Retry-Strategie für Hintergrundjobs: Backoff, Grenzwerte und Alerts
Retry-Strategie für Hintergrundjobs, die Fehler sichtbar macht: Backoff, maximale Versuche, Dead-Letter-Queue und Alerting hinzufügen, damit Jobs sicher wiederhergestellt werden können.
Warum „es lief nicht“ ein riskanter Weg ist, Fehler zu finden
Hintergrundjobs sind die kleinen Aufgaben, die Ihre App im Hintergrund ausführt, damit das Hauptprodukt schnell bleibt. Sie versenden E-Mails, importieren CSVs, synchronisieren Daten, verarbeiten Zahlungen und liefern Webhooks. Nutzer sehen den Job selten direkt. Sie bemerken nur das Ergebnis.
Deshalb sieht der häufigste Fehler so aus: Beim Test lief alles, dann hörte es in Produktion stillschweigend auf. Niemand sieht eine Fehlerseite. Nichts stürzt offensichtlich ab. Man merkt es erst Tage später, wenn ein Kunde sagt: „Ich habe die E-Mail nie bekommen“, oder ein Export fehlt.
Stille Fehler sind schlimmer als sichtbare Fehler, weil sie Vertrauen zerstören und die Ursache verbergen. Sichtbare Fehler erzwingen eine Reaktion. Stille erzeugen einen Rückstau gebrochener Versprechen: nicht gesendete E-Mails, nicht synchronisierte Daten, blockiertes Onboarding, nicht verarbeitete Rückerstattungen. Wenn Sie es schließlich bemerken, beheben Sie den Job und räumen das Chaos auf, das er hinterlassen hat.
Ein guter Retry-Plan ist nicht „immer wieder versuchen“. Er sollte vier Dinge tun:
- Von vorübergehenden Problemen erholen (Timeouts, kurzzeitige Ausfälle, Rate-Limits).
- Unter Last zurückfallen, damit Sie Ihre Datenbank oder eine externe API nicht zuschütten.
- Nach einer angemessenen Anzahl von Versuchen stoppen.
- Fehler sichtbar machen, damit ein Mensch eingreifen kann.
Wenn ein E-Mail-Provider ein temporäres 503 zurückgibt, ist spätere Wiederholung sinnvoll. Wenn der Job aber wegen einer falschen Template-Variable oder gebrochener Authentifizierung fehlschlägt, verbrennen Retries nur Zeit und Geld, während nichts repariert wird.
Das sieht man oft in AI-generierten Prototypen: Die App „funktioniert größtenteils“, dann scheitert die Hintergrundarbeit still, weil Secrets fehlen, die Fehlerbehandlung wackelig ist oder die Job-Logik verheddert ist. Der erste Schritt ist, Fehler laut, begrenzt und wiederherstellbar zu machen.
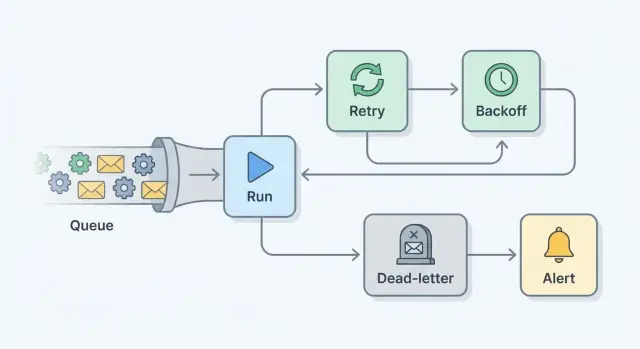
Kernbausteine: Retries, Backoff, Max-Versuche, Dead-Letter, Alerts
Ein Retry-Plan ist eine Reihe kleiner Schutzvorrichtungen, die stille Fehler in sichtbare, wiederherstellbare Arbeit verwandeln.
Ein Retry führt denselben Job nach einem Fehler erneut aus. Das hilft bei temporären Fehlern, z. B. bei einer instabilen Netzwerkverbindung.
Backoff ist die Pause zwischen Versuchen. Statt sofort erneut zu versuchen (und eine Herde von gleichzeitigen Anfragen zu erzeugen), warten Sie bei jedem Versuch länger, oft mit etwas Zufall.
Max-Versuche ist die harte Grenze. Nach N Versuchen hören Sie auf, damit ein fehlerhafter Job nicht ewig in einer Schleife läuft.
Eine Dead-Letter-Queue (DLQ) (oder eine Tabelle für fehlgeschlagene Jobs) ist der Ort, an den Jobs gehen, nachdem Sie aufgeben. Nichts geht verloren. Sie können prüfen, was passiert ist, die Ursache beheben und den Job gezielt erneut ausführen.
Alerting ist, wie Menschen davon erfahren. Ziel ist nicht, bei jedem Retry zu benachrichtigen. Es soll informieren, wenn etwas Aufmerksamkeit braucht, z. B. wenn ein Job die Max-Versuche erreicht oder die DLQ-Zahl zu steigen beginnt.
Eine Idee, die viel Schmerz spart: Idempotenz
Ein Job ist idempotent, wenn es sicher ist, ihn zweimal auszuführen.
„Rechungsstatus auf PAID setzen“ ist sicherer als „die Karte belasten“. Wenn Sie eine Aktion nicht vollständig idempotent machen können, fügen Sie eine Schutzmaßnahme hinzu: einen eindeutigen Schlüssel, ein "bereits verarbeitet"-Flag oder ein Idempotency-Token des Providers.
Transiente vs. permanente Fehler
Transiente Fehler lösen sich meist von selbst: Timeouts, kurzzeitige Ausfälle, gesperrte Zeilen. Permanente Fehler tun das nicht: fehlende Datensätze, ungültige E-Mail-Adressen, ein falscher API-Schlüssel.
Retries reduzieren Vorfälle, aber sie beseitigen nicht alle Fehler. Es geht darum, die Explosionsweite zu begrenzen, echte Probleme schnell sichtbar zu machen und Ihnen einen sicheren Ort (DLQ) zur Wiederherstellung zu geben.
Wissen, was Sie retryen: transiente vs. permanente Fehler
Ein Retry-Plan beginnt mit einer Entscheidung: Wird dieser Fehler wahrscheinlich von selbst verschwinden, oder bleibt er bestehen, bis jemand etwas ändert? Wenn Sie alles retryen, bekommen Sie laute Queues, höhere Kosten und Verzögerungen, die das echte Problem verbergen.
Transiente Fehler sind temporär. Mit Backoff erneut zu versuchen hilft meist, weil sich die Umgebung ändert: Netzwerk stabilisiert sich, der Service erholt sich, Sperren lösen sich oder das Rate-Limit-Window setzt zurück.
Permanente Fehler beheben sich nicht von selbst. Sie sind meist Datenprobleme, Berechtigungsfehler, fehlende Migrationen oder einfache Bugs. Retries verzögern nur die echte Lösung.
Falsche Zuordnung ist wichtig. Behandeln Sie einen permanenten Fehler als retrybar, und Sie können einen Rückstau erzeugen, der gesunde Arbeit blockiert. Zudem werden Vorfälle schwerer erkennbar, weil das System „beschäftigt“ statt „kaputt“ aussieht.
Eine einfache Regel: Retry nur, wenn Sie eine realistische Bedingung benennen können, die sich ohne menschliches Eingreifen ändern wird. Wenn der Job beim erneuten Ausführen in 1 bis 10 Minuten wahrscheinlich erfolgreich wäre, ist er retrybar. Wenn er morgen noch gleich fehlschlagen würde, stoppen Sie, senden Sie ihn in die DLQ und alarmieren Sie.
Backoff, das unter Last gut reagiert
Wenn ein Job fehlschlägt, ist das Schlimmste, was Sie tun können, sofort in einer engen Schleife erneut zu versuchen. Kommt der Fehler von einem partiellen Ausfall, einem Rate-Limit oder einer langsamen Datenbank, erhöhen sofortige Retries die Last genau dann, wenn das System bereits kämpft.
Exponential Backoff ist ein gesünderer Default: Jeder Retry wartet länger als der vorherige. Ein einfaches Muster kann 5 Sekunden, 15 Sekunden, 45 Sekunden, 2 Minuten und dann 5 Minuten sein.
Fügen Sie Jitter (etwas Zufall) zu jeder Verzögerung hinzu. Ohne Jitter werden Worker, die zusammen fehlgeschlagen sind, auch zusammen neu versuchen und erneut Spitzen erzeugen. Mit Jitter kann eine geplante 2-minütige Wartezeit zu 1:30–2:30 werden. Diese kleine Streuung macht Retries geschmeidiger.
Backoff sollte zum Job passen. Eine Passwort-Zurücksetzen-E-Mail und ein nächtlicher Bericht brauchen nicht dasselbe Timing. Als Ausgangspunkt können nutzernahe Jobs schnell mit einer kurzen Obergrenze retryen, während schwere Jobs und strikte externe APIs längere Kappen und bei jedem Versuch Jitter benötigen.
Max-Versuche und klare Stoppbedingungen festlegen
Unbegrenzte Retries fühlen sich sicher an, können aber einen Fehler in eine endlose Schleife verwandeln. Der Job läuft weiter, sammelt Queue-Zeit und API-Kosten und versteckt einen echten Bug, weil nichts jemals zum „endgültigen“ Fehler wird.
Es gibt auch ein praktisches Risiko: Wiederholte Retries können Schaden verursachen. Sie könnten dieselbe E-Mail mehrfach senden, Datensätze doppelt erstellen oder eine Karte erneut belasten, wenn der Job nicht idempotent ist.
Wählen Sie Max-Versuche nach Auswirkung. Hochriskante Aktionen wie Zahlungen sollten schnell fehlschlagen (oft 1–3 Versuche). Sichere Nutzerbenachrichtigungen können mehr Versuche erlauben. Für langsame Drittanbieter-APIs können mehr Versuche in Ordnung sein, solange das Backoff konservativ ist.
Fügen Sie außerdem ein Gesamtzeitlimit hinzu, nicht nur eine Zählung. Zum Beispiel: „Bis zu 5 Mal retryen, aber nach 2 Stunden stoppen.“ Das verhindert, dass ein Job sich über Tage hinzieht.
Wenn ein Job die Max-Versuche erreicht, behandeln Sie das als echtes Ereignis. Speichern Sie genug zum Debuggen und Replay: die letzte Fehlermeldung, Fehlerart, Zeitstempel der Versuche und die Payload (oder eine redigierte Version). Erfassen Sie externe IDs (user_id, order_id), die helfen, nachzuvollziehen, was betroffen war.
Verwenden Sie eine Dead-Letter-Queue, damit Fehler wiederherstellbar sind
Retries sind für temporäre Probleme. Manche Jobs werden nie erfolgreich sein, ohne dass etwas geändert wird. Eine DLQ ist der sichere Ort, um diese Jobs nach Erreichen der Max-Versuche abzulegen, damit sie nicht weiter Ressourcen verbrennen und menschlich sichtbar werden.
Denken Sie an die DLQ als ein „braucht Aufmerksamkeit“-Postfach. Statt Arbeit zu verlieren oder endlos zu schleifen, erfassen Sie genug Details, um zu diagnostizieren, zu reparieren und den Job bewusst erneut zu starten.
Was in einem Dead-Letter-Eintrag gespeichert werden sollte
Ein DLQ-Eintrag sollte zwei Fragen beantworten: Was wollte der Job tun und warum ist er fehlgeschlagen?
Halten Sie es klein, aber vollständig: Job-Name (und Version, falls vorhanden), Eingabe-Payload (oder ein Verweis, wenn sie groß ist), Fehlermeldung und Typ (plus Stacktrace, wenn verfügbar), Anzahl der Versuche mit Zeitstempeln und Korrelations-IDs (User ID, Order ID, Request ID), um es mit Logs zu verknüpfen.
Seien Sie vorsichtig mit Secrets. Wenn Payloads Tokens oder Passwörter enthalten können, redigieren Sie diese, bevor Sie sie speichern.
Wie man sicher wieder einreiht
Wieder-Einreihen sollte bewusst erfolgen, nicht automatisch in einer Schleife. Reparieren Sie zuerst die Ursache, dann starten Sie den Job über eine Admin-Oberfläche oder ein kleines Skript erneut.
Fügen Sie eine minimale Audit-Spur hinzu: Beim Requeue setzen Sie den Versuchszähler zurück und protokollieren, wer es getan hat und warum. Wenn die Eingabe niemals validieren wird, erlauben Sie das Markieren als „wird nicht erneut versucht“ mit einer kurzen Notiz.
Retention ist ebenfalls wichtig. Bewahren Sie DLQ-Items lange genug auf, um Muster zu erkennen und langsame Fixes zu bearbeiten, aber nicht so lange, dass sensible Daten unnötig verbleiben.
Alerting, das nützlich, nicht laut ist
Alerts sollten eine Frage schnell beantworten: „Was ist kaputt, wer ist betroffen und was soll ich als Nächstes tun?“ Wenn Fehler stundenlang verborgen bleiben, erfahren Sie davon nur vom Kunden.
Beginnen Sie mit Triggern, die echten Schmerz repräsentieren, nicht mit jedem einzelnen fehlgeschlagenen Versuch. Nützliche Signale sind wiederholte Fehler desselben Job-Typs, neue oder steigende DLQ-Meldungen, lange Queue-Zeiten (Jobs warten länger als Ihr Nutzer-Versprechen), plötzliche Durchsatz-Einbrüche und Fehlerspitzen für einen bestimmten Job.
Leiten Sie Alerts an diejenigen, die handeln können. In frühen Teams ist das oft die On-Call-Person oder der Gründer. Geben Sie genug Kontext, damit sie nicht 20 Minuten suchen müssen: Job-Name, Umgebung, erster Fehlerzeitpunkt, letzte Fehlermeldung, wie viele Jobs betroffen sind und ob Nachrichten die DLQ treffen.
Um Lärm zu vermeiden, nutzen Sie drei Kontrollen: Schwellenwerte (alert nach N Fehlern), Gruppierung (ein Alert pro Job-Typ pro Zeitfenster) und ein Cooldown-Fenster (nicht erneut alerten für 15 Minuten, außer es wird schlimmer).
Wenn Sie eskalieren müssen, halten Sie es einfach: Primären On-Call benachrichtigen, nach kurzer Verzögerung einen Backup, und wenn es weiter wächst, einen breiteren Kanal mit einer Impact-Übersicht.
Fehler sichtbar machen mit Logs und Grundmetriken
Ein Retry-Plan funktioniert nur, wenn Sie sehen können, was passiert. Sonst landen Sie beim gleichen Bericht: „der Job lief nicht.“ Das Ziel ist simpel: Jeder Versuch hinterlässt eine klare Spur, und ein paar Zahlen zeigen, ob es schlimmer wird.
Bei Logs bleiben Sie bei konsistenten Feldern, damit sich ein einzelner Fehler über Retries leicht nachverfolgen lässt. Jeder Versuch sollte eine Job-ID (oder Korrelations-ID), Versuchszahl, Start- und Endzeit und Ergebnis enthalten. Bei Fehlern loggen Sie eine Fehlerklasse (Timeout, Auth, Validation) plus eine kurze Nachricht. Es hilft auch, Queue- und Worker-Name einzubeziehen.
Logs sicher halten: Loggen Sie keine Tokens, Passwörter, API-Keys, vollständige Request-Header oder unmaskierte personenbezogene Daten. Nutzen Sie interne IDs oder maskierte Werte.
Bei Metriken brauchen Sie nicht viel, um Wert zu erhalten. Verfolgen Sie Erfolgsrate pro Job-Typ, Retries pro Job (Durchschnitt und p95), DLQ-Anzahl und -Rate sowie Zeit bis zum Erfolg (wie lange Jobs im Retry-Prozess verbringen).
Während eines Vorfalls sollte ein kleines Dashboard beantworten: Steigt die DLQ, treibt ein Job-Typ die meisten Retries an, und begannen Fehler zu einem bestimmten Zeitpunkt (Hinweis auf Deploy oder externen Ausfall)?
Beispiel: Ein E-Mail-Job, der fehlschlägt und dann sicher wiederhergestellt wird
Ein häufiger Job ist das Versenden einer Onboarding-E-Mail nach der Anmeldung. Wochenlang funktioniert alles, dann meldet der Support: „einige Nutzer haben die E-Mail nie bekommen.“ Wenn Sie nur nach „es lief nicht“ suchen, verpassen Sie die eigentliche Geschichte: Der Job lief, schlug fehl und verschwand.
Was passiert, wenn Fehler beginnen
Um 09:02 versucht der Job, eine E-Mail zu senden, aber der Provider timed out. Das ist transient, also retryt der Worker mit exponentialem Backoff. Er wartet 30 Sekunden, dann 2 Minuten, dann 10 Minuten. Backoff entlastet den Provider und Ihr eigenes System.
Beim 5. Versuch schlägt es immer noch fehl. Der Job erreicht die Max-Versuche und stoppt. Statt verloren zu gehen, wandert er in die DLQ mit nützlichen Details: user ID, E-Mail-Typ (Onboarding), letzte Fehlermeldung, Versuchszähler und wann die Fehler begannen.
Ein Alert feuert einmal, nicht 50 Mal: „OnboardingEmailJob: 12 Nachrichten in der DLQ in den letzten 15 Minuten. Top-Fehler: Timeout.“ Die On-Call-Person sieht, dass es real ist, wächst und Handeln erfordert.
Wie Sie reparieren und sicher requeueen
Sie untersuchen und finden die Ursache: Der API-Schlüssel wurde rotiert, aber der Worker verwendet noch das alte Secret. Das ist häufig in frühen Codebasen, in denen Secrets hardcodiert oder inkonsistent geladen werden.
Nach Aktualisierung des Secrets und Redeploy requeueen Sie die DLQ-Nachrichten. Bevor Sie den Vorfall schließen, bestätigen Sie, dass die DLQ-Anzahl sinkt, neue Anmeldungen E-Mails innerhalb der normalen Zeit erhalten, Alerts sich löschen und für ein volles Retry-Fenster ruhig bleiben und Logs erfolgreiche Sends ohne wiederkehrende Timeouts zeigen.
Der Fehler wird sichtbar, eingegrenzt und wiederherstellbar — und kein Nutzer wird stillschweigend übersprungen.
Häufige Fehler, die wiederkehrende Vorfälle verursachen
Wiederkehrende Vorfälle sind meist kein „Pech“. Sie entstehen durch Muster, die einen kleinen Fehler in einen Rückstau verwandeln.
Eines der größten Probleme ist das Retryen eines nicht-idempotenten Jobs. Wenn „zweimal ausführen" bedeutet „zweimal belasten" oder „zwei E-Mails senden“, können Retries Kundenproblemen verursachen, obwohl der ursprüngliche Fehler klein war. Fügen Sie einen eindeutigen Request-Key hinzu, prüfen Sie den aktuellen Zustand vor Aktion und schreiben Sie Ergebnisse so weg, dass ein zweiter Lauf ein No-Op wird.
Eine weitere Falle ist, alle Fehler abzufangen und endlos zu retryen. Das fühlt sich sicher an, verbirgt jedoch echte Bugs (falsche Daten, defekte Logik, fehlende Berechtigungen) und verbraucht Kapazität.
Die häufigsten Quellen wiederkehrender Probleme sind:
- Keine Max-Versuche oder Stoppbedingung, sodass Fehler loopen, bis es jemand bemerkt.
- Keine DLQ (oder Äquivalent), sodass Sie fehlgeschlagene Jobs nicht prüfen und wiederherstellen können.
- Alerts, die niemandem gehören, oder so laut sind, dass sie stummgeschaltet werden.
- Secrets oder personenbezogene Daten in Payloads und Logs, die Debugging zu einem Sicherheitsproblem machen.
- Manuelles Wiederholen ohne Wissen, was bereits erfolgreich war, wodurch Duplikate entstehen.
Ein realistisches Beispiel: Ein Zahlungsquittungs-Job timoutet nachdem die Belastung erfolgreich war, retryt und sendet zwei Quittungen. Wochen später führt jemand ein Batch-Run „just in case“ aus und Kunden werden erneut zugespamt.
Schnelle Checkliste bevor Sie in Produktion gehen
Bevor Sie einen neuen Worker oder eine Queue in Produktion einschalten, entscheiden Sie, wie „sicheres Scheitern“ aussieht.
- Definieren Sie, was retrybar ist (Timeouts, 503s, Rate-Limits) vs. was schnell fehlschlagen sollte (falsche Eingabe, fehlender Datensatz, Berechtigungsfehler).
- Nutzen Sie Backoff mit Jitter und einer sinnvollen Obergrenze, damit ein Ausfall keinen riesigen Retry-Stapel erzeugt.
- Setzen Sie Max-Versuche und ein Zeitlimit (z. B. "nach 10 Minuten stoppen"), dann markieren Sie als fehlgeschlagen.
- Aktivieren Sie eine DLQ (oder eine failed-jobs-Tabelle) und prüfen Sie, dass Sie sicher ohne Duplikate requeueen können.
- Machen Sie Fehler beobachtbar: loggen Sie Job-ID, Versuchszahl, Queue-Name, Fehlermeldung und sicheren Kontext (interne IDs, keine Secrets).
Testen Sie dann den gesamten Loop einmal. Wählen Sie einen Job (z. B. das Senden einer Quittungs-E-Mail), erzwingen Sie einen transienten Fehler (gibt einmal ein gefälschtes 502 zurück) und bestätigen Sie, dass er mit erwarteter Verzögerung retryt, beim nächsten Versuch erfolgreich ist und genau eine E-Mail produziert.
Nächste Schritte: Einen Job verbessern, dann das Muster skalieren
Wählen Sie einen täglich wichtigen Job, der weh tut, wenn er fehlschlägt. Gute Kandidaten sind Quittungs-E-Mails, Payment-Syncs oder Rechnungs-Generierung. Wenn Sie einen Job sicher fehlschlagen, automatisch wiederherstellen und alarmieren können, haben Sie eine Vorlage, die Sie wiederverwenden können.
Anfangen Sie klein: Klassifizieren Sie Fehler und retryen nur transiente. Fügen Sie Backoff, eine Max-Versuch-Grenze und einen DLQ-Pfad für alles, was weiterhin fehlschlägt, hinzu. Fügen Sie einen handlungsfähigen Alert hinzu, wenn ein Job die Max-Versuche erreicht oder in die DLQ gelangt. Behalten Sie für jeden Versuch eine klare Log-Zeile mit Job-ID, Versuchszahl und der letzten Fehlermeldung.
Wenn Sie einen AI-generierten Codebestand geerbt haben, in dem Worker „manchmal fehlschlagen“, vermeiden Sie zuerst große Refactorings. Umgeben Sie Jobs mit Schutzvorrichtungen (Versuchs-Tracking, Backoff, Stoppbedingungen) und bereinigen Sie die Logik, sobald Fehler sichtbar sind.
Wenn Sie unsicher sind, ob Sie den Code sicher ändern können: FixMyMess (fixmymess.ai) kann ein kostenloses Code-Audit durchführen, um Probleme in Job-Logik, Retries, Secrets-Handling und Produktionsreife zu erkennen, und verifizierte Fixes liefern, die oft innerhalb von 48 bis 72 Stunden einsatzbereit sind.
Häufige Fragen
Was ist ein „stiller Ausfall“ bei einem Hintergrundjob?
Silent failures passieren, wenn ein Job im Hintergrund läuft, fehlschlägt und niemand es bemerkt. Nutzer merken später nur das fehlende Ergebnis, z. B. keine Quittungs-E-Mail oder ein Export, der nie ankommt.
Was ist ein guter Default-Retry-Plan für die meisten Hintergrundjobs?
Nicht unbegrenzt retryen. Wiederholen Sie nur Fehler, die wahrscheinlich bald von selbst verschwinden, fügen Sie Backoff hinzu, um Systeme nicht zu überlasten, stoppen Sie nach einer festen Grenze und machen Sie den endgültigen Fehler sichtbar, damit ein Mensch die Ursache behebt.
Wie unterscheide ich transiente von permanenten Fehlern?
Transiente Fehler lösen sich ohne Code- oder Datensänderung, z. B. Timeouts, kurzzeitige Ausfälle, Rate-Limits oder temporäre Datenbanksperren. Permanente Fehler sind meist fehlerhafte Eingaben, fehlende Datensätze, ungültige Berechtigungen oder Bugs — und Retries verzögern nur die eigentliche Lösung.
Warum Exponential Backoff und Jitter statt sofortigem Retry?
Exponential Backoff verteilt die Versuche weiter auseinander und reduziert Belastung, wenn etwas bereits kämpft. Mit Jitter fügt man Zufall hinzu, damit nicht viele Worker gleichzeitig erneut versuchen und erneut Spitzen erzeugen.
Warum sind unbegrenzte Retries eine schlechte Idee?
Unbegrenzte Retries verstecken echte Bugs und führen zu hoher Queue-Zeit, API-Kosten und doppelten Nebenwirkungen. Ein Max-Limit erzwingt einen klaren „das braucht Aufmerksamkeit“-Moment und verhindert, dass ein kaputter Job gesunde Arbeit blockiert.
Wie viele Retries sollte ich erlauben und wie lange retryen?
Beginnen Sie mit Risikoabschätzung. Hochriskante Aktionen wie Zahlungen sollten schnell stoppen (oft 1–3 Versuche). Geringere Risiken wie Benachrichtigungen können mehr Versuche erlauben, aber stets mit einer Zeitbegrenzung, damit Sie nicht tagelang retryen und das Problem vergessen.
Was ist eine Dead-Letter-Queue und warum brauche ich eine?
Eine Dead-Letter-Queue (oder eine Tabelle für fehlgeschlagene Jobs) ist der Ort, an den ein Job nach Erreichen der Max-Versuche geht. Sie bewahrt den Kontext, damit Arbeit nicht verloren geht, und erlaubt ein bewusstes, sicheres Wiederholen nachdem die Ursache behoben wurde.
Wie requeue ich fehlgeschlagene Jobs sicher, ohne Duplikate zu erzeugen?
Nur nachdem Sie die Ursache behoben haben requeueen, und stellen Sie sicher, dass der Job keine Duplikate erzeugt, wenn er zweimal läuft. Protokollieren Sie, wer neu einreiht und warum, und vermeiden Sie das erneute Einreihen von Jobs mit ungültigen Eingaben.
Was bedeutet „idempotenter Job“ und wann ist das wichtig?
Idempotenz heißt: Ein Job mehrmals ausführen erzeugt kein zweites Charge, keine zweite E-Mail und keine doppelten Datensätze. Verwenden Sie Zustands-Set-Operationen, oder fügen Sie einen eindeutigen Schlüssel bzw. einen Idempotency-Token des Providers hinzu, damit Wiederholungen zu No-Ops werden.
Worüber sollte ich Alerts auslösen und was sollte ich für Hintergrundjobs loggen?
Alerten Sie, wenn ein Job handlungsbedarf erreicht — z. B. beim Erreichen der Max-Versuche oder beim Eintritt in die DLQ —, nicht bei jedem Retry. Loggen Sie jeden Versuch mit Job-ID und Fehlertyp, und verfolgen Sie einfache Metriken wie DLQ-Wachstum und Retry-Rate, damit Sie Probleme bemerken, bevor Kunden es tun.
Welche Informationen sollten Alerts enthalten, damit jemand reagieren kann?
Fassen Sie relevante Informationen zusammen: Job-Name, Umgebung, erster Fehlerzeitpunkt, letzte Fehlermeldung, wie viele Jobs betroffen sind und ob Nachrichten in die DLQ gehen. Das hilft dem Verantwortlichen, schnell zu handeln statt lange zu suchen.