptop, der noch alte Daten anzeigt, ändert später bio. Ohne Freshness-Check kann der zweite Save Teile des ersten überschreiben.
Verwende optimistische Nebenläufigkeitskontrolle, damit der Server veraltete Änderungen ablehnen kann:
- Versionsfeld: speichere eine Ganzzahl wie
profileVersion; nur aktualisieren, wenn sie übereinstimmt. updatedAt-Prüfung: der Client sendet den zuletzt gesehenen Timestamp; der Server aktualisiert nur, wenn er unverändert ist.- ETag + If-Match: der Client beweist, dass er die neueste Version bearbeitet.
Bei Konflikten gib einen klaren Fehler zurück (oft HTTP 409 oder 412) und fordere den Client zum Nachladen auf.
Häufige Fehler, die Felder löschen
Die meisten Datenverluste bei Updates sind kein Datenbankproblem. Es ist ein API-Contract-Problem: Der Server behandelt fehlende Felder als „bitte entfernen“.
Häufige Ursachen:
- PUT-Semantik mit einem Client, der nur geänderte Felder sendet
- Speichern eines vollständigen Objekts, das aus veraltetem Client-State gebaut wurde
- Aktualisieren verschachtelter Objekte als Ganzes statt die Kinder zu patchen (Ersetzen von
addresslöschtaddress.line2, wenn der Client nuraddress.citysendet) - Fehlende Felder mit Defaults während Validierung oder Normalisierung auffüllen
Eine sicherere Denkweise ist einfach:
- Fehlend: in Ruhe lassen
- Null: löschen (nur wenn erlaubt)
- Unbekannt: ablehnen
Schnelle Checks bevor du auslieferst
Bevor du einen Update-Endpoint auslieferst, mach einen Durchlauf mit Fokus auf ein Risiko: Ändert das Aktualisieren eines Feldes aus Versehen andere?
Eine kurze Checkliste:
- Bestätige, dass jeder Update-Pfad dieselben Regeln für fehlend/null befolgt.
- Erzwinge Allowlists auf dem Server (nicht nur in der UI).
- Teste, dass fehlende Felder gespeicherte Daten nicht ändern (aktualisiere nur
displayName, verifiziere, dassemail,phone,addressidentisch bleiben). - Teste, dass
nullnur Felder löscht, die du explizit erlaubst. - Füge eine Concurrency-Prüfung hinzu, damit zwei Änderungen sich nicht gegenseitig überschreiben.
Ein schneller Szenario-Test, der viel findet: Nimm einen echten Datensatz aus Staging mit vielen gesetzten Feldern, sende ein Update mit nur einem Feld und diff den Datensatz nach dem Nachladen. Jede unerwartete Änderung ist ein Warnsignal.
Beispiel: ein Profil-Edit, das nicht gesendete Felder löscht
Ein häufiger Bug sieht harmlos aus: Ein Nutzer ändert sein Profilfoto, klickt Speichern und merkt später, dass seine Telefonnummer weg ist. Nichts hat es absichtlich gelöscht. Es wurde überschrieben.
So passiert es: Der Profilbildschirm lässt nur das Foto ändern, also sendet der Client nur dieses eine Feld. Der Server behandelt die Anfrage als vollständigen Ersatz und schreibt einen neuen Datensatz nur mit dem, was gesendet wurde.
Vorher: Replace-Style Update (löscht Felder)
Existing record in the database:
{
"id": "u_123",
"displayName": "Sam",
"phone": "+1-555-0100",
"photoUrl": "https://cdn.example/old.png"
}
Client sends:
{ "photoUrl": "https://cdn.example/new.png" }
Server does (conceptually):
profile = request.body
save(profile)
Result: phone disappears because it wasn’t included.
Danach: PATCH-Semantik + Feld-Allowlist (behält Felder)
Behandle die Nutzlast statt als Ersatz als Änderungen, und akzeptiere nur die Felder, die der Endpoint bearbeiten darf.
allowed = ["photoUrl"]
changes = pick(request.body, allowed)
profile = loadProfile(userId)
profile = merge(profile, changes)
save(profile)
Jetzt ändert sich nur photoUrl. Alles andere bleibt.
Nächste Schritte: audit deiner Update-Endpunkte und gefährliche Endpoints fixen
Finde jeden Endpoint, der gespeicherte Daten ändern kann (Profile, Einstellungen, Billing, „update status“). Vergleiche für jeden, was in der Speicherung existiert, was der Client sendet und was der Server schreibt. Wenn der Server mehr Felder schreiben kann, als die Anfrage enthält, besteht ein Risiko.
Eine praktische Audit-Checkliste:
- Suche nach Handlern, die komplette Datensätze aus Request-Bodies überschreiben.
- Mach jeden Endpoint entweder echten Replace (und lehne partielle Payloads ab) oder echten Patch (wende nur erlaubte, vorhandene Felder an).
- Füge eine Allowlist pro Endpoint hinzu und lehne unerwartete Felder ab.
- Standardisiere Regeln für fehlend vs null, damit Clients konsistent handeln.
- Prüfe Background-Jobs und Admin-Tools, nicht nur öffentliche APIs.
Wenn du einen AI-generierten Codebestand geerbt hast, sind Update-Endpoints ein häufiger Fehlerpunkt, weil generierte Handler oft standardmäßig auf „replace“ setzen. FixMyMess (fixmymess.ai) konzentriert sich auf Diagnose und Reparatur solcher Produktionsprobleme, einschließlich Verschärfen der Update-Semantik, Hinzufügen von Allowlists und Härtung der Validierung, damit echte Nutzerdaten nicht gelöscht werden.
Häufige Fragen
Should I use PUT or PATCH for updates?
Use PATCH for partial edits so missing fields stay unchanged. Keep PUT only for true full replacements where the client can reliably send the entire resource every time.
Why do fields get wiped when I “update” only one field?
Because a replace-style update treats the request body as the whole new record. Any field you don’t send can get overwritten with null, an empty value, or a default, which looks like a silent deletion.
What’s the safest way to treat missing fields vs null?
Pick one clear rule and enforce it server-side: missing means “leave as-is,” while null means “clear it” only for fields where clearing is allowed. If you can’t safely support clearing, reject null for that field.
Can web forms cause accidental data loss even if the user didn’t touch those fields?
Yes, and it’s common. Many forms only submit visible inputs, so hidden or tabbed fields won’t be included in the payload. If your backend replaces the record, those unsubmitted fields can get reset.
How do I prevent clients from updating fields they shouldn’t touch?
Use a field allowlist per endpoint and only apply changes for keys that are both allowed and present in the request. Unknown fields should be rejected so typos and unexpected payloads don’t quietly change data.
What’s a safe server-side pattern for partial updates?
Load the existing record, build a changes object by picking only allowed keys from the request, validate the changes, then merge and save. Avoid constructing a full model purely from the request body.
How do I handle nested objects like address without wiping subfields?
Don’t treat nested objects as all-or-nothing replacements unless that’s the contract. Patch nested keys individually (for example address.city) so sending one nested field doesn’t wipe siblings like address.line2.
Why are defaults dangerous in update endpoints?
Defaults belong in create flows, not update flows. If you apply defaults during updates, missing fields can get “helpfully” filled with default values and overwrite real stored data.
How do I stop two edits from overwriting each other (race conditions)?
Use optimistic concurrency control so stale clients can’t overwrite newer changes. A version number, an updatedAt check, or ETag/If-Match can let the server reject outdated edits with a clear conflict response.
What’s the quickest test to catch “wiped field” bugs before shipping?
Test with a real record that has many fields set, send an update that changes only one field, then re-fetch and diff the full record. If anything else changed, your update path is doing replacement or applying defaults incorrectly.