Webhook-Handler-Beobachtbarkeit: Logs, Event-IDs, Admin-Ansicht
Webhooks schlagen oft stillschweigend fehl ohne die richtige Sichtbarkeit. Lernen Sie Webhook-Handler-Beobachtbarkeit mit protokollierten Signaturprüfungen, gespeicherten Event-IDs und einer einfachen Admin-Ansicht.
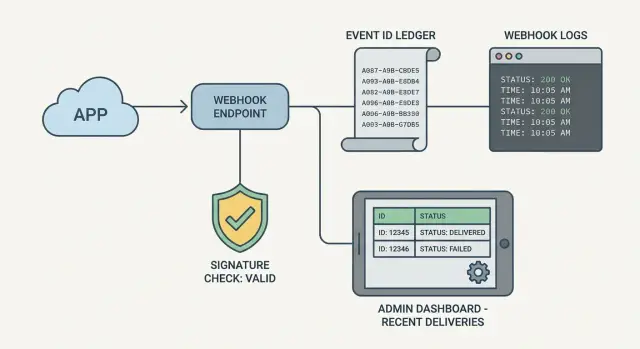
Warum Webhook-Handler sich unsichtbar anfühlen, wenn sie ausfallen
Webhooks sind schwerer zu debuggen als normale API-Aufrufe, weil Sie nicht derjenige sind, der den Button klickt, der die Anfrage abschickt. Ein Provider sendet ein Ereignis, wenn er will, aus Infrastruktur, die Sie nicht kontrollieren, und oft erfahren Sie nur von einem Problem, nachdem ein Kunde sich beschwert hat.
Bei einem typischen API-Endpunkt können Sie den Aufruf reproduzieren, die Antwort beobachten und iterieren. Bei Webhooks kann ein Fehler leise bleiben: der Provider versucht im Hintergrund erneut, Ihre App liefert ein generisches 500, und Sie rätseln, ob die Anfrage authentisch war, ob Ihr Code ausgeführt wurde und wo er abbrach.
Das Frustrierendste ist die Lücke, sobald Retries starten. Vielleicht sehen Sie einen Traffic-Peak und dann nichts Nützliches: keine eindeutige Ereigniskennung, keine Spur dessen, was bei jedem Versuch passiert ist, und keinen Nachweis, ob Sie es bereits verarbeitet haben. So kommt es zu Doppelbelastungen, verpassten Abo-Updates oder doppelten Datensätzen.
Beobachtbarkeit für Webhook-Handler bedeutet einfach, einige Fragen schnell beantworten zu können, ohne Roh-Payloads zu lesen oder einen lauten Debug-Modus einzuschalten:
- Wer hat die Anfrage gesendet, und hat sie die Signaturprüfung bestanden?
- Welches Ereignis war es (ID, Typ, Timestamp) und haben wir es schon gesehen?
- Was hat unser Handler getan, und warum ist er fehlgeschlagen (falls er fehlgeschlagen ist)?
Gute Beobachtbarkeit bleibt klein, sicher und leicht zu pflegen. Sie brauchen kein komplexes Monitoring. Ein paar strukturierte Logs, eine gespeicherte Event-ID und eine winzige Admin-Ansicht können einen unsichtbaren Webhook in etwas verwandeln, das Sie in Minuten verstehen.
Was „beobachtbar" für einen Webhook-Endpunkt bedeutet
„Beobachtbar" heißt, dass wenn eine Zustellung fehlschlägt (oder zwar OK aussieht, aber das falsche Ergebnis bringt), Sie ohne Rätselraten, blindes Neusenden oder Einmal-Dumps sagen können, was passiert ist.
Für jede Zustellung sollten Sie beantworten können:
- Haben wir die Anfrage erhalten, und wann?
- Hat die Signaturverifikation bestanden oder failed, und warum?
- Welches Ereignis war es (Event-ID), und haben wir es schon verarbeitet?
- Wie lange dauerte die Verarbeitung, und wo ging die Zeit verloren?
- Was haben wir an den Sender zurückgegeben (Statuscode und Fehlerart)?
Das ist der Kern: eine klare Spur von „angekommen" bis „fertig", mit genug Kontext, um Retries, Duplikate und Teilfehler zu debuggen.
Eine solide Basis erfasst eine kleine Menge Request-Header (nicht alle), das Ergebnis der Signaturprüfung (pass/fail plus kurzer Grund), eine stabile Ereigniskennung, Zeitstempel (empfangen/gestartet/beendet) und ein finales Ergebnis (processed, skipped as duplicate, rejected as invalid).
Achten Sie auf Datenschutz. Loggen Sie standardmäßig keine Geheimnisse, rohen Signaturen, Auth-Tokens oder komplette Payloads. Wenn Sie Payload-Visibility brauchen, speichern Sie eine minimale, redigierte Momentaufnahme (z. B. Event-Typ, Kunden-ID-Hash, Betrag) und bewahren Sie rohe Bodies nur kurzfristig an einem geschützten Ort auf.
Wenn Payloads persönliche Daten enthalten können (Namen, E-Mails, Adressen, Gesundheits- oder Finanzdaten), behandeln Sie Webhook-Logs wie Nutzerdaten. Setzen Sie Aufbewahrungsfristen, beschränken Sie den Zugriff und dokumentieren Sie, wer sie sehen darf. Das ist oft der Unterschied zwischen „nützlichem Logging" und einem Compliance-Zwischenfall.
Signaturprüfungen protokollieren, ohne Geheimnisse zu leaken
Die Signaturprüfung ist der Test „Bist du wirklich der, der du vorgibst zu sein?". Sie stoppt zufällige Anrufer, die sich als Ihr Zahlungsanbieter, E-Mail-Service oder ein anderes System ausgeben möchten.
Für Beobachtbarkeit wollen Sie genug Details, um zwei Dinge schnell zu beantworten: Wurde die Verifikation ausgeführt, und warum ist sie fehlgeschlagen? Der Trick ist, Ergebnisse und Kontext zu loggen, nicht geheime Inhalte.
Ein sicheres Muster ist ein Verifikations-Datensatz pro Anfrage mit Feldern, die für Support und Debugging nützlich, aber harmlos sind, wenn sie in ein Ticket kopiert werden.
Loggen Sie etwa:
- Ergebnis:
verified=true/falseund einen klarenreasonwiemissing_signature,bad_format,timestamp_out_of_windowodermismatch - Was Sie erwartet haben: Algorithmusname (z. B.
hmac-sha256) und welcher Header geprüft wurde (nur Header-Name) - Zeitkontext: Server-Timestamp, Alter der Anfrage (Sekunden) und ob Replay-Schutz angewandt wurde
- Identifier: Ihre generierte
request_idund, falls vorhanden, die Event-ID des Providers
Loggen Sie nicht den Secret-Key, den rohen Signaturwert, den vollen rohen Payload oder unredigierte Header.
Wenn die Verifikation fehlschlägt, vermeiden Sie „dump the request"-Logging. Loggen Sie stattdessen eine kleine redigierte Zusammenfassung: Payload-Größe, Content-Type und welche erforderlichen Header vorhanden waren.
Fügen Sie einfache Zähler hinzu, damit Fehler sichtbar werden, auch wenn niemand die Logs aktiv beobachtet. Mindestens sollten Sie Gesamtzahlen für verified, failed und missing signature verfolgen (optional nach Provider aufgeschlüsselt). Wenn ein Deploy aus Versehen den erwarteten Header-Namen ändert, sollten Ihre Logs einen Spike bei reason=missing_signature zeigen, statt eines vagen 401 ohne Hinweis.
Event-IDs speichern, um Dedupe und Retries nachzuvollziehen
Die meisten Webhook-Provider versuchen das gleiche Ereignis erneut, wenn Ihr Endpunkt timeouts hat, ein 500 zurückgibt oder ein Netzwerkproblem auftritt. Wenn Sie keine stabile Event-ID speichern, können Sie doppelt abrechnen, zweimal provisionieren oder doppelte E-Mails versenden. Das Speichern der Event-ID ist der einfachste Weg zur Idempotenz: dasselbe Ereignis kann Sie 1- oder 10-mal treffen, aber Sie wenden seine Effekte nur einmal an.
Beginnen Sie damit, für jede eingehende Webhook-Anfrage einen kleinen Datensatz zu speichern, selbst wenn Sie sonst nichts tun. Sie können ihn in einer Datenbanktabelle, einem Key-Value-Store oder einer Queue plus kleinem Audit-Table ablegen.
Ein minimaler Datensatz enthält üblicherweise Provider, Event-ID, Empfangs-Timestamp, Status (received/processed/failed/ignored) und eine optionale kurze Fehlermeldung.
Dann gehen Sie bei jeder Anfrage so vor: extrahieren Sie die Event-ID, fügen Sie sie mit einer Unique-Constraint auf (provider, event_id) ein, und wenn sie bereits existiert, geben Sie schnell 200 zurück und überspringen die Business-Aktion. Diese eine Prüfung verwandelt Retries von Ratenwerk in eine verlässliche Timeline.
Manche Provider senden keine klare Event-ID, oder Ihr Handler kann sie erst nach der Signaturprüfung lesen. In diesem Fall leiten Sie eine eigene ID aus stabilen Teilen der Anfrage ab, z. B. einem Hash aus provider + request path + einem stabilen Header + rohen Body-Bytes. Vermeiden Sie Zeitstempel oder alles, was sich zwischen Retries ändert.
Retention ist wichtig, weil Webhook-Payloads oft persönliche Daten enthalten. Eine praktische Regel ist: Zusammenfassungen länger behalten und rohe Daten kürzer (oder gar nicht). Bewahren Sie die Event-Zeile (provider, event ID, Zeitstempel, Status) 30–90 Tage auf, rohe Bodies nur kurzfristig (z. B. 24–72 Stunden) wenn überhaupt, und begrenzen Sie die Fehler-Nachrichtlänge, um das Risiko des Leakens zu verringern.
Beispiel: Ein Zahlungsanbieter versucht dasselbe invoice.paid-Ereignis dreimal. Mit gespeicherten Event-IDs sehen Sie einen Datensatz als processed und spätere Zustellungen als duplicate markiert, also wissen Sie, dass der Kunde nicht zweimal belastet wurde und warum der Provider weiter versucht hat.
Den Lebenszyklus aufzeichnen: received bis processed bis responded
Ein Webhook kann „ok" aussehen, weil der Sender ein 200 bekam, während Ihre App danach scheiterte. Um Beobachtbarkeit real zu machen, trennen Sie Lieferungs-Empfang (was Sie an den Sender zurückgeben) von Business-Verarbeitung (was Ihre App wirklich getan hat).
Wo möglich, antworten Sie schnell und erledigen Sie schwerere Arbeit im Hintergrund. Selbst wenn Sie inline verarbeiten, zeichnen Sie beide Teile als getrennte Schritte auf, damit Sie erkennen können, ob das Problem Verifikation, Parsing, Datenbankarbeit oder ein Timeout war.
Ein einfaches Lebenszyklus-Modell, das Sie abfragen können
Wählen Sie eine kleine Menge Zustände und bleiben Sie dabei. Es geht nicht um perfekte Details, sondern um schnelle Antworten.
Speichern Sie pro eingehendem Event eine Zeile (oder ein Dokument) mit:
- Zeitstempeln: received, verified, processing started, processing finished, responded
- Dauern: verification time, processing time, total time
- Zustand: received, verified, processed, failed, ignored
- Antwort: Statuscode, Handler-Version (optional), Fehlerklasse (ohne Geheimnisse)
- Korrelation: Provider-Event-ID plus Ihre interne Correlation-ID
Mit dieser Struktur zeigen sich Muster schnell. Wenn die meisten Fehler nach der Verifikation und nach 25 Sekunden auftreten, liegt die Vermutung nahe bei langsamen DB-Aufrufen, blockierten Queue-Workern oder fehlenden Indizes.
Correlation-IDs verbinden den Webhook mit dem Rest des Systems
Ein Webhook endet selten am Endpunkt. Er legt einen Nutzer an, markiert eine Rechnung als bezahlt, verschickt einen Beleg oder aktualisiert Zugangsrechte.
Speichern Sie die Event-ID des Providers und generieren Sie eine Correlation-ID, die Sie in Logs und nachgelagerte Jobs weiterreichen. Dann zeigt eine Suche die komplette Kette: request received, signature verified, job enqueued, payment marked paid, email sent.
Das ist wichtig in Codebasen, in denen der Handler „auf das Webhook antworten" und „die ganze Arbeit machen" in einer Funktion mischt. Die explizite Lebenszyklus-Darstellung verwandelt ein Rätsel in eine Timeline.
Schritt für Schritt: Beobachtbarkeit zu einem bestehenden Handler hinzufügen
Jede Webhook-Anfrage sollte eine Spur hinterlassen, der Sie später folgen können, auch wenn sie unterwegs abbricht.
Eine praktische Reihenfolge, die an einem bestehenden Endpunkt gut funktioniert:
- Fügen Sie strukturierte Logs mit einem konsistenten Feldsatz für jede Anfrage hinzu (provider, event ID, request ID, signature checked, outcome, duration).
- Überprüfen Sie früh die Signatur, und loggen Sie nur das Ergebnis (pass/fail) und den Grund. Nie das Secret oder die rohe Signatur loggen.
- Persistieren Sie die Event-ID des Providers, sobald Sie sie haben, und deduplizieren Sie darauf. Wenn es ein Retry ist, geben Sie eine sichere Antwort zurück und verzeichnen, dass es dedupliziert wurde.
- Verpacken Sie die Business-Logik so, dass Sie immer Status, Fehlerklasse und Timing erfassen, auch wenn eine Exception geworfen wird.
- Fügen Sie eine kleine Admin-Ansicht hinzu, die jüngste Webhook-Ereignisse und die Details zeigt, um die Frage „Was ist passiert?“ zu beantworten.
Nach dem ersten Schritt halten Sie das Log-Schema stabil. Wenn Felder jede Woche wechseln, wird das Suchen zur Ratelei. Wenn möglich, erzeugen Sie eine request ID an der Peripherie und tragen Sie sie durch Logs und den Event-Datensatz.
Bei Signaturprüfungen machen Sie Fehlermeldungen menschlich: „Signature failed: missing header X" ist handlungsorientiert. „Invalid signature" ist es nicht. Genau hier leaken Teams oft sensible Daten aus Versehen, also seien Sie strikt, was Sie aufzeichnen.
Für die Admin-Ansicht reicht kein volles Dashboard. Eine Tabelle der letzten 50 Events plus eine Detailseite genügen. Die Detailseite sollte empfangene Zeit, Event-ID, Verarbeitungsstatus, Response-Code, Dauer und die letzte Fehlerklasse (z. B. ValidationError vs DatabaseError) zeigen.
Eine kleine Admin-Ansicht, die „Was ist passiert?“ beantwortet
Sie brauchen kein großes Dashboard, um Webhooks zu debuggen. Die kleinste nützliche Admin-Ansicht ist ein Screen mit einer Tabelle der letzten Ereignisse und einem Detailpanel. Wenn jemand fragt, warum eine Zahlung, Anmeldung oder Sendung nicht aktualisiert wurde, sollten Sie in zwei Minuten antworten können.
Eine gute Recent-Events-Tabelle zeigt genug, um Muster wie wiederholte Retries, einen Provider-Ausfall oder 500er Ihres Handlers zu erkennen. Halten Sie das Layout konsistent, damit es schnell scanbar ist.
Einschließen sollten Sie:
- Event-ID (Provider-ID plus interne ID, falls vorhanden)
- Provider und Event-Typ, Empfangszeit
- Status (received, verified, processed, failed, ignored)
- Versuche und Zeitpunkt des letzten Versuchs
- Letzte Fehlermeldung (kurz, abgeschnitten)
Im Detailpanel fokussieren Sie auf das Wesentliche: hat die Signaturprüfung bestanden, welche Handler-Version lief, welche Antwort wurde gesendet, wichtige Zeitstempel (received/verified/processed) und die Correlation-ID, die in Ihre Logs führt.
Aktionen können helfen, aber nur wenn sie sicher sind: Reprocess (nur wenn Ihr Handler idempotent ist), mark as ignored (für bekannte fehlerhafte Events oder Test-Noise), interne Notiz hinzufügen und eine Support-Zusammenfassung kopieren (Event-ID, Status, letzte Fehlermeldung).
Sperren Sie diese Ansicht für Admins und protokollieren Sie jede Admin-Aktion (wer, wann, warum).
Häufige Fehler, die Webhook-Debugging erschweren
Ein Webhook kann „funktionieren" und trotzdem unverständlich sein, wenn etwas schiefläuft. Vieles entsteht durch kleine Entscheidungen, die das eigentliche Versagen verbergen oder laute Nebenwirkungen erzeugen.
Ein großer Fehler ist das Loggen kompletter Rohpayloads. Viele Bodies enthalten E-Mails, Adressen, Tokens oder Geheimnisse. Loggen Sie stattdessen eine sichere Zusammenfassung: Event-Typ, Provider, Event-ID, Request-Timestamp und einen kurzen Hash des Bodys. Wenn Sie tiefere Details brauchen, speichern Sie eine verschlüsselte Kopie mit kurzer Aufbewahrung und strengem Zugriff.
Retries können sich auch selbst schaden: Wenn ein Ereignis bereits verarbeitet wurde, löst eine Nicht-2xx-Antwort oft endlose Retries und doppelte nachgelagerte Aktionen aus. Machen Sie „already processed" zu einem expliziten Ergebnis und geben Sie 2xx mit einer klaren Logzeile zurück, dass es dedupliziert wurde.
Eine weitere Falle ist das Vermischen von Verifikations- und Verarbeitungsfehlern. Wenn die Signaturprüfung fehlschlägt, ist das ein Sicherheits-Signal. Wenn die Business-Logik nach der Verifikation scheitert, ist das ein Anwendungsfehler oder ein Datenproblem. Wenn beides wie „500 error" aussieht, verlieren Sie die Handlungsfähigkeit.
Operative Probleme, die häufig auftreten:
- Keine Timeouts für Datenbank- oder API-Aufrufe, sodass der Handler hängt, bis der Provider aufgibt
- Fehler ohne Provider-Name, Event-Typ, Event-ID und interne Request-ID loggen
- Nur Exceptions loggen, nicht aber die Entscheidung (ignored, queued, processed, deduped)
- Unterschiedliche Log-Formate zwischen Umgebungen, was Vergleiche erschwert
Beispiel: Ein Zahlungsanbieter retried ein Event 12-mal. Ihre Logs zeigen 12 mal „500", aber keinen Hinweis, ob die Signatur fehlgeschlagen ist, die DB einen Timeout hatte oder das Event bereits verarbeitet wurde. Mit Beobachtbarkeit würde der erste Eintrag „verified ok" zeigen, der nächste „DB timeout after 3s" und spätere Retries würden als deduped verzeichnet.
Schnelle Checks, bevor Sie sagen, es sei fertig
Testen Sie die Webhook-Beobachtbarkeit wie eine gestresste, müde Person mit Zeitdruck. Wenn Sie grundlegende Fragen nicht schnell beantworten können, wird das zukünftige Sie quälen, wenn der Provider dasselbe Event stundenlang neu versucht.
Starten Sie mit einem einfachen Benchmark: Wählen Sie eine echte Provider-Event-ID und stoppen Sie die Zeit. Sie sollten dieses einzelne Event (und seine Zustellungshistorie) in unter 30 Sekunden finden können, ohne zu raten, welcher Server es bearbeitet hat.
Eine kurze Preflight-Checkliste deckt die meisten Lücken ab:
- Suche funktioniert: Ein Einfügen der Provider-Event-ID zeigt einen klaren Datensatz, nicht fünf Near-Duplikate
- Signaturstatus ist offensichtlich: Logs zeigen verified yes/no plus den Grund bei Fehlern
- Retries sind sichtbar: Anzahl der Versuche und letzter Versuch sind leicht zu finden
- Fehlerart ist klar: Sie können Exception vs Timeout vs Validation Failure unterscheiden
- Daten sind sicher: Geheimnisse und persönliche Daten sind in Logs und Speicherung ausgeschlossen oder redigiert
Führen Sie einen realistischen Drill durch. Triggern Sie ein Event, von dem Sie wissen, dass es fehlschlagen wird (z. B. ein Payload ohne ein Pflichtfeld). Bestätigen Sie, dass Sie beantworten können: Ist es bei Ihnen angekommen, hat die Verifikation bestanden, was haben Sie zurückgegeben, war es langsam, und wurde es erneut versucht?
Scannen Sie abschließend auf unbeabsichtigte Leaks. Webhooks enthalten oft E-Mails, Adressen, Tokens oder vollständige Kartendaten. Logs sollten nur das speichern, was zum Debuggen nötig ist: Event-ID, Provider-Name, Zeitstempel, Signaturergebnis, Status und eine kurze Fehlermeldung.
Beispiel: Ein fehlgeschlagener Zahlungs-Webhook und wie Sie ihn nachverfolgen
Ein typisches Support-Ticket: Ihr Zahlungsanbieter sendet ein invoice.paid-Webhook, die Karte des Kunden wird belastet, aber der Kunde hat trotzdem keinen Zugriff auf den bezahlten Plan.
Mit Beobachtbarkeit stoppen Sie das Rätselraten. Sie öffnen Ihre Admin-Ansicht und suchen im Zeitfenster. Sie finden den exakten Webhook-Aufruf.
Die ersten Fragen sind sofort beantwortet: Signaturverifikation ist pass, die Provider-Event-ID ist gespeichert (z. B. evt_01H...), und der Request-Timestamp stimmt mit dem des Providers überein. Sie wissen, dass es echt ist und Ihren Server erreicht hat.
Im Event-Detail zeigt der Lebenszyklus:
- Received: 2026-01-20 14:03:12
- Verified: pass
- Processing: failed
- Responded: 500
Das Error-Feld deutet auf die Ursache hin, z. B. „Cannot insert subscription row: missing user_id." Das sagt Ihnen: der Bug liegt in Ihrem Code, nicht beim Provider.
Jetzt kommen Retries rein. Hier zählt Idempotenz. Weil Sie die Event-ID gespeichert und als einzigartig behandelt haben, gewährt der Handler keinen doppelten Zugriff. Spätere Zustellungen werden als Duplikate markiert und übersprungen oder je nach Design sicher erneut ausgeführt.
Nachdem Sie den Bug behoben haben, können Sie das fehlgeschlagene Event aus der Admin-Ansicht neu verarbeiten. Der Zustand wechselt zu processed, die Antwort wird 200 und der Kunde erhält Zugriff.
Für den Support haben Sie jetzt saubere Fakten: Timestamp des Originals, Event-ID und den aktuellen Zustand (received, verified, processed, failed).
Nächste Schritte, wenn Ihr Webhook-Code weiterhin brüchig wirkt
Wenn Ihr Webhook-Handler sich noch wie eine Blackbox anfühlt, beginnen Sie mit der kleinsten Änderung, die Ihnen ein Signal gibt: loggen Sie das Ergebnis der Signaturprüfung (pass oder fail) und speichern Sie die Event-ID des Providers. Das alleine verwandelt „es hat nicht funktioniert" meist in einen klaren Weg zur Lösung, ohne die Business-Logik zu ändern.
Halten Sie diese ersten Logs langweilig und sicher. Zeichnen Sie Ergebnisse und Zeit auf, nicht Geheimnisse. Loggen Sie, dass die Verifikation fehlgeschlagen ist, welcher Provider beteiligt war und welche Event-ID vorhanden war, aber niemals rohe Header oder Signaturwerte.
Sobald Sie zuverlässig Event-IDs und Status erfassen, fügen Sie eine kleine Admin-Ansicht hinzu. Bauen Sie noch kein komplettes Dashboard. Eine einfache Tabelle, die beantwortet „haben wir es erhalten, haben wir es verifiziert, haben wir es verarbeitet, was ist gescheitert und was haben wir zurückgesendet?" ist ausreichend.
Wenn der Webhook-Code von einer KI generiert wurde und unzuverlässig wirkt, planen Sie eine Aufräumaktion. Häufige Warnsignale sind gebrochene Auth-Annahmen, chaotisches Retry-Verhalten (Doppelbelastungen, doppelte E-Mails) und Geheimnisse, die in Konfigurationen oder Logs verstreut sind.
Eine praktische Reihenfolge:
- Strukturierte Logs für Signaturergebnis und Request-ID hinzufügen
- Webhook-Event-IDs speichern und darauf deduplizieren
- Einen klaren Status-Lebenszyklus aufzeichnen (received, verified, processed, failed)
- Eine kleine Admin-Ansicht für letzte Events und Fehler bauen
- Gezieltes Refactoring für Retries, Idempotenz und Secret-Handling
Wenn Sie mit einem kaputten, KI-erstellten Prototypen arbeiten und ihn produktionsreif machen müssen: FixMyMess (fixmymess.ai) spezialisiert sich auf Diagnose und Reparatur von KI-generiertem Code, einschließlich Webhook-Handlern mit wackeliger Auth, Retry-Bugs und unsicherem Logging.
Häufige Fragen
What’s the simplest way to make my webhook handler observable?
Beginnen Sie damit, bei jeder Anfrage drei Dinge zu protokollieren: ob die Signaturprüfung bestanden hat, die Event-ID des Providers und ein klares Ergebnis wie processed, failed oder deduped. Fügen Sie Zeitangaben (empfangen und beendet) hinzu, damit Sie Timeouts erkennen. Diese kleine Basis macht aus einem mysteriösen 500 meist etwas, womit man schnell arbeiten kann.
Why do webhook bugs feel so hard to debug compared to normal API calls?
Webhooks scheitern leise, weil Sie nicht kontrollieren, wann oder von wo sie gesendet werden, und Provider oft im Hintergrund neu versuchen. Ohne gespeicherte Event-IDs und strukturierte Logs sieht jede Retry wie eine neue Anfrage aus, und Sie können nicht unterscheiden, ob es ein Duplikat, ein Signaturproblem oder ein echtes Verarbeitungsproblem ist.
What should I log for signature verification without leaking secrets?
Protokollieren Sie das Ergebnis und den Grund, nicht geheimes Material. Ein gutes Eintragungsformat ist verified=true/false plus ein kurzer Grund wie missing_signature oder timestamp_out_of_window, zusammen mit dem Header-Namen, den Sie geprüft haben, und dem Algorithmusnamen. Protokollieren Sie niemals den Signier-Geheimnis, die rohe Signatur oder vollständige Header.
How do I stop retries from causing duplicate charges or duplicate records?
Speichern Sie die Event-ID des Providers so früh wie möglich und erzwingen Sie eine eindeutige Einschränkung auf (provider, event_id). Wenn die ID schon bekannt ist, geben Sie eine sichere 2xx-Antwort zurück und überspringen die Geschäftsaktion, während Sie aufzeichnen, dass sie dedupliziert wurde. So vermeiden Sie Doppelbelastungen, doppelte Provisionierung und wiederholte E-Mails bei Retries.
What if my webhook provider doesn’t include a reliable event ID?
Leiten Sie eine stabile ID aus Teilen ab, die sich bei Retries nicht ändern, z. B. ein Hash aus Provider-Name + Request-Pfad + rohen Body-Bytes oder einem stabilen Header plus Body. Vermeiden Sie Zeitstempel oder andere Felder, die bei jedem Versuch anders sind. Behandeln Sie die abgeleitete ID danach wie eine normale Event-ID für Dedupe und Tracing.
What lifecycle fields should I record so I can trace where it failed?
Trennen Sie „Zustellbestätigung“ von „Business-Verarbeitung“. Zeichnen Sie auf, wann die Anfrage ankam, wann die Verifikation abgeschlossen war, wann die Verarbeitung begann und endete, und welchen Status-Code Sie zurückgaben. So sehen Sie sofort, ob Sie 200 an den Sender zurückgegeben haben, aber die eigentliche Arbeit später fehlgeschlagen ist.
How do I log webhook data without creating a privacy or compliance problem?
Standardmäßig nur sichere Zusammenfassungen: Provider, Event-ID, Event-Typ, Zeitstempel, Status und eine kurze Fehlerklasse/-nachricht ohne Geheimnisse oder persönliche Daten. Wenn Sie Rohdaten speichern, verschlüsseln Sie sie, beschränken Sie den Zugriff und bewahren sie nur kurz auf. Behandeln Sie Webhook-Logs wie Nutzerdaten, da sie oft E-Mails, Adressen oder finanzielle Metadaten enthalten.
What should a minimal admin view for webhooks include?
Eine Tabelle der letzten Ereignisse plus eine Detailansicht reichen. Zeigen Sie Event-ID, Provider, Typ, Empfangszeit, Status, Versuche/letzter Versuch, Signaturergebnis, Response-Code, Dauer und die letzte Fehlerklasse. Wenn Sie eine Reprocess-Schaltfläche anbieten, stellen Sie sicher, dass Ihr Handler idempotent ist, damit ein erneutes Verarbeiten Effekte nicht doppelt anwendet.
What are the most common mistakes that make webhook debugging worse?
Protokollieren Sie keine kompletten Rohpayloads und loggen Sie keine rohen Header, Tokens oder Signaturen. Trennen Sie Signaturfehler von Verarbeitungsfehlern, setzen Sie Timeouts auf Datenbank- und externe Aufrufe und speichern Sie Event-IDs — andernfalls verlieren Sie die Fähigkeit, Duplikate und Retries klar zu erkennen.
My webhook code was generated by an AI tool and keeps breaking—what should I do?
Wenn der Handler von einer KI erzeugt und fehlerhaft ist, beginnen Sie mit einer schnellen Überprüfung der Signaturverifikation, Idempotenz, Geheimnisbehandlung und Logging-Sicherheit. Wenn Sie es schnell repariert brauchen, kann FixMyMess (fixmymess.ai) kaputte Webhook-Handler diagnostizieren und reparieren, Auth-Probleme beheben und unsicheres Logging entfernen — in der Regel innerhalb von 48–72 Stunden nach einem kostenlosen Code-Audit.