Pfad‑Traversal in Download‑Endpunkten: erkennen und beheben
Pfad‑Traversal in Download‑Endpunkten kann private Dateien offenlegen. Erfahren Sie sichere Dateinamen‑Verarbeitung mit Zulassungslisten, kanonischen Pfaden und Speicher‑Zugriffssteuerungen.
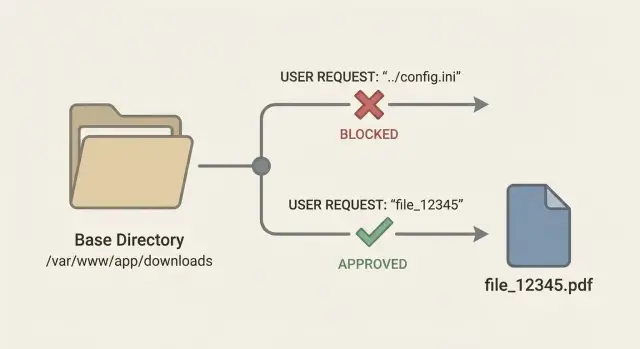
Warum Download‑Endpunkte leicht schiefgehen
Ein Download‑Endpoint sollte eine einfache Aufgabe haben: wenn ein angemeldeter Nutzer auf „Download“ klickt, findet der Server die richtige Datei und schickt sie zurück (mit dem richtigen Dateinamen und Content‑Type).
In der Praxis ist der Schritt „Datei finden“ der Punkt, an dem oft Fehler passieren. Der häufigste Fehler ist, Benutzereingaben wie einen sicheren Dateinamen zu behandeln. Ein Entwickler nimmt etwas wie ?file=invoice.pdf und hängt es an einen Ordnerpfad — in der Annahme, der Nutzer würde nur seine eigenen Dateien anfragen. Angreifer denken nicht in Dateinamen. Sie denken in Pfaden.
Das ist das Kernrisiko bei Pfad‑Traversal in Download‑Endpunkten: ein Angreifer versucht zu kontrollieren, wo der Server liest, nicht nur welches Dokument er bekommt. Wenn Ihr Code einen Pfad aus untrusted Input baut, kann eine Anfrage aus dem vorgesehenen Ordner hinauswandern und in sensible Bereiche gelangen.
Dann kann der Schaden weit über „jemand lädt die falsche Rechnung“ hinausgehen. Ein Angreifer kann Konfigurationsdateien lesen, die Datenbankzugänge oder API‑Keys enthalten, Quellcode (nützlich, um weitere Bugs zu finden), private Uploads und Exporte oder andere Serverdateien, die ihm helfen, Ihre Umgebung zu kartieren.
Download‑Endpunkte sind auch deshalb leicht fehleranfällig, weil sie harmlos erscheinen. Sie werden oft spät geliefert, weniger geprüft und „funktionieren“ in einfachen Tests. Der Bug zeigt sich erst, wenn jemand seltsame Eingaben, kodierte Pfade oder unerwartete Separatoren sendet.
Wie sich Pfad‑Traversal in realen Requests zeigt
Ein Download‑Endpoint nimmt üblicherweise etwas aus der Anfrage und macht daraus einen Dateipfad. Der Fehler tritt auf, wenn der Server dieser Eingabe vertraut. Wenn der Code so etwas macht wie baseDir + "/" + filename, kann ein Angreifer die Bedeutung von „filename“ ändern.
Von außen fragt eine normale Anfrage report.pdf an. Ein Angreifer probiert Nutzlasten, die Verzeichnisse nach oben laufen lassen oder auf ein anderes Laufwerk springen.
Gängige Payload‑Formen sind:
../secrets.envoder../../../../etc/passwd..\\..\\Windows\\System32\\drivers\\etc\\hosts/etc/passwd(absoluter Pfad unter Linux)C:\\Windows\\win.ini(absoluter Pfad unter Windows)- Gemischte Separatoren wie
..\\../..\\config.yml
Kodierung macht das im Log schwerer zu erkennen. Viele Apps decodieren URL‑Parameter bevor sie validieren, was bedeutet, dass ein blockierter String nach der Decodierung wieder auftauchen kann. Angreifer probieren oft %2e%2e%2f (wird zu ../) oder Double‑Encoding wie %252e%252e%252f (zweimal decodiert von manchen Stacks). Sie mischen auch Groß-/Kleinschreibung und Separatoren, zum Beispiel %2E%2E%5C um ..\\ zu bekommen.
Ein realistisches Szenario: Ihr Endpoint ist GET /download?file=invoice-123.pdf. Wenn der Handler diesen Wert direkt verwendet, versucht der Angreifer file=..%2f..%2f.env oder file=..\\..\\appsettings.json. Existiert die Datei und kann Ihr Prozess sie lesen, kann der Server sie als „Download“ zurückgeben, ohne offensichtlichen Fehler.
Plattformunterschiede sind gerade genug relevant, um gefährlich zu sein. Linux nutzt typischerweise / und ist case‑sensitive. Windows akzeptiert \\ und oft auch /, unterstützt Laufwerksbuchstaben und hat Gerätedateinamen wie CON und NUL. Wenn Ihre Validierung nur in einem OS‑Stil denkt, kann sie den anderen Stil im Betrieb oder bei Angriffsversuchen übersehen.
Schnellkriterien, um unsichere Dateinamensbehandlung zu erkennen
Die meisten Pfad‑Traversal‑Fälle in Download‑Endpunkten beginnen mit einem Fehler: die Anfrage darf entscheiden, welchen Pfad Sie von der Festplatte lesen. Sie können das oft schnell erkennen, indem Sie nachverfolgen, wo die Download‑Route ihre Eingabe bekommt und wo diese Eingabe verwendet wird.
Risikofaktoren sehen typischerweise so aus:
- Ein Query‑Param wie
file,path,nameoderdownloadwird gelesen und anopen(),readFile(),sendFile()oder einen Path‑Join übergeben. - Der Server vertraut einem Header (z. B.
X-File,Content-Dispositionoder sogarReferer) zur Auswahl der auszuliefernden Datei. - „Sanitizing“ wird mit String‑Tricks wie
replace("../", "")oder dem Abschneiden von Punkten gemacht, statt einen sicheren Basisordner zu erzwingen. - Der Endpoint baut einen Pfad aus Benutzereingabe und Basisordner, prüft aber nie, wo er nach Normalisierung tatsächlich landet.
- Downloads kommen direkt vom App‑Server‑Filesystem, obwohl Dateien auch anders gespeichert werden könnten (Object Storage, Blob‑Felder in der DB oder ein Upload‑Service).
Sie können einen Verdacht mit ein paar sicheren Tests in einer Dev‑Umgebung bestätigen. Akzeptiert ein Download‑Endpoint einen Dateinamen, probieren Sie Werte, die niemals funktionieren sollten: ../.env, ../../etc/passwd, ..\\..\\windows\\win.ini oder URL‑kodierte Varianten wie %2e%2e%2f. Selbst wenn die Antwort ein Fehler ist, achten Sie auf Hinweise in Logs (aufgelöste Pfade, Stacktraces oder Fehlermeldungen, die reale Verzeichnisse nennen).
Ein häufiges „sieht sicher aus, ist es aber nicht“-Muster: Der Code prüft, ob die Eingabe auf .pdf endet und öffnet dann die Datei. Angreifer können Kodierungstricks, doppelte Erweiterungen oder andere Randfälle nutzen, um naive Prüfungen zu umgehen. Auch wenn manche älteren Null‑Byte‑Beispiele für Ihren Stack nicht mehr gelten, bleibt die Lektion: Suffix‑Checks sind keine Grenze.
Sichere Variante: Datei‑IDs und serverseitige Zuordnung
Der einfachste Weg, Pfad‑Traversal in Download‑Endpunkten zu vermeiden, ist aufzuhören, Dateinamen aus der URL zu akzeptieren. Dateinamen sind kompliziert. Sie können Slashes, Backslashes, ..‑Sequenzen und Kodierungen enthalten, die ihre Bedeutung ändern, sobald Ihr Server Strings zu Pfaden verbindet.
Ein sichereres Muster ist, eine stabile Datei‑ID zu verwenden, z. B. GET /download/7f3a2c, und den realen Speicherort serverseitig zu verwalten. Die ID ist nur ein Zeiger. Ihre App entscheidet, auf welche Datei sie verweist.
Wenn eine Anfrage kommt, schlagen Sie die Datei in einer Datenbanktabelle (oder einem anderen vertrauenswürdigen Speicher) anhand dieser ID nach. Speichern Sie Metadaten, die Ihnen eine sichere Entscheidung erlauben: Eigentümer, Storage‑Key, erwarteter Content‑Type und ob die Datei noch gültig ist.
Ein einfacher Ablauf:
- Akzeptieren Sie nur eine opaque ID (UUID, zufälliger Token, Datenbank‑ID).
- Holen Sie Dateimetadaten per ID (Owner, Org, Storage‑Key, Content‑Type).
- Prüfen Sie, ob der aktuelle Nutzer Zugriff auf diesen Datensatz hat.
- Laden Sie die Datei über den vertrauenswürdigen Storage‑Key, nicht über Benutzereingaben.
- Setzen Sie Response‑Header aus gespeicherten Metadaten, nicht aus der Anfrage.
Beispiel: Ein Kunde klickt „Invoice herunterladen“ und Ihre UI ruft /download/inv_12345 auf. Ihr Server prüft, dass inv_12345 zum Kundenkonto gehört und liest dann storage_key=accounts/889/invoices/2025-01.pdf. Der Nutzer kann nie ../../etc/passwd senden, weil es keinen Dateinamen‑Parameter gibt, den er angreifen könnte.
Das macht Audits auch einfacher. Sie können eine einzige Autorisierungsprüfung rund um die Lookup‑Logik überprüfen, anstatt zu versuchen, jede mögliche Dateinamenvariante sicher zu machen.
Allowlists, die tatsächlich helfen (und was zu vermeiden ist)
Eine Allowlist hilft nur, wenn sie Downloads auf Dinge beschränkt, die Sie bereits als sicher kennen. Für Downloads bedeutet das in der Regel entweder (1) eine Liste bekannter, von Ihnen erzeugter Objekt‑Keys oder (2) eine kurze Liste von Dateitypen, die Sie wirklich unterstützen.
Die sicherste Allowlist ist die exakte gespeicherte Key‑Liste, nicht ein vom Benutzer übergebener Dateiname. Der Nutzer sendet eine ID wie fileId=8f3c..., Ihr Server holt den gespeicherten Datensatz (Eigentümer, Bucket‑Pfad, exakter Objekt‑Key) und liefert diesen aus. Der Nutzer beeinflusst den Pfad nie.
Wenn Sie unbedingt Dateinamen akzeptieren müssen, behandeln Sie Extensions‑Allowlists als Backup, nicht als Hauptkontrolle. Validieren Sie eine kurze Menge (z. B. pdf, csv) und lehnen Sie alles andere ab. „Bereinigen“ ist riskanter als konsequentes Ablehnen.
Bevor Sie validieren, normalisieren Sie, damit Angreifer nicht an Checks vorbeischlüpfen. Halten Sie es langweilig und konsistent: Trimmen Sie Whitespace, normalisieren Sie Groß-/Kleinschreibung wenn passend, und lehnen Sie Pfadseparatoren (/ und \\) sowie Sequenzen wie .. ab. Achten Sie auch auf trickreiche Namen wie invoice.pdf.exe oder report.pdf .
Was zu vermeiden ist: Blacklists (sie übersehen Varianten), endsWith‑Prüfungen auf rohem Input, und Allowlists, die trotzdem Verzeichnisanteile erlauben.
Kanonische Pfade: eine Basisverzeichnis‑Grenze durchsetzen
Die sicherste Regel für Downloads ist einfach: der Nutzer darf niemals einen Dateisystempfad wählen. Wenn Sie etwas wie einen Dateinamen akzeptieren müssen, wandeln Sie ihn in einen kanonischen Pfad um und beweisen Sie dann, dass er immer noch in einem zugelassenen Ordner (z. B. downloads_root) liegt. Das schließt den klassischen ../‑Trick.
Kanonisieren heißt, den echten Pfad zu ermitteln, den das OS verwenden wird. Er muss . und .. zusammenfassen, Separatoren normalisieren und — falls Ihre Plattform das unterstützt — Symlinks auflösen. Symlinks sind wichtig, weil ein harmlos aussehender Pfad innerhalb Ihres Download‑Ordners nach außen zeigen kann.
Ein praktisches Muster sieht so aus:
base = realpath(downloads_root)
requested = realpath(join(downloads_root, user_input))
if requested is null -> error
if not requested starts_with base + separator -> error
serve requested
Bevor Sie kanonisieren, lehnen Sie offensichtlich gefährliche Eingaben ab. Das reduziert Randfälle und macht Logging einfacher. Übliche Ablehnungen sind absolute Pfade (/etc/passwd, C:\\Windows\\...) und Eingaben, die Pfadseparatoren enthalten, wenn Sie nur einen einfachen Dateinamen erwarten.
Regeln, die sich bewährt haben:
- Akzeptieren Sie nur relative Eingaben (kein führendes
/, keine Laufwerksbuchstaben). - Bauen Sie Pfade mit sicheren Join‑Funktionen, nie per String‑Konkatenation.
- Kanonisieren Sie zu einem realen Pfad und prüfen Sie, dass er unter
downloads_rootbleibt. - Wenn die Kanonisierung fehlschlägt, behandeln Sie das als Blockierung, nicht als „versuchen Sie es nochmal“.
Geben Sie schließlich für „nicht gefunden“ und „blockiert“ dieselbe generische Fehlermeldung zurück. Unterschiedliche Meldungen erlauben Angreifern, herauszufinden, welche Dateien auf Ihrem Server existieren, selbst wenn sie sie nicht herunterladen können.
Speicherebene‑Zugriffssteuerungen, die den Blast‑Radius verringern
Selbst bei guter Eingabevalidierung behandeln Sie Download‑Endpoints als hohes Risiko. Wenn Traversal durchrutscht, entscheidet die Speicherwahl, ob der Angreifer eine Datei oder die ganze Maschine bekommt.
Vermeiden Sie es, Benutzerdateien vom gleichen Datenträger wie Ihren App‑Container auszuliefern. Wenn Uploads und App‑Code ein Dateisystem teilen, kann ein einziger Bug Konfigurationsdateien, Keys und Quellcode offenlegen. Lagern Sie Dateien außerhalb des Web‑Roots und deaktivieren Sie das direkte statische Ausliefern für dieses Verzeichnis, sodass nur Ihre Anwendung die Dateien lesen und zurückgeben kann.
Für viele Teams ist Object Storage der einfachste Weg, das Risiko zu reduzieren. Statt lokale Pfade zu lesen, speichern Sie Dateien als Objekte und erzwingen Zugriff per Objekt‑Berechtigungen oder kurzlebigen signierten Zugängen. Ihre App prüft, wer der Nutzer ist und welche Datei‑ID angefragt wurde; erst dann generiert sie ein zeitlich begrenztes Download‑Token oder proxyt die Datei.
Kontrollen, die sich schnell auszahlen:
- Halten Sie Buckets standardmäßig privat.
- Bevorzugen Sie kurzlebige signierte Zugriffe statt dauerhaften öffentlichen URLs.
- Wenn Sie lokalen Speicher verwenden müssen, legen Sie Dateien außerhalb des Web‑Roots ab.
- Führen Sie die App mit minimalen Filesystem‑Rechten (nur Lesen, wo nötig).
- Trennen Sie Umgebungen und Buckets (Dev vs Prod).
Logging ist genauso wichtig wie Blocken. Protokollieren Sie für jede Download‑Anfrage die Nutzer‑ID, Datei‑ID und die Entscheidung (erlaubt oder blockiert) plus einen Grundcode wie „not owner“ oder „expired token“. Dieses Audit‑Trail hilft, Scans zu erkennen und zu dokumentieren, was passiert ist.
Häufige Fehler und Bypässe, die Angreifer nutzen
Die meisten Pfad‑Traversal‑Fixes scheitern, weil der Code davon ausgeht, der Angreifer würde ein einfaches ../ senden. Reale Angriffe sind gestaffelt und so entworfen, dass sie genau an der Stelle vorbeischlüpfen, an der Sie geglaubt haben, abgesichert zu sein.
Ein klassischer Fehler ist, Client‑Seiten‑Regeln oder versteckte Formularfelder zu vertrauen. Wenn Ihre UI nur eine Auswahl aus einem Dropdown erlaubt, der Server aber trotzdem einen path‑Parameter akzeptiert, kann ein Angreifer diesen Wert in der Anfrage ändern. Der Server muss so handeln, als gäbe es die UI nicht.
Kodierungs‑Tricks sind ein weiterer häufiger Bypass. Teams decodieren einmal, validieren und später decodiert ein Framework oder Proxy erneut. Das kann aus einem harmlosen String nach der Validierung wieder ../ machen. Die Lösung ist Konsistenz: Normalisieren und validieren Sie an einer Stelle, und stellen Sie sicher, dass genau der Wert geöffnet wird, den Sie validiert haben.
Extension‑Checks lassen sich leicht austricksen. Nur .pdf zu erlauben klingt sicher, aber Angreifer können in sensible Ordner traversen und Dateien herunterladen, die zufällig auf .pdf enden, oder zusätzliche Segmente ausnutzen, wenn Ihre Pfadbehandlung schlampig ist. Wenn das Ziel ist, nur Rechnungen auszuliefern, sollte der Pfad nicht vom Nutzer steuerbar sein.
Häufige Bypässe:
- Vertraute, client‑generierte oder versteckte Dateipfade
- Decodierung auf verschiedenen Ebenen (App, Framework, Proxy)
- „Erlaube .pdf nur“‑Checks, die Verzeichnisse und Segmente ignorieren
- Symlinks im erlaubten Ordner, die nach außen zeigen
- Zip‑Slip: Ein Archiv enthält
../‑Pfade und extrahiert Dateien außerhalb des Zielordners
Symlinks verdienen besondere Aufmerksamkeit. Selbst wenn Sie einen Basisordner mit einem Dateinamen joingen, kann ein innerhalb dieses Basisordners platzierter Symlink die Grenze überspringen. Die zuverlässige Lösung sind kanonische Pfadprüfungen (nach Auflösen von Symlinks) und strikte Filesystem‑Berechtigungen.
Kurze Checkliste vor dem Ausliefern einer Download‑Funktion
Download‑Endpoints wirken einfach, sind aber eine häufige Ursache für Traversal in Produktion. Ein paar kleine Entscheidungen (wie das Akzeptieren eines Dateinamens aus der URL) können einen normalen Rechnungsdownload in „lies jede Datei auf dem Server“ verwandeln.
Die sicherste Standardmethode
Entscheiden Sie zuerst, welche Dateien ein Nutzer anfragen darf. Nutzer sollten per ID anfragen, nicht per Pfad, den sie formen können.
- Eingabe: akzeptieren Sie nur eine Datei‑ID (oder Rechnungsnummer), niemals einen rohen Pfad oder Dateinamen.
- Lookup: mappen Sie die ID auf einen gespeicherten Datensatz, der den realen Storage‑Key oder absoluten Serverpfad enthält.
- Validierung: wenn Sie Namen handhaben müssen, verwenden Sie eine enge Allowlist (erwartete Endungen, erwartete Zeichen), dann kanonisieren und bestätigen Sie, dass das Ergebnis im Basisverzeichnis bleibt.
- Autorisierung: prüfen Sie Eigentum und Rolle, bevor Sie die Datei lesen, nicht danach.
- Response: setzen Sie sichere Header und vermeiden Sie, die Benutzereingabe ungeprüft in
Content-Dispositionzu spiegeln.
Blast‑Radius mit Speicher und Tests reduzieren
Privat‑by‑default Speicher rettet Sie, wenn Code einen Fehler macht. Halten Sie herunterladbare Dateien außerhalb des Web‑Roots und vermeiden Sie öffentliche Buckets, in denen das Erraten eines Namens ausreicht.
Ein einfacher praktischer Test: versuchen Sie, ../‑Sequenzen, URL‑kodierte Varianten und zusätzliche Slashes gegen Ihre Download‑Route. Blockierte Versuche sollten geloggt werden (Nutzer‑ID, angefragte ID, Grund), aber keine Secrets enthalten.
Beispiel‑Szenario: Rechnungs‑Downloads, die Serverdateien freigeben
Ein Gründer liefert schnell ein Rechnungsfeature: Kunden klicken auf einen Button und die App ruft /download?filename=invoice-1042.pdf auf. Der Server nimmt filename, baut einen Pfad, liest die Datei und gibt sie zurück.
In Tests funktioniert das, weil alle normale Dateien anfragen. Das Problem ist, der Server vertraut der Benutzereingabe, um eine Datei auszuwählen. Ein Angreifer kann den Parameter zu ../../.env oder ../../../etc/passwd ändern. Wenn der Code Strings zusammenfügt (oder URL‑kodierte Werte decodiert und dann joingt), kann die App Dateien außerhalb des Rechnungsordners lesen.
Ein Plan, um das Feature zu behalten, aber das Risiko zu entfernen:
- Wechseln Sie von Dateinamen zu Datei‑IDs (z. B.
/download?id=inv_1042) und schlagen Sie den realen Pfad serverseitig nach. - Erzwingen Sie Auth‑ und Eigentumsprüfungen, sodass nur der richtige Kunde seine Rechnung herunterladen kann.
- Speichern Sie Rechnungen in privatem Speicher (nicht einem öffentlichen Ordner) und liefern Sie sie über kontrollierte Downloads aus.
- Fügen Sie einfache Allowlists hinzu: nur bekannte Rechnungsformate (z. B. PDF) erlauben und alles andere ablehnen.
- Loggen Sie abgewiesene Anfragen, damit Sie Scan‑Versuche früh sehen.
Zum Bestätigen, dass es gefixt ist, verlassen Sie sich nicht auf „scheint ok zu sein“:
- Versuchen Sie
../‑Payloads und vergewissern Sie sich, dass Sie immer einen generischen Fehler zurückgeben. - Prüfen Sie die Logs, um sicherzustellen, dass Traversal‑Muster blockiert und aufgezeichnet werden.
- Fügen Sie einen automatisierten Test hinzu, der
../../.envanfragt und eine Verweigerung erwartet.
Nächste Schritte: auditieren Sie Ihre Endpunkte und beheben Sie Probleme schnell
Gehen Sie davon aus, dass Sie mehr als einen „Download“‑Pfad haben. In vielen Apps werden Dateien an mehreren Stellen ausgeliefert: eine Rechnungsroute, ein Exporte‑Endpoint, eine Attachment‑Vorschau und manchmal ein Debug‑Hilfswerkzeug, das versehentlich mitgeliefert wird.
Ein praktisches Audit:
- Listen Sie jeden Endpoint auf, der eine Datei zurückgibt (Download, Export, Report, Image, Attachment, Backup).
- Verfolgen Sie, wo jeder seine Dateinamen oder Pfade herbekommt (Query, Route‑Param, JSON‑Body, Header, Datenbank).
- Schreiben Sie alle Speicherorte auf (lokale Verzeichnisse, Temp‑Ordner, Netzlaufwerke, Object‑Storage‑Buckets).
- Suchen Sie nach Pfadaufbau und Dateioperationen (
join,resolve,open,readFile,sendFile, Zip‑Erstellung). - Prüfen Sie Access‑Checks: wer darf welche Datei anfragen und wie wird das Mapping durchgesetzt?
Wenn Sie den Angriffsflächenbereich kennen, machen Sie einen gezielten Remediation‑Durchlauf. Bevorzugen Sie Datei‑IDs mit serverseitigem Lookup (ID -> gespeicherter Pfad) statt die Benutzereingabe Dateisystempfade beeinflussen zu lassen. Fügen Sie kanonische Pfadvalidierung hinzu, um eine einzige Basisverzeichnis‑Grenze für alle verbliebenen Disk‑Zugriffe durchzusetzen, und nutzen Sie eine enge Allowlist nur für wirklich statische Dateien.
Beenden Sie mit Tests, die beweisen, dass die Fixes bleiben:
- Anfragen mit
../und URL‑kodierten Varianten werden abgelehnt. - Absolute Pfade (Unix und Windows) werden abgelehnt.
- Symlink‑Randfälle können das Basisverzeichnis nicht verlassen.
- Nur Dateien, die dem aktuellen Nutzer oder der Organisation gehören, sind herunterladbar.
Wenn Sie einen AI‑generierten Codebestand geerbt haben, lohnt sich ein zweiter Blick auf file‑serving Routen. FixMyMess (fixmymess.ai) konzentriert sich darauf, AI‑generierte Apps zu diagnostizieren und zu reparieren — ein kurzes Audit kann Probleme wie unsichere Download‑Handler, fehlerhafte Auth‑Checks, exponierte Secrets und riskante Speicher‑Muster aufdecken, bevor sie in Produktion gehen.
Häufige Fragen
Was ist Pfad‑Traversal in einem Download‑Endpoint?
Ein Download‑Endpoint wird gefährlich, wenn er benutzerkontrollierte Eingaben in einen Dateipfad auf der Festplatte umwandelt. Wenn Ihr Code etwa Basisordner + Benutzereingabe macht, kann ein Angreifer mit ../ oder kodierten Varianten versuchen, aus dem vorgesehenen Verzeichnis zu entkommen und andere Dateien zu lesen.
Was können Angreifer tatsächlich erreichen, wenn Pfad‑Traversal funktioniert?
Gelingt Pfad‑Traversal, kann ein Angreifer Konfigurationsdateien mit Geheimnissen, Quellcode, private Uploads, Exporte oder andere Serverdateien stehlen. Der eigentliche Schaden entsteht oft durch Folgeschritte, zum Beispiel durch Verwendung geleakter Zugangsdaten, um auf Datenbanken oder Drittdienste zuzugreifen.
Wie erkenne ich unsichere Dateinamensbehandlung schnell im Code?
Suchen Sie nach Routen, die file, path, name oder ähnliches aus Query, Route‑Param, JSON‑Body oder Header lesen und diesen Wert an Datei‑APIs wie open, readFile oder sendFile übergeben. String‑basierte „Sanitisierungen“ wie replace("../", "") sind ein Warnsignal — sie übersehen oft Kodierungen und Randfälle.
Warum behebt das Blockieren von "../" in einem Stringcheck das Problem nicht?
Weil Angreifer selten einfach ../ im Klartext senden. Sie nutzen URL‑Encoding, Double‑Encoding, gemischte Separatoren und plattformspezifische Pfade, sodass der gefährliche String erst nach Decodierung oder Normalisierung sichtbar wird.
Wie sollte ein sicherer Download‑Endpoint aussehen?
Am sichersten ist eine undurchsichtige Datei‑ID in der URL und eine serverseitige Zuordnung zum echten Speicherort oder Key. Der Nutzer fragt Datei 123 an, und die App entscheidet, wo diese Datei liegt und ob der aktuelle Nutzer Zugriff hat.
Reichen Allowlists für Dateiendungen wie „nur .pdf“ aus?
Nicht verlässlich. Ein Check wie „muss auf .pdf enden“ verhindert nicht Directory Traversal und stoppt nicht, dass jemand eine sensible PDF herunterlädt, die zufällig anderswo auf dem Server liegt. Verwenden Sie Extensions‑Prüfungen nur als kleine Zusatzkontrolle, nachdem die Kontrolle über Pfade entfernt wurde.
Was bedeutet "kanonischer Pfad" praktisch?
Lösen Sie den angeforderten Pfad in einen kanonischen (realen) Pfad auf und prüfen Sie dann, ob er noch innerhalb eines zugelassenen Basisverzeichnisses liegt. Entkommt der kanonisierte Pfad dieser Grenze, blockieren Sie den Zugriff und geben eine generische Fehlermeldung zurück, damit Angreifer nicht ausloten können, welche Dateien existieren.
Warum sind Unterschiede zwischen Windows und Linux bei der Validierung wichtig?
Weil es unterschiedliche Pfadformate sind, die eine einseitige Validierung umgehen können. Windows verwendet Backslashes, akzeptiert oft auch /, hat Laufwerksbuchstaben und spezielle Gerätedateinamen; Linux nutzt / und ist meist case‑sensitive. Prüfen Sie beide Stile, sonst übersehen Sie Umgehungen.
Wie verringern Speicherentscheidungen den Schaden, falls ein Fehler durchrutscht?
Vermeiden Sie es, herunterladbare Dateien auf demselben Dateisystem wie App‑Code und Secrets zu lagern. Nutzen Sie private Object‑Storage‑Buckets mit kurzlebigen Zugriffstokens oder ein Server‑Proxying‑Modell. Führen Sie die App mit minimalen Lese‑Rechten, damit ein Fehler nicht die ganze Maschine offenlegt.
Was sollte ich für Download‑Endpoints protokollieren und überwachen?
Protokollieren Sie Nutzer‑ID, Datei‑ID (oder angefragten Wert) und ob der Zugriff erlaubt oder blockiert wurde mit einem einfachen Grundcode. Protokollieren Sie nicht vollständige aufgelöste Pfade oder secret‑haltige Dateiinhalte. Wenn Sie vermuten, dass file‑serving Routen riskant sind, kann FixMyMess schnell prüfen und unsichere Handler, fehlerhafte Auth‑Checks und mögliche Secret‑Lecks aufdecken.