Umgebungsvariablen beim Start mit einem Env-Schema validieren
Validiere Umgebungsvariablen beim Start, um fehlende oder ungültige Konfiguration früh zu erkennen, klare Fehler auszugeben und fehlerhafte Deploys zu verhindern, bevor Nutzer betroffen sind.
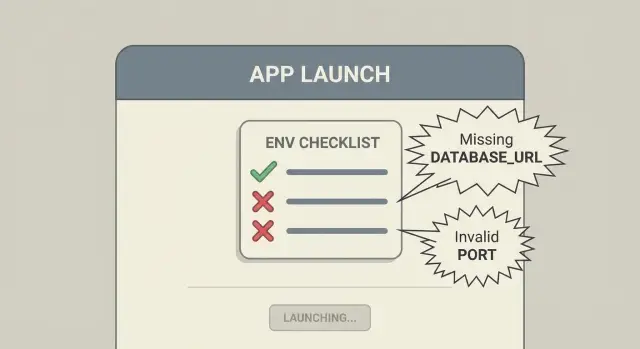
Warum Probleme mit Umgebungsvariablen erst nach dem Deployment auftauchen
Umgebungsvariablen (env vars) sind Einstellungen, die deine App beim Start liest. Dazu gehören meist die Datenbank-URL, API-Schlüssel, die Basis-URL der App und in welcher Umgebung du gerade läufst (Entwicklung vs Produktion). Diese Werte außerhalb des Codes zu halten erlaubt es, das gleiche Build in verschiedenen Umgebungen mit unterschiedlichen Einstellungen zu verwenden.
Die meisten Fehler mit env vars folgen der gleichen Geschichte: lokal funktioniert alles, nach dem Deploy bricht es. Auf deinem Rechner sammelt sich über Monate eine .env-Datei an oder das Framework liefert stillschweigend Defaults. In Produktion musst du die Werte in einem Hosting-Dashboard oder im CI erneut eintragen. Dort entstehen Tippfehler, fehlende Keys und „Staging-Werte in Prod“-Fehler.
Diese Fehler treten oft spät auf. Viele Apps verwenden bestimmte Variablen nur auf konkreten Seiten oder in Hintergrund-Jobs. Ein fehlender EMAIL_API_KEY schlägt vielleicht erst beim ersten Passwort-Reset fehl. Eine falsche DATABASE_URL zeigt sich vielleicht erst bei hoher Last, wenn der Connection-Pool unter Stress steht. Es wirkt zufällig, ist aber schlicht Konfiguration.
Die Lösung ist: schnell fehlschlagen. Wenn die App startet, validiere die benötigten env vars, gib eine klare Fehlermeldung aus (ohne Geheimnisse zu zeigen) und beende den Prozess mit einem Nicht-Null-Exit-Code. Ein schlechter Deploy soll sofort und laut fehlschlagen, nicht halb funktionieren und dann echte Nutzer treffen.
Was man validieren sollte (und was nicht)
Die Validierung beim Start soll nicht beweisen, dass alles funktioniert. Sie soll schlechte Konfiguration früh mit klaren Fehlern auffangen, bevor die App Traffic verarbeitet.
Beginne damit, Variablen in zwei Gruppen zu trennen:
- Erforderlich: die App kann ohne sie nicht sicher laufen (Database-URL, Auth-Secret, Base-URL).
- Optional: Feature-Flags oder Tuning-Parameter, für die ein sinnvoller Default akzeptabel ist.
Was sich bei jedem Start lohnt zu prüfen:
- Vorhandensein und Nicht-Leer-Werte für Pflicht-Keys (behandle Leerzeichen und
""als fehlend). - Typen: striktes Parsen für Zahlen und Booleans, plus URL-Validierung wo relevant.
- Erlaubte Werte und Grenzen: Enums wie
ENV=production|staging|development, Ports 1–65535, Timeouts > 0. - Cross-Field-Regeln: wenn
FEATURE_X=true, dann istFEATURE_X_KEYerforderlich. - Umgebungsspezifische Regeln: in Produktion sind oft strengere Anforderungen sinnvoll (HTTPS-URLs, stärkere Secrets,
DEBUG=false).
Was du nicht beim Start validieren solltest: alles, was den Boot zu einem langsamen, fehleranfälligen Integrationstest macht. Blockiere den Start nicht durch Aufrufe externer APIs, Senden von E-Mails oder schwere Migrationen. Halte die Startprüfungen auf die Form und Sicherheit der Konfiguration beschränkt.
Und niemals Secrets durch Ausgeben validieren. Es ist okay zu melden, dass JWT_SECRET fehlt oder zu kurz ist – gib niemals den Wert selbst aus.
Schema statt verstreuter Prüfungen
Wenn du nur ein paar env vars hast, kann if (!process.env.X) throw funktionieren – bis es das nicht mehr tut. Mit der Zeit wachsen Features und neue Variablen werden hinzugefügt, Prüfungen landen verstreut in Routen, Jobs und Hilfsdateien. Das führt zu:
- inkonsistenten Namen (
DB_URLin einer Datei,DATABASE_URLin einer anderen) - Prüfungen, die zu spät ausgeführt werden (nur bei einem seltenen Endpoint)
- vagen Fehlern („cannot read property of undefined“) statt „du hast X vergessen"
Ein schema-basierter Ansatz sammelt alle Konfig-Regeln an einem Ort: was erforderlich ist, was optional, erwartete Typen, erlaubte Werte und Cross-Field-Regeln. Wenn die Validierung fehlschlägt, erhältst du eine klare Fehlerzusammenfassung, die genau auf die fehlende oder ungültige Einstellung zeigt.
Führe die Validierung so früh wie möglich aus: bevor du die DB verbindest, bevor du Third-Party-SDKs initialisierst und bevor der Server anfängt, Requests anzunehmen.
Schritt für Schritt: Startup-Validierung, die schnell fehlschlägt
Behandle Konfiguration wie erforderliche Eingabe für deine App, nicht als etwas, das du nach dem ersten fehlgeschlagenen Request entdeckst.
1) Env vars einmal an einer Stelle laden
Wähle ein einzelnes Modul, das beim Boot läuft (häufig config oder startup). Lies dort die env vars ein und gib die geparste Konfiguration weiter. So vermeidest du, dass verschiedene Teile der App Werte unterschiedlich interpretieren.
2) Ein Env-Schema definieren
Schreibe auf, was die App zum Start braucht: Pflicht-Keys, erwarteter Typ und Formatregeln (URL, E-Mail, Integer-Bereich). Entscheide, welche Werte Defaults haben dürfen und welche zwingend geliefert werden müssen.
Ein einfacher Ansatz im Code sieht so aus (Beispiel in Node):
const schema = {
DATABASE_URL: { required: true, format: 'url' },
JWT_SECRET: { required: true, minLen: 32 },
PORT: { required: false, type: 'int', default: 3000 },
};
3) Alles validieren und alle Fehler sammeln
Falle nicht beim ersten Fehler durch. Es ist frustrierend, einen fehlenden Key zu fixen, neu zu deployen und dann auf den nächsten zu stoßen. Validiere das ganze Schema und gib eine Zusammenfassung aller Probleme zurück.
Halte die Prüfungen strikt:
- Pflicht vs optional
- Typ-Parsen (int, bool)
- Formatregeln (URL, Mindestlänge)
- Defaults nur für klar sichere Werte anwenden
4) Klare, handlungsfähige Fehler ausgeben
Deine Fehlermeldungen sollten in Minuten zu beheben sein:
- welche Keys fehlen
- welche Keys ungültig sind und welches Format erwartet wurde
- in welcher Umgebung du die App vermutest
Gib niemals geheime Werte aus.
5) Mit Nicht-Null-Code beenden
Wenn die Validierung fehlschlägt, stoppe den Prozess (z. B. process.exit(1) in Node). Das zwingt das Deployment dazu, schnell zu scheitern, anstatt live zu gehen und Auth, Zahlungen oder Jobs zur Laufzeit zu zerstören.
Defaults, optionale Werte und umgebungsspezifische Regeln
Defaults helfen nur, wenn sie echte Probleme nicht verschleiern. Ein sicherer Default macht Verhalten vorhersehbar; ein unsicherer Default lässt einen kaputten Deploy unentdeckt.
Als Regel: Default nur für Werte, die nicht sensibel sind und einen offensichtlichen Fallback haben (wie PORT im lokalen Dev). Secrets niemals defaulten. Fehlt ein Secret, sollte der Start fehlschlagen.
Wenn eine Variable wirklich optional ist, kennzeichne das im Schema und dokumentiere, was passiert, wenn sie fehlt.
Ein häufiger Sonderfall ist der leere String. Viele Plattformen erlauben, ein Secret versehentlich leer zu speichern. Behandle "" bei Secrets als fehlt.
Für umgebungsspezifische Regeln brauchst du meist kein komplett separates Schema. Nutze ein Basisschema und füge ein paar bedingte Regeln hinzu:
- development: lokale Defaults und optionale Integrationen erlauben
- staging: die meisten Einstellungen verlangen, Test-Credentials erlauben
- production: alle Secrets verlangen und strengere Formate durchsetzen (z. B. HTTPS erzwingen)
Hilfreiche Fehler ohne Geheimnisse zu leaken
Startprüfungen helfen nur, wenn Menschen schnell handeln können. Konfigurationsfehler sind aber auch eine häufige Quelle dafür, dass Geheimnisse in Logs, Screenshots und Support-Tickets landen.
Gute Fehlermeldungen nennen den Variablennamen, was falsch ist (fehlt, leer, falscher Typ, ungültiges Format) und einen sicheren Hinweis zum erwarteten Format (z. B. „muss mit postgres:// beginnen“). Wenn du zeigen musst, was empfangen wurde, dann redigiere es.
Behandle Namen, die SECRET, TOKEN, KEY, PASSWORD, PRIVATE, SESSION oder COOKIE enthalten, standardmäßig als sensibel.
Achte außerdem auf clientseitige Bundling-Regeln. Manche Frameworks exponieren env vars an den Browser basierend auf einem Prefix. Füge eine Regel hinzu, die secret-ähnliche Namen vom client-exponierten Config ausschließt.
Häufige Fehler, die trotzdem Laufzeitfehler verursachen
Die meisten Laufzeit-Konfigurationsfehler entstehen, weil Validierung zwar existiert, aber zu spät ausgeführt wird, zu wenig prüft oder vage meldet.
Auf diese Muster solltest du achten:
- Validierung nach dem Serverstart (Traffic kann halbfertigen Code treffen)
- nur das prüfen, „was zuletzt gebrochen ist“, statt die komplette erforderliche Menge
- schwache Typbehandlung (jeder nicht-leere String als
truebehandeln,NaNerlauben) - generische Fehler wie „Config invalid“ ohne Feld-Details
Halte das Schema aktuell, wenn du neue Features hinzufügst. Neue Features bringen fast immer neue Konfiguration mit.
Schnellchecks, bevor du auslieferst
Konfiguration ist ein Feature, das du testen kannst. Vor dem Deploy:
- entferne eine Pflichtvariable und vergewissere dich, dass der Fehler genau den Key nennt
- gib einen ungültigen Wert (z. B.
"abc"für eine Zahl) und prüfe, ob die Meldung den erwarteten Typ/Format erklärt - stelle sicher, dass Secrets in Logs redigiert bleiben, auch bei Fehlern
- vergewissere dich, dass die Validierung vor Migrationen, Workern, Queues oder Netzwerkaufrufen läuft
- vergewissere dich, dass der Prozess mit Nicht-Null beendet wird, sodass deine Plattform den Deploy als fehlgeschlagen markiert
Beispiel: Einen schlechten Deploy abfangen, bevor Nutzer es merken
Ein häufiger Produktionsfehler ist eine fehlende DATABASE_URL. Ohne Startprüfungen bootet der Server und scheitert erst beim ersten Request, der auf Daten zugreifen will. Die Logs zeigen einen langen Stacktrace vom DB-Client, und man rätselt, ob es Netzwerk, Berechtigungen oder Queries sind.
Mit einem Env-Schema verweigert die App das Starten und gibt eine klare Fehlermeldung aus:
- Fehlende erforderliche Umgebungsvariable:
DATABASE_URL - Erwartetes Format: URL (z. B.
postgres://...)
Wert setzen, neu deployen, fertig. Nutzer sehen nie eine defekte App.
Dasselbe gilt für Auth-Callback-URLs. Wenn AUTH_CALLBACK_URL fehlt, leer ist oder in Produktion kein HTTPS hat, ist es besser, den Start abzubrechen, als Nutzer später eine Login-Schleife erleben zu lassen.
Nächste Schritte: Konfiguration zuverlässig halten, wenn die App wächst
Sobald du ein Env-Schema hinzugefügt hast, mache es zum normalen Bestandteil des App-Starts in allen Umgebungen: lokaler Dev, Staging, Preview-Builds und Hintergrund-Worker. Konsistentes Verhalten zählt. Wenn eine Variable erforderlich ist, sollte die App überall verweigern zu starten.
Eine kurze Übergabedokumentation hilft zusätzlich: welche Variablen es gibt, wo sie gesetzt werden (Hosting-Dashboard, CI-Secrets, Container-Config) und wie sie rotiert werden.
Wenn du ein AI-generiertes Prototype geerbt hast, ist die Behandlung von env vars oft eine der schnellsten Stabilitätsverbesserungen – Konfiguration ist dort häufig verstreut und inkonsistent. FixMyMess (fixmymess.ai) hilft Teams, kaputte AI-erstellte Apps in produktionsreife Software zu verwandeln. Eine kurze Codebasis-Diagnose kann fehlende Config-Validierung und riskante Geheimnisbehandlung aufspüren, bevor daraus ein Deploy-Tag-Notfall wird.
Häufige Fragen
Warum funktioniert meine App lokal, bricht aber direkt nach dem Deployment?
Weil dein Laptop oft eine über Jahre angesammelte .env-Datei hat oder Framework-Defaults Lücken stillschweigend füllen. In Produktion musst du Werte in einem Dashboard oder CI neu eintragen – dort entstehen Tippfehler, fehlende Keys und falsche Umgebungswerte, die erst nach dem Deploy sichtbar werden.
Was bedeutet „fail fast“ bei der Validierung von Umgebungsvariablen?
Konfiguration so früh wie möglich beim Start prüfen: Fehlende oder ungültige Variablen klar benennen (ohne Geheimnisse auszugeben) und den Prozess mit einem Fehlercode beenden. So schlägt ein schlechter Deploy sofort fehl, anstatt halb zu funktionieren, bis ein Nutzer auf den fehlerhaften Pfad trifft.
Welche Env-Checks lohnen sich beim Start?
Die Form und Sicherheit der Konfiguration prüfen: Vorhandensein und Nicht-Leer-Werte, Typprüfung (int/bool), grundlegende URL-Validierung und erlaubte Werte wie production|staging|development. Langsame Checks wie Aufrufe externer APIs oder schwere Migrationen überspringen.
Wann sollte ich Defaults für Env-Variablen verwenden und wann nicht?
Defaults sind in Ordnung für nicht-sensible Werte mit offensichtlichem Fallback (z. B. lokaler PORT). Vermeide Defaults für sicherheitsrelevante Werte (Secrets, Tokens, Passwörter), weil sie einen defekten Deploy verschleiern können.
Wie soll ich leere Strings in Umgebungsvariablen behandeln?
Behandle "" und nur aus Leerzeichen bestehende Strings bei Pflichtwerten als fehlt, besonders bei Geheimnissen. Viele Plattformen erlauben aus Versehen leere Werte, die dann zwar gesetzt aussehen, aber unbrauchbar sind.
Brauche ich separate Schemata für Entwicklung, Staging und Produktion?
Behalte ein Schema für alle Umgebungen und ergänze nur ein paar bedingte Regeln für Produktion. Übliche Produktionsregeln verlangen HTTPS-URLs, längere Secrets und DEBUG=false.
Warum ein Schema statt verstreuter `if (!process.env.X)`-Prüfungen?
Sammle alle Regeln an einem Ort (z. B. ein config- oder Startup-Modul), validiere einmal beim Boot und gib die geparste Konfiguration weiter. So vermeidest du Namensinkonsistenzen wie DB_URL vs DATABASE_URL und Prüfungen, die nur bei seltenen Routen laufen.
Wie zeige ich hilfreiche Fehler, ohne Geheimnisse in Logs zu leaken?
Echoe niemals Geheimnisse in Fehlermeldungen oder Logs. Nenne die Variable und was falsch ist; wenn du zeigen musst, was empfangen wurde, dann nur in geredacter Form, damit Tickets oder Screenshots keine Zugangsdaten verraten.
Wann genau soll die Env-Validierung im Startablauf laufen?
Validation muss laufen, bevor der Server Anfragen entgegennimmt, bevor Datenbankverbindungen aufgebaut werden und bevor Third-Party-SDKs oder Worker initialisiert werden. Wenn du erst nach dem Start prüfst, können Anfragen halbfertige Pfade triggern.
Kann FixMyMess helfen, wenn mein AI-generiertes Prototype wegen Konfigurationsproblemen fehlschlägt?
Wenn die App von einer AI generiert wurde, sind Umgebungsvariablen oft inkonsistent verteilt über Routen, Jobs und Build-Schritte. FixMyMess bietet einen kostenlosen Code-Audit an, findet fehlende Validierung, exponierte Secrets und unsichere Annahmen und hilft, das Setup so zu reparieren, dass Releases laut und sicher fehlschlagen statt Nutzer zu beeinträchtigen.