Readiness- und Liveness-Checks, die echte Ausfälle aufdecken
Lernen Sie, wie Sie Readiness- und Liveness-Checks gestalten, die Datenbank, Queue und kritische APIs prüfen, damit Ausfälle sichtbar werden, bevor Nutzer sie bemerken.
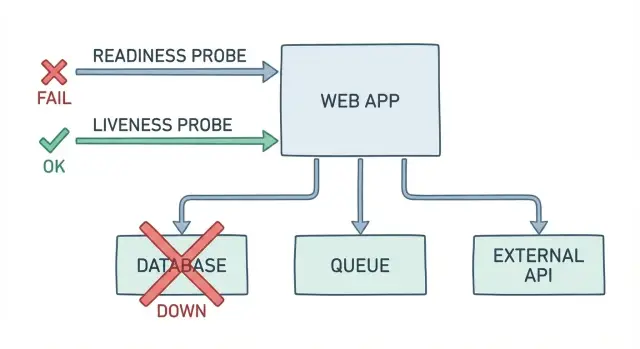
Warum “OK”-Health-Checks Nutzer trotzdem kaputtlassen
Ein einfacher /health-Endpunkt beantwortet normalerweise eine Frage: läuft der Prozess? Das ist nicht dasselbe wie: kann ein Nutzer sich jetzt einloggen, bezahlen oder seine Arbeit beenden. Wenn Ihr Health-Check „OK“ zurückgibt, während die App ihre eigentliche Aufgabe nicht erfüllt, bekommen Sie false‑green Alerts und einen langsameren, chaotischeren Incident.
So sieht das in der Praxis aus: der Pod ist hoch, die CPU sieht normal aus und der Health-Endpunkt sagt „OK“. Aber das Login schlägt fehl, weil die Datenbank während einer Migration gesperrt ist. Zahlungen schlagen fehl, weil ein Secret rotiert wurde und Credentials abgelaufen sind. Hintergrundjobs stauen sich, weil die Queue-Verbindung hängt, sodass Bestätigungen nie verschickt werden.
False‑green Checks kosten Zeit und Vertrauen. On‑Call jagt „sieht gut aus“-Signale hinterher. Support hört davon, bevor das Monitoring anschlägt. Nutzer versuchen es erneut, brechen ab und erinnern sich an den schlechten Tag.
Readiness- und Liveness-Checks sollten abbilden, was Nutzer brauchen, um erfolgreich zu sein. Ein guter Probe ist kein Vanity‑„OK“. Es ist ein kleiner, schneller Test des kritischen Pfads.
Eine abhängigkeitssensible Probe sollte Fragen wie diese beantworten:
- Können wir zur Datenbank verbinden und eine winzige Abfrage ausführen?
- Können wir uns bei der Queue authentifizieren und eine Nachricht veröffentlichen (oder zumindest die Verbindung prüfen)?
- Sind erforderliche Credentials gültig und nicht abgelaufen?
- Sind die wenigen externen Dienste, von denen wir wirklich abhängen, erreichbar?
Wenn Sie eine KI-generierte App geerbt haben, die „läuft“ aber in Produktion kaputtgeht (oft bei Auth, Secrets und Job-Queues), stoppen bessere Probes schlechte Deploys, bevor sie Nutzer stillschweigend verletzen.
Readiness vs Liveness in einfacher Sprache
Readiness beantwortet: kann diese spezifische Instanz jetzt sicher Traffic empfangen? Wenn die Antwort nein ist, sollte sie weiterlaufen, aber aus dem Rotation genommen werden, damit Nutzer nicht zu einer kaputten Kopie geleitet werden.
Liveness beantwortet: ist der Prozess lebendig und macht Fortschritt, oder steckt er so fest, dass ein Restart helfen würde? Wenn die Antwort nein ist, sollte die Plattform ihn neu starten.
Ein einfaches Readiness‑Beispiel: Ihre App bootet, aber die Datenbank ist down oder die Credentials sind falsch. Der Prozess läuft, aber jedes Login und jeder Seitenaufruf schlägt fehl. Eine gute Readiness‑Probe schlägt hier fehl, sodass Anfragen nicht mehr an diese Instanz gehen, bis die Datenbank wieder arbeitet.
Ein einfaches Liveness‑Beispiel: ein Bug verursacht einen Deadlock und die App reagiert nicht mehr, obwohl der Container noch läuft. Readiness könnte auch fehlschlagen, behebt aber nicht das Grundproblem. Eine Liveness‑Probe erkennt, dass die App keinen Fortschritt macht und löst einen Restart aus.
Eine Merkhilfe:
- Readiness schützt Nutzer vor schlechten Instanzen.
- Liveness hilft dem System, sich von festgefahrenen Instanzen zu erholen.
Diese Checks sind keine vollständigen End‑to‑End‑Tests. Sie sollten keine kompletten Nutzerflüsse nachspielen oder bei jedem Probeaufruf jede Abhängigkeit ansprechen. Halten Sie sie klein und auf die wenigen Dinge fokussiert, die für das sichere Bedienen von Traffic nötig sind.
Fangen Sie mit dem an, was für Nutzer funktionieren muss
Ein Health‑Check ist nur nützlich, wenn er mit dem übereinstimmt, was Nutzer tatsächlich tun. Bevor Sie Readiness- und Liveness‑Checks schreiben, notieren Sie die wenigen Aktionen, die „die App funktioniert“ für Ihr Produkt definieren. Wenn diese Aktionen fehlschlagen, sind Nutzer kaputt, auch wenn Ihr Endpoint 200 zurückgibt.
Halten Sie die Liste klein und realistisch: anmelden und das Dashboard laden, ein Projekt oder eine Bestellung anlegen, eine Datei hochladen und sie sehen, einen Job auslösen oder eine Nachricht senden, Checkout abschließen (wenn Sie Zahlungen haben).
Mappen Sie nun jede Aktion auf das, was sie braucht. „Projekt anlegen“ bedeutet meist, dass die Datenbank schreibbar ist und Migrationen angewendet sind. „Datei hochladen“ könnte Object Storage plus einen Background Worker brauchen, der sie verarbeitet. „Nachricht senden“ könnte von erreichbarer Queue und laufenden Konsumenten abhängen.
Wählen Sie aus dieser Map die minimalen Checks, die am besten repräsentieren, dass Nutzer den Pfad abschließen können. Ein Datenbank‑Ping reicht nicht, wenn Writes blockiert sind. Eine Queue‑Verbindung reicht nicht, wenn das Publish fehlschlägt. Zielen Sie auf ein bis zwei Checks pro kritischem Pfad, anhand der Abhängigkeiten, die am häufigsten das Erlebnis brechen.
Entscheiden Sie schließlich, was „degradiert aber nutzbar“ bedeutet. Können Nutzer browsen, aber nichts erstellen? Können sie sich einloggen, aber Uploads sind temporär deaktiviert? Treffen Sie diese Entscheidung bewusst, denn sie steuert das Readiness‑Verhalten (soll die App Traffic erhalten oder nicht).
Ein einfaches Szenario: Ihre App lädt, aber neue Projekte erscheinen nie, weil der Worker Jobs nicht in die Queue stellen kann. Ihr UI‑Health‑Endpoint sagt weiterhin „OK“. Eine Readiness‑Probe, die ein leichtgewichtiges Enqueue (oder Publish‑Check) einschließt, fängt den Fehler ab, den Nutzer spüren.
Was zu prüfen ist: DB, Queue und Ihre kritischen Abhängigkeiten
Ein nützlicher Health‑Endpoint sollte eine Frage beantworten: funktioniert eine echte Nutzeranfrage gerade? Das bedeutet, Readiness (und jede Abhängigkeits‑Health‑Endpoint, die Sie hinzufügen) muss die gleichen Abhängigkeiten berühren, die Ihre App braucht, um ihre Arbeit zu tun — nicht nur „OK“ zurückgeben, weil der Webserver läuft.
Datenbank
Starten Sie einfach und sicher. Prüfen Sie, dass Sie sich mit denselben Credentials verbinden können, die Ihre App nutzt, und führen Sie eine winzige read‑only Abfrage wie SELECT 1 aus. Das fängt kaputte Netzwerke, abgelaufene Passwörter und falsch konfigurierte Connection‑Strings. Halten Sie es schnell und sperren Sie keine Tabellen oder führen Sie keine Migrationen aus einem Probe‑Aufruf heraus.
Queue und Hintergrundarbeit
Wenn Ihre App auf Hintergrundjobs angewiesen ist, reicht die Prüfung der API allein nicht. Ihre Probe sollte bestätigen, dass Sie eine Testnachricht publizieren können (oder zumindest am Broker authentifizieren), und dass Worker tatsächlich konsumieren. Achten Sie außerdem auf ein wachsendes Backlog, denn eine Queue kann „up“ sein, während Arbeit effektiv steckt.
Ein praktisches Startset ist:
- DB‑Connect + eine leichte Abfrage
- Queue‑Publish (und idealerweise ein Consume‑Signal von einem Worker)
- Ein kritischer interner Service‑Call, ohne den der Betrieb nicht möglich ist
- Ein externer API‑Call, von dem Ihr Kernfluss abhängt
- Config‑Sanity: erforderliche Env‑Vars vorhanden und Secrets korrekt verdrahtet
Externe APIs verdienen besondere Aufmerksamkeit. Sie testen nicht das ganze Internet, aber Sie sollten wissen, ob Credentials ungültig sind, DNS kaputt ist oder Antworten stark verlangsamt wurden.
Ein konkretes Beispiel: ein Signup schreibt eine User‑Zeile und enqueued dann einen „Welcome‑Email“-Job. Wenn der DB‑Check passt, aber die Queue Nachrichten nicht annimmt, können Nutzer sich „registrieren“ und nie Verifizierungs‑E‑Mails erhalten. Eine Readiness‑Probe, die die Queue einschließt, blockiert Traffic, bis dieser Pfad funktioniert, statt stille Fehler zuzulassen.
Schritt‑für‑Schritt: Baue eine Readiness‑Probe, die Traffic blockiert
Eine Readiness‑Probe sollte beantworten: kann diese Instanz echte Nutzeranfragen jetzt bearbeiten? Wenn nicht, sollte sie fehlschlagen, damit neuer Traffic zurückgehalten wird.
1) Beweise das Minimum, das zählt
Beginnen Sie mit der kleinsten DB‑Operation, die trotzdem beweist, dass die App funktionieren kann. Eine TCP‑Verbindung allein reicht nicht. Bevorzugen Sie eine winzige Abfrage, die dieselben Credentials, Schema und Netzwerkpfade nutzt wie die App.
Ein gängiges Muster ist ein Endpoint wie /ready, der eine schnelle Abfrage ausführt und ein oder zwei kritische Abhängigkeiten prüft.
- Führen Sie eine leichte DB‑Abfrage aus (z. B.
SELECT 1) über die normale App‑Verbindung. - Setzen Sie strikte Timeouts (Hunderte von Millisekunden, nicht Sekunden), damit Fehler schnell sichtbar werden.
- Wenn die DB unerreichbar ist oder timeoutet, geben Sie „not ready“ zurück, damit der Load‑Balancer Traffic fernhält.
- Fügen Sie im Response‑Body einen menschenlesbaren Grund ein, aber niemals Secrets, Connection‑Strings oder vollständige Error‑Dumps.
- Geben Sie eine kurze Startup‑Grace‑Periode, damit Cold‑Starts nicht flappen, während die App warm wird.
2) Mach Fehler offensichtlich (aber sicher)
Geben Sie einen klaren Statuscode und eine kleine, sichere Payload zurück:
{ "ready": false, "reason": "db_timeout" }
Dieses reason‑Feld spart Zeit im Incident, weil es auf die fehlernde Abhängigkeit zeigt, ohne private Daten offenzulegen.
3) Verdrahten Sie es so, dass es tatsächlich Traffic blockiert
In Kubernetes‑Health‑Checks ist Readiness das, was steuert, ob ein Pod Traffic erhält. Stellen Sie sicher, dass Ihre App erst dann ready meldet, wenn sie die reale Operation abschließen kann.
Schritt‑für‑Schritt: Baue eine Liveness‑Probe, die Restarts auslöst
Eine Liveness‑Probe beantwortet: macht dieser Prozess noch Fortschritt, oder ist er festgefahren? Wenn er festhängt, ist ein Restart oft der schnellste Weg zurück für Nutzer.
- Wählen Sie ein „Fortschritts‑Signal“, das beweist, dass die App nicht wedged ist. Gute Signale sind lokal und einfach: ein interner Watchdog‑Timestamp, oder „Zeit seit letztem abgeschlossenen Request“.
- Halten Sie es leichtgewichtig und lokal. Eine Liveness‑Probe sollte nicht die Datenbank, Queue oder externe Dienste aufrufen. Netzwerkaussetzer würden sonst sinnlose Restarts verursachen.
- Fügen Sie Thresholds hinzu, um Restart‑Loops zu vermeiden. Prüfen Sie regelmäßig, aber erfordern Sie mehrere Fehler, bevor der Container als tot gilt. Auch hier eine Startup‑Grace‑Periode einplanen.
- Loggen Sie den Grund direkt bevor Sie failen. Schreiben Sie eine klare Zeile mit dem festgefahrenen Signal und einigen Schlüsselmesswerten (Pending‑Tasks, Busy‑Threads, Speicher).
- Testen Sie unter realer Last, nicht nur in Dev. Simulieren Sie hohe Last, langsame Downstream‑Calls und große Payloads. Viele Apps sehen bis zum Auffüllen der Thread‑Pools gut aus und stoppen dann zu reagieren.
Beispiel: ein Service akzeptiert HTTP‑Requests, aber alle Worker‑Threads hängen auf einem Deadlock. Requests blockieren, Nutzer sehen Lade‑Spinner und Readiness kann sogar grün bleiben. Eine Liveness‑Probe, die „Zeit seit letztem Request abgeschlossen“ beobachtet, erkennt das Einfrieren und löst einen Restart aus.
Gut gemacht arbeiten Readiness und Liveness zusammen: Readiness schützt Nutzer vor kaputten Abhängigkeiten, Liveness rettet Sie vor festgefahrenem Code.
Timeouts, Retries und Thresholds, die in Produktion gut verhalten
Health‑Probes sollten schnell und langweilig sein. Wenn eine Probe zu lange braucht, stauen sich Requests, Ihre App macht zusätzliche Arbeit und die Probe selbst kann zum Ausfall werden. Für die meisten Apps streben Sie ein kurzes Timeout an (oft 1–2 Sekunden) und eine kleine, fixe Menge Arbeit pro Probe.
Vermeiden Sie schwere Retries innerhalb der Probe. Retries können echte Fehler verbergen und bei bereits belasteten Systemen zusätzliche Last erzeugen. Wenn die Datenbank timeouts liefert, kann eine Probe, die dreimal retryt, manchmal noch Erfolg melden, trifft die DB aber auch während des schlimmsten Moments härter.
Einfache Thresholds, die Blips von Ausfällen trennen
Statt innerhalb der Probe zu retryen, nutzen Sie einfache Thresholds auf Orchestrator‑Ebene. In Kubernetes bedeutet das meist, ein paar Fehlschläge zu erlauben, bevor gehandelt wird.
Ein praktischer Startpunkt:
- Readiness timeout: 1–2s, failureThreshold: 2–3
- Liveness timeout: 1–2s, failureThreshold: 3–5
- periodSeconds: 5–10 (nicht jede Sekunde sondieren, es sei denn, es ist nötig)
- successThreshold: 1
Denken Sie daran: ein kleines Failure‑Budget — eine langsame Antwort sollte nicht sofort Chaos auslösen, aber wiederholte Fehler schon.
Unready vs. dead: Wählen Sie die am wenigsten störende Aktion
Readiness und Liveness sind nicht derselbe Hebel. Wenn eine Abhängigkeit down ist, ist es meist sicherer, die App unready zu markieren, damit sie keinen Traffic mehr bekommt. Neustarten behebt oft keine kaputte Datenbank oder Queue und kann die Erholung verlangsamen.
Verwenden Sie Readiness, um zu sagen: „Ich kann Nutzer gerade nicht korrekt bedienen.“ Verwenden Sie Liveness, um zu sagen: „Ich bin festgefahren und brauche einen Restart."
Häufige Fehler, die false‑greens (oder ständiges Flapping) erzeugen
Die meisten Health‑Checks scheitern aus zwei Gründen: sie sind zu oberflächlich (alles ist „OK“, während Nutzer sich nicht einloggen können), oder zu tief (sie schlagen bei normalen Aussetzern fehl und verursachen Restarts).
Ein klassisches false‑green ist ein Probe, das nur beweist, dass der Webserver läuft. Wenn Ihre App HTTP akzeptiert, aber nicht aus der Datenbank lesen kann, nicht in die Queue publiziert oder wichtige Config nicht laden kann, sind Nutzer trotzdem kaputt.
Die häufigsten Fehler:
- Einen End‑to‑End‑Flow als Liveness verwenden (Login + DB + Queue + externe API). Wenn irgendeine Abhängigkeit blipt, tötet der Orchestrator einen gesunden Prozess und verursacht selbstverschuldete Downtime.
- Readiness von instabilen Drittparteien abhängig machen. Wenn eine Payment‑ oder Email‑API 30 Sekunden langsam ist, können Sie zwischen ready und not‑ready flappen und Traffic verlieren. Bevorzugen Sie weichere Signale (gecachte last‑success, Circuit‑Breaker‑Zustand) statt bei jedem Fehler hart zu fehlschlagen.
- Raw Error Dumps loggen oder zurückgeben. Health‑Endpoints sind verlockende Orte für Stacktraces, Connection‑Strings und Tokens. Halten Sie Antworten minimal und gesäubert.
- „Ready“ sagen, bevor die App nutzbar ist. Häufige Ursachen: Migrationen laufen noch, Caches sind nicht warm, Worker nicht verbunden oder der Queue‑Consumer ist down.
- Timeouts und Thresholds ignorieren. Eine Probe ohne enge Timeouts kann Requests stauen. Eine Probe ohne Failure‑Threshold kann ständig oszillieren.
Halten Sie Liveness flach (ist der Prozess fest?) und Readiness ehrlich (kann er Nutzern sicher dienen?).
Mach Fehler sichtbar und handhabbar
Eine Probe, die still fehlschlägt, ist fast so schlecht wie eine, die immer OK zurückgibt. Wenn Readiness- oder Liveness‑Checks fehlschlagen, möchten Sie, dass ein Operator weiß, was kaputt ist, wie weit verbreitet es ist und was das System dagegen tut.
Loggen Sie Probe‑Fehler mit einem kurzen, stabilen Error‑Code. Halten Sie die Code‑Menge klein und konsistent, damit sie gesucht und grafisch dargestellt werden kann. Fügen Sie einen Satz Kontext hinzu und vermeiden Sie, bei jedem fehlgeschlagenen Probe Stacktraces zu spammen.
Nützliche Probe‑Ausgaben enthalten typischerweise einen stabilen Code (z. B. DB_CONN_TIMEOUT oder QUEUE_AUTH_FAILED), den Namen der Abhängigkeit plus die gescheiterte Operation (connect, query, publish, consume) und einen Basisstatus wie ready oder not-ready. Wenn Sie degraded verwenden, erklären Sie klar, was das bedeutet und welcher Traffic noch sicher ist.
Stellen Sie sicher, dass „not‑ready“ Zähne hat. Testen Sie es, indem Sie eine echte Abhängigkeitsstörung forcieren (z. B. Queue‑Credentials in Staging entziehen). Bestätigen Sie, dass die Instanz aus dem Traffic entfernt wird und keine Anfragen mehr erhält. Wenn Nutzer sie weiterhin erreichen, ist Ihr Readiness‑Signal nicht so mit dem Routing verbunden, wie Sie denken.
Seien Sie ebenso streng bei Restarts. Ein Liveness‑Fehler sollte nur dann Restarts auslösen, wenn der Prozess wirklich festhängt. Wenn ein temporärer DB‑Blip wiederholt Restarts verursacht, haben Sie ein Abhängigkeitsproblem in ein größeres Outage verwandelt.
Ein konkretes Beispiel: Sign‑ins schlagen fehl, weil die Datenbank erreichbar ist, aber Migrationen nicht angewendet wurden. Die App liefert HTTP 200 auf /health, und trotzdem werfen Logins Fehler. Eine bessere Readiness‑Probe würde not-ready mit MIGRATION_PENDING melden und kaputte Instanzen aus dem Verkehr halten.
Schnelle Checkliste, bevor Sie Health‑Checks in Produktion vertrauen
Bevor Sie sich auf Readiness und Liveness in Produktion verlassen, stellen Sie sicher, dass Ihre Probes aus denselben Gründen fehlschlagen wie echte Nutzer. Wenn eine Abhängigkeit down ist, sollte die Probe das schnell und klar melden.
Readiness sollte Traffic blockieren, wenn Kernabhängigkeiten brechen: unerreichbare DB, falsche Credentials oder eine einfache Abfrage, die timeoutet. Queue‑Checks sollten echten Nachrichtenfluss widerspiegeln, nicht nur „kann ich den Host erreichen“. Jede Probe braucht ein hartes Timeout. Fehlerantworten müssen sicher sein (Codes und kurze Reasons, keine Stacktraces oder Secrets). Und Deploys sollten nicht flappen — geben Sie eine Startup‑Grace‑Periode für Warm‑up‑Arbeit.
Ein Staging‑Test, den es wert ist
Simulieren Sie einen echten Ausfall: sperren Sie für ein paar Minuten den DB‑Zugriff oder stoppen Sie Ihre Queue‑Worker. Bestätigen Sie, dass Readiness schnell rot wird, Traffic stoppt und die App sauber wiederherstellt, wenn die Abhängigkeit zurückkommt.
Beispiel: Die App sieht gut aus, aber die Queue ist kaputt
Ein häufiger Ausfall sieht so aus: Nutzer können eine Bestellung aufgeben, Checkout gibt 200 zurück und Ihr „health“‑Endpoint antwortet „OK“. Aber Kunden erhalten niemals Bestellbestätigungen und der Support‑Pegel steigt.
Was ist passiert? Die Web‑App bedient immer noch Requests, aber der Nachrichtentransport zur Queue ist gebrochen. Vielleicht kann die App wegen falscher Credentials nicht publizieren. Vielleicht ist die Queue zwar up, aber so stark verbacklogged, dass Nachrichten erst in Stunden verarbeitet werden. Von außen sieht die App in Ordnung aus.
Hier zeigen Readiness und Liveness ihren Wert. Der alte Probe beweist nur eines: der Webserver kann antworten. Eine bessere Readiness‑Probe verhält sich mehr wie eine Abhängigkeits‑Health‑Probe und prüft, was für reale Nutzer wirklich funktionieren muss.
Eine einfache Readiness‑Probe für diesen Fall:
- Versuchen Sie ein leichtgewichtiges Queue‑Publish (oder eine permission‑only API‑Abfrage) mit kurzem Timeout.
- Optional: prüfen Sie Queue‑Lag (z. B. Alter der ältesten Nachricht) und failen Sie Readiness, wenn ein Schwellenwert überschritten ist.
- Geben Sie „not ready“ zurück, damit Traffic stoppt, bis der Queue‑Pfad wieder gesund ist.
Liveness ist anders. Wenn der Queue‑Worker festhängt (Deadlock, Memory Leak, Poisoned‑Message‑Loop), wollen Sie meist den Worker‑Prozess neu starten, während der Web‑Prozess weiterläuft. Das heißt oft separate Probes: Web‑Container live halten und Worker‑Container Liveness fehlschlagen lassen, wenn sie keinen Fortschritt mehr machen.
Behandeln Sie die Nacharbeit als Untersuchung, nicht als Raten. Loggen Sie den genauen Fehler (Publish‑Timeout, Auth‑Error, Backlog‑Spike), dann isolieren Sie die Ursache: Queue‑Service, Credentials, Network‑Policy oder Consumer‑Code.
Nächste Schritte: Probes verbessern, dann die Ursachen beheben
Wenn Ihre Health‑Endpoints existieren, ist der nächste Schritt, sie nützlich zu machen. Gute Readiness‑ und Liveness‑Checks melden nicht nur, dass der Prozess läuft. Sie fangen echte Ausfälle früh und halten kaputte Pods davon ab, Nutzer zu bedienen.
Notieren Sie, was ein Nutzer tun muss, um die Hauptaktion in Ihrer App abzuschließen (einloggen, bezahlen, hochladen, senden). Wählen Sie die drei wichtigsten Abhängigkeiten aus, die für diese Aktion gesund sein müssen. Für jede fügen Sie einen einzelnen Check hinzu, der beweist, dass die App sie tatsächlich nutzen kann, nicht nur, dass ein Hostname erreichbar ist.
Beheben Sie danach, was die Probes aufzeigen. Wenn Readiness fehlschlägt, weil DB‑Verbindungen leaken, macht die Probe ihren Job. Die Arbeit besteht darin, Verbindungen zu schließen, Pool‑Limits zu setzen, Timeouts zu handhaben und klare Fehler zu liefern. Wenn Queue‑Checks fehlschlagen, weil Nachrichten sich anhäufen, untersuchen Sie Konsumenten, Retry‑Logik und Dead‑Letter‑Handling.
Wenn Sie eine KI‑generierte Prototype geerbt haben, die in Basischecks „grün“ bleibt, aber unter realem Traffic kaputtgeht, hilft ein fokussiertes Audit. FixMyMess (fixmymess.ai) spezialisiert sich darauf, KI‑generierte Apps zu reparieren — kaputte Auth, exponierte Secrets und unzuverlässige Hintergrundjobs — oft beginnend mit einem kostenlosen Code‑Audit, das schnell zeigt, was in Produktion tatsächlich schiefgeht.
Häufige Fragen
Why does my /health endpoint say OK when users can’t log in or pay?
Ein grundlegender /health-Endpunkt beweist meist nur, dass der Web-Prozess eine Antwort zurückgibt. Nutzer können trotzdem blockiert sein, wenn die Datenbank gesperrt ist, Credentials abgelaufen sind, Migrationen ausstehen oder die Queue festhängt. Ein nützlicher Check sollte widerspiegeln, ob die App die minimale Arbeit erledigen kann, von der die Nutzer abhängen.
What’s the simplest way to explain readiness vs liveness?
Readiness bedeutet: „Soll diese Instanz gerade Traffic erhalten?“ — und sollte fehlschlagen, wenn wichtige Abhängigkeiten für echte Requests nicht nutzbar sind. Liveness bedeutet: „Ist der Prozess so festgefahren, dass ein Restart hilft?“ — und sollte nur fehlschlagen, wenn die App keine Fortschritte mehr macht, nicht bei kurzen Aussetzern einer Abhängigkeit.
What should a readiness check do for the database?
Beginnen Sie mit einer kleinen Operation, die den gleichen Pfad wie Ihre App nutzt, z. B. SELECT 1 über die normale Verbindung und mit striktem Timeout. Das fängt Netzwerkprobleme, falsche Credentials und viele DB-Ausfälle ab. Wenn Ihr Kern-Flow Schreibzugriffe benötigt, überlegen Sie eine sichere prüfbare Größe (z. B. Migrationen sind angewendet) statt nur Lesetests.
How do I include the queue in readiness without making probes heavy?
Wenn Ihre App auf Hintergrundjobs angewiesen ist, sollte die Readiness prüfen, ob die App Nachrichten in die Queue publizieren kann (oder wenigstens eine Berechtigungs-/Handshake-Prüfung durchführen) mit kurzem Timeout. Das ist oft der Grund, warum „alles hoch“ aussieht, aber Bestätigungen, E‑Mails oder asynchrone Verarbeitung heimlich fehlschlagen. Halten Sie den Check leichtgewichtig, damit er in Vorfällen keine zusätzliche Last erzeugt.
Should my liveness check call the database or external APIs?
Vermeiden Sie, dass Liveness externe Dienste aufruft, denn ein kurzer Ausfall eines Drittanbieters kann sonst zu Neustart-Schleifen führen und die Situation verschlimmern. Liveness sollte lokal sein: ein Watchdog-Timestamp, ein Event-Loop-Herzschlag oder „Zeit seit letztem abgeschlossenen Request“ reicht in der Regel. Verwenden Sie Readiness, um externe Abhängigkeiten zu reflektieren.
How should I set timeouts and retries for readiness and liveness probes?
Verwenden Sie enge Timeouts, damit Probes schnell fehlschlagen, und lassen Sie den Orchestrator kurzzeitige Störungen mit Failure-Thresholds behandeln. So reduzieren Sie Probe-Traffic während teilweiser Ausfälle und vermeiden, echte Probleme mit internen Retries zu kaschieren. Wenn eine Abhängigkeit langsam ist, ist es meist besser, schnell unready zu gehen, statt halbfunktionale Pods im Verkehr zu lassen.
How do I stop readiness checks from flapping when a third-party API is unstable?
Ein häufiger Fehler ist, Readiness an eine flakige Drittpartei zu knüpfen, was ständiges Flapping und Traffic-Verlust verursacht. Eine weitere ist, Probes zu schwer zu machen, sodass Health-Checks zu Mini-Lasttests werden. Konzentrieren Sie Readiness auf das, was unbedingt stimmen muss, und behandeln Sie optionale Integrationen lieber als "degraded" statt sofort nicht-ready.
What should my health endpoints return when something is wrong?
Geben Sie einen klaren Statuscode (häufig 503) und eine kurze, stabile Reason-String zurück, z. B. db_timeout oder queue_auth_failed. Loggen Sie denselben Code einmal pro Probe-Failure-Fenster, damit er suchbar ist, ohne die Logs zu fluten. Nie Stacktraces, Tokens, Connection-Strings oder rohe Exception-Dumps in den Probe-Antworten ausgeben.
Can my app be “degraded but usable,” and how should readiness handle that?
Ja, das ist möglich, wenn es die richtige Abwägung für Ihr Produkt ist. Sie können für read-only Browsing bereitbleiben und Erstell-Funktionen deaktivieren, müssen aber sicherstellen, dass die App dieselben Regeln durchsetzt, damit Nutzer nicht auf kaputte Pfade stoßen. Wenn Sie „sicher“ nicht zuverlässig trennen können, dann failen Sie Readiness und stoppen Traffic, bis der Kernpfad wieder funktioniert.
My app was generated by an AI tool and breaks in production—can you help?
KI-generierte Apps „laufen“ oft, aber scheitern bei Auth, Secrets, Migrationen und Background-Jobs — Dinge, die einfache Health-Checks nicht erfassen. FixMyMess konzentriert sich darauf, diese Produktionsprobleme zu diagnostizieren und zu reparieren, inklusive Härtung der Probes, damit fehlerhafte Deploys Nutzer nicht stillschweigend schädigen. Wenn Sie nicht wissen, wo Sie anfangen sollen, kann ein kostenloses Code-Audit schnell die tatsächlichen Fehlerpunkte zeigen.