Parallelitätslimits für Hintergrund-Worker, die deine DB schützen
Parallelitätslimits für Hintergrund-Worker halten die DB-Last stabil, indem sie parallele Jobs und Warteschlangentiefe begrenzen. Lerne einfache Regeln, schnelle Prüfungen und ein Praxisbeispiel.
Warum Hintergrund-Worker die DB überlasten können
Ein „DB-Spike“ zeigt sich oft als Kettenreaktion. Seiten, die vorher schnell waren, bleiben hängen. Logins schlagen fehl. In deiner API tauchen Timeouts auf und die Zahl fehlgeschlagener oder erneut gestarteter Jobs wächst. Selbst wenn nur ein Feature im Hintergrund läuft, kann es die ganze App lahmlegen, weil die Datenbank der gemeinsame Engpass ist.
Hintergrund-Worker überlasten Datenbanken schneller als Web-Traffic, weil sie persistent und parallel arbeiten. Eine Web-Anfrage ist durch Nutzerinteraktion und Request-Timeouts begrenzt. Worker ziehen fortlaufend Jobs und arbeiten so schnell, wie die CPUs es erlauben. Wenn jeder Job ein paar Abfragen macht, werden daraus schnell hunderte oder tausende Abfragen pro Minute ohne natürliche Pause.
Das Schwierige ist: Es sieht oft nach „langsamen Abfragen“ aus, obwohl das eigentliche Problem Parallelität ist. Wenn zu viele Jobs gleichzeitig die DB treffen, gehen die Verbindungen aus, die Datenbank beginnt intern Arbeit zu queueen und alles verlangsamt sich zusammen.
Symptome, die häufig auf zu hohe Parallelität hinweisen:
- Viele unterschiedliche Abfragen werden gleichzeitig langsamer (nicht nur ein Endpunkt)
- Connection-Pool-Fehler oder Meldungen wie "too many connections"
- Retry-Spikes direkt nach einem Deploy oder wenn ein geplanter Task startet
- DB-CPU steigt, während der Durchsatz nicht mehr wächst
Das Ziel eines Concurrency-Limits ist nicht, Jobs absichtlich zu verlangsamen, sondern den Durchsatz gleichmäßig statt sprunghaft zu halten: stabile DB-Last, weniger Vorfälle und konsistente Latenz für echte Nutzer.
Beispiel: Ein nächtlicher „rebuild search index“-Job startet 20 Worker. Jeder liest Zeilen, aktualisiert Status und schreibt Fortschritt. Die Seite ist nachts ruhig, aber die DB sättigt sich und der Morgenverkehr trifft ein erschöpftes, aufgestautes System.
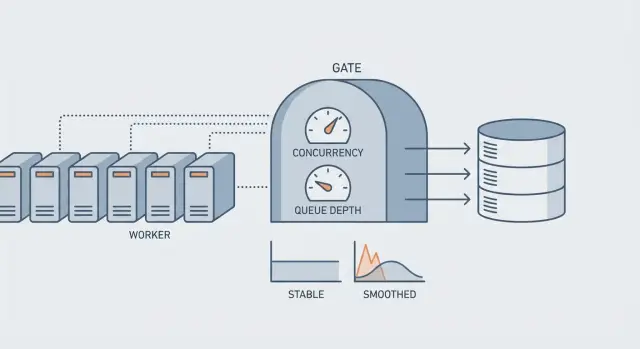
Concurrency, Rate und Queue Depth in einfachen Worten
Wenn Leute sagen „wir brauchen mehr Worker“, meinen sie meist einen von drei Reglern. Jeder löst ein anderes Problem, und den falschen hochzudrehen kann die Datenbank überlasten.
Concurrency ist, wie viele Jobs gleichzeitig laufen. Bei Concurrency = 20 können 20 Jobs parallel auf die DB zugreifen.
Rate ist, wie schnell du Jobs über die Zeit startest, z. B. „5 Jobs pro Sekunde“, selbst wenn mehr parallel möglich wären.
Queue Depth ist, wie viele Jobs in der Warteschlange stehen. Backlog Age sagt, wie lange der älteste Job schon wartet.
Queue Depth sagt dir das Volumen. Backlog Age sagt dir den Schmerz. Eine tiefe Queue kann in Ordnung sein, wenn sie gleichmäßig abläuft. Eine kleine Queue kann zur Krise werden, wenn Jobs feststecken und der älteste Stunden alt ist.
Warum „mehr Worker“ oft zunächst alles verschlimmert: Worker konkurrieren an denselben Punkten. Der versteckte Engpass ist meist die Datenbank – sei es Connection-Pool-Limits, Zeilen- oder Tabellensperren oder lange Transaktionen. Wenn du die Parallelität erhöhst, erzeugst du mehr Konkurrenz. Anfragen warten auf DB-Verbindungen, Transaktionen bleiben länger offen, Sperren dauern länger, und alles verlangsamt sich.
Ein kurzes Beispiel: 10 Worker führen je einen Job aus, der eine Transaktion für 300 ms hält. Das klingt wenig. Wenn diese Jobs dieselben Tabellen berühren, kann eine Erhöhung auf 20 Worker Wartezeiten bei Sperren verdoppeln und die Transaktionszeit auf Sekunden drücken. Web-Anfragen konkurrieren dann mit den Workern um Verbindungen, und die App wirkt down, obwohl sie nur überlastet ist.
Was in der Datenbank meist zuerst kaputtgeht
Wenn Hintergrund-Worker spikes erzeugen, ist der erste Fehler oft nicht „die Datenbank ist langsam“, sondern „die Datenbank kann gerade keine Arbeit annehmen“. Das zeigt sich als Timeouts, eine Ansammlung wartender Abfragen und steigende Fehlerquoten, obwohl die CPU noch normal wirkt.
1) Erschöpfung des Connection-Pools
Die meisten Apps haben pro Prozess einen festen Connection-Pool. Jeder Worker-Thread oder -Prozess braucht eine Verbindung für die Abfragen, die er ausführt. Wenn du mehr Worker startest, als der Pool handhaben kann, warten sie auf Verbindungen. Wartende Worker verbrauchen dennoch Speicher und versuchen weiter, was zusätzlichen Druck erzeugt.
Ein typisches Muster: Deine Web-App braucht 20 Verbindungen, damit alles gesund bleibt, aber Worker nehmen den Rest des Pools und die Website beginnt, Logins oder Checkout fehlschlagen zu lassen.
2) Sperren durch lange Transaktionen
Sperren sind der nächste häufige Ausfallgrund. Selbst wenn Abfragen schnell sind, halten lange Transaktionen Zeilen gesperrt. Wenn viele Jobs dieselben „heißen“ Zeilen oder Tabellen anfassen (z. B. dasselbe Nutzerkonto, Kontostand oder ein "last_processed_at"-Feld), wird die Arbeit seriell: nur ein Job kann sich bewegen, der Rest wartet.
Sperrwarten kann wie zufällige Langsamkeit aussehen, die eigentliche Ursache ist aber zu viel Parallelität auf denselben Daten.
3) Teure Abfragemuster in Jobs
Jobs machen oft kleine Arbeiten in einer dichten Schleife, was viele Abfragen erzeugt. Übliche Fehler sind N+1-Patterns, Einzel-Updates statt Batch-Updates, wiederholtes Neuberechnen gleicher Aggregationen, fehlende Indizes auf Job-Filtern und das Abrufen viel zu vieler Daten.
4) Externe Aufrufe innerhalb einer Transaktion
Beginnt ein Job eine Transaktion und ruft dann eine externe API (E-Mail, Payments, AI, Storage) bevor er committet, werden DB-Verbindung und Sperren gehalten, während der Worker auf das Netzwerk wartet. Multipliziert sich das durch parallele Worker, hast du sehr schnell Connection-Sättigung.
Concurrency-Limits helfen, aber sie wirken am besten zusammen mit kurzen Transaktionen und vorhersagbaren Abfragekosten.
Wie man sinnvolle Limits aussucht (ohne zu raten)
Ein gutes Limit ist keine Zahl anhand eines Bauchgefühls. Es ist eine Zahl, die deine Datenbank an einem schlechten Tag aushält, wenn Traffic hoch ist und Cache-Misses steigen. Das Ziel ist einfach: halte die DB in sicheren Bereichen für Verbindungen und Abfragezeiten, während die Arbeit stetig vorankommt.
Starte mit einer konservativen Basis, die an der Datenbank orientiert ist, nicht am App-Server. Schau auf deinen DB-Connection-Pool (oder max connections) und halte Platz für Web-Anfragen, Admin-Tasks und Migrations. Berücksichtige dann, wie lange ein typischer Job eine Verbindung hält.
Ein praktisches Basisvorgehen:
- Reserviere 50–70 % der DB-Verbindungen für Online-Traffic und unbekannte Arbeit.
- Nutze die verbleibenden 30–50 % als Gesamtbudget für alle Worker zusammen.
- Starte mit geringer Parallelität (oft 1–3 Worker pro Queue) und erhöhe nur, wenn die DB-Latenz stabil bleibt.
- Prüfe die Limits nach neuen Features. Grenzen, die letzten Monat funktioniert haben, können nach einer Abfrageänderung oder einem fehlenden Index versagen.
Verwende nicht eine einzige globale Zahl für alle Jobs. Teile Limits pro Queue basierend auf Business-Impact auf. Eine kritische Queue (Passwort-Resets, Onboarding) sollte auch bei einer großen Bulk-Queue reaktionsfähig bleiben.
Einige Job-Typen sind bekannte DB-Buller: Exporte, Billing-Läufe, große Imports oder alles, was große Tabellen scannt. Setze auf diese pro-Job Caps, auch wenn der Gesamt-Pool größer ist. Beispiel: Du erlaubst 10 Worker insgesamt, aber nur 1 Export gleichzeitig.
Entscheide auch, was passiert, wenn die Queue wächst. Ignorierst du das, bekommst du später oft überraschende Spikes, wenn Worker aufholen.
- Backpressure: Producer verlangsamen (Schedules seltener, Delays hinzufügen, Enqueues pro Minute begrenzen).
- Arbeit verwerfen: Niedrigwertige Jobs droppen oder zusammenfassen (Duplikate mergen, nur das Neueste behalten).
- Verschieben: Große Tasks auf Off-Peak-Fenster mit strengen Caps verlegen.
- Aufteilen: Einen riesigen Job in kleinere Chunks teilen mit harten Limits pro Chunk.
Schritt für Schritt: Concurrency- und Queue-Depth-Limits setzen
Beginne damit, die Job-Typen zu benennen. Notiere, was jeden Job auslöst, wie oft er läuft und ob er viele Zeilen liest oder schreibt. Markiere die DB-intensiven Jobs (Imports, Analytics-Backfills, "sync everything", E-Mails, die auch Nutzerzustand aktualisieren). Diese kontrollierst du zuerst.
Setze dann eine Obergrenze, wie viele Jobs gleichzeitig laufen dürfen, und verteile diese Obergrenze über die Queues. Ein häufiges Setup ist eine Default-Queue für normale Arbeit und eine Heavy-Queue für DB-intensive Jobs. So kann ein lauter Job nicht alle DB-Verbindungen an sich reißen.
Ein praktischer Anfang:
- Globales Limit: halte die Gesamtzahl gleich oder unter deinem sicheren DB-Verbindungsbudget.
- Per-Queue-Limit: schwere Jobs bekommen einen kleineren Anteil als schnelle Jobs.
- Per-Job-Limit (falls unterstützt): nur 1–2 identische teure Jobs gleichzeitig.
- Priorisierung: Nutzerrelevante Arbeit vor Wartungsarbeiten.
- Zeitfenster: Schwere Queues in Traffic-arme Stunden verschieben.
Dann begrenze die Queue-Tiefe. Entscheide, was passiert, wenn die Queue voll ist: neue Enqueues pausieren, verzögern (mit geplantem Startzeitpunkt) oder ablehnen mit klarer Fehlermeldung. Wenn deine Heavy-Queue 1.000 Jobs erreicht, stoppst du eventuell neue Bulk-Imports und bittest Nutzer, es später erneut zu versuchen.
Retries können ebenfalls Spikes erzeugen. Füge Jitter (kleine zufällige Verzögerungen) hinzu, damit Fehler nicht synchron retryen, und nutze ein Backoff, das bei DB-Fehlern schnell wächst.
Rolle Änderungen schrittweise aus. Verringere zuerst die Concurrency, beobachte die DB und erhöhe dann in kleinen Schritten. Wenn Abfragezeiten steigen oder Verbindungen am Maximum kleben, dreh zurück bevor Nutzer es spüren.
Monitoring, das zeigt, ob Limits wirken
Limits funktionieren, wenn deine Datenbank stabil bleibt, selbst wenn das Job-Volumen schwankt. Du solltest kontrollierte Peaks sehen, nicht plötzliche Abstürze, bei denen alles gleichzeitig langsamer wird.
Wichtige Datenbank-Signale
Beobachte eine kleine Menge Metriken zusammen:
- Aktive Verbindungen (und Wartezeit im Connection-Pool)
- Anzahl langsamer Abfragen und p95-Abfragezeit
- Sperrwarten und Deadlocks
- CPU-Auslastung und Speicherdruck
- Disk-IOPS und Lese/Schreib-Latenz
Wenn Verbindungen am Anschlag sind bei niedriger CPU, hast du wahrscheinlich zu viele parallele Abfragen, die auf Sperren oder I/O warten. Wenn CPU hoch ist und langsame Abfragen zunehmen, macht die DB zu viel Arbeit pro Abfrage.
Worker-Signale, die zeigen, ob Throttling hilft
Verfolge laufende Jobs, wartende Jobs, Job-Dauer (p50 und p95), Retry-Rate und Dead-Letters. Ein gesundes System hat eine Queue, die wächst und schrumpft, aber die Backlog Age bleibt in etwa stabil.
Handlungsfähige Alerts:
- Backlog Age steigt für 10–15 Minuten
- Retry-Rate steigt zusammen mit DB-Timeouts
- DB-Verbindungen kleben nahe dem Maximum für mehrere Minuten
- Job-Dauer driftet nach oben (insbesondere p95)
Wie du entscheidest, was zu ändern ist: Wenn das Reduzieren der Worker-Concurrency DB-Metriken beruhigt und die Job-Dauer verbessert, waren die Limits zu hoch. Wenn das wenig hilft, aber langsame Abfragen und Sperrwarten bleiben, brauchst du schnellere Abfragen oder bessere Indizes, nicht nur mehr Throttling.
Beispiel: Wenn ein nächtlicher E-Mail-Job Retries und Sperrwarten verursacht, kann das Limit in Ordnung sein, aber die Selektionsabfrage für Empfänger braucht vielleicht kleinere Batches oder einen besseren Index.
Häufige Fehler, die trotzdem zu Spikes führen
Viele Teams setzen Limits und erleben dennoch überraschende Spikes. Meist wurde das Limit nach Worker-Kapazität gesetzt, nicht danach, was die Datenbank verkraftet. Worker-Concurrency nach CPU-Kernen zu bemessen klingt plausibel, ignoriert aber Connection-Pool-Größe, Sperrkonkurrenz und langsame Abfragen. Die DB kann weit vor dem Worker-Host „voll sein“.
Retry-Verhalten ist ein weiterer stiller Spike-Erzeuger. Unbegrenzte Retries oder Retries, die alle zur gleichen Zeit feuern (z. B. "retry in 30 seconds" für jeden Fehler), können einen Retry-Sturm erzeugen. Ein kurzer Ausfall wird so zum zweiten Ausfall, wenn tausende Jobs gleichzeitig wieder aktiv werden.
Queue-Design kann das Problem verstärken. Eine einzige Queue für alles lässt Bulk-Arbeit kritische Arbeit verhungern. Ein großer Backfill verzögert Nutzer-Jobs, jemand erhöht die Concurrency, um aufzuholen, und das trifft die DB noch härter.
Während Vorfällen ist ein häufiger Fehler, Limits zu erhöhen, um das Backlog zu leeren. Das verwandelt eine handhabbare Queue oft in Connection-Sättigung. Du räumst zwar schneller auf, aber Timeouts, Sperrwarten und Deadlocks steigen, sodass der Rückstau zurückkommt.
Richtlinien, die gängige Fehler vermeiden:
- Basier Concurrency auf DB-Verbindungen und Abfragekosten, nicht auf CPU-Kernen.
- Füge Jitter und exponentielles Backoff für Retries hinzu, mit einem harten Maximum.
- Trenne Queues für kritisch vs. Bulk-Arbeit.
- Betrachte "Limits erhöhen" als letzte Option und mache es in kleinen Schritten.
- Definiere eine klare Verzögerungs-, Ablehnungs- oder Abschneidungs-Policy, wenn die Queue voll ist.
Schnelle Checkliste bevor du in Produktion gehst
Bevor du Hintergrund-Worker in Produktion freigibst, nimm das schlimmste Szenario an: ein Deploy, ein Restart oder eine Incident-Wiederherstellung, bei der alle Worker gleichzeitig aufwachen. Die Datenbank sieht nicht "Hintergrundarbeit" – sie sieht eine plötzliche Welle von Verbindungen und Abfragen.
Checkliste:
- Peak-Connections-Mathe ist dokumentiert. Addiere Web-Server + Worker-Prozesse × Worker-Threads + Admin-Skripte. Vergleiche das mit deinem DB-Connection-Limit (und lasse Puffer).
- Schwere Jobs sind getrennt und begrenzt. Lege teure Job-Typen (Imports, Backfills, große E-Mail-Blasts, Daten-Syncs) in eigene Queues mit niedrigerer Concurrency.
- Queue-Depth hat eine harte Obergrenze und Backlog Age wird überwacht. Eine Max-Länge verhindert unendliche Anhäufungen, ein Alert auf das Alter des ältesten Jobs erkennt Verzögerungen früh.
- Retries erzeugen keinen Retry-Sturm. Streue Retries, beende nach einem sinnvollen Fenster und vermeide sofortige Retries bei DB-Fehlern, die lastbedingt sind.
- Du hast einen sicheren Notfall-Schalter. Kenne Wege, Worker-Concurrency schnell zu reduzieren (und nur die Heavy-Queue zu pausieren) ohne Redeploy.
Ein praktisches Beispiel: Wenn ein nächtlicher Report-Job viele Zeilen berührt, gib ihm eine eigene Queue mit Concurrency 1–2, begrenze die Tiefe dieser Queue und warne, wenn ein Report-Job älter als 15 Minuten ist.
Beispiel: wie du verhinderst, dass ein nächtlicher Job deine App lahmlegt
Stell dir eine SaaS-App vor, bei der Nutzer bis spät aktiv sind und um 1:00 Uhr nachts ein Import startet. Der Import liest eine große CSV, reichert jede Zeile an und schreibt Updates in dieselben Tabellen, die für Logins, Dashboards und Billing genutzt werden.
Ohne Limits versucht das Worker-System, so schnell wie möglich fertigzuwerden und startet viele Jobs gleichzeitig. Innerhalb von Minuten sind DB-Verbindungen ausgelastet. Abfragen, die früher 50 ms brauchten, dauern plötzlich Sekunden. Web-Requests timeouts. Dann starten Retries, und du hast eine zweite Welle von Arbeit, die um dieselben DB-Ressourcen kämpft.
Ein simpler Plan verändert die Geschichte:
- Lege die Import-Jobs in eine eigene Queue, getrennt von nutzerkritischen Jobs (E-Mails, Webhooks, Payments).
- Begrenze die Import-Concurrency auf eine kleine Zahl basierend auf DB-Kapazität (z. B. 3–5 Worker).
- Setze eine Queue-Depth-Grenze, damit bei großem Rückstau keine neuen Jobs mehr angenommen werden.
- Füge Ratenbegrenzung für die schwersten DB-Operationen (z. B. Upserts) hinzu, um Burstglätten zu erreichen.
Der Import läuft nun länger, bleibt aber vorhersehbar. Nutzeranfragen behalten einen stabilen Anteil an DB-Verbindungen. Wenn der Import mehr Arbeit erzeugt, als das System sicher verarbeiten kann, wartet sie in der Warteschlange statt einen Stau zu verursachen.
Der Kompromiss ist einfach: ein etwas langsamerer Batch-Job im Austausch für eine stabile App. Die meisten Teams akzeptieren, dass ein Import später fertig wird, wenn dadurch Support-Tickets und Notfall-Rollbacks vermieden werden.
Wenn Limits nicht ausreichen (und was du als Nächstes ändern solltest)
Concurrency-Limits sind Schutzgeländer, keine Heilung. Wenn du jeden Tag die Limits erreichst und die Queue nie aufholt, ist meist der Job selbst das Problem, nicht die Worker-Anzahl.
Skaliere Worker nur, wenn der Job effizient ist und du einfach nur mehr Volumen hast. Verbessere die Job-Logik, wenn jeder Job zu schwer ist (zu viele Abfragen, wiederholte Arbeit oder lange gehaltene Sperren).
DB-Load reduzieren, bevor du mehr Worker hinzufügst
Die meisten Spike-Incidents entstehen durch Jobs, die viele kleine Datenbankzugriffe parallel ausführen. Änderungen mit hoher Wirkung sind:
- Batch-Arbeit: in Chunks updaten oder einfügen statt Zeile für Zeile.
- Idempotente Jobs: sicher retrybar ohne doppelte Nebenwirkungen.
- Roundtrips reduzieren: einmal nötige Daten holen und dann im Speicher arbeiten.
- Richtige Indizes: langsame Scans multiplizieren sich unter Parallelität schnell.
- Transaktionen verkürzen: weniger Arbeit während Sperren.
Beispiel: Ein nächtlicher "recalculate stats"-Job, der 10.000 Nutzer lädt und pro Nutzer 10 Abfragen ausführt, wird deine DB trotz niedriger Concurrency zerstören. Stelle ihn auf Batch-Verarbeitung oder aggregierte Abfragen um, und aus einer Abfragesturm werden wenige vorhersagbare Abfragen.
Read/Write-Trennung: hilfreich, aber kein Allheilmittel
Read-Only-Arbeit auf Replikas auszulagern hilft, wenn es wirklich nur ums Lesen geht und die Replikas mithalten können. Es hilft nicht bei Writes, Zeilensperren oder heißen Tabellen, die alle Jobs berühren. Achte auf Replica-Lag: Ein Job, der von einer Replica liest und auf dem Primary schreibt, kann auf veralteten Daten basieren.
Wenn du dauerhaft ausschließlich auf Throttling setzt, definiere ein Ziel (z. B. Queries pro Job halbieren oder Laufzeit unter 30 Sekunden) und überprüfe Limits, nachdem du die Arbeitslast verbessert hast.
Nächste Schritte für AI-generierte Codebases
AI-generierte Apps kommen oft mit unsicheren Defaults, weil das Ziel meist "funktioniert" statt "produktionssicher" war. So entstehen ungebundene Queues, Worker, die so viele Tasks starten, wie die Maschine erlaubt, und kein Backpressure, wenn die Datenbank langsamer wird.
Ein typisches Muster: Ein Hintergrund-Job liest 50.000 Zeilen und schreibt dann für jeden Eintrag ohne Batching. Selbst wenn jede Schreiboperation schnell ist, kann die kumulierte Last Verbindungs-Sättigung, Sperrstau und Timeouts bedeuten. In solchen Fällen helfen sinnvolle Limits, sind aber nur ein Teil der Lösung.
Wenn du ein AI-generiertes Prototype von Tools wie Lovable, Bolt, v0, Cursor oder Replit geerbt hast und schon Spike-Verhalten siehst, kann FixMyMess (fixmymess.ai) mit einem kostenlosen Code-Audit starten, um die genaue Ursache des DB-Drucks zu finden und sichere Worker- und Queue-Einstellungen zu empfehlen, bevor du in Produktion gehst.
Häufige Fragen
Why do background workers overload the database faster than normal web traffic?
Hintergrund-Worker laufen kontinuierlich und parallel, sodass sie konstanten Druck auf die Datenbank erzeugen ohne natürliche Pausen. Selbst wenn jeder Job nur ein paar Abfragen macht, führt hohe Parallelität schnell zu Wartezeiten auf Verbindungen, Sperrkonflikten und Timeouts, die die ganze Anwendung betreffen.
How can I tell if the problem is concurrency rather than one slow query?
Wenn viele unterschiedliche Abfragen gleichzeitig langsamer werden, deutet das meist auf Konkurrenz um Ressourcen hin und nicht auf eine einzelne langsame Abfrage. Auch Verbindungs-Pool-Fehler, erhöhte Retry-Raten kurz nach einem geplanten Task und steigende DB-CPU ohne höheren Durchsatz sind starke Hinweise auf zu viel Parallelität.
What’s the difference between concurrency, rate limiting, and queue depth?
Concurrency beschreibt, wie viele Jobs gleichzeitig laufen. Rate Limiting bestimmt, wie schnell Jobs gestartet werden (z. B. 5 Jobs pro Sekunde). Queue Depth ist die Anzahl wartender Jobs; Backlog Age sagt, wie lange der älteste Job wartet. Mehr Parallelität bei einem datenbankseitigen Engpass verschlechtert die Lage oft zunächst.
What usually breaks first in the database during a worker spike?
Meistens bricht zuerst der Connection Pool: Worker und Web-Anfragen konkurrieren um eine begrenzte Anzahl Verbindungen. Danach führen lange Transaktionen und Sperren dazu, dass Arbeit effektiv seriell wird – mehr Worker bedeuten dann nur längere Wartezeiten.
Why is it dangerous to call external APIs inside a DB transaction?
Halte Transaktionen kurz und vermeide Netzwerkaufrufe innerhalb einer offenen Transaktion. Ruft ein Job während einer Transaktion externe APIs auf, blockiert er Datenbankverbindungen und Sperren, und eine kleine Netzwerklatenz wird durch parallele Worker zum großen Ausfallmultiplikator.
How do I choose a safe worker concurrency limit without guessing?
Berechne zuerst deinen Verbindungs-Budget: reserviere die Mehrheit der DB-Verbindungen für Web-Traffic und unbekannte Arbeit, und nutze den Rest als Gesamtbudget für Worker. Beginne mit niedriger Parallelität pro Queue und erhöhe nur, wenn DB-Latenz und Sperrzeiten stabil bleiben.
Should I use one queue for everything or separate queues?
Trenne Jobs nach Einfluss und DB-Kosten, damit Bulk-Arbeit kritische Aufgaben nicht verhungern lässt. Schwere Queues bekommen niedrigere Concurrency; für bekannte "DB-Buller" wie Exporte oder Backfills gelten strengere Limits oder per-Job Caps.
How should I cap queue depth, and what should happen when it’s full?
Setze eine harte Obergrenze und entscheide, was passiert, wenn sie erreicht ist: verzögern, Produzenten pausieren oder neue Bulk-Aufträge mit einer klaren Fehlermeldung ablehnen. Eine Tiefe-Grenze verhindert unbegrenzte Anhäufungen und zwingt zu planbarem Umgang mit Überlast.
How do I prevent retries from creating a second spike?
Verwende Jitter und exponentielles Backoff mit einem harten Maximalfenster für Retries, besonders bei DB-Timeouts. Ohne Jitter starten viele Jobs gleichzeitig neu und erzeugen einen Retry-Sturm, der einen kurzen Ausfall in einen zweiten Ausfall verwandelt.
What metrics tell me if my limits are working, and what do I change next?
Beobachte DB-Verbindungen und Pool-Wartezeiten, p95-Abfragezeiten, Sperrwarten/Deadlocks und die Backlog-Age der Worker zusammen mit Retry-Raten. Wenn das Senken der Concurrency die DB-Metriken schnell stabilisiert und Job-Laufzeiten verbessert, waren die Limits zu hoch; wenn nicht, müssen Abfragen oder Indizes optimiert werden.