SQLite zu Postgres migrieren: Ein Playbook für einen gestaffelten Cutover
Ein praktisches Playbook zur Migration von SQLite zu Postgres in KI-generierten Apps: Schema‑Mapping, Datentypen, Index‑Änderungen, gestufte Cutovers und Prüfungen.
Warum diese Migration in KI-generierten Apps riskant ist
KI-generierte Prototypen „funktionieren“ oft, weil SQLite nachsichtig ist. SQLite speichert ungewöhnliche Werte, akzeptiert lockere Typen und lässt dich mit minimaler Einrichtung weit kommen. Viele KI‑Tools setzen aus demselben Grund standardmäßig auf SQLite: keine Konfiguration und leicht zu liefern. Das Problem ist, dass diese frühen Abkürzungen zu versteckten Annahmen im Code werden.
Bei der Migration von SQLite zu Postgres sehen die ersten Fehler oft harmlos aus, breiten sich aber schnell aus. Eine Abfrage, die in SQLite funktioniert hat, kann in Postgres scheitern wegen strengerer Typisierung, anderem Verhalten bei Datum und Boolean oder weil Vergleiche case‑sensitive sind. Migrationen können auch daran scheitern, dass SQLite das Hinzufügen von Spalten oder Änderungen an Tabellen erlaubt hat, die sich nicht sauber nach Postgres übersetzen lassen.
Was meist zuerst kaputtgeht:
- Authentifizierung und Sessions (Zeitstempel, Unique-Constraints, Case‑Sensitivity)
- „Es lief lokal“-Queries (implizite Casts, lockeres GROUP BY-Verhalten)
- Hintergrundjobs und Importe (schlechte Daten, die SQLite tolerierte)
- Performance (fehlende Indexe, die in SQLite nicht auffallen)
- Deploy‑Skripte (Annahmen über dateibasierte DB vs. Server‑DB)
Eine Migration lohnt sich, wenn du Concurrency brauchst, echte Backups, bessere Query‑Planung, sicherere Zugriffssteuerung oder dein Single‑Node-Setup an Grenzen stößt. Sie lohnt sich nicht, wenn die App jede Woche verworfen wird, Anforderungen unstabil sind oder das Hauptproblem Produkt‑Fit statt Datenbankgrenzen ist.
„Keine überraschenden Downtimes“ heißt nicht „kein Risiko“. Es heißt: du planst für die typischen Fehler, kannst Fortschritt messen und hast einen sauberen Rollback‑Pfad. In der Praxis zielst du auf keine sichtbare Ausfallzeit für Nutzer oder ein sehr kurzes, geplantes Fenster mit klarer Rückfalloption.
Dieses Playbook folgt einem einfachen Ablauf: inventarisiere, was du wirklich hast, übersetze das Schema sorgfältig, konvertiere Daten sicher, plane Indexe und Performance, führe einen gestaffelten Cutover mit Sync durch, behebe die App‑Änderungen, die oft übersehen werden, und teste sowie probe den Rollback. Wenn deine App von Tools wie Lovable, Bolt, v0, Cursor oder Replit generiert wurde, starten Teams wie FixMyMess oft mit einer schnellen Codebasis‑Diagnose, um SQLite‑spezifische Annahmen zu finden, bevor du Produktionsdaten anfasst.
Was du inventarisieren solltest, bevor du die Datenbank anfasst
Bevor du SQLite zu Postgres migrierst, verschaffe dir Klarheit darüber, was du tatsächlich hast. In KI‑gebauten Apps funktionieren Demos oft, verbergen aber Überraschungen wie stille Typkonvertierungen, ad‑hoc SQL und Hintergrundjobs, die weiter schreiben, während du Daten verschiebst.
Beginne mit einer Tabelle‑für‑Tabelle‑Karte. Du brauchst Namen, Zeilenzahlen und welche Tabellen schnell wachsen. Die größten Tabellen bestimmen meist deinen Cutover‑Plan, weil sie am längsten zum Kopieren brauchen und am schmerzhaftesten sind, um sie neu zu indexieren.
Wenn möglich, erfasse schnell Größe und Wachstum:
-- SQLite: approximate quick checks
SELECT name FROM sqlite_master WHERE type='table';
SELECT COUNT(*) FROM your_big_table;
Als Nächstes: verstehe den Traffic. Eine Datenbankmigration wird selten durch Reads blockiert. Sie wird von vergessenen Writes blockiert: Webhooks, Queues, geplante Tasks und „Hilfsskripte“, die jemand manuell ausführt.
Eine einfache Inventarliste, die die meisten Downtime‑Überraschungen verhindert:
- Tabellen: Zeilenanzahl, größte Tabellen und „heiße“ Tabellen mit häufigen Updates
- Datenfluss: welche Endpunkte schreiben, welche nur lesen und welche Jobs geplant laufen
- Query‑Stil: wo verwendest du ein ORM vs. rohe SQL‑Strings im Code
- SQLite‑Eigenheiten: Stellen, die auf lockere Typen, implizite Booleans oder ungewöhnliche Datumsbehandlung angewiesen sind
- Konfiguration: wo Connection‑Strings, API‑Keys und Datenbank‑Secrets gespeichert und injiziert werden
Rohes SQL ist die klassische Falle. Ein ORM passt Abfragen für Postgres an, aber ein kopiertes SQL‑Snippet aus einem Chat‑Tool nutzt vielleicht SQLite‑spezifische Syntax oder geht von NULL‑Sortierverhalten aus.
Konkretes Beispiel: Ein Prototyp aus Replit speichert Booleans in einer Tabelle als "true"/"false" Text, in einer anderen als 0/1 Integer und verlässt sich darauf, dass SQLite beides akzeptiert. Postgres fordert dich zu einer Entscheidung und diese Wahl beeinflusst Queries, Indexe und App‑Logik.
Wenn du eine unordentliche, KI‑generierte App geerbt hast, kann eine kurze Codebasis‑Diagnose (wie FixMyMess sie macht) diese versteckten Schreiber und SQLite‑Annahmen aufdecken, bevor sie einen fehlerhaften Cutover verursachen.
Schema‑Übersetzung, die später nicht überrascht
Beim Wechsel von SQLite zu Postgres ist das größte Risiko nicht das Kopieren der Daten. Es ist die Entdeckung, dass deine App sich auf SQLite‑Verhalten stützte, das du nie dokumentiert hast.
SQLite akzeptiert oft ein vages Schema: fehlende Foreign Keys, lockere Spaltentypen und implizite Regeln im App‑Code. KI‑gebautes Schema verschlimmert das, weil es schnell generiert und dann vor Ort gepatcht wurde.
Mache das Schema explizit (Tabellen, Keys, Beziehungen)
Beginne damit, eine klare Karte jeder Tabelle und ihrer Verknüpfungen zu schreiben. Verlass dich nicht auf Vermutungen – bestätige es mit dem tatsächlichen Schema und echten Daten.
Eine praktische Reihenfolge zur Übersetzung:
- Definiere den Primary Key jeder Tabelle und ob er sich jemals ändern darf.
- Entscheide, wie jede Beziehung funktioniert (1:1, 1:many) und füge Foreign Keys bewusst hinzu.
- Füge Constraints hinzu, auf die du bislang implizit vertraut hast (NOT NULL, UNIQUE, CHECK).
- Handhabe zirkuläre Beziehungen, indem du zuerst Tabellen erstellst und anschließend die Foreign Keys ergänzt.
- Halte Namen konsistent (Spalten wie userId vs user_id führen später zu stillen Bugs).
Autoincrement‑IDs: wähle die Postgres‑Variante jetzt
In SQLite ist INTEGER PRIMARY KEY ein Spezialfall mit Autoincrement. In Postgres solltest du GENERATED BY DEFAULT AS IDENTITY (oder ALWAYS) statt älterer SERIAL-Typen wählen und dokumentieren.
Beispiel: Ein AI‑Prototyp könnte Nutzer ohne explizite id einfügen und davon ausgehen, dass IDs nie kollidieren. Wenn du Daten nachfüllst und vergisst, die Identity‑Sequenz zurückzusetzen, kann der nächste Insert fehlschlagen oder IDs wiederverwenden.
Stelle abschließend sicher, dass dein Migrationsskript mehrfach sicher ausführbar ist (idempotent): Objekte nur erstellen, wenn sie fehlen, und Constraints kontrolliert hinzufügen, sodass ein partieller Lauf ohne Rätsel fortgesetzt werden kann.
Datentyp‑Mismatch und sichere Konvertierungen
Die meisten fiesen Fehler bei der Migration von SQLite zu Postgres kommen von stillen Typunterschieden. SQLite speichert gern "true" in einer Spalte, die du für Integer gehalten hast. Postgres tut das nicht – und das ist gut –, aber es verlangt explizite Konvertierungen.
Die Mismatches, die echten Schaden anrichten
Einige Muster tauchen in KI‑gebauten Apps immer wieder auf:
- Booleans: SQLite‑Apps nutzen oft 0/1, "true"/"false" oder sogar leere Strings. In Postgres nutze
booleanund konvertiere mit klaren Regeln (z. B. nur 1 und "true" werden true). - Als Text gespeicherte Integer: IDs und Zähler sind manchmal Strings. Konvertiere nur, wenn alle Werte sauber sind; ansonsten behalte Text und füge eine neue Integer‑Spalte ein, die du sicher backfillst.
- Nulls und Defaults: SQLite verhält sich locker bei fehlenden Werten. Postgres erzwingt
NOT NULLund Defaults. Wenn alte Zeilen NULLs enthalten, füge Constraints erst hinzu, nachdem du backfilled hast.
Datetime ist eine weitere Falle. SQLite‑Projekte speichern oft lokale Zeit‑Strings, gemischte Formate oder Epoch‑Sekunden. Wähle zuerst einen Standard: timestamptz in UTC ist meist die sicherste Wahl. Konvertiere dann Schritt für Schritt aus einem bekannten Format und logge Zeilen, die sich nicht parsen lassen. Wenn die App für Nutzer „gestern“ anzeigt, liegt das oft daran, dass lokale Zeit und UTC vermischt wurden.
JSON‑Felder brauchen eine bewusste Entscheidung. Wenn du innerhalb des JSONs filterst oder indexierst, nutze jsonb. Wenn du nur Blob‑Speicherung willst, reicht text, du verlierst dann aber Validierung und Query‑Möglichkeiten.
Geldbeträge und Dezimalzahlen sollten nicht als Float gespeichert werden. Wenn ein AI‑generierter Checkout $19.989999 anzeigt, behebe das mit numeric(12,2) (oder der benötigten Skalierung) und runde während der Konvertierung.
Ein praktischer Ansatz: Führe eine Trockenkonvertierung auf einer Kopie der Produktionsdaten durch, zähle Fehler pro Spalte und entscheide erst dann über finale Typen und Constraints.
Indexierung und Performance‑Änderungen planen
Nach der Migration von SQLite zu Postgres fühlt sich die App oft langsamer an. Ein großer Grund ist, dass SQLite und Postgres unterschiedliche Entscheidungen treffen, wann und wie Indexe genutzt werden.
SQLite kommt mit weniger Indexen aus, weil es im Prozess läuft, einen einfachen Planner hat und geringere Workloads. Postgres ist für Concurrency und größere Daten gebaut, ist aber streng bei Statistik, Selektivität und Query‑Form. Wenn eine KI‑App mit unabsichtlichen Full‑Table‑Scans ausgeliefert wurde, führt Postgres diese einfach aus – nur sichtbar langsamer.
Beginne damit, Indexe aus echten Abfragen abzuleiten, nicht aus Vermutungen. Nimm die Top‑Read‑ und Write‑Queries (Login, List‑Seiten, Suche, Dashboard‑Counts) und designe darum herum. Beispiel: Läuft oft WHERE org_id = ? AND created_at >= ? ORDER BY created_at DESC LIMIT 50, ist ein zusammengesetzter Index auf (org_id, created_at DESC) meist hilfreicher als zwei Einspalten‑Indexe.
Zusammengesetzte Indexe und Einzigartigkeit
Die Reihenfolge in Postgres zusammengesetzter Indexe ist wichtig. Setze den selektivsten Filter zuerst (oft org_id oder user_id), dann die Spalte für Sortierung oder Range‑Scans. Füge die Sortierreihenfolge hinzu, wenn sie zur Abfrage passt.
Unterscheide zudem „muss einzigartig sein“ von „hilft der Performance“. Ein UNIQUE‑Constraint erzwingt Regeln und erstellt einen Index. Wenn es wirklich eine Geschäftsregel ist, modelle es als Constraint, damit es klar und konsistent ist.
Was zu prüfen ist, wenn Queries langsam werden
Nach dem Umzug fokussiere auf:
- Fehlende zusammengesetzte Indexe für häufige Filter‑+‑Sort‑Muster
- Falsche Datentypen, die Casts erzwingen (und Indexnutzung blockieren)
- Veraltete Statistiken (nach Bulk‑Loads ANALYZE ausführen)
- Sequential Scans auf großen Tabellen, wo du Index‑Scans erwartest
- Neue Schreib‑Overhead durch zu viele Indexe auf heißen Tabellen
Wenn du ein AI‑generiertes Schema geerbt hast mit „alles indexieren“ oder „nichts indexieren“, zahlt sich ein kurzer Audit (wie FixMyMess ihn macht) schnell aus.
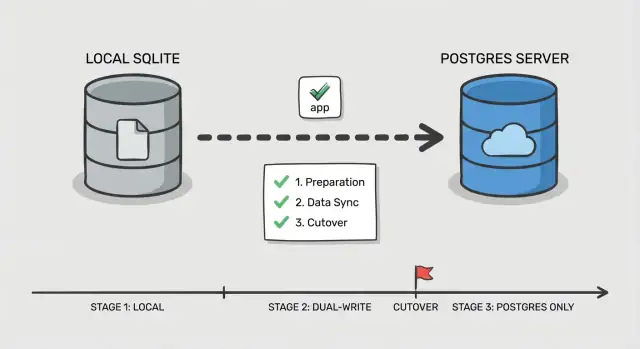
Schritt‑für‑Schritt gestaffelter Cutover‑Plan
Ein sicherer Cutover ist weniger ein großer Schalter als das schrittweise Beweisen, dass jeder Teil funktioniert, während Nutzer weiterarbeiten. Das ist besonders wichtig bei der Migration von SQLite zu Postgres in KI‑gebauten Apps, wo versteckte Queries und seltsame Edge‑Cases häufig sind.
Phase 0: Entscheide, wie du umschaltest
Wähle eine einfache Reihenfolge: zuerst Reads, dann Writes. Reads sind leichter zu validieren und zurückzudrehen. Writes ändern die Quelle der Wahrheit, behandle sie also als letzten Schritt.
Füge einen Kontrollpunkt in die App ein: ein Feature‑Flag oder eine Konfig‑Toggle, die auswählt, welche Datenbank für Reads und welche für Writes zuständig ist. Halte es simpel und explizit, damit du im Vorfall schnell umschalten kannst.
Phase 1–5: Führe den Cutover in kleinen Schritten aus
Bevor du Traffic anfasst, richte Postgres ein (Datenbank, Nutzer, Rollen und Least‑Privilege‑Zugriff). Stelle sicher, dass deine App sich in derselben Umgebung verbinden kann wie bisher.
Dann folge diesem Ablauf:
- Bulk‑Kopie: Snapshot von SQLite nehmen und in Postgres laden.
- Inkrementeller Sync: Postgres mit neuen Änderungen aktuell halten, während die App weiterhin auf SQLite schreibt.
- Read‑Cutover: Leseabfragen zu Postgres routen, Writes auf SQLite belassen, Fehler‑ und Langsamkeitsraten beobachten.
- Write‑Cutover: Writes zu Postgres routen, ein kurzes Fenster offenhalten, um zurückzufallen.
- Finalisieren: Sync stoppen, alte Credentials sperren und SQLite für eine definierte Zeit nur lesbar lassen.
Definiere den Rollback, bevor du irgendetwas umschaltest: welches Toggle zurückgedreht wird, welche Daten verloren gehen könnten und wie du damit umgehst. Beispiel: Wenn Sessions und Passwort‑Resets in der DB liegen, entscheide, ob diese Tabellen spezielle Behandlung brauchen, damit ein Rollback nicht Logins kaputtmacht.
Benötigst du eine zweite Meinung, hilft FixMyMess oft Teams, diesen Plan an unordentlichen KI‑Codebasen zu proben, bevor es ernst wird.
Daten während der Übergangszeit synchron halten
Der schwierige Teil beim Migrations‑Cutover ist nicht das erste Snapshot‑Kopieren. Es ist, Änderungen konsistent zu halten, während echte Nutzer weiter interagieren.
Zwei einfache Sync‑Muster (und wann du sie nutzt)
Wenn die App wenig Traffic hat und Änderungen leicht nachspielbar sind, können periodische Backfill‑Jobs funktionieren: initial kopieren, dann geplante Jobs, die Zeilen seit dem letzten Lauf kopieren (z. B. per updated_at oder append‑only Events‑Tabelle). Einfach, aber erhöht das Risiko kurzfristiger Abweichungen kurz vor dem Cutover.
Bei aktiver Nutzung ist Dual‑Write sicherer: Jeder Write geht vorübergehend in beide DBs. Mehr Aufwand, aber die Lücke schrumpft und der Cutover wird stressfreier.
IDs konsistent halten
Entscheide früh, welches System Primary Keys verwaltet. Die einfachste Regel: behalte dieselben IDs in Postgres und nummeriere nicht neu. Wenn SQLite Integer‑IDs nutzte, setze Postgres‑Sequenzen so, dass neue Reihen oberhalb des aktuellen Maximums beginnen, um Kollisionen zu vermeiden. Wenn du auf UUIDs umsteigst, füge zuerst eine UUID‑Spalte hinzu, backfille sie und behalte die alte ID als externe Referenz, bis die App vollständig umgezogen ist.
Definiere Konfliktregeln vorab:
- Wähle eine Quelle der Wahrheit für Writes (oft Postgres, sobald Dual‑Write läuft)
- Bei Widersprüchen: „latest updated_at wins“ nur, wenn Uhren zuverlässig sind
- Für Geld, Berechtigungen und Auth: explizite Regeln statt Timestamp‑Entscheidungen
- Zeichne jeden Konflikt zur Nachprüfung auf
Betreibe beide Systeme lange genug, um normalen Gebrauch abzudecken (ein paar Tage bis ein kompletter Geschäftszyklus). Logge genug, um Drift schnell zu erkennen: Zeilenzähler pro Tabelle, Prüfsummen‑Stichproben für heiße Tabellen, Write‑Fehler nach Endpunkt und eine kleine Audit‑Spur geänderter IDs. Teams beauftragen oft FixMyMess, um Dual‑Write zu verifizieren und Drift zu finden, bevor Kunden es bemerken.
App‑Level Änderungen, die oft übersehen werden
Der Datenbankwechsel ist nur die halbe Arbeit. Viele Teams migrieren Daten, zeigen die App auf Postgres und jagen dann den Tag über seltsame Fehler, die in SQLite nie auftauchten.
Verbindungseinstellungen und Pooling
SQLite heißt oft „eine Datei, geringe Konkurrenz“. Postgres ist ein Server und akzeptiert viele Verbindungen, bis er plötzlich nicht mehr kann.
Wenn deine App einen Pool nutzt, setze ein echtes Limit und Timeouts. Ein häufiges Muster nach Migration ist, dass Hintergrundjobs und die Web‑App jeweils eigene Pools öffnen, Verbindungen multiplizieren und so Verlangsamungen verursachen, die sich als „Postgres ist langsam“ darstellen, obwohl es „zu viele Verbindungen“ ist.
Queries, die von SQLite‑Nachsicht profitierten
SQLite liefert oft Ergebnisse, selbst wenn SQL schlampig ist. Postgres ist strenger – meistens zu Recht.
Achte auf Vergleiche über Typen hinweg (Text vs Zahlen), implizite Casts und lockeres GROUP BY. Prüfe auch String‑Matching und Case‑Regeln: Eine Suche, die in SQLite „funktionierte“, kann sich ändern, wenn du versehentlich von case‑insensitiver Suche profitierst.
Transaktionen und Locking‑Annahmen können sich ebenfalls umdrehen. Code, der mit „schreibe wann immer“ gut lief, kann jetzt Deadlocks oder Contentions erleben, wenn lange Transaktionen große Reads und Writes kombinieren.
Auth und Session‑Speicherung sind eine leise Falle. Kleine Unterschiede (Zeitstempel, Unique‑Constraints, Cleanup‑Jobs) können zu plötzlichen Logouts oder kaputten Login‑Flows führen.
Schnelle App‑Checks, die die meisten Überraschungen abfangen:
- Bestätige, dass jeder App‑Prozess (Web, Worker, Cron) dieselbe DB‑Konfiguration und Pool‑Limits liest.
- Ersetze SQLite‑only SQL (Upserts‑Eigenheiten, Datumsfunktionen, Boolean‑Handling).
- Auditiere rohes SQL auf Unterschiede bei Quotes und Parametern.
- Überprüfe Transaktionsgrenzen und vermeide, dass lange Jobs Locks unnötig halten.
- Verifiziere Session‑ und Token‑Tabellen, Ablauf‑Logik und Unique‑Constraints.
Beispiel: Ein AI‑Prototyp speichert Sessions in einer Tabelle mit einer createdAt Text‑Spalte und vergleicht sie als String mit „now“. Das kann in SQLite funktionieren, bricht in Postgres aber die Expiry‑Checks, wenn du es nicht in einen echten Timestamp konvertierst.
Wenn du eine KI‑generierte Codebasis von Replit oder Cursor geerbt hast, finden Services wie FixMyMess hier oft die meisten versteckten Bruchstellen: Die Daten sind in Ordnung, aber die App‑Logik setzte auf SQLite‑Verhalten.
Testing, Monitoring und Rollback‑Proben
Die meisten Downtime‑Überraschungen entstehen, weil der Cutover wie ein einmaliges Ereignis behandelt wird, nicht wie ein geprobter Ablauf. KI‑Apps sind hier riskanter, weil Validation schwach ist, Queries inkonsistent sind und Edge‑Cases erst mit echten Daten auftreten.
Beginne mit einem reproduzierbaren Smoke‑Test, den du in Minuten gegen beide Datenbanken laufen lassen kannst. Halte ihn klein und fokussiert auf echte Nutzerpfade, nicht auf alle Features:
- Signup/Login/Logout (inkl. Passwort‑Reset, falls vorhanden)
- Erstelle ein zentrales Objekt (Projekt, Bestellung, Notiz)
- Bearbeite das Objekt und verifiziere die Sichtbarkeit überall
- Lösche oder soft‑delete und bestätige Berechtigungen
- Führe einen Admin/Report aus, der mehrere Tabellen joined
Als Nächstes: Shadow‑Read‑Test. Für einen Traffic‑Slice oder einen Cron Job, lese parallel aus Postgres und SQLite und vergleiche Ergebnisse. Logge Abweichungen mit genug Kontext zum Debuggen (User‑ID, Query‑Inputs, zurückgegebene Primary Keys). Das fängt subtile Probleme wie unterschiedliche Sortierungen, NULL‑Handling, Case‑Sensitivity und Zeitzonenfehler.
Load‑Teste die Endpunkte, die deine heißesten Tabellen treffen, nicht die ganze App. Ein häufiger Fall nach Migration ist, dass eine vormals „okay“ Abfrage jetzt einen fehlenden Index offenbart. Beobachte p95 Latency und Connection‑Pool‑Sättigung.
Probiere schließlich einmal den Rollback, zeitlich getaktet. Schreibe die genauen Schritte auf, wer sie ausführt und wie ein „Stop the world“ aussieht (Feature‑Flag‑Flip, Read‑Only‑Modus oder Traffic‑Drain). Definiere Erfolgskriterien vorab: akzeptable Fehlerquote, p95‑Latency‑Grenze und eine Abweichungsanzahl, die null erreichen muss (oder eine klar begründete Ausnahmeliste).
Häufige Fehler und wie man sie vermeidet
SQLite ist nachsichtig. Postgres ist strikt. Viele Teams werden gebrannt, weil die App „irgendwie“ auf SQLite lief und danach bei der Migration scheitert.
Eine häufige Falle: annehmen, Datentypen „funktionieren einfach“. SQLite speichert Text in einer integer‑artigen Spalte oder Daten als beliebige Strings. Postgres tut das nicht. Scanne vor dem Umzug nach Spalten mit gemischten Werten ("", "N/A", "0000-00-00") und entscheide, welcher Typ wirklich gemeint ist.
Indexe sind eine andere klassische Später‑Aufgabe, die zur Produktionskrise wird. SQLite fühlt sich auf kleinen Datensätzen auch ohne Indexe schnell an. Postgres kann langsamer werden, sobald echter Traffic kommt, wenn du Indexe für Foreign Keys, übliche Filter und Sort‑Spalten vergisst.
Cutovers scheitern, wenn Writes zu früh wechseln. Schreibst du auf Postgres, bevor Drift‑Checks laufen, weißt du nicht mehr, welche DB „richtig“ ist, wenn etwas schiefgeht. Füge Drift‑Checks (Zeilenzähler, updated_at‑Bereiche, Prüfsummen) hinzu, bevor du dem neuen System vertraust.
Suche außerdem nach versteckten SQLite‑Dateipfaden. KI‑Apps haben oft Default‑Werte wie ./db.sqlite in Environment‑Variablen oder Docker‑Images. In Staging sieht alles gut aus, aber Produktion schreibt immer noch in die alte Datei.
Lange Migrationen sind der stille Killer bei großen Tabellen. Ein einzelnes ALTER TABLE oder Backfill kann Writes lange genug blockieren, um Timeouts zu verursachen.
Vermeide diese Probleme mit einer kurzen Pre‑Flight‑Checkliste:
- Auditiere „messy“ Spalten und normalisiere Werte vor dem Casten der Typen.
- Erstelle Postgres‑Indexe vor dem Abschluss des ersten Full‑Loads.
- Halte Dual‑Write oder Change‑Capture aus, bis Drift‑Detektion läuft.
- Suche Konfigurationen und Container nach verbleibenden SQLite‑Pfaden.
- Teile große Backfills in Batches mit Zeitlimits auf.
Wenn du eine wackelige KI‑Codebasis geerbt hast, starten Teams wie FixMyMess oft mit einem schnellen Audit, um diese Risiken vor dem Cutover aufzuzeigen.
Kurze Checkliste und nächste Schritte
Wenn du dir nur eines merken darfst beim Migrieren von SQLite zu Postgres: Die meisten Downtime‑Überraschungen entstehen durch kleine Lücken zwischen Plan und dem, was die App tatsächlich in Produktion macht.
Vor dem Cutover (bereit machen)
Mache diese Dinge, bevor du Produktions‑Traffic anfasst. Wenn etwas unklar ist, pausier und teste kurz.
- Stelle sicher, dass Backups sich sauber wiederherstellen lassen (nicht nur existieren) und erfasse den genauen Cutover‑Zustand.
- Validier, dass das übersetzte Schema zur echten Nutzung passt: Constraints, Defaults und Timestamp‑Verhalten.
- Sorge dafür, dass der Sync‑Pfad läuft und stabil ist (Dual‑Writes oder Change‑Capture) mit klarer Fehlerzuständigkeit.
- Führe einen kurzen produktionsähnlichen Lasttest auf Postgres aus und prüfe die Top‑Seiten oder Endpunkte.
Cutover (sicher umschalten)
Ziel ist ein schneller, unspektakulärer Schalter mit klaren Signalen und Exit‑Plan.
- Nutze einen einzigen, expliziten Toggle (Env‑Var, Config‑Flag oder Router‑Switch) und lege fest, wer ihn flippt.
- Zeige Monitoring vor dem Umschalten an: Fehlerquote, Latenz, DB‑Verbindungen und Replikations/Sync‑Lag.
- Habe den Rollback bereit und geprobt: wie die App zurückzeigt und wie Writes während des Cutovers gehandhabt werden.
Nach dem Umschalten verifiziere zuerst Korrektheit, dann Performance. Vergleiche Zeilenzahlen und Prüfsummen für Schlüssel‑Tabellen, führe kritische Queries End‑to‑End aus (Login, Checkout, Create/Edit) und scanne Logs nach neuen Fehlern wie Constraint‑Verletzungen oder Zeitzonen‑Überraschungen.
Anschließend gehst du Performance‑Probleme an: Ziehe die langsamsten Queries heran, bestätige Indexnutzung und behebe die wenigen Queries, die den meisten Nutzerärger verursachen.
Wenn deine App von Tools wie Lovable, Bolt, v0, Cursor oder Replit generiert wurde, verstecken sich in der Datenbankschicht oft unsaubere Annahmen (String‑Dates, fehlende Constraints, unsichere Queries). FixMyMess bietet ein kostenloses Code‑Audit an, um solche Migrationsrisiken früh zu erkennen, bevor du dich auf einen Cutover festlegst.