Dead-Letter-Queue für Hintergrundjobs: Wiederholungen und sichere Wiedergabe
Erfahren Sie, wie eine Dead-Letter-Queue für Hintergrundjobs Poison Messages abfängt, Retries begrenzt und ein sicheres Replay ermöglicht, ohne Nebenwirkungen zu duplizieren.
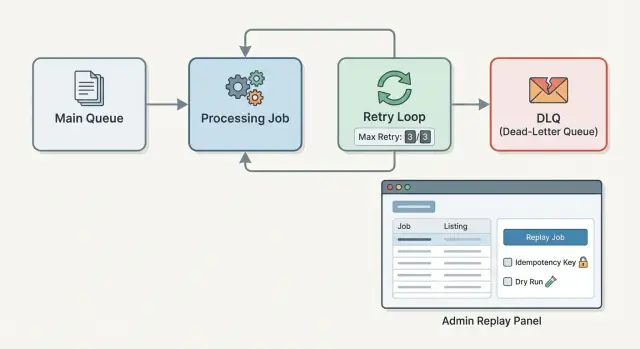
Was schiefgeht, wenn Hintergrundjobs immer wieder fehlschlagen
Ein Hintergrundjob läuft meist im Verborgenen: eine E-Mail senden, eine Karte belasten, ein Bild skalieren, einen Datensatz synchronisieren. Wenn er einmal fehlschlägt, behebt ein Retry das oft. Problematisch wird es, wenn derselbe Job immer wieder fehlschlägt, ohne Grenze und ohne klaren Ablageort.
Solche Jobs nennt man oft „poison message“ oder fehlerhafte Nachricht. Einfach gesagt: eine fehlerhafte Eingabe oder eine kaputte Situation, die den Worker jedes Mal abstürzen lässt. Ursache kann eine fehlerhafte Payload, eine fehlende Datenbankzeile, ein abgelaufener API-Schlüssel oder ein Bug sein, der nur für einen Kunden auftaucht.
Endlose Wiederholungen schaden mehr, als man denkt. Sie können:
- Einen Ausfall verursachen, weil Worker mit denselben fehlerhaften Aufgaben beschäftigt sind, statt gesunde Jobs zu bearbeiten.
- Kosten treiben (mehr Compute, mehr Queue-Operationen, mehr DB-Traffic).
- Logs und Alerts zumüllen, sodass echte Probleme übersehen werden.
- Wiederholte Nebenwirkungen auslösen, z. B. doppelte Abbuchungen oder doppelte Mails, wenn der Job nach der Aktion abstürzt.
Ein häufiges Muster ist der partielle Erfolg. Beispiel: Ihr Job sendet eine E-Mail und stürzt dann ab, bevor er „gesendet“ in die Datenbank schreibt. Der nächste Retry sieht kein „gesendet“-Flag und sendet die E-Mail erneut. Ergebnis: Duplikate, verärgerte Nutzer und eine chaotische Audit-Historie.
Deshalb führen Teams eine Dead-Letter-Queue (DLQ) für Hintergrundjobs ein. Statt endlos zu wiederholen, begrenzen Sie die Versuche und legen den fehlerhaften Job beiseite mit den Fehlerdetails. Dann beheben Sie die Ursache und spielen den Job gezielt wieder ab.
Eine solide Lösung hat drei Teile: eine Retry-Policy, die stoppt bevor es eskaliert, ein DLQ-Eintrag, der das Geschehene bewahrt, und ein Replay-Flow, der Duplikate verhindert. Wenn Sie einen wackeligen Worker geerbt haben (auch einen schnell von einem AI-Tool generierten), verwandeln solche Schutzmaßnahmen ein lautes System in ein vertrauenswürdiges.
Dead-letter-Queues, einfach erklärt
Eine Dead-Letter-Queue (DLQ) ist ein Ablageort für Hintergrundjobs, die fehlgeschlagen sind und nicht weiter automatisch wiederholt werden sollten. Sie ist kein Ort, an dem Arbeit leise verschwindet. Sie macht Fehler sichtbar, überprüfbar und behebbar.
Denkbar ist es wie das Herausschieben eines feststeckenden Jobs aus der Hauptstraße, damit der Rest des Systems weiterläuft. Sie wählen Klarheit statt endloser Retries.
Einige Begriffe, die oft verwechselt werden:
- Retry-Queue: Jobs, die fehlgeschlagen sind, aber später vermutlich erfolgreich sind (z. B. bei vorübergehendem Netzwerkproblem). Sie laufen nach einer Verzögerung erneut.
- DLQ: Jobs, die menschliche Aufmerksamkeit, einen Code-Fix, eine Datenkorrektur oder eine Entscheidung brauchen, bevor man es wieder versucht.
- Parking-Lot-Queue: ein breiterer Eimer, den manche Teams für „nicht dringend“ nutzen. Praktisch wird das oft zur inoffiziellen DLQ ohne klare Regeln.
Wann retryen und wann in die DLQ? Retryen, wenn der Fehler wahrscheinlich vorübergehend und sicher zu wiederholen ist. In die DLQ verschieben, wenn Retries wenig bringen oder Schaden anrichten könnten. Beispiel: "rate limited by provider" ist meist retrybar. "Ungültige Kunden-ID" oder "fehlende Pflichtfelder" benötigen meist Daten- oder Codekorrektur und gehören in die DLQ.
Wenn ein Job in die DLQ verschoben wird, sollte er genug Kontext tragen, um später sicher debuggt und wiedergegeben zu werden:
- Die Job-Payload (genaue Eingaben)
- Fehlermeldung und Stack-Trace (oder Äquivalent)
- Retry-Zähler und Zeitstempel (erstes Auftreten, letzter Versuch)
- Ein stabiler Idempotency-Key oder Job-Fingerprint
- Der zuletzt bekannte Zustand der Nebenwirkung (falls vorhanden), z. B. „Charge erstellt“ oder „E-Mail gesendet"
Dieser letzte Punkt ist wichtig. Eine DLQ fängt nicht nur Fehler ab. Sie macht den nächsten Versuch kontrolliert und informiert möglich.
Entscheiden, was retrybar ist und was nicht
Retries helfen nur, wenn das Problem vorübergehend ist. Bei permanenten Problemen verschwenden Retries Worker-Zeit und verbergen das eigentliche Problem. Das ist die erste Entscheidung hinter jeder DLQ: Was soll erneut versucht werden und was sollte schnell stoppen.
Eine einfache Regel hilft: Retry, wenn der Job später ohne Änderung an Code oder Input Erfolg haben könnte. Wenn er mit derselben Payload nie Erfolg haben kann, retry nicht.
Fehler nach Absicht klassifizieren
Behandeln Sie Ausnahmen nicht alle gleich, sondern ordnen Sie sie wenigen klaren Kategorien zu:
- Transient: Netzwerk-Timeouts, verlorene DB-Verbindung, vorübergehende 5xx-Antworten von einem Provider.
- Throttling: Rate Limits (429), Überschreiten von Quoten, "try again in 60 seconds".
- Not found / fehlender Zustand: verbundener Datensatz gelöscht, Nutzer existiert nicht mehr.
- Ungültige Eingabe: Payload schlägt Validierung fehl, Pflichtfeld fehlt, falsches Format.
- Auth / Permissions: abgelaufene Credentials, entzogenes Recht, verbotene Aktion.
Diese Klassifikation sollte das weitere Vorgehen bestimmen: sofortiger Retry, verzögerter Retry oder Verschieben in die DLQ mit klarer Begründung.
Beispiel: Ein Job, der eine Karte belastet, schlägt mit einem Timeout beim Zahlungsanbieter fehl. Das ist transient, also macht ein Retry Sinn. Wenn der Job aber wegen fehlender Kunden-ID in der Payload fehlschlägt, hilft ein Retry nicht. Ab in die DLQ und jemand muss die Daten (oder den Produzenten des Jobs) korrigieren.
Warum das für Alerts und Replay wichtig ist
Eine DLQ ist kein Lagerplatz. Der Grund, weshalb ein Job dorthin kam, zeigt, was als Nächstes zu tun ist:
- Transiente Fehler deuten oft auf besseren Backoff statt auf einen Menschen hin.
- Ungültige Eingaben bedeuten meist Code- oder Datenkorrektur vor dem Replay.
- Auth-Fehler brauchen oft Key-Rotation, bevor etwas unternommen wird.
Das macht Replay sicherer. Wenn ein Job in der DLQ wegen „ungültiger Payload“ liegt, kann Ihr Admin-Tool Replay standardmäßig blockieren und zuerst um eine Korrektur bitten. Viele übernommene Worker scheitern, weil alles als "retryable" behandelt wird, bis jemand klare Kategorien und Abbruchregeln hinzufügt.
Eine Retry-Policy, die Ihr System nicht schmilzt
Retries sind nützlich, aber unkontrollierte Retries können aus einem kaputten Job einen systemweiten Ausfall machen. Eine gute Policy begrenzt Schaden, verteilt Last über die Zeit und stoppt früh, wenn ein Job offensichtlich nicht funktionieren wird.
Maximale Versuche sollten zum Fehlertyp passen. "One size fits all" führt dazu, dass Sie die falschen Dinge wiederholen. Ein flaky Netzwerkaufruf mag 5–10 Versuche rechtfertigen. Eine fehlerhafte Payload (fehlende Pflichtfelder) sollte nicht 10 Versuche bekommen – sie gehört schnell in die DLQ. Behandeln Sie die DLQ als Ablage, wenn Ihr Retry-Budget aufgebraucht ist.
Backoff und Jitter, einfach erklärt
Backoff heißt, dass die Wartezeit zwischen den Versuchen zunimmt. Das gibt den Downstream-Services Zeit zur Erholung und verhindert, dass Worker denselben Endpunkt zu sehr belasten.
- Fixed Backoff: bei jedem Retry dieselbe Wartezeit.
- Exponentieller Backoff: die Wartezeit wächst mit jedem Versuch.
- Jitter: ein kleines zufälliges Offset, damit viele Jobs nicht zur gleichen Sekunde retryen.
Beispiel: Ihr Zahlungsanbieter hat eine kurze Störung. Ohne Jitter retryen alle fehlschlagenden Jobs genau nach 30 Sekunden und verursachen eine zweite Welle von Fehlern.
Zeitlimits, die „endlosen Schmerz“ verhindern
Setzen Sie zwei Zeitmesser:
- Per-Attempt-Timeout (wie lange ein einzelner Versuch laufen darf, bevor er abgebrochen wird).
- Gesamtzeitfenster (wie lange Sie bereit sind, insgesamt zu retryen, bevor Sie aufgeben).
Ein praktischer Default für viele Teams ist: 3–5 Versuche, exponentieller Backoff ab 10–30 Sekunden, kleines Jitter (z. B. 0–10 Sekunden), ein Per-Attempt-Timeout passend zur normalen Aufrufdauer und ein Gesamtfenster von 15–60 Minuten. Ziel ist nicht Perfektion, sondern das Stoppen von runaway-Retries, bevor sie sich stapeln und gesunde Arbeit blockieren.
Was Sie speichern sollten, wenn ein Job in die DLQ wandert
Wenn ein Hintergrundjob in einer DLQ landet, speichern Sie nicht nur eine "fehlgeschlagene Nachricht". Sie legen eine Akte an, die jemand später braucht, um den Fehler zu verstehen, zu beheben und sicher erneut auszuführen.
Beginnen Sie mit den minimalen Daten, die nötig sind, um den Fehler zu reproduzieren und die richtige Entscheidung zu treffen. Ein guter DLQ-Eintrag enthält üblicherweise:
- Job-Typ (welcher Worker ihn behandeln sollte) und Version (falls sich die Payload-Struktur über die Zeit ändert)
- Original-Payload (wie empfangen) plus eine redigierte, admin-sichere Zusammenfassung
- Versuchsanzahl und Retry-Historie (wie oft und warum es immer wieder fehlschlug)
- Zeitstempel: zuerst gesehen, letzter Versuch, in die DLQ verschoben
- Fehlerdetails: letzte Fehlermeldung/Stack + wenn möglich die Root-Cause-Kette
Eine stabile Job-ID ist kritisch. Generieren Sie eine beim Erstellen des Jobs und behalten Sie sie über Retries und Replays. Fügen Sie dann einen Dedupe- bzw. Idempotency-Key hinzu, der die reale Nebenwirkung beschreibt (z. B. „send_invoice_email:invoice_123:recipient_456"). Das ermöglicht Replay ohne doppelte Aktionen.
Seien Sie vorsichtig mit dem, was Admins sehen. Payloads enthalten oft Geheimnisse, Tokens oder persönliche Daten. Speichern Sie die rohe Payload nur, wenn unbedingt nötig, und legen Sie zusätzlich ein redigiertes Feld ab (z. B. Nutzer-ID statt kompletter E-Mail; nur die letzten 4 Ziffern einer Karte statt des vollständigen Tokens).
Zum Schluss: Bewahren Sie sowohl die letzte Fehlermeldung als auch die ursprüngliche Ursache, wenn möglich. Beispiel: Ein Job endet mit „Timeout beim Provider“, die Root-Cause war aber „fehlender API-Key“. Wenn Ihre DLQ die Kette speichert, ist die Lösung klar und das Replay sicherer.
Schritt für Schritt: DLQ und begrenzte Retries im Worker einbauen
Behandeln Sie jeden Joblauf wie eine kleine Transaktion: Entweder er ist abgeschlossen, oder er schlägt so fehl, dass Sie später etwas damit anfangen können. Eine DLQ ist einfach der Ort, wo Jobs landen, bei denen gilt: "wir haben genug versucht, jetzt muss ein Mensch schauen".
Ein einfacher Ablauf, der in den meisten Stacks funktioniert:
- Führen Sie den Handler innerhalb eines try/catch (oder Äquivalent) aus, das einen typisierten Fehler erfasst, nicht nur eine String-Meldung.
- Bei Fehlern erhöhen Sie den Attempt-Zähler und berechnen die nächste Laufzeit mit Backoff (z. B. 1m, 5m, 20m) plus etwas Jitter, damit die Retries sich nicht ballen.
- Wenn der Fehler klar nicht retrybar ist (falscher Input, fehlender Datensatz, permission denied) oder die Versuche das Limit erreicht haben, verschieben Sie den Job in die DLQ statt ihn erneut einzuplanen.
- Triggern Sie ein Alert mit genug Kontext zum Debuggen (Job-Typ, ID, Attempt, Fehlerklasse, zuerst gesehen). Vermeiden Sie, komplette Payloads in Alerts zu dumpen – sie enthalten oft Geheimnisse oder persönliche Daten.
- Tracken Sie ein paar Zähler, damit Probleme früh auffallen.
try {
handle(job)
markDone(job)
} catch (err) {
attempts = job.attempts + 1
if (!isRetryable(err) || attempts >= MAX_ATTEMPTS) {
moveToDLQ(job, err)
alert(job, err)
} else {
reschedule(job, backoff(attempts))
}
}
Für Dashboards brauchen Sie nichts Kompliziertes. Tracken Sie laufende Jobs, Jobs, die für einen Retry geplant sind, DLQ-Tiefe und "DLQ hinzugefügt pro Stunde".
Doppelte Nebenwirkungen beim Replay verhindern
Replay eines fehlgeschlagenen Jobs ist die eigentliche Gefahr. Der ursprüngliche Job könnte den gefährlichen Teil (Karte belasten, E-Mail senden, eine Zeile schreiben) bereits ausgeführt haben und dann beim Logging, Status-Update oder einem zweiten Schritt abgestürzt sein. Wenn Sie aus der DLQ ohne Schutz neu ausführen, können Sie doppelt belasten, doppelt mailen oder doppelte Datensätze erzeugen.
Die einfachste Schutzmaßnahme ist Idempotenz. Einfach gesagt: dieselbe Anfrage soll dasselbe Ergebnis bringen, auch wenn sie zweimal ausgeführt wird. Ihr Job sollte erkennen können: „Das habe ich bereits gemacht“ und ohne erneute Nebenwirkung beenden.
Praktische Ansätze:
- Idempotency-Keys: generieren Sie einen stabilen Key pro realer Aktion (z. B.
invoice_123_charge) und speichern Sie das Ergebnis. Beim Replay prüfen Sie zuerst den Key. - Unique-Constraints: lassen Sie die Datenbank „nur einmal“ durchsetzen (eine Auszahlung pro Bestellung, eine Willkommens-Mail pro Nutzer) und behandeln Sie Duplikate als Erfolg.
- Outbox-Pattern: schreiben Sie die Absicht einmal in die DB und lassen einen separaten Sender die Zustellung übernehmen. Replays prüfen und senden nur, was noch aussteht.
Ein gutes Modell ist "write once, send later." Zuerst halten Sie eine dauerhafte Tatsache wie "Zahlung für Bestellung 8821 autorisiert" in einer Transaktion fest. Danach rufen Sie den externen Service auf. Stirbt der Job dazwischen, sieht ein Replay den gespeicherten Fakt und erledigt nur das noch ausstehende Minimum.
Beispiel: Ein Job sendet nach einem Kauf eine Receipt-Mail. Er sendet die Mail und stürzt dann ab, bevor er receipt_sent=true markiert. Ein Replay würde die Mail erneut senden. Beheben Sie das, indem Sie receipt_sent_at mit einem eindeutigen Key wie receipt:{order_id} vor dem Senden speichern oder die Mail in einer Outbox-Tabelle ablegen und ein dedizierter Sender die Lieferung übernimmt.
Einen Admin-Replay-Flow bauen, der standardmäßig sicher ist
Wenn Leute defekte Jobs mit einem Klick neu ausführen können, werden sie das tun. Der Admin-Flow muss mit Fehlern, Druck und teilweisem Kontext rechnen. "Safe by default" bedeutet: Die einfachste Aktion ist auch die sicherste.
Beginnen Sie mit ein paar Ansichten, die die Grundlagen schnell beantworten:
- DLQ-Liste: filterbar nach Jobtyp, Fehlerklasse, Datum und Umgebung.
- Detailansicht: Payload, Idempotency-Key, Header/Metadaten und die genaue Fehlermeldung.
- Replay: Optionen für sofortiges Replay vs. Zeitplanung, Einzel- vs. Batch-Replay.
- Dismiss/Resolve: Möglichkeit, mit Grund als „wird nicht behoben“ zu markieren.
Auf der Detailansicht zeigen Sie die Attempt-Historie: Zeitstempel, Worker-Version, Retry-Count und aufgezeichnete Nebenwirkungen (z. B. „Invoice #1234 erstellt“). Daraus resultieren gute Entscheidungen.
Die Replay-Kontrollen sollten den Operator zur Absicht zwingen. Batch-Replay sollte eine Filter-Vorschau verlangen ("32 Jobs stimmen überein") und eine zweite Bestätigung, die den Jobtyp und das Risiko der Nebenwirkung nennt ("kann Mails senden"). Ein Dry-Run-Modus ist sinnvoll: prüfen Sie Eingaben und Abhängigkeiten, ohne Schreibvorgänge oder externe Calls auszuführen, und zeigen Sie dann das Ergebnis an.
Guardrails verhindern, dass Replay aus einem schlechten Job zwei schlimme Ergebnisse macht:
- Blockieren Sie Replay, wenn derselbe Idempotency-Key bereits erfolgreich war.
- Standardmäßig Batch-Aktionen planen (ein paar Minuten später), statt sofort auszuführen.
- Bei nicht-idempotenten Jobs eine explizite Wahl verlangen.
- Replay-Raten pro Jobtyp begrenzen, um Peaks zu vermeiden.
- Immer einen Audit-Eintrag schreiben.
Berechtigungen sind wichtig. Begrenzen Sie Replay auf eine kleine Rolle und protokollieren Sie, wer wann warum replayt hat.
Häufige Fehler und Fallen
Die meisten DLQ-Setups scheitern an banalen Gründen: Regeln sind unklar, Retries zu aggressiv oder Replay wird wie ein harmloser Knopf behandelt.
Typische Fallen (und wie man sie vermeidet):
- Retry auf alles, für immer. Wenn jeder Fehler mit "nochmal versuchen" beantwortet wird, lernt man nie, was wirklich kaputt ist. Definieren Sie klare DLQ-Regeln (falsche Eingabe, fehlende Datensätze, Auth-Fehler, 4xx von Drittanbietern) und verschieben Sie solche Jobs schnell aus dem heißen Pfad.
- Kein Limit + kein Backoff = Retry-Stürme. Eine einzige Störung kann in eine Flut umschlagen, die Ihr gesamtes System verlangsamt. Setzen Sie Max-Attempts, nutzen Sie exponentiellen Backoff mit Jitter und stoppen Sie Retries bei eindeutig nicht-temporären Fehlern.
- Ein Replay-Button, der Nebenwirkungen verdoppeln kann. Replays, die bereits belastete Karten oder verschickte Mails erneut auslösen, sind gefährlich. Machen Sie Handler idempotent (Idempotency-Key, Unique-Constraint oder Marker "already processed") und gestalten Sie Replay sicher, selbst wenn es zweimal gedrückt wird.
- Geheimnisse in Payloads oder Fehlern loggen. DLQs speichern oft die Original-Job-Body. Enthält das Tokens, Passwörter oder vollständige Kundendaten, entsteht eine stille Leckage. Redigieren Sie sensible Felder vor dem Enqueueing und säubern Sie Fehlermeldungen, bevor Sie sie speichern.
- Die DLQ als Langzeitlager. Ohne Verantwortung wird eine DLQ zur Grablege. Setzen Sie einen Owner, eine Aufbewahrungsrichtlinie und planen Sie Cleanup. Tracken Sie einige Metriken (DLQ-Größe, Alter des ältesten Eintrags, Replay-Erfolgsrate), damit es unter Kontrolle bleibt.
Eine einfache Regel: Ihre DLQ sollte ein kurzfristiges Untersuchungs-Postfach sein, kein Ablageort für alles. Wenn sie wächst, ist das ein Produkt- oder Ops-Problem, und jemand muss es beheben.
Beispiel: ein fehlgeschlagener E-Mail-Job, der nicht zweimal senden darf
Ein Nutzer registriert sich, und Ihre App legt einen Hintergrundjob "Willkommens-E-Mail senden" an. Der Job enthält user_id, to_email, template_id und ein send_id (ein eindeutiger Idempotency-Key für diese E-Mail).
Bei einer Anmeldung ist die Adresse fehlerhaft wie alex@@example.com. Der Worker ruft den E-Mail-Provider auf, bekommt ein 400 "invalid recipient" und schlägt fehl.
Ihre Retry-Policy versucht es ein paar Mal erneut (z. B. 3 Versuche innerhalb von 10 Minuten) in der Hoffnung, es sei temporär. Jeder Versuch schlägt gleich fehl, also wird der Job mit einem klaren, nicht-retrybaren Grund in die DLQ verschoben: „Invalid email format: alex@@example.com“. Dieser eine Satz hilft einem Admin, das Problem zu beheben, ohne Stacktraces zu wälzen.
Während des Vorfalls sollten Logs und Metriken die Geschichte deutlich machen:
- Job-Versuche: 3 (alle mit demselben 400 gescheitert)
- DLQ-Anzahl: +1 (getaggt
reason=invalid_recipient) - E-Mail-Sends: 0 (keine Provider-Message-ID gespeichert)
- Time-to-DLQ: 10m (zeigt, dass Retries begrenzt sind)
Ein Admin öffnet den DLQ-Eintrag, korrigiert die Eingabe (oder den Nutzer-Datensatz) und klickt auf Replay. Der Replay-Flow sollte standardmäßig sicher sein: Er legt den Job mit demselben send_id wieder in die Queue, und der Worker prüft zuerst eine sent_emails-Tabelle. Gibt es dort bereits einen Eintrag für send_id, beendet er sich. Falls nicht, sendet er die Mail, speichert die Provider-Message-ID und markiert den Job als erledigt.
Um denselben Fehler in Zukunft zu vermeiden: frühzeitig validieren (schlechte E-Mails vor Enqueue ablehnen) und Idempotenz bei jeder Nebenwirkung sicherstellen (E-Mails, Abbuchungen, Webhooks).
Schnelle Checkliste und nächste Schritte
Eine DLQ hilft nur in Produktion, wenn die langweiligen Details stimmen. Genau diese Details verhindern, dass Fehler zu Duplikaten, Ausfällen oder stillen Datenproblemen werden.
Checkliste für Retries und DLQ-Erfassung:
- Begrenzen Sie Versuche und definieren Sie Backoff (z. B. 5 Versuche mit exponentiellem Backoff und Jitter) sowie ein hartes Timeout pro Versuch.
- Schreiben Sie auf, was retrybar ist und was nicht (Netzwerk-Hiccups, 429/503, temporäre DB-Locks sind retrybar); alles andere sollte standardmäßig nicht-retrybar sein.
- Fügen Sie eine Abbruchbedingung für Poison Messages hinzu (gleiche Fehlersignatur wiederholt, ungültige Payload, fehlende Felder), damit sie früh in die DLQ gehen.
- Speichern Sie DLQ-Grunddaten: Job-Typ, Argumente (redigiert), Versuchszähler, letzte Fehlerklasse und -nachricht, Stacktrace, Zeitstempel und Worker-Version.
- Redigieren Sie Geheimnisse und persönliche Daten bevor Sie etwas speichern (Tokens, Passwörter, vollständige E-Mails, rohe Request-Bodies) und führen Sie ein Audit-Protokoll, wer was geändert hat.
Checkliste für sicheres Replay:
- Wählen Sie eine Idempotenz-Strategie pro Jobtyp (Idempotency-Key, Unique-Constraint oder Marker "already processed") und testen Sie sie, indem Sie denselben Job zweimal wiedergeben.
- Trennen Sie Replay von Retry: Replay sollte eine menschliche Entscheidung erfordern und idealerweise mit einem Kommentar versehen werden.
- Rechte beschränken (Admin-only), eine eindeutige Bestätigung einfordern und eine Vorschau zeigen, was passieren wird (inkl. Nebenwirkungen wie Zahlungen oder E-Mails).
- Legen Sie fest, welche Änderungen vor Replay erlaubt sind (Payload editieren, Ziel ändern, Config überschreiben) und protokollieren Sie jede Bearbeitung.
- Schreiben Sie nach dem Replay das Ergebnis zurück (erfolgreich, erneut fehlgeschlagen mit neuer Fehlermeldung oder abgebrochen), damit die DLQ kein schwarzes Loch wird.
Wenn Ihre Codebasis von AI generiert wurde und Retry-, Idempotency- und sicheres Replay-Design fehlen, kann FixMyMess (fixmymess.ai) helfen, den Worker und das Queue-Verhalten zu diagnostizieren, die Logik zu reparieren und für Produktion zu härten.
Häufige Fragen
What is a “poison message” in a background job queue?
Eine "poison message" ist ein Job, der bei jeder Ausführung mit denselben Eingaben fehlschlägt, sodass Wiederholungen nicht helfen. Die Lösung besteht darin, automatische Wiederholungen früh zu stoppen, den Job mit Fehler- und Payload-Details in eine DLQ zu verschieben und dann Code oder Daten zu korrigieren, bevor man ihn absichtlich erneut ausführt.
What’s the difference between a retry queue and a dead-letter queue (DLQ)?
Eine Retry-Warteschlange ist für Fehler gedacht, die wahrscheinlich vorübergehend sind und die man sicher wiederholen kann (z. B. Timeouts oder kurzzeitige Ausfälle). Eine DLQ ist für Jobs gedacht, die zuerst eine Entscheidung oder eine Korrektur brauchen (z. B. ungültige Payloads, fehlende Datensätze, Berechtigungsprobleme), damit sie die Worker nicht weiter verstopfen.
How many retries should a background job get before going to the DLQ?
Ein praktikabler Startpunkt sind nur wenige Versuche mit zunehmenden Verzögerungen und ein harter Stopp nach einem festgelegten Zeitfenster. Beginnen Sie mit 3–5 Versuchen und exponentiellem Backoff; wenn das Retry-Budget aufgebraucht ist, sollte der Job in die DLQ wandern, damit ein einzelner schlechter Job nicht das ganze System ausbremst.
How do I decide what errors are retryable vs non-retryable?
Retryen Sie nur, wenn dieselbe Payload später ohne Änderungen an Code oder Daten erfolgreich sein könnte. Timeouts, vorübergehende 5xx-Fehler und kurzzeitige DB-Verbindungsprobleme sind meist retryable; ungültige Eingaben, fehlende Pflichtfelder und “not found”-Zustände gehören normalerweise schnell in die DLQ.
What should I store when a job is moved to the DLQ?
Speichern Sie genug, um den Fehler zu reproduzieren und sicher wiederzugeben: Jobtyp, Payload (sensitiv redigiert), Anzahl der Versuche und Zeitpunkte sowie die vollständigen Fehlerinformationen. Legen Sie außerdem eine stabile Job-ID und einen Idempotency-Key an, damit ein Replay erkennt, ob die Aktion bereits ausgeführt wurde.
How do I prevent double charges or duplicate emails when replaying DLQ jobs?
Idempotenz ist der wichtigste Schutz: Der Job muss so gestaltet sein, dass ein zweiter Lauf das gleiche Ergebnis liefert, ohne die Nebenwirkung zu wiederholen. Verwenden Sie einen stabilen Idempotency-Key, erzwingen Sie eine Unique-Constraint für die reale Aktion oder speichern Sie vor dem externen Call ein "already processed"-Marker, damit Replays nicht doppelt belasten (Charges, E-Mails etc.).
What does a safe admin replay flow look like?
Lassen Sie das Replay Absicht erfordern und bauen Sie Schutzmechanismen ein: zeigen Sie Payload und Fehler, blockieren Sie Replay, wenn der Idempotency-Key bereits erfolgreich war, und protokollieren Sie, wer was und warum erneut ausgeführt hat. Bei Unsicherheit zuerst einzelnes Replay testen, bevor Sie Batch-Replays erlauben.
Why are endless retries so dangerous in production?
Endlose Wiederholungen können dazu führen, dass Worker blockiert werden und aus einem einzelnen schlechten Job ein Ausfall entsteht. Sie treiben Kosten für Compute und Queues in die Höhe, überschwemmen Alerts mit Rauschen und erhöhen die Chance für wiederholte Nebenwirkungen bei partiellen Erfolgen.
How do I avoid leaking secrets or personal data through DLQ payloads and errors?
Bereinigen Sie Payloads und Fehlerinformationen, bevor Sie sie speichern oder anzeigen, denn Jobs enthalten oft Tokens, Zugangsdaten oder personenbezogene Daten. Halten Sie für Admins eine redigierte Zusammenfassung bereit, speichern Sie nur, was wirklich zum Debuggen nötig ist, und vermeiden Sie, dass Logs oder Alerts rohe Geheimdaten ausgeben.
Can FixMyMess help if my background job system was generated by an AI tool and keeps failing?
Ja. Besonders wenn Worker und Retry-Logik schnell von einem AI-Tool generiert wurden und Idempotenz sowie sicheres Replay nie vorgesehen waren. FixMyMess (fixmymess.ai) kann die Queue- und Worker-Logik prüfen, die Ursachen für Fehler und Duplikate finden und den Code für den Produktionseinsatz reparieren und härten, oft innerhalb von 48–72 Stunden nach einem kostenlosen Code-Audit.