Konfigurationsprobleme „it works on my machine“ für Dev, Staging und Prod
Behebe „it works on my machine“-Konfigurationsprobleme mit klarer Trennung von Dev, Staging und Prod, Validierung von Umgebungsvariablen und einfachen Prüfungen, die Laufzeitüberraschungen verhindern.
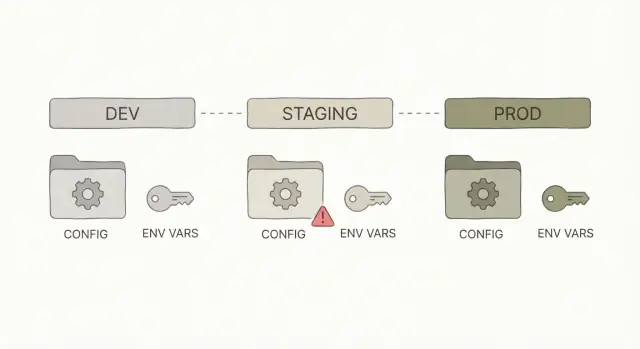
Was „it works on my machine“ normalerweise bedeutet
Wenn jemand sagt „it works on my machine“, meint er oft: Die App läuft auf seinem Laptop, bricht aber nach dem Deploy zusammen. Der Code kann derselbe sein, aber das Drumherum ist anders.
Meistens ist das kein Logikfehler. Es ist Konfiguration: Die App bekommt je nach Umgebung unterschiedliche Eingaben. Lokal füllt dein Rechner oft stillschweigend Lücken (gespeicherte Logins, lokale Dateien, initiale Datenbanken, gecachte Tokens). In Staging oder Produktion sind diese Krücken nicht da.
Häufige Ursachen:
- Fehlende oder falsche Umgebungsvariablen (API-Keys, Datenbank-URL, Auth-Callback-URL)
- Unterschiedliche externe Dienste (lokale SQLite vs. gehostetes Postgres, Test-Stripe vs. Live-Stripe)
- Unterschiedliche URLs und Redirects (localhost vs. echte Domain)
- Unterschiedliche Build- und Laufzeit-Einstellungen (Node-Version, Port, Feature-Flags)
- Secrets, die in Code oder
.env-Dateien gelandet sind und in Produktion nie gesetzt wurden
Konfigurationsprobleme zeigen sich oft als verwirrende Symptome: Login funktioniert lokal, bricht nach dem Deploy; Zahlungen laufen in Zeitüberschreitung; Bilder laden nicht hoch; Background-Jobs laufen nicht. Der Codepfad ist gleich, aber die App zeigt auf das falsche Ziel oder es fehlt ein erforderlicher Wert.
Das Ziel ist reproduzierbares Verhalten in jeder Umgebung. Dev, Staging und Prod können unterschiedliche Werte nutzen, aber sie sollten denselben Regeln folgen. Wenn eine Variable in Prod erforderlich ist, behandle sie überall als erforderlich. Wenn Staging eine andere Datenbank nutzt, sollte sie trotzdem dasselbe Schema und dieselbe Art der Verbindung verwenden.
Beispiel: Eine AI-generierte App deployed und wirft sofort „DATABASE_URL is undefined.“ Lokal hatte der Entwickler eine private .env-Datei. In Produktion wurde sie nie gesetzt. Die Lösung ist nicht, im Code zu suchen. Die Lösung ist, erforderliche Konfiguration zu definieren, beim Start zu validieren und in jeder Umgebung zu setzen.
Dev vs Staging vs Prod: Was sich ändert und was nicht
Dev, Staging und Prod sind dieselbe App an drei verschiedenen Orten.
- Dev ist der Ort, an dem du schnell auf deinem Laptop baust und ausprobierst.
- Staging ist eine Generalprobe, die sich wie Produktion verhalten sollte, aber ohne echte Kunden.
- Prod ist das Live-System, auf das Menschen angewiesen sind.
Einige Dinge sollten zwischen den Umgebungen unterschiedlich sein, weil sie auf andere Dienste oder Daten zeigen. Andere Dinge müssen identisch bleiben, damit du wirklich testest, was du auslieferst.
Was sich ändern sollte
Behalte den gleichen App-Code, aber tausche die Werte drumherum aus:
- Service-URLs (API-Basis-URL, OAuth-Callback-URL, Webhook-URL)
- Keys und Secrets (für jede Umgebung eigene Zugangsdaten)
- Datenquellen (separate Datenbanken und Buckets oder zumindest separate Schemata)
- Feature-Flags (sichere Defaults in Prod, mehr Schalter in Dev)
- Logging-Level (mehr Details in Dev, weniger Lärm in Prod)
Die Umgebung sollte diese Werte bestimmen, nicht der lokale Rechner des Entwicklers.
Was nicht geändert werden darf
Build und Laufzeit sollten zwischen Staging und Prod übereinstimmen: gleiche Dependencies, gleicher Build-Schritt, gleicher Start-Befehl und dieselbe Runtime-Version. Wenn Staging node 20 nutzt, Prod aber node 16, testest du eine andere App.
Vermeide „nur dieser eine schnelle Change“ in Produktion, wie das direkte Editieren einer Konfigurationsdatei auf dem Server oder das Hinzufügen einer fehlenden Env-Var per Hand, ohne es zu dokumentieren. Solche One-off-Fixes schaffen Fehler, die sich später nicht reproduzieren lassen. Ein häufiges Beispiel: Jemand fixt im Hotfix einen Auth-Redirect in Prod, Staging bleibt veraltet und der nächste Deploy bricht erneut den Login.
Umgebungsvariablen 101 (ohne Fachchinesisch)
Eine Umgebungsvariable (Env Var) ist eine Einstellung, die deine App beim Start liest. Sie liegt außerhalb deines Codes und wird meist vom Terminal, dem Hosting-Service oder dem Deployment-Tool bereitgestellt.
Betrachte Env Vars als Eingaben für deine App. Behandle sie als Anforderungen, nicht als Vorschläge. Fehlt ein Wert, sollte die App schnell mit einer klaren Meldung abbrechen, statt weiterzuarbeiten und später zu scheitern.
Eine einfache Einteilung, was wohin gehört:
- Env Vars: Werte, die sich pro Umgebung ändern oder sensibel sind. Beispiele:
DATABASE_URL,JWT_SECRET,STRIPE_API_KEY,S3_BUCKET,APP_ENV. - Code: Defaults und Logik, die überall gleich sein sollten. Beispiel: „Sessions laufen nach 7 Tagen ab.“
- Konfigurationsdateien (im Repo): Nicht-geheime Einstellungen, die du überprüfen und versionieren willst. Beispiel: Feature-Flags, UI-Labels, erlaubte CORS-Ortigin (nur wenn sie nicht sensibel sind).
Beim Benennen wird es oft chaotisch. Wählt eine Konvention und haltet euch daran: Großbuchstaben, Unterstrich als Trenner und ggf. ein Prefix für mehrere Services. Vermeidet nahezu identische Namen wie DB_URL, DATABASE und DATABASE_URL an verschiedenen Stellen.
Eine häufige Falle sind „optionale“ Env Vars, die Features stillschweigend deaktivieren. Zum Beispiel könnte eine App E-Mails nur senden, wenn process.env.SMTP_PASSWORD gesetzt ist – ohne Warnung, wenn sie fehlt. Das Ergebnis: Lokale Signups funktionieren, in Produktion kommen keine Passwort-Zurücksetzen-Mails an.
Bessere Regel: Wenn ein Feature in einer Umgebung aktiviert ist, müssen seine erforderlichen Env Vars vorhanden sein, andernfalls soll die App stoppen und sagen, was fehlt.
Schritt-für-Schritt: eine einfache, konsistente Konfig-Struktur einrichten
Die meisten "it works on my machine"-Bugs entstehen, weil Config verstreut ist. Jemand setzt Werte in einer lokalen Datei, jemand anders im Hosting-Dashboard und die App nimmt einfach das zuerst Gefundene. Entscheidet euch für eine Struktur und haltet sie ein.
1) Eine einzige Quelle der Wahrheit wählen
Für die meisten Web-Apps ist die sauberste Regel: Umgebungsvariablen sind die Quelle der Wahrheit. Eine lokale .env-Datei kann eine Komfortfunktion für die Entwicklung sein, aber dein Code sollte überall auf dieselbe Weise Config lesen.
Wenn du sowohl Config-Datei als auch Env Vars unterstützen musst, definiere eine klare Priorität (z. B. Env Vars überschreiben Datei) und dokumentiere sie, damit es keine Überraschungen gibt.
2) Eine explizite Umgebungsflag hinzufügen
Lass die App ankündigen, was sie glaubt zu sein. Nutze eine Variable wie APP_ENV mit drei erlaubten Werten: development, staging, production. Vermeide das Erraten anhand von Domains oder "wenn debug true ist."
Ist die Umgebung explizit, kannst du sichere Defaults setzen, z. B. ausführliches Logging in Dev und weniger Noise in Prod.
Eine praktische Einrichtung für die meisten Teams:
- Behalte eine verpflichtete Vorlage
.env.example, die jede erforderliche Variable listet (ohne echte Secrets). - Nutze eine lokale-only
.env-Datei für Bequemlichkeit und halte sie aus der Versionskontrolle heraus. - Lege Staging- und Production-Werte in den Umgebungs-Einstellungen deines Hosters ab.
- Lade Config an einer Stelle (ein zentrales Config-Modul) und importiere es überall.
3) Defaults sicher machen
Defaults sind in der Entwicklung in Ordnung (z. B. eine lokale Datenbank-URL). In Produktion vermeide Defaults für alles Sensible. Ein fehlendes DATABASE_URL in Produktion sollte sofort abbrechen, nicht stillschweigend auf etwas Unbeabsichtigtes zurückfallen.
4) Dokumentiere, was Teamkollegen zum Laufen brauchen
Trage die erforderlichen Variablen an einer Stelle zusammen (in der Regel .env.example plus eine kurze README-Notiz). Das ist besonders wichtig bei AI-generierten Apps, wo Konfiguration schnell wild wächst und zwischen Code, Dateien und Dashboards verteilt landet.
Validiere Env Vars beim Start, um Überraschungen zu vermeiden
Viele "it works on my machine"-Probleme entstehen, weil die App mit fehlenden oder falschen Einstellungen startet und später bei einem bestimmten Nutzerpfad versagt. Eine einfache Lösung ist, Env Vars einmal beim Boot zu validieren und die Ausführung zu verweigern, wenn etwas nicht passt.
Schnell abbrechen mit klaren Checks
Behandle Config wie Eingabedaten. Fehlen erforderliche Werte, stoppe die App und gib eine Fehlermeldung aus, die genau sagt, was gesetzt werden muss (ohne Geheimnisse zu verraten).
Was sich lohnt, früh zu validieren:
- Vorhandensein: erforderliche Werte wie
DATABASE_URL,AUTH_SECRET,PORT - Typ:
PORTist eine Zahl,DEBUGist boolean, Timeouts sind Integer - Format: URLs sehen aus wie URLs, E‑Mails wie E‑Mails
- Cross-Field-Regeln: wenn
FEATURE_X=true, muss auchFEATURE_X_KEYgesetzt sein - Erlaubte Werte:
APP_ENVist eines vondevelopment,staging,production
Nach der Validierung logge eine kurze Start‑Zusammenfassung wie Umgebungsname, App-Version und welche optionalen Features aktiviert sind. Drucke niemals Secrets, komplette Connection-Strings oder Tokens. Falls Bestätigung nötig ist, logge nur, dass ein Wert gesetzt ist, oder einen sicheren Fingerabdruck (z. B. die letzten 4 Zeichen).
Füge einen Config-Self-Test-Command hinzu
Ein leichter Konfig-Selbsttest macht Deploys sicherer, weil du ihn vor dem Start des Servers laufen lassen kannst.
Zum Beispiel:
config:testlädt Env Vars, validiert sie und beendet sich mit Exit-Code 0/1- Es gibt aussagekräftige Fehler aus (fehlende Schlüssel, falsche Typen, ungültige URLs)
- Es kann sicher eine Verbindung bestätigen (z. B. Erreichbarkeit der DB), ohne Zugangsdaten auszudrucken
Halte Secrets aus dem Code (und aus Logs)
Ein „Secret“ ist alles, was Zugang gewährt: API-Keys, OAuth-Client-Secrets, Session-Signing-Keys, DB-Passwörter, private Verschlüsselungsschlüssel, Webhook-Signing-Secrets und interne Service-Tokens. Wenn jemand so etwas hat, kann er sich als du oder deine App ausgeben.
AI-generierte Apps leaken Geheimnisse oft an zwei Stellen: im Code und in Logs. Ein Key wird „nur zum Testen“ hardcodiert, eine Connection-String landet in einem Commit oder jemand druckt process.env zum Debuggen und vergisst es vor dem Shippen.
Regeln, die die meisten Vorfälle verhindern:
- Committe niemals Secrets ins Repo, auch nicht „temporäre“.
- Sende niemals Secrets an den Browser oder mobile Clients. Wenn der Nutzer es sehen kann, ist es kein Secret.
- Logge keine Secrets oder komplette Header. Redaktiere Tokens und Passwörter.
- Bevorzuge kurzlebige Tokens, wo möglich.
Wenn du vermutest, ein Key wurde exposed, behandle ihn als kompromittiert. Rotiere ihn und bestätige, dass der alte Wert wirklich ungültig ist (viele Plattformen lassen alte Keys aktiv, bis du sie deaktivierst). Prüfe Deployment-History, Logs und geteilte Screenshots oder Fehlerberichte.
Verwende für jede Umgebung separate Zugangsdaten. Dev, Staging und Prod sollten nicht denselben DB-User, API-Key oder Signatur-Secret teilen. Dann führt ein Leak in Staging nicht automatisch zu Prod-Zugriff.
Sorge dafür, dass Staging genug wie Prod ist, um nützlich zu sein
Staging fängt Probleme, die erst nach dem Deploy auftreten, aber es funktioniert nur, wenn es in den relevanten Bereichen wie Produktion ist.
Beginne mit reproduzierbaren Builds. Wenn Staging Node 20 nutzt und Prod Node 18, oder wenn eine Umgebung andere Dependency-Versionen installiert, testest du nicht dasselbe. Sperre Runtime-Versionen und Dependencies (pinne Versionen, committe Lockfile, nutze denselben Build-Befehl überall). Vermeide umgebungsspezifische Installationsschritte, die Verhalten verändern oder Checks überspringen.
Halte Staging in den kritischen Pfaden nahe an Prod: dieselbe Art von Datenbank, dasselbe Cache- oder Queue-System, wenn du eines nutzt, und dieselbe Startreihenfolge (Migrationen, Seed-Schritte, Background-Jobs). Es braucht nicht die volle Skalierung oder echte Daten, aber es sollte dieselben Dienste und dieselbe Reihenfolge der Operationen nutzen.
Health-Checks sind dein Frühwarnsystem. Ein guter Staging-Deploy sollte schnell fehlschlagen, wenn er die Datenbank nicht erreichen kann, Migrationen ausstehen oder erforderliche Env Vars fehlen.
Ein einfacher Standard:
- Gleiche Runtime und Dependency-Lockfile in Dev, Staging und Prod
- Derselbe Build-Artefakt wird von Staging zu Prod promoted (nicht neu gebaut)
- Gleiche Start-Schritte (migrate, dann Web-Prozess starten, dann Worker)
- Ein grundlegender Health-Check, der DB-Verbindung und ein paar Schlüssel-Endpunkte prüft
- Ein aufgezeichneter Config-Fingerprint pro Deploy (welche Env-Var-Namen gesetzt waren, Feature-Flags an/aus), ohne Werte
Häufige Fehler, die Laufzeit-Ausfälle verursachen
Die meisten "es lief gestern noch"-Bugs sind nicht zufällig. Sie stammen meist von Config-Drift: Jemand ändert eine Einstellung, macht einen Hotfix oder passt ein Secret an einer Stelle an und vergisst, es zu dokumentieren. Eine Woche später rollt ein Deploy den Code zurück, aber nicht die Settings, und die App bricht auf eine Weise, die mysteriös wirkt.
Ein weiterer Klassiker ist das Verlassen auf lokale Dateien, die in Produktion nicht existieren. Dein Laptop hat vielleicht einen uploads/-Ordner mit großzügigen Rechten, eine lokale SQLite-Datei oder eine .env, die nie auf dem Server ist. In Produktion ist das Dateisystem ggf. read-only, Container starten neu und „diese Datei“ ist einfach nicht da.
Fehler, die oft zu Ausfällen führen:
- Warnungen als unkritisch behandeln: fehlende Env Vars, Fallback-Defaults oder "optionale" Einstellungen, die später erforderlich werden
- Client- und Server-Env Vars vermischen und damit Secrets exponieren oder Builds brechen, weil der Browser server-only Werte nicht lesen kann
- OAuth- oder Payment-Callback-URLs in einer Umgebung vergessen zu registrieren
- Annehmen, lokale Pfade existieren überall (Uploads, Temp-Dirs, lokale DB-Dateien, Zertifikate)
- Notfall-Konfig-Änderungen im Hosting-Dashboard vornehmen und diese nicht in die gemeinschaftliche Dokumentation zurückspielen
Kleines Beispiel: Ein Gründer hat ein AI-generiertes Prototyp in einer gehosteten Dev-Umgebung, aber der Production-Login schlägt fehl. Die Ursache: Die App fällt auf eine Dev-Callback-URL zurück, weil die Produktionsvariable fehlt. Keine klare Fehlermeldung, nur eine Redirect-Schleife.
Kurze Checkliste vor dem Ship
Eine kurze Pre-Ship-Routine fängt die häufigsten Config-Probleme ab. Führe sie in genau der Umgebung aus, die du auslieferst (Staging zur Generalprobe, Production für den echten Release).
- Bestätige, dass jede erforderliche Umgebungsvariable gesetzt ist (und nicht leer). Überprüfe besonders Werte, die sich je nach Umgebung unterscheiden: Basis-URLs, API-Keys, E-Mail-Einstellungen.
- Verifiziere, dass die App auf die richtige Datenbank und den richtigen Storage zeigt (DB-Host/-Name, Storage-Bucket, Queue, Cache). Ein falscher Wert kann Production-Traffic an Staging schicken.
- Prüfe Auth-Einstellungen End-to-End: Redirect-URLs, Cookie-Domain, Session-Settings, erlaubte CORS-Origins.
- Führe Startup-Config-Validierung vor dem Release aus. Die App sollte das Starten verweigern, wenn etwas Kritisches fehlt oder offensichtlich falsch ist.
- Mache einen realistischen End-to-End-Flow in Staging: Signup, Login, Passwort-Zurücksetzen, Zahlung, Upload, Export, einen Teammember einladen.
Wenn Staging-Tests passen, aber Production-Login scheitert, liegt die Ursache oft in grundlegenden Dingen: Redirect-URL zeigt auf die falsche Domain, Cookie-Domain ist falsch oder ein erforderliches Auth-Secret fehlt.
Beispiel: echte Config-Aufräumarbeit an einer AI-generierten App
Ein Gründer hatte eine AI-generierte App, die lokal gut aussah, aber nach dem Deploy sofort scheiterte. Das Problem war nicht kompliziert. Production nutzte andere Variablennamen, ein Secret fehlte und eine URL zeigte noch auf localhost.
Was nach dem Deploy kaputtging
Nutzer konnten die Seite öffnen, aber der Login schlug fehl. Die Symptome variierten: mal ein weißer Bildschirm, mal ein generischer 500-Fehler.
Ursachen:
- OAuth-Callback-URL war noch
http://localhost:3000/... - Ein erforderliches Auth-Secret (zum Signieren von Sessions oder Tokens) war in Produktion nicht gesetzt
- Eine Staging-Datenbank-URL wurde versehentlich in Produktion verwendet
Wie wir es ohne Raten gefixt haben
Zuerst haben wir die Umgebungsvariablen auditiert: jeden Konfig-Wert, den die App liest, woher er kommt und welche Umgebung ihn braucht. Dann standardisierten wir Namen und trennten Werte sauber zwischen Dev, Staging und Prod.
Wir fügten Guardrails hinzu, damit Fehler sofort sichtbar werden:
- Validierung erforderlicher Variablen beim Start und Liste der fehlenden Werte
- Format-Validierung (z. B. in Prod nur HTTPS-URLs, Secrets mit Mindestlänge)
- Blockieren unsicherer Defaults in Produktion (keine localhost-Callbacks, keine Platzhalter-Keys)
- Nur sichere Hinweise loggen (nie Secrets drucken)
Danach wurden Deploys vorhersehbar. Staging verhielt sich da wie Prod, wo es wichtig war, und Probleme traten beim Start auf statt beim User-Login.
Nächste Schritte: Härtung der Konfiguration, ohne stecken zu bleiben
Versuche nicht, alles auf einmal perfekt zu machen. Wähle eine kleine Änderung, die Überraschungen sofort reduziert, verifiziere sie lokal und nach dem Deploy und mach vor dem nächsten Release eine kurze Nachbesserung.
Gute "heutige" Erfolge:
- Eine
.env.examplehinzufügen, die jede erforderliche Variable listet (mit sicheren Platzhaltern) - Startup-Validierung hinzufügen, damit die App schnell fällt, wenn eine Variable fehlt oder falsch formatiert ist
- Hardcodierte Keys, URLs und Debug-Flags aus dem Code entfernen und in die Umgebungs-Konfiguration verschieben
- Aufhören, Secrets in Logs zu drucken (auch nicht in "temporären" Debug-Logs)
- Verwirrende Variablen umbenennen, damit sie dem Zweck entsprechen
Dann eine zeitlich begrenzte Härtung:
- Vergleich von Dev-, Staging- und Prod-Variablennamen: nur Werte sollen unterschiedlich sein
- Auth-Einstellungen pro Umgebung nachprüfen (Redirect-URLs, Cookie-Settings, OAuth-Callbacks)
- Sicherstellen, dass Secrets im Secret-Store der Deployment-Plattform liegen, nicht im Repo
- Einen sauberen Deploy von Grund auf durchführen, um fehlende Variablen und Annahmen zu erkennen
Wenn du ein chaotisches AI-generiertes Repo geerbt hast, beginne mit einem Config- und Secrets-Audit, bevor du Features anfasst. Dort verstecken sich meist Default-Werte, Leaks und Deploy-only-Fehler.
Wenn du nicht weiterkommst, kann FixMyMess (fixmymess.ai) dabei helfen, kaputte AI-generierte Apps zu diagnostizieren und zu reparieren, inklusive Config-Drift, Auth-Fehlern, exponierten Secrets und Deploy-Readiness. Ihr kostenloses Code-Audit zeigt dir, was fehlt und was als Nächstes zu tun ist.
Häufige Fragen
What does “it works on my machine” actually mean?
Das bedeutet meist, dass der Code selbst in Ordnung ist, die Umgebung nach dem Deploy aber anders ist. Etwas, das dein Laptop automatisch bereitstellt (Env Vars, lokale Dateien, zwischengespeicherte Tokens, initiale Daten, eine andere Datenbank) fehlt in Staging oder Produktion, sodass die App zwar im Repo gleich bleibt, aber trotzdem fehlschlägt.
What should I check first when an app breaks only after deploy?
Prüfe zuerst die Konfiguration, nicht die Geschäftslogik. Vergleiche Umgebungsvariablen, Runtime-Versionen (z. B. Node) und Service-Endpunkte zwischen lokal und deployed Umgebung und versuche, das Problem mit genau den gleichen Eingaben zu reproduzieren, die der Server sieht.
What’s the most common config mistake that causes deploy failures?
Fehlende oder falsche Umgebungsvariablen sind die häufigste Ursache. Ein typisches Anzeichen ist ein Fehler wie DATABASE_URL is undefined oder dass Features stillschweigend nicht funktionieren, weil ein Schlüssel in Produktion nicht gesetzt ist.
What should be different between dev, staging, and production?
Behalte eine App, aber drei Wertevorräte. Dev ist zum schnellen Entwickeln, Staging ist eine Generalprobe, die sich wie Prod verhalten sollte, und Prod ist die Live-Umgebung. Service-URLs, Secrets und Datenquellen verändern sich pro Umgebung; Build, Runtime-Version und Start-Schritte sollten konsistent bleiben.
What belongs in env vars versus code versus config files?
Behandle Umgebungsvariablen als veränderliche oder vertrauliche Eingaben. Geschäftsregeln und unveränderliche Defaults gehören in den Code. Nicht-geheime, überprüfbare Einstellungen kannst du in versionierten Konfigurationsdateien lassen, wenn du sicher bist, dass sie unbedenklich sind.
How do I avoid confusing “which environment am I in?” behavior?
Füge eine einzelne explizite Variable wie APP_ENV hinzu und erlaube nur erkennbare Werte wie development, staging und production. Vermeide das Erraten anhand von Domainnamen oder eines Debug-Toggles, weil das versteckte Verhaltensunterschiede erzeugt, die schwer zu reproduzieren sind.
How do I make env var problems fail fast instead of failing later?
Validiere beim Start und verweigere das Ausführen, wenn erforderliche Werte fehlen oder falsch formatiert sind. So fängst du Probleme ab, bevor echte Nutzer auf eine kaputte Seite treffen. Die Fehlermeldung sollte sagen, was gesetzt werden muss, ohne Geheimnisse zu verraten.
Is it worth adding a config:test command to my app?
Ja. Ein kleines config:test- oder ähnliches Command ist ein sicherer Vor-Deploy-Schritt: Es lädt die Konfiguration, prüft Typen und Formate und beendet sich mit aussagekräftigen Fehlern, damit du einen schlechten Release stoppen kannst, bevor der Webserver startet.
How do I prevent secrets from leaking in AI-generated apps?
Halte Geheimnisse aus dem Repo, aus clientseitigem Code und aus Logs. Wenn du annimmst, ein Secret sei geleakt, rotiere es sofort und sorge dafür, dass jede Umgebung eigene Zugangsdaten hat, damit ein Leak in Staging nicht automatisch Prod öffnet.
What’s the fastest way to stabilize a messy AI-generated app that won’t run in production?
Stelle zuerst die Struktur der Konfiguration wieder her: zentralisiere das Laden von Config, standardisiere Variablennamen und füge Start-Validierung hinzu. Wenn du ein chaotisches AI-generiertes Repo geerbt hast, kann FixMyMess eine kostenlose Code-Audit anbieten und dabei helfen, Config-Drift, Auth-Probleme und Deploy-Readiness schnell zu reparieren.