SSRF in KI‑generierten Apps: Endpunkte finden und serverseitige Abfragen härten
SSRF in KI‑generierten Apps kann interne Dienste offenlegen. Erfahren Sie, wie Sie riskante serverseitige Fetch‑Endpunkte finden und Allowlists, DNS‑ und Anfragehärtung anwenden.
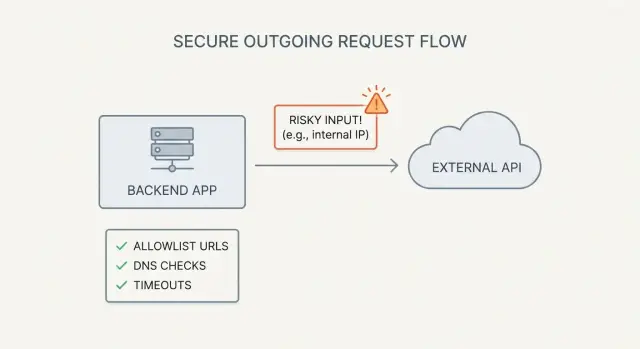
Was SSRF ist (und warum KI‑erzeugte Apps es auslösen)
SSRF (Server‑Side Request Forgery) passiert, wenn Ihre App dazu verleitet wird, eine Netzwerk‑Anfrage im Sinne eines Angreifers auszuführen.
Der Angreifer braucht keinen Zugriff auf Ihre Server. Er benötigt nur eine Funktion, die eine URL (oder einen Hostnamen) akzeptiert und diese dann vom Backend abruft.
Ein einfaches Beispiel: Sie fügen einen Button „Import from URL“ hinzu. Der Browser sendet url=https://example.com/data.json an Ihre API, und Ihr Server lädt die Datei herunter. Wenn derselbe Endpunkt auch http://localhost:3000/admin oder http://169.254.169.254/ (Cloud‑Metadaten) akzeptiert, kann Ihr Server interne Daten offenlegen.
Das tritt ständig in KI‑generierten Prototypen auf. Diese enthalten oft „fetch everything“‑Endpunkte (Image‑Proxies, Link‑Previews, Webhook‑Tester, PDF/Screenshot‑Generatoren), weil sie Demos vollständig erscheinen lassen. Aber sie werden ohne die Schutzmaßnahmen ausgeliefert, die serverseitige Fetches sicher machen.
SSRF ist gefährlich, weil Server normalerweise Zugriff haben, den Benutzer nicht haben. Ein erfolgreicher SSRF‑Angriff kann:
- Interne Admin‑Panels und Services auf
localhostoder privaten IPs erreichen - Cloud‑Metadaten‑Endpunkte auslesen und Zugangsdaten stehlen
- Ihr internes Netzwerk scannen und offene Ports/Services finden
- IP‑basierte Regeln umgehen (weil die Anfrage von Ihrem Server kommt)
SSRF ist nicht dasselbe wie eine Anfrage, die der Browser eines Nutzers macht. Wenn der Browser direkt eine URL lädt, ist das clientseitig. SSRF bedeutet speziell, dass Ihr Backend (oder eine serverlose Funktion) den Fetch durchführt — mit Ihrem Netzwerkzugang und Ihren Secrets.
Wo SSRF sich meist versteckt: Endpunkte, die Sie prüfen sollten
SSRF versteckt sich überall dort, wo der Server eine URL abruft, die ein Nutzer beeinflussen kann. Diese Endpunkte wirken harmlos, weil sie „nur Inhalte ziehen“, können aber genutzt werden, um interne Dienste, Cloud‑Metadaten oder andere private Ziele zu erreichen.
Beginnen Sie damit, Produktfunktionen aufzulisten, die direkt oder indirekt eine URL akzeptieren. Häufige Verstecke sind Link‑Previews, Import‑from‑URL‑Tools (CSV/JSON/Templates), Webhook‑Tester, Datei‑ und Image‑Proxies sowie RSS/Feed‑Reader.
Prüfen Sie auch Admin‑Tools. KI‑generierte Apps enthalten oft schnelle „Connection Tester“‑Seiten, Health‑Checks, die Abhängigkeiten anpingen, oder Integrations‑Setup‑Screens, die eine URL verifizieren. Diese sind besonders riskant, weil sie mit erhöhtem Netzwerkzugang laufen und normale Validierungen überspringen können.
Vergessen Sie nicht verzögerte Fetches. Background‑Jobs, Queues und Cron‑Tasks können jetzt eine URL speichern und später abrufen — diese Lücke macht den Fehler schwerer erkennbar.
Bei der Suche im Code (und in Request‑Logs) achten Sie auf Parameter‑Namen, die oft URLs tragen, selbst wenn sie harmlos klingen: url, callback, avatarUrl, webhookUrl, redirect.
Ein konkretes Beispiel: Eine Einstellung „Profilfoto von URL“ könnte das Bild serverseitig herunterladen, um es zu skalieren. Wenn der Endpunkt avatarUrl ohne strenge Prüfungen akzeptiert, kann ein Angreifer ihn auf eine interne Adresse zeigen und den Image‑Fetch als Tunnel nutzen.
Kurz‑Threat‑Model für Missbrauch serverseitiger Fetches
Bevor Sie etwas reparieren, klären Sie, was ein Angreifer erreichen will.
Ermitteln Sie zuerst, was Ihr Server aus dem Netzwerk heraus erreichen kann. Das umfasst normalerweise Localhost‑Dienste (Admin‑Panels, Debug‑Ports), private IP‑Bereiche innerhalb Ihrer VPC und Cloud‑Provider‑Metadaten‑Endpunkte, die Zugangsdaten ausgeben können. Wenn die App in einem Container läuft, berücksichtigen Sie interne Servicenamen und Sidecars.
Bestimmen Sie dann, was geschützt werden muss. Die wichtigsten Ziele sind Secrets und Tokens (API‑Keys, Session‑Secrets), Datenbankzugänge, interne Dashboards und alle Dienste, die Anfragen aus dem internen Netz vertrauen.
Schreiben Sie schließlich die Grenzen für jede serverseitige Fetch‑Funktion auf:
- Wer kann sie auslösen (öffentlich, eingeloggter Nutzer, Admin)
- Was darf sie abrufen (exakte Domains oder eine kleine Partnerliste)
- Was darf niemals erreichbar sein (localhost, private IPs, Metadaten)
- Wofür wird die Antwort verwendet (gespeicherte Datei, geparste Daten, gerenderte HTML)
Wenn Sie einen Prototypen von Tools wie Bolt oder Replit geerbt haben, ist dieses schnelle Threat‑Model ein guter erster Schritt vor einer tieferen Prüfung.
Schritt für Schritt: Finde jeden serverseitigen Fetch im Code
SSRF beginnt meist mit einer einfachen Funktion: „fetch diese URL“, „importiere über Link“, „zeige einen Webhook‑Preview“, oder „prüfe, ob diese Seite erreichbar ist“. Bevor Sie Abwehrmaßnahmen einbauen, brauchen Sie ein vollständiges Inventar aller Orte, an denen Ihr Server ausgehende Requests macht.
1) Suche nach ausgehenden Requests (inkl. Wrappern)
Beginnen Sie mit einer Textsuche über das Repo. Achten Sie auf gängige HTTP‑Clients und Hilfsfunktionen, nicht nur auf fetch.
- JavaScript/Node:
fetch,axios,got,superagent,node-fetch - Python:
requests,httpx,urllib,aiohttp - Ruby:
Net::HTTP,Faraday - Shell‑Wrapper:
curl,wget,exec(,spawn(
Suchen Sie außerdem nach Wörtern, die solche Features oft umgeben: "webhook", "callback", "import", "download", "proxy", "scrape".
Wenn die App mit Tools wie Lovable, Bolt, v0, Cursor oder Replit generiert wurde, suchen Sie nach Helper‑Modulen, die Netzwerkaufrufe hinter Namen wie getUrlContent() oder scrapePage() verbergen.
2) Verfolgen Sie, woher die URL kommt
Für jede Aufrufstelle verfolgen Sie die Variable zurück bis zur Quelle. Häufige Quellen sind Request‑Body‑Felder, Query‑Parameter, Header, Datenbankeinträge, Umgebungsvariablen und Template‑Strings, die Nutzereingaben mit einer Basis‑URL kombinieren.
Achten Sie auf indirekte Kontrolle, z. B. nutzerkontrollierte Subdomains, ein pro‑Mandant baseUrl oder eine ID, die in der DB zu einer URL aufgelöst wird.
3) Prüfen Sie versteckte Fetch‑Pfade
Stellen Sie sicher, ob der Client Weiterleitungen folgt, Short‑Links auflöst oder mit alternativen URLs erneut versucht. Eine Anfrage, die sicher aussieht, kann nach einer 302‑Weiterleitung unsicher werden und auf interne Hosts zeigen.
4) Bestätigen Sie das Verhalten und dokumentieren Sie es
Erzeugen Sie gezielt Fehler (ungültige Domain, Timeout, große Antwort) und sehen Sie, was passiert: was wird geloggt, welcher Fehltext wird zurückgegeben und ob Teile der Antwort an den Nutzer reflektiert werden.
Dokumentieren Sie jeden Endpunkt mit seinen Eingaben, Ausgaben, Auth‑Anforderungen und den vorgesehenen Ziel‑Domains. Dieses Inventar ist Ihre Basis für den SSRF‑Fix‑Plan.
Allowlists, die funktionieren: Host, Scheme und Port validieren
Blocklists versagen oft, weil URL‑Regeln knifflig sind und Angreifer sehr ausdauernd sind. Eine strikte Allowlist bekannter, guter Ziele ist der sicherste Standard, besonders wenn Nutzer Inhalte von URLs importieren können.
Parsen und normalisieren Sie die URL, bevor Sie einen Vergleich anstellen. Prüfen Sie nicht nur den Roh‑String. Zerlegen Sie die URL in Scheme, Hostname, Port und Pfad. Vergleichen Sie den normalisierten Hostnamen und den effektiven Port (inklusive Defaults wie 443 für https).
Ein praktischer Allowlist‑Ablauf:
- Parsen Sie die URL mit einem echten URL‑Parser (kein Regex)
- Erzwingen Sie das Scheme
https(oderhttpnur, wenn es wirklich nötig ist) - Verlangen Sie einen Hostnamen (vermeiden Sie nackte IPs, außer Sie erlauben sie ausdrücklich)
- Erlauben Sie nur zugelassene Ports (normalerweise 443, manchmal 80)
- Vergleichen Sie den Hostnamen mit Ihren Allowlist‑Regeln
Schemes und Ports sind übliche Umgehungswege. Wenn Sie nur die Domain prüfen, aber das Scheme ignorieren, kann ein Angreifer in manchen Umgebungen ungewohnte Handler nutzen. Wenn Sie jeden Port erlauben, kann der Angreifer interne Dienste auf ungewöhnlichen Ports sondieren, selbst wenn der Host akzeptabel aussieht.
Subdomains brauchen klare Regeln. Exact‑Match ist am einfachsten (nur api.example.com). Wenn Wildcards nötig sind, setzen Sie echte Grenzen, damit example.com.evil.com nicht durchrutscht.
Behandeln Sie die Allowlist als Konfiguration, nicht als verstreuten Code. Halten Sie sie an einem Ort und loggen Sie, welche Regel gegriffen hat, damit Reviews leichter sind und Ausnahmen nicht unbemerkt bestehen bleiben.
DNS‑Schutz: Rebinding und interne IP‑Tricks stoppen
DNS‑Rebinding ist ein einfacher Trick mit bösem Ausgang. Ihre App validiert https://example.com/image.png. Harmlos. Der Angreifer kontrolliert example.com und ändert, worauf es auflöst, nachdem Sie geprüft haben. Wenn Ihr Server dann verbindet, kann der Host auf 127.0.0.1 oder eine Cloud‑Metadaten‑IP zeigen.
Deshalb reichen einfache Hostname‑Checks nicht aus.
Ein sichereres Muster ist, den Hostnamen selbst aufzulösen, jede IP zu prüfen und nur zu verbinden, wenn alle IPs sicher sind.
Was Sie blockieren sollten (IPv4 und IPv6)
Wenn Sie den Hostnamen auflösen, lehnen Sie Adressen in privaten oder speziellen Bereichen ab, einschließlich privater Netzwerke (RFC1918) und IPv6 ULA, Loopback (127.0.0.1, ::1), Link‑Local (169.254.0.0/16, fe80::/10), reservierte/unspezifizierte Bereiche (wie 0.0.0.0, ::) und IPv4‑gemappte IPv6‑Formen.
Prüfen Sie alle zurückgegebenen Records, nicht nur den ersten. Angreifer nutzen oft mehrere A/AAAA‑Records, wobei einer öffentlich aussieht (Validierung besteht) und ein anderer intern ist.
Kurz vor der Verbindung erneut prüfen
Wenn Ihr HTTP‑Client es unterstützt, lösen und validieren Sie direkt vor dem Öffnen des Sockets und vermeiden Sie spätere DNS‑Auflösungen während Redirects. Wenn Sie das nicht kontrollieren können, halten Sie die Zeit zwischen Validierung und Fetch so kurz wie möglich.
Anfragehärtung: Timeouts, Redirects und sichere Defaults
Selbst mit einer guten Allowlist sind serverseitige HTTP‑Clients oft zu permissiv eingestellt. Ziel ist einfach: schnell fehlschlagen, weniger abrufen und nie Redirects folgen, die an Orte führen, die Sie nicht beabsichtigt haben.
Beginnen Sie damit, strikte Limits für jeden serverseitigen Fetch zu setzen. Wenn eine Anfrage langsam, groß oder unklar ist, behandeln Sie sie als verdächtig und stoppen Sie.
Sicherere Defaults für serverseitige Fetches
Eine Basis, die in der Praxis gut funktioniert:
- Enge Timeouts setzen (getrennte Connect‑ und Read‑Timeouts) und die Antwortgröße begrenzen.
- Redirects für benutzergelieferte URLs deaktivieren oder nur einen Redirect erlauben, wenn das finale Ziel erneut validiert wird.
- Methoden auf GET (und eventuell HEAD) beschränken.
- Sensible Header entfernen. Schicken Sie keine Cookies, API‑Keys oder internen Auth‑Tokens an ausgehende Requests.
- Eine kurze Zusammenfassung loggen (Host, Pfad, Status, Zeit). Vermeiden Sie es, komplette URLs zu loggen, wenn diese Geheimnisse enthalten könnten.
Ein typisches Fehlermuster: Eine „Preview this URL“‑Funktion erlaubt Redirects. Ein Angreifer reicht eine URL ein, die per 302 auf ein internes Admin‑Panel oder eine Cloud‑Metadaten‑Adresse weiterleitet. Ihre App folgt und leitet versehentlich einen Authorization‑Header weiter, der intern wiederverwendet wird.
Fehler: Nutzer schützen, Entwickler informieren
Wenn ein Fetch blockiert oder fehlschlägt, zeigen Sie dem Nutzer eine generische Meldung (z. B. „Konnte die URL nicht abrufen“). Detaillierte Gründe (Timeout vs Redirect vs geblockter Host) nur in internen Logs ablegen. Detaillierte UI‑Fehler lehren Angreifer oft, welche Regeln Sie verwenden.
Häufige Fehler, die SSRF offenlassen
SSRF‑Bugs überleben oft „grundlegende“ Fixes. Das Ergebnis wirkt geschützt, aber ein Angreifer kann Ihren Server trotzdem interne Dienste oder Metadaten erreichen lassen.
Viele Teams beginnen mit String‑Checks wie startsWith('https://'). Das scheitert bei fummeligen URLs, ungewöhnlichen Encodings oder URLs, die zwar sicher aussehen, aber gefährlich auflösen.
Weitere häufige Fehler:
- Redirects zulassen, ohne jeden Hop erneut zu prüfen
- Den Host validieren, aber später mit einem anderen Wert verbinden
- Nur
127.0.0.1blocken und IPv6 Loopback (::1),0.0.0.0und private Bereiche wie10.*,172.16.*,192.168.*vergessen - DNS‑Rebinding‑Schutz überspringen (einmal prüfen, später abrufen)
Wenn Sie gefetchte Inhalte direkt an den Browser zurückgeben, entsteht ein weiteres Problem: Ihr Server wird zum Proxy. Ohne strikte Limits können Angreifer große Dateien ziehen, um Kosten zu verursachen, oder unerwartete Content‑Typen liefern, die Ihr Frontend falsch verarbeitet.
Kurz‑Checklist vor dem Launch für SSRF‑Abwehr
Vor dem Launch: Gehen Sie davon aus, dass jemand versuchen wird, jeden serverseitigen Fetch in einen Tunnel zu verwandeln.
Inventarisieren Sie jeden Ort, an dem ein Nutzer (oder ein anderes System) eine URL, einen Host oder eine entfernte Datei referenzieren kann. Dazu gehören offensichtliche Felder wie „Import from URL“, sowie Webhook‑Tester, Image‑Previewer, PDF‑Generatoren, Feed‑Reader und Integrationen, die Callback‑URLs akzeptieren.
Validieren Sie in Staging einige essentielle Punkte:
- Jeder Endpunkt und Background‑Job, der eine URL/Hostname akzeptiert, ist gelistet.
- Die Allowlist wird serverseitig für jeden Fetch durchgesetzt (nicht nur in der UI).
- Scheme, Host und Port werden vor der Anfrage validiert.
- DNS/IP‑Checks blockieren interne Bereiche für IPv4 und IPv6 und die Prüfung erfolgt nahe am Verbindungszeitpunkt.
- Timeouts, Limits für Antwortgrößen und Redirect‑Regeln sind gesetzt.
Für einfache Tests mit „bekannten schlechten Zielen“ probieren Sie localhost, eine private IP, einen internen Hostnamen aus Ihrer Umgebung und die übliche Cloud‑Metadaten‑Adresse. Sie wollen nichts ausnutzen, sondern nur bestätigen, dass Ihre App die Anfrage ablehnt und keine hilfreichen Fehlermeldungen nach außen gibt.
Beispiel: Ein „Import from URL“ sicher machen
Ein häufiges Muster ist eine Komfortfunktion wie „Import avatar from URL“. Ein Generator legt einen Backend‑Endpunkt an, der eine URL entgegennimmt, das Image serverseitig herunterlädt und speichert.
Der Exploit‑Pfad ist vorhersehbar. Ein Angreifer reicht eine URL ein, die gar kein Image‑Host ist, sondern eine interne Adresse wie einen Metadaten‑Service, ein privates Admin‑Panel oder einen HTTP‑Datenbankport, der nur intern erreichbar ist. Wenn Ihr Server das abruft, kann der Angreifer Geheimnisse, interne Hostnamen erfahren oder HTML zurückbekommen, wenn Sie die Antwort speichern oder anzeigen.
Machen Sie den Fetch langweilig und strikt:
- Allowlisten Sie nur spezifische Image‑Hosts, die Sie kontrollieren oder denen Sie vertrauen.
- Erzwingen Sie https und blockieren Sie nicht‑standardmäßige Ports.
- Lösen Sie DNS selbst auf und blockieren Sie private, Loopback‑ und Link‑Local‑IPs, bevor Sie verbinden.
- Redirects deaktivieren oder nur einen einzelnen Redirect erlauben, der dennoch die Prüfung besteht.
- Enge Timeouts und eine kleine Max‑Download‑Größe setzen und Content‑Type sowie Magic‑Bytes prüfen.
Fügen Sie Monitoring hinzu, damit Sie Probing bemerken. Es zeigt sich oft als viele fehlgeschlagene Requests über verschiedene Hosts hinweg, wiederholte Versuche, 169.254.169.254 oder localhost zu erreichen, oder Spitzen bei geblockten DNS‑Ergebnissen und Redirect‑Blocks.
Nächste Schritte: Fetch‑Funktionen vereinfachen und gezielte Prüfung
Wenn Sie auch nur einen serverseitigen Fetch finden, der eine nutzerangegebene URL erreichen kann, gehen Sie davon aus, dass noch mehr existieren. Die schnellste Risikominderung ist, die Angriffsfläche zu verkleinern.
Überlegen Sie, welche Fetch‑Funktionen wirklich nötig sind. Viele Apps liefern Extras wie „Import from URL“, „Preview this link“, „fetch Open Graph data“, „webhook tester“, „image proxy“ oder „connect to any API“. Jede ist ein potenzieller SSRF‑Einstiegspunkt. Wenn eine Funktion nicht wesentlich ist, ist Entfernen oft sicherer als ewiges Härten.
Setzen Sie dann einige Regeln, die für jeden serverseitigen Fetch gelten müssen:
- Nur genehmigte Schemes, Ports und Hosts sind erlaubt (keine „beliebige URL").
- DNS‑ und IP‑Prüfungen erfolgen zur Anfragezeit, nicht nur einmal bei der Validierung.
- Timeouts, Redirect‑Limits und Antwortgrößenbegrenzungen sind immer aktiv.
- Fetches zentral in einem Helper bündeln, damit neue Endpunkte die Schutzmaßnahmen nicht umgehen.
Wenn Sie eine schnelle externe Prüfung für eine KI‑generierte Codebase möchten, kann FixMyMess (fixmymess.ai) den Code analysieren und Sicherheits‑Härtungen für Prototypen liefern, die mit Lovable, Bolt, v0, Cursor oder Replit erstellt wurden. Sie bieten auch ein kostenloses Code‑Audit an, um SSRF‑ähnliche Fetch‑Risiken und andere wirkungsvolle Probleme vor dem Release zu identifizieren.
Häufige Fragen
Was ist SSRF in einfachen Worten?
SSRF bedeutet, dass Ihr Backend (oder eine serverlose Funktion) dazu gebracht werden kann, eine URL abzurufen, die ein Angreifer kontrolliert. Weil die Anfrage von Ihrem Server kommt, kann sie interne Dienste, private IPs oder Cloud‑Metadaten erreichen, auf die normale Nutzer keinen Zugriff haben.
Warum haben KI-erzeugte Apps so häufig SSRF-Fehler?
KI‑generierte Prototypen fügen oft „komfortable“ Funktionen ein, die URLs serverseitig abrufen — etwa Link‑Previews, Image‑Proxies, Import‑from‑URL, Webhook‑Tester oder Screenshot/PDF‑Generatoren. Sie funktionieren für Demos, werden aber meist ohne strikte Allowlists, DNS/IP‑Prüfungen und Redirect‑Kontrollen ausgeliefert.
Welche Endpunkte sollte ich zuerst auf SSRF prüfen?
Suche nach Endpunkten oder Jobs, die Felder wie url, webhookUrl, callback, avatarUrl, redirect oder eine "Integrationstest"‑Adresse akzeptieren. Überprüfe auch Background‑Worker und Cron‑Jobs, die jetzt eine URL speichern und später abrufen — SSRF kann sich außerhalb normaler Request‑Pfade verstecken.
Wie finde ich jeden serverseitigen Fetch in meinem Codebase?
Beginnen Sie mit einer Bestandsaufnahme aller ausgehenden Requests im Code: suche nach HTTP‑Clients (z. B. fetch/axios/requests) und internen Hilfsfunktionen, die sie umschließen. Verfolge für jede Stelle, woher die URL kommt, und prüfe, ob Benutzereingaben sie direkt oder indirekt beeinflussen (z. B. über DB‑Felder oder Mandanten‑Konfiguration).
Sollte ich eine Allowlist oder eine Blocklist zur Verhinderung von SSRF verwenden?
Verwenden Sie standardmäßig eine Allowlist mit exakt erwarteten Domains und lehnen Sie alles andere ab. Parsen und normalisieren Sie die URL mit einem echten Parser, verlangen Sie https und erlauben Sie nur sichere Ports (normalerweise 443, manchmal 80), damit Angreifer nicht über ungewöhnliche Ports interne Dienste sondieren können.
Wie schütze ich mich gegen DNS‑Rebinding und Tricks, bei denen es auf localhost auflöst?
DNS kann sich nach der Validierung ändern. Lösen Sie den Hostnamen selbst auf, prüfen Sie jede zurückgegebene IP und lehnen Sie private, Loopback‑, Link‑Local‑ und andere spezielle Bereiche für IPv4 und IPv6 ab. Führen Sie diese Prüfung möglichst nah am Zeitpunkt der tatsächlichen Verbindung durch.
Was sind die sichersten Standardeinstellungen für serverseitige HTTP‑Anfragen?
Engere Timeouts, eine Begrenzung der maximalen Antwortgröße und die Behandlung von Redirects als gefährlich für benutzer‑gelieferte URLs. Sicherste Voreinstellung ist: keine Redirects; falls nötig, nach jedem Hop die Ziel‑URL erneut prüfen und niemals interne Auth‑Header oder Cookies an den Remote‑Host weiterleiten.
Welche häufigen SSRF-„Fixes“ lassen mich trotzdem verwundbar?
Einfache String‑Checks wie startsWith('https://') und reine "block localhost"‑Regeln übersehen Umgehungen wie IPv6‑Loopback, private Bereiche, Redirects und DNS‑Änderungen zwischen Validierung und Verbindung. Ein weiterer Fehler ist, einen Host zu validieren, aber letztlich mit einem anderen, später ermittelten Wert zu verbinden.
Wie kann ich schnell testen, ob meine SSRF‑Abwehr wirklich funktioniert?
Versuchen Sie bekannte Zieladressen wie localhost, private IP‑Bereiche und die typische Cloud‑Metadaten‑IP und bestätigen Sie, dass Ihre App diese blockiert, ohne dem Benutzer detaillierte Fehlergründe zu verraten. Testen Sie außerdem das Redirect‑Verhalten und stellen Sie sicher, dass das finale Ziel weiterhin validiert wird, nicht nur die anfängliche URL.
Kann FixMyMess helfen, eine KI-generierte Codebase gegen SSRF zu härten?
Wenn Ihre App mit Tools wie Lovable, Bolt, v0, Cursor oder Replit erzeugt wurde, ist es leicht, einen versteckten Fetch‑Pfad oder Background‑Job zu übersehen. FixMyMess (fixmymess.ai) kann ein kostenloses Code‑Audit durchführen, um serverseitige Fetches zu inventarisieren und dann Allowlists, DNS/IP‑Prüfungen, Redirect‑Regeln und Timeouts zu implementieren.