Migration von JSON-Blobs zu normalisierten Tabellen mit Backfills
Lernen Sie, wie Sie schrittweise von JSON-Blobs zu normalisierten Tabellen migrieren: neues Schema, Backfills, Dual Writes, sichere Umschaltung und Rückfalloptionen.
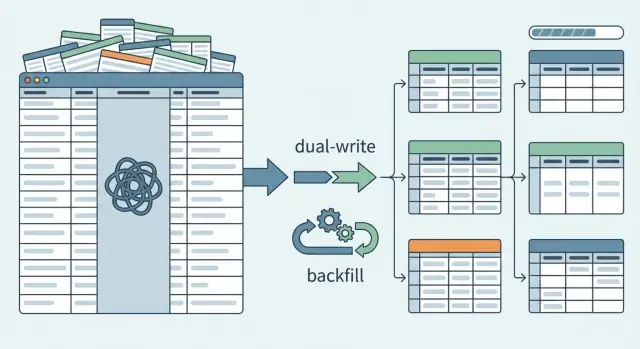
Warum JSON-Blob-Spalten mit dem Wachstum aufhören zu funktionieren
Eine JSON-Blob-Spalte ist ein einzelnes Datenbankfeld, das ein ganzes Objekt als Text enthält, z. B. { "status": "paid", "coupon": "NEW10", "notes": "..." }. Teams beginnen damit, weil es schnell wirkt: Felder lassen sich hinzufügen, ohne das Schema zu ändern, und viele AI-Code-Generatoren greifen standardmäßig darauf zurück, wenn sie schnell vorankommen wollen.
Das Problem taucht auf, sobald die App reale Nutzer, echtes Datenvolumen und echte Fragestellungen hat, die die Datenbank beantworten muss. Was früher ein einfacher Schreibvorgang war, wird zu langsamen Lesevorgängen, unübersichtlichen Reports und vielen Spezialfällen im Code.
Meist merkt man, dass der JSON-Blob an seine Grenzen stößt, an einigen vorhersehbaren Anzeichen:
- Abfragen werden langsamer, weil Filtern und Sortieren in JSON schwieriger zu optimieren ist.
- Felder driften in unterschiedliche Formen (
phone,phoneNumber, manchmal fehlend). - Reporting wird zur Schätzung, weil Sie sich nicht auf Typen, Pflichtfelder oder Beziehungen verlassen können.
- Datenkorrekturen werden riskant, weil Sie große Blobs bearbeiten statt eine klare Spalte zu aktualisieren.
- Bugs bleiben monatelang verborgen, weil fehlerhafte Daten weiterhin in das JSON „passen“.
JSON-Blobs verschleiern außerdem Datenqualitätsprobleme, bis es teuer wird, sie zu beheben. Ein Wert, der eine Zahl sein sollte, kann stillschweigend zum String werden. Ein Feld, das erforderlich sein sollte, kann verschwinden. Später, wenn Sie genaue Summen, Deduping oder Compliance-Protokolle brauchen, merken Sie, dass Sie Regeln nie durchgesetzt haben.
„Normalisierte Tabellen“ bedeutet, den Blob in separate Tabellen und Spalten zu zerlegen, die jeweils genau eine Sache darstellen, mit klaren Typen und Beziehungen. Statt eines order.data-Blobs könnten Sie orders, order_items, payments und addresses haben, mit Spalten, die Sie indexieren und validieren können.
Es gibt Fälle, in denen Sie warten sollten. Migrieren Sie nicht, wenn das Produkt sich täglich ändert, das Datenvolumen winzig ist oder Sie keine klare Definition haben, was die Felder bedeuten. Entscheiden Sie zuerst, was stabil bleiben muss.
Wenn Sie eine AI-erstellte App geerbt haben, in der „alles in JSON“ liegt, ist dieses Muster üblich: Es funktioniert in Demos, bricht aber in Produktion auseinander. Die gute Nachricht: Sie können phasenweise mit Backfills sicher migrieren, ohne einen Big-Bang-Refactor.
Kartieren Sie Ihre aktuellen Daten, bevor Sie etwas ändern
Bevor Sie von einem JSON-Blob zu normalisierten Tabellen wechseln, klären Sie, wie der Blob heute tatsächlich verwendet wird. Die meisten fehlgeschlagenen Migrationen beginnen mit Vermutungen darüber, was im JSON steckt und welche Teile wichtig sind.
Schreiben Sie die wichtigsten Lese- und Schreibflüsse auf, die den Blob berühren, basierend auf echtem Verhalten: die Seiten, die Nutzer laden, die Formulare, die sie absenden, die API-Aufrufe, Hintergrundjobs und Exporte, auf die Ihr Team angewiesen ist. In vielen Apps sind die ersten Fälle vorhersehbar: eine Benutzerseite, eine Speichern-Aktion, mindestens ein Hintergrundjob, eine Admin-/Reporting-Ansicht, die viele Zeilen liest, und ein oder zwei Integrationen oder Webhooks, die nur Teile des Blobs verwenden.
Öffnen Sie dann ein paar reale Produktionszeilen und listen Sie die Felder auf, die Entscheidungen steuern. Überspringen Sie Rauschen wie temporären UI-State, alte Flags, die nie gelesen werden, oder zufällige Schlüssel, die einmal aufgetaucht sind und nie wiederkamen.
Kennzeichnen Sie jedes Feld als erforderlich, optional oder veraltet.
- Erforderlich: Die App bricht oder Geschäftsregeln schlagen fehl ohne dieses Feld.
- Optional: Nützlich, aber nicht immer vorhanden.
- Veraltet: Kann später entfernt werden, wenn bestätigt ist, dass niemand es liest.
Achten Sie auf dieselben Daten, die in unterschiedlicher Form doppelt gespeichert sind. Ein häufiges Zeichen ist, wenn ein Feld sowohl als Top-Level-Spalte als auch im JSON existiert, oder wenn zwei JSON-Schlüssel dasselbe Konzept repräsentieren (z. B. userId vs customer_id). Diese Duplikate verwirren Backfills und machen Fehler schwer nachzuvollziehen.
Definieren Sie den Erfolg messbar, bevor Sie das Schema anfassen. Schnellere Abfragen auf bestimmten Bildschirmen. Reporting, das kein benutzerdefiniertes JSON-Parsing braucht. Weniger Datenfehler. Einfachere Validierung. Weniger Support-Anfragen wegen „fehlender Daten“. Ohne messbare Verbesserung ist schwer zu sagen, wann die Migration wirklich abgeschlossen ist.
Entwerfen Sie das normalisierte Schema in kleinen, sicheren Schritten
Versuchen Sie nicht, die gesamte JSON-Spalte auf einmal zu ersetzen. Wählen Sie einen ersten Slice, der klar relevant ist: einen Bildschirm, über den Nutzer klagen, einen Report, der langsam ist, oder einen API-Endpunkt, der häufig timeouts verursacht. Ein kleiner Erfolg zwingt zur Klarheit und hält den Aufwand überschaubar.
Starten Sie damit, reale Entitäten zu benennen. Wenn der Blob „Benutzerprofil“, „Abonnementplan“, „Zahlungen“ und „Audit-Ereignisse“ mischt, sind das keine Felder in einer Tabelle. Das sind separate Tabellen mit Beziehungen. Ein einfacher Test: Können Sie jede Tabelle in einem Satz beschreiben, ohne „JSON“ zu erwähnen?
Wählen Sie Identifikatoren, die sich nicht ändern. Wenn Sie bereits einen Primärschlüssel für die Parent-Zeile haben (z. B. account_id), behalten Sie ihn und verwenden ihn als Fremdschlüssel in neuen Tabellen. Für Kind-Records fügen Sie stabile IDs hinzu (payment_id, event_id) statt sich auf Array-Positionen im JSON zu verlassen. Das ist bei Backfills und Replays wichtig, weil Sie eine zuverlässige Zuordnung brauchen.
Setzen Sie Constraints, hinter denen Sie heute stehen können, nicht die perfekte Menge, die Sie sich wünschen. Für den ersten Slice konzentrieren Sie sich auf:
NOT NULLfür Muss-Spalten (z. B.user_id,created_at).- Einfache Foreign Keys, wo Sie dem Parent vertrauen.
- Eindeutigkeit dort, wo Duplikate das Feature brechen würden (z. B. genau ein aktiver Plan pro Account).
Wenn Sie Rückverfolgbarkeit während der Transition brauchen, machen Sie sie explizit und temporär. Eine raw_json-Spalte in der neuen Tabelle kann beim Debuggen der Zuordnungen helfen, sollte aber eine bewusste Wahl sein, nicht ein neuer Dumping Ground.
Planen Sie Indizes anhand Ihrer realen Abfragen, nicht theoretisch. Wenn die App immer „neueste Events für Account“ oder „aktueller Plan für User“ abruft, indexieren Sie genau diese Filter- und Sortiermuster. Ein kleiner Slice mit den richtigen Indizes schlägt ein riesiges Schema, das niemand schnell abfragen kann.
Richten Sie eine phasenweise Migration mit minimalem Risiko ein
Der sicherste Weg ist hinzufügen, nicht ersetzen. Erstellen Sie zuerst die neuen Tabellen und lassen Sie die bestehende JSON-Spalte stehen. Die Produktion bleibt stabil, während Sie den neuen Weg beweisen.
Am Anfang bleibt das alte Verhalten Standard. Reads kommen weiterhin aus der JSON-Spalte, auch nachdem die neuen Tabellen existieren. Im Hintergrund können Sie den neuen Leseweg für einen kleinen Teil des Traffics oder für interne Accounts einschalten.
Eine Feature-Flag hilft hier. Sie erlaubt, zwischen alter Quelle (JSON) und neuer Quelle (Tabellen) zu wechseln, ohne alles auf ein Deploy zu setzen. Sie bietet auch eine sofortige Rücksetzung, wenn etwas schief aussieht.
Als Nächstes beginnen Sie mit Dual Writes. Beim Erstellen oder Aktualisieren einer Zeile schreiben Sie sowohl in die JSON-Spalte als auch in die neuen normalisierten Tabellen. So sammelt sich neue Datenstruktur an, während die App noch auf das alte Modell setzt.
Dual Writes können driften, wenn Sie keine einfachen Schutzmaßnahmen hinzufügen. Ein praktisches Muster ist, ein updated_at-Timestamp und eine kleine schema_version an beiden Stellen zu speichern. Wenn Versionen abweichen, wissen Sie, dass die Zeile veraltet ist und Aufmerksamkeit braucht, bevor Sie ihr vertrauen.
Ein minimales phasenweises Setup, das in Produktion hält, sieht oft so aus:
- Neue Tabellen und Indizes hinzufügen, aber die JSON-Spalte nicht entfernen.
- Eine Lese-Feature-Flag hinzufügen, die standardmäßig die JSON-Quelle nutzt.
- Dual Writes für Create- und Update-Operationen implementieren.
updated_atund eine einfacheschema_versionzum Vergleichen speichern.- Abweichungen protokollieren und einen schnellen Rollback-Schalter bereithalten.
Backfills: Bestehende JSON-Daten in neue Tabellen verschieben
Ein Backfill ist der Prozess, bei dem Sie unordentliches JSON in saubere Zeilen verwandeln. Behandeln Sie ihn wie eine echte Datenpipeline, nicht als Einmal-Skript. Sie wollen ihn stoppen, neu starten und erneut laufen lassen können, ohne Daten zu duplizieren oder die Zieltabellen zu beschädigen.
Machen Sie den Job idempotent und restartbar. Ein gängiges Muster: JSON parsen, auf neue Spalten abbilden und dann mit einem stabilen natürlichen Schlüssel (z. B. user_id + Feldname) oder einer deterministischen generierten ID in die Zieltabelle upserten. Speichern Sie einen Checkpoint, damit Sie immer wissen, was verarbeitet wurde.
Um das Risiko gering zu halten, backfillen Sie in kleinen Batches und verfolgen den Fortschritt. ID-Bereiche funktionieren gut, wenn IDs dicht belegt sind. Zeitfenster sind praktisch, wenn Ihre Daten natürlich ereignisgetrieben sind. Eine Queue mit Primärschlüsseln ist sicherer, wenn IDs spärlich sind. Viele Teams machen am Ende noch einen „changed since last run“-Durchlauf, um alles zu erwischen, was sich während des Backfills bewegt hat.
Validierung ist wichtiger als Geschwindigkeit. JSON verbirgt oft falsche Typen und fehlende Felder, also legen Sie Parsing-Regeln fest: Default-Werte, Typkonversionen und was „leer“ bedeutet. Wenn Sie "age": "" sehen, speichern Sie NULL, 0 oder lehnen Sie es ab? Entscheiden Sie die Regel und halten Sie sie konsistent.
Gehen Sie davon aus, dass ein Teil des JSON kaputt ist, und planen Sie dafür. Lassen Sie nicht zu, dass der ganze Job crasht. Isolieren und protokollieren Sie Fehler, damit Sie sie gezielt beheben können:
- Protokollieren Sie die Quell-Row-ID und den JSON-Pfad, der fehlgeschlagen ist.
- Speichern Sie das rohe JSON-Fragment, das den Fehler verursachte.
- Markieren Sie den Grund (ungültiges JSON, fehlendes Pflichtfeld, Typfehler).
- Verarbeiten Sie die nächste Zeile weiter.
Hier scheitern Migrationen oft in AI-erstellten Apps: halb-parsierte Edge-Cases, stille Abschneidungen und „Best-Effort“-Konversionen, die erstmal ok aussehen, bis Reporting oder Billing darauf angewiesen sind. Ein striktes Log dessen, was nicht migriert werden konnte und warum, verwandelt Überraschungen in eine kurze, umsetzbare To‑Do-Liste.
Korrektheit mit Vergleichen und Schutzmaßnahmen verifizieren
Das Schlimmste ist nicht das Verschieben der Daten. Es ist, dem Ergebnis zu vertrauen. Sie brauchen einfache Checks, die Ihnen in klaren Worten sagen, ob die neuen Tabellen das abbilden, was die App früher aus JSON gelesen hat.
Starten Sie mit Vergleichen, die denselben Wert auf zwei Wegen berechnen: (1) JSON-Spalte wie der alte Code parsen und (2) aus den neuen Tabellen lesen. Machen Sie das zuerst für nutzer-sichtbares Verhalten: Berechtigungen, Preise, Plan-Limits, Statusflags. Dann erweitern Sie auf tiefere Felder.
Rollen Sie das mit Sampling aus, bevor Sie alles validieren. Nehmen Sie eine kleine Stichprobe (z. B. jüngste Datensätze pro Tenant oder pro Tag), prüfen Sie Abweichungen, korrigieren Sie Ihre Mappings und weiten Sie die Abdeckung aus, bis Sie bereit sind, Checks über den gesamten Datensatz laufen zu lassen.
Wenn Sie Abweichungen verfolgen, behalten Sie Kategorien bei, die leicht zu bearbeiten sind:
- Missing: Wert existiert im JSON, aber kein Eintrag in den neuen Tabellen.
- Different: Beide existieren, stimmen aber nach Normalisierung nicht überein (Typen, Rundung, Groß-/Kleinschreibung).
- Invalid: JSON lässt sich nicht parsen oder scheitert an der Validierung.
- Unexpected: Neue Tabellen enthalten Werte, die es vorher nicht im JSON gab.
Entscheiden Sie die Quelle der Wahrheit während der Transition und schreiben Sie sie auf. Gängige Optionen sind „JSON ist die Wahrheit (neue Tabellen sind abgeleitet)“ oder „Neue Tabellen sind die Wahrheit (JSON ist ein Kompatibilitäts-Spiegel)“. Wählen Sie pro Phase eine. Sonst werden Ingenieurteams Abweichungen beheben, indem sie beide Seiten unterschiedlich updaten.
Schutzmaßnahmen machen Fehler günstiger: Feature-Flags für Reads, harte Limits, wie viele Zeilen ein Backfill-Job pro Lauf ändern darf, und Alerts, wenn die Abweichungsrate steigt. Halten Sie jede Phase umkehrbar mit einem klaren Rollback-Pfad: ein Schalter zurück auf JSON-Reads, eine Möglichkeit, Writes zu pausieren, und ein Cleanup-Plan für teilweise migrierte Daten.
Reads schrittweise umstellen, ohne Nutzer zu stören
Sobald die neuen Tabellen gefüllt und aktuell gehalten werden, ändern Sie den Leseweg in kleinen Schritten. Behandeln Sie jeden Read-Pfad wie ein eigenes Release, nicht als einen großen Flip.
Verstecken Sie den neuen Read hinter einer Feature-Flag. Rollen Sie ihn zuerst für einen kleinen Traffic-Anteil aus (oder nur interne Accounts), dann schrittweise. So bleiben Fehler begrenzt und Rollback einfach.
Eine praktische Reihenfolge, die für die meisten Apps funktioniert:
- Schalten Sie nacheinander einen Bildschirm oder API-Endpunkt um.
- Behalten Sie den JSON-Read als Fallback für diesen Endpunkt.
- Vergleichen Sie die Ergebnisse im Hintergrund und protokollieren Sie Abweichungen.
- Erhöhen Sie die Sichtbarkeit schrittweise (1%, 10%, 50%, 100%).
- Entfernen Sie den Fallback erst, nachdem die Ergebnisse längere Zeit übereinstimmen.
Beobachten Sie nach jedem Wechsel zuerst das Nutzererlebnis: Fehlerraten, Timeouts und langsame Abfragen. Normalisierte Reads können versehentlich viele kleine Abfragen erzeugen, und ein fehlender Index kann eine zuvor schnelle Seite in die Knie zwingen. Setzen Sie Alerts vor dem Rollout, nicht danach.
Behalten Sie Dual Writes, bis Sie den neuen Read unter realer Last vertrauen. Wenn Sie zu früh aufhören, in den Blob zu schreiben, wird ein Rollback zum Datenverlust. Dual Write ist Versicherung. Entfernen Sie es erst, wenn Sie sicher sind, dass Sie nicht zurückmüssen.
Machen Sie Blob-only-Abhängigkeiten explizit. Wenn ein Feature noch auf einem JSON-only-Key beruht, entscheiden Sie, ob es zu einer echten Spalte/Tabelle wird oder wegfällt. Vage Lösungen führen dazu, dass Teams dauerhaft aus beiden Modellen lesen.
Häufige Fehler, die zu Datenverlust oder Ausfall führen
Die meisten Ausfälle bei einer JSON-zu-Tabellen-Migration passieren, weil die Arbeit wie ein einzelner Schalter behandelt wird. Tatsächlich betreiben Sie für eine Weile zwei Datenmodelle gleichzeitig, und genau die Überschneidung ist fehleranfällig.
Ein häufiger Fehler ist, Dual Writes einzuschalten, ohne zu entscheiden, was passiert, wenn die beiden Writes abweichen. Selbst wenn beide Updates in derselben Anfrage passieren, brauchen Sie eine Konflikt-Policy (welche Seite gewinnt) und eine Möglichkeit, fehlende Writes zu erkennen und erneut auszuführen.
Backfills bereiten auch Probleme, wenn sie nicht fortsetzbar sind. Lange Jobs werden unterbrochen: Deploys, Timeouts, gesperrte Zeilen oder eine fehlerhafte Zeile. Startet der Job dann von vorn, drohen Duplikate, partielle Updates oder Lastspitzen, die wie ein DoS auf die eigene Datenbank aussehen.
Stiller Daten-Drift ist ein weiterer häufiger Fehler. Teams „bereinigen“ Feldbedeutungen während der Migration (z. B. Statuswerte oder Datumsformate) und dokumentieren die Mapping-Änderung nicht. Alles wirkt erst einmal ok, bis Reports, E-Mails oder Billing anders funktionieren.
Die Fehler, die am häufigsten auftreten:
- Keine klare Konflikt-Policy für Dual Writes und keine Audit-Spur, um Abweichungen zu erkennen.
- Backfills, die nicht idempotent sind und keine Checkpoints haben.
- Feldbedeutungen mittendrin ändern ohne versioniertes Mapping und Tests.
- Downstream-Reader vergessen: Analytics-Queries, Exporte, Webhooks und Hintergrundjobs.
- Die JSON-Spalte zu früh löschen, bevor Reads vollständig verschoben und verifiziert sind.
Ein reales Beispiel: Eine App speichert „User Profile“, „Subscription“ und „Permissions“ in einer JSON-Spalte. Ein Backfill kopiert Daten in neue Tabellen, aber ein nächtlicher Job liest weiterhin JSON und überschreibt die normalisierten Tabellen, wodurch neue Änderungen gelöscht werden. Die Lösung ist selten cleverer Code. Es sind klare Regeln: resumable Backfills, strikte Mappings und die alte Spalte behalten, bis das neue Modell bewiesen hat, dass es korrekt ist.
Kurze Checkliste vor dem Cutover
Der Cutover-Tag sollte langweilig sein. Wenn er sich noch wie ein Sprung ins Unbekannte anfühlt, brauchen Sie wahrscheinlich einen weiteren Trockenlauf.
- Tabellen und Releases sind sicher zu deployen: Neue Tabellen existieren in Produktion, Migrations-Skripte sind idempotent, und Indizes/Constraints sind geprüft.
- Backfill ist sichtbar und wiederholbar: Fortschritt, Fehlerzahlen und Checkpoints sind einsehbar, und Sie können neu starten ohne Duplikate.
- Dual Write ist aktiv und Konfliktregeln dokumentiert: Sie wissen, welche Quelle gewinnt (z. B. neuester Timestamp) und protokollieren Konflikte.
- Leseumschaltungen sind abgesichert: Reads lassen sich pro Endpoint oder Tenant per Feature-Flag umschalten und schnell zurücksetzen.
- Die Abweichungsrate ist akzeptabel und Rollback getestet: Sie vergleichen Schlüssel-Summen, prüfen stichprobenhaft Datensätze und haben Rollback an Produktions-ähnlichen Daten geübt.
Beispiel-Szenario: Eine AI-erstellte App bereinigen, die alles in JSON gespeichert hat
Ein Gründer bringt in einem Wochenende einen AI-generierten CRM-Prototyp raus. Für Demos reicht es, aber jedes Kundenprofil liegt als ein JSON-Blob in einer Spalte. Ein Profil kann Name, E-Mail, Status, last_contacted, Notizen und benutzerdefinierte Felder enthalten.
Drei Monate später zeigt sich der Schmerz. Reporting ist langsam, weil die DB für jedes Diagramm JSON scannen und parsen muss. Schlimmer: Das Feld status ist ein Chaos: "Active", "active", "ACTIV", "In progress", "In-Progress" und "inprogress" bedeuten ungefähr dasselbe. Filter verlieren Einträge, Dashboards widersprechen sich und Vertriebsnotizen landen in der falschen Phase.
Ein sicherer erster Slice ist, genau das zu normalisieren, was das Dashboard antreibt: Kunden und Status.
Dieser Slice könnte so aussehen:
- Eine
customers-Tabelle mit stabilen Spalten (id,name,email,created_at). - Eine
statuses-Lookup-Tabelle (id,canonical_name) mit einer erlaubten Menge von Werten. - Eine Verbindung zwischen ihnen (entweder
customers.status_idoder eine separatecustomer_status-Tabelle, je nach Historienbedarf).
Dann backfillen Sie aus dem existierenden JSON:
- Parsen Sie jeden Profil-Blob und insert/updaten Sie die Customer-Row.
- Mappen Sie unordentliche Status-Strings auf kanonische Status mit einem klaren „unknown“-Bucket.
- Protokollieren Sie alles, was beim Parsen fehlschlägt, damit Sie Daten reparieren statt raten.
Der Cutover bleibt gestaffelt. Zuerst schalten Sie nur die Dashboard-Reads auf die neuen Tabellen um. Für den Rest der App bleiben JSON-Reads aktiv, während Sie Counts und Summen vergleichen. Wenn das Dashboard korrekt und schnell ist, migrieren Sie die restlichen Bildschirme nacheinander.
Nächste Schritte: Migration abschließen und sauber halten
Sobald Ihre Reads vollständig auf den neuen Tabellen liegen und Sie eine stabile Zeit ohne Überraschungen hatten, entscheiden Sie, was mit der alten JSON-Spalte passiert. Die meisten Teams frieren sie ein (keine weiteren Writes, nur kurz zur Sicherheit) oder entfernen sie nach Backups und Abnahme.
Wenn Sie Sicherheitsfeatures zurückgestellt haben, um schnell voranzukommen, fügen Sie sie jetzt hinzu. Normalisierte Tabellen zahlen sich langfristig aus, wenn sie schlechten Daten vorbeugen, nicht nur wenn sie Daten speichern.
Das neue Contract festschreiben
Schreiben Sie die Regeln auf, von denen Ihre App jetzt abhängt: welche Felder Pflicht sind, was „gültig“ bedeutet und wo jedes Datum lebt. Das wird zum Datenvertrag für zukünftige Features und hilft neuen Teammitgliedern, nicht aus Bequemlichkeit wieder einen Blob einzuführen.
Eine einseitige Dokumentation reicht: Tabellennamen, Schlüsselfelder, Ownership (wer was schreibt) und ein kurzes Beispiel eines gültigen Datensatzes.
Verhindern, zurück in Blobs zu rutschen
Nach der Migration ist das größte Risiko Drift: neue Features stopfen still neue Felder in ein Catch-All JSON-Feld.
Frieren oder entfernen Sie die JSON-Spalte nach einem definierten Stabilitätsfenster. Fügen Sie die Constraints und Indizes hinzu, die Sie verschoben haben (Foreign Keys, Unique-Constraints, NOT NULL und die Indizes, die Ihre Top-Abfragen brauchen). Wenn Sie ein JSON-Feld für echtes „Misc“-Metadata behalten, fügen Sie eine leichte Prüfung hinzu, damit neue Keys nicht ohne Plan auftauchen.
Wenn Sie eine AI-generierte Codebasis geerbt haben, die stark auf JSON-Blobs setzt, konzentriert sich FixMyMess (fixmymess.ai) auf Diagnose und Reparatur solcher AI-erstellten Architekturen — inklusive phasierter Migrationen, Logikfixes und Sicherheits-Hardening mit menschlicher Verifikation, bevor Änderungen ausgeliefert werden.