Doppelte Benutzerkonten verhindern mit eindeutigen Constraints und sicheren Backfills
Erfahre, wie du doppelte Benutzerkonten mit normalisierten Werten, eindeutigen Datenbank-Constraints und einem sicheren Backfill-Plan verhinderst — ohne Ausfallzeiten oder Datenverlust.
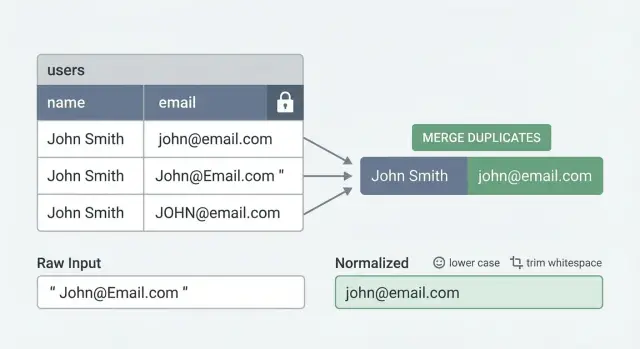
Das eigentliche Problem: warum doppelte Benutzer weiterhin auftreten
Doppelte Benutzer sehen selten so aus, als wäre dieselbe E-Mail zweimal exakt gleich eingetippt worden. Meist treten sie durch kleine Unterschiede auf, die Menschen als dieselbe Person wahrnehmen, die Datenbank aber als verschiedene Werte.
Häufige Beispiele:
- Gleiche E-Mail, unterschiedliche Groß-/Kleinschreibung:
[email protected]vs[email protected] - Versteckte Leerzeichen:
[email protected]vs[email protected] - Mehrere Anmeldewege: ein Konto mit Passwort erstellt, später ein weiteres per Google oder GitHub mit derselben E-Mail
- Unterschiedliche Erstellungszeitpunkte: ein User-Datensatz während des Checkouts erstellt, dann ein weiterer während des Onboardings
- Provider-Eigenheiten:
[email protected]einmal verwendet,[email protected]ein anderes Mal (manche Apps wollen diese zusammenführen, andere nicht)
Für Kund:innen wirkt das zufällig. Jemand meldet sich mit „der anderen“ Methode an und landet im „anderen“ Konto. Abrechnungen können sich aufsplitten, sodass eine zahlende Person als nicht zahlend erscheint. Support-Fälle werden zu Detektivarbeit, weil „Ich sehe meine Projekte nicht“ oft heißt „du hast zwei Konten und deine Daten sind im anderen.“ Auch Analytics wird unzuverlässig, Retention und Conversion werden dadurch schwerer zu interpretieren.
Teams versuchen oft, Duplikate im UI zu verhindern: Submit-Button deaktivieren, „E-Mail existiert bereits“ anzeigen oder vor dem Anlegen prüfen. Das hilft, ist aber nicht ausreichend. Deine Datenbank kann von Mobile-Apps, Backend-APIs, Admin-Panels, Importen, Hintergrundjobs, Webhooks und Retries beschrieben werden. Zwei Requests können sich außerdem überlappen: beide prüfen „existiert diese E-Mail?“ gleichzeitig, beide sehen „nein“ und beide fügen ein.
Datenbankseitiger Schutz ist anders. Die Datenbank setzt die Regel bei jedem Schreibvorgang durch, egal woher er kommt. Du definierst, was einzigartig sein muss (oft eine normalisierte E-Mail oder eine Kombination wie provider + provider_user_id) und die Datenbank lehnt Inserts/Updates ab, die einen zweiten Datensatz mit derselben Identität erzeugen würden. Diese Leitplanke macht aus „wir versuchen Duplikate zu vermeiden“ ein echtes „Duplikate können nicht mehr passieren."
Wie Duplikate üblicherweise entstehen
Doppelte Benutzer entstehen, wenn die App davon ausgeht, die Datenbank würde das „schon regeln“. Wenn die DB keine Einzigartigkeit erzwingt, werden Randfälle zu vielen Zeilen für dieselbe Person, und man versucht, Duplikate allein per Anwendungscode zu verhindern.
Ein häufiger Grund ist eine Race-Condition beim Signup. Zwei Requests können fast gleichzeitig eintreffen (Doppelklick, schlechte Verbindung, zwei Tabs). Wenn beide zuerst „prüfen, ob der Nutzer existiert“ und bevor einer inserted, entscheiden beide, der Nutzer sei neu.
Eine weitere Quelle sind mehrere Einstiegspfade, die Nutzer anlegen: Web, Mobile, Admin, CSV-Import, Invite-Flow, Support-Tool. Jeder Pfad entwickelt über die Zeit eigene Regeln. Der eine trimmt E-Mails, der andere nicht. Der eine prüft bestehende Nutzer, der andere überspringt die Prüfung „nur für dieses Feature“.
OAuth kann Identitäten ebenfalls trennen. Jemand meldet sich mit E-Mail/Passwort an und klickt später „Mit Google fortfahren“ mit derselben E-Mail. Wenn das OAuth-Callback einen neuen Nutzer anlegt statt die Identität zu verknüpfen, hast du zwei Konten, die beide gültig aussehen.
Unterschiede in der Eingabeformatierung sorgen für heimtückische Duplikate:
- Unterschiede in Groß-/Kleinschreibung und Leerzeichen ("[email protected]" vs "[email protected] ")
- Unterschiede in Telefonnummernformaten ("+1 555 123 4567" vs "5551234567")
- Optionale Felder, die später eintreffen (Benutzer startet mit Telefon, fügt später E-Mail hinzu)
- Internationale Varianten (Ländervorwahlen, führende Nullen)
- Unicode-Optical-Glitches (selten, aber möglich)
Retries und Timeouts sorgen ebenfalls dafür. Wenn ein Client keine Antwort bekommt (Netzwerkstörung, Gateway-Timeout), kann er automatisch erneut senden. Wenn dein Server jeden Retry als neuen Signup behandelt statt als dieselbe Aktion, erzeugst du Duplikate. Das ist besonders häufig in Prototypen, wo Signup-Logik über Routen kopiert wird ohne Idempotenz oder DB-Constraints.
Definiere, was „einzigartiger Nutzer" für dein Produkt bedeutet
Bevor du Constraints setzt, entscheide, was ein „einzigartiger Nutzer“ in deinem System ist. Viele Duplikate entstehen, weil das Produkt mehrere Identitätsbegriffe hat.
Beginne mit den Identifikatoren, denen du vertraust: E-Mail, Telefonnummer und externe Provider-IDs (Google subject, GitHub id, Enterprise SSO subject). Wenn du mehrere Anmeldewege unterstützt, entscheide, ob sie alle auf eine einzelne Nutzerzeile zeigen oder ob jede Methode ihre eigene Zeile erzeugt, die später verknüpft wird.
Geh dann die komplizierten Fälle explizit an:
- Was, wenn die E-Mail leer, unverifiziert oder versteckt ist (Apple private relay)?
- Erlaubst du Gastnutzer ohne Registrierung?
- Wenn E-Mail
NULLsein kann: Sind mehrereNULL-E-Mails erlaubt (oft ja) und wie wird ein Gast zum echten Konto?
Der Mandanten- oder Workspace-Scope ist genauso wichtig. Gilt Einzigartigkeit global oder pro Tenant? In vielen B2B-Apps darf dieselbe E-Mail in verschiedenen Workspaces existieren, muss aber innerhalb eines Workspaces einzigartig sein. In Consumer-Apps willst du meist globale Einzigartigkeit.
Ein konkretes Szenario zum Entscheiden: Jemand meldet sich Montag mit Google an und Dienstag per E-Mail/Passwort mit derselben E-Mail. Wenn deine Definition „eine Person = eine Zeile" ist, brauchst du eine Merge-Regel, und du solltest sie dokumentieren.
Eine einfache Merge-Policy:
- Wähle einen „primären“ Datensatz (verifizierte E-Mail gewinnt; sonst zuletzt aktive).
- Behalte sicherheitskritische Felder vom Primary (Passworthash, MFA-Settings).
- Merghe Profilfelder (Name, Avatar) nur, wenn sie beim Primary fehlen.
- Zeige verknüpfte Daten (Bestellungen, Mitgliedschaften, API-Keys) auf das Primary.
- Schreibe eine Audit-Notiz, damit du später erklären kannst, was passiert ist.
Schreibe diese Regeln in einfachem Klartext, bevor du an die Datenbank gehst. Das sorgt dafür, dass Engineering, Support und Product abgestimmt sind, wenn echte Randfälle auftauchen.
Normalisiere Eingaben, damit die DB Einzigartigkeit erzwingen kann
Unique-Constraints funktionieren nur, wenn die Werte, die du speicherst, konsistent sind. Wenn dieselbe Person sich als [email protected], [email protected] und [email protected] anmelden kann, sieht die DB drei verschiedene Strings.
Normalisierung bedeutet, ein Speicherformat für dieselbe Identität zu wählen und dieses Format immer in der DB zu schreiben. Das ist der stille Schritt, der einen Unique-Constraint tatsächlich wirksam macht.
Was normalisieren (und worauf achten)
Bei E-Mails: Starte einfach: Trim und Lowercase vor dem Speichern. Entscheide, wie du mit Plus-Addressing umgehst ([email protected]). Manche Teams entfernen den +...-Teil, um Duplikate zu reduzieren, aber das ist provider-spezifisch und nicht immer sicher. Ein sicherer Default ist Lowercase + Trim; Plus-Addressing nur behandeln, wenn es zu deinen Produktregeln passt.
Bei Telefonnummern: Speichere ein konsistentes Format, idealerweise mit Ländervorwahl und nur Ziffern. Sonst können +1 (415) 555-0123 und 4155550123 die Einzigartigkeit umgehen.
Bei Nutzernamen: Passe das an das Produktverhalten an. Wenn dein UI Jane und jane als gleich behandelt, sollte das Backend vor dem Insert genauso normalisieren.
Ein praktisches Muster ist, beides zu speichern:
- Raw input (was der Nutzer eingegeben hat, nützlich für Anzeige und Support)
- Normalisierter Wert (auf den du Einzigartigkeit durchsetzt)
Backend-Throughput schlägt Frontend-Hinweise
Normalisiere im Backend bei jedem Erstellen/Aktualisieren eines Nutzers. Frontend-Prüfungen verbessern die UX, sind aber leicht zu umgehen (alte Clients, mehrere Apps, direkte API-Aufrufe).
Ein häufiger Fehler: Ein Gründer importiert Nutzer per CSV während Anmeldungen laufen. Der Import behält Groß-/Kleinschreibung, das Signup-Formular lowercaset, und plötzlich hast du zwei Konten für dieselbe E-Mail. Backend-Normalisierung plus eine normalisierte Unique-Constraint verhindert diese Spaltung.
Wähle die richtige Unique-Constraint für dein Schema
Eine Unique-Constraint ist eine Regel, die die DB erzwingt: keine zwei Zeilen dürfen denselben „einzigartigen“ Wert teilen. Ein Unique-Index ist die Mechanik, die den Check schnell macht. Viele Datenbanken legen bei einer Unique-Constraint automatisch einen Unique-Index an, sodass der praktische Unterschied meist in der Absicht liegt.
Das Schwierige ist, die richtigen Spalten auszuwählen. „E-Mail muss einzigartig sein“ klingt simpel, bricht aber schnell zusammen, sobald Tenants, mehrere Sign-in-Provider, optionale E-Mails oder Soft-Deletes ins Spiel kommen.
Wann Composite Uniqueness sinnvoll ist
Wenn Nutzer zu einem Workspace oder Tenant gehören, will man Einzigartigkeit oft nur innerhalb dieses Tenants, nicht global. Das wird eine Composite-Regel, z. B.:
tenant_id + normalized_email(gleiche E-Mail in verschiedenen Tenants erlaubt)provider + provider_user_id(wahre Identität bei OAuth logins)tenant_id + provider + provider_user_id(wenn dieselbe Provider-Identität mehreren Tenants beitreten kann)
Composite-Constraints helfen auch, wenn du sowohl Passwort-Login als auch OAuth unterstützt. So kannst du starke Regeln für jede Identitätsart durchsetzen, ohne ein Feld (wie E-Mail) alles regeln zu lassen.
Partielle Einzigartigkeit und Soft-Deletes
Echte Daten sind unordentlich. Manche Nutzer haben noch keine E-Mail, oder du erlaubst telefonbasierte Konten. Dann enforce Einzigartigkeit nur, wenn der Wert existiert (partielle Regel). Ein Beispiel: „E-Mail muss einzigartig sein, aber nur für Zeilen, in denen E-Mail vorhanden ist."
Soft-Deletes erzwingen eine weitere Entscheidung. Wenn Nutzer als gelöscht markiert werden statt vollständig entfernt, wähle eine Policy:
- Einzigartig unter aktiven Nutzern (ermöglicht Re-Signup mit derselben E-Mail)
- Einzigartig über alle Nutzer inkl. gelöschter (verhindert Wiederverwendung und vereinfacht Audit)
Plane heutige Duplikate vor der Enforcement
Eine Constraint einzuschalten, wenn schon Duplikate existieren, wird fehlschlagen oder im schlimmsten Fall Signups blockieren. Mache vor dem Erzwingen ein Inventar der Duplikate, entscheide welcher Datensatz „gewinnt“ und stelle sicher, dass Referenzen (Sessions, Bestellungen, Mitgliedschaften) sicher umgestellt werden können.
Schritt-für-Schritt: Einführen von Einzigartigkeit ohne Downtime
Ziel ist, doppelte Nutzer zu verhindern, ohne Sign-ups zu stoppen oder Logins zu blockieren. Der sicherste Weg ist, die Bausteine zuerst hinzuzufügen, sie schrittweise zu füllen, schwierige Fälle zu bereinigen und erst dann die DB Einzigartigkeit erzwingen zu lassen.
Sichere Rollout-Sequenz
Füge zunächst einen normalisierten Schlüssel hinzu, den die DB zuverlässig vergleichen kann. Bei E-Mail heißt das meist eine lowercased, getrimmte Version (plus weitere Regeln, die dein Produkt braucht).
Ein praktischer Rollout:
- Füge eine neue Spalte für den normalisierten Wert hinzu (z. B.
email_normalized) und sorge dafür, dass bei jedem neuen Signup sowohlemailals auchemail_normalizedgeschrieben werden. - Backfille
email_normalizedfür bestehende Nutzer in kleinen Chargen (ID-Bereiche oder Zeitfenster), sodass jede Charge schnell fertig wird. - Führe Duplikat-Erkennung mit dem normalisierten Schlüssel aus und groupe Kollisionen (z. B. alle Zeilen, wo
email_normalized = "[email protected]"). - Löse jede Gruppe, bevor du Einzigartigkeit enforce: wähle einen Gewinner, merge nötige Daten und markiere die anderen als gemerged/deaktiviert.
- Füge den Unique-Index/die Constraint erst hinzu, wenn keine Duplikate mehr existieren, idealerweise per Online/Concurrent-Option, wenn die DB das unterstützt.
Konkretes Beispiel: Ein Prototyp speichert [email protected], [email protected] und [email protected] als drei verschiedene Nutzer. Sobald du email_normalized = "[email protected]" backfillst, kollidieren diese und werden zu einer Gruppe, die du mergen kannst.
Sperren und Überraschungen minimieren
Die meisten Downtimes passieren, wenn eine Änderung lange Table-Locks auslöst. Halte jede Operation kurz und vorhersehbar.
Einige Regeln, die helfen:
- Backfille mit einer festen Batch-Größe und Timeout. Wenn eine Charge zu lange braucht, mache sie kleiner.
- Sorge dafür, dass die App normalisierte Werte schreibt, bevor du mit dem Backfill startest. Sonst kommen neue Zeilen mit NULL an und du kommst nie hinterher.
- Überwache „neue Duplikate pro Stunde“ während des Rollouts. Wenn es ansteigt, schreibt etwas noch inkonsistente Keys.
- Erstelle den Unique-Index so, dass Schreibvorgänge nicht blockiert werden (z. B. „concurrent/online“ Creation, je nach DB).
Backfill-Plan: Duplikate finden und sicher mergen
Backfilling ist weniger Fancy-SQL und mehr Vorsicht bei Identität. Ziel: einen Datensatz behalten, alles dorthin umleiten und eine klare Spur hinterlassen.
Beginne damit, Duplikate mit demselben normalisierten Schlüssel zu listen, den du später erzwingen willst (z. B. lowercased und getrimmte E-Mail). Mach das zuerst im Read-Only-Modus und exportiere die Gruppen zur Prüfung.
-- Example: find duplicate emails by normalized value
SELECT
LOWER(TRIM(email)) AS email_norm,
COUNT(*) AS user_count,
ARRAY_AGG(id ORDER BY created_at) AS user_ids
FROM users
WHERE email IS NOT NULL
GROUP BY LOWER(TRIM(email))
HAVING COUNT(*) > 1
ORDER BY user_count DESC;
Für jede Duplikat-Gruppe wähle einen „primary“ Nutzer. Ein praktisches Kriterium ist, das Konto zu behalten, das am wahrscheinlichsten echt und aktiv ist. Nützliche Tiebreaker: verifizierte E-Mail, zuletzt aktiv, zahlender Plan.
Dann merge in vorhersehbarer Reihenfolge, damit keine Daten verloren gehen:
- Sperre die Duplikat-Gruppe (oder führe den Merge in einer Transaktion aus), um neue Writes während des Moves zu verhindern.
- Zeige verwandte Datensätze (Bestellungen, Projekte, Mitgliedschaften, API-Keys, Tickets) von
duplicate_user_idaufprimary_user_idum. - Löse Feldkonflikte einzeln (behalte verifizierte E-Mail, neueste Profildetails, höchste Rolle).
- Schreibe eine Audit-Zeile:
duplicate_user_id -> primary_user_id, Zeitpunkt, wer/was es ausgeführt hat. - Deaktiviere den Nicht-Primary-Nutzer (soft-delete) und lösche erst später endgültig, wenn nichts mehr davon abhängt.
Credentials und E-Mails brauchen besondere Behandlung. Wenn das Primary die E-Mail behält, entferne oder nullify die E-Mail beim Nicht-Primary, damit sie nicht mehr zum Sign-in genutzt werden kann. Bei Passwörtern, Sessions und OAuth-Identities migriere nur, wenn du sicher bist, dass sie zur selben Person gehören; andernfalls widerrufe Sessions auf den Nicht-Primary-Accounts und fordere einen frischen Login an.
Sign-in nicht kaputtmachen: Auth und Sessions während Merges
Ein Merge ist nicht nur Profildaten verschieben. Sign-in hängt oft an User-IDs, die in Sessions, Refresh-Tokens, Passwort-Reset-Links und Drittanbieter-Webhooks verankert sind. Merge zwei Konten und ignoriere diese Referenzen, und Leute landen in Login-Schleifen oder „Account nicht gefunden“-Fehlern.
Ein sicheres Muster ist, einen Primary-Account zu behalten und jedes Duplikat als Alias darauf zu zeigen. Wenn sich jemand über ein gemergtes Konto einloggt, löst du es zum Primary auf und machst weiter, ohne zu ändern, was die Person eingegeben hat.
Duplikate zum Primary umleiten
Halte ein kleines Lookup (z. B. eine Tabelle) wie merged_user_id -> primary_user_id. Bei jedem Auth-Read prüfst du diese Zuordnung und schreibst die User-ID vor dem Erstellen einer neuen Session auf den Primary um. Das verhindert Loops, weil das System nie Sessions für Konten erstellt, die nicht mehr „existieren."
Dieser Alias-Ansatz verschafft dir auch Zeit, alte Aufrufer ohne Ausfall umzuziehen.
Tokens, Resets und Integrationen: was muss aktualisiert werden
Bevor du den Schalter umlegst, entscheide, was du invalidierst vs. migrierst:
- Sessions und Refresh-Tokens: entweder auf den Primary umstellen oder widerrufen und einen frischen Login erzwingen.
- "Remember me"-Tokens: bei nächstem Login rotieren, um stille Fehler zu vermeiden.
- Passwort-Resets und E-Mail-Verifikationen: neue Links erzeugen, die an das Primary gebunden sind; alte Links nicht auf einen gemergeden ID zeigen lassen.
- Externe Integrationen: wenn ein Partner dein altes User-ID speichert, behalte Alias-Auflösung, damit eingehende Events dem Primary zugeordnet werden.
- Audit-Logs: Behalte historische User-IDs, zeige aber in Admin-UI die primäre Identität, um Verwirrung zu reduzieren.
Beispiel: Wenn Anna versehentlich zwei Konten mit derselben E-Mail erstellt hat (eins via Google, eins via Passwort), sollte der Merge ihre laufende Session weiter funktionieren lassen und künftige Passwort-Resets nur noch das Primary-Konto betreffen.
Häufige Fehler, die Ausfälle oder Datenverlust verursachen
Die meisten Ausfälle passieren, wenn die DB eine Regel erzwingen soll, die die Daten noch nicht erfüllen. Ein Unique-Constraint ist unerbittlich: existiert auch nur ein Duplikat, schlagen Writes fehl, Queues stauen sich und Sign-ups können ausfallen.
Ein typisches Beispiel: Ein Team legt freitags einen Unique-Index auf users.email an, in der Annahme „wir haben keine Duplikate.“ Über Nacht läuft ein alter Importjob nochmal und fügt dieselbe E-Mail mit anderer Groß-/Kleinschreibung ein. Am Montagmorgen werfen Signups 500er und der Support bricht zusammen.
Fehler, die Probleme verursachen:
- Constraint einschalten, bevor vorhandene Duplikate bereinigt sind.
- In einer Code-Route normalisieren, in anderen nicht (Web-App lowercaset, Admin/Import nicht).
- Annehmen, dass E-Mail immer vorhanden oder verifiziert ist (Telefon-only und Social Logins existieren; Nutzer ändern E-Mails).
- Nutzer mergen, ohne Fremdschlüssel überall zu aktualisieren (Bestellungen, Mitgliedschaften, Audit-Logs, API-Keys, Sessions, "created_by"-Felder).
- Daten beim Mergen stillschweigend löschen ohne Rollback-Plan.
Behandle Deduplizierung wie eine reversible Datenmigration, nicht wie ein einmaliges Cleanup-Skript. Behalte beide Datensätze, protokolliere, was sich geändert hat, und lösche erst, wenn du beweisen kannst, dass nichts mehr vom alten Datensatz abhängt.
Eine einfache Sicherheitsstrategie, die gut funktioniert:
- Logge jede Merge-Entscheidung (Gewinner-ID, Verlierer-ID, ausgewählte Felder, Timestamp).
- Verschiebe Referenzen in Chargen und verifiziere Counts vor und nachher.
- Füge ein kanonisches User-Mapping hinzu, damit alte IDs während der Transition noch auflösbar sind.
- Teste alle Schreibpfade (App, Admin, Imports, Worker) mit derselben Normalisierungsfunktion.
Kurze Checkliste und nächste Schritte
Fang bei Konsistenz an. Deine DB kann dich nur schützen, wenn jeder Schreibpfad denselben "unique key" erzeugt.
Checkliste:
- Bestätige, dass Normalisierungsregeln auf jedem Schreibpfad angewendet werden (Signup, Invite, Admin Create, OAuth, Imports, Background Jobs).
- Führe einen Duplicate-Scan mit dem normalisierten Schlüssel aus und prüfe die Ergebnisse im Team.
- Teste Merge-Logik an einer kleinen, realen Stichprobe und bestätige, was mit Profilen, Mitgliedschaften, Abonnements und Audit-Logs passiert.
- Bereinige Duplikate vollständig und aktiviere dann die DB-Enforcement (Unique-Index/Constraint) erst, wenn die Daten sicher sind.
- Füge Monitoring für neue Konflikte (Constraint Violations) hinzu, damit du Probleme aus Logs statt von Nutzern erfährst.
Wähle einen Owner und eine klare Timeline. „Dedupe“ bleibt stecken, wenn es vage ist. Mach es konkret: definiere den kanonischen Datensatz, wie Fremdschlüssel umgelenkt werden, und wie du bei Feldkonflikten entscheidest (Name, Telefon, Billing-Info, letzter Login).
Ein einfacher Dry-Run hilft: Nimm 50 Duplikat-Cluster aus Produktion, führe deinen Merge in einer Staging-Kopie aus und verifiziere, dass Nutzer sich weiterhin anmelden können, das richtige Workspace sehen und Passwort-Resets funktionieren.
Wenn du eine AI-generierte App geerbt hast und Duplikate auftreten, weil Constraints und Normalisierung nicht durchgängig implementiert wurden, kann FixMyMess (fixmymess.ai) helfen, indem es jeden Nutzer-Erstellungsweg diagnostiziert, Auth- und Merge-Logik repariert und dich zu einem DB-erzwungenen Einzigartigkeits-Setup bringt, ohne Sign-ins zu unterbrechen.
Häufige Fragen
Warum tauchen trotz UI-Prüfung weiterhin doppelte Benutzerkonten auf?
Weil Duplikate normalerweise durch mehrere Schreibpfade und Timing-Probleme entstehen, nicht dadurch, dass im UI zweimal dieselbe E-Mail eingegeben wird. Zwei Requests können sich überlappen, Importe können Prüfungen überspringen, OAuth-Callbacks können neue Zeilen anlegen oder ein Retry nach einem Timeout die Signup-Logik erneut ausführen. Nur eine Datenbankregel blockiert Duplikate unabhängig davon, wo der Schreibzugriff herkommt.
Was ist die einfachste Methode, doppelte E-Mails durch Groß-/Kleinschreibung oder Leerzeichen zu verhindern?
Normalisiere den Wert, auf den du Einzigartigkeit durchsetzen willst. Bei E-Mails ist ein guter Default trim + lowercase im Backend, jedes Mal wenn du einen Benutzer anlegst oder aktualisierst, und enforce dann die Einzigartigkeit auf der normalisierten Spalte. Bewahre die originale E-Mail zusätzlich auf, wenn du genau zeigen willst, was der Nutzer eingegeben hat.
Sollten wir Einzigartigkeit per E-Mail oder per OAuth-Provider-User-ID erzwingen?
Bei OAuth solltest du normalerweise die Identität des Providers durchsetzen, nicht nur die E-Mail. Speichere und erzwinge etwas wie provider + provider_user_id, damit eine Google-Identität nicht mehrere Zeilen anlegt, und verknüpfe diese Identität mit dem bestehenden Benutzer, wenn die E-Mail zu deinen Merge-Regeln passt.
Sollten wir Gmail-Plus-Addressing als denselben Nutzer behandeln?
Standardmäßig solltest du Plus-Addressing nicht entfernen, es sei denn, du bist sicher, dass das zu deinen Produktregeln passt. Manche Teams wollen [email protected] und [email protected] als dieselbe Person behandeln, aber das Verhalten ist provider-spezifisch und kann Nutzer auf Nicht-Gmail-Domains überraschen. Starte mit lowercase+trim und füg provider-spezifische Regeln nur hinzu, wenn nötig.
Wie handhaben wir Einzigartigkeit in einer Multi-Tenant-App?
Wenn dein Produkt Workspaces/Tenants hat, ist Einzigartigkeit oft pro Tenant zu betrachten. Das bedeutet eine Regel wie tenant_id + email_normalized, sodass dieselbe E-Mail in verschiedenen Workspaces existieren kann, aber nicht zweimal innerhalb eines Workspaces. Consumer-Apps setzen normalerweise globale Einzigartigkeit durch.
Was ist mit soft-gelöschten Nutzern — kann jemand die gleiche E-Mail später wiederverwenden?
Entscheide die Policy zuerst und kodifiziere sie dann in der Constraint. Eine gängige Wahl ist „einzigartig unter aktiven Nutzern“, was ein erneutes Signup nach dem Löschen erlaubt; das erfordert aber eine partielle Constraint, die auf active oder deleted_at prüft. Wenn du strikte Audit-History brauchst und Wiederverwendung verhindern willst, enforce die Einzigartigkeit über alle Datensätze hinweg, inkl. gelöschter.
Wie führt man eine Unique-Constraint ein, ohne Downtime zu verursachen?
Füge zuerst die normalisierte Spalte hinzu und schreibe sie für alle neuen Signups, backfille dann bestehende Nutzer in kleinen Chargen. Erkenne Kollisionen mit dem normalisierten Schlüssel, merge oder deaktiviere Duplikate und füge den Unique-Index/die Constraint erst hinzu, wenn die Daten sauber sind — idealerweise online/concurrent, wenn die DB das unterstützt. Diese Reihenfolge vermeidet den Ausfall durch plötzlich fehlschlagende Schreibvorgänge.
Wie mergen wir doppelte Nutzer, ohne Sign-in oder Abonnements zu zerstören?
Wähle einen Primary-User, zeige alle zugehörigen Datensätze auf diesen um und behalte eine explizite merged-to-Zuordnung, damit alte User-IDs während der Übergangszeit noch auflösbar sind. Sessions, Refresh-Tokens, Passwort-Resets und Verifizierungs-Links brauchen besondere Behandlung; die sicherste Default-Strategie ist, sie auf das Primary-Konto umzuleiten oder neu auszustellen, damit Nutzer nicht in Login-Schleifen landen.
Wie stoppen wir Duplikate, die durch Retries, Timeouts oder Doppel-Submits entstehen?
Erzeuge einen Idempotency-Key für die Signup-Intention und behandle Retries als dieselbe Operation, nicht als neuen Account. Selbst mit Idempotency solltest du die Datenbank-Constraint behalten, weil Race-Conditions und parallele Requests weiterhin auftreten können. Die Kombination verhindert sowohl versehentliche Wiederholungen als auch echte Konkurrenzprobleme.
Wir haben eine AI-generierte App übernommen und überall Duplikate — wie können wir das am schnellsten beheben?
Man kann es schnell beheben, wenn man es sowohl als Daten- als auch als Auth-/Datenmodell-Problem behandelt. FixMyMess kann alle Nutzererstellungs-Pfade auditieren, Backend-Normalisierung implementieren, die richtigen Unique-Constraints hinzufügen und einen sicheren Backfill-/Merge-Plan ausführen, sodass Duplikate aufhören, ohne dass Logins kaputtgehen. Wenn du eine AI-generierte Codebasis geerbt hast, die inkonsistente Nutzer anlegt, ist es oft schneller, die Flows komplett reparieren zu lassen als einzelne Routen zu patchen.