Sanfter Shutdown für Node-Server: zufällige 502s verhindern
Lerne, wie du Node-Server sauber herunterfährst: Keep-alive-Verbindungen abdrainen, in-flight-Anfragen beenden, DB-Pools schließen und zufällige 502s bei Deploys verhindern.
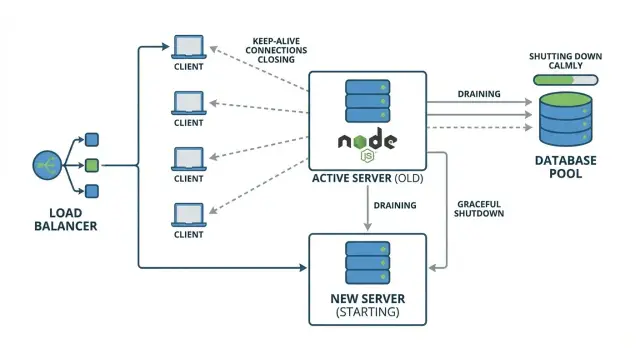
Warum Deploys zufällige 502s verursachen können
Eine „zufällige 502“ während eines Deploys bedeutet meistens, dass dein Reverse-Proxy oder Load-Balancer eine Anfrage an eine App-Instanz geschickt hat, die gerade herunterfährt. Für einen kurzen Moment kann der Proxy die Instanz noch als verfügbar ansehen oder eine bestehende Verbindung wiederverwenden, auf deren anderer Seite kein gesunder Server mehr antwortet.
Es wirkt zufällig, weil es von Timing abhängt. Die meisten Nutzer treffen auf Instanzen, die noch laufen, und erhalten normale Antworten. Eine kleinere Gruppe trifft das Pechfenster: Ihre Anfrage kommt genau in dem Moment an, in dem der Prozess beendet wird, der Server aufhört zu lauschen oder eine Verbindung gekappt wird.
Keep-alive verschärft das Problem. Clients und Proxies nutzen bestehende TCP-Verbindungen für mehrere Anfragen, sodass während eines Deploys langlebige Verbindungen weiterhin Anfragen an eine Instanz senden können, die du gerade ersetzen willst. Wenn die App den Server sofort schließt, schlagen diese wiederverwendeten Verbindungen auf verwirrende Weise fehl, und der Proxy meldet oft einen 502.
Die Kernidee ist ein sauberer Shutdown: keine neue Arbeit annehmen, die bereits laufende Arbeit beenden und dann exit.
Ein einfaches Szenario: Du deployst eine neue Version, dein Orchestrator sendet ein Stop-Signal und Node beendet sich sofort. Ein Nutzer ist mitten im Checkout (eine in-flight Anfrage). Ein anderer Nutzer nutzt eine wiederverwendete keep-alive-Verbindung, um die nächste Seite zu laden. Beide Anfragen werden abgebrochen. Alle anderen, die zu anderen Instanzen geroutet werden, bemerken nichts.
Ein Shutdown, der Verbindungen entleert und kurz auf in-flight Anfragen wartet, verhindert diese „zufälligen“ Fehler und macht Deploys vorhersehbar.
Was genau du runterfährst
Ein Node-Server ist nicht einfach „ein Prozess, der stoppt“. Er ist ein Prozess mitten im Gespräch mit Clients und hält Ressourcen offen wie Sockets, Timer und Datenbankverbindungen. Graceful Shutdown dreht sich hauptsächlich darum, diese Gespräche in der richtigen Reihenfolge zu beenden.
Ein typischer Request-Lifecycle sieht so aus: ein Client verbindet sich, schickt eine Anfrage, deine App führt Code aus (häufig mit Abfragen an eine Datenbank oder eine andere API), dann sendet der Server eine Antwort und die Anfrage ist abgeschlossen. Wenn du den Prozess mitten drin killst, bekommt der Client eine kaputte Antwort und dein Load-Balancer meldet möglicherweise einen 502.
„In-flight requests“ sind Anfragen, die begonnen wurden, aber noch nicht fertig sind. Das sind die Anfragen, die am ehesten während Deploys abgeschnitten werden. Selbst kurze Anfragen können in-flight werden, wenn die Datenbank langsam ist, eine Downstream-API hängt oder das Event-Loop beschäftigt ist.
Keep-alive fügt eine weitere Ebene hinzu. Eine TCP-Verbindung kann über die Zeit viele Anfragen transportieren. Während des Shutdowns willst du neue Anfragen stoppen, hast aber möglicherweise noch offene keep-alive-Sockets, die entweder idle sind oder auf die nächste Anfrage warten.
Manche Arbeiten bleiben länger "in-flight" und brauchen besondere Sorgfalt: Uploads (große Dateien, langsame Clients), Exporte/Report-Generierung, Streaming-Antworten und Server-Sent Events (SSE) sowie WebSockets (keine „Anfragen“ im üblichen Sinn, aber trotzdem aktive Verbindungen).
Du fährst also drei Dinge herunter: neuen eingehenden Traffic, aktuelle in-flight Anfragen und alle langlebigen Verbindungen, die den Prozess beschäftigt halten, auch wenn er oberflächlich idle wirkt.
Signale und Timing: wie Shutdown ausgelöst wird
Die meisten Deploy-Probleme beginnen gleich: dein Node-Prozess bekommt ein Stop-Signal, aber niemand ist sich sicher, wann oder wie lange er zum Fertigwerden hat.
Auf Linux sind zwei Signale am wichtigsten:
- SIGTERM: „Bitte jetzt beenden, aber zuerst sauber aufräumen.“ Plattformen schicken das während eines normalen Stops oder Deploys.
- SIGINT: „Stopp, weil ein Mensch das verlangt hat.“ Das ist Ctrl+C im Terminal.
Process-Manager und Container folgen meist einer einfachen Abfolge: Ein Deploy beginnt, die alte Instanz erhält SIGTERM und ein Countdown startet (häufig Grace-Period genannt). Wenn die App rechtzeitig exitet, prima. Wenn nicht, sendet die Plattform ein hartes Kill (SIGKILL) und der Prozess verschwindet sofort.
Wenn du nichts unternimmst, läuft Node weiter, bis es zwangsweise beendet wird. Das bedeutet, keep-alive-Sockets können mitten in einer Anfrage gekappt werden, in-flight-Arbeit kann nie fertigwerden und DB-Verbindungen bleiben hängen. Das Ergebnis zeigt sich als „zufällige“ 502s, selbst wenn deine App-Logs sauber aussehen.
Mach das Shutdown-Verhalten konsistent, nicht opportunistisch. Entscheide vorher, welches Signal du behandelst (gewöhnlich SIGTERM), wie lange du wartest, bevor du zwangsbeendest, und was zuerst stoppt (neuer Traffic) versus was du fertig zu Ende bringen versuchst (in-flight Anfragen).
Wenn Shutdown vorhersehbar ist, sind Deploys kein Glücksspiel mehr.
Schritt-für-Schritt: sicher keine neue Arbeit annehmen
Ein Deploy sollte sich nicht anfühlen wie das Ziehen am Stecker. Das Ziel ist einfach: zuerst neuen Traffic stoppen, dann die laufende Arbeit beenden.
Beginne damit, ein einfaches "draining"-Flag in deiner App zu ergänzen. Wenn es auf true schaltet, ist der Server noch am Leben, bereitet sich aber aufs Beenden vor.
Eine sichere Reihenfolge für die meisten HTTP-APIs:
- Setze
draining = truesobald das Shutdown-Signal ankommt. - Lass deinen Readiness-Check fehlschlagen, damit der Load-Balancer aufhört, neue Requests an diese Instanz zu schicken.
- Für jede neue Anfrage, die trotzdem ankommt, sende ein klares
503 Service Unavailablemit kurzer Nachricht. - Weise den HTTP-Server an, keine neuen Verbindungen mehr anzunehmen.
- Halte den Prozess lebendig, während bestehende Anfragen fertig werden (mit Timeout, siehe unten).
Ein kleines Beispiel (Express-Style) sieht so aus:
let draining = false;
app.get('/ready', (req, res) => {
if (draining) return res.sendStatus(503);
res.sendStatus(200);
});
app.use((req, res, next) => {
if (draining) return res.status(503).send('Server is restarting, try again');
next();
});
process.on('SIGTERM', () => {
draining = true;
server.close(); // stop accepting new connections
});
Halte Health-Checks ehrlich. Während des Shutdowns soll „ready" schnell rot werden, aber ein einfacher „alive"-Check sollte grün bleiben, bis du wirklich exitest. Das verhindert, dass die Plattform den Prozess zu früh killt und damit genau die 502s erzeugt, die du vermeiden willst.
Keep-alive-Verbindungen abdrainieren ohne Nutzer fallen zu lassen
Keep-alive bedeutet, dass der Browser (oder ein Load-Balancer) dieselbe TCP-Verbindung für mehrere HTTP-Anfragen wiederverwenden kann. Das ist gut für Performance, überrascht aber bei Deploys: du hörst auf, neue Verbindungen anzunehmen, aber alte keep-alive-Sockets bleiben offen und können noch eine weitere Anfrage an den abbauenden Prozess schicken.
Node's server.close() stoppt neue Verbindungen, schließt aber nicht automatisch bestehende keep-alive-Sockets. Um sicher zu entleeren, tracke Sockets beim Verbinden und schließe im Shutdown die idle-Sockets sanft, während aktive Anfragen fertiglaufen.
Ein einfaches Muster:
- Halte ein
Setvon Sockets aus demconnection-Event des Servers. - Markiere Sockets als "busy", während eine Anfrage läuft.
- Beim Shutdown
server.close()aufrufen und für idle-Socketssocket.end(). - Nach einer Deadline alles Übrige
socket.destroy().
Hier ein kompaktes Beispiel:
const sockets = new Set();
const busy = new Set();
server.on('connection', (socket) => {
sockets.add(socket);
socket.on('close', () => { sockets.delete(socket); busy.delete(socket); });
});
server.on('request', (req, res) => {
busy.add(req.socket);
res.on('finish', () => busy.delete(req.socket));
});
async function shutdown() {
server.close();
for (const s of sockets) if (!busy.has(s)) s.end();
setTimeout(() => { for (const s of sockets) s.destroy(); }, 10_000);
}
Diese Force-Close-Deadline ist wichtig. Ohne sie kann ein hängender Client die alte Instanz am Leben halten und ein Rollout in eine Mischung aus Timeouts und intermittierenden Proxy-Fehlern verwandeln.
In-flight-Anfragen mit klarem Timeout beenden
Wenn ein Deploy startet, sollen bestehende Anfragen normal fertigwerden, aber du brauchst auch eine harte Grenze, damit die alte Instanz nicht ewig hängt. Der einfachste Ansatz ist, aktive Anfragen zu zählen und ein draining-Flag zu nutzen.
Hier ein kleines Muster, das mit den meisten Node-HTTP-Frameworks funktioniert:
let draining = false;
let active = 0;
app.use((req, res, next) => {
if (draining) return res.status(503).set('Connection', 'close').send('Server restarting');
active += 1;
res.on('finish', () => { active -= 1; });
res.on('close', () => { active -= 1; });
next();
});
function beginShutdown() {
draining = true;
}
Während des Draining vermeide es, neue Arbeit zu erzeugen, die über die Anfrage hinausläuft. Ein häufiger Fehler ist, während der Request-Verarbeitung Hintergrundaufgaben (Mails, Reports, Cleanup) zu enqueuen, nachdem du bereits mit Shutdown angefangen hast. Wenn du trotzdem enqueuen musst, prüfe das draining-Flag und überspringe solche Aufgaben während des Shutdowns.
Setze ein Shutdown-Timeout passend zu deinem Traffic. Viele Teams starten mit 10 bis 30 Sekunden und passen dann an, basierend auf wirklich langsamen Endpunkten.
Der Ablauf ist simpel: Draining starten und keine neuen Requests mehr annehmen, warten bis active === 0, und wenn der Timer abläuft, verbleibende Verbindungen zwangsweise schließen und exit.
Wenn eine Anfrage nach Beginn des Draining ankommt, gib 503 Service Unavailable und füge Connection: close hinzu. Das signalisiert Clients und Load-Balancern, die Socket nicht offen zu halten und reduziert halb geschlossene keep-alive-Fehler, die oft als 502 auftauchen.
DB-Pools und andere Ressourcen sauber schließen
Den HTTP-Server zu schließen ist nicht dasselbe wie dem Node-Prozess erlauben zu exiten. Ein Datenbank-Pool hält offene TCP-Sockets (und manchmal Timer), sodass das Event-Loop weiterhin Arbeit hat. Deshalb kann ein Deploy „fertig“ aussehen, während die alte Instanz noch hängt und später gekillt wird – was Fehler erzeugt.
„Den Pool schließen“ heißt meist: keine neuen Verbindungen mehr ausgeben, idle-Verbindungen schließen und warten, bis aktive Queries fertig sind. Beispiele:
- PostgreSQL (
pg):await pool.end() - MySQL (
mysql2):await pool.end() - Mongoose:
await mongoose.connection.close()(und neue Ops stoppen)
Die Reihenfolge zählt. Stoppe zuerst neuen Traffic (damit keine frische DB-Arbeit entsteht), dann lass in-flight-Anfragen fertig werden und schließe danach den DB-Pool. Danach kannst du den Rest herunterfahren.
Ausstehende Queries und Transaktionen brauchen klare Regeln. Während des Shutdowns blockiere neue schreibende Requests, lass aktuelle Anfragen bis zu einem Timeout fertigwerden und falle dann schnell zurück. Bei langen Transaktionen versuche, sie schnell zu beenden und bei Erreichen der Deadline zu rollbacken.
async function shutdown() {
server.close(); // stop new HTTP connections
await Promise.race([
waitForInFlightToFinish(),
sleep(10_000),
]);
await dbPool.end();
await redis?.quit();
await queue?.close();
}
Andere Ressourcen, die den Prozess am Leben halten, sind Redis-Clients, Job-Queues, Kafka-/Rabbit-Verbindungen, Cron-Timer und offene Datei-Handles. Sie explizit zu schließen macht den Shutdown zuverlässig.
Hintergrund-Jobs: vergiss die versteckte Arbeit nicht
HTTP-Traffic ist nur die halbe Geschichte. Viele Node-Server führen Hintergrundarbeit im selben Prozess aus: Queue-Consumer, Cron-Jobs, geplante Refreshes und Worker-Loops. Während eines Deploys können diese die Process-Lebenszeit verlängern oder nach dem Shutdown noch die Datenbank berühren.
Erste Regel: Sobald Shutdown beginnt, starte keine neue Hintergrundarbeit mehr. Pausiere Queue-Consumption, stoppe Polling und verhindere, dass Cron neue Läufe startet. Wenn du eine Bibliothek nutzt, suche nach einer echten Pause-/Stop-Methode (nicht nur Disconnect), denn Disconnect kann Retries triggern und zusätzlichen Lärm erzeugen.
Nachdem du neue Jobs gestoppt hast, lass laufende Jobs fertigwerden, aber nur bis zu einer klaren Grenze. Sonst kann ein hängender Job den Shutdown verzögern, bis die Plattform den Prozess tötet – und dann steigen die Fehlerzahlen.
Sicher abbrechen vs. warten
Wähle je nach Job-Typ:
- Warten bei Arbeiten mit bekannter Obergrenze (eine Mail senden, ein Bild skalieren).
- Abbrechen bei langen Jobs mit unklarer Dauer (große Importe, Drittanbieter-Calls, die hängen).
- Abbrechen alles, was eine DB-Transaktion offenhält.
- Warten bei Jobs, die Checkpoints schreiben und später fortsetzen können.
- Abbrechen Jobs, die bei Wiederholung Schaden anrichten könnten (doppelte Abbuchungen, doppelte Rückerstattungen).
Wenn du abbrichst, mache es bewusst: setze ein isShuttingDown-Flag, hör auf, Nachrichten zu ziehen, und lass Jobs an sicheren Punkten das Flag prüfen, damit sie sauber exiten.
Was du loggen solltest, um zu sehen, was den Exit verhindert
Logge genug, um die Frage „Was lief noch?“ beantworten zu können. Erfasse Startzeit und Signal des Shutdowns, aktive Job-Zähler (nach Queue-Name), das älteste laufende Job-Alter und IDs, welche Subsysteme noch offen sind (Queue-Client, Cron, Timer) und ob du die Shutdown-Deadline erreicht und Dinge zwangsweise gestoppt hast.
Spezialfälle: WebSockets, Streaming und Uploads
Shutdown ist einfacher, wenn Anfragen kurz sind. Probleme entstehen, wenn Verbindungen Minuten offen bleiben.
WebSockets: ohne Überraschungen schließen
WebSockets sind per Design langlebig, also kill den Prozess nicht einfach. Während des Shutdowns keine neuen Socket-Verbindungen mehr annehmen, aktive Clients benachrichtigen und ihnen ein kurzes Fenster geben, sich woanders zu reconnecten.
Ein praktisches Muster: sende ein "server restarting"-Event, stoppe neue Nachrichten und schließe mit einem normalen Close-Code (kein Fehler). Wenn du einen Load-Balancer hast, stelle sicher, dass er aufhört, neue Verbindungen an die Instanz zu routen, bevor du Sockets schließt.
Streaming, SSE und Long Polls
SSE und andere Streaming-Endpunkte können für Proxies „idle“ aussehen, obwohl sie arbeiten. Beende Streams sauber, damit der Client reconnecten kann, und setze eine maximale Drain-Zeit, damit du nicht ewig wartest.
Bei Long Polling retryen Clients schnell. Eine klare „try again“-Antwort ist besser, als die Verbindung sterben zu lassen und einen 502 zu erzeugen.
Ein praktischer Ansatz: zuerst keine neuen Verbindungen annehmen, die Instanz als draining markieren, eine abschließende Nachricht senden und Streams/Sockets sauber schließen, Uploads ein kurzes Gnadenfenster geben und dann abbrechen, und eine harte Timeout-Grenze für alles setzen, damit Deploys abgeschlossen werden.
Datei-Uploads mittendrin
Wenn ein Client mitten im Upload ist, kann das Kappen der Verbindung die Datei beschädigen und Zeit verschwenden. Bevorzuge resumable Uploads, wenn möglich. Wenn nicht, schreibe in eine temporäre Datei und „committe“ erst, wenn der Upload vollständig ist.
Prüfe auch die Timeouts des Reverse-Proxys (Nginx, ALB etc.). Ein Idle-Timeout, das kürzer ist als dein Stream- oder Upload-Fenster, kann wie ein deploy-bedingter 502 aussehen, auch wenn dein Code korrekt ist.
Häufige Fehler, die trotzdem zu 502s führen
Die meisten „zufälligen“ 502s bei Deploys sind nicht zufällig. Sie passieren, wenn Shutdown in falscher Reihenfolge geschieht oder der Load-Balancer weiter Anfragen an einen Prozess routet, der bereits im Abschalten ist.
Ein Timing-Fehler ist, zu lange zu warten, bis du neuen Traffic stoppst. Wenn du erst mit dem Schließen beginnst und dann drainest, entsteh ein Fenster, in dem neue Anfragen ankommen, aber kritische Ressourcen (z. B. DB-Verbindungen) bereits nicht mehr verfügbar sind. Das sieht aus wie flakige Netzwerkfehler.
Ein anderer klassischer Fehler ist, den DB-Pool zuerst zu schließen. Anfragen, die bereits geroutet wurden, brauchen noch Queries, Sessions oder Transaktionen. Wenn der Pool weg ist, schlagen diese Requests in-flight fehl.
Deploy-Umgebungen senden üblicherweise SIGTERM, nicht SIGINT. Wenn du nur Ctrl+C lokal getestet hast, läuft dein Shutdown-Handler in Produktion vielleicht nie. Das sieht man oft bei AI-generiertem Node-Code: lokal läuft alles, bis das erste echte Deploy kommt und die Plattform hart killt, weil der erwartete Signal-Handler fehlt.
Die Probleme, die am häufigsten Shutdown brechen, sind simpel: nicht früh genug in den Drain-Modus wechseln, keine Shutdown-Deadline (oder eine zu kurze), Readiness grün lassen während Drain, keep-alive-Sockets zu aggressiv schließen statt sie zu drainen, und vergessen, dass Hintergrundarbeit den Prozess nach Schließen des HTTP-Servers am Leben hält.
Wenn du nur eine Sache reparierst: verbessere die Health-Checks. Sobald Draining beginnt, sollte die Instanz schnell nicht mehr "ready" sein, damit Traffic weggezogen wird, bevor du etwas abschaltest.
Schnell-Checkliste vor dem Deploy
Führe einen Dry-Run in Staging direkt vor dem Release durch. Wenn der Prozess gestoppt wird, sollte er keine neue Arbeit mehr annehmen, das Fertiggestellte beenden und keine losen Enden hinterlassen.
Eine kurze Checkliste:
- Sende ein echtes Shutdown-Signal (SIGTERM) und verifiziere, dass die App sofort reagiert: klare Log-Zeile, Readiness kippt und der Server akzeptiert keine neuen Verbindungen mehr.
- Während des Draining: bestätige, dass neue Requests eine kontrollierte Antwort bekommen (z. B. 503 mit kurzer Nachricht) statt zu hängen, bis der Load-Balancer timeoutet.
- Erzeuge eine langsame Anfrage (sleep, schwere Query oder großes Render) und prüfe, dass sie fertigwerden kann. Bestätige auch, dass du ein hartes Timeout hast, damit der Prozess rechtzeitig exitet, wenn etwas hängt.
- Prüfe Cleanup: DB-Pool schließt, Message-Queue-Clients trennen sich, Timer stoppen. Nach Exit sollte der Prozess nicht durch offene Handles am Leben gehalten werden.
- Review der Shutdown-Logs End-to-End: Startzeit, wann Draining beginnt, aktive Request-Anzahl und eine abschließende "shutdown complete"-Zeile.
Eine einfache Methode, Probleme zu fangen: starte zwei curls gleichzeitig: eine lange Anfrage und eine weitere kurz nachdem du SIGTERM gesendet hast. Wenn die lange Anfrage fertig wird und die neue Anfrage eine schnelle, vorhersehbare Antwort bekommt, bist du nah dran.
Wenn dein Server von einem AI-Tool generiert wurde (Lovable, Bolt, v0, Cursor, Replit), fehlen diese Hooks oft oder sind nur halb implementiert. Frühes Beheben verhindert das Gefühl von „zufälligen 502s“ während Deploys.
Beispiel: Rolling Deploy ohne abgeworfene Requests
Stell dir ein kleines Prod-Setup vor: zwei Node-API-Instanzen (A und B) hinter einem Load-Balancer. Clients nutzen keep-alive, sodass ein Browser-Tab dieselbe TCP-Verbindung zu Instanz A für Minuten wiederverwenden kann.
Bei einem Rolling Deploy leitet der Load-Balancer neue Requests an B, während A ersetzt wird. Der Knackpunkt ist keep-alive: selbst wenn der Load-Balancer aufhört, A neue Verbindungen zu geben, haben einige Clients noch offene Verbindungen zu A und schicken weiterhin Requests darauf.
Daraus entstehen intermittierende 502s. Wenn A SIGTERM bekommt und schnell exitet, zeigen diese wiederverwendeten Verbindungen plötzlich auf einen Prozess, der nicht mehr da ist. Die nächste Anfrage auf diesem Socket schlägt fehl und der Proxy meldet 502.
Ein Graceful Shutdown vermeidet das, indem er drei Dinge in Reihenfolge macht:
- neue Verbindungen auf A stoppen
- bestehende keep-alive-Verbindungen drainen
- auf in-flight-Anfragen bis zu einer klaren Timeout warten, dann DB-Pools schließen und exit
Teste lokal oder in Staging: füge einen langsamen Endpunkt hinzu (z. B. eine Route, die 10 Sekunden wartet), schicke wiederholt Requests mit keep-alive und starte dann nur eine Instanz neu. Wenn das Draining funktioniert, beendet die langsame Anfrage und du siehst keine intermittierenden 502s.
Nächste Schritte: mach Deploys langweilig
Graceful Shutdown hilft nur, wenn du es unter echtem Traffic siehst. Füge Shutdown-Logs hinzu, die die Reihenfolge der Ereignisse zeigen: Signal empfangen, Readiness gekippt, keine neuen Requests mehr, aktive Request-Anzahl, Keep-Alive-Drain, DB-Pool geschlossen, Prozess beendet.
Vor dem nächsten Release: führe einen "slow request"-Test in Staging durch: mach einen Endpunkt absichtlich langsam (10–20 Sekunden) und deploye während diese Anfrage läuft. Du willst zwei Ergebnisse: die langsame Anfrage beendet erfolgreich und neue Anfragen gehen ohne Fehler an die neue Instanz.
Wenn der Code unordentlich oder AI-generiert ist und Deploys weiterhin unvorhersehbar sind, kann ein gezieltes Audit schneller helfen als random Änderungen. FixMyMess (fixmymess.ai) hilft Teams, Shutdown-Pfade, Connection-Draining und Cleanup-Probleme in übernommenen AI-generierten Node-Apps zu diagnostizieren, damit Rollouts keine überraschenden 502s mehr produzieren.