Webhook-Zuverlässigkeit: Nie wieder Stripe-, GitHub- oder Slack-Ereignisse verpassen
Webhook-Zuverlässigkeit verhindert verpasste oder doppelt verarbeitete Stripe-, GitHub- und Slack-Ereignisse durch Signaturprüfung, Idempotenz, Wiederholungsstrategien und Dead-Letter-Verarbeitung.
Warum Webhook-Handler in der Praxis scheitern
Ein Webhook ist ein Callback: ein System schickt deinem Server eine HTTP-Anfrage, wenn etwas passiert — etwa eine Zahlung, ein Push oder eine neue Nachricht.
Auf dem Papier klingt das sauber. In Produktion bricht die Zuverlässigkeit, weil Netzwerke unordentlich sind und Anbieter sich mit Retries absichern. Dasselbe Ereignis kann zweimal ankommen, verspätet ankommen oder so aussehen, als sei es nie angekommen.
Teams stoßen meistens auf einige wiederkehrende Fehlerbilder:
- Fehlende Events: dein Endpoint ist getimed out, abgestürzt oder kurz nicht erreichbar gewesen.
- Duplikate: der Anbieter hat erneut gesendet und du hast dasselbe Event zweimal verarbeitet.
- Lieferung außer Reihenfolge: Event B kommt vor Event A an, obwohl A zuerst passiert ist.
- Teilweise Verarbeitung: du hast in die Datenbank geschrieben, bist dann gescheitert, bevor du geantwortet hast, und wurdest erneut aufgerufen.
Die meisten Anbieter garantieren nur "mindestens einmal" Lieferung, nicht "einmal und nur einmal". Sie versuchen hart zu liefern, können aber kein perfektes Timing, exakte Reihenfolge oder eine einzelne Zustellung sicherstellen.
Das Ziel ist also nicht, Webhooks perfekt zu machen. Das Ziel ist, dass dein Ergebnis korrekt ist, selbst wenn Requests doppelt, verspätet oder außer Reihenfolge ankommen. Der Rest dieses Leitfadens konzentriert sich auf vier Schutzmaßnahmen, die die meisten realen Ausfälle abdecken: Idempotenz, Signaturprüfung, sinnvolle Retries und ein Dead-Letter-Pfad, damit Fehler sichtbar werden statt still zu verschwinden.
Was Stripe, GitHub und Slack mit deinem Endpoint machen werden
Webhook-Anbieter sind höflich, aber nicht geduldig. Sie senden ein Event, warten kurz und wenn dein Endpoint nicht so antwortet wie erwartet, versuchen sie es erneut. Das ist normales Verhalten.
Nimm an, dass Folgendes früher oder später passiert:
- Timeouts: dein Endpoint braucht zu lange, deshalb gilt die Zustellung als fehlgeschlagen.
- Retries: sie senden dasselbe Event neu, manchmal mehrfach.
- Bursts: ein ruhiger Tag verwandelt sich in 200 Events pro Minute.
- Temporäre Fehler: dein Server liefert 500, ein Deploy startet Worker neu, oder DNS hat einen Aussetzer.
- Lieferverzögerungen: Events kommen Minuten später als erwartet an.
Doppelte Zustellung überrascht viele Teams. Selbst wenn dein Code alles richtig machte, weiß der Anbieter das oft nicht. Wenn dein Handler timet out, keinen 2xx-Status zurückgibt oder die Verbindung früh schließt, kann dasselbe Event nochmal kommen. Wenn du jede Zustellung als neu behandelst, kannst du doppelt belasten, doppelt upgraden, doppelte E-Mails senden oder doppelte Datensätze erzeugen.
Auch die Reihenfolge ist nicht garantiert. Du könntest "subscription.updated" vor "subscription.created" sehen, oder eine Slack-Message-Editierung vor der ursprünglichen Erstellung, abhängig von Retries und Netzwerkwegen. Wenn deine Logik eine saubere Sequenz annimmt, kannst du neuere Daten mit älteren überschreiben.
Das wird schlimmer, wenn dein Handler von langsamer downstream-Arbeit abhängt wie einer Datenbankschreibung, dem Versenden von E-Mails oder dem Aufruf einer anderen API. Ein realistischer Ausfall sieht so aus: dein Code wartet 8 Sekunden auf einen E-Mail-Anbieter, der Webhook-Sender timet bei 5 Sekunden aus, wiederholt die Zustellung, und jetzt kämpfen zwei Requests darum, denselben Datensatz zu aktualisieren.
Ein guter Handler behandelt Webhooks wie unzuverlässige Zustellungen: schnell akzeptieren, verifizieren, deduplizieren und kontrolliert verarbeiten.
Idempotenz: die eine Maßnahme, die doppelte Verarbeitung verhindert
Idempotenz bedeutet: wenn dasselbe Webhook-Event zweimal (oder zehnmal) deinen Server trifft, landet dein System im selben Zustand, als hättest du es nur einmal verarbeitet. Das ist wichtig, weil Retries normal sind.
In der Praxis ist Idempotenz Deduping mit Gedächtnis. Wenn ein Event eintrifft, prüfst du, ob du es schon verarbeitet hast. Wenn ja, gibst du Erfolg zurück und tust sonst nichts. Wenn nein, verarbeitest du es und zeichnest auf, dass du es getan hast.
Was du zum Deduping brauchst
Du brauchst nicht viel, aber etwas Stabiles:
- Event-ID des Anbieters (am besten, wenn verfügbar)
- Name des Anbieters (Stripe vs GitHub vs Slack)
- Wann du es zuerst gesehen hast (nützlich für Cleanup und Debugging)
- Verarbeitungsstatus (empfangen, verarbeitet, fehlgeschlagen)
Speichere das an einem langlebigen Ort. Eine Datenbanktabelle ist die sicherste Vorgabe. Ein Cache mit TTL kann bei unkritischen Events funktionieren, aber er kann bei Neustarts oder Evictions vergessen werden. Bei Zahlungs- oder Zugriffsänderungen behandle den Dedupe-Eintrag als Teil deiner Daten.
Wie lange solltest du Schlüssel aufbewahren? Länger als das Retry-Fenster des Anbieters und länger als deine eigenen verzögerten Retries. Viele Teams behalten 7 bis 30 Tage und laufen dann alte Einträge aus.
Seiteneffekte, die du schützen solltest
Idempotenz schützt deine risikoreichsten Aktionen: doppelte Abbuchungen, doppelte E-Mails, zweimaliges Upgraden einer Rolle, doppelte Rückerstattungen oder doppelte Tickets. Wenn du diese Woche nur eine Zuverlässigkeitsverbesserung machst, dann diese.
Signaturprüfung ohne Stolperfallen
Signaturprüfung verhindert, dass beliebiger Internettraffic so tut, als käme er von Stripe, GitHub oder Slack. Ohne sie kann jede*r deine Webhook-URL anpingen und Aktionen auslösen wie "Rechnung als bezahlt markieren" oder "Benutzer ins Workspace einladen". Gefälschte Events können echt genug aussehen, um einfache JSON-Checks zu umgehen.
Was du normalerweise prüfst: den rohen Request-Body (exakte Bytes), einen Zeitstempel (gegen Replay-Angriffe), ein geteiltes Secret und den erwarteten Algorithmus (oft ein HMAC). Wenn sich einer dieser Inputs auch nur minimal ändert, passt die Signatur nicht mehr.
Die häufigste Falle in echten Integrationen: JSON parsen, bevor du verifizierst. Viele Frameworks parsen und serialisieren den Body neu, wodurch Whitespace oder Schlüsselreihenfolge verändert werden. Dein Code prüft dann eine andere Zeichenkette, als der Anbieter signiert hat, und du lehnt echte Events ab.
Weitere häufige Stolperfallen:
- Verwendung des falschen Secrets (Test vs Production oder Secret des falschen Endpoints).
- Ignorieren einer Zeitstempeltoleranz und dann gültige Events ablehnen, wenn deine Serveruhr abweicht.
- Prüfung des falschen Headers (manche Anbieter senden mehrere Signatur-Versionen).
- 200 zurückgeben, obwohl die Verifikation fehlgeschlagen ist — das macht Debugging schwer.
Sicheres Fehlerverhalten ist einfach: wenn die Verifikation fehlschlägt, lehne schnell ab und führe keine Geschäftslogik aus. Gib einen klaren Client-Fehler zurück (üblich 400, 401 oder 403, je nach Anbieter). Logge nur das, was beim Diagnostizieren hilft: Anbietername, Event-ID (falls vorhanden), eine kurze Begründung wie "bad signature" oder "timestamp too old" und deine eigene Request-ID. Vermeide das Loggen roher Bodies oder voller Header, da diese Secrets enthalten können.
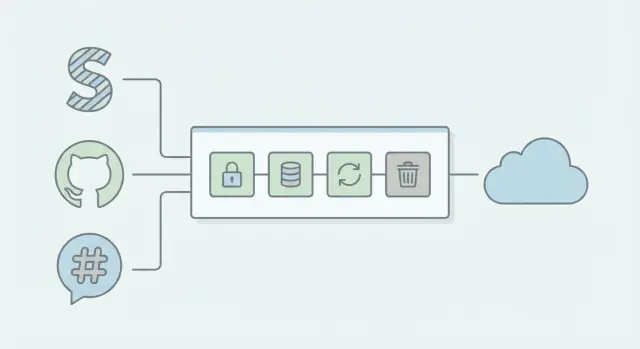
Eine einfache Webhook-Architektur, die unter Last stabil bleibt
Das zuverlässigste Muster ist unspektakulär: mache in der HTTP-Anfrage so wenig wie möglich, und übergib die eigentliche Arbeit an einen Hintergrund-Worker.
Der sichere, schnelle Request-Pfad
Wenn Stripe, GitHub oder Slack deinen Endpoint aufruft, halte den Request-Pfad kurz und vorhersehbar:
- Signatur und grundlegende Header verifizieren (bei ungültigen Daten schnell ablehnen)
- Das Event und einen eindeutigen Event-Key aufzeichnen
- Einen Job in die Warteschlange stellen (oder eine "Inbox"-Zeile schreiben)
- Sofort mit 2xx antworten
Ein schnelles 2xx ist wichtig, weil Webhook-Sender bei Timeouts und 5xx-Fehlern erneut senden. Wenn du langsame Arbeit (Datenbank-Fan-out, API-Aufrufe, E-Mails) vor dem Antwortsenden machst, erhöhst du Retries, doppelte Zustellungen und Thundering-Herd-Effekte bei Zwischenfällen.
Ingestion von Verarbeitung trennen
Denke an zwei Komponenten:
- Ingestion-Endpoint: Sicherheitschecks, minimale Validierung, Enqueue, 2xx
- Worker: idempotente Business-Logik, Retries und State-Updates
Diese Trennung hält deinen Endpoint unter Last stabil, weil der Worker skalieren und retryen kann, ohne neue Events zu blockieren. Wenn Slack während eines Benutzerimports eine Flut von Events sendet, bleibt der Endpoint schnell, während die Queue den Spike puffert.
Für Logging erfasse, was du zum Debuggen brauchst, ohne Secrets oder PII zu leaken: Event-Typ, Sender (Stripe/GitHub/Slack), Delivery-ID, Ergebnis der Signaturprüfung, Verarbeitungsstatus und Zeitstempel. Vermeide das Dumpen ganzer Header oder Bodies in Logs; bewahre Payloads nur in einem geschützten Event-Store auf, wenn du sie wirklich benötigst.
Schritt für Schritt: ein Webhook-Handler-Muster zum Kopieren
Die meisten Webhook-Bugs entstehen, weil der Handler versucht, alles innerhalb der HTTP-Anfrage zu erledigen. Behandle die eingehende Anfrage als Quittungsschritt und verschiebe die eigentliche Arbeit in einen Worker.
Der Request-Handler (schnell und strikt)
Dieses Muster funktioniert in jedem Stack:
- Validiere die Anfrage und erfasse den rohen Body. Prüfe Methode, erwarteten Pfad und Content-Type. Speichere die rohen Bytes bevor du JSON parst, damit Signaturchecks nicht brechen.
- Verifiziere die Signatur früh. Lege ungültige Signaturen mit einer klaren 4xx-Antwort lahm. "Best guesses" über die Bedeutung des Payloads sind keine Option.
- Extrahiere eine Event-ID und baue einen Idempotency-Key. Bevorzuge die Event-ID des Anbieters. Wenn keine vorhanden ist, konstruiere einen Schlüssel aus stabilen Feldern (Quelle + Zeitstempel + Aktion + Objekt-ID).
- Schreibe einen Idempotency-Eintrag bevor Seiteneffekte passieren. Mache ein atomares Insert wie "event_id noch nicht gesehen". Wenn er schon existiert, gib 200 und stoppe.
- Enqueue die Arbeit und gib schnell 200 zurück. Lege das Event (oder einen Verweis auf den gespeicherten Payload) in eine Queue. Der Webrequest sollte keine Drittanbieter-APIs aufrufen, keine E-Mails senden oder schwere Arbeit leisten.
Der Worker (sichere Seiteneffekte)
Der Worker lädt das queued Event, führt die Business-Logik aus und aktualisiert den Idempotency-Eintrag in einen klaren Zustand wie processing, succeeded oder failed. Retries gehören hierher, mit Backoff und einem Limit.
Beispiel: Ein Stripe-Zahlungswebhook trifft zweimal ein. Die zweite Anfrage findet denselben Event-ID-Eintrag, sieht den vorhandenen Idempotency-Eintrag und beendet sich ohne das Upgrade erneut auszuführen.
Retries, die helfen statt Schaden zu verursachen
Retries sind sinnvoll, wenn der Fehler temporär ist. Schädlich sind sie, wenn sie einen echten Bug in einen Traffic-Spike verwandeln oder eine Anfrage wiederholen, deren Erfolg nicht erwünscht ist.
Retry nur, wenn die nächste Chance hoch ist, dass es klappt: Netzwerk-Timeouts, Verbindungsabbrüche und 5xx-Antworten von Abhängigkeiten. Wiederhole keine 4xx-Antworten, die bedeuten "deine Anfrage ist falsch" (ungültige Signatur, schlechtes JSON, fehlende Felder). Versuch auch nicht noch einmal, wenn du bereits weißt, dass das Event dupliziert und durch Idempotenz sicher behandelt wurde.
Eine einfache Regel:
- Retry: Timeouts, 429 Rate-Limits, 500–599, temporäre DNS/Connect-Fehler
- Nicht retryen: 400–499 (außer 429), ungültige Signatur, fehlgeschlagene Schema-Validierung
- Als Erfolg behandeln: bereits verarbeitetes Event (idempotenter Replay)
- Schnell stoppen: Abhängigkeit ist für alle down (Circuit Breaker verwenden)
- Immer: Versuche und Gesamtzeit begrenzen
Verwende exponentielles Backoff mit Jitter. Einfach gesagt: warte kurz, dann immer länger, und addiere eine zufällige Verzögerung, damit nicht alle Retries gleichzeitig schlagen. Beispiel: 1s, 2s, 4s, 8s plus/minus bis zu 20% Zufallsstreuung.
Setze sowohl eine maximale Anzahl von Versuchen als auch ein maximales Gesamt-Retry-Fenster. Ein praktischer Startpunkt ist 5 Versuche über 10–15 Minuten. Das verhindert "unendliche Retry-Schleifen", die Probleme verbergen bis sie eskalieren.
Mache Downstream-Calls sicher: kurze Timeouts für DB und API-Aufrufe setzen und einen Circuit Breaker hinzufügen, damit du eine fallende Service-Dependence für eine Minute oder zwei nicht permanent weiter belastest.
Schließlich: protokolliere, warum du retried hast — Timeout, 5xx, 429, Name der Abhängigkeit und wie lange es gedauert hat. Diese Tags machen aus "wir verpassen manchmal Webhooks" ein behebares Problem.
Dead-Letter-Handling: wie du vermeidest, Events für immer zu verlieren
Du brauchst einen Plan für Events, die selbst nach Retries nicht verarbeitet werden. Eine Dead-Letter-Queue (DLQ) ist ein Aufbewahrungsort für Webhook-Zustellungen, die immer wieder fehlschlagen, damit sie nicht in Logs verschwinden oder endlos retryen.
Ein guter DLQ-Eintrag enthält genug Kontext, um zu debuggen und wieder abzuspielen ohne Rätselraten:
- Roh-Payload (als Text) und geparstes JSON
- Header, die du für Verifikation und Tracing brauchst (Signatur, Event-ID, Zeitstempel)
- Fehlermeldung und Stacktrace (oder eine kurze Fehlerbegründung)
- Anzahl der Versuche und Zeitstempel für jeden Versuch
- Dein interner Verarbeitungsstatus (Benutzer erstellt, Plan aktualisiert usw.)
Dann mach Replays sicher. Replays sollten denselben idempotenten Pfad durchlaufen wie das Live-Webhook, mit einem stabilen Event-Key (meist die Event-ID des Anbieters). So macht ein erneutes Abspielen nichts beim zweiten Mal.
Ein einfacher Workflow hilft nicht-technischen Teams, schnell zu handeln, ohne Code zu berühren. Beispiel: Wenn ein Zahlungs-Event wegen eines temporären DB-Ausfalls scheitert, kann jemand es nach Systemstabilisierung erneut abspielen.
Halte den Workflow minimal:
- Wiederholte Fehler automatisch nach N-Versuchen in die DLQ routen
- Eine kurze "was ist fehlgeschlagen"-Meldung plus Payload-Zusammenfassung anzeigen
- Replay erlauben (mit erzwingender Idempotenz)
- "Als ignoriert markieren" erlauben mit Pflicht-Notiz
- Eskalation an Engineering, wenn derselbe Fehler wiederholt auftritt
Setze Aufbewahrungszeiten und Alerts. Bewahre DLQ-Einträge lange genug auf, um Wochenenden und Urlaub abzudecken (oft 7–30 Tage) und warne einen klaren Besitzer, wenn die DLQ eine kleine Schwelle überschreitet.
Beispiel: doppelte Upgrades durch einen Stripe-Payment-Webhooks verhindern
Ein typischer Stripe-Flow: ein Kunde zahlt, Stripe sendet ein payment_intent.succeeded Event und deine App upgraded das Konto.
So bricht es oft. Dein Handler erhält das Event, versucht dann die DB zu aktualisieren und eine Billing-Funktion aufzurufen. Die Datenbank hängt, die Anfrage timet out und dein Endpoint liefert 500. Stripe nimmt an, die Zustellung sei fehlgeschlagen und retryt. Nun trifft dasselbe Event wieder ein und der Nutzer wird zweimal upgegradet (oder bekommt zwei Credits, zweimal eine Rechnung markiert oder zwei Willkommens-E-Mails).
Die Schichten der Lösung:
Zuerst: die Stripe-Signatur prüfen, bevor du irgendetwas anderes tust. Ist die Signatur falsch, 400 zurückgeben und stoppen.
Dann: die Verarbeitung idempotent machen mit der Stripe-event.id. Lege ein Record wie processed_events(event_id) mit Unique-Constraint an. Wenn das Event eintrifft:
- Wenn
event_idneu ist, akzeptiere es. - Wenn
event_idschon existiert, gib 200 zurück und tu nichts.
Trenne anschließend Empfang und Arbeit: validieren + aufzeichnen + enqueuen, dann lässt du einen Worker das Upgrade durchführen. Der Endpoint antwortet schnell, dadurch sind Timeouts selten.
Schließlich: einen Dead-Letter-Pfad hinzufügen. Wenn der Worker wegen eines DB-Fehlers scheitert, speichere Payload und Fehlergrund zur sicheren Wiederholung. Beim Replay sollte derselbe Worker-Code laufen, und Idempotenz stellt sicher, dass kein doppeltes Upgrade passiert.
Nach diesen Änderungen sieht der Nutzer ein Upgrade, es gibt weniger Verzögerungen und weit weniger Support-Tickets vom Typ "Ich habe zweimal bezahlt".
Häufige Fehler, die stille Webhook-Bugs erzeugen
Die meisten Webhook-Bugs sind nicht laut. Dein Endpoint gibt 200, Dashboards sehen gut aus, und Wochen später stellst du fehlende Upgrades, doppelte E-Mails oder inkonsistente Daten fest.
Ein Klassiker ist das versehentliche Zerstören der Signaturprüfung. Viele Anbieter signieren den rohen Request-Body, aber einige Frameworks parsen JSON zuerst und verändern Whitespace oder Schlüsselreihenfolge. Wenn du gegen den geparsten Body prüfst, können valide Requests als manipuliert abgelehnt werden. Die Lösung: gegen die rohen Bytes verifizieren, dann parsen.
Ein weiterer stiller Fehler ist, zu früh 200 zurückzugeben. Wenn du das Event anerkennst und danach die Verarbeitung (DB-Write, Drittanbieter-API-Aufruf, Job-Enqueue) fehlschlägt, wird der Anbieter nicht retryen, weil du bereits gesagt hast, dass es klappt. Bestätige Erfolg erst, nachdem du das Event sicher aufgezeichnet (oder enqueued) hast.
Langsame Arbeit im Request-Thread ist ebenfalls ein Zuverlässigkeitskiller. Webhook-Sender haben oft kurze Timeouts. Wenn du schwere Logik oder Netzaufrufe vor der Antwort ausführst, produzierst du Retries, Duplikate und gelegentlich verlorene Events.
Deduping-Fehler können subtil sein. Wenn du auf den falschen Schlüssel dedupst, etwa Nutzer-ID oder Repository-ID, wirfst du echte Events weg. Dedupe sollte auf der eindeutigen Event-ID basieren (und manchmal auf dem Event-Typ), nicht darauf, was das Event betrifft.
Und sei vorsichtig mit Logs. Das Dumpen ganzer Payloads kann Secrets, Tokens, E-Mails oder interne IDs leaken. Logge minimalen Kontext (Event-ID, Typ, Zeitstempel) und redacte sensible Felder.
Kurze Checkliste: Ist deine Webhook-Integration jetzt sicher?
Ein Webhook-Handler ist "sicher", wenn er bei Duplikaten, Retries, langsamen Datenbanken und gelegentlichen fehlerhaften Requests korrekt bleibt.
Fang mit den Grundlagen an, die Betrug und doppelte Verarbeitung verhindern:
- Verifiziere die Signatur mit dem rohen Request-Body (vor JSON-Parsing oder anderen Body-Transformations).
- Erstelle und speichere einen Idempotency-Eintrag vor Seiteneffekten. Speichere die Event-ID (oder einen berechneten Schlüssel) zuerst, dann mache die Arbeit.
- Gib schnell ein 2xx zurück, sobald die Anfrage verifiziert und sicher in die Queue gestellt wurde.
- Setze klare Timeouts überall. Handler, DB-Calls, ausgehende API-Calls.
- Habe Retries mit Backoff und einer Max-Anzahl. Retries sollten sich über die Zeit verlangsamen und nach einem Limit stoppen.
Dann sorge dafür, dass du wiederherstellen kannst, wenn trotzdem etwas fehlschlägt:
- Dead-Letter-Storage existiert und enthält Payload, benötigte Header, Fehlergrund und Attempt-Count.
- Replay funktioniert wirklich. Du kannst ein Dead-Letter-Event sicher erneut laufen lassen und Idempotenz verhindert doppelte Effekte.
- Grundlegendes Monitoring ist eingerichtet: Zählungen für empfangene, verarbeitete, retryte und dead-letterte Events plus ein Alert, wenn die DLQ wächst.
Kurzer Selbsttest: Wenn dein Server mitten in einer Anfrage neu startet, würdest du das Event verlieren oder doppelt verarbeiten? Wenn du dir nicht sicher bist, behebe das zuerst.
Nächste Schritte, wenn deine Webhooks schon brüchig sind
Wenn du bereits verpasste Events oder seltsame Duplikate hast, behandle das wie ein kleines Reparaturprojekt, nicht wie einen Quick-Fix. Wähle eine Integration (Stripe, GitHub oder Slack) und behebe sie Ende-zu-Ende, bevor du die anderen anfasst.
Praktische Reihenfolge:
- Zuerst Signaturprüfung hinzufügen und Fehler im Log deutlich machen.
- Verarbeitung idempotent machen (Event-ID speichern und Wiederholungen ignorieren).
- "Empfangen" von "Verarbeiten" trennen (schnell bestätigen, Arbeit im Background).
- Sichere Retries mit Backoff für temporäre Fehler.
- Dead-Letter-Handling hinzufügen, damit fehlgeschlagene Events gespeichert werden.
Schreibe dann einen kleinen Testplan, den du bei jeder Änderung laufen lassen kannst:
- Doppelzustellung: Sende dasselbe Event zweimal und bestätige, dass es nur einmal angewendet wird.
- Ungültige Signatur: Bestätige, dass die Anfrage abgelehnt wird und nichts verarbeitet wird.
- Out-of-order-Events: Überprüfe, dass dein System konsistent bleibt.
- Langsame Downstream-Services: Simuliere Timeouts, um zu bestätigen, dass Retries sicher ablaufen.
Wenn du einen KI-generierten Webhook-Code geerbt hast und er sich brüchig anfühlt (schwer zu verstehen, überraschende Seiteneffekte, Secrets an seltsamen Orten), ist ein konzentrierter Remediation-Durchlauf oft schneller, als Symptombekämpfung. FixMyMess (fixmymess.ai) hilft Teams, kaputte KI-Prototypen in produktionsreife, sichere Webhook-Flows zu verwandeln.
Häufige Fragen
Warum erhalte ich dasselbe Webhook-Event mehrmals?
Behandle Duplikate als normal, nicht als Randfall. Die meisten Anbieter liefern Webhooks mindestens einmal, daher kann ein Timeout oder ein kurzzeitiger 500-Fehler dazu führen, dass dasselbe Event erneut gesendet wird, selbst wenn dein Code schon einmal ausgeführt hat.
Wann sollte mein Webhook-Endpunkt 200 zurückgeben?
Gib ein 2xx nur zurück, nachdem du die Signatur verifiziert und das Event sicher aufgezeichnet (oder in die Warteschlange gestellt) hast, sodass du es wiederherstellen kannst. Wenn du 200 zurückgibst und anschließend der Datenbankeintrag oder das Enqueue fehlschlägt, geht der Anbieter davon aus, dass alles funktioniert hat und wird nicht erneut senden — das erzeugt stille Datenverluste.
Wie verhindere ich Doppelabbuchungen oder doppelte Upgrades durch Retries?
Verwende Idempotenz basierend auf einem stabilen eindeutigen Schlüssel, idealerweise der Event-ID des Anbieters. Speichere diesen Schlüssel in dauerhaftem Speicher mit einer Unique-Constraint; wenn du ihn erneut siehst, brich früh ab und gib trotzdem Erfolg zurück, damit die Retries aufhören.
Wie gehe ich mit Webhook-Events aus der Reihenfolge um, ohne Zustand zu beschädigen?
Gehe nicht von einer festen Reihenfolge aus, auch nicht beim selben Anbieter. Mache Updates bedingt per Versionierung, Zeitstempel oder aktuellem Zustand, damit ein älteres Event nicht neuere Daten überschreibt. Gestalte Handler so, dass jedes Event sicher angewendet werden kann, auch wenn es verspätet ankommt.
Warum schlägt die Signaturprüfung fehl, obwohl das Secret korrekt ist?
Verifiziere gegen die rohen Request-Bytes, genau so wie sie eingetroffen sind, bevor du JSON parsest oder neu serialisierst. Viele Frameworks verändern Whitespace oder Schlüsselreihenfolge beim Parsen — diese Änderung reicht aus, damit eine korrekte Signatur als ungültig erscheint.
Soll mein Webhook-Handler die Geschäftslogik im Request-Thread ausführen?
Standardmäßig: prüfe die Signatur, schreibe ein Inbox-/Idempotency-Record, stelle die Arbeit in die Warteschlange und antworte sofort. Langsame Arbeiten wie E-Mails, Drittanbieter-APIs oder umfangreiche DB-Operationen gehören in einen Worker, damit der Anbieter nicht wegen Timeouts erneut sendet.
Welche Fehler sollte ich wiederholen und welche nicht?
Retry, wenn der Fehler wahrscheinlich vorübergehend ist: Timeouts, Netzwerkfehler, 429-Rate-Limits oder 5xx-Antworten von Abhängigkeiten. Nicht retryen bei ungültigen Signaturen oder fehlerhaften Payloads. Begrenze stets die Anzahl der Versuche und das gesamte Retry-Fenster, damit Fehler sichtbar werden anstatt endlos zu schleifen.
Was sollte ich zur Duplikatsvermeidung speichern und wie lange?
Speichere einen Dedupe-Key, wann du ihn zuerst gesehen hast, und einen Verarbeitungsstatus, damit du zwischen empfangen, abgeschlossen und fehlgeschlagen unterscheiden kannst. Bei Aktionen, die Geld oder Zugriffsrechte betreffen, behandle den Dedupe-Eintrag als dauerhaften Teil deiner Daten und bewahre ihn lange genug auf, um die Retry-Window des Anbieters und deine eigenen verzögerten Reprozesse abzudecken.
Was ist eine Dead-Letter-Queue und wann brauche ich sie?
Ein Dead-Letter-Pfad ist der Ort, an den Events kommen, nachdem die Retries erschöpft sind, damit sie nicht in Logs verschwinden. Speichere genügend Kontext, um das Problem zu verstehen und sicher erneut abzuspielen; sorge dafür, dass Replays den selben idempotenten Pfad durchlaufen, damit sie keine doppelten Seiteneffekte erzeugen.
Meine Webhooks sind brüchig und wurden von einem KI-Tool generiert – was ist der schnellste Weg, sie zu reparieren?
Meist fehlt eine Kern-Sicherheits- oder Zuverlässigkeitsschicht: Signaturprüfung, Idempotenz, schnelles Acknowledge + Hintergrundverarbeitung, kontrollierte Retries oder Dead-Letter-Visibility. Wenn der Code von einer KI generiert wurde und schwer nachzuvollziehen ist, kann ein fokussierter Remediation-Pass schneller sein als das Verfolgen einzelner Symptome. FixMyMess (fixmymess.ai) kann den Webhook-Flow prüfen, Logik- und Sicherheitsprobleme beheben und ihn in ein sicheres Ingest-and-Worker-Muster überführen.