Kosten‑Audit für KI‑erstellte Prototypen: API‑ und DB‑Ausgaben senken
Ein Kosten‑Audit für KI‑generierte Prototypen zeigt Endpunkte, Queries und Hintergrundjobs, die die Rechnung aufblasen, und hilft, die größten Verschwendungen schnell zu beheben.
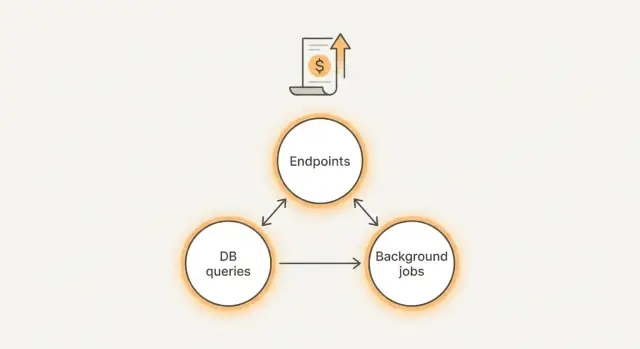
Was treibt Ihre Rechnung wirklich an?
Viele KI-erstellte Prototypen werden aus einem einfachen Grund teuer: Sie funktionieren im Demo gut, verschwenden aber im Hintergrund Geld. Code‑Generatoren duplizieren oft Aufrufe, überspringen Caching und fügen „hilfreiches“ Polling hinzu, das nie stoppt. Das fällt erst auf, wenn echte Nutzer kommen oder einige Tester die App den ganzen Tag offenlassen.
Die meisten überraschenden Kosten entstehen an drei Stellen:
- Endpoints: Ein Screen löst zu viele API‑Aufrufe, Retries oder zu große Antworten aus.
- Queries: Langsame oder ungebundene DB‑Abfragen, die viel mehr Daten scannen als nötig.
- Hintergrundaufgaben: Cron‑Jobs, Queue‑Worker und Webhooks, die zu oft laufen oder nie stoppen.
„Gute" Ausgaben sind langweilig. Sie sind vorhersehbar und bewegen sich mit echter Produktnutzung. Bei 10x mehr aktiven Nutzern steigen die Kosten vielleicht, aber der Sprung ist nachvollziehbar. „Schlechte" Ausgaben wachsen, wenn eigentlich niemand etwas tut oder wenn ein Feature heimlich Hunderte Aufrufe auslöst.
Wenn Sie nur 30 Minuten haben, messen Sie die wenigen Dinge, die Probleme schnell aufdecken:
- Top‑Endpoints nach Anfrageanzahl und durchschnittlicher Antwortgröße
- Die langsamsten und häufigsten Datenbankabfragen
- Hintergrundjobs nach Ausführungsfrequenz und durchschnittlicher Laufzeit
- Drittanbieter‑API‑Aufrufe nach Endpoint und Fehler-/Retry‑Rate
- Baseline‑Kosten während Stunden, in denen „niemand die App benutzt"
Ein schneller Reality‑Check hilft: Öffnen Sie die App, führen Sie eine normale Aktion aus (z. B. Dashboard laden) und beobachten Sie, was ausgelöst wird. Wenn diese einzelne Aktion 20 Requests, drei lange Queries und einen Spike in der Job‑Queue auslöst, haben Sie Ihren Startpunkt gefunden.
Binden Sie Kosten an echte Features (nicht an vage „Nutzung")
Dashboards, die „API‑Calls“ oder „DB‑Reads“ zeigen, sagen Ihnen nicht, was zu reparieren ist. Es wird einfacher, wenn Sie Ausgaben in echte Produktaktionen übersetzen, die ein Nutzer ausführt.
Erstellen Sie eine einfache Kostenübersicht
Schreiben Sie die Handvoll Aktionen auf, die Geld kosten dürfen, und behandeln Sie alles andere als verdächtig, bis das Gegenteil bewiesen ist. Für viele Prototypen sind das:
- Signup und Login (Email, SMS, OAuth)
- Suche und Filter
- Chat oder Content‑Generierung
- Reports und Exporte
- Datei‑Uploads und Verarbeitung
Hängen Sie zu jeder Aktion eine grobe Erwartung an: „Eine Chat‑Nachricht sollte weniger als X kosten“ oder „Ein Reportlauf sollte unter Y Sekunden dauern.“ Sie brauchen keine perfekten Zahlen, sondern Ziele, die Verschwendung offensichtlich machen.
Trennen Sie als Nächstes nutzergetriebene Kosten von immer‑aktiven Kosten.
Nutzergetriebene Kosten entstehen nur, wenn jemand klickt. Immer‑aktive Kosten laufen, selbst wenn niemand die App nutzt: Cron‑Jobs, Queue‑Worker, Background‑Polling, automatische Retries und „Health Checks“, die teure Endpunkte treffen. Immer‑aktive Kosten sind oft der schnellste Gewinn, weil sie rund um die Uhr Geld verbrennen.
Prüfen Sie auch, welche Umgebung Geld ausgibt. KI‑Apps zeigen oft, dass Dev oder Staging auf dieselben bezahlten Dienste wie Prod zeigen oder Test‑Worker über Nacht laufen lassen. Wenn Sie nicht klar sagen können „das ist Prod“, nehmen Sie an, dass ein Teil der Kosten nicht produktiv ist.
Setzen Sie Ihr Ziel, bevor Sie Code anfassen:
- Diese Woche 20% sparen (größte Verschwendung abschalten)
- Diesen Monat 80% sparen (Architektur, Caching und Datenzugriff überarbeiten)
Ein gängiges Muster: Ein „Report“ wird einmal täglich gebraucht, aber ein Background‑Job generiert ihn alle 5 Minuten für jeden Account. Das Dashboard zeigt „hohe DB‑Nutzung“, aber das eigentliche Problem ist ein Feature, das niemand verlangt hat und ständig läuft.
Schritt für Schritt: Inventar für Endpoints, Queries und Jobs
Ziel ist es, das Raten zu stoppen. Sie wollen eine Karte aller Stellen, an denen Ihre App Geld ausgibt, verknüpft mit echten Requests und echter Arbeit.
Wählen Sie einen normalen Tag mit Traffic als Baseline. Wenn Sie noch nicht viel Traffic haben, nutzen Sie einen Tag interner Tests, an dem Sie die Hauptabläufe (Signup, Checkout, Suche, Chat, Uploads) durchspielen. Speichern Sie diese Baseline, um nach Änderungen zu vergleichen.
Erstellen Sie eine einseitige Inventarliste
Gehen Sie die App in drei Bereichen durch: Endpoints, Datenbankabfragen und Hintergrundarbeit.
- Endpoints
- Listen Sie jede API‑Route (inkl. interner Routen) und notieren Sie, wer sie aufruft: Browser, mobile App, Cron‑Job, Webhook oder ein anderer Service.
- Fügen Sie grobes Volumen und Latenz hinzu. Exakte Zahlen sind gut, aber „hoch/mittel/niedrig“ und „schnell/langsam“ reichen, um erste Probleme zu erkennen.
- Queries
- Erfassen Sie für jeden Endpoint die wichtigsten DB‑Abfragen, die er auslöst.
- Samples aus Logs, Tracing oder der DB‑Slow‑Query‑Ansicht helfen; notieren Sie die Form der Abfrage (betroffene Tabellen, Filter, Joins).
- Hintergrundarbeit
- Schreiben Sie jeden geplanten Job, Webhook‑Handler und Queue‑Worker auf.
- Geben Sie an, wie oft er läuft und was er tut (Sync, Email, Embeddings, Cleanup).
Halten Sie alles an Ihrem Baseline‑Tag fest, damit Sie Kosten pro 1.000 Requests oder pro aktivem Nutzer schätzen können.
Sobald Sie diese Liste haben, springen Muster ins Auge: Ein Endpoint wird bei jedem Page‑Load aufgerufen, eine „kleine“ Abfrage scannt eine große Tabelle, oder ein Hintergrundjob läuft jede Minute, obwohl sich nichts ändert.
Endpoints, die heimlich teuer werden
Einige der größten Lecks verbergen sich in „normalen“ Endpoints, die den ganzen Tag aufgerufen werden. Oft ist das Backend pro Request nicht teuer; es wird teuer, weil derselbe Request hunderte oder tausende Male passiert.
Ein häufiger Übeltäter ist Polling: Das Frontend prüft alle paar Sekunden auf Updates, auch wenn sich nichts ändert. Refresh‑Schleifen können auch versehentlich entstehen, z. B. wenn eine Seite neu rendert und einen weiteren Fetch auslöst oder wenn zwei Komponenten denselben Endpoint unbekannt voneinander aufrufen. Wenn Nutzer einen Tab offenlassen, wird diese ruhige Schleife zu einem stetigen Verbrauch.
Ein weiteres Muster ist ein Endpoint, der pro Request zu viel Arbeit macht. KI‑generierter Code bündelt oft mehrere Lookups, zusätzliche Joins oder Dateiverarbeitung in einer Route „der Bequemlichkeit halber“. In Demos funktioniert das, aber jeder Aufruf löst eine Kette von DB‑Queries und Drittanbieter‑Aufrufen aus.
Read‑lastige Routen werden teuer, wenn kein Caching vorhanden ist. Liefert ein Endpoint für viele Nutzer dieselben Daten (Preise, Einstellungen, Template‑Listen), zahlen Sie wiederholt für identische Lesevorgänge.
Retries multiplizieren Kosten schnell. Sind Timeouts zu kurz oder fehlen Rate‑Limits, wiederholen Clients aggressiv. Sie zahlen oft das Zweifache (oder mehr) für dieselbe Aktion.
Ein paar Anzeichen, dass ein Endpoint Priorität hat:
- Er wird per Timer (Polling) oder bei jedem Tastenanschlag aufgerufen
- Er löst mehrere nachgelagerte Aufrufe aus (DB plus externe APIs)
- Er liefert oft dieselbe Antwort, hat aber kein Caching
- Er timeouts gelegentlich und Clients retryen automatisch
- Er hat keine Rate‑Limits, sodass Lastspitzen teuer werden
Beispiel: Ein /messages‑Endpoint in einem Chatbot‑Prototyp wird alle 2 Sekunden aufgerufen, um neue Antworten zu prüfen. Zusätzlich rekalkuliert er Konversationskontext und greift mehrmals auf die DB zu. Häufigkeit reduzieren und schwere Arbeit aus dem Request verschieben senkt die Kosten sofort.
Queries, die Ihre DB‑Kosten in die Höhe treiben
Datenbankkosten kommen oft von wenigen Queries, die viel öfter laufen als gedacht. KI‑generierter Code kann Ineffizienzen hinter einem ORM verstecken, sodass die App im Test OK aussieht, aber mit echtem Traffic teuer wird.
Ein großer Fehler ist das N+1‑Muster: Sie holen eine Liste von Items, und der Code lädt verwandte Daten für jede Zeile einzeln nach. Eine Seite mit 50 Bestellungen kann so zu 51 Queries werden (oder 201, wenn jede Bestellung Kunde und Artikel lädt), und bei jedem Refresh wiederholt sich die Arbeit.
Fehlende Indizes sind ein weiterer Multiplikator. Filtern Sie nach user_id, created_at oder status oder joinen bei Fremdschlüsseln, sollte die DB nicht jedes Mal die ganze Tabelle scannen. Fehlt der Index, steigen die Kosten mit wachsendem Datenbestand.
Achten Sie auch auf Abfragen, die zu viel holen. Alle Spalten selektieren, große JSON‑Blobs laden oder Tausende Zeilen zurückgeben, obwohl die UI nur die ersten 20 anzeigt, verschwendet CPU, Speicher und Netzwerk. Suche, Aktivitätsfeeds und Admin‑Tabellen sind häufige Fälle, besonders wenn Pagination fehlt.
Fünf Checks, die meist die schlimmsten Spitzen finden:
- Suchen Sie nach wiederholten Reads in Schleifen (N+1) in Logs oder Traces
- Prüfen Sie, ob Indizes für häufige Filter und Join‑Schlüssel existieren
- Selektieren Sie nur benötigte Spalten, nicht
SELECT * - Fügen Sie Pagination und harte Limits für Scrolls und Suche hinzu
- Stellen Sie sicher, dass Connection‑Pooling gesetzt ist, damit pro Request nicht neue DB‑Verbindungen geöffnet werden
Beispiel: Ein Chatbot speichert Nachrichten und „lädt die letzten 5.000“ bei jedem Seitenaufruf, um Kontext zu bauen. Auf die letzten 30 Nachrichten zu begrenzen, conversation_id zu indexieren und verwandte Lookups zu batchen kann die DB‑Last schnell senken.
Hintergrundjobs, die öfter laufen als gedacht
Hintergrundjobs sind ein häufiger Grund, warum ein KI‑Prototyp in Tests billig aussieht und in Produktion teuer wird. Sie laufen, wenn niemand die App nutzt, und berühren oft die teuersten Teile Ihres Stacks: externe APIs, Datenbank und Dateispeicher.
Listen Sie zuerst jeden Job auf, der geplant ist, und schreiben Sie seinen Zeitplan in einfacher Sprache auf. „Jede Minute“ und „alle 5 Minuten“ sind häufige Budgetkiller, besonders wenn der Job bezahlte APIs aufruft oder große Tabellen scannt.
Suchen Sie als Nächstes nach Jobs, die laufen, auch wenn es nichts zu tun gibt. Ein typisches Beispiel ist ein Sync‑Task, der nach neuen Daten schaut, aber trotzdem Tausende Zeilen holt oder eine API aufruft, obwohl sich nichts geändert hat. Einfache Guards vor den teuren Teilen reichen oft, um das Leck zu stoppen.
Fan‑out‑Verhalten ist der andere stille Multiplikator. Ein geplanter Job kann pro Nutzer, Workspace oder Datensatz je einen Job in die Queue stellen. Läuft er stündlich und Sie haben 2.000 Nutzer, sind das plötzlich 48.000 Jobs pro Tag.
Einige schnelle Fixes, die meist Kosten reduzieren:
- Fügen Sie einen „keine Arbeit“-Check ein (Queue‑Länge, letztes Updated‑Timestamp oder ein günstiges Count), bevor teure Queries oder API‑Aufrufe laufen
- Drosseln Sie Fan‑out mit Batching (z. B. 100 Datensätze pro Lauf) und Backoff bei hoher Last
- Machen Sie Jobs idempotent, damit Retries teure Arbeit nicht wiederholen (unique Job Key oder ein processed‑Marker)
- Loggen Sie Counts und Laufzeiten: verarbeitete Items, API‑Aufrufe, gescannte Zeilen, Gesamtlaufzeit
Wie Sie die wenigen Fixes auswählen, die schnell Kosten senken
Ein Audit ist nur sinnvoll, wenn es in einen kurzen, fokussierten Plan mündet. Ziel ist nicht Perfektion, sondern die wenigen Hotspots zu entfernen, die den Großteil der Rechnung verursachen.
Für jede mögliche Änderung notieren Sie zwei Dinge: wie schwer sie umzusetzen ist und wie viel sie sparen könnte. Halten Sie es schlank, damit Sie schnell entscheiden können.
- Anfrage‑Limits an teure Endpunkte setzen (geringer Aufwand, große Einsparung)
- Read‑lastige Antworten 60 Sekunden cachen (geringer Aufwand, mittel bis hohe Einsparung)
- Einen DB‑Index zu einer Top‑Query hinzufügen (mittlerer Aufwand, hohe Einsparung)
- Polling‑Frequenz im Worker oder UI reduzieren (geringer Aufwand, mittel bis hohe Einsparung)
- Ein ganzes Modul refactoren (großer Aufwand, unklare Einsparung)
Priorisieren Sie Änderungen, die einen dieser Treiber reduzieren:
- Anzahl der API‑Aufrufe (weniger Requests, weniger Retries, kleinere Antworten)
- Gescannte Zeilen (schnellere Queries, weniger Full‑Table‑Scans)
- Job‑Frequenz (weniger Polling, weniger geplante Läufe)
Schnelle Guardrails gewinnen oft zuerst. Setzen Sie Caps gegen missbräuchliche Muster (Rate‑Limits, Timeouts, max Page Size). Fügen Sie Caching hinzu, wo sich Daten nicht jede Sekunde ändern. Bei Hintergrundarbeit wechseln Sie von „jede Minute prüfen“ zu „bei Bedarf ausführen“ oder längeren Intervallen.
Nutzen Sie eine klare Stoppregel: Schicken Sie 2–3 Änderungen, messen Sie dann einen Tag (oder einen normalen Geschäftszyklus) erneut. Wenn Sie keinen spürbaren Rückgang sehen, gehen Sie zurück zum Inventar. Große Rewrites sind verlockend, verpassen aber oft den echten Kostentreiber.
Beispiel: Wenn ein Chatbot‑Prototyp bei jeder Nachricht die gesamte Konversation erneut sendet, kann eine kleine Änderung wie das Zusammenfassen älterer Nachrichten oder das Limitieren der Historie Token‑Kosten schneller senken als ein kompletter Neuaufbau.
Beispiel: Chatbot‑Prototyp mit explodierenden Kosten
Ein typischer Fall: Ein Lovable‑ oder Bolt‑Prototyp mit einfachem Chat‑Screen plus Dashboard für „Usage“ und „History“. In Demos klappt alles, aber die Rechnung wächst schneller als die Nutzerzahl.
Das Muster: Bei jedem Page‑Load werden mehrere AI‑Calls „vorsorglich“ gemacht (Summaries, vorgeschlagene Prompts, Sentiment, Titelgenerierung). Gleichzeitig läuft das Dashboard Voll‑Table‑Scans, um Statistiken neu aufzubauen. Ein paar aktive Tester erzeugen hunderte Aufrufe pro Stunde, und die DB fängt an, schwere Leseoperationen auszuführen, die wie zufällige Spitzen aussehen.
Oft ist ein einzelner Hauptschuldiger da: ein Chat‑Endpoint, der bei jeder Nachricht Embedding‑Arbeit wiederholt, manchmal mehrmals pro Request. Er bildet den Nutzertext, re‑embedet die letzten N Nachrichten und re‑embedet dieselben Knowledge‑Base‑Stücke, weil nichts gecached wird. Wenn der Endpoint außerdem alles speichert und dann sofort „alle Nachrichten dieses Nutzers“ ohne Limits abfragt, wächst die Query‑Last mit jeder Konversation.
Fixes, die Kosten senken, sind oft langweilig, aber effektiv:
- UI‑Triggers debouncen, sodass eine Nutzeraktion einen Request auslöst, nicht fünf
- Embeddings cachen und wiederverwenden, wenn sich Text nicht geändert hat
- Pagination und Limits für Nachrichtenhistorie und Dashboard‑Tabellen
- „Nice to have“ AI‑Arbeit (Titel, Zusammenfassungen) in seltener laufende Jobs verschieben
- Guardrails: Timeouts, max Tokens und Rate‑Limits pro Nutzer
Das Ziel: weniger Aufrufe pro Nutzeraktion und eine flachere Kostenkurve. Nach den Änderungen sollten Sie die Ausgaben aus aktiven Nutzern vorhersagen können, statt von einem einzigen geschäftigen Nachmittag überrascht zu werden.
Häufige Fehler, die Sie beim Kosten‑Audit vermeiden sollten
Ein Audit kann schiefgehen, wenn Sie es wie eine Tabellenkalkulation behandeln statt wie eine Jagd nach den wenigen Dingen, die den Großteil der Rechnung erzeugen. Ziel ist nicht perfekte Messung, sondern schnelle, sichere Einsparungen.
Eine Falle ist, viele Metriken zu sammeln und die Offender zu übersehen. Teams tracken jede Route, jede Tabelle, jedes Dashboard und handeln dann nie an den schlimmsten Verursachern. In der Praxis erklären oft Ihre Top‑5 Endpunkte und Top‑5 Queries den Großteil der Kosten.
Ein anderer Fehler ist, die falsche Ebene zu optimieren. Sie können eine langsame Query tunen, aber wenn ein Hintergrundjob sie jede Minute aufruft (oder zweimal wegen Retries), ändert sich die Rechnung nicht. Bestätigen Sie immer, was die Arbeit auslöst: Nutzeraktionen, Cron‑Schedules, Webhooks, Retries oder Queue‑Worker.
Achten Sie auf diese Fehlermuster:
- Sie schalten ein Feature ab, um Kosten zu sparen, aber das wirkliche Problem war eine versehentliche Call‑Schleife oder ein Client, der zu oft pollt
- Sie optimieren eine Query, während ein Export‑ oder Sync‑Job dieselbe Query tausendfach ausführt
- Sie jagen Einsparungen und brechen dabei Korrektheit (teilweise Daten, fehlende Writes, veralteter Cache)
- Sie überspringen grundlegende Sicherheitschecks und veröffentlichen Secrets, schwache Auth oder Injection‑Risiken
- Sie „lösen" Kosten durch das Senken von Limits, ohne zu klären, warum die App diese Limits erreicht
Beispiel: Ein Prototype‑Feature „Notifications“ wirkt teuer, also wird es abgeschaltet. Später zeigt sich, dass der echte Übeltäter ein Worker war, der dasselbe Batch immer wieder verschickte, weil der Job nie seinen Checkpoint speicherte.
Kurze Checkliste: bevor und nachdem Sie etwas ändern
Behandeln Sie das wie ein kleines Experiment: Messen Sie zuerst, ändern Sie eine Sache, messen Sie erneut. Ansonsten riskieren Sie, „Geld zu sparen“ auf dem Papier und gleichzeitig Login‑Probleme, langsamere Seiten oder Retries einzuführen, die noch mehr kosten.
Wählen Sie einen Baseline‑Tag (oder ein typisches 24‑Stunden‑Fenster) und notieren Sie Ihre Zahlen an einem Ort: gesamte API‑Kosten, DB‑Kosten und Hintergrundworker‑Kosten sowie einige Top‑Offender.
Bevor Sie Code ändern, stellen Sie sicher, dass Sie diese Fragen beantworten können:
- Was sind die Top‑3 Endpoints nach Kosten und nach Volumen (Requests)?
- Was sind die Top‑3 Queries nach Gesamtzeit oder gescannten Zeilen?
- Haben Sie eine vollständige Liste geplanter Jobs, Queues und Cron‑Tasks plus wie oft sie laufen?
- Haben Sie „Vorher“-Zahlen für ein Baseline‑Fenster (Kosten, Latenz, Fehler‑Rate, Retries)?
- Wissen Sie, wie „gut" für Nutzer aussieht (Page‑Load‑Zeit, Time‑to‑First‑Response, erfolgreiche Checkout‑ oder Login‑Rate)?
Nach Änderungen prüfen Sie dasselbe Fenster erneut und fügen zwei Checks hinzu: Retries und Nutzererlebnis. Eine häufige Falle ist, die Rechenzeit pro Request zu reduzieren, aber 500er oder Timeouts einzuführen, die automatische Retries auslösen. Ein kaputter Endpoint kann Traffic und Kosten verdoppeln, ohne neue Nutzer.
Prüfen Sie auch, ob Sie Kosten nur verschoben haben (z. B. weniger API‑Calls, aber schwerere DB‑Queries oder weniger DB‑Reads, aber mehr Hintergrundjobs).
Nächste Schritte, wenn Ihr KI‑Prototyp schwer zu entwirren ist
Wenn Ihr Audit sagt „alles ist teuer“, liegt das Problem meist im Code, nicht in der Cloud. KI‑generierte Projekte liefern oft verknotete Routen, duplizierte Logik und versteckte Retries. Bevor Sie Zeile für Zeile optimieren, machen Sie eine kurze Diagnose, um zu kartieren, was in Produktion tatsächlich läuft und wie Requests fließen.
Finden Sie Hotspots. Haben Sie nur 1–3 klare Übeltäter (ein lauter Endpoint, eine langsame Query, ein überaktiver Job), ist Patchen oft der schnellste Weg. Finden Sie ein Dutzend mittelgroße Probleme über viele Dateien verteilt, verschwenden Sie Zeit mit Symptombekämpfung — ein kleiner Refactor ist dann oft günstiger.
Eine einfache Faustregel:
- Patchen, wenn der Fix isoliert und testbar ist (Rate‑Limit an einem Endpoint, Cache einbauen, ein N+1 fixen)
- Refactoren, wenn das gleiche Bug‑Muster sich wiederholt (kopierter Datenzugriff, mehrere Endpoints, die dasselbe tun, Jobs, die sich gegenseitig triggern)
- Neuaufbauen, wenn Grundlegendes kaputt ist (unsichere Auth, exponierte Secrets, Architektur verhindert sichere Änderungen)
Wenn Sie externe Hilfe hinzuziehen, ist der Handover wichtiger als lange Erklärungen. Bringen Sie einen Baseline‑Tag und ein kurzes Paket Fakten mit:
- Endpoint‑Liste mit Request‑Counts und schlimmsten Kandidaten
- Top‑Queries mit Durchschnittszeit und Häufigkeit
- Hintergrundjob‑Liste mit Zeitplänen und tatsächlichen Ausführungszahlen
- Aktuelle Deploy‑Notizen (was sich geändert hat, als die Kosten stiegen)
Wenn der Code aus Tools wie Lovable, Bolt, v0, Cursor oder Replit stammt und schwer nachzuvollziehen ist, kann FixMyMess (fixmymess.ai) ein kostenloses Code‑Audit durchführen, um Endpunkte, Queries und Jobs zu kartieren, bevor Sie etwas anfassen. Danach konzentriert sich die Arbeit auf logische Reparaturen, Security‑Härtung, Refactoring und Deployment‑Vorbereitung, damit der Prototyp sich wie Produktionssoftware verhält und nicht wie eine Demo.
Häufige Fragen
Meine KI-Prototyp-Rechnung ist hoch—was sollte ich zuerst prüfen?
Beginnen Sie damit herauszufinden, was Geld verbrennt, wenn niemand aktiv die App benutzt. Vergleichen Sie ein ruhiges Nachtfenster mit einer geschäftigen Stunde und suchen Sie dann nach einer kleinen Anzahl von Hotspots: einige Endpunkte mit sehr hohen Request-Zahlen, wenige Datenbankabfragen, die die Gesamtzeit dominieren, und Hintergrundjobs, die in engen Intervallen laufen. Wenn die Kosten auch während „niemand nutzt es“ nicht fallen, ist die schnellste Einsparung meist immer‑aktiver Hintergrundbetrieb, nicht ein Nutzerfeature.
Wie setze ich eine Basislinie, bevor ich Code ändere?
Wählen Sie einen normalen 24‑Stunden‑Zeitraum und notieren Sie die Zahlen, die Sie später leicht wieder prüfen können: gesamte API‑Kosten, Datenbankkosten und Hintergrund-Worker‑Kosten sowie die größten Übeltäter nach Volumen und Latenz. Es geht nicht um perfekte Abrechnung, sondern um einen „Vorher“-Snapshot, damit Sie sehen, ob Ihre Änderungen wirklich Kosten senken und sie nicht nur verschieben.
Wie binde ich Cloud‑Kosten an ein echtes Feature statt vager Metriken?
Übersetzen Sie „Nutzung“ in echte Nutzeraktionen wie Dashboard laden, eine Chat‑Nachricht senden, einen Report ausführen oder eine Datei hochladen. Beobachten Sie, was jede Aktion in Produktion auslöst: Requests, ausgeführte Queries, Job‑Spitzen und Drittanbieter‑Aufrufe. Wenn eine einfache Aktion eine überraschende Kette von Arbeiten startet, haben Sie das Problem gefunden.
Warum treiben Polling-Konzepte die Kosten selbst bei wenigen Nutzern in die Höhe?
Polling wirkt harmlos, weil jede Anfrage klein ist, läuft aber ständig und multipliziert sich über geöffnete Tabs und Nutzer. Wenn die UI alle paar Sekunden prüft, obwohl sich selten etwas ändert, steigen die Kosten trotz Leerlauf. Übliche Lösungen sind Polling reduzieren/entfernen, nur bei Änderungen abrufen oder Nutzer explizit aktualisieren lassen.
Wie erhöhen Retries und Timeouts heimlich meine Ausgaben?
Retries können Ihre Rechnung verdoppeln oder verdreifachen, weil Sie für dieselbe Arbeit mehrfach bezahlen. Das passiert durch zu aggressive Timeouts, unzureichendes Error‑Handling oder Clients, die automatisch unbegrenzt neu versuchen. Abhilfe schafft sinnvolle Timeout‑Konfiguration, Rate‑Limits, idempotente Requests und sicherstellen, dass Fehlschläge keine teure Downstream‑Arbeit auslösen.
Was ist das N+1-Query-Problem und wie erkenne ich es?
Das N+1‑Problem entsteht, wenn Sie eine Liste holen und dann in einer Schleife zu jedem Eintrag verwandte Daten einzeln nachladen. Bei kleinen Tests fällt es nicht auf, skaliert aber schlecht und wird schnell teuer. Praktische Abhilfe ist Batch‑Laden oder JOINs, sodass ein Seitenaufruf nicht dutzende oder hunderte separate Queries auslöst.
Wann ist das Hinzufügen eines DB‑Index die beste Kostenmaßnahme?
Wenn Sie nach Feldern wie user_id, created_at oder status filtern oder auf Fremdschlüssel joinen und die DB jedes Mal die ganze Tabelle scannt, sehen Sie langsame Queries, die mit wachsendem Datenbestand schlimmer werden. Den richtigen Index zu setzen bringt oft einen direkten, messbaren Rückgang bei Laufzeit und CPU‑Last. Wichtig ist, Indizes auf die Felder zu setzen, die Ihre Top‑Endpunkte tatsächlich verwenden.
Warum verursachen Hintergrundjobs über Nacht „Idle“-Kosten?
Weil sie auch laufen, wenn niemand die App benutzt, und oft teure Teile Ihres Stacks berühren: DB, bezahlte APIs und Storage. Ein Job, der jede Minute ausgeführt wird, kann zu einem 24/7‑Kostenleck werden, besonders wenn er viele Zeilen scannt oder pro Nutzer Aufgaben verteilt. Fügen Sie einfache „keine Arbeit“-Checks ein und stoppen Sie unnötige Fan‑Outs, um schnell Kosten zu senken ohne Nutzerfeatures zu ändern.
Wie entscheide ich zwischen Patch, Refactor oder Rebuild?
Beginnen Sie mit Änderungen, die leicht testbar sind und einen klaren Treiber reduzieren, z. B. Request‑Anzahl, gescannte Zeilen oder Job‑Frequenz. Patchen Sie, wenn das Problem isoliert ist und Sie die Auswirkung in einem Tag prüfen können (z. B. Polling reduzieren, Cache hinzufügen, ein N+1 fixen). Refactor, wenn das Muster mehrfach vorkommt. Neuaufbau nur, wenn Grundlegendes kaputt ist (unsichere Auth, exponierte Secrets, Architekturprobleme).
Was sollte ich übergeben, wenn ich jemanden beauftrage, ein teures KI‑generiertes Codebase zu reparieren?
Bringen Sie einen Basistag mit und eine kurze Zusammenfassung der teuren Bereiche: lautstarke Endpunkte, langsame und häufige Queries und Jobs, die zu oft laufen. Wenn der Code aus Tools wie Lovable, Bolt, v0, Cursor oder Replit stammt und schwer nachzuvollziehen ist, kann FixMyMess mit einem kostenlosen Code‑Audit starten und dann die Hotspots mit menschlicher Überprüfung beheben. Die meisten Projekte werden innerhalb von 48–72 Stunden abgeschlossen, mit dem Ziel, Demo‑Code in vorhersehbares Produktionsverhalten zu verwandeln.