Strukturierte Protokollierung für 5‑Minuten-Debugging in Produktion
Strukturierte Protokollierung macht Produktionsfehler schneller reproduzierbar. Fügen Sie Request-IDs, Error-Boundaries und kopierfertige Log-Patterns hinzu, damit Debugging in 5 Minuten möglich ist.
Warum sich Produktionsfehler unmöglich reproduzierbar anfühlen
Ein Produktions-Bug-Report sieht oft so aus: „Es ist kaputt gegangen, als ich den Button gedrückt habe.“ Kein Screenshot, keine genaue Zeit, keine Nutzer-ID und kein Hinweis, welches Gerät oder welcher Browser verwendet wurde. Wenn Sie es dann selbst versuchen, funktioniert es einwandfrei.
Produktion ist chaotisch, weil die exakten Bedingungen schwer nachzubilden sind. Echte Nutzer haben unterschiedliche Accounts, verschiedene Daten, instabile Netze, mehrere Tabs offen und veraltete Sessions. Ein seltener Timing-Fehler kann zu einem Absturz führen, den Sie in Staging nie sehen.
Konsole-Ausgaben und vage Fehlermeldungen überleben diese Umgebung nicht. Die Konsole eines Nutzers ist nicht Ihre Konsole, und selbst wenn Sie Logs sammeln, sagt „etwas ist fehlgeschlagen“ nicht, welche Anfrage, welches Feature-Flag oder welcher Upstream-Dienst es ausgelöst hat. Schlimmer noch: ein einzelner unbehandelter Fehler kann die App stoppen, bevor sie die eine Information loggt, die Sie gebraucht hätten.
Das Ziel ist einfach: Wenn ein Bericht eingeht, sollten Sie binnen Minuten drei Fragen beantworten können:
- Was ist passiert (das Ereignis und die Nutzeraktion)
- Wo ist es passiert (die genaue Anfrage, Seite und Komponente)
- Warum ist es passiert (der Fehler plus der wichtige Kontext)
Deshalb ist strukturierte Protokollierung wichtig. Statt zufällige Sätze zu schreiben, loggen Sie konsistente Ereignisse mit denselben Feldern jedes Mal, sodass Sie filtern und die Geschichte über Dienste und Bildschirme hinweg verfolgen können.
Sie brauchen dafür keine große Umstellung. Kleine Änderungen addieren sich schnell: Fügen Sie jeder Anfrage eine Request-ID hinzu, nehmen Sie sie in jede Logzeile auf und fangen Sie Abstürze mit Error-Boundaries ab, damit Sie beim UI-Fehler noch Kontext erfassen.
Hier ein realistisches Beispiel. Ein Gründer sagt: „Checkout dreht manchmal ewig.“ Ohne bessere Logs raten Sie: Zahlungsanbieter? Datenbank? Auth? Mit Request-IDs und konsistenten Ereignissen können Sie eine ID suchen und sehen: checkout_started, payment_intent_created, dann ein Timeout bei inventory_reserve, gefolgt von einem UI-Fehler. Jetzt haben Sie einen einzelnen Pfad, den Sie reproduzieren können.
Wenn Sie eine AI-generierte App geerbt haben, in der Logs zufällig oder fehlend sind, ist das meistens eine der Maßnahmen mit der höchsten Rendite. Teams wie FixMyMess starten oft mit einem schnellen Audit dessen, was Sie heute nachverfolgen können, und fügen dann das minimale Logging hinzu, damit der nächste Bug eine 5-Minuten-Untersuchung statt einer Woche Rätselraten wird.
Was strukturierte Logs in einfachen Worten sind
Plain-Text-Logs sind die Art, die Sie wahrscheinlich schon gesehen haben: ein Satz in der Konsole wie „User login failed“. Sie sind leicht zu schreiben, aber schwer zu nutzen, wenn in Produktion etwas kaputtgeht. Jeder formuliert Nachrichten anders, Details werden weggelassen und Suchen werden zu Ratespielen.
Strukturierte Protokollierung bedeutet, dass jede Logzeile derselben Form folgt und wichtige Details als benannte Felder enthält (häufig in JSON). Statt eines Satzes speichern Sie ein Ereignis plus den Kontext drumherum. So können Sie Logs wie Daten filtern, gruppieren und vergleichen.
Ein gutes Log sollte ein paar grundlegende Fragen beantworten können:
- Wer war betroffen (welcher Nutzer oder welches Konto)
- Was ist passiert (die Aktion oder das Ereignis)
- Wo ist es passiert (Service, Route, Screen, Funktion)
- Wann ist es passiert (Timestamp wird meist automatisch ergänzt)
- Ergebnis (Erfolg oder Fehler, und warum)
Hier der Unterschied in der Praxis.
Plain-Text (schwer zu durchsuchen):
Login failed for user
Strukturiert (einfach zu filtern und zu gruppieren):
{
"level": "warn",
"event": "auth.login",
"userId": "u_123",
"requestId": "req_8f31",
"route": "/api/login",
"status": 401,
"error": "INVALID_PASSWORD"
}
Die nützlichsten Felder sind meist die unspektakulären, die Sie später gerne gehabt hätten: event, userId (oder Konto-/Team-ID), requestId und status. Wenn Sie nur vier Felder hinzufügen, fangen Sie dort an. Sie erlauben die Antwort auf: „Welche exakte Anfrage hat dieser Nutzer geschickt und was hat die App zurückgegeben?“
Struktur ist es, die Debugging in Produktion schnell macht. Sie können schnell alle event = auth.login-Fehler suchen, nach status gruppieren oder jedes Log mit requestId = req_8f31 ziehen, um die ganze Geschichte eines Nutzerproblems zu sehen. Das ist der Unterschied zwischen 30 Minuten Scrollen und dem Finden des Fehlers in 5.
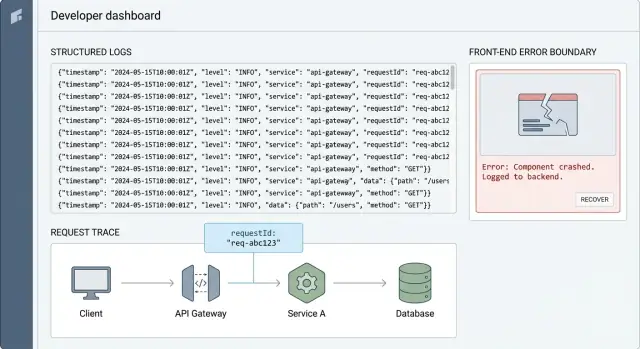
Request-IDs: der schnellste Weg, ein Nutzerproblem zu verfolgen
Eine Request-ID ist ein kurzer eindeutiger String (wie req_7f3a...), den Sie einer einzelnen Nutzeraktion zuordnen. Der Punkt ist simpel: Sie verbindet alles, was für diese Aktion passiert ist — vom Frontend-Klick über die API bis zur Datenbankabfrage und zurück.
Ohne sie wird Debugging in Produktion zu Ratespielerei. Sie suchen Logs nach Zeit, Nutzer oder Endpoint und haben am Ende einen Haufen nicht zusammenhängender Meldungen. Mit einer Request-ID filtern Sie auf eine Story und lesen sie der Reihenfolge nach.
Das ist Korrelation: dieselbe ID erscheint in jeder Logzeile, die zur selben Anfrage gehört. Sie ist der Klebstoff, der strukturierte Protokollierung unter Druck überhaupt nutzbar macht.
Wo die Request-ID erzeugt werden sollte
Erstellen Sie die ID so früh wie möglich und geben Sie sie durch jede Schicht weiter.
- Am Edge (CDN / Load Balancer) oder API-Gateway, wenn Sie eines haben
- Andernfalls am Backend-Einstiegspunkt (die erste Middleware, die die Anfrage behandelt)
- Wenn keines vorhanden ist (häufig bei AI-generierten Prototypen), erzeugen Sie sie im Server-Handler, bevor weitere Arbeit geschieht
Sobald sie erzeugt ist, geben Sie sie auch im Response-Header an den Client zurück. Wenn ein Nutzer sagt „es ist fehlgeschlagen“, können Sie nach dieser ID fragen oder sie im Support-Interface anzeigen.
Wann wiederverwenden vs. neu erzeugen
Verwenden Sie dieselbe Request-ID für die gesamte Lebenszeit einer Anfrage, einschließlich interner Aufrufe, die sie auslöst. Wenn Ihre API einen anderen Dienst aufruft, geben Sie die ID mit, damit die Spur nicht abreißt.
Erzeugen Sie eine neue ID, wenn Sie nicht mehr dieselbe Anfrage behandeln:
- Retries: behalten Sie die ursprüngliche ID als Parent, geben Sie aber jedem Versuch eine eigene attempt-ID (so sehen Sie wiederholte Fehler)
- Background-Jobs: erstellen Sie eine neue Job-ID und speichern Sie die ursprüngliche Request-ID als „trigger“ (damit Sie den Job zur Nutzeraktion zurückverknüpfen können)
Ein einfaches Beispiel: ein Nutzer klickt auf „Bezahlen“ und bekommt einen Fehler. Das Frontend loggt requestId=abc123, die API loggt dasselbe abc123 mit Route und Nutzer-ID, und die Datenbankschicht loggt abc123 neben der Abfrage und der Dauer. Wenn die Zahlung fehlschlägt, können Sie abc123 aufrufen und genau sehen, wo es gebrochen ist — meist in Minuten.
Wie man Request-IDs Ende-zu-Ende hinzufügt (Schritt für Schritt)
Eine Request-ID ist ein kurzer eindeutiger Wert, der eine Nutzeraktion durch Ihr System begleitet. Wenn Support sagt „Checkout schlug um 14:14 fehl“, lässt die Request-ID Sie jede relevante Logzeile in Sekunden abrufen.
Schritt-für-Schritt-Setup
Nutzen Sie dasselbe grundlegende Muster in jedem Stack:
- Erzeugen (oder akzeptieren) Sie eine Request-ID am Server-Edge. Wenn der Client bereits eine sendet (häufig
X-Request-Id), behalten Sie sie. Falls nicht, erzeugen Sie eine, sobald die Anfrage in Ihrer API ankommt. - Speichern Sie sie im Request-Kontext, damit jedes Log sie enthält. Legen Sie sie irgendwo ab, wo Ihr Code sie lesen kann, ohne sie durch jede Funktion zu reichen. Viele Frameworks haben request-local storage. Falls nicht, hängen Sie sie ans Request-Objekt.
- Geben Sie sie im Response an den Client zurück. Fügen Sie einen Response-Header wie
X-Request-Idhinzu. Das gibt Support und Nutzern etwas Konkretes zum Kopieren. - Leiten Sie sie an Downstream weiter. Fügen Sie denselben Header bei ausgehenden HTTP-Calls hinzu, nehmen Sie sie in Queue/Job-Payloads auf und geben Sie sie an Datenbank-Wrapper weiter, damit langsame Queries zurückverfolgbar sind.
- Fügen Sie sie optional in Fehlerberichte ein. Wenn Sie Exceptions erfassen, hängen Sie
requestIdan, damit Crash-Reports und Logs zusammenpassen. Bei nutzerseitigen Fehlern können Sie einen kurzen „Support-Code“ anzeigen, der von der Request-ID abgeleitet ist.
Hier ein einfaches Node/Express-Beispiel. Die Idee ist in anderen Sprachen dieselbe:
import crypto from "crypto";
app.use((req, res, next) =\u003e {
const incoming = req.header("X-Request-Id");
req.requestId = incoming || crypto.randomUUID();
res.setHeader("X-Request-Id", req.requestId);
next();
});
function log(req, level, message, extra = {}) {
console.log(JSON.stringify({
level,
message,
requestId: req.requestId,
...extra
}));
}
Sobald das eingerichtet ist, wird strukturierte Protokollierung sofort nützlicher: jedes Ereignis kann nach requestId durchsucht werden, selbst wenn das Problem mehrere Dienste überspringt.
Wenn Sie eine AI-generierte App geerbt haben, in der Logs zufällige Strings sind (oder komplett fehlen), ist das Hinzufügen von Request-IDs eine der schnellsten Reparaturen, weil es Debugging verbessert, ohne die Business-Logik zu ändern.
Ereignisse gestalten, die Sie wirklich durchsuchen können
Gute Logs lesen sich wie eine Timeline. Wenn etwas schiefgeht, sollten Sie beantworten können: was ist passiert, bei welcher Anfrage, und welche Entscheidung hat der Code getroffen.
Bei strukturierter Protokollierung bedeutet das: jede Logzeile ist ein kleiner Datensatz mit denselben Feldern, nicht ein Freitextsatz. Konsistenz ist es, die Suche funktionieren lässt.
Beginnen Sie mit einer kleinen Menge an Ereignisnamen
Wählen Sie einige Kern-Ereignistypen und verwenden Sie sie im ganzen App. Vermeiden Sie jede Woche einen neuen Namen für dasselbe.
Hier sind gängige Ereignistypen, die langfristig nützlich bleiben:
- request_started
- request_finished
- db_query
- auth_failed
- error
Benennen Sie Ereignisse in Kleinschreibung mit Unterstrichen und halten Sie die Bedeutung stabil. Wenn Sie z. B. bereits auth_failed haben, fügen Sie nicht später login_denied und sign_in_rejected hinzu, es sei denn, sie meinen wirklich etwas anderes.
Loggen Sie eine Entscheidung, nicht jede Codezeile
Eine einfache Regel: loggen Sie, wenn das Programm eine Entscheidung trifft, die das Ergebnis verändert. Genau diesen Punkt werden Sie später finden wollen.
Schlecht: jede Zeile um einen Datenbankaufruf zu loggen.
Besser: ein einzelnes db_query-Ereignis, das sagt, was wichtig war: welches Modell/Tabelle (nicht rohes SQL), ob es erfolgreich war und wie lange es dauerte.
Immer Ergebnisfelder einschließen
Machen Sie es leicht, nach Fehlern und langsamen Pfaden zu filtern. Fügen Sie ein paar Felder hinzu, die bei den meisten Ereignissen auftauchen:
- ok: true oder false
- errorType: eine kurze Kategorie wie ValidationError, AuthError, Timeout
- durationMs: für alles, was gemessen wird (Requests, DB, externe APIs)
- statusCode: für HTTP-Antworten
Ein realistisches Beispiel: Wenn ein Nutzer meldet „Checkout schlägt fehl“, sollten Sie nach event=auth_failed oder ok=false suchen können, dann nach statusCode=401 oder errorType=AuthError filtern und schließlich den langsamen Teil durch Sortieren nach durationMs finden.
Wenn Sie AI-generierten Code erben, fehlt das oft oder ist inkonsistent. Bei FixMyMess ist eines der ersten Reparaturen, Event-Namen und Felder zu normalisieren, damit Produktions-Debugging kein Ratespiel mehr ist.
Log-Level und Volumen, ohne im Rauschen zu ersticken
Wenn jedes Ereignis als Fehler geloggt wird, verlieren Sie das Vertrauen in Ihre Logs. Wenn Sie alles als Debug loggen, vergraben Sie den einen Hinweis, den Sie gebraucht hätten. Gutes Produktions-Debugging beginnt mit einem einfachen Versprechen: die Standard-Logs sollten erklären, was passiert ist, ohne Ihr System zu überfluten.
Wofür die Levels da sind
Denken Sie an Log-Level als Sortiersystem für Dringlichkeit und Erwartbarkeit. In strukturierter Protokollierung ist level nur ein weiteres Feld, nach dem Sie filtern können.
- DEBUG: Details, die Sie nur bei einer Untersuchung sehen wollen. Beispiel: die Antwortzeit eines Downstream-APIs oder der genaue Zweig, den Ihr Code genommen hat.
- INFO: Normale Meilensteine. Beispiel: „user signed in“, „payment intent created“, „job completed“.
- WARN: Etwas ist schiefgelaufen, aber die App kann sich erholen. Beispiel: ein Retry, ein Fallback-Wert, ein Drittanbieter gibt 429 zurück.
- ERROR: Die Operation ist fehlgeschlagen und benötigt Aufmerksamkeit. Beispiel: eine unbehandelte Exception, ein fehlgeschriebener DB-Write oder eine Anfrage, die 5xx zurückgibt.
Eine praktische Regel: Wenn es jemanden nachts wecken würde, wenn es ansteigt, ist es wahrscheinlich ERROR. Wenn es hilft, eine Nutzerbeschwerde später zu erklären, ist es vermutlich INFO. Wenn es nur nützlich ist, während ein Ticket offen ist, ist es DEBUG.
Volumen unter Kontrolle halten
High-Traffic-Endpunkte können schnell Lärm erzeugen, besonders in AI-generierten Apps, in denen Logging oft überall ohne Plan hinzugefügt wird. Statt Logs zu löschen, kontrollieren Sie den Firehose.
Verwenden Sie einfache Taktiken:
- Sampling: Loggen Sie 1% der erfolgreichen Requests, aber 100% der WARN und ERROR. Sampling ist besonders nützlich bei Health-Checks, Polling-Endpoints und chatty Hintergrund-Jobs.
- Rate Limits: Wenn dieselbe Warnung immer wiederkommt, loggen Sie sie einmal pro Minute mit einem Zähler.
- Ein Ereignis pro Ergebnis: Bevorzugen Sie ein einziges "request finished"-Log mit Dauer und Status statt 10 kleiner Logs.
Überwachen Sie schließlich die Performance. Vermeiden Sie schwere String-Builds oder JSON-Serialisierung in heißen Pfaden. Loggen Sie stabile Felder (wie route, status, duration_ms) und berechnen Sie teure Details nur, wenn das Level aktiviert ist.
Error-Boundaries: Abstürze abfangen und nützlichen Kontext behalten
Eine Error-Boundary ist ein Sicherheitsnetz im UI. Wenn eine Komponente beim Rendern, in einem Lifecycle-Method oder Constructor abstürzt, fängt die Boundary das ab, zeigt einen Fallback-Screen und — am wichtigsten — zeichnet auf, was passiert ist. So verwandeln Sie eine leere Seite und eine vage Beschwerde in etwas, das Sie reproduzieren können.
Was sie fängt: synchrone UI-Fehler, die beim Aufbau der Seite auftreten. Was sie nicht fängt: Fehler in Event-Handlern, Timeouts oder die meiste asynchrone Logik. Dafür brauchen Sie weiterhin normale try/catch-Blöcke und Handling für abgelehnte Promises.
Was beim UI-Absturz geloggt werden sollte
Wenn die Boundary auslöst, loggen Sie ein einzelnes Ereignis mit genug Kontext, um ähnliche Fehler zu gruppieren und zu suchen. Bei strukturierter Protokollierung bleiben Sie bei konsistenten Schlüsseln.
Erfassen Sie:
route(der aktuelle Pfad) und relevanten UI-Status (Tab, geöffnetes Modal, Wizard-Schritt)component(wo es abgestürzt ist) underrorName+messageuserAction(was der Nutzer gerade getan hat, z. B. "clicked Save")requestId(falls Sie eine vom Server oder API-Client haben)build-Info (App-Version, Environment), damit Sie es einer Release zuordnen können
Hier eine einfache Form:
log.error("ui_crash", {
route,
component,
userAction,
requestId,
errorName: error.name,
message: error.message,
stack: error.stack,
appVersion,
});
Was Nutzer sehen sollten vs. was Entwickler brauchen
Die Nutzer-Nachricht sollte ruhig und sicher sein: „Etwas ist schiefgelaufen. Bitte Seite neu laden. Wenn es weiter auftritt, kontaktieren Sie den Support.“ Vermeiden Sie rohe Fehltexte, Stacktraces oder IDs, die interne Details offenlegen könnten.
Entwickler hingegen brauchen den vollen Kontext in den Logs. Ein gutes Muster ist, im UI einen kurzen "Fehlercode" anzuzeigen (z. B. ein Zeitstempel oder zufälliges Token) und das detaillierte Ereignis mit demselben Token zu loggen.
Auf dem Server verwenden Sie äquivalente Sicherheitsnetze: einen globalen Fehler-Handler für Requests sowie Handler für unhandled promise rejections und uncaught exceptions. Hier versagen viele AI-generierte Apps, weshalb Teams wie FixMyMess oft „stille“ Abstürze ohne requestId und ohne nützliche Logs finden.
Wenn Sie das einmal eingerichtet haben, wird ein Produktions-Crash kein Rätsel mehr sein, sondern ein durchsuchbares Ereignis, das Sie schnell beheben können.
Sicheres Logging: Vermeiden Sie das Leaken von Geheimnissen und persönlichen Daten
Gute Logs helfen, Bugs schnell zu beheben. Schlechte Logs schaffen neue Probleme: geleakte Passwörter, offengelegte API-Keys und persönliche Daten, die Sie nie speichern wollten. Eine einfache Regel funktioniert gut: loggen Sie, was Sie brauchen, um Verhalten zu debuggen — nicht, was ein Nutzer getippt hat.
Loggen Sie niemals diese Dinge (auch nicht „nur fürs Debugging“): Passwörter, Session-Cookies, Auth-Tokens (JWTs), API-Keys, OAuth-Codes, private Keys, vollständige Kreditkartennummern, CVVs, Bankdaten und vollständige Kopien von Dokumenten. Behandeln Sie auch personenbezogene Daten als sensibel: E‑Mail-Adressen, Telefonnummern, Wohnadressen, IPs (in vielen Fällen) und Freitextfelder, die alles enthalten könnten.
Sicherere Alternativen, die trotzdem Debuggen erlauben
Statt ganze Payloads zu dumpen, loggen Sie kleine, stabile Kontextstücke, die helfen, das Problem zu reproduzieren.
- Redact: ersetzen Sie Secrets automatisch durch "[REDACTED]".
- Partielle Werte: loggen Sie nur die letzten 4 Zeichen eines Tokens oder einer Karte.
- Hash: loggen Sie einen Einweg-Hash einer E-Mail, um Ereignisse zu korrelieren, ohne die E-Mail zu speichern.
- Verwenden Sie IDs: userId, orderId, invoiceId und requestId reichen meist aus.
- Zusammenfassen: loggen Sie Counts und Typen ("3 items", "payment_method=card") statt des kompletten Objekts.
Beispiel: Statt eine gesamte Checkout-Anfrage zu loggen, loggen Sie orderId, userId, cartItemCount und paymentProviderErrorCode.
Warum AI-generierter Code Geheimnisse leakt (und wie man es stoppt)
AI-generierte Prototypen loggen oft ganze Request-Bodies, Header oder Environment-Variablen im "Debug-Mode". Das ist in Produktion riskant und leicht zu übersehen, weil es „funktioniert“. Achten Sie auf typische Stolperfallen: console.log(req.headers), print(request.json()), das Logging von process.env oder das Loggen des kompletten Error-Objekts, das Header enthält.
Schützen Sie sich mit zwei Gewohnheiten: sanitizen Sie vor dem Loggen und blockieren Sie gefährliche Keys per Default. Erstellen Sie ein kleines "safe logger"-Wrapper, das Felder wie password, token, authorization, cookie, apiKey und secret automatisch redacted, egal wo sie auftauchen.
Behalten Sie außerdem eine Retention-Perspektive. Bewahren Sie detaillierte Logs nur so lange auf, wie Sie sie wirklich für Debugging und Sicherheitsprüfungen benötigen. Behalten Sie Zusammenfassungen länger, löschen Sie rohe Ereignisdaten früher und machen Sie es einfach, Logs für einen Nutzer zu löschen, wenn erforderlich.
Ein realistisches 5‑Minuten-Debugging-Beispiel
Ein Nutzer meldet: „Ich kann mich nicht einloggen. Auf meinem Laptop funktioniert es, aber in Produktion nicht.“ Lokal können Sie es nicht reproduzieren, und der einzige Hinweis ist ein Zeitstempel und seine E-Mail.
Mit strukturierter Protokollierung und Request-IDs können Sie von der Nutzer-Meldung rückwärts auf eine einzelne Anfrage gehen.
Minute 1: die Anfrage finden
Ihr Support- oder App-UI zeigt einen kurzen "Support-Code" (das ist nur die requestId). Falls Sie dieses UI noch nicht haben, können Sie trotzdem in Logs nach dem Nutzer-Identifier (gehashte E-Mail) um die gemeldete Zeit suchen und die requestId aus dem ersten passenden Ereignis ziehen.
Minuten 2–4: den Fluss verfolgen und den fehlerhaften Schritt finden
Filtern Sie Logs nach requestId=9f3c... und Sie haben eine saubere Story: ein Login-Versuch Ende-zu-Ende über mehrere Dienste.
{"level":"info","event":"auth.login.start","requestId":"9f3c...","userHash":"u_7b1...","ip":"203.0.113.10"}
{"level":"info","event":"auth.oauth.callback","requestId":"9f3c...","provider":"google","elapsedMs":412}
{"level":"error","event":"db.query.failed","requestId":"9f3c...","queryName":"getUserByProviderId","errorCode":"28P01","message":"password authentication failed"}
{"level":"warn","event":"auth.login.denied","requestId":"9f3c...","reason":"dependency_error","status":503}
Die dritte Zeile ist die ganze Antwort: die Datenbank hat die Verbindung in Produktion abgelehnt. Weil das Log einen stabilen event-Namen und Felder wie queryName und errorCode hat, verschwenden Sie keine Zeit damit, Textwände zu lesen oder zu raten, welcher Stacktrace zu diesem Nutzer gehört.
Wenn Sie außerdem eine Error-Boundary auf dem Client haben, sehen Sie möglicherweise ein passendes Ereignis wie ui.error_boundary.caught mit derselben requestId (als Header weitergegeben) und dem betroffenen Screen. Das bestätigt die sichtbar für den Nutzer auftretende Auswirkung, ohne auf Screenshots angewiesen zu sein.
Minute 5: Logs in einen reproduzierbaren Test verwandeln
Jetzt können Sie einen engen Reproduktionsfall schreiben, der der Realität entspricht:
- Nutzen Sie denselben Login-Pfad (Google-Callback)
- Testen Sie gegen eine production-ähnliche Konfiguration (korrekte DB-User/Secret-Quelle)
- Führen Sie die einzelne fehlerhafte Operation (
getUserByProviderId) aus - Prüfen Sie das erwünschte Verhalten (einen klaren 503 mit einer sicheren Nachricht zurückgeben)
In vielen AI-generierten Codebasen, die wir bei FixMyMess sehen, passiert genau dieses Problem, weil Secrets lokal hardcodiert sind, aber in Produktion anders bezogen werden. Der Sinn der Logs ist nicht mehr Daten, sondern die richtigen Felder, damit Sie von einer Nutzerbeschwerde zu einem fehlerhaften Schritt gelangen — schnell.
Kurze Checkliste, häufige Fehler und nächste Schritte
Wenn ein Produktionsproblem auftritt, wollen Sie Logs, die drei Fragen schnell beantworten: was ist passiert, wem und wo ist es gebrochen. Diese Checkliste hält strukturierte Protokollierung unter Druck nützlich.
Kurze Checkliste
- Jede Anfrage erhält eine
requestId, die in jeder Logzeile dieser Anfrage auftaucht. - Jeder Error-Log enthält
errorTypeund einen Stacktrace (oder das Äquivalent in Ihrer Sprache). - Auth und Payments (oder jeder Geldpfad) haben klare "start"- und "finish"-Ereignisse, damit Sie sehen, wo der Fluss stoppt.
- Secrets und Tokens werden standardmäßig redacted und Sie dumpen niemals komplette Request- oder Response-Payloads.
- Dieselben Kernfelder sind immer vorhanden:
service,route,userId(oderanonId),requestIdunddurationMs.
Wenn Sie sonst nichts tun: stellen Sie sicher, dass Sie eine requestId in Ihre Log-Suche einfügen können und die ganze Story vom ersten Handler bis zum letzten Datenbank-Aufruf sehen.
Häufige Fehler, die Zeit verschwenden
Auch gute Teams laufen in ein paar Fallen, die Logs schwer nutzbar machen, wenn es darauf ankommt.
- Inkonsistente Feldnamen (z. B.
req_id,requestIdundrequest_idin verschiedenen Teilen). - Fehlender Kontext (ein Fehler wird geloggt, aber Sie können nicht erkennen, welche Route, Nutzer oder welcher Schritt ihn verursacht hat).
- Nur bei Fehlern loggen (Sie brauchen ein paar Schlüssel-"Meilenstein"-Ereignisse, um zu sehen, wo ein Flow stoppt).
- Zu viel Rauschen auf dem falschen Level (alles ist
info, sodass echte Warnungen vergraben werden). - Accidentelle Datenleaks (Tokens, API-Keys, Session-Cookies oder komplette Zahlungs-Payloads in Logs).
Nächste Schritte: Wählen Sie die Top-3-nutzerkritischen Flows (oft Signup/Login, Checkout und Passwort-Reset). Fügen Sie Request-IDs Ende-zu-Ende hinzu und dann 3–6 durchsuchbare Ereignisse pro Flow (start, wichtiger Schritt, finish und ein klares failure-Ereignis). Sobald diese stabil sind, erweitern Sie auf den Rest der App.
Wenn Ihre AI-generierte App schwer zu debuggen ist, weil Logs unordentlich oder fehlend sind, kann FixMyMess ein kostenloses Code-Audit durchführen und helfen, Request-IDs, konsistente Ereignisfelder und sicherere Fehlerbehandlung hinzuzufügen, damit Produktionsprobleme leichter reproduzierbar werden.