Korrelations-IDs, um Klicks über APIs und Jobs nachzuverfolgen
Korrelations-IDs verbinden einen Nutzerklick mit API-Logs und Hintergrundjobs, damit Sie Fehler schnell eingrenzen, klare Fehlerberichte teilen und Probleme mit weniger Rätselraten beheben können.
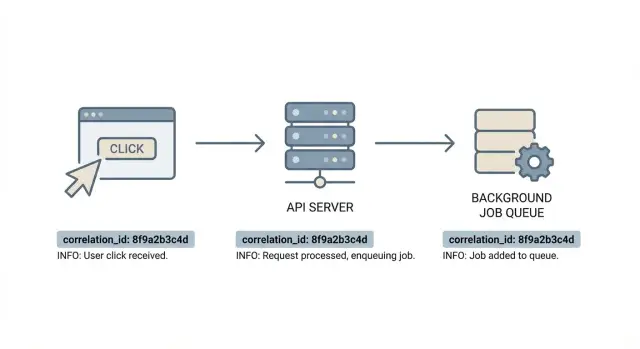
Warum Debugging sich zufällig anfühlt ohne eine gemeinsame ID
Ein Fehlerbericht beginnt oft einfach: "Ich habe auf Speichern geklickt und es ist fehlgeschlagen." Dann öffnet man die Logs und alles wird zur Ratesache. Die Browser-Konsole hat eine Gruppe Nachrichten, die API-Logs liegen anderswo und die Logs der Hintergrundjobs leben in einem weiteren System. Selbst wenn an jedem Ort viel geloggt wird, passt nichts zueinander.
Dann fühlt sich Debugging zufällig an. Sie suchen nach Zeitbereichen, Nutzer-IDs oder vagen Texten wie "payment failed" in der Hoffnung, die richtigen Zeilen zu finden. Wenn mehrere Nutzer aktiv sind oder Retries passieren, folgt man leicht dem falschen Faden.
Deshalb kommt so oft "auf meinem Rechner lief es" vor. Auf Ihrem Laptop wiederholen Sie den Klick und er klappt. In Produktion trifft derselbe Klick vielleicht einen anderen Server, verfehlt einen Cache, ruft einen langsamen Drittanbieter auf oder legt einen Job in die Queue, der später fehlschlägt. Ohne eine Möglichkeit, diese Ereignisse zu verbinden, zerfällt die Geschichte in Fragmente.
Eine Nutzeraktion kann schnell auseinanderlaufen: Ein Frontend-Klick löst eine oder mehrere API-Aufrufe aus; die API spricht die Datenbank und eventuell andere Dienste an; sie kann Jobs für E‑Mail, Abrechnung, Bildverarbeitung oder Indizierung enqueuen; und diese Jobs laufen später auf anderen Maschinen, manchmal mit Retries. Webhooks und Callbacks fügen noch mehr Schritte hinzu.
Das Ziel ist einfach: eine Spur, der Sie vom Anfang bis zum Ende folgen können. Mit Korrelations-IDs nehmen Sie ein Support-Ticket, greifen eine ID und ziehen das zugehörige Frontend-Ereignis, die exakte API-Anfrage und jede Log-Zeile der anschließend gelaufenen Jobs. Debugging hört auf, eine Schatzsuche zu sein, und wird eine verlässliche Timeline.
Was eine Korrelations-ID ist (und was nicht)
Eine Korrelations-ID ist ein einzelnes Label, das ein Stück Arbeit begleitet, während es durch Ihr System wandert. Denken Sie daran als Kontext für "eine Nutzeraktion": ein Klick, eine API-Anfrage, die ausgelösten Hintergrundjobs und alle nachgelagerten Aufrufe.
Jede Log-Zeile, die zu dieser Kette gehört, enthält dieselbe ID. So können Sie einmal suchen und die ganze Geschichte sehen.
Eine Korrelations-ID ist keine Nutzerkennung. Sie sollte nicht beschreiben, wer der Nutzer ist, worauf er geklickt hat oder welche Daten beteiligt waren. Es ist ein undurchsichtiger Tag, der Ihnen hilft, Ereignisse über Systeme hinweg ohne Vermutungen zu verbinden.
Oft wird sie mit anderen IDs verwechselt:
- Session ID verbindet viele Aktionen über die Zeit mit einer Browsersession. Nützlich für Auth und Analytics, aber zu breit, um eine einzelne fehlerhafte Aktion zu verfolgen.
- Datenbank-Record-ID identifiziert eine einzelne Zeile (z. B. eine Bestell-ID). Nützlich für Geschäftslogik, aber sie verbindet nicht automatisch Frontend, API und Queue-Verarbeitung.
- Korrelations-ID (Request ID) verbindet alle Schritte eines Ablaufs, selbst wenn mehrere Services und Jobs beteiligt sind.
Wann sollte man sie erzeugen? Idealerweise am Rand: im Browser, wenn die Aktion startet (und dann als Header mitsenden), oder am ersten API-Einstiegspunkt (Gateway/Load Balancer/App-Server), wenn Sie dem Client nicht vertrauen können. Viele Teams akzeptieren eine client-seitig übergebene ID, prüfen das Format und generieren eine neue, wenn sie fehlt oder ungültig ist.
Wie sollte sie aussehen? Machen Sie sie einzigartig, undurchsichtig und sicher zum Loggen. Ein UUID- oder ULID-ähnlicher Wert funktioniert gut. Bauen Sie keine E‑Mails, Nutzer-IDs oder sensible Daten ein.
Wo die ID in einer typischen App reisen sollte
Eine Korrelations-ID hilft nur, wenn sie die ganze Reise überlebt. Denken Sie an sie als Label, das eine Nutzeraktion vom Browser über Ihre API bis in die Hintergrundarbeit begleitet, sodass jede Log-Zeile auf denselben Moment referenzierbar ist.
In den meisten Apps bedeutet das, dieselbe ID durchzutragen in:
- dem Frontend-Ereignis (Klick oder Formular-Submit)
- der API-Anfrage
- nachgelagerten Aufrufen (interne Services und Drittanbieter)
- Hintergrundjobs (Publish und Worker-Verarbeitung)
- finalen Seiteneffekten (Datenbank-Schreibvorgänge, E‑Mails, Datei-Verarbeitung)
Verwenden Sie dieselben wenigen "Träger" überall. Im Web ist der häufigste Carrier ein HTTP-Header (viele Teams nutzen Namen wie X-Request-Id oder X-Correlation-Id). Auf dem Server speichern Sie ihn im per-request-Context, damit jede Log-Zeile ihn automatisch enthalten kann. Für Jobs fügen Sie ihn in die Job-Metadaten oder den Payload, damit der Worker ihn vor dem Loggen wiederherstellen kann.
Traceability bricht meistens an Grenzen:
- Redirects und Cross-Domain-Navigation, die Custom-Header verlieren
- Retries und Timeouts, die eine neue Request-ID erzeugen ohne die alte zu kopieren
- Queue-Publisher, die vergessen, die ID in den Job-Payload zu schreiben
- Worker-Code, der loggt, bevor er die ID in den Log-Kontext lädt
- Fan-Out-Arbeit (ein Klick erzeugt viele Jobs) ohne klare Eltern-Kind-Beziehung
Eine einfache Regel, die viel Verwirrung vermeidet: Das erste Backend, das die Anfrage empfängt, ist die Quelle der Wahrheit. Das Frontend kann eine vorhandene ID weiterleiten, wenn es schon eine hat, aber das Backend entscheidet, was akzeptiert oder neu generiert wird.
Schritt für Schritt: Korrelations-IDs Ende-zu-Ende hinzufügen
Wählen Sie einen Header-Namen und verwenden Sie ihn überall. Konsistenz ist wichtiger als die genaue Schreibweise, weil jeder Hop (Browser, API, Queue, Worker) dasselbe Feld erkennen muss.
Beginnen Sie im Frontend. Wenn der Nutzer einen Button klickt, verwenden Sie entweder eine bestehende ID für die aktuelle Aktion oder erzeugen eine neue. Bewahren Sie sie im Speicher (oder in einem kurzlebigen Request-Context-Objekt) und hängen Sie sie an jede API-Anfrage, die durch diesen Klick ausgelöst wird.
Auf der API-Seite lesen Sie den Header in Middleware. Wenn er fehlt, generieren Sie einen. Speichern Sie ihn im Request-Context, damit Logs, Fehler und nachgelagerte Aufrufe ihn aufnehmen können. Echoen Sie ihn außerdem im Response-Header zurück, damit der Browser (und der Support) die exakt verwendete ID referenzieren können.
Ein praktischer Ablauf sieht so aus:
- Frontend setzt
X-Correlation-Ideinmal pro Nutzeraktion und verwendet sie für zusammenhängende Requests wieder. - API akzeptiert den Header (oder erzeugt einen), speichert ihn im Request-Context und fügt ihn in Antworten ein.
- Beim Enqueue wird dieselbe ID in die Job-Metadaten oder den Payload kopiert.
- Der Worker stellt die ID vor dem Loggen in seinem Kontext wieder her.
- Fehler enthalten die ID in den Antworten, die Nutzern oder dem Support angezeigt werden.
Retriees sind ein häufiger Verlustpunkt. Wenn eine Anfrage wegen eines Timeouts erneut gesendet wird, behalten Sie dieselbe ID, damit ersichtlich ist, dass es dieselbe Nutzeraktion ist. Klickt der Nutzer später erneut, erzeugen Sie eine neue ID.
Bei einem unordentlichen Codebase implementieren Sie das zuerst an einem Ort pro Layer: ein Frontend-Helper, eine API-Middleware und ein Job-Wrapper. Das reicht meist, damit Debugging vorhersehbar wird.
Logging, das die ID nützlich macht
Eine Korrelations-ID hilft nur, wenn sie in den Logs auftaucht, die Sie wirklich lesen. Am einfachsten macht man sie durch konsistentes, strukturiertes Logging durchsuchbar. JSON-Logs lassen sich leicht nach correlation_id filtern und über Frontend, API und Background-Jobs vergleichen.
Mindestens sollte jede request-bezogene Log-Zeile ein paar Felder enthalten, auf die Sie sich verlassen können:
correlation_idroute(oderaction)status(HTTP-Status oder Job-Result)message(kurz, für Menschen lesbar)duration_ms(wenn anwendbar)
Loggen Sie nicht alles. Eine saubere Basis ist: eine Zeile beim Request-Start, eine beim Request-Ende und nur zusätzliche Zeilen für wichtige Pfade wie Validierungsfehler, Retries, externe API-Aufrufe und Exceptions.
So sieht "sichtbar bei Erfolg und Fehler" aus:
{"level":"info","message":"request_start","correlation_id":"c-9f3a","route":"POST /checkout","user_id":"u_42"}
{"level":"info","message":"request_end","correlation_id":"c-9f3a","route":"POST /checkout","status":200,"duration_ms":184}
{"level":"error","message":"payment_failed","correlation_id":"c-9f3a","route":"POST /checkout","status":402,"error":"card_declined"}
Achten Sie darauf, was Sie loggen. Geben Sie nicht vollständige Request-Bodies, Auth-Header, Tokens, Cookies oder Secrets aus. Loggen Sie stattdessen kurze Zusammenfassungen wie items_count, plan=pro, provider=stripe oder email_domain=gmail.com. Das ist besonders wichtig in schnell gebauten Prototypen, wo Logs manchmal versehentlich Umgebungsvariablen oder Datenbank-URLs drucken.
Hintergrundjobs: die Spur durch Queues erhalten
Request-Logs und Job-Logs beantworten unterschiedliche Fragen. Request-Logs decken ab, was passierte, während der Nutzer wartete: der Klick, die API-Anfrage, die Antwort. Job-Logs zeigen, was danach passierte: verschickte E‑Mails, verarbeitete Dateien, Retries und spätere Fehler. Ohne eine gemeinsame Kennung treffen diese beiden Welten nie zusammen.
Wenn Sie eine Nachricht in eine Queue publizieren, hängen Sie dieselbe ID an, die Sie für die API-Anfrage verwendet haben. Einige Teams setzen sie in Message-Metadaten (Headers/Attributes) und zusätzlich in den Payload als Fallback. Wichtig ist Konsistenz: wählen Sie einen Feldnamen und verwenden Sie ihn überall, damit die Log-Suche vorhersehbar bleibt.
Ein lesbares Muster:
- Eine Root-Korrelations-ID pro Nutzeraktion.
- Wenn die API einen Job enqueued, fügen Sie diese Root-ID und optional eine eigene Job-ID hinzu.
- Wenn ein Klick mehrere Jobs erzeugt, behalten Sie dieselbe Root-ID für alle.
- Für geplante Jobs ohne Nutzerklick generieren Sie eine neue Root-ID beim Scheduler.
Auf der Worker-Seite behandeln Sie die ID als erstes, das Sie lesen. Bevor Sie irgendetwas loggen, ziehen Sie die ID aus der Nachricht, setzen Sie in den Log-Kontext und beginnen Sie dann mit der Verarbeitung. Ansonsten passiert das schmerzhafteste Problem: Der Job macht nützliche Arbeit, wirft einen Fehler und loggt erst dann etwas — aber ohne die ID.
Beim Fan-Out gilt eine zusätzliche Regel: behalten Sie die gemeinsame Root-ID, fügen Sie aber pro Job einen Child-Identifier hinzu, damit Sie sehen, welcher Zweig fehlgeschlagen ist.
Die ID für Support und Fehlerberichte sichtbar machen
Wenn nur Ingenieure die ID sehen können, hilft sie nicht, wenn ein Kunde meldet "der Button hat nichts gemacht". Machen Sie die Korrelations-ID leicht auffindbar, damit der Support danach fragen und die Entwicklung direkt zu den richtigen Logs springen kann.
Ein einfacher Ansatz ist, ein kurzes Label nur in Fehlerzuständen anzuzeigen, nicht auf jeder Seite. Platzieren Sie es dort, wo Nutzer ohnehin nach Details schauen: ein Fehler-Toast, eine fehlgeschlagene Formularmeldung oder eine "Etwas ist schiefgelaufen"-Seite.
Wie man sie zeigt, ohne Nutzer zu verwirren
Formulieren Sie ruhig: "Referenz: ABCD-1234." Vermeiden Sie Begriffe wie "trace" oder "distributed". Wenn die ID lang ist, zeigen Sie eine verkürzte Version (z. B. die ersten 8–12 Zeichen) und halten Sie den vollen Wert per "Kopieren"-Button verfügbar.
Der Support braucht außerdem ein konsistentes Vorgehen. Halten Sie es einfach: Fragen Sie nach dem "Referenz"-Code, und falls dieser nicht sichtbar ist, bitten Sie den Nutzer, den Fehler zu reproduzieren und einen Screenshot zu schicken. Wenn möglich, sammeln Sie die ungefähre Zeit und was geklickt wurde und fügen Sie den Code ins Ticket, damit die Entwicklung sofort suchen kann.
Hinweis zum Datenschutz
Behandeln Sie Korrelations-IDs als Diagnose-Label, nicht als personenbezogene Daten. Kodieren Sie keine E‑Mails, Nutzer-IDs oder Geräte-Fingerprints in den Wert. Halten Sie ihn zufällig und uninteressant, sodass er sicher in einem Screenshot oder Ticket geteilt werden kann.
Häufige Fehler, die die Nachverfolgbarkeit zerstören
Die meisten Tracing-Fehler sind keine ausgefallenen Bugs. Es sind kleine Entscheidungen, die die Kette zwischen Nutzerklick, API-Anfrage und Hintergrundjob durchschneiden.
- Bei jedem Hop eine neue ID generieren. Neue IDs sind okay für Unteroperationen, aber behalten Sie die Original-ID als Parent.
- Eine bestehende upstream-ID überschreiben. Gateways, CDNs oder Partner können bereits eine Request-ID senden. Wenn Sie sie ersetzen, verlieren Sie die Möglichkeit, deren Logs mit Ihren zu verbinden.
- Die ID beim Enqueue fallen lassen. Wenn das API-Log die ID zeigt, das Job-Log aber nicht, bleiben Sie im Dunkeln.
- Sie nur in einer Ebene loggen. Nur Frontend-IDs helfen nicht, wenn der Server vor der Antwort scheitert. Nur Server-IDs helfen dem Support nicht, das zu verbinden, was der Nutzer gesehen hat.
- Die ID wie ein Sicherheitsmerkmal behandeln. Eine Korrelations-ID ist kein Session-Token. Verwenden Sie sie nicht zur Auth und packen Sie keine Secrets hinein.
Ein kurzes Beispiel: Ein Nutzer klickt "Export". Der Browser erzeugt eine ID, aber die API generiert eine neue und loggt nur diese. Der Export-Job loggt später seine eigene zufällige ID. Sie haben jetzt drei voneinander unabhängige IDs für einen Klick.
Eine einfache Regel behebt das meist: Akzeptieren Sie eine eingehende ID, validieren Sie ihr Format und leiten Sie sie unverändert weiter. Falls Sie zusätzliche Details brauchen, fügen Sie ein zweites Feld wie parent_id oder job_id hinzu.
Schnelle Checkliste, um zu bestätigen, dass es funktioniert
Sie wissen, dass Korrelations-IDs ihren Zweck erfüllen, wenn eine ID die Frage beantworten kann: "Was passierte nach diesem Klick?"
Testen Sie eine Aktion (Staging reicht): Klicken Sie "Speichern", kopieren Sie die Korrelations-ID aus der UI oder dem Response-Header und suchen Sie danach in den Server-Logs. Sie sollten einen klaren Request-Start und -Ende sehen sowie alle nachgelagerten Aufrufe.
Checkliste:
- Eine ID findet den API-Request-Start, wichtige Schritte und das Request-Ende.
- Dieselbe ID erscheint in jedem Hintergrundjob, der durch diese Anfrage erzeugt wurde (Enqueue, Job-Start, Job-Ende).
- Fehler enthalten die ID und eine klare Nachricht, was fehlgeschlagen ist (nicht nur ein Stacktrace).
- Retries behalten dieselbe Korrelations-ID für dieselbe Nutzeraktion und fügen eine Versuchszahl hinzu.
- Support kann nach der ID fragen und die komplette Spur ohne Rätselraten finden.
Realitätsprüfung: Wenn die Suche nach einer Korrelations-ID nur eine Zeile zurückgibt, hängen Sie sie nicht an alle Log-Zeilen an. Wenn ein Klick mehrere nicht zusammenhängende IDs erzeugt, erzeugen Sie neue IDs in der API oder im Job-Runner statt die Originale weiterzugeben.
Beispiel: Einen fehlgeschlagenen Klick durch API und Job verfolgen
Ein Kunde klickt "Bezahlen" auf Ihrer Checkout-Seite. Der Button dreht sich kurz, dann zeigt die UI einen generischen Fehler: "Etwas ist schiefgelaufen." Ohne eine gemeinsame ID raten Sie. Mit Korrelations-IDs folgen Sie einem Faden vom Browser über das Backend in die Job-Queue.
Im Browser erzeugt die App beim Klick eine ID und sendet sie mit der API-Anfrage im Header (z. B. X-Correlation-Id). Der Nutzer sieht sie nur, wenn Sie sich entscheiden, einen Referenzcode bei Fehlern anzuzeigen.
Worauf Sie nacheinander achten sollten:
- Browser-Konsole:
pay_click correlationId=7f3a... - API-Access-Log:
POST /api/pay correlationId=7f3a... status=500 - API-Error-Log:
correlationId=7f3a... error=\"Stripe token missing\" userId=... - Queue-Record:
job=enrich_receipt correlationId=7f3a... queued - Job-Worker-Log:
correlationId=7f3a... failed error=\"DB timeout\" retry=1
Jetzt ist die Suche schnell. Statt alle Zahlungsfehler der letzten Stunde zu scannen, filtern Sie die Logs nach correlationId=7f3a... und erhalten eine enge Timeline: Klick um 10:14:03, API-Fehler um 10:14:04, Job-Retry um 10:14:20.
Oft entdecken Sie zwei Probleme auf einmal: den Produktfehler ("Stripe token missing") und die fehlende Observability, die es zufällig erscheinen ließ (der Job-Worker hat nicht dieselbe ID geloggt oder die Queue-Nachricht hat sie fallen lassen).
Nächste Schritte, wenn Ihre App heute schwer zu debuggen ist
Wenn Ihre App sich unnachvollziehbar anfühlt, versuchen Sie nicht, alles auf einmal zu beheben. Rollen Sie es in einer kleinen Oberfläche aus, beweisen Sie den Nutzen und weiten Sie dann aus.
Starten Sie mit einer Nutzeraktion, die oft kaputtgeht (zum Beispiel "Einstellungen speichern") und verfolgen Sie sie durch einen API-Endpunkt und einen Job-Typ. Wählen Sie etwas, das Sie wiederholt auslösen können. Wenn Sie eine einzelne ID aus dem Browser nehmen und jede zugehörige Log-Zeile finden können, haben Sie das Muster gebaut, das Sie überall wiederverwenden.
Schreiben Sie eine kurze Konventionsnotiz, um Drift zu verhindern:
- welcher Header-Name akzeptiert und weitergeleitet wird
- welcher Log-Feldname geschrieben wird
- wo die ID erzeugt und wann sie wiederverwendet wird
- wie sie in Hintergrundjobs übergeben wird
- wo der Support sie in der UI sehen kann
Wenn Sie ein AI-generiertes Prototype geerbt haben, das in Produktion Probleme macht, hilft oft ein fokussiertes Audit, um herauszufinden, wo IDs und Logging-Kontext über API, Queues und Worker verloren gehen. Teams nutzen FixMyMess (fixmymess.ai) für solche Codebase-Diagnosen und Reparaturen, besonders wenn die bestehende App schnell produktionsbereit gemacht werden muss.
Sobald der erste Endpunkt und Job nachverfolgbar sind, erweitern Sie Schnitt für Schnitt. Debugging wird jede Woche besser, ohne auf einen großen Rewrite zu warten.
Häufige Fragen
Was ist eine Korrelations-ID in einfachen Worten?
Eine Korrelations-ID ist ein einzelner, undurchsichtiger Wert, der einen Ablauf von Anfang bis Ende markiert — zum Beispiel ein Klick und alles, was daraus entsteht. Sie ermöglicht es, einmal zu suchen und das zugehörige Frontend-Ereignis, die API-Anfrage, nachgelagerte Aufrufe und Hintergrundjobs zu sehen.
Wo sollte die Korrelations-ID erzeugt werden?
Erzeugen Sie sie am frühestmöglichen vertrauenswürdigen Punkt, üblicherweise am ersten Backend-Einstiegspunkt (Gateway oder API-Middleware). Wenn der Client eine ID schickt, akzeptieren Sie sie nur, wenn sie Ihrem erwarteten Format entspricht; andernfalls generieren Sie eine neue und verwenden diese als Quelle der Wahrheit.
Sollte eine Korrelations-ID Nutzer- oder Geschäftsdaten enthalten?
Behandeln Sie sie als Diagnose-Label, nicht als Nutzerkennzeichen. Sie sollte keine E‑Mails, Nutzer-IDs, Bestellnummern oder sensible Daten enthalten, weil sie in Logs, Screenshots und Support-Tickets auftauchen wird.
Wie übertrage ich die Korrelations-ID vom Browser zur API?
Wählen Sie einen Header-Namen und schicken Sie ihn mit jeder API-Anfrage, die zur gleichen Nutzeraktion gehört. Echoen Sie ihn außerdem in der Response-Header zurück, damit der Browser und der Support die genau verwendete ID referenzieren können.
Sollen Retries dieselbe Korrelations-ID wiederverwenden oder eine neue erzeugen?
Ja — sofern die Retries zur gleichen Nutzeraktion gehören. Dieselbe ID zu behalten macht klar, dass mehrere Versuche zu einem Klick gehören. Falls nötig, fügen Sie in den Logs eine Versuchsnummer hinzu.
Wie behalte ich die Korrelations-ID, wenn Arbeit in eine Queue/Hintergrundjob verschoben wird?
Kopieren Sie die gleiche Korrelations-ID in die Message-Metadaten oder den Payload, wenn Sie Arbeit in eine Queue stellen, und lassen Sie den Worker die ID in den Logging-Kontext laden, bevor er etwas loggt. Wenn der Worker ohne die ID loggt, bricht die Spur genau dort ab, wo Sie sie brauchen.
Was, wenn ein Klick mehrere Hintergrundjobs auslöst?
Verwenden Sie eine Root-Korrelations-ID für den gesamten Klick und fügen Sie für jeden Jobzweig eine eigene Job-Kennung hinzu, falls Sie die Zweige unterscheiden müssen. So finden Sie mit der Root-ID die ganze Geschichte und können zugleich sehen, welcher Job gescheitert ist.
Was sollte ich zusammen mit der Korrelations-ID loggen, damit sie tatsächlich nützlich ist?
Schreiben Sie die ID als konsistentes Feld in jede request- und job-bezogene Logzeile, idealerweise in strukturierten Logs, damit Filtern einfach ist. Eine einfache Basis ist: eine Zeile beim Start, eine beim Ende und zusätzliche Zeilen nur für wichtige Pfade wie externe Aufrufe, Retries und Exceptions.
Wie kann ich die Korrelations-ID Nutzern und dem Support sichtbar machen, ohne zu verwirren?
Zeigen Sie sie nur bei Fehlerzuständen als einfachen „Reference“-Code, damit nicht-technische Nutzer sie ohne Verwirrung teilen können. Bei langen IDs eine gekürzte Version anzeigen und den vollen Wert kopierbar für den Support halten.
Was ist der schnellste Weg, das in einem chaotischen oder AI-generierten Codebase zu implementieren?
Am schnellsten ist es oft, einen Frontend-Helper, eine API-Middleware und einen Job-Wrapper hinzuzufügen, um IDs und Logging zu standardisieren, und dann Endpoint für Endpoint auszurollen. Wenn Sie ein AI-generiertes Projekt geerbt haben, bei dem IDs, Auth oder Logging durcheinander sind, kann FixMyMess (fixmymess.ai) ein kostenloses Code-Audit durchführen und innerhalb von 48–72 Stunden produktionsrelevante Probleme beheben, einschließlich Ende-zu-Ende-Traceability.