Zuverlässige Zähler bei gleichzeitigen Zugriffen: Driftende Metriken stoppen
Erfahren Sie, wie Sie Zähler unter Parallelität zuverlässig halten: atomare Updates, Idempotenz-Keys und Batch-Writes sorgen dafür, dass Metriken in der Produktion korrekt bleiben.
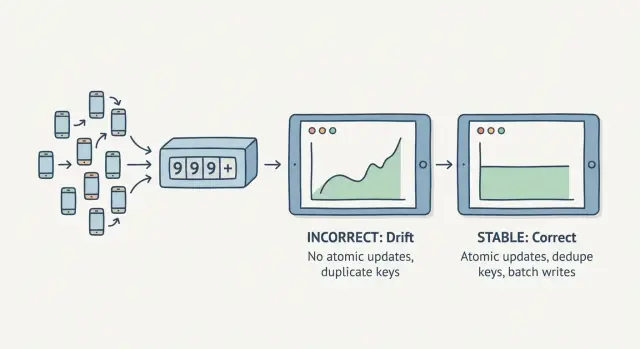
Warum Zähler driften, wenn mehrere Anfragen gleichzeitig eintreffen
Ein Zähler driftet, wenn Sie ihm nicht mehr vertrauen können. Sie aktualisieren ein Dashboard und die Summe ändert sich, obwohl nichts Neues passiert ist. Oder die Zahl springt nach einem kurzen Traffic-Spike. Das ist schwer im Test zu finden, weil es meist echte Parallelität braucht.
Drift sieht oft so aus:
- Derselbe Bericht zeigt bei jedem Neuladen unterschiedliche Summen.
- Zähler springen nach einem Traffic-Burst oder einem Deploy.
- Summen an einem Ort (Datenbank) stimmen nicht mit einer anderen Quelle (Analytics) überein.
Die übliche Ursache ist eine Race-Condition: viele Requests versuchen gleichzeitig dieselbe Zahl zu aktualisieren. Wenn Ihr Code „aktuellen Wert lesen, +1 rechnen, zurückschreiben“ macht, können zwei Requests beide 10 lesen, beide +1 rechnen und beide 11 schreiben. Eine Inkrement-Operation geht verloren.
Deshalb tritt das Problem oft erst nach dem Launch auf. Auf einem Laptop oder in einer ruhigen Staging-Umgebung kommen Requests nacheinander an. Nach einer Kampagne, einem beliebten Feature oder parallel laufenden Hintergrundjobs prallen diese Updates aufeinander.
Es gibt auch einen Trade-off zwischen Genauigkeit und Aktualität. Jeden Request sofort in einen Zähler zu schreiben kann genau sein, aber nur wenn das Update wirklich nebenläufig sicher ist. Viele Teams wählen nahe Echtzeit: Ereignisse schnell sammeln und Summen dann in kleinen Batches alle paar Sekunden aktualisieren. Die Zahl wirkt leicht verzögert, ist aber meist stabiler und einfacher korrekt zu halten.
Ein einfaches Beispiel: zwei Nutzer klicken zugleich auf „Kaufen“. Wenn beide Requests separat die neue Summe berechnen und schreiben, kann Ihr Kaufzähler unterzählen, obwohl beide Bestellungen erfolgreich waren.
Wählen Sie den richtigen Metriktyp, bevor Sie coden
Viele „Zähler-Probleme“ sind eigentlich Definitionsprobleme. Wenn Sie den falschen Metriktyp wählen, macht eine korrekte Inkrement-Logik Ihre Analytics nicht stabil.
Wenn jemand „einen Zähler“ will, meint er meist eines dieser Dinge:
- Counter: wie oft etwas passiert ist (Pageviews, Button-Klicks)
- Summe: Gesamtbetrag über Ereignisse (Umsatz, geschautes Minutenvolumen)
- Eindeutige Anzahl: wie viele unterschiedliche Nutzer/Objekte etwas getan haben (unique signups, unique purchasers)
- Rate: ein Verhältnis über Zeit (Signups pro Stunde, Conversion-Rate)
Ein einfaches +1 reicht oft für wenig kritische, sehr häufige Events wie Pageviews. Ein wenig Rauschen durch Duplikate stört selten.
Sobald aber Geld, Nutzerzustand oder Messaging im Spiel sind, brauchen Sie eine strengere Definition der „Wahrheit“. Signups, Käufe, Passwort-Resets, Einladungen und „Trial gestartet“-Ereignisse werden häufiger wiederholt als gedacht (Clients, Hintergrundjobs, Zahlungsanbieter). Retries als neue Ereignisse zu zählen ist, wie Dashboards aufgebläht werden.
Eine praktische Entscheidungshilfe ist die Wahl der Quelle der Wahrheit:
- Append-only Events: speichere jedes Ereignis einmal und berechne dann Summen aus den Events.
- Gespeicherte Summen: behalte eine laufende Zahl und aktualisiere sie, wenn Ereignisse eintreffen.
Event-Logs sind einfacher zu prüfen und neu zu berechnen. Gespeicherte Summen sind schneller zu lesen, funktionieren aber nur, wenn Updates korrekt sind und Duplikate blockiert werden.
Beispiel: Ein Checkout empfängt payment_succeeded zweimal, weil die erste Webhook-Antwort ein Timeout hatte. Wenn Ihr „purchases“-Metrik ein einfacher Zähler ist, springt er um 2. Wenn Ihre Wahrheit „ein Kauf pro payment_id“ ist, messen Sie eindeutige payment IDs, nicht rohe Webhook-Zustellungen.
Atomare Updates: die sicherste Methode zu inkrementieren
Wenn Sie zuverlässige Zähler unter Parallelität brauchen, verwenden Sie atomare Updates. „Atomar“ bedeutet, die Änderung passiert als eine einzelne Operation: sie wird einmal angewendet oder gar nicht. Kein Zwischenschritt, kein gegenseitiges Überschreiben.
Der klassische Bug ist read-modify-write: 100 lesen, im App-Code +1 rechnen, 101 schreiben. Zwei Requests können beide 100 lesen und beide 101 schreiben.
Atomare Updates führen das Inkrement innerhalb der Datenbank oder des Speichers aus, wo es auch bei vielen gleichzeitig eintreffenden Anfragen sicher angewendet werden kann:
UPDATE counters
SET value = value + 1
WHERE name = 'signups';
INCR signups
Ein schneller Sanity-Check: Wenn Ihre App den Zählerwert nur liest, um ihn zu inkrementieren, sind Sie wahrscheinlich wieder im read-modify-write-Bereich.
Atomare Inkremente sind nicht kostenlos. Wenn eine einzelne Zeile/Key ständig aktualisiert wird (ein „Hot Key“ wie ein globaler Pageviews-Zähler), können Sie auf folgende Probleme stoßen:
- Lock-Contention oder langsamere Updates
- Höhere Latenz während Spikes
- Replikationsverzögerung, wenn Sie von Replikaten lesen
- Timeouts, die Retries auslösen
Dedupe-Keys: doppelte Zählung durch Retries und Replays verhindern
Idempotenz bedeutet, dieselbe Aktion zweimal einzusenden hat denselben Effekt wie einmal. Für Zähler ist das der Unterschied zwischen „meist korrekt“ und vertrauenswürdig.
Duplikate sind häufig:
- Ein Nutzer klickt zweimal auf „Jetzt zahlen“.
- Ein Mobil-Client verliert die Verbindung und versucht erneut.
- Ein Webhook-Anbieter sendet nach einem 500 erneut.
- Eine Warteschlange liefert einen Job erneut.
Ein Dedupe-Key ist normalerweise eine event_id, die das reale Ereignis eindeutig identifiziert. Sie kann aus einer Provider-WebHook-ID, einer vom Client erzeugten UUID, einer serverseitig generierten ID oder einem deterministischen Schlüssel wie order_id + event_type stammen.
Sobald Sie eine event_id haben, speichern Sie sie und verweigern das Zweit-Zählen derselben ID. Die Grundregel: zuerst die event_id einfügen, dann inkrementieren, oder beides in einer Transaktion tun.
Gängige Speicheroptionen:
- Eine Datenbanktabelle mit verarbeiteten Ereignissen und einer UNIQUE-Constraint auf
event_id - Ein UNIQUE-Index auf Ihrer Analytics-/Event-Tabelle
- Ein Cache (z. B. Redis) mit TTL für kurzfristige Dedupe-Fenster
Beispiel: Ein Purchase-WebHook trifft ein, Ihr Handler timet out und der Provider spielt ihn erneut ab. Ohne Dedupe erfassen Sie zwei Käufe und addieren den Umsatz zweimal. Mit einer eindeutigen event_id wird der zweite Versuch zum No-Op.
Batch-Writes: weniger Datenbank-Hits, stabilere Analytics
Unter Last können Einzelzeilen-Schreibvorgänge sich stapeln. Das erhöht Lock-Zeit, verlangsamt Antworten und erhöht die Chance auf Timeouts oder Teilausfälle. Batching reduziert Roundtrips zur Datenbank und kann Analytics stabiler machen.
Ein einfaches Gedankenspiel: Ereignisse schnell erfassen, dann Zusammenfassungen in weniger, größeren Updates schreiben. Gängige Ansätze sind Puffern und alle N Sekunden flushen, Events in Queues stellen und in Worker aggregieren, geplante Rollups (stündlich/täglich) oder ein Hybrid (kleine Echtzeit-Zähler plus periodische Backfills).
Der Trade-off ist die Aktualität. Ihr Dashboard kann um Sekunden oder Minuten hinterherhinken, aber in der Regel sehen Sie weniger fehlgeschlagene Writes und weniger durch Retry-Stürme verursachte Spitzen.
Wählen Sie das Batch-Fenster nach Verwendungszweck der Metrik:
- Sekunden: Live-Feeds, Rate-Limiting, „jetzt aktiv“-Widgets
- Zehner von Sekunden: Marketing-Dashboards und Signup-Funnels
- Minuten: Umsatz und die meisten Admin-Reports
- Stunden/Tage: Finanz-Grade-Reporting und Audits
Ein sicheres Muster für Zähler und Analytics
Behandle jedes Inkrement als Ergebnis eines spezifischen Ereignisses. Der Zähler ist nur eine Zusammenfassung.
Ein Pattern, das unter Last standhält:
-
Benennen Sie das Ereignis und wählen Sie eine stabile, eindeutige ID. Nutzen Sie etwas, das bei Retries gleich bleibt (z. B.
order_id,payment_intent_idoder eine generierteevent_id, die durch den Flow mitgegeben wird). -
Speichern Sie das Ereignis (oder eine leichtgewichtige Dedupe-Zeile) zuerst. Legen Sie die ID in einer
events- oderdedupe-Tabelle mit Unique-Constraint ab. -
Inkrementieren Sie atomar. Verwenden Sie ein einzelnes Statement für das Inkrement, nicht „lesen, +1, schreiben“. Wenn möglich, schreiben Sie das Event und das Counter-Update in einer Transaktion.
-
Machen Sie Retries sicher. Wenn der Dedupe-Insert fehlschlägt, weil der Schlüssel schon existiert, behandeln Sie das als Erfolg und überspringen das Inkrement.
-
Batchen Sie, wo es sinnvoll ist, ohne die Regeln zu verletzen. Puffern und periodisch flushen ist okay, aber erst nachdem das Event/Dedupe sicher gespeichert ist.
Beispiel: Ein Nutzer klickt „Kaufen“, Ihr Server erstellt ein purchase_completed-Event mit Dedupe-Key order_123. Wenn der Zahlungsanbieter den WebHook nochmal sendet, trifft der zweite Insert auf die Unique-Constraint und Sie zählen keinen zweiten Kauf dazu.
Retries, Timeouts und Message-Queues ohne aufgeblähte Zähler
Viele Systeme liefern Ereignisse mit einer „at-least-once“-Garantie. Plain English: dieselbe Nachricht kann zweimal ankommen.
Timeouts sind die heimtückischste Variante. Ein Client ruft Ihre API auf, wartet, bekommt ein Timeout und versucht es erneut. Der Server hat die Arbeit vielleicht bereits abgeschlossen und das Zähler-Update committed. Nun haben Sie zwei „erfolgreiche“ Versuche für eine einzige reale Aktion.
Die Regel: nur Arbeit neu versuchen, die idempotent ist.
Ein praktisches Queue-Pattern:
- Die API erzeugt ein Event mit einer eindeutigen
event_id(z. B.purchase-<order_id>) und legt es in die Queue. - Ein Worker verarbeitet das Event und schreibt zwei Dinge in einer Transaktion: (1) markiert
event_idals verarbeitet, (2) inkrementiert den Zähler. - Wird die Message redelivered, sieht der Worker, dass
event_idbereits verarbeitet ist, und überspringt das Inkrement.
Für Incident-Debugging halten Sie Logs langweilig und konsistent:
event_id- Zeitstempel (empfangen und committed)
- Quelle (API, Queue, Cron)
- Ergebnis (processed, skipped as duplicate, failed)
- Retry-Anzahl
Häufige Fehler, die driftende Metriken verursachen
Diese Probleme tauchen in vielen Produkten wieder auf.
Fehler 1: Lesen, dann schreiben für Inkremente
Zwei Requests können denselben Wert lesen und denselben neuen Wert schreiben. Nutzen Sie einen atomaren Datenbank-Inkrement, damit die Aktualisierung in einer Operation passiert.
Fehler 2: Zählen bevor die Aktion wirklich erfolgreich ist
Wenn Sie inkrementieren, sobald ein Request startet, overcounten Sie, wenn die Aktion später fehlschlägt (abgelehnte Zahlung, fehlgeschickte E-Mail, zurückgerollte Transaktion). Zählen Sie erst nach einem echten Erfolgssignal.
Fehler 3: Dedupe-Keys ohne Durchsetzung
Ein Dedupe-Key funktioniert nur, wenn Sie Eindeutigkeit auf Datenbankebene erzwingen (Unique-Constraint/Index). Ohne das rutschen Duplikate bei Retries und parallelen Workern trotzdem durch.
Fehler 4: Batch-Writes, die Daten verlieren
Batching reduziert Last, aber In-Memory-Puffer können bei Neustarts verschwinden. Machen Sie Flushing explizit: zeitbasiertes Flush, größenbasiertes Flush und ein Shutdown-Flush.
Fehler 5: Kaputte Tagesgrenzen bei Rollups
Tägliche Metriken driften, wenn Services unterschiedliche Zeitzonen oder Tag-Grenzen verwenden. Wählen Sie einen Standard (häufig UTC), speichern Sie Zeitstempel konsistent und behalten Sie rohe Events lange genug, um Rollups neu zu berechnen.
Schnelle Checks, um zu verifizieren, dass Ihre Zähler vertrauenswürdig sind
Wenn Sie ein Inkrement nicht erklären können, können Sie nicht beweisen, dass es korrekt ist. Selbst eine einfache Roh-Events-Tabelle reicht oft für Spot-Checks.
Ein schneller Sanity-Scan:
- Können Sie jedes Inkrement zu einer gespeicherten
event_idim Roh-Event zurückverfolgen? - Erzwingen Sie Eindeutigkeit für Dedupe-Keys (Unique-Index/Constraint)?
- Werden Zähler mit atomaren Updates aktualisiert (ein Statement), nicht als read-modify-write im App-Code?
- Reichen Sie die Summen gegen Roh-Events ab (mindestens tägliche Spot-Checks)?
- Alarmieren Sie bei plötzlichen Resets oder ungewöhnlich großen Sprüngen?
Ein praktischer Test: Wählen Sie eine Metrik wie „neue Signups“, ziehen Sie 50 jüngere event_ids und prüfen Sie, dass jede genau einem Inkrement entspricht. Reproduzieren Sie dann dieselbe Anfrage/Nachricht ein paar Mal und bestätigen Sie, dass der Zähler sich nicht bewegt.
Beispiel: Signup- und Kaufzähler in einer echten App reparieren
Eine kleine Abo-App trackt Signups, Käufe und „Willkommens-E-Mail gesendet“. Wochenlang sieht das Dashboard gut aus. Dann wächst der Traffic und der Support hört „Ich wurde doppelt belastet“ oder „Ich habe nur einmal geklickt“. Totale weichen von Zahlungsberichten ab.
Was passiert: Double-Clicks, Client-Retries nach Timeouts und wiederholte Payment-WebHooks. Wenn Ihr Code zuerst inkrementiert und später nachfragt, driften die Metriken.
Eine stabile Lösung kombiniert drei Maßnahmen:
- Pro Aktion dedupen:
signup:<user_id>,purchase:<payment_event_id>,email:<message_id>, mit Unique-Constraint gespeichert. - Atomare Inkremente: read-modify-write durch ein einzelnes Datenbank-Inkrement ersetzen.
- Batchen von hochvolumigen Updates: Echtzeit dort behalten, wo Sie sie brauchen, batchen, wo es nicht nötig ist.
Ein einfacher Rollout-Plan:
- Replizieren Sie denselben Webhook-Payload 5–10 Mal in Staging und bestätigen Sie, dass der Zähler nach dem ersten Mal nicht mehr steigt.
- Shippen Sie hinter einem Feature-Flag und aktivieren Sie es für einen kleinen Traffic-Slice.
- Führen Sie einen Reconciliation-Job aus, der Roh-Events mit Zählern vergleicht und Differenzen backfilled.
- Überwachen Sie „dedupe hits“, um zu bestätigen, dass Retries gefangen werden.
Nächste Schritte: Metriken stabilisieren, ohne alles neu zu schreiben
In der Regel brauchen Sie keinen kompletten Neubau. Sie brauchen eine klare Karte, wo Zählungen entstehen, wo Retries passieren und wo Duplikate durchsickern.
Beginnen Sie mit einem einfachen Inventar:
- Wo jeder Zähler lebt (Datenbank, Cache, Analytics-Tool)
- Wo Ereignisse entstehen (Endpoints, Hintergrundjobs, Webhooks)
- Alle Retry-Pfade (Client-Retries, Queue-Retries, Webhook-Redirigierungen)
- Wie Sie ein Ereignis identifizieren (
event_id,request_id,order_id) - Wo geschrieben wird (ein Ort vs viele)
Dann in dieser Reihenfolge reparieren:
- Double-Counting stoppen (Dedupe-Keys und idempotentes Handling auf den heißesten Pfaden)
- Inkremente atomar machen
- Performance verbessern (Batching, asynchrones Processing)
- Laufende Checks hinzufügen (Roh-Events vs Zähler abgleichen, Alarme bei seltsamen Sprüngen)
Wenn Sie ein KI-generiertes Codebase geerbt haben, gehen Sie davon aus, dass Zählerlogik kopiert und an mehreren Stellen leicht unterschiedlich implementiert wurde. Diese Pfade in eine gemeinsame Funktion oder einen Service zu vereinheitlichen ist oft der schnellste Weg, damit Fixes halten.
Wenn Sie eine zweite Meinung möchten: FixMyMess (fixmymess.ai) fokussiert sich auf Diagnose und Reparatur von Problemen wie nicht-atomaren Updates, fehlender Idempotenz und replay-empfindlichen Webhooks in KI-generierten Apps. Ein kostenloses Code-Audit kann schnell die wenigen Stellen hervorheben, die unter realem Traffic am meisten Drift verursachen.