Wann man eine Read-Replica hinzufügen sollte: Anzeichen, Routing und Fallstricke
Wann man eine Read-Replica hinzufügen sollte: eindeutige Anzeichen, sicheres Routing von Lesezugriffen und wie man Überraschungen durch Replikations-Lag und falsche Annahmen vermeidet.
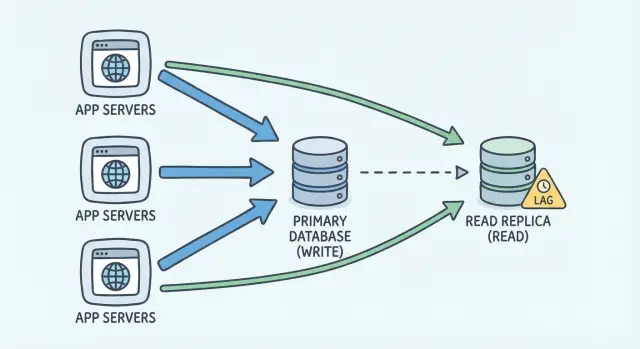
Welches Problem löst eine Read-Replica wirklich
Eine Read-Replica hilft, wenn Ihre Datenbank so viel Zeit mit Beantworten von Leseanfragen verbringt, dass die Schreibvorgänge darunter leiden. Es geht dabei nicht nur darum, Seiten schneller wirken zu lassen. Es geht darum, die Primary-Datenbank zu schützen, damit sie weiter Updates annehmen kann, statt hinter schweren SELECT-Abfragen stecken zu bleiben.
Das zeigt sich meist in einem vertrauten Muster: ein oder zwei beliebte Bildschirme (oder API-Endpunkte) erzeugen den Großteil der Datenbankarbeit. Ein Dashboard, das häufig aktualisiert wird, eine Suchseite oder eine "alles auflisten"-Admin-Ansicht kann CPU und I/O auffressen. Dann beginnen Teile der App, die Bestellungen anlegen, Profile aktualisieren oder Logs schreiben, Timeouts zu bekommen oder unvorhersehbar zu werden.
Eine Replica macht im Wesentlichen eine Sache: sie gibt Ihnen eine weitere Kopie der Daten, von der gelesen werden kann. Ihre App kann einige SELECTs an die Replica schicken, damit die Primary mehr Luft für INSERT/UPDATE/DELETE hat.
Was sie nicht löst:
- Langsame Abfragen, weil sie schlecht geschrieben sind oder Indizes fehlen
- Locking-Probleme durch lange Transaktionen auf der Primary
- Zu viele Schreibvorgänge (eine Replica erhöht nicht die Schreibkapazität)
- App-Logik, die davon ausgeht, dass jede Leseanfrage sofort aktuell ist
Der letzte Punkt macht deutlich: die Entscheidung betrifft die Korrektheit, nicht nur die Geschwindigkeit. Eine Replica hängt in der Regel etwas hinter der Primary. Wenn Sie zu einem ungünstigen Zeitpunkt von ihr lesen, sieht ein Nutzer vielleicht seine gerade aktualisierten Einstellungen nicht, eine "Bezahlung erfolgreich"-Seite sieht noch unbezahlt aus oder ein Support-Mitarbeiter glaubt, eine Aktion sei nicht erfolgt.
Eine gute Faustregel: Fügen Sie eine Read-Replica hinzu, wenn Sie eindeutig leseintensiven Traffic haben, der die Schreibleistung beeinträchtigt, und Sie benennen können, welche Endpunkte mit leicht veralteten Daten bedient werden dürfen.
Read-Replica-Grundlagen (ohne Fachsprache)
Eine Read-Replica ist ein zweiter Datenbankserver, der eine Kopie Ihrer Hauptdatenbank enthält. Sie behalten eine "Primary" als Quelle der Wahrheit. Alle Schreibvorgänge laufen dorthin, denn nur dort ist garantiert die aktuellste Version der Daten.
Die Replica ist hauptsächlich zum Lesen gedacht. Anstatt dass jede Seitenladung, jeder Bericht oder jedes Dashboard die Primary trifft, können einige schreibfreie Abfragen zur Replica gehen, damit die Primary für Schreibvorgänge und kritische Anfragen reaktionsfähig bleibt.
Wie die Kopie aktuell bleibt
Die meisten Setups verwenden asynchrone Replikation. Einfach gesagt: die Primary schreibt die Änderungen zuerst, dann empfängt die Replica diese Änderungen und wendet sie etwas später an. Diese Verzögerung nennt man Replikations-Lag. Manchmal ist sie winzig (Millisekunden). Unter Last oder während Spitzen kann sie auf Sekunden oder mehr wachsen.
Diese eine Tatsache erklärt die meisten Überraschungen, auf die Menschen stoßen.
Der Trade-off, den Sie wählen
Eine Replica kann Ihre App schneller wirken lassen, aber Sie bezahlen mit Aktualität. Reads von der Replica können etwas hinter der Primary liegen.
Ein einfaches mentales Modell:
- Primary: jetzt korrekt, behandelt Schreibvorgänge
- Replica: skaliert Reads, kann hinterherhinken
- Lag: die Lücke zwischen dem, was Sie gerade geschrieben haben, und dem, was die Replica sehen kann
Beispiel: ein Nutzer aktualisiert seine E-Mail-Adresse und lädt sofort die Profilseite neu. Wenn diese Seite von der Replica liest, zeigt sie für einen Moment möglicherweise noch die alte E-Mail. Das ist nicht dauerhaft falsch, aber verwirrend, wenn Sie die Reads nicht vorsichtig routen.
Anzeichen, dass Sie bereit sind, eine Replica in Betracht zu ziehen
Eine Read-Replica hilft, wenn Ihre Datenbank den Großteil ihrer Zeit mit Reads (SELECTs) verbringt, nicht mit Writes. Wenn CPU der Datenbank hoch ist und Ihre Top-Abfragen hauptsächlich SELECTs sind, ist das ein starkes Signal.
Ein weiteres häufiges Zeichen ist: "Leseverkehr schadet den Writes." Sie sehen, dass die Schreiblatenz genau dann ansteigt, wenn die Leseanfragen ihren Höhepunkt erreichen, obwohl das Schreibvolumen gleich geblieben ist. Reads und Writes konkurrieren um dieselbe CPU, denselben Speicher und dieselben Festplattenressourcen, daher können schwere Reporting-Seiten Checkout, Anmeldungen oder Updates verlangsamen.
Schauen Sie genau hin, was langsam ist. Listenseiten, Dashboards, Admin-Tabellen, Suchergebnisse und Exporte sind oft gute Kandidaten. Diese Endpunkte scannen häufig viele Zeilen und werden oft von echten Nutzern (oder Hintergrundjobs) aufgerufen.
Verbindungs-Pool-Druck ist ein weiterer praktischer Auslöser. Wenn Sie wegen leseintensiver Endpunkte die maximalen Verbindungen erreichen, kann eine Replica die Konkurrenz verringern. Sie behebt ineffiziente Abfragen nicht, kann aber Luft verschaffen.
Caching kann das Bedürfnis nach einer Replica verzögern, ist aber nicht immer ausreichend. Sie sind oft bereit für eine Replica, wenn:
- Die Cache-Hit-Rate niedrig bleibt, weil sich Daten häufig ändern oder Keys schwer zu entwerfen sind
- Caching zu sichtbaren "falschen Zahlen" für Nutzer führt
- Sie frische-ish Daten brauchen, aber nicht perfekt sofortige
- Exporte und Ad-hoc-Filter nicht sicher cachen lassen
- Ihre Cache-Schicht bereits eine Hauptquelle von Bugs ist
Ein Entscheidungsprozess, dem Sie folgen können
Behandeln Sie das Hinzufügen einer Replica wie ein kleines Experiment mit einem klaren Erfolgsmetriken. Das Ziel ist nicht "mehr Datenbanken hinzufügen", sondern "Schmerz reduzieren, ohne die Korrektheit zu brechen".
Beginnen Sie konkret. "Die App fühlt sich träge an" ist nicht ausreichend. Sie wollen eine kurze Liste von Endpunkten und Abfragen, die Sie vor und nachher messen können.
Ein Entscheidungsprozess, der für die meisten Teams funktioniert:
- Identifizieren Sie Ihre Top-Read-Endpunkte nach Abfrageanzahl und Gesamtzeit (Dashboard, Suche, Feed, Reports).
- Bestätigen Sie, dass die Datenbank der Flaschenhals ist (nicht App-Server-CPU, langsamer Code, fehlender Cache oder chatty API-Aufrufe).
- Teilen Sie Reads in zwei Buckets: muss-frisch-sein (Kontostände, Berechtigungen, Checkout) vs. kann-leicht-veraltet-sein (Analytics, Aktivitätslisten, öffentliche Seiten).
- Setzen Sie ein Ziel, das Sie verifizieren können, z. B. „reduziere Primary-Read-Last um 40 %“ oder „senke p95 Dashboard-Ladezeit von 3s auf 1s“.
- Definieren Sie einen Rollback-Plan: wie Sie Reads schnell zurück auf die Primary schalten, wenn etwas schief aussieht.
Dann entscheiden Sie, wohin Sie Reads routen. Ein guter erster Schritt ist, nur "kann-leicht-veraltet-sein"-Endpunkte an die Replica zu senden und alle Writes auf der Primary zu belassen. Vermeiden Sie zuerst das Mischen von Reads und Writes innerhalb derselben Anfrage. Genau dort schlägt Lag am stärksten zu.
Bevor Sie etwas in Produktion umschalten, führen Sie einen kurzen Sicherheitscheck durch:
- Können Sie erkennen, welche DB eine Anfrage bedient hat (Logs, Tags oder Tracing)?
- Können Sie Lag erkennen und temporär auf die Primary zurückfallen?
- Haben Sie einen kurzen Testplan für nutzerrelevante Korrektheit (Login, Zahlungen, Berechtigungen)?
Wenn Sie Verbesserung nicht messen können und nicht schnell zurückrollen können, pausieren Sie. Eine Replica fügt Komplexität hinzu, daher sollte der Nutzen offensichtlich sein.
Welche Endpunkte profitieren (und welche auf der Primary bleiben sollten)
Eine Read-Replica hilft am meisten, wenn Sie viele Reads haben, die nicht perfekt aktuell sein müssen. Ziel ist nicht, alles zu verschieben, sondern die Primary zu entlasten und die App korrekt zu halten.
Gute Kandidaten für eine Replica
Diese sind meist sicher, weil sie leseintensiv sind und selten Geld oder Zugriff betreffen:
- Öffentliche Seiten (Marketingseiten, Blog, öffentliche Produktseiten)
- Suche und Browsing (Filter, Kategorieseiten)
- Analytics und Reporting (Charts, Trends, Exporte)
- Admin-Listen (Tabellen mit Nutzern, Bestellungen, Logs), bei denen Klicks in Details die Primary treffen
- Schreibgeschützte APIs für Partner oder interne Tools
Nutzerprofil-Ansichten und Produktkataloge sind oft mit etwas Vorsicht in Ordnung. Die meisten Nutzer merken nicht, wenn ein Avatar oder eine Bio kurz verzögert aktualisiert wird.
Endpunkte, die auf der Primary bleiben sollten
Wenn es Geld oder Zugriff betrifft, lassen Sie es auf der Primary. Dazu gehören Checkout, Zahlungen, Abonnementstatus und alles, was entscheidet, was ein Nutzer sehen oder tun darf.
Achten Sie auch auf Endpunkte, die zwar lesend aussehen, aber stillschweigend schreiben. Teams fügen oft kleine Writes hinzu wie last_seen aktualisieren, View-Counter inkrementieren, Sessions auffrischen oder "zuletzt angesehen"-Einträge speichern. Wenn Sie solche Endpunkte zur Replica routen, können sie fehlschlagen (Replicas sind oft read-only) oder inkonsistent reagieren.
Eine einfache Regel: Senden Sie nur idempotente, schreibfreie Abfragen an Replikate. Behalten Sie alles, das den Zustand ändert oder über Zugriff entscheidet, auf der Primary. Wenn Sie nicht 100 % sicher sind, behandeln Sie es zunächst als Primary, bis Sie die Abfragen verifiziert haben.
Wie Sie Reads routen, ohne die App fragil zu machen
Reads zu routen klingt einfach: SELECTs zur Replica, Writes zur Primary. In der Praxis ist das Fragile alles drumherum: Connection-Handling, "read your own write"-Momente und was passiert, wenn die Replica hinterherhinkt.
Zwei praktische Routing-Ansätze
Sie routen üblicherweise an einer von zwei Stellen.
Wenn Sie im Anwendungscode routen, wählen Sie die Datenbank pro Endpunkt (oder pro Abfrage). Das ist klar und explizit: "Produkte durchsuchen" kann die Replica verwenden, während "Profil aktualisieren" die Primary nutzt. Nachteilig ist, dass Routing-Regeln über den Code verstreut und schwer zu überblicken werden können.
Wenn Sie über einen DB-Proxy oder Router routen, leben die Richtlinien an einem zentralen Ort, was Rollbacks beschleunigen kann. Das Risiko ist, dass Überraschungen verborgen werden: eine Abfrage, die Sie für sicher hielten, könnte zur Replica geroutet werden und plötzlich veraltete Ergebnisse liefern.
Machen Sie es robust (und einfach rückgängig)
Behandeln Sie Primary und Replica als unterschiedliche Ressourcen, nicht als austauschbare Hosts. Verwenden Sie getrennte Verbindungen und separate Pools, damit eine langsame Replica nicht den Pool für Writes verstopft.
Eine kleine Menge Sicherheitsregeln verhindert die meisten Vorfälle:
- Nach einem Schreibvorgang bleiben Nutzer für ein kurzes Fenster (oft Sekunden) "sticky" zur Primary.
- Standardmäßig Primary für alles, was Geld, Auth, Berechtigungen oder nutzergenerierte Inhalte kurz nach der Erstellung betrifft.
- Fügen Sie einen Kill-Switch hinzu, der alle Reads sofort zurück zur Primary lenkt (Config-Flag, Env-Var, Feature-Flag), und testen Sie ihn.
- Setzen Sie aggressive Timeouts für Replica-Reads und fallen Sie bei Timeout auf die Primary zurück, statt die Anfrage fehlschlagen zu lassen.
Beispiel: Ein Dashboard lädt 12 Widgets. Routen Sie langsame, nicht-kritische Widgets (Wochendiagramme, Top-Seiten) zur Replica, behalten Sie "aktueller Plan" und "letzte Rechnung" auf der Primary. Wenn die Replica Latenz hat, funktioniert die Seite weiterhin; nur die Diagramme sind etwas verzögert.
Wie Sie mit Replikations-Lag sicher umgehen
Replikations-Lag ist die Zeit, bis neue Daten, die auf der Primary geschrieben wurden, auf der Read-Replica sichtbar werden. Wenn Ihre App zu früh von der Replica liest, sehen Nutzer veraltete Informationen und denken, etwas sei kaputt.
Beginnen Sie damit, zu definieren, was "sicher veraltet" für Ihr Produkt bedeutet. Für ein Dashboard kann 5–30 Sekunden Verzögerung akzeptabel sein. Für Abrechnung, Passwörter oder Berechtigungen können selbst 1 Sekunde zu viel sein.
Praktische Regeln, die Überraschungen verhindern
Ein paar Regeln decken die meisten Fälle ab:
- Read-after-write: nachdem ein Nutzer etwas geändert hat, routen Sie die nächsten Anfragen für diesen Nutzer (oder Datensatz) zur Primary.
- Halten Sie kritische Bildschirme auf der Primary: Zahlungen, Login, Zugriffskontrolle und alles, was jemanden aussperren könnte.
- Wenn Sie Replica-Daten auf einem kritischen Bildschirm zeigen müssen, zeigen Sie einen "wird aktualisiert"-Zustand und behaupten Sie nicht, etwas sei final.
- Erkennen Sie Lag und hören Sie auf, die Replica zu benutzen, wenn der Lag zu hoch wird.
- Vermeiden Sie das Mischen von Primary- und Replica-Ergebnissen in derselben Antwort (das erzeugt unmögliche Kombinationen).
Konkretes Beispiel: Ein Nutzer ändert seine E-Mail-Adresse und landet auf der Profilseite. Wenn diese Seite von der Replica liest, zeigt sie möglicherweise noch die alte E-Mail. Mit Read-after-Write routen Sie diese Profilseite 30–60 Sekunden nach dem Update zur Primary. Nach Ablauf dieses Fensters sind normale Replica-Reads in Ordnung.
Lag-aware Routing ist auch bei Spitzen und Deploys wichtig. Replikate fallen oft zurück, wenn die Primary beschäftigt ist oder eine lang laufende Abfrage auftaucht. Wenn Ihre App den Replica-Lag messen kann (oder einen einfachen Schwellenwert prüft), können Sie Reads solange auf die Primary umschalten, bis die Replica aufgeholt hat.
Was zuerst kaputtgeht, wenn Sie eine Replica hinzufügen
Die ersten Fehler sind meist die, die Nutzer sofort bemerken: "Ich habe gespeichert, aber es hat sich nicht geändert." Eine kleine Verzögerung kann zu großem Vertrauensverlust führen.
Support-Tickets steigen oft, wenn Leute ein Profil bearbeiten, Einstellungen ändern oder einen Kommentar posten und nach dem Refresh die alten Daten sehen. Planen Sie für "read your own write"-Momente, nicht nur für mehr Kapazität.
Authentifizierung und Berechtigungsprüfungen fallen ebenfalls früh auf. Wenn ein Nutzer gerade einen Plan upgegraded hat, zu einem Team hinzugefügt wurde oder der Zugriff entzogen wurde, kann ein Replica-Read noch den vorherigen Zustand zurückliefern. Das führt zu "Warum bin ich noch ausgesperrt?" oder schlimmer, "Warum kann ich das noch sehen?".
Hintergrundjobs können sich ebenfalls merkwürdig verhalten. Viele Job-Systeme lesen eine Zeile, um zu entscheiden, ob Arbeit nötig ist. Mit veralteten Reads denken zwei Worker möglicherweise beide, die Arbeit sei noch offen, und führen sie doppelt aus, oder sie verpassen sie, weil die Replica nicht nachgezogen hat.
Selbst wenn technisch nichts falsch ist, kann die UI inkonsistent wirken. Paginierung und Sortierung springen, wenn eine Anfrage die Primary trifft und die nächste eine hinterherhinkende Replica. Sie sehen Duplikate, fehlende Einträge oder sich ändernde Seitenzahlen zwischen Klicks.
Zähler driften schneller, als man erwartet: Rate-Limits, View-Counts, ungelesene Badges, Benachrichtigungszahlen. Wenn eine Anfrage auf der Primary inkrementiert, die nächste aber von einer hinterherhängenden Replica liest, können Zahlen zurückspringen.
Wenn Sie eine einfache Default-Regel wollen, behalten Sie diese primary-only, bis Sie sie gründlich getestet haben:
- Bildschirme direkt nach einem Schreibvorgang (Speichern, Checkout, Einstellungen)
- Login, Berechtigungsprüfungen und sessions-bezogene Reads
- Work-Queue-Tabellen, die von Hintergrundjobs verwendet werden
- Alles, das auf exakte Reihenfolge oder exakte Counts angewiesen ist
- Rate-Limits, Kontingente und Badge-Counter
Häufige Fehler und Fallen
Die größte Falle ist, alle SELECTs an die Replica zu schicken, weil es "nur Reads" sind. Viele Reads sind Teil eines Flows, der das neueste Schreiben erwartet: "Konto erstellen" und dann "Profil laden", oder "in den Warenkorb legen" und dann "Warenkorb zeigen".
Ein weiteres häufiges Problem sind versteckte Read-after-Write-Abhängigkeiten. Eine Einstellungsseite speichert vielleicht Präferenzen und fetched sie sofort wieder. Ein Login-Endpunkt liest vielleicht eine Session direkt nach dem Schreiben. Treffen diese Reads während Lag auf die Replica, wirkt die App kaputt, obwohl der Write erfolgreich war.
Connection-Handling ist eine stille Schmerzquelle. Teilen Sie nicht einen Connection-Pool für Primary und Replica: die App könnte versehentlich Writes an die Replica schicken (oder Replica-only-Einstellungen auf der Primary laufen lassen). Selbst wenn es "funktioniert", wird Debugging schwerer, weil Logs und Metriken nicht klar zeigen, welche DB die Abfrage ausgeführt hat.
Monitoring wird oft zu spät hinzugefügt. Überwachen Sie Lag, Replica-Query-Fehler und langsame Abfragen separat und alarmieren Sie bei plötzlichen Änderungen nach Deploys.
Einige Fallen, die Sie besonders beachten sollten:
- Routing nach Endpunktnamen statt nach Frischebedarf
- Vergessen, dass Admin-Tools und Hintergrundjobs ebenfalls Abfragen ausführen
- Nicht testen, was passiert, wenn die Replica down ist oder Lag-Spitzen auftreten
- Caching veralteter Reads und damit längere Veralterung als beabsichtigt
- Keine schnelle Umschaltung, um den gesamten Traffic zurück auf die Primary zu schicken
Planen Sie einen Rollback, bevor Sie ausrollen. Ein Feature-Flag, das alle Reads erzwingt, kann Stunden retten.
Schnelle Checkliste, bevor Sie umschalten
Fangen Sie nicht mit der Infrastruktur an. Starten Sie mit einem Sicherheitscheck, damit Sie keine langsamen Seiten gegen verwirrende "warum hat meine Änderung nicht gespeichert"-Bugs eintauschen.
- Listen Sie Ihre Top-Read-Last-Bildschirme auf und markieren Sie, wie frisch die Daten sein müssen.
- Definieren Sie eine Read-after-Write-Regel (wer bleibt wie lange auf der Primary und welche Bildschirme sind abgedeckt).
- Messen Sie Replikations-Lag und legen Sie einen Schwellenwert fest, ab dem Sie die Replica nicht mehr verwenden.
- Beweisen Sie, dass Sie einen Kill-Switch haben und dass er funktioniert.
- Rollen Sie schrittweise aus und beobachten Sie Timeouts, Fehlerquoten und sichtbare Nutzerinkonsistenzen.
Ein einfaches Beispiel: Dashboard beschleunigen ohne UX zu brechen
Stellen Sie sich eine kleine SaaS-App vor. Das Dashboard hat Charts, "Top Customers" und Datumsfilter, die schwere Reporting-Abfragen auslösen. Gleichzeitig verwaltet der Einstellungsbereich Billing-Details, Teammitglieder und Berechtigungen. Der Traffic wächst, das Dashboard wird träge und Schreibvorgänge fühlen sich während Spitzen langsamer an.
Das ist ein guter Zeitpunkt für eine Read-Replica: nicht weil Sie unbedingt eine neue Datenbank wollen, sondern weil Sie vermeiden möchten, dass teure Reads mit wichtigen Writes konkurrieren.
Eine saubere Trennung sieht oft so aus:
- Dashboard-Reports, Exporte und Analytics-Widgets lesen von der Replica.
- Einstellungen, Berechtigungen, Einladungen und alles, was sofortige Wirkung haben muss, bleibt auf der Primary.
- Gemischte Endpunkte (z. B. Dashboard-Karten, die auch den aktuellen Plan des Nutzers zeigen) lesen den Plan entweder von der Primary oder akzeptieren eine kurze Verzögerung.
Dann fügen Sie kurzzeitige Stickiness nach Writes hinzu. Wenn ein Nutzer eine Rolle von "Viewer" zu "Admin" ändert und zurück zum Dashboard geleitet wird, kann das Lesen von der Replica die alte Rolle für ein paar Sekunden zeigen. Markieren Sie die Session mit "read from primary until time X" (oft 30–60 Sekunden) nach einem erfolgreichen Speichern. In diesem Fenster routen Sie Reads zur Primary. Nach Ablauf kehren Sie zur Replica zurück.
Wenn Sie mit einem übernommenen AI-generierten Codebestand arbeiten, in dem Read/Write-Routing bereits verstreut oder brüchig ist, hilft FixMyMess (fixmymess.ai) beim Diagnostizieren und Reparieren von Problemen wie unsicherem Read/Write-Splitting und fehlenden Lag-Fallbacks, sodass Replikate die Performance verbessern, ohne Korrektheit zu opfern.
Häufige Fragen
Welches Problem löst eine Read-Replica tatsächlich?
Eine Read-Replica hilft, wenn der Leseverkehr so stark ist, dass die Schreibvorgänge auf Ihrer Primary-Datenbank langsamer werden. Ziel ist es, die Primary für Updates reaktionsfähig zu halten, indem sichere, schreibfreie Abfragen an eine andere Kopie der Daten ausgelagert werden.
Wenn Ihre App sich langsam anfühlt, die Datenbank aber gar nicht der Engpass ist, löst eine Replica das eigentliche Problem nicht.
Wann sollte ich eine Read-Replica hinzufügen statt nur Abfragen zu optimieren?
Nutzen Sie eine Replica, wenn Ihre teuersten Abfragen überwiegend SELECTs sind und Sie feststellen, dass die Schreiblatenz bei Lese-Spitzen ansteigt. Ein häufiges Zeichen ist, dass ein paar Bildschirme (Dashboards, Suche, Admin-Listen) den Großteil der Datenbankzeit verbrauchen.
Liegt das Problem an schlechtem Query-Design oder fehlenden Indizes, beheben Sie das zuerst, bevor Sie zusätzliche Komplexität einführen.
Welche Endpunkte sind normalerweise sicher, an eine Replica zu senden?
Beginnen Sie damit, Endpunkte zu routen, die leicht veraltete Daten tolerieren, wie Analyse-Widgets, Aktivitäts-Feeds, Suchergebnisse und große Admin-Tabellen. Diese erzeugen meist viel Lese-Last ohne perfekte Aktualität zu benötigen.
Halten Sie den ersten Rollout eng gefasst, damit Sie die Wirkung messen und bei verwirrenden Nutzerberichten schnell zurückrollen können.
Was sollte immer auf der Primary-Datenbank bleiben?
Belassen Sie alles, was mit Geld, Zugriff oder sofortiger Nutzerbestätigung zu tun hat, auf der Primary. Dazu gehören Checkout, Zahlungen, Abonnementsstatus, Login, Berechtigungsprüfungen und Seiten, die Nutzer direkt nach dem Speichern sehen.
Diese Abläufe benötigen oft "read your own write" und Replikationslag kann die App inkonsistent erscheinen lassen.
Was ist Replikations-Lag und warum ist es wichtig?
Replikations-Lag ist die Verzögerung zwischen dem Schreiben auf der Primary und dem Sichtbarwerden dieser Änderung auf der Replica. Bei asynchroner Replikation ist die Replica in der Regel etwas hinterher; unter Last kann der Rückstand Sekunden betragen.
Deshalb ist die Entscheidung für eine Replica eine Frage der Korrektheit, nicht nur der Geschwindigkeit.
Wie verhindere ich, dass Nutzer "Ich habe es gerade aktualisiert, aber sehe noch die alten Daten" sagen?
Eine einfache Standardregel: nachdem ein Nutzer etwas geschrieben hat, routen Sie seine nächsten Anfragen für kurze Zeit (oft einige Sekunden) zur Primary. Das vermeidet das "Ich habe gespeichert, aber es hat sich nichts geändert"-Erlebnis.
Implementieren lässt sich das etwa als sitzungsbasierte Sticky-Logik oder als Routing-Regeln für bestimmte Endpunkte nach einem Schreibvorgang.
Was bricht am ehesten zuerst nach dem Hinzufügen einer Replica?
Das typischste Problem sind nutzersichtbare Inkonsistenzen: Jemand ändert Einstellungen, lädt die Seite neu und sieht den alten Wert, weil die Anfrage die Replica traf. Auch Zugriffsprüfungen können fehlschlagen, wenn Rollen- oder Planänderungen noch nicht auf der Replica angekommen sind.
Hintergrundjobs können doppelt arbeiten oder Arbeit verpassen, wenn sie sich auf veraltete Reads verlassen.
Was sind die größten Fehler, die Teams mit Read-Replicas machen?
Vermeiden Sie zuerst das Versenden aller SELECTs an die Replica — viele Reads sind Teil von Abläufen, die das jüngste Schreiben erwarten. Auch das Mischen von Primary- und Replica-Reads in derselben Antwort schafft widersprüchliche Zustände.
Halten Sie Routing-Regeln verständlich und sorgen Sie für eine einfache Rückschaltmöglichkeit, damit Sie bei Vorfällen nicht feststecken.
Wie mache ich Replica-Routing sicher rückgängig?
Haben Sie einen Kill-Switch, der alle Reads sofort zurück auf die Primary lenkt, und testen Sie ihn, bevor Sie ihn brauchen. Setzen Sie aggressive Timeouts für Replica-Reads und fallen Sie im Fehlerfall auf die Primary zurück, anstatt die Anfrage scheitern zu lassen.
Überwachen Sie Replikations-Lag und stellen Sie die Nutzung der Replica ein, wenn der Lag einen für Ihr Produkt unsicheren Schwellwert überschreitet.
Was, wenn mein Codebestand unordentlich (oder AI-generiert) ist und Read-Routing riskant klingt?
Wenn der Codebestand verstreute Datenzugriffe, versteckte Schreibzugriffe in scheinbar Lese-Endpunkten oder keine Möglichkeit zur Durchsetzung von Read-after-Write-Regeln hat, kann eine Replica verwirrende Bugs erzeugen. In solchen Fällen lohnt es sich oft, Routing, Connection-Pooling und Lag-Fallbacks zuerst zu reparieren.
FixMyMess hilft Teams dabei, AI-generierten oder übernommenen Code zu reparieren, bei dem Read/Write-Splitting brüchig ist, sodass Replikate Leistung verbessern, ohne die Korrektheit zu zerstören.