Hintergrundjobs laufen nicht? Queues, Cron und Worker schnell beheben
Hintergrundjobs, die nicht laufen, können E-Mails, Abrechnung und Sync unterbrechen. Erfahre, ob es Cron, Queues, Worker, Retries oder Idempotenz ist und wie du es schnell behebst.
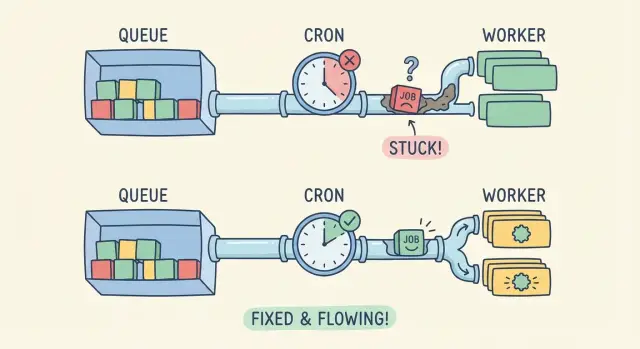
Wie sich ausfallende Hintergrundjobs äußern
Wenn Hintergrundjobs nicht laufen, wirkt die App anfangs oft in Ordnung. Seiten laden, Nutzer klicken, Formulare werden abgeschickt. Aber die „nachgelagerten“ Arbeiten passieren nie.
Menschen bemerken fehlende Seiteneffekte: Die Willkommens-E-Mail kommt nicht an, ein CSV-Import bleibt ewig auf „processing“, ein Payment-Webhook wird empfangen, das Bestellupdate bleibt aber aus, oder ein nächtlicher Sync ändert plötzlich keine Zahlen mehr. Support-Tickets klingen vage („es hängt“), weil nichts offensichtlich abstürzt.
Das ist besonders häufig bei AI-generierten Prototypen. Lokal funktioniert oft alles, weil eine Maschine alle Rollen übernimmt: Webapp, Scheduler und Worker. In Production sind diese Teile getrennt über Services, Container oder Maschinen verteilt. Ein fehlendes Teil bricht die Kette.
Die meisten Ausfälle lassen sich in vier Kategorien einordnen:
- Scheduling: Cron/Timer feuern nicht, Zeitzonen stimmen nicht, oder der Zeitplan läuft in der falschen Umgebung.
- Worker-Deployment: Der Worker läuft nicht, kann die Queue nicht erreichen oder hört auf den falschen Queue-Namen.
- Retries: Jobs schlagen fehl und werden endlos wiederholt, oder sie schlagen einmal fehl und verschwinden ohne Alarm.
- Idempotenz: Ein Job läuft zweimal und korruptiert den Zustand, weshalb er deaktiviert wird oder ständig Fehler wirft.
Bevor du Code anfasst, sammle ein paar Fakten. Das spart Stunden an Rätselraten und macht klarer, wo die Pipeline bricht:
- Der Zeitstempel, wann die Nutzeraktion stattfand (oder wann der Schedule ausgelöst sein sollte)
- Der Job-Name/-Typ und jede Job-ID, die dein System loggt
- Worker-Logs aus diesem Zeitraum (nicht nur Web-Logs)
- Queue-Metriken: pending, in-progress, failed
- Die letzte erfolgreiche Laufzeit desselben Jobs
Wenn du ein Prototype von Tools wie Replit, Cursor oder Bolt geerbt hast, ist dieses „Evidence Pack“ genau das, womit Teams wie FixMyMess prüfen, ob ein Scheduler fehlt, ein Worker tot ist oder ein Job leise fehlschlägt.
Cron, Queues und Worker: das einfache Modell
Stell dir die Hintergrundarbeit als Liefersystem vor. Etwas entscheidet wann Arbeit passiert, etwas speichert die Arbeit, und etwas führt sie aus.
Cron (oder ein Scheduler) ist die Uhr. Er triggert Aufgaben nach einem Zeitplan wie „alle 5 Minuten“ oder „montags 9 Uhr“. Eine Queue ist der Briefkasten. Sie hält Jobs, bis ein Worker bereit ist. Ein Worker ist der Zusteller. Er zieht Jobs aus der Queue und führt den Code aus.
Einmalige Jobs und wiederkehrende Jobs starten unterschiedlich. Ein einmaliger Job wird meist von der App erstellt (z. B. „resiziere dieses Bild nach Upload“). Ein wiederkehrender Job wird meist vom Cron erstellt (z. B. „sende wöchentliche Reports“). Wenn du eine Queue verwendest, landen beide am selben Ort: ein Job-Datensatz, der darauf wartet, verarbeitet zu werden.
In Production muss Zustand an einem gemeinsamen, dauerhaften Ort leben: eine Datenbanktabelle für geplante Läufe, Redis für Queue-Nachrichten oder ein gemanagter Queue-Service. Wenn ein Prototype auf In-Memory-Zustand setzt, funktioniert er lokal und fällt auseinander, sobald du mehr als einen Server hast oder nach einem Restart.
Lokale Entwicklung kaschiert Probleme, weil alles in einem Prozess läuft. In Production sind es getrennte Komponenten. Wenn Cron nicht installiert ist, der Worker nicht deployed ist oder der Worker keine Verbindung zu Redis oder der Datenbank hat, siehst du das klassische Symptom: Hintergrundjobs laufen nicht, obwohl die App an der Oberfläche „gesund“ wirkt.
Schnelle Triage: Wo bricht die Pipeline?
Rate nicht. Finde heraus, welcher Teil der Pipeline ausfällt: Werden Jobs nicht erstellt, nicht abgeholt oder laufen sie und schlagen fehl?
1) Werden Jobs überhaupt erstellt?
Beginne mit der einfachsten Trennung: „kein Job existiert“ vs. „Job existiert, aber nichts passiert“. Suche nach einem Job-Datensatz in deinem Queue-Speicher/-Tabelle oder nach einem Log-Eintrag, der bestätigt, dass ein Job enqueued wurde.
Wenn du nichts findest, ist es meist Scheduling. Cron/Timer laufen vielleicht nicht in Production, laufen in der falschen Umgebung oder haben nicht die richtigen Rechte. Ein häufiger Prototyp-Fehler ist, auf einen lokalen Scheduler (deinen Laptop) zu vertrauen, ohne einen tatsächlichen Scheduler-Prozess zu deployen.
2) Werden Jobs erstellt, aber nie verarbeitet?
Wenn Jobs existieren, aber „queued“ bleiben, hast du wahrscheinlich einen Worker, der keine Jobs verarbeitet. Bestätige, dass ein Worker tatsächlich in der Production-Umgebung läuft (nicht nur während des Deploys) und denselben Queue-Namen hört, an den deine App schreibt.
Prüfe auch Konnektivität und Credentials. Worker benötigen Zugriff auf das Queue-Backend (Redis/SQS/Datenbank) und dieselben Env-Variablen wie die App. Eine falsche Variable kann den Worker „gesund“ erscheinen lassen, obwohl er die Jobs nie sieht.
3) Laufen Jobs, schlagen fehl und retryen ewig?
Wenn du steigende Attempts siehst, ist das Scheduling wahrscheinlich in Ordnung. Nun geht es um die Ausführung. Öffne den neuesten Fehler und suche nach der wiederkehrenden Ursache (Auth-Fehler, fehlende Secrets, Timeouts). Retries sollten Backoff und eine Max-Anzahl an Versuchen haben.
Wenn ein Job Geld, E-Mails oder Nutzerdaten berührt, geh davon aus, dass er zweimal ausgeführt werden kann. Fehlende Idempotenz ist der Grund, warum „es schlägt fehl“ zu „es schlägt laut fehl“ wird — doppelte Abbuchungen oder wiederholte E-Mails.
Scheduling-Probleme beheben (Cron und Timer)
Verifiziere zuerst die Basics: Wird überhaupt etwas getriggert, und passiert das zur erwarteten Zeit?
Bestätige, dass der Zeitplan dem entspricht, was du denkst
Cron-Ausdrücke können korrekt aussehen und trotzdem falsch sein. Zeitzonen sind die häufigste Falle. Dein Laptop könnte lokale Zeit nutzen, während Production in UTC läuft. Das verwandelt „täglich 9 Uhr“ in „täglich 1 Uhr“ oder in Zeiten außerhalb deines Testfensters.
Prüfe auch, wie deine Plattform den Zeitplan interpretiert. Manche Systeme nutzen 5-Felder-Cron, andere 6 Felder (mit Sekunden). Ein zusätzliches Feld verschiebt alles.
Schnelle Checks, die die meisten Fehler finden:
- Logge die nächsten 5 Laufzeiten deines Schedulers und bestätige, dass sie deinen Erwartungen entsprechen.
- Bestätige die Zeitzoneneinstellung in App-Config und Hosting-Umgebung.
- Validere den Cron-String gegen die Scheduler-Bibliothek, die du tatsächlich verwendest.
- Stelle sicher, dass der Job in Production aktiviert ist (Feature-Flags und Env-Vars unterscheiden sich oft).
- Bestätige, dass nur eine Scheduler-Instanz aktiv ist (sonst gibt es Duplikate).
Den Scheduler in Production sicher machen
Ein Scheduler auf deinem Laptop läuft nach Deployment nicht automatisch weiter. In Prototypen steckt man den Scheduler oft in den Webserver-Prozess. Dann stoppt er bei Neustarts, skaliert auf null oder schläft. Ein solcher Scheduler löst stillschweigende Ausfälle aus.
Verpasste Läufe sind ein weiteres stilles Problem. Wenn die App um 9:01 neu startet, feuert der 9:00-Job nicht automatisch, es sei denn, du planst dafür. Für wichtige Tasks erwäge eine Catch-up-Strategie: Beim Start prüfe, was hätte laufen sollen, und enqueue es nach.
Handhabe auch Überlappungen: Wenn ein Job länger braucht als sein Intervall, brauchst du ein Lock oder eine „nicht überlappen“-Regel. Sonst siehst du doppelte Sends, doppelte Abrechnungen oder konkurrierende Updates.
Worker-Deployment und Konnektivität fixen
Wenn der Zeitplan korrekt aussieht, Jobs aber dennoch nicht verarbeitet werden, schau dir den Worker an. Eine Queue bewegt sich nur, wenn ein Worker-Prozess online, verbunden und in der Lage ist, dauerhaft zu laufen.
Bestätige, dass ein Worker-Prozess in derselben Umgebung läuft, in der die App deployed ist (nicht nur auf deinem Laptop). Du möchtest Belege, dass er startet, stabil bleibt und auf dieselbe Queue zeigt, an die deine App Jobs sendet. Prüfe Prozesse oder Service-Dashboard und suche in den Logs nach einer Startzeile wie "listening" oder "connected".
Häufige Deployment-Lücken in AI-generierten Prototypen:
- Der Worker wurde nie deployed (nur die Web-App wurde).
- Der Worker-Befehl ist falsch (er startet ein Dev-Skript oder beendet sich sofort).
- Env-Variablen fehlen im Worker (Queue-URL, Credentials,
NODE_ENV). - Der Worker hört auf einen anderen Queue-Namen/Region als die Web-App.
- Der Worker crasht und startet in einer Schleife neu (meist wegen Speicherlimits oder fehlender Abhängigkeiten).
Konnektivitätsprobleme sehen ähnlich aus: Jobs häufen sich, und niemand konsumiert sie. Häufige Ursachen sind ein falscher Host, blockierte Ports, abgelaufene Credentials oder ein Queue-Service, der nur aus einem privaten Netzwerk erreichbar ist, in dem dein Worker nicht sitzt.
Concurrency spielt ebenfalls eine Rolle. Zu wenige Worker bedeuten langsame Verarbeitung; zu viele führen zu Timeouts, Rate-Limits oder OOM-Crashes. Ein einfacher Anfangswert sind 1–2 Worker mit geringer Concurrency; erhöhe erst, wenn Speicher stabil ist und Jobzeiten vorhersehbar sind.
Beispiel: Ein Startup deployed einen Job „Send invoice emails“. Die Web-App enqueued korrekt, aber der Worker läuft in Production ohne Queue-Credentials und beendet sich. Das Fixen der Worker-Umgebung (und das Hinzufügen einer klaren "connected to queue"-Logzeile) macht das Problem beim nächsten Mal sofort sichtbar.
Retries, Backoff und fehlerresistente Handhabung
Manchmal heißt „Hintergrundjobs laufen nicht“ eigentlich: der Job läuft, schlägt sofort fehl und retryt so schnell, dass er nie Fortschritt macht. Gute Retry-Regeln halten dein System ruhig und die Logs lesbar.
Sortiere Fehler in zwei Gruppen:
- Transiente Fehler lösen sich meist von selbst: Timeouts, Rate-Limits, kurzzeitige DB-Locks, Netzwerkstörungen. Diese sollten retryen.
- Permanente Fehler bessern sich nicht mit der Zeit: fehlende Daten, falscher API-Key, "user not found", Validierungsfehler oder ein Code-Bug, der immer an derselben Stelle wirft. Diese sollten schnell fehlschlagen und in einem Dead-Zustand zur Überprüfung landen.
Backoff verhindert, dass ein kleines Problem zur Lawine wird. Ein sinnvoller Default ist eine kleine Anzahl Versuche (z. B. 3–10) mit wachsender Verzögerung. Füge ein wenig zufälligen Jitter hinzu, damit nicht tausend Jobs in derselben Sekunde erneut versuchen.
Halte bei jedem Job-Fehler dieselben Basisinfos fest, damit du ihn später reproduzieren kannst:
- Job-Name, eindeutige Job-ID und Attempt-Nummer
- Das genaue Input-Payload (oder eine sichere Zusammenfassung) und relevante Record-IDs
- Die Fehlermeldung und Stack-Trace sowie den Upstream-Response-Code bei API-Aufrufen
- Timing-Infos: wie lange der Job lief und wie lange bis zum nächsten Retry
Alerts können einfach sein. Wenn die Queue-Länge 10 Minuten lang wächst oder das Alter des ältesten Jobs einen Schwellenwert überschreitet, wecke jemanden oder schreibe zumindest in einen gemeinsamen Channel. So entdeckst du „leise“ Fehler, bei denen der Worker lebt, aber jeder Job hängt.
Beispiel: Ein wöchentlicher E-Mail-Job trifft montagmorgens auf ein Rate-Limit beim Provider. Ohne Backoff retryt er sofort, verbraucht alle Versuche und verwirft E-Mails. Mit Backoff und klarer "rate limited"-Log wartet er, erholt sich und du kannst die Ursache bestätigen.
Idempotenz: Jobs sicher mehrfach ausführbar machen
Sobald Jobs wieder laufen (oder Retries greifen), taucht oft ein neues Problem auf: derselbe Job läuft zweimal. Wenn der Job nicht idempotent ist, bedeutet „zweimal“ doppelte Abbuchungen, doppelte E-Mails oder doppelte Datensätze.
Idempotenz heißt, dass du denselben Job mehrfach ausführen kannst und trotzdem ein korrektes Einzel-Ergebnis erhältst. Stell dir einen Task „Karte belasten und Beleg mailen“ vor. Ein Netzwerkfehler kann nach erfolgreicher Zahlung passieren, bevor deine App das Ergebnis speichert. Die Queue retryt und der Kunde wird erneut belastet.
Wo Idempotency-Keys am meisten helfen
Für alles, was mit externen Diensten spricht (Zahlungen, E-Mail-Provider, SMS, Webhooks), füge einen Idempotency-Key hinzu, der für die logische Aktion gleich bleibt, nicht für den Versuch. Ein guter Key ist an eine stabile Business-ID gebunden, z. B. invoice_1234 oder order_987.
Schütze außerdem deine Datenbank vor Duplikaten. Die einfachste Schutzmaßnahme ist eine Unique-Constraint, z. B. „nur ein Receipt pro Invoice“. Dann kann dein Job „Try Insert“ machen und „already exists“ als Erfolg behandeln.
Praktische Muster, die in Prototypen gut in Produktion funktionieren:
- Schreibe zuerst einen Job-State (z. B.
payment_pending), mache dann den externen Aufruf und markiere anschließendpayment_completed. - Speichere einen „processed key“ (Job-ID oder Business-ID) und prüfe ihn vor Seiteneffekten.
- Nutze Unique-Constraints für One-Time-Dinge (Receipts, E-Mails, Subscriptions).
- Gib Erfolg zurück, wenn das Ergebnis bereits existiert.
Wenn du ein AI-generiertes Prototype geerbt hast, fehlt das oft: Jobs führen zuerst den Seiteneffekt aus und versuchen dann zu speichern. Die Umkehrung dieser Reihenfolge eliminiert bereits die meisten doppelten Abbuchungen und E-Mails.
Schritt-für-Schritt: Ein wiederholbarer Debug-Workflow
Hör auf zu raten und teste einen Punkt der Pipeline nach dem anderen. Ziel ist, ein vages Symptom (E-Mails kommen nicht an, Reports werden nicht erstellt) in einen klaren Fehlerpunkt zu verwandeln.
Nutze einen kleinen Test-Job mit einem bekannten Payload und halte sonst alles wie in Production:
- Beweise, dass der Scheduler triggert: starte den Scheduler einmal manuell (oder setze den Cron temporär auf jede Minute) und bestätige, dass er versucht, den Job zu enqueuen.
- Beweise, dass der Job erstellt wird: prüfe Queue, Job-Tabelle oder Broker auf einen neuen Eintrag mit deinem bekannten Payload und Zeitstempel.
- Beweise, dass ein Worker ihn sehen kann: starte einen einzelnen Worker im Vordergrund und beobachte, wie er den Job abholt.
- Lies den echten Fehler: finde den ersten Fehler (fehlende Env-Var, falsche DB-URL, blockierter Outbound-Mail-Call, Berechtigungen).
- Starte denselben Job erneut: bestätige, dass er abschließt und dass er beim zweiten Lauf keine Änderungen doppelt anwendet.
Wenn du das geschafft hast, weißt du, welche Schicht kaputt ist: Scheduling, Enqueueing, Worker-Deployment/Konnektivität oder Job-Logik.
Nachdem es einmal funktioniert: Guardrails hinzufügen
Ein Job, der nur läuft, wenn du zusiehst, ist noch nicht wirklich gefixt. Füge ein paar Schutzmaßnahmen hinzu, damit Fehler nicht still stapeln:
- Timeouts und Limits (damit Jobs nicht ewig hängen)
- Klare Retry-Regeln mit Backoff (damit Fehler nicht endlos schleifen)
- Dead-Letter-Queue (damit schlechte Jobs gute nicht blockieren)
- Idempotency-Checks (damit ein Retry nicht doppelt belastet oder doppelt sendet)
- Logs mit Job-ID und wichtigen Eingabefeldern
Häufige Fallen, die Jobs am Abschließen hindern
Oft ist die Ursache nicht das Queue-System selbst, sondern eine kleine Unstimmigkeit zwischen Scheduler, Worker und dem, was der Job zum Erfolg braucht.
Eine häufige Ursache ist das versehentliche Aufspalten der Pipeline. Beispiel: Cron läuft auf dem Webserver, aber der Worker ist auf einer anderen Maschine/Container deployed, der in Production nicht läuft. Der Scheduler enqueued fröhlich, aber niemand holt die Jobs ab.
Weitere typische Fallen:
- Nutzung einer In-Memory-Queue (oder dev-only Adapter), sodass Jobs bei Restart oder Scale-Out verschwinden.
- Fehler werden gefangen und trotzdem als „Erfolg“ zurückgemeldet, sodass der Job scheinbar erledigt ist, aber nichts getan wurde.
- Keine Fehler-Sichtbarkeit, sodass kaputte Jobs tage- oder wochenlang stapeln.
- Secrets und Endpunkte sind hardcodiert und unterscheiden sich zwischen lokal, Staging und Prod.
- Jobs hängen von lokalen Dateien oder temporären Ordnern ab, die auf dem Worker nicht existieren.
Ein kleines Beispiel: Ein Job versendet Rechnungen und ruft eine externe API auf. Lokal funktioniert es, weil der API-Key in deiner .env liegt. In Production hat der Worker diese Variable nicht, der Code fängt die Exception und markiert den Job als abgeschlossen. Du bemerkst das erst, wenn Kunden sich beschweren.
Wenn du so etwas vermutest, beantworte zwei Fragen: Wo läuft der Job (welcher Service) und wo findest du seine Logs? Wenn du beides nicht findest, können Fehler lange verborgen bleiben.
Kurze Checkliste vor dem nächsten Deploy
Bevor du erneut pushst, geh die Pipeline kurz durch. Die meisten „Hintergrundjobs laufen nicht“-Meldungen sind kein einzelner Bug, sondern kleine Unstimmigkeiten zwischen Scheduling, Enqueueing und Worker-Setup.
Fang beim Scheduler an. In vielen Prototypen läuft der Cron-Prozess nie in Production oder in einem Container, der runter skaliert wird. Bestätige, dass er jetzt läuft (nicht nur konfiguriert) und dass er dieselben Env-Variablen wie die App hat.
Prüfe als Nächstes, ob Jobs tatsächlich erstellt werden. Schau, ob der Job-Zeitstempel (run_at / scheduled_for) zur Production-Zeitzone passt und ob das Payload echte IDs enthält (keine leeren Strings, Platzhalter-Mails oder null User-IDs). Werden Jobs für die ferne Zukunft geplant, wirken sie „gestaut“, obwohl nichts kaputt ist.
Dann verifiziere den Worker. Sorge dafür, dass mindestens ein Worker-Prozess dauerhaft läuft und genau auf den Queue-Namen hört, den deine App nutzt. Ein Tippfehler oder eine Default-Queue-Diskrepanz reicht für stille Aufhäufung.
Mach Fehler sichtbar und retries sicher:
- Logge Fehler mit genug Kontext (Job-Name, ID, Schlüssel-Felder)
- Begrenze Retries und nutze Backoff, damit Fehler nicht in Schleifen laufen
- Mach Jobs idempotent, damit ein Retry nicht doppelt sendet/abbucht/erstellt
Beispiel: Der wöchentliche E-Mail-Job, der lokal funktioniert, aber nicht in Production
Eine typische „funktioniert auf meinem Laptop“-Geschichte: Ein Prototype verschickt montags um 9 Uhr einen Wochenreport. Nach Deployment kommt nichts an. Dashboard OK, Nutzer können sich einloggen, und es gibt keine offensichtlichen Fehler.
Erster Check: Ist der Schedule in Production real? Lokal startet dein Dev-Server vielleicht automatisch einen Scheduler (oder du hast ihn einmal gestartet). In Production existiert der Cron-Eintrag zwar in der Konfiguration, aber es läuft kein Scheduler-Prozess. Der Code ist korrekt, aber nichts triggert die Queue.
Nach dem Deploy eines Schedulers (oder dem Aktivieren des Platform-Cron) tauchen Jobs auf. Das offenbart das zweite Problem: Der Worker retryt denselben Job, weil die Env-Var für den E-Mail-Provider fehlt. Jeder Lauf schlägt fehl, requeues und baut Backlog auf. Neue Jobs verzögern sich, und die Queue wirkt „gestaut“, obwohl der Worker beschäftigt ist — er scheitert nur ständig.
Was das dauerhaft behebt:
- Ein einfaches Health-Log, wenn der Scheduler Jobs enqueued (so kannst du Trigger nachweisen).
- Fail fast bei fehlenden Env-Vars am Startup (so crasht der Worker laut statt endlos zu retryen).
- Begrenzte Retries mit Backoff (z. B. 5 Versuche innerhalb von 30 Minuten), dann Dead-Letter für Review.
- Mach den E-Mail-Job idempotent, z. B. indem du vor dem Senden einen Schlüssel wie
report:teamId:weekStartDatespeicherst und überspringst, falls er bereits existiert.
Mit diesen Änderungen kannst du Worker neu starten, neu deployen oder von Abstürzen erholen, ohne Duplikate zu erzeugen oder endlose Retry-Schleifen zu provozieren.
Nächste Schritte: Pipeline härten und stabil halten
Wenn Jobs wieder laufen, ist das Ziel, denselben Ausfall künftig zu verhindern. Behandle Hintergrundjobs als Produktionsrisiko, nicht als einmaligen Bug.
Schreibe das Gelernte in einen kurzen Runbook, dem jeder folgen kann:
- Wo Schedules definiert sind (Cron-Config, Platform-Scheduler, App-Timer)
- Wie Worker gestartet werden (Prozessname, Start-Command, benötigte Env-Vars)
- Wie „gesund“ aussieht (Queue-Tiefe, letzte erfolgreiche Laufzeit)
- Die häufigsten Fehler, die du gesehen hast (Timeouts, Auth, fehlerhafte Payloads)
- Die sichere Vorgehensweise zum Replay von Jobs (und wie man Double-Sends vermeidet)
Füge minimale Überwachung hinzu, die zwei Fragen beantwortet: Stapeln sich Jobs, und schlagen sie fehl? Selbst einfache Alerts zur Queue-Tiefe und eine tägliche Failed-Job-Statistik fangen die meisten Probleme früh.
Wenn dein Prototype Web-Request-Code und Job-Logik mischt, plane ein kleines Refactor. Pack die Kernarbeit des Jobs in eine einzelne Funktion, die vom Worker ausgeführt wird, und lass die Web-Request nur enqueuen und input validieren. Das macht Retries sicherer und entfernt versteckte Abhängigkeiten von Request-State.
Wenn du ein AI-generiertes Projekt geerbt hast und schnell eine zweite Meinung brauchst: FixMyMess (fixmymess.ai) spezialisiert sich darauf, kaputte Prototypen zu diagnostizieren und zu reparieren, sodass Queues, Worker, Retries und Deployment-Verhalten dem entsprechen, was du lokal siehst — mit menschlicher Verifikation vor dem Shippen.
Häufige Fragen
How do I know it’s a background job problem and not a normal app bug?
Wenn Seiten laden, aber die „nachgelagerten“ Aktionen nie passieren (keine E-Mails, Importe bleiben auf „processing“, Webhooks werden empfangen, aber nichts wird aktualisiert), dann ist wahrscheinlich ein Problem mit Hintergrundjobs. Bestätige das, indem du prüfst, ob ein Job überhaupt enqueued wurde und ob ein Worker um den Zeitpunkt der Benutzeraktion einen Versuch unternommen hat.
Why do background jobs work locally but not in production?
Weil die lokale Entwicklung oft alles in einem Prozess laufen lässt: Webserver, Scheduler und Worker. In Production sind das getrennte Services oder Container. Fehlt eine Komponente (kein Scheduler, kein deployter Worker, falsche Queue-Verbindung), bricht die Kette, obwohl die Web-App weiterhin normal aussieht.
What’s the fastest way to triage where the pipeline is breaking?
Entscheide zuerst, welche Stufe kaputt ist: Erstellung des Jobs, Abholung durch den Worker oder Ausführung. Suche zuerst nach einem Enqueue-Log oder einem Job-Datensatz; fehlt das, ist es meist Scheduling. Sind Jobs vorhanden, bleiben aber queued, ist es in der Regel ein Worker- oder Connectivity-Problem. Steigt die Attempt-Anzahl, läuft der Job und schlägt fehl — dann fokussiere auf den Fehler und die Retry-Regeln.
What are the most common scheduling (cron) mistakes?
Scheduling ist dann kaputt, wenn zur erwarteten Zeit kein Job erstellt wird. Häufige Ursachen sind: kein Scheduler in Production, Zeitdifferenzen (lokal vs UTC), der Scheduler für die falsche Umgebung oder ein Cron-Format-Mismatch (5-Felder vs 6-Felder). Ein schneller Check: logge die nächsten Run-Zeiten und bestätige, dass sie deinen Erwartungen entsprechen.
What’s the difference between the queue and the worker, and what breaks most often?
Die Queue ist der Ort, an dem Jobs warten; der Worker ist der Prozess, der sie abholt und ausführt. Wenn Jobs als „queued“ liegen bleiben, läuft meist kein Worker, der Worker hört auf einen anderen Queue-Namen oder er kann das Queue-Backend wegen falscher Credentials oder Netzwerkeinstellungen nicht erreichen.
Why does my worker look “healthy” but still never processes jobs?
Weil Web-App und Worker oft unterschiedliche Umgebungsvariablen haben. Die App enqueued korrekt, während dem Worker die Queue-URL, Datenbank-URL oder API-Keys fehlen, sodass er zwar startet, aber keine Jobs verarbeiten kann. Prüfe, dass der Worker dieselben kritischen Env-Variablen wie der Web-Prozess hat und beim Start eine klare "connected to queue"-Meldung loggt.
If retries keep happening, does that mean scheduling is fine?
Nicht unbedingt; es kann bedeuten, dass der Job sofort fehlschlägt und wiederholt wird. Prüfe, ob die Attempt-Anzahl steigt und ob derselbe Fehler wiederholt auftritt. Führe eine Max-Attempt-Grenze und Backoff ein, damit permanente Fehler nicht endlos retryed werden, und stelle sicher, dass unbehebbare Fehler in einen überprüfbaren Failed-Zustand landen.
How do I prevent duplicate emails or double charges when jobs retry?
Idempotenz bedeutet, dass ein Job mehrmals laufen kann, ohne ein falsches Ergebnis zu produzieren. Verwende stabile Idempotency-Keys für externe Nebenwirkungen (Zahlungen, E-Mails, SMS) und setze Datenbank-Constraints (z. B. eindeutige Einschränkungen), sodass „bereits vorhanden“ als Erfolg behandelt wird. So verhinderst du doppelte Abbuchungen oder doppelte E-Mails bei Retries.
What information should I collect before changing code?
Sammle den Zeitpunkt der Benutzeraktion (oder der erwarteten Schedule-Zeit), den Job-Namen/Typ und eventuelle Job-IDs, Worker-Logs für das Zeitfenster, Queue-Tiefe und Fehlerraten sowie die letzte erfolgreiche Laufzeit desselben Jobs. Dieses „Evidence Pack“ zeigt schnell, ob Jobs nicht erstellt, nicht konsumiert oder bei der Ausführung fehlschlagen.
When should I bring in FixMyMess instead of debugging longer?
Wenn du ein AI-generiertes Prototype geerbt hast und Jobs stecken bleiben, still fehlschlagen oder Seiteneffekte duplizieren, ist es häufig ein Deployment- oder Pipeline-Mismatch statt eines kleinen Bugs. FixMyMess kann ein kostenloses Code-Audit durchführen, um zu identifizieren, ob ein Scheduler fehlt, ein Worker tot ist oder Secrets/Retries das Problem sind, und dann schnell mit menschlicher Verifikation reparieren und härten.