Synthetische Checks für fehlerhafte Anmeldungen: Fehler früh erkennen
Synthetische Checks für fehlerhafte Anmeldungen erkennen fehlgeschlagene Anmeldung, Onboarding und Checkout von außerhalb Ihres Netzwerks und alarmieren, bevor echte Nutzer abspringen.
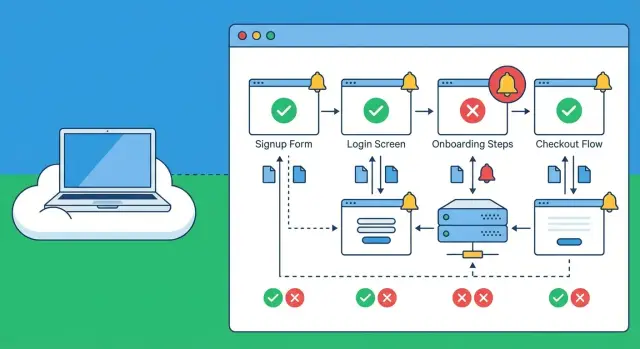
Warum fehlerhafte Anmeldungen durchrutschen und wie Nutzer sie erleben
Eine fehlerhafte Anmeldung sieht selten wie ein dramatischer Ausfall aus. Für eine echte Person fühlt es sich an, als würde die Seite einfach nicht funktionieren: ein Button, der nichts tut, ein Spinner, der nie aufhört, eine vage „Etwas ist schiefgelaufen“-Meldung oder ein Formular, das abgesendet wird und den Nutzer dann stillschweigend wieder auf den Login-Bildschirm zurückwirft.
Manchmal sagt die UI „Check your email“, aber die E-Mail kommt nie an. Oder sie kommt zu spät, der Link ist abgelaufen und der Nutzer gibt auf. Auf Mobilgeräten kann ein einziger zusätzlicher Schritt (z. B. ein CAPTCHA, das nicht lädt) ausreichen, um den Flow zu zerstören.
Diese Fehler rutschen durch, weil Teams gewöhnlich den Happy Path in der eigenen Umgebung testen. Interne Checks können bestätigen, dass der Server läuft und die Datenbank reagiert, aber das garantiert nicht, dass die komplette Nutzerreise aus dem öffentlichen Internet funktioniert. Probleme, die oft nur extern auftreten, sind unter anderem:
- CDN- oder Caching-Probleme, die ein altes JavaScript-Bundle ausliefern
- Drittanbieter für Auth oder E-Mail, die in bestimmten Regionen blockiert oder rate-limitiert sind
- Falsch konfigurierte Cookies, Redirects oder CORS, die außerhalb des Netzwerks anders reagieren
- Ein Deploy, das für eingeloggte Admins funktioniert, aber neue Accounts kaputt macht
Der geschäftliche Schaden ist direkt und schnell spürbar. Eine kaputte Anmeldung bedeutet bezahlte Klicks ohne Leads, verlassene Warenkörbe beim Checkout und mehr Support-Tickets, die mit „Ich kann kein Konto erstellen“ beginnen. Noch schlimmer: Viele Nutzer beschweren sich nicht — sie gehen einfach weg.
Synthetische Checks für fehlerhafte Anmeldungen helfen, weil sie wie ein echter Kunde agieren. Sie führen wiederholt die gleichen Schritte aus (Anmeldung, Verifikation, erster Login) und alarmieren, wenn die Reise fehlschlägt. Sie ersetzen kein echtes Nutzer-Feedback, keine Analysen oder Supportberichte, verkürzen aber die Zeit zwischen „es ist kaputt“ und „Sie wissen, dass es kaputt ist."
Was synthetische Checks sind (und was nicht)
Synthetische Checks sind geplante Skripte, die wie ein echter Nutzer handeln. Sie öffnen Ihre Seite oder App, klicken durch die wichtigen Schritte, geben Daten ein und bestätigen einen „Erfolgsmoment“ (zum Beispiel, dass ein neues Konto auf einer Willkommensseite landet oder das erste Dashboard lädt). Denken Sie an sie als einen zuverlässigen, wiederholbaren Kunden, der alle paar Minuten auftaucht und berichtet, was passiert ist.
„Von außerhalb Ihres Netzwerks“ bedeutet, dass der Check aus dem öffentlichen Internet läuft, nicht über Ihr Büro-WLAN, VPN oder interne Cloud-Netzwerk. Das ist wichtig, weil viele Anmeldefehler nur in der realen Welt auftreten: DNS-Probleme, CDN-Fehler, blockierte Cookies, Geo-Routing-Quirks oder Drittanbieterskripte, die außerhalb Ihrer Umgebung anders laufen.
Basis-Uptime-Checks beantworten nur eine Frage: „Antwortet die Startseite?“ Synthetische Checks für Anmeldungen gehen weiter und folgen der gesamten Reise end-to-end. Eine Seite kann „up“ sein, während die Anmeldung stillschweigend wegen eines JavaScript-Fehlers, einer schlechten API-Antwort oder eines abgelaufenen Secrets kaputt ist.
Synthetische Checks erkennen gut UI-Probleme (Buttons nicht klickbar, Formulare hängen, Seiten laden nicht), API-Fehler (500er, Validierungsbugs, kaputte Auth), Drittanbieter-Ausfälle (Zahlungen, Captchas, Skripte, die die Seite crashen) und langsame Schritte, die timeouts verursachen.
Was sie allein nicht zuverlässig beweisen können, ist, ob ein Mensch die E-Mail erhalten und den Link genutzt hat. Sie können prüfen, dass eine E-Mail angefordert wurde, aber die Zustellung ins Postfach variiert. Eine übliche Herangehensweise ist, das Backend-Ereignis zu validieren („Verifizierungs-E-Mail erstellt“) und die Inbox-Zustellung als separaten Check zu behandeln.
Wählen Sie die Reisen, die zählen: Anmeldung, Onboarding, Checkout
Die meisten Teams versuchen, alles zu überwachen und überwachen am Ende nichts richtig. Beginnen Sie, indem Sie 2 bis 4 Nutzerreisen auswählen, die direkt Umsatz oder Support-Last beeinflussen. Für die meisten Produkte zahlen sich Signup-Checks am schnellsten aus, weil kleine Fehler (eine fehlende E-Mail, ein hängender Spinner) neue Nutzer leise halbieren können.
Wählen Sie Reisen, die eine reale Person repräsentieren, die Kunde werden will — nicht interne Admin-Pfade oder selten genutzte Einstellungsbildschirme. Eine solide Anfangsauswahl ist:
- Konto erstellen (E-Mail oder Social)
- Einloggen (inklusive eines „falsches Passwort“-Versuchs)
- Onboarding (erste sinnvolle Aktion, z. B. Workspace erstellen)
- Checkout (vom Warenkorb bis zur Bestellbestätigung)
- Passwort zurücksetzen (anfordern plus bestätigen)
Für jede Reise notieren Sie ein Erfolgssignal, das Sie verifizieren können. Verlassen Sie sich nicht auf „Seite geladen“. Nutzen Sie einen klaren Moment, der beweist, dass der Flow funktioniert hat, z. B. ein Redirect zur Willkommensseite, eine sichtbare „Du bist drin“-Meldung oder ein Bezahlungsbildschirm mit einer Bestellnummer.
Entscheiden Sie, wo das Skript stoppt. Der beste Stopp-Punkt ist der erste zentrale Erfolgsmoment, nicht jeder Randfall. Ein Signup-Check, der den Bestätigungsbildschirm prüft, reicht oft aus. Tiefere Fälle (mehrere Pläne, Coupons, Adressformate) speichern Sie für später, sonst erzeugen Sie laute Alerts.
Lassen Sie das Skript wie einen neuen Besucher agieren: frische Browsersession, keine Cookies und normale Viewport-Größe. Dort treten versteckte Probleme auf, wie kaputte Auth-Redirects, Drittanbieter-Cookie-Probleme oder ein Onboarding-Schritt, der nur fehlschlägt, wenn der Local Storage leer ist.
Beispiel: Sie testen Checkout als eingeloggter Langzeitnutzer, aber neue Nutzer müssen zuerst die E-Mail verifizieren. Ihr synthetisches Skript sollte den Pfad für neue Nutzer durchlaufen, sonst übersieht es den Fehler.
Testdaten und Accounts: realistisch, aber risikofrei
Synthetische Checks helfen nur, wenn sie sich wie echte Kunden verhalten. Das heißt echte Bildschirme, echte E-Mails, echte Redirects und manchmal sogar ein echter Zahlungs-Schritt. Aber Sie sollten niemals echte Kundendaten dafür verwenden.
Beginnen Sie mit dedizierten Testnutzern. Machen Sie sie auffällig (z. B. synth_signup_01) und taggen Sie sie in Ihrer Datenbank, wenn möglich, damit Support und Analytics sie nicht mit echten Kunden verwechseln. Verwenden Sie test-only E-Mail-Adressen und eine Test-Zahlungsmethode aus dem Sandbox-Bereich Ihres Zahlungsanbieters, oder ein risikoarmes Produkt und Betrag, falls Sie in Produktion testen müssen.
E-Mail und Einmalcodes sind der größte Schmerzpunkt. Sie haben ein paar sichere Optionen: ein Test-Inbox, das Ihr Skript lesen kann; einen bekannten Testcode nur für synthetische Nutzer zulassen; oder einen separaten Verifikationspfad, der nur für ein synthetisches Flag funktioniert. Ziel ist, den gleichen Flow wie Kunden zu testen, ohne Ihr Auth-System zur leichten Angriffsfläche zu machen.
Staging ist gut für schnelle Checks, aber viele Teams führen Signup-Checks auch in Produktion durch, weil dort die echten Fehler passieren: Ratenbegrenzungen, Drittanbieter-Ausfälle, falsch konfigurierte Redirects oder ein abgelaufenes Secret. Wenn Sie in Prod überwachen, halten Sie das Skript niedrig in der Wirkung: ein Lauf, ein Nutzer, ein Kauf (oder eine $0-Autorisierung) und bereinigen Sie danach.
Zugangsdaten sind jetzt Teil des Produkts, behandeln Sie sie entsprechend:
- Speichern Sie Testzugänge im Secret Manager, nicht im Skript oder Repo.
- Verwenden Sie die geringstmöglichen Rechte (eine Testrolle, kein Admin).
- Rotieren Sie Passwörter, API-Keys und Test-Karten regelmäßig.
- Beschränken Sie den Test-Inbox-Zugang nur auf das Monitoring-System.
- Loggen Sie jede synthetische Anmeldung, damit Missbrauch auffällt.
Wo und wie oft Checks außerhalb Ihres Netzwerks laufen sollten
Wenn Ihr synthetisches Skript nur von Ihrer Büro-IP (oder derselben Cloud, in der Ihre App liegt) ausgeführt wird, kann es die Fehler übersehen, die echte Kunden sehen. Führen Sie Checks aus dem öffentlichen Internet und aus mehreren Orten aus, damit Sie Probleme durch Routing, DNS, CDN-Edge oder regionale Drittanbieter-Ausfälle entdecken.
Eine einfache Einrichtung sind 2–4 Regionen, die zu Ihren Nutzern passen. Wenn die meisten Kunden in den USA und Europa sind, führen Sie einen Check aus US East, einen aus US West und einen aus Westeuropa aus. So erkennen Sie „funktioniert für mich“-Probleme, z. B. einen Auth-Provider, der nur in einer Region timeouts hat.
Taktung: wie oft ist „oft genug“?
Frequenz ist ein Kompromiss zwischen Geschwindigkeit, Lärm und Kosten. Wählen Sie eine Taktung pro Reise, nicht eine Einheitsgröße für alles:
- Alle 1 Minute: Checkout und Zahlungen, oder hoher Traffic bei einem Launch
- Alle 5 Minuten: Kern-Signup und Login für ein stabiles Produkt
- Alle 15 Minuten: Onboarding-Schritte, die selten geändert werden
- Nach Deployments: Führen Sie direkt nach einem Release eine zusätzliche Runde durch
Machen Sie Fehler leicht lesbar, indem Sie Timeouts pro Schritt setzen. Verwenden Sie getrennte Limits für Page Load, API-Antwort und Bestätigungsbildschirm. Wenn „Konto erstellen“ innerhalb von 20 Sekunden nie das Erfolgssignal zeigt, sollte die Alarmmeldung das klar benennen, nicht nur „Test fehlgeschlagen."
Beweise erfassen, wenn es bricht
Wenn um 3 Uhr morgens etwas fehlschlägt, wollen Sie Beweise, keine Vermutungen. Konfigurieren Sie Ihre Checks so, dass bei einem Fehler ein Screenshot des fehlschlagenden Schritts, Console-Logs und Netzwerkfehler, der genaue Schritt und das auslösende Timeout sowie ein kurzer Trace der wichtigsten Requests (Signup, Token-Exchange, Bestätigung) gespeichert werden.
Schritt für Schritt: ein synthetisches Skript bauen, das wirklich zur Realität passt
Ein nützlicher synthetischer Check liest sich wie eine echte User-Story. Tun Sie so, als wären Sie ein Erstbesucher mit langsamer Verbindung, ohne Cookies, von außerhalb Ihres Büro-Netzwerks. Ihr Skript sollte diesem Pfad folgen, nicht dem Pfad, den Sie auswendig kennen.
Praktische Bau-Reihenfolge
Fangen Sie einfach an und verfeinern Sie, bis es die Fehler trifft, die Kunden erleben.
- Schreiben Sie die Reise zuerst in klaren Schritten, dann automatisieren Sie sie: öffentliche Seite öffnen, warten bis sie lädt, dieselben Felder ausfüllen, die ein Nutzer sieht, absenden und bestätigen, dass Sie im erwarteten Zustand landen (z. B. „Welcome“ plus eingeloggter Header).
- Verwenden Sie stabile Selektoren und vorhersehbare Waits. Bevorzugen Sie Attribute, die Sie kontrollieren (wie
data-testid) gegenüber zufälligen IDs oder zerbrechlichen CSS-Ketten. Warten Sie auf ein spezifisches Element, das signalisiert, dass die Seite bereit ist, nicht auf eine feste Pause. - Validieren Sie das richtige Ergebnis, nicht nur „kein Crash“. Ein Erfolgsscreen kann durch Frontend-Fehler vorgetäuscht werden. Wenn möglich, bestätigen Sie auch serverseitige Realität, z. B. „User-Record erstellt“ oder „Session-Cookie gesetzt“ über einen API-Check.
- Fügen Sie Retries mit Bedacht hinzu. Das Wiederholen eines Page Loads ist in Ordnung. Das Wiederholen einer Geschäftsaktion (Account erstellen, Bestellung abschicken, Karte belasten) kann Duplikate erzeugen und echte Fehler verbergen.
- Erfassen Sie bei Fehlern Beweise. Speichern Sie Screenshot, Console-Logs und relevante Netzwerkfehler, damit die On-Call-Person sehen kann, was kaputtging, ohne lokal reproduzieren zu müssen.
Gegen falsche Positive resistent machen
Synthetische Signup-Checks scheitern oft, weil sie nur die UI testen. Ein häufiges Beispiel: Das Formular wird abgesendet, Sie sehen eine Erfolgsmeldung, aber Auth ist kaputt und die nächste Seite springt zurück zum Login. Fügen Sie einen abschließenden Schritt „Kann ich die Account-Seite aufrufen?“ hinzu, um zu beweisen, dass die Session wirklich funktioniert.
Alerts und Triage: Fehler erfassen ohne Lärm zu erzeugen
Alerts sollten zwei Fragen schnell beantworten: „Ist das echt?“ und „Wer muss handeln?“ Wenn das fehlt, fangen Leute an, sie zu ignorieren, und der nächste echte Ausfall wird übersehen.
Beginnen Sie mit Schwellenwerten, die zum unsteten Internet passen. Ein einzelner fehlgeschlagener Lauf kann ein Ausreißer sein (temporäres Provider-Problem, kurz Netzverlust). Aufeinanderfolgende Fehler sind meist ein echtes Problem.
Ein einfacher Ansatz, der für die meisten Teams funktioniert:
- Alarm nach 2 aufeinanderfolgenden Fehlern vom selben Standort
- Erstelle ein Ticket oder sende eine Nachricht bei 1 Fehler, wenn es Checkout oder Zahlung betrifft
- Auto-Resolve erst nach 1 bis 2 sauberen Läufen
- Füge eine tägliche Zusammenfassung von „Beinahe-Fehlschlägen“ hinzu, damit Sie Muster ohne Lärm sehen
Routing ist genauso wichtig wie Erkennung. Ein kaputter Anmeldeschritt kann zu Produkt (Copy oder Consent), Engineering (API oder Auth) oder einer Agentur gehören. Wenn nicht klar ist, wer den Schritt besitzt, entscheiden Sie das zuerst und dokumentieren Sie es.
Machen Sie Alerts handlungsfähig, indem Sie Kontext beifügen, der die ersten Fragen beantwortet: welcher Schritt schlug fehl, was erwartete das Skript, was wurde stattdessen gesehen, von wo lief es und wann hat es zuletzt funktioniert. Fügen Sie die letzte Erfolgszeit und einen kurzen Fehlerausschnitt (Statuscode, UI-Text oder Validierungsnachricht) hinzu. „Signup failed“ ist Lärm. „Fehlgeschlagen bei E-Mail-Verifikation: Code-Eingabe erscheint nicht; letzter Erfolg 03:12 UTC; US-East" ist nützlich.
Halten Sie ein kurzes Runbook, damit die Triage konsistent ist:
- Einmal von einem anderen Ort erneut ausführen, um zu bestätigen
- Kürzliche Deploys, Feature Flags und Drittanbieter-Status prüfen (E-Mail/SMS, Zahlungen)
- Den gleichen Flow in einem Inkognito-Fenster mit einem Testkonto ausprobieren
- Den genauen fehlschlagenden Schritt und den Fehlertext erfassen, bevor eskaliert wird
- Mit dem Kontext an den Owner eskalieren
Häufige Fehler, die synthetische Checks nutzlos (oder gefährlich) machen
Synthetische Checks helfen nur, wenn sie sich wie echte Kunden verhalten und aus denselben Gründen fehlschlagen. Einige häufige Abkürzungen können Checks „grün“ erscheinen lassen, während Nutzer feststecken, oder — noch schlimmer — in Produktion echten Schaden anrichten.
Ein einfacher Fehler ist, nur den Happy Path zu testen. Eine Anmeldung, die mit „Account created“ endet, kann dennoch kaputt sein, wenn die E-Mail-Verifikation nie ankommt, der Verifizierungslink fehlschlägt oder der erste Login nach der Verifikation einen Fehler hat. Gleiches gilt für Passwort-Resets. Viele Teams scripteten das nicht, daher merken sie nie, dass das Reset-Template kaputt ist oder der Token sofort abläuft.
Eine weitere Falle ist, Checks nur aus Ihrem eigenen Netzwerk laufen zu lassen. Läuft das Skript in Ihrer VPC, kann es genau die Dinge umgehen, auf die Kunden angewiesen sind: DNS-Auflösung, CDN-Verhalten, WAF-Regeln, Geofencing oder falsch konfigurierte Redirects an der Edge. Die App sieht intern gut aus, während reale Nutzer Timeouts, geblockte Requests oder ein gecachter schlechtes Asset treffen.
Flaky-Skripte sind oft selbstverschuldet. Wenn der Check auf einen Button klickt, der sich verschiebt, auf einen Spinner wartet, indem er die Zeit rät, oder einen Selektor benutzt, der sich mit jedem Build ändert, bekommen Sie Alarmmüdigkeit. Warten Sie auf stabile Seitensignale (klarer Text-Header oder bekannte API-Antwort) und wählen Sie Selektoren für Tests.
Seien Sie vorsichtig mit „hilfreichen“ Retries. Ein Formular-Submit zu wiederholen kann heimlich doppelte Nutzer, doppelte Testabos oder sogar doppelte Bestellungen erzeugen, wenn Ihr Backend nicht idempotent ist. Wenn Retries nötig sind, wiederholen Sie sichere Schritte (Seitenladevorgang), nicht Käufe oder Kontoerstellungen.
Eine schnelle Sicherheits-Checklist:
- Verifizieren und Reset abdecken, nicht nur erste Anmeldung
- Mindestens von einer echten Region außerhalb Ihres Netzwerks laufen lassen
- Stabile Selektoren und verlässliche Wartebedingungen nutzen
- Aktionen vermeiden, die Daten resubmitten
- Zugangsdaten aus Code und Logs fernhalten
Behandeln Sie Secrets wie Produktionsdaten. Testaccounts sollten minimale Berechtigungen haben und Credentials in einem Secret-Store leben, nicht im Skript-Repo oder in Alarm-Texten.
Schnelle Checkliste: Deckt Ihr Monitoring echten Nutzer-Schmerz ab?
Wenn Ihr Monitoring nur prüft, dass die Startseite lädt, verpasst es die Fehler, die tatsächlich Umsatz stoppen. Nutzen Sie diese Checkliste, um zu prüfen, ob Ihr Signup-Monitoring das abbildet, was ein echter neuer Kunde tut, in der richtigen Reihenfolge und mit verwertbaren Beweisen.
Ein guter Check endet mit einem klaren Erfolgssignal. „200 OK“ ist nicht genug. Sie wollen den ersten Bildschirm sehen, der bestätigt, dass der Nutzer wirklich drin ist (z. B. Willkommensseite, Dashboard oder ein „Check your email“-Schritt, der nur nach erfolgreichem Submit erscheint).
Eine schnelle Pass/Fail-Checkliste, die echten Nutzer-Schmerz abbildet:
- Ein brandneuer Nutzer kann das Signup-Formular absenden und landet auf dem ersten Erfolgsbildschirm (kein generischer Redirect).
- Login funktioniert direkt nach der Anmeldung in einer frischen Sitzung (Browser-Kontext schließen und neu öffnen, damit keine gecachte Auth genutzt wird).
- Onboarding verändert tatsächlich den App-Zustand (z. B. ein Profilfeld wird gespeichert oder das erste Workspace/Projekt wird erstellt und ist nach Refresh sichtbar).
- Checkout erreicht eine Bestätigungsseite ohne Retries und löst beim Neuladen der Seite keine zweite Abbuchung aus.
- Wenn etwas fehlschlägt, enthält der Alert einen Screenshot und den exakten Schritt, der gebrochen ist (welcher Button, welche URL, welcher Fehlertext).
Ein einfacher Realitätscheck: Stellen Sie sich vor, Ihr Signup-Formular schlägt fehlslos zu, aber die nächste Seite crasht nur für Erstnutzer, weil ein fehlender „default team“-Datensatz nicht erstellt wurde. Lokales Testen sieht das nie, weil Ihr Konto bereits Daten hat. Ein synthetischer Lauf, der jedes Mal einen neuen Nutzer erstellt, fängt das schnell.
Beispiel-Szenario: Die Anmeldung funktioniert bei Ihnen, aber nicht bei Kunden
Ein Gründer launcht an einem Montag. Der Traffic ist gesund, aber neue Accounts gehen nahezu auf null. Das Team prüft die Uptime — alles sieht gut aus: Startseite lädt, API antwortet, keine Server-Errors.
Das Problem ist einfach: Der Gründer (und sein Team) testet die Anmeldung immer vom Büro-Netzwerk in einem Land und in einem Browser, während echte Nutzer aus mehreren Regionen und Geräten kommen.
Sie fügen synthetische Checks hinzu, die von außerhalb ihres Netzwerks laufen. Ein Check läuft aus den USA, einer aus der EU und einer aus Asien. US und EU bestehen, aber der Asien-Lauf schlägt jedes Mal direkt nach dem „Continue with Google“-Button fehl.
Der Alert ist nützlich, weil er zeigt, was ein echter Mensch sehen würde:
- Einen Screenshot einer Redirect-Schleife zwischen der App und dem Identity-Provider
- Einen kurzen Console-Error wie „redirect_uri_mismatch“ und die finale sich wiederholende URL
- Den exakten Schritt, der fehlschlug (nach Auth, vor Kontoerstellung)
Die Ursache war eine falsch konfigurierte Auth-Callback-URL. Die App war mit einem Callback eingerichtet, der für die primäre Domain funktionierte, aber ein regionaler Edge oder ein alternativer Domainpfad in Asien erzeugte eine leicht abweichende Redirect-URL. Auf dem Laptop des Gründers tauchte das nie auf.
Die Lösung ist klein: Erlaubte Callback-URLs im Auth-Provider aktualisieren und sicherstellen, dass die App immer ein konsistentes Redirect-Ziel zurückgibt. Dann das synthetische Skript aus allen Regionen erneut laufen lassen, bestätigen, dass jeder Lauf bis „Account created“ kommt, und den Vorfall schließen.
Vor dem Weitergehen: Fügen Sie eine Regression-Prüfung hinzu: Führen Sie dasselbe Signup-Skript nach jedem Deploy aus, mindestens von einem externen Standort, und alarmieren Sie nur, wenn es zweimal hintereinander fehlschlägt.
Nächste Schritte: Setzen Sie Ihre ersten Checks auf und stabilisieren Sie die App
Fangen Sie klein an und bringen Sie diese Woche etwas zum Laufen. Ein Skript für Signup und eins für Checkout reicht, um die meisten „nichts funktioniert“-Momente zu erkennen. Wählen Sie zuerst den einfachsten Happy Path und fügen Sie später Varianten hinzu (verschiedene Pläne, Promo-Codes, Zahlungsarten, neuer Nutzer vs. Rückkehrer).
Führen Sie Ihre ersten zwei Skripte wie ein Produkt-Release aus:
- Schreiben Sie eine Signup-Reise und eine Checkout-Reise, die dem echten Kundenverhalten entsprechen, von außerhalb Ihres Netzwerks.
- Erstellen Sie eine Basislinie: Erfolgsrate und durchschnittliche Dauer jeder Reise.
- Fügen Sie klare Pass/Fail-Regeln hinzu (z. B.: Konto erstellt, Willkommensseite angezeigt, Zahlung bestätigt).
- Setzen Sie je Reise einen Alert und routen Sie ihn an die Person, die handeln kann.
- Reviewen Sie die Ergebnisse wöchentlich und erweitern Sie die Abdeckung nur, wenn das Grundsätzliche stabil bleibt.
Sobald die Checks live sind, beobachten Sie die Zahlen einige Tage. Ein kleiner Rückgang der Erfolgsrate kann so wichtig sein wie ein kompletter Ausfall. Tracken Sie auch Time-to-Complete. Wenn Ihre Anmeldung plötzlich doppelt so lange braucht, ist häufig etwas halb kaputt (langsame API, hängender Spinner, verzögerte E-Mail-Zustellung), bevor es ganz ausfällt.
Bei häufigen Fehlern: Pause machen und die App stabilisieren, bevor Sie mehr Monitoring hinzufügen. Übliche Schuldige sind Auth-Edge-Cases, brüchige Onboarding-Schritte und fehlende Fehlerbehandlung (eine einzelne schlechte Antwort oder ein leeres Feld bricht den ganzen Flow). Beheben Sie die Ursache und straffen Sie dann das Skript, sodass es die richtigen Bildschirmmeldungen und Statusänderungen prüft.
Wenn Sie eine KI-generierte Codebasis geerbt haben und nicht sagen können, ob das Skript falsch ist oder die App, kann ein gezielter Reparaturdurchgang viel Zeit sparen. FixMyMess (fixmymess.ai) spezialisiert sich auf Diagnose und Reparatur von Problemen wie kaputter Authentifizierung, unordentlichem Routing, exponierten Secrets und Sicherheitslücken, damit Ihr Signup-Monitoring echte Nutzer-Gesundheit widerspiegelt statt ständiger Fehlalarme.
Häufige Fragen
Why does signup work for us but fail for real users?
Weil die meisten Teams nur den „Happy Path“ in ihrer eigenen Umgebung testen, wo DNS, CDN-Edge, Cookies und Drittanbieter anders funktionieren. Reale Nutzer sehen die öffentliche Internet-Version, sodass Probleme wie ein gecachter alter JavaScript-Bundle, falsch gesetzte Cookies oder regionale Ratenbegrenzungen die Anmeldung unterbrechen können, ohne dass es intern auffällt.
What’s the difference between uptime monitoring and a synthetic signup check?
Ein Uptime-Check sagt nur, ob eine Seite antwortet. Ein synthetischer Signup-Check klickt den kompletten Ablauf durch und bestätigt einen echten Erfolgsmoment, z. B. das Erreichen einer Willkommensseite oder das Laden des ersten Dashboards nach dem Erstellen eines neuen Kontos.
Which user journeys should we monitor first?
Beginnen Sie mit 2–4 Nutzerreisen, die direkt Umsatz oder Support-Last beeinflussen. Für die meisten Produkte sind das Konto erstellen, erster Login, Passwort-Reset und Checkout — das sind Pfade, bei denen Nutzer schnell abspringen, wenn etwas schiefgeht.
What’s a good success signal for a signup synthetic check?
Wählen Sie ein einzelnes „Beweis“-Signal, dass die Reise wirklich funktioniert, nicht nur, dass eine Seite geladen wurde. Ein guter Default ist, zu prüfen, ob der Nutzer in einer frischen Sitzung auf einen authentifizierten Bildschirm zugreifen kann, so verhindern Sie falsche Positive durch nur front-end-basierte Erfolgsmeldungen.
How do we test email verification if inbox delivery is unreliable?
Am einfachsten ist es, das Backend-Ereignis zu validieren, dass eine E-Mail erzeugt und in die Queue gestellt wurde, und die Inbox-Zustellung als separaten Check zu behandeln. Wenn Sie den Link Ende-zu-Ende prüfen müssen, nutzen Sie ein dediziertes Test-Postfach, das das Skript lesen kann, und beschränken Sie den Zugang.
What’s the safest way to handle test accounts and credentials?
Nutzen Sie dedizierte Testnutzer, die klar gekennzeichnet und von echten Kunden getrennt sind, und verzichten Sie vollständig auf echte Kundendaten. Speichern Sie Test-Credentials in einem Secret Manager, halten Sie Berechtigungen minimal und rotieren Sie alles, worauf das Skript angewiesen ist.
Where should synthetic checks run from to catch real-world failures?
Führen Sie Checks aus dem öffentlichen Internet und aus mehreren Regionen aus, sonst übersehen Sie DNS/CDN-Edge-Probleme und geo-spezifische Drittanbieter-Ausfälle. Ein praktischer Default sind 2–4 Regionen, die zu Ihren Nutzern passen, damit Sie „funktioniert hier, bricht dort“ Probleme erkennen.
How often should we run signup checks without creating alert noise?
Für stabile Produkte ist alle 5 Minuten für Signup und Login ein guter Ausgangspunkt, mit einem zusätzlichen Lauf direkt nach Deployments. Erhöhen Sie die Frequenz während Launches oder für Checkout, und setzen Sie klare Timeouts pro Schritt, damit Alerts genau sagen, wo es hakte.
How do we prevent flaky scripts and false passes?
Nutzen Sie stabile Selektoren, die Sie kontrollieren (z. B. data-testid), und warten Sie auf klare Ready-Signale statt fester Pausen. Vermeiden Sie das automatische Wiederholen von Aktionen, die Daten erzeugen (Konto anlegen, Bestellung abschicken), denn Retries können echte Probleme verbergen und Duplikate erzeugen.
What if our app is AI-generated and signup is already unstable?
Wenn wiederholt Fehler auftreten und Sie nicht sicher sind, ob das Skript oder die App schuld ist, beheben Sie zuerst den zugrunde liegenden Flow. FixMyMess (fixmymess.ai) kann einen KI-generierten Code-Base prüfen, kaputte Authentifizierung, Routing und Sicherheitsprobleme reparieren und so Ihre Monitoring-Suite verlässlich machen statt laut.