Mit KI erstellte Apps scheitern bei echten Nutzern: 3 Demo‑Fallen erkennen
Mit KI erstellte Apps scheitern bei echten Nutzern, wenn Demos Edge‑Cases überspringen. Beispiele zu Login, E‑Mail und Zahlungen sowie Prüfungen, um deine App vor dem Launch zu härten.
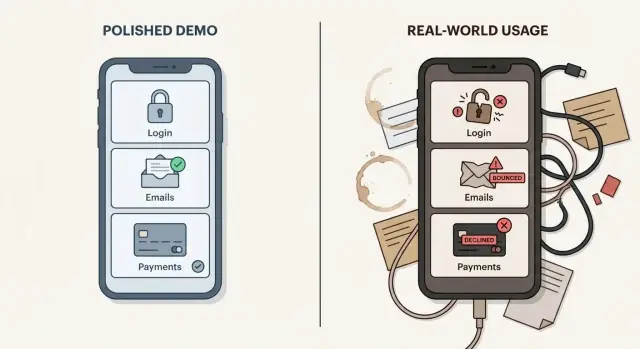
Was in einer Demo gut aussieht und was in Produktion bricht
Eine Demo ist ein kontrollierter Moment. Du nutzt ein Gerät, ein Konto, saubere Beispieldaten und einen Ablauf, von dem du weißt, dass er funktioniert. Echte Nutzer machen genau das Gegenteil. Sie klicken in anderer Reihenfolge, benutzen alte Links, tippen Passwörter falsch, laden zur falschen Zeit neu und probieren es auf Handys, die du nie getestet hast.
Deshalb scheitern mit KI erstellte Apps bei echten Nutzern, selbst wenn die Demo perfekt wirkt. Ein Prototyp zeigt oft nur, dass eine Idee möglich ist, nicht dass sie zuverlässig ist.
Frühe Nutzer verhalten sich außerdem anders als der Erbauer erwartet. Sie lesen keine Anweisungen. Sie melden sich mit Firmen‑, Privat‑ oder temporären E‑Mails an. Sie öffnen die App hinter Unternehmens‑Firewalls. Sie versuchen mit Karten aus anderen Ländern zu bezahlen. Und sie schreiben noch am selben Tag an den Support, weil alles „live“ einfach funktionieren sollte.
In einer Demo bedeutet „funktioniert“ oft „ich kann den Happy Path einmal durchlaufen.“ In Produktion bedeutet „funktioniert“ Zuverlässigkeit, Sicherheit, Wartbarkeit und Wiederherstellbarkeit. Wichtige Aktionen müssen wiederholt gelingen (auch bei schlechter Verbindung). Private Daten müssen privat bleiben. Wenn etwas fehlschlägt, brauchst du genug Sichtbarkeit, um zu verstehen, was passiert ist, und schnell zu helfen. Und du brauchst sichere Wege, Dinge erneut zu versuchen, zurückzusetzen oder zu reparieren, ohne alles andere kaputtzumachen.
Du musst die Geschwindigkeit, die dich zum Prototyp geführt hat, nicht verlieren. Behalte denselben Ablauf bei, füge aber die unspektakulären Prüfungen hinzu: solides Fehlerhandling, Logging, Ratenbegrenzung, sichere Speicherung von Zugangsdaten und Tests mit unordentlichen Daten.
Warum KI‑generierte Prototypen Abkürzungen nehmen
KI‑generierter Code ist oft darauf optimiert, so schnell wie möglich „etwas Funktionierendes“ zu zeigen. Demos belohnen den Happy Path: ein Konto, ein Gerät, ein sauberes Netz und vorhersehbare Eingaben. Produktion belohnt das Gegenteil: Resilienz.
Prototypen überspringen oft die unbequemen Teile. Was passiert, wenn eine Anfrage ausläuft, eine API nur eine Teilantwort liefert oder zwei Aktionen gleichzeitig passieren? In einer Demo klickst du einmal und machst weiter. In Produktion laden Leute neu, senden doppelt, wechseln Tabs, verlieren das Signal und versuchen es wieder.
Ein weiteres häufiges Problem sind versteckte Annahmen. KI‑Code kann Werte hartkodiert haben, die an Tag eins harmlos wirken: eine feste Nutzerrolle, eine einzelne Environment‑Einstellung, ein temporärer API‑Key, eine Währung oder eine Zeitzone. Lokal funktioniert alles, nach Deployment, bei Teamzugriff oder beim ersten echten Kunden bricht es.
Die meisten fehlenden Teile sind langweilig, verhindern aber, dass Support‑Tickets sich häufen: Timeouts und Retries behandeln, Eingaben mit hilfreichen Meldungen validieren, mit Teil‑Fehlern umgehen, Demo‑Settings und Secrets entfernen und Logs hinzufügen, die zur echten Ursache weisen.
Stell dir einen einfachen Ablauf vor: Ein Nutzer meldet sich an, erhält eine Bestätigungs‑E‑Mail und zahlt dann. Eine Demo beweist, dass die Buttons funktionieren. Produktion muss beweisen, dass die ganze Kette unter Last hält und bei einem Fehler upstream sanft scheitert.
Szenario 1 – Login funktioniert einmal, dann sind Nutzer ausgesperrt
Ein Demo‑Login folgt meist dem glücklichsten Pfad: ein Testkonto, dein Laptop, ein Browser, stabile Verbindung. Du meldest dich an, landest im Dashboard und alle nicken.
Echte Nutzer verhalten sich nicht so. Sie loggen sich vom Handy und vom Firmenlaptop ein. Sie vergessen Passwörter. Sie klicken „Anmelden mit Google“ in einem In‑App‑Browser. Sie schließen den Tab, kommen morgen zurück und erwarten, weiterhin angemeldet zu sein.
Viele „funktioniert einmal“ Login‑Bugs kommen von wenigen Fehlerpunkten:
- OAuth‑Callbacks sind pingelig. Die Callback‑URL muss exakt passen, und kleine Redirect‑Abweichungen können den letzten Schritt nach der „Success“-Meldung des Providers brechen.
- Cookies und Sessions können so gesetzt sein, dass sie nur auf localhost, nur in einem Browser oder unter strengeren Datenschutz‑Einstellungen funktionieren.
- Sessions laufen ab, aber die App erholt sich nicht sauber, sodass Nutzer in Schleifen steckenbleiben.
Was Nutzer melden ist fast immer vage: „Ich kann mich einmal einloggen, dann funktioniert es nicht mehr.“ Dieser Satz kann alles verbergen, von einem falsch gesetzten Cookie bis zu einer blockierten Cross‑Site‑Anfrage oder einem Redirect, der ein Token fallenlässt.
Bevor du Leute einlädst, mach ein paar einfache Prüfungen (kein tiefes Technikwissen nötig). Logge dich auf deinem Handy und einem zweiten Gerät ein und bestätige, dass beide angemeldet bleiben. Schließe den Tab und komm nach 10 Minuten und dann nach 24 Stunden zurück. Probiere Passwort‑Reset und bestätige, dass das neue Passwort sofort funktioniert. Teste ein Inkognito‑Fenster und einen anderen Browser. Und bitte jemanden außerhalb deines Netzwerks, sich von deren Verbindung aus anzumelden.
Wenn eines davon fehlschlägt, pausier und diagnostiziere. Authentifizierung ist oft der Blocker, der einen „funktionierenden“ Prototyp in etwas verwandelt, von dem Nutzer sofort abspringen.
Szenario 2 – E‑Mails werden im Test gesendet, erreichen aber nie Kunden
In einer Demo sieht E‑Mail „erledigt“ aus, weil du es einmal ausprobierst und sie im Postfach landet. Das kann wahr sein, auch wenn das System für echte Nutzer nicht bereit ist.
Die Lücke zeigt sich, sobald du an Leute außerhalb deines Teams sendest. Reale Postfächer filtern aggressiv, und deine Domain hat einen Ruf (oder noch keinen). Fehlen SPF, DKIM und DMARC oder sind sie falsch, behandeln viele Provider Nachrichten als verdächtig. Aus Sicht deiner App wurde die Mail „gesendet“, aber der Nutzer sieht sie nie.
Andere Bruchstellen sind einfacher und genauso schmerzhaft. Die Absenderadresse ist falsch. Der Absendername triggert Spamregeln. Eine Vorlage rendert in einem Client, bricht aber in einem anderen. Links zeigen auf localhost oder eine Staging‑Domain. Wenn du einen Burst sendest (z. B. eine Warteliste importierst), greifen Ratenlimits und du verlierst Nachrichten, wenn du nicht queue‑st und erneut versuchst.
Die Auswirkung für Nutzer ist sofort: keine Verifizierungs‑Mail heißt kein Konto. Kein Passwort‑Reset bedeutet Support‑Tickets. Keine Quittungs‑Mail lässt Leute denken, sie seien belastet worden, obwohl die Zahlung in Ordnung war.
Bevor du „E‑Mails sind unzuverlässig“ als Schuldigen nennst, prüfe die Grundlagen: Provider‑Logs (accepted, deferred, rejected), Bounce‑ und Complaint‑Events, SPF/DKIM/DMARC‑Ausrichtung und einen kleinen Batch‑Test über Gmail, Outlook und Apple Mail. Scanne außerdem Templates auf kaputte Links und alles, was nach Staging aussieht.
Ein häufiger Fehler sieht so aus: Deine Anmeldung funktioniert für deine eigene Adresse, aber ein Kunde mit Outlook bekommt die Verifizierungs‑Mail nie. Er klickt fünfmal „erneut senden“ und deine App drosselt oder sperrt ihn. Oft ist die wirkliche Ursache Zustellbarkeit plus ein Template‑Problem, sodass selbst zugestellte Mails in einer Sackgasse landen.
Szenario 3 – Zahlungen funktionieren im Sandbox, schlagen mit echten Karten fehl
Sandbox‑Zahlungen sind freundlich gestaltet. Testkarten werden oft genehmigt und der Happy Path sieht perfekt aus. Echte Banken verhalten sich nicht wie eine Sandbox, und die App muss mit unordentlichen Ergebnissen umgehen.
Bei echten Karten tauchen zusätzliche Prüfungen auf. Ein Nutzer kann 3D Secure sehen und den Fluss abbrechen. AVS/CVC‑Checks können fehlschlagen, wenn die Rechnungsadresse leicht abweicht. Banken lehnen aus Gründen ab, die du nicht vorhersiehst. Füg Währungsumrechnung, Steuern und regionale Regeln hinzu, und dein „Ein‑Button‑Bezahlen“ wird zu einer Menge Verzweigungen.
Der häufigste Produktionsbruch ist nicht das Zahlungsformular. Es ist alles drumherum, besonders Webhooks. In einer Demo ist es verführerisch anzunehmen, „Zahlung erfolgreich“ und sofort Zugriff freizugeben. In Produktion ist das Webhook‑Ereignis die Quelle der Wahrheit, und es kann spät ankommen, zweimal ankommen oder gar nicht, wenn das Endpoint falsch konfiguriert ist.
Achte auf diese Tag‑1‑Muster:
- Zugriff gewährt vor Bestätigung, dann schlägt die Belastung fehl oder wird zurückgebucht.
- Webhooks werden ignoriert, Nutzer zahlen, ihr Konto wird aber nicht aktualisiert.
- Keine Idempotenz, sodass Retries doppelte Abbuchungen erzeugen.
- Race‑Bedingungen zwischen der Erfolgsseite und der Webhook‑Verarbeitung.
Support‑Tickets folgen demselben Drehbuch: Ein Kunde sieht „Zahlung fehlgeschlagen“, versucht es erneut und findet dann zwei Abbuchungen. Oder er erhält Zugriff, obwohl die Zahlung nie abgeschlossen wurde, was zu Rückerstattungschaos führt.
Was du validieren musst, bevor echte Nutzer zahlen, ist einfach, aber unverhandelbar: End‑to‑End Webhook‑Flow, Idempotency‑Keys bei Create/Confirm‑Aktionen und saubere Stornierungs‑ und Rückerstattungspfade. Teste Fehler absichtlich (falsche CVC, gescheiterte 3D Secure, abgelehnte Karte) und bestätige, dass deine Datenbank konsistent bleibt.
Schritt‑für‑Schritt – Einen Prototyp in eine nutzerbereite Version verwandeln
Wenn mit KI erstellte Apps bei echten Nutzern scheitern, ist es selten ein großer Fehler. Es sind viele kleine Lücken, die die Demo nie trifft. Der schnellste Weg vorwärts ist, ein paar reale Journeys auszuwählen und sie langweilig zuverlässig zu machen.
Beginne damit, die fünf wichtigsten Nutzerwege in einfachen Worten aufzuschreiben: Anmeldung, Einloggen, E‑Mail‑Verifizierung, Passwort zurücksetzen und Bezahlen. Definiere für jeden, was „Erfolg“ für den Nutzer bedeutet und was in deiner Datenbank wahr sein sollte.
Füge dann grundlegendes Logging hinzu, damit du drei Fragen schnell beantworten kannst: Was ist fehlgeschlagen, für welchen Nutzer und warum. Du brauchst keine ausgefallenen Dashboards in dieser Phase, nur genug Breadcrumbs, um das Rätselraten zu beenden.
Eine praktische Reihenfolge, die für die meisten Teams funktioniert:
- Definiere die fünf Journeys und eine kurze Erfolgsliste für jede.
- Füge Logs an riskanten Stellen hinzu (Auth‑Callbacks, E‑Mail‑Sends, Zahlungsbestätigung).
- Teste Edge‑Cases absichtlich: falsches Passwort, abgelaufener Reset‑Link, langsames Netzwerk, doppeltes Klicken auf „Pay“.
- Füge Schutzmechanismen hinzu: Timeouts, sichere Retries und Fehlermeldungen, die dem Nutzer sagen, was als Nächstes zu tun ist.
- Starte ein kleines Pilotprogramm (5–20 Nutzer) und behebe zuerst die Dinge, die sie treffen, bevor du mehr einlädst.
Eine kleine Änderung mit sofortiger Wirkung: Wenn der Passwort‑Reset fehlschlägt, zeige nicht „Etwas ist schiefgelaufen.“ Sag dem Nutzer, ob der Link abgelaufen ist, biete an, ihn erneut zu senden, und logge den genauen Grund (Token ungültig, Nutzer nicht gefunden, Provider‑Ablehnung).
Die versteckten Risiken – Sicherheit, Secrets und Datenintegrität
Ein Prototyp kann sich „fertig“ anfühlen, weil der Happy Path funktioniert. In Produktion sind viele Ausfälle eigentlich Sicherheits‑ und Datenkonsistenzprobleme, die sich als „zufällige Bugs" zeigen.
Sicherheitsprobleme, die wie gewöhnliche Glitches aussehen
Nicht‑technische Teams erleben diese oft als wackeliges Verhalten: Jemand wird ausgeloggt, ein Feature funktioniert bei einer Person, aber nicht bei einer anderen, oder Daten „verschwinden“. Im Hintergrund kann das eine Sicherheitslücke sein.
Häufige Probleme in KI‑Code sind exponierte Secrets (API‑Keys in Repos, in Browser‑Bundles oder Logs), kaputte Autorisierung (Nutzer können durch Ändern einer ID auf fremde Datensätze zugreifen) und Injection‑Risiken (Eingaben werden ohne sichere Behandlung in DB‑Queries eingefügt). Ein realistisches Beispiel: Ein Admin‑Screen sieht im Test gut aus, aber in Produktion kann jeder eingeloggte Nutzer ihn laden, weil die App nur prüft „ist eingeloggt“ und die „ist Admin“ Prüfung vergisst.
Datenintegrität: Die App funktioniert, bis sie es nicht mehr tut
Datenprobleme sind schwerer zu erkennen als UI‑Bugs. Du siehst sie oft erst, nachdem reale Nutzung Edge‑Cases erzeugt.
Achte auf doppelte Aktionen (Doppelklicks oder Retries, die doppelte Bestellungen erzeugen), fehlende Transaktionen (Schritt 1 gelingt, Schritt 2 scheitert und hinterlässt halb aktualisierte Daten) und Teil‑Updates (die UI sagt „gespeichert“, aber nur einige Felder wurden geändert).
Häufige Fallen, die Teams beim schnellen Release übersehen
Eine Demo belohnt den Happy Path. Echte Nutzer bringen vergessene Passwörter, langsame Verbindungen, abgelaufene Sessions und merkwürdiges Timing mit.
Ein Fehler ist, dem ersten Erfolg zu vertrauen. Hast du Login nur einmal auf deinem Laptop getestet, hast du nicht geprüft, was nach Logout, Refresh, auf einem zweiten Gerät oder bei einer über Nacht abgelaufenen Session passiert. Die App kann stabil wirken, ist aber oft nur eine Edge‑Case‑Änderung von echten Sperren entfernt.
Eine andere Falle ist das Aufschieben von Wiederherstellungsfunktionen. Passwort‑Reset, E‑Mail‑Änderung und Account‑Recovery fühlen sich optional an, bis der erste Kunde nicht mehr reinkommt. Dann wird Support dein Produkt und du patchst sicherheitskritische Flows unter Druck.
Hintergrundarbeit ist der Bereich, in dem viele Prototypen Abkürzungen nehmen. E‑Mails, Zahlungsupdates und Datenabgleiche hängen oft von Webhooks, Queues und Cron‑Jobs ab. Fehlen diese oder sind sie brüchig, sieht alles beim Klicken gut aus, aber der echte Systemzustand driftet über Stunden und Tage.
Einige Fallen tauchen immer wieder auf:
- Ein Feature „funktioniert einmal“, schlägt aber beim zweiten Mal fehl, weil Zustand im Browser statt auf dem Server gespeichert wird.
- Account‑Recovery fehlt, sodass ein schlechter Login‑Versuch in einen verlorenen Nutzer mündet.
- Webhook‑Ereignisse werden nicht vollständig verarbeitet, sodass Rückerstattungen, fehlgeschlagene Zahlungen und Bounces nie die DB aktualisieren.
- Es gibt keinen Monitoring‑Plan, sodass du von wütenden Nachrichten statt von Alerts über Ausfälle erfährst.
- Die Codebasis verknotet sich schnell und macht jede Änderung riskant.
Beispiel: Du startest eine bezahlte Beta am Montag. Am Dienstag wird die Support‑Inbox voll. Die App markiert Bestellungen als bezahlt, obwohl das nur die anfängliche Checkout‑Antwort war, und du kannst das Problem nicht reproduzieren, weil es vom Webhook‑Timing abhängt.
Kurze Checkliste, bevor du echte Nutzer einlädst
Mach eine kurze "Real‑User‑Rehearsal". Demos verbergen Alltagsdinge: Gerätewechsel, Passwortvergessen, Doppelklicks und unordentliche Daten.
Führe diese Prüfungen in einer Staging‑Umgebung mit zwei Konten durch (ein neues, ein bestehendes). Schreib auf, was passiert und wie lange jeder Schritt dauert.
- Account‑Loop: Erstelle ein Konto, bestätige es (falls nötig), logg dich aus und wieder auf einem anderen Gerät oder Browserprofil ein.
- Passwort‑Reset‑Loop: Starte einen Reset, überprüfe, dass die Mail schnell ankommt (Ziel: unter 2 Minuten) und dass der Reset‑Link nur einmal funktioniert.
- Zahlungs‑Loop: Teste eine erfolgreiche Belastung, eine abgelehnte Karte, eine Rückerstattung und einen Doppelklick auf "Pay".
- Secrets‑Check: Untersuche das Frontend‑Build und Netzwerkanfragen und bestätige, dass keine API‑Keys, DB‑URLs oder Service‑Tokens im Browser offengelegt sind.
- Sichtbarkeits‑Check: Erzwinge einen Fehler (falsches Webhook‑Secret, ungültige E‑Mail, fehlgeschlagene Zahlung) und bestätige, dass du ihn klar in den Logs mit genug Details siehst, um zu handeln.
Eine praktische Methode: Bitte eine Freundin/einen Freund, die Schritte ohne Hilfe durchzuführen. Wenn sie verwirrt sind oder du Fehler nicht schnell diagnostizieren kannst, pausiere den Launch und schließe diese Lücken zuerst.
Ein realistisches Launch‑Week‑Beispiel (und wie man sich erholt)
Ein Gründer baut eine KI‑gemachte App, liefert eine starke Demo und lädt 50 Beta‑Nutzer am Montag ein. Die erste Stunde fühlt sich großartig an. Bis zum Mittag häufen sich Support‑Nachrichten.
Am ersten Tag führen drei kleine Risse zu echten Problemen. Einige Nutzer landen in Login‑Schleifen nach einem Passwort‑Reset, weil Sessions und Redirects schlampig gehandhabt wurden. Andere erhalten nie Verifizierungs‑Mails, weil die App eine Test‑Sender‑Konfiguration nutzte, die lokal funktionierte, aber nicht in echten Postfächern. Einige bezahlen, sehen eine Erfolgsseite und haben trotzdem keinen Zugriff, weil die App „Zahlung erfolgreich“ und „Abo aktiv“ gleichsetzt.
Am zweiten Tag macht der Gründer manuelle Fixes: Konten löschen, Flags in der DB umschalten und Nutzer bitten, es erneut zu versuchen. Verwirrte Nutzer melden sich doppelt an, Mail‑Provider drosseln Zugriffe, und einige Kunden fordern Rückerstattungen, nachdem sie belastet, aber blockiert wurden. Die App ist nicht „down“, aber Vertrauen ist weg.
Ein fokussierter Reparatur‑Sprint unterscheidet sich vom wilden Patchen. Ziel ist, die Top‑Flows zuverlässig zu machen, bevor Neues hinzugefügt wird:
- Reproduziere Fehler Ende‑zu‑Ende für Kern‑Flows (Login, E‑Mail‑Verifizierung, Bezahlen, Freischaltung).
- Behebe Root‑Causes, nicht nur Symptome (Tokens, Redirects, Webhooks, State‑Checks).
- Füge Schutzmechanismen hinzu wie Ratenbegrenzung, sichere Retries und klare Fehlermeldungen.
- Reteste unter realen Bedingungen (frische Konten, echte Postfächer, echte Karten).
- Führe ein kleines Beta (5–10 Nutzer) erneut durch, bevor du wieder öffnest.
Triff dann eine klare Entscheidung zum Umfang. Patch, wenn die Architektur überwiegend intakt ist und die Fehler isoliert sind. Refaktoriere, wenn dasselbe Bug‑Muster überall auftaucht. Baue neu, wenn die Codebasis zu verknotet ist, um sicher Änderungen vorzunehmen — das kommt bei KI‑generierten Prototypen häufig vor.
Nächste Schritte – Klarheit gewinnen, dann die richtigen Dinge zuerst reparieren
Wenn deine App mit Tools wie Lovable, Bolt, v0, Cursor oder Replit gebaut wurde, nimm an, dass sie für eine Demo optimiert wurde. Das heißt nicht, dass sie schlecht ist. Es heißt, dass du Abkürzungen bei Login, E‑Mails, Zahlungen und Sicherheit erwarten solltest.
Bevor du neu schreibst, verschaffe Klarheit darüber, was tatsächlich fehlschlägt. Teams verlieren Wochen, weil sie die falschen Teile neu bauen, wenn sie von Meinungen statt von Beweisen ausgehen.
Sammle Beweise aus echtem Gebrauch und reduziere sie auf die wenigen Flows, die zählen. Ein Nutzer kann sein Passwort nicht zurücksetzen, ein anderer bekommt keine Willkommens‑Mail, ein dritter sieht einen Zahlungsfehler mit einer echten Karte. Das reicht, um den nächsten Sprint zu planen.
Was du in einem kurzen Durchlauf sammeln solltest:
- 3–5 Nutzerberichte mit genauen Schritten (was sie angeklickt haben und was sie erwartet haben)
- Screenshots von Fehlermeldungen und der vollständige Text der Meldungen
- Die Top‑3 gebrochenen Flows, die Anmeldungen oder Umsatz blockieren
- Hinweise, wo es passiert (Gerät, Browser, Uhrzeit)
- Zugriff auf Logs oder das, was dein Host bereitstellt
Fordere dann eine Diagnose statt eines sofortigen Rebuilds an. Ein gutes Audit ordnet Symptome Root‑Causes zu (Session‑Handling, E‑Mail‑Domain‑Setup, fehlende Validierung, nicht verarbeitete Webhooks) und priorisiert Fixes nach Impact.
Wenn du einen geerbten KI‑generierten Prototypen hast, der unter realer Nutzung bricht, konzentriert sich FixMyMess (fixmymess.ai) auf die Diagnose und Reparatur genau dieser Lücken: Authentifizierung, Zustellbarkeit, Webhook‑Logik, Sicherheits‑Härtung und Aufräumarbeiten, die den Code sicher zur Auslieferung machen. Ein kurzes Audit kann aus „funktioniert in der Demo" eine kurze, priorisierte Fix‑Liste machen, die du mit Vertrauen abarbeiten kannst.
Häufige Fragen
Warum sieht meine App in der Demo perfekt aus, bricht aber bei echten Nutzern zusammen?
Eine Demo beweist einmalig den Happy Path unter deinen Bedingungen. Produktion muss wiederholte Nutzung, unordentliche Eingaben, langsame Netze, abgelaufene Sessions, mehrere Geräte und Nutzer, die in „falscher“ Reihenfolge klicken, verarbeiten.
Was sollte ich zuerst fixen, bevor ich echte Nutzer einlade?
Konzentriere dich auf die Kernwege, die Vertrauen und Umsatz schaffen: Anmelden, Einloggen, E‑Mail verifizieren, Passwort zurücksetzen und Bezahlen. Sorge dafür, dass jeder Ablauf wiederholt gelingt und Fehler verständlich sind, damit Nutzer sich selbst erholen können.
Warum sagen Nutzer: „Ich kann mich einmal einloggen, dann funktioniert es nicht mehr"?
Das ist meist ein Problem mit Sessions oder Redirects, nicht mit dem Login-Button selbst. Cookies können so gesetzt sein, dass sie nur auf localhost funktionieren, oder Browser‑Privacy‑Einstellungen blockieren sie, was nach dem ersten erfolgreichen Login zu Schleifen führt.
Was ist der häufigste OAuth‑Fehler in KI‑generierten Apps?
OAuth‑Provider verlangen exakt passende Callback‑URLs und Redirect‑Verhalten. Eine kleine Abweichung zwischen Umgebungen kann dazu führen, dass der Provider „Erfolg“ meldet, deine App aber die Session nicht abschließt und Nutzer zurück auf den Login schickt.
Warum funktionieren E‑Mails bei mir, erreichen Kunden sie aber nie?
Senden heißt nicht gleich Zustellen. Fehlt SPF/DKIM/DMARC oder sind diese falsch konfiguriert, stufen viele Provider die Mails als verdächtig ein. Deine App meint „gesendet“, der Kunde sieht die Verifizierungs‑ oder Reset‑Mail aber nie.
Was sollte ich an E‑Mail‑Templates vor dem Launch prüfen?
Oft bleibt ein Staging‑Artefakt: Links zeigen noch auf localhost oder eine Testdomain, oder die Absenderidentität triggert Spamfilter. Selbst wenn die Mail ankommt, macht ein defekter Link oder die falsche Umgebung sie wirkungslos.
Warum funktionieren Zahlungen im Sandbox, aber mit echten Karten nicht?
Sandbox‑Flows sind nachsichtig; echte Banken sind es nicht. 3D Secure, AVS/CVC‑Prüfungen, Währungsumrechnung, Steuern und regionale Regeln schaffen Abzweigungen, die dein System verarbeiten muss, ohne den Zustand zu korruptieren.
Was sind die größten Webhook‑Fehler, die Abrechnungschaos verursachen?
Webhooks sind in Produktion die Wahrheit. Sie können verspätet, doppelt oder gar nicht ankommen. Ohne Idempotenz und konsistente Webhook‑Verarbeitung siehst du doppelte Abbuchungen, bezahlte Nutzer ohne Zugriff oder Zugriff ohne Bezahlung.
Welche Sicherheitsprobleme verbergen sich hinter „zufälligen" Produktionsfehlern?
KI‑generierte Prototypen legen manchmal Geheimnisse offen (API‑Keys in Repos oder Builds) und haben fehlerhafte Autorisierung, sodass Nutzer Daten sehen, die sie nicht sollten. Solche Probleme wirken wie zufällige Fehler, sind aber ernsthafte Sicherheitslücken.
Wann sollte ich patchen vs. refaktorisieren vs. komplett neu bauen, und wer kann helfen?
Erst sammel genug Informationen, um zu wissen, was für welchen Nutzer warum fehlschlägt, und reproduziere das Problem dann Ende‑zu‑Ende. Wenn du wiederholt mit Flickwerk kämpfen musst oder der Code zu verknotet ist, hilft ein Auditergebnis, das Symptome den Ursachen zuordnet und Fixes nach Wirkung priorisiert. FixMyMess (fixmymess.ai) bietet solche Audits und kann oft innerhalb von 48–72 Stunden nach Diagnose einen klaren Plan liefern.