Apps criados por IA falham com usuários reais: 3 armadilhas de demo para identificar
Apps criados por IA quebram com usuários reais quando demos ignoram casos de borda. Veja cenários de login, e‑mail e pagamento, e checagens para endurecer seu app antes do lançamento.
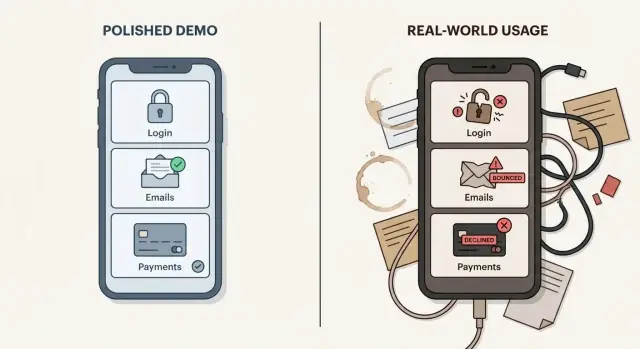
O que parece bem numa demo e o que quebra em produção
Uma demo é um momento controlado. Você usa um dispositivo, uma conta, dados de exemplo limpos e um caminho que você já sabe que vai funcionar. Usuários reais fazem o oposto. Eles clicam fora de ordem, reutilizam links antigos, digitam senhas errado, atualizam na hora errada e testam em celulares que você nunca verificou.
Por isso apps criados por IA falham com usuários reais mesmo quando a demo parece perfeita. Um protótipo costuma provar que uma ideia é possível, não que ela é confiável.
Usuários iniciais também se comportam diferente do que o criador espera. Eles não leem instruções. Criam conta com e‑mails do trabalho, pessoais e às vezes temporários. Acessam o app atrás de firewalls corporativos. Tentam pagar com cartões de outros países. E fazem perguntas ao suporte no mesmo dia, porque algo “ao vivo” deveria simplesmente funcionar.
Numa demo, “funciona” muitas vezes significa “consigo completar o caminho feliz uma vez”. Em produção, “funciona” inclui confiabilidade, segurança, suportabilidade e recuperação. Ações chave devem ter sucesso repetidamente (mesmo com conexão ruim). Dados privados devem permanecer privados. Quando algo falha, você precisa de visibilidade suficiente para entender o que aconteceu e ajudar rápido. E precisa de formas seguras de tentar de novo, reverter ou consertar problemas sem quebrar o restante.
Você não precisa perder a velocidade que levou ao protótipo. Mantenha o mesmo fluxo, mas acrescente as checagens pouco glamourosas: tratamento sólido de erros, logs, limites de taxa, armazenamento seguro de credenciais e testes com dados bagunçados.
Por que protótipos gerados por IA cortam caminhos
Código gerado por IA costuma ser otimizado para “mostrar algo funcionando” o mais rápido possível. Demos recompensam o caminho feliz: uma conta, um dispositivo, uma rede limpa e entradas previsíveis. Produção recompensa o oposto: resiliência.
Protótipos frequentemente pulam as partes desconfortáveis. O que acontece quando uma requisição expira, uma API retorna resposta parcial ou duas ações ocorrem ao mesmo tempo? Numa demo você clica uma vez e segue. Em produção, pessoas renovam a página, enviam duas vezes, trocam de aba, perdem sinal e tentam novamente.
Outro problema comum são suposições ocultas. Código gerado por IA pode deixar valores fixos que parecem inofensivos no primeiro dia: um papel de usuário fixo, uma única configuração de ambiente, uma chave de API temporária, uma moeda ou um fuso horário. Funciona localmente e depois quebra após o deploy, acesso de equipe ou o primeiro cliente real.
A maioria das peças que faltam é chata, mas evita que tickets de suporte se acumulem: tratar timeouts e retries, validar entradas com mensagens úteis, lidar com falhas parciais, remover configurações e segredos só de demo e adicionar logs que apontem para a causa real.
Imagine um fluxo simples: um usuário se cadastra, recebe um e‑mail de confirmação e depois paga. Uma demo prova que os botões funcionam. Produção tem que provar que toda a cadeia aguenta sob pressão e falha de forma graciosa quando algo upstream quebra.
Cenário 1 - Login funciona uma vez e depois usuários ficam bloqueados
Um login de demo geralmente segue o caminho mais feliz: uma conta de teste, seu laptop, um navegador, conexão estável. Você entra, chega ao painel e todo mundo concorda.
Usuários reais não se comportam assim. Entram pelo celular e pelo laptop do trabalho. Esquecem senhas. Clicam em “Entrar com Google” dentro de um navegador embutido no app. Fecham a aba, voltam amanhã e esperam continuar conectados.
Muitos bugs de “funciona uma vez” no login vêm de alguns pontos de ruptura:
- Callbacks OAuth são exigentes. a URL de callback deve coincidir exatamente, e pequenas diferenças de redirect podem quebrar a etapa final após o provedor indicar “Success”.
- Cookies e sessões podem ser definidos de forma que só funcionam no localhost, só em um navegador ou falham sob configurações de privacidade mais rígidas.
- Sessões expiram, mas o app não recupera de forma limpa, deixando usuários presos em loops.
O que usuários reportam quase sempre é vago: “Consigo entrar uma vez, depois para de funcionar.” Essa frase única pode esconder qualquer coisa, desde um cookie mal configurado até uma requisição cross‑site bloqueada ou um redirect que descarta um token.
Antes de convidar pessoas, faça algumas checagens simples (sem precisar de alta especialização). Entre pelo seu celular e por um segundo dispositivo e confirme que ambos continuam conectados. Feche a aba e volte em 10 minutos, depois em 24 horas. Tente redefinir a senha e confirme que a nova senha funciona imediatamente. Teste em janela anônima e em outro navegador. Peça a alguém fora da sua rede para se cadastrar da conexão dele.
Se algo falhar, pause e diagnose. Autenticação frequentemente é o bloqueador que transforma um protótipo “funcional” em algo do qual os usuários saem imediatamente.
Cenário 2 - E-mails são enviados em testes, mas nunca chegam aos clientes
Numa demo, o e‑mail parece “resolvido” porque você testa uma vez e ele aparece na sua caixa. Isso pode ser verdade mesmo quando o sistema não está pronto para usuários reais.
A lacuna aparece no momento em que você envia para pessoas fora do seu time. Caixas reais filtram agressivamente, e seu domínio tem uma reputação (ou nenhuma ainda). Se SPF, DKIM e DMARC estiverem ausentes ou mal configurados, muitos provedores tratam mensagens como suspeitas. Do ponto de vista do app, o e‑mail “foi enviado”, mas o usuário nunca vê.
Outros pontos de ruptura são mais simples e igualmente dolorosos. O endereço do remetente está errado. O nome “from” aciona regras de spam. Um template renderiza bem em um cliente e quebra em outro. Links apontam para localhost ou um domínio de staging. Se você enviar um estouro (como importar uma lista de espera), limites de taxa entram em ação e você perde mensagens a menos que faça fila e retries.
O impacto no usuário é imediato: sem e‑mail de verificação, sem conta. Sem redefinição de senha, tickets de suporte. Sem recibo, pessoas acham que foram cobradas e não receberam nada, mesmo que o pagamento tenha ocorrido.
Antes de culpar o “e‑mail instável”, verifique o básico: logs do provedor (accepted, deferred, rejected), eventos de bounce e complaint, alinhamento SPF/DKIM/DMARC e um teste em pequena escala no Gmail, Outlook e Apple Mail. Também revise templates procurando links quebrados e qualquer coisa parecendo staging.
Uma falha comum parece assim: seu cadastro funciona no seu próprio endereço, mas um cliente no Outlook nunca recebe o e‑mail de verificação. Ele clica em “reenviar” cinco vezes e seu app aplica throttling ou bloqueia. Frequentemente o problema real é entregabilidade junto com um template com defeito, então mesmo e‑mails entregues viram becos sem saída.
Cenário 3 - Pagamentos sucedem no sandbox e falham com cartões reais
Pagamentos em sandbox são amigáveis por design. Cartões de teste costumam aprovar e o caminho feliz parece perfeito. Bancos reais não se comportam como sandbox, e o app precisa lidar com resultados bagunçados.
Com cartões reais, aparecem checagens extras. O usuário pode cair no 3D Secure e abandonar o fluxo. Checagens AVS/CVC falham se o endereço de cobrança estiver ligeiramente diferente. Bancos recusam por motivos imprevisíveis. Acrescente conversão de moeda, impostos e regras regionais, e seu “pagar com um botão” vira um conjunto de ramificações.
A quebra mais comum em produção não é o formulário de pagamento. É tudo ao redor, especialmente webhooks. Numa demo, é tentador assumir “pagamento confirmado” e liberar acesso imediatamente. Em produção, o evento de webhook é a fonte de verdade, e ele pode chegar atrasado, duplicado ou nunca chegar se o endpoint estiver mal configurado.
Fique atento a esses padrões do primeiro dia:
- Acesso concedido antes da confirmação, e depois a cobrança falha ou é estornada.
- Webhooks ignorados, então usuários pagam mas a conta não atualiza.
- Falta de idempotência, fazendo retries criarem cobranças duplicadas.
- Condições de corrida entre a página de “sucesso” e o processamento do webhook.
Tickets de suporte seguem o mesmo roteiro: um cliente vê “pagamento falhou”, tenta novamente e depois encontra duas cobranças. Ou recebe acesso mesmo sem pagamento concluído, o que vira caos de reembolso.
O que validar antes de usuários reais pagarem é simples, mas inegociável: fluxo de webhook end‑to‑end, chaves de idempotência em ações de criar/confirmar e caminhos limpos de cancelamento e reembolso. Teste falhas de propósito (CVC errado, 3D Secure falhado, cartão recusado) e confirme que seu banco de dados permanece consistente.
Passo a passo - Transforme um protótipo em um release pronto para usuários
Quando apps criados por IA falham com usuários reais, raramente é um grande bug. São muitas pequenas lacunas que a demo nunca alcançou. O caminho mais rápido é escolher algumas jornadas reais e torná‑las tediosamente confiáveis.
Comece escrevendo as cinco jornadas de usuário mais importantes em linguagem simples: cadastrar, entrar, verificar e‑mail, redefinir senha e pagar. Para cada uma, defina o que significa “sucesso” para o usuário e o que deve ser verdadeiro no banco de dados.
Em seguida, adicione logs básicos para que você responda rapidamente a três perguntas: o que falhou, para qual usuário e por quê. Você não precisa de dashboards sofisticados nesse estágio, apenas migalhas suficientes para parar de chutar.
Uma sequência prática que funciona para a maioria das equipes:
- Defina as cinco jornadas e uma checklist de sucesso curta para cada uma.
- Adicione logs em pontos de risco (callbacks de auth, envios de e‑mail, confirmação de pagamento).
- Teste casos extremos de propósito: senha errada, link de redefinição expirado, rede lenta, duplo clique em “Pagar”.
- Adicione guardrails: timeouts, retries seguros e mensagens de erro que digam ao usuário o que fazer a seguir.
- Rode um piloto pequeno (5–20 usuários) e corrija o que eles encontrarem antes de convidar mais.
Uma mudança pequena que rende imediatamente: se a redefinição de senha falhar, não mostre “Algo deu errado”. Diga ao usuário se o link expirou, ofereça reenvio e registre a causa exata (token inválido, usuário não encontrado, rejeição do provedor).
Os riscos ocultos - segurança, segredos e integridade de dados
Um protótipo pode parecer “pronto” porque o caminho feliz funciona. Em produção, muitas falhas são realmente problemas de segurança e consistência de dados aparecendo como “bugs aleatórios”.
Problemas de segurança que parecem falhas comuns
Times não técnicos frequentemente vivem isso como comportamento instável: alguém é deslogado, um recurso funciona para uma pessoa e não para outra, ou dados “desaparecem”. Por trás pode haver uma falha de segurança.
Problemas comuns em código gerado por IA incluem segredos expostos (chaves de API em repositórios, bundles de browser ou logs), autorização quebrada (usuários acessam registros alheios trocando um ID) e riscos de injeção (entradas montadas em consultas ao banco sem tratamento seguro). Um exemplo realista: uma tela de admin parece OK em testes, mas em produção qualquer usuário logado consegue acessá‑la porque o app verifica apenas “está logado” e esquece “é admin”.
Integridade de dados: o app funciona até que não funcione
Problemas de dados são mais difíceis de perceber que bugs de UI. Você normalmente só os vê depois que o uso real cria casos de borda.
Fique atento a ações duplicadas (duplo clique ou retries criando pedidos duplicados), transações faltando (passo 1 conclui e passo 2 falha, deixando dados pela metade) e atualizações parciais (a UI diz “salvo”, mas só alguns campos mudaram).
Armadilhas comuns que equipes perdem quando só lançam rápido
Uma demo recompensa o caminho feliz. Usuários reais trazem senhas esquecidas, conexões lentas, sessões expiradas e tempos estranhos.
Um erro é confiar no primeiro sucesso. Se você testou login uma vez no seu laptop, ainda não testou o que acontece após logout, refresh, segundo dispositivo ou sessão que expira durante a noite. O app pode parecer estável enquanto está a um caso limite de travar todo mundo.
Outra armadilha é adiar recursos de recuperação. Redefinição de senha, troca de e‑mail e recuperação de conta parecem extras até o primeiro cliente não conseguir voltar. Aí o suporte vira produto e você corrige fluxos que mexem em código sensível à segurança sob pressão.
Trabalhos de background são onde muitos protótipos cortam caminho. E‑mails, atualizações de pagamento e sincronização de dados frequentemente dependem de webhooks, filas e jobs agendados. Se essas peças estiverem faltando ou frágeis, tudo parece ok enquanto você clica, mas o estado real do sistema deriva ao longo de horas e dias.
Algumas armadilhas se repetem:
- Um recurso “funciona uma vez” mas falha na segunda tentativa porque o estado está no navegador em vez do servidor.
- Recuperação de conta ausente, então um erro de login vira usuário perdido.
- Eventos de webhook não tratados por completo, então estornos, falhas de pagamento e bounces nunca atualizam seu BD.
- Não há plano de monitoramento, então você descobre outages por mensagens raivosas, não por alertas.
- A estrutura do código vira spaghetti rápido, deixando cada correção arriscada.
Exemplo: você lança um beta pago na segunda. Na terça, o cartão de um usuário é recusado, mas seu app ainda marca o pedido como pago porque só checou a resposta inicial do checkout. Na quinta, sua caixa de suporte está cheia e você não consegue reproduzir porque depende do timing do webhook.
Checklist rápido antes de convidar usuários reais
Antes de enviar convites, faça um “ensaio de usuário real”. Demos escondem o cotidiano: trocar de dispositivo, esquecer senha, clicar duas vezes, usar dados bagunçados.
Rode essas checagens em um ambiente de staging com duas contas (uma nova, outra existente). Anote o que acontece e quanto tempo cada passo leva.
- Loop de conta: crie uma conta, confirme (se necessário), saia e entre novamente em outro dispositivo ou perfil do navegador.
- Loop de redefinição de senha: acione recover, confirme que o e‑mail chega rápido (meta: < 2 minutos) e verifique que o link de reset funciona apenas uma vez.
- Loop de pagamentos: teste cobrança bem‑sucedida, cartão recusado, reembolso e duplo clique em Pagar.
- Checagem de segredos: inspecione o build frontend e chamadas de rede e confirme que nenhuma chave de API, URL de BD ou token de serviço está exposto ao browser.
- Checagem de visibilidade: force um erro (secret webhook errado, e‑mail inválido, pagamento falho) e confirme que você o vê claramente nos logs com detalhe suficiente para agir.
Uma maneira prática de rodar isso: peça a um amigo para fazer os passos sem ajuda. Se ele se confundir ou você não conseguir diagnosticar falhas rápido, pause o lançamento e feche essas lacunas.
Exemplo realista de semana de lançamento (e como se recuperar)
Um fundador constrói um app feito por IA, arrasa na demo e convida 50 beta users na segunda. A primeira hora é ótima. Ao meio‑dia, mensagens de suporte começam a chegar.
No Dia 1, três pequenas rachaduras viram problemas reais. Alguns usuários entram em loop de login após redefinir senha porque sessões e redirects foram tratados de forma frouxa. Outros nunca recebem e‑mail de verificação porque o app usou um setup de remetente de teste que funcionava localmente mas não em caixas reais. Alguns pagam, veem tela de sucesso e ainda assim não conseguem acessar a área paga porque o app trata “pagamento sucedido” e “assinatura ativa” como a mesma coisa.
No Dia 2, o fundador faz correções manuais: exclui contas, alterna flags no banco e pede aos usuários para tentar de novo. Usuários confusos se cadastram duas vezes, provedores começam a aplicar throttling e alguns clientes pedem reembolso após serem cobrados mas bloqueados. O app não está “fora do ar”, mas a confiança está.
Um sprint de reparo focado é diferente de patches aleatórios. O objetivo é deixar os fluxos principais confiáveis antes de adicionar qualquer coisa nova:
- Reproduza falhas end‑to‑end nos fluxos core (login, verificar e‑mail, pagar, liberar acesso).
- Corrija causas‑raiz, não sintomas (tokens, redirects, webhooks, checagens de estado).
- Adicione guardrails como limites de taxa, retries seguros e mensagens de erro claras.
- Reteste em condições reais (contas novas, caixas reais, cartões reais).
- Refaça um beta pequeno (5–10 usuários) antes de abrir as portas novamente.
Então tome uma decisão clara de escopo. Faça patch quando a arquitetura estiver basicamente sólida e as falhas isoladas. Refatore quando o mesmo padrão de bug aparece em todo lugar. Reconstrua quando a base de código estiver tão emaranhada que fica perigoso mexer — comum em protótipos gerados por IA.
Próximos passos - obtenha clareza, depois corrija o que importa primeiro
Se seu app foi construído com ferramentas como Lovable, Bolt, v0, Cursor ou Replit, presuma que foi otimizado para demo. Isso não significa que seja ruim. Significa que você deve esperar atalhos em login, e‑mails, pagamentos e segurança.
Antes de reescrever qualquer coisa, esclareça o que está realmente falhando. Equipes perdem semanas reconstruindo partes erradas quando começam por opiniões em vez de evidências.
Colete provas do uso real e reduza isso às poucas jornadas que importam. Um usuário não consegue redefinir senha, outro nunca recebe e‑mail de boas‑vindas e um terceiro vê erro de pagamento com cartão real. Isso já é suficiente para planejar o próximo sprint.
O que reunir em uma passada curta:
- 3–5 relatos de usuários com passos exatos (o que clicaram e o que esperavam)
- Capturas de tela dos erros e o texto completo das mensagens
- Top 3 fluxos quebrados que bloqueiam cadastros ou receita
- Notas sobre onde acontece (dispositivo, navegador, horário)
- Acesso aos logs ou ao que seu host fornece
A partir daí, peça diagnóstico antes de reconstruir. Uma auditoria sólida mapeia sintomas para causas‑raiz (manuseio de sessão, configuração de domínio de e‑mail, validação ausente, webhooks não tratados) e ranqueia correções por impacto.
Se você herdou um protótipo gerado por IA que está quebrando com uso real, FixMyMess (fixmymess.ai) foca em diagnosticar e reparar essas lacunas exatas: autenticação, entregabilidade, lógica de webhooks, endurecimento de segurança e limpeza que torna o código seguro para produção. Uma auditoria rápida pode transformar “funciona na demo” em uma lista priorizada de correções que você executa com confiança.
Perguntas Frequentes
Por que meu app parece perfeito numa demo mas desaba com usuários reais?
Um demo prova o caminho feliz uma vez, nas suas condições. Produção precisa lidar com uso repetido, entradas bagunçadas, redes lentas, sessões expiradas, múltiplos dispositivos e pessoas clicando fora da ordem “esperada”.
O que devo consertar primeiro antes de convidar usuários reais?
Priorize as jornadas que geram confiança e receita: cadastro, login, verificação de e-mail, redefinição de senha e pagamento. Faça cada uma delas funcionar repetidamente e torne as falhas compreensíveis para que o usuário se recupere sem precisar te contatar.
Por que os usuários dizem “Consigo entrar uma vez, depois para de funcionar”?
Normalmente é um problema de sessão ou redirect, não do botão de login. Cookies podem estar configurados de forma que funcionam no localhost, mas falham em domínios reais, com configurações de privacidade ou em navegadores diferentes, causando loops após o primeiro acesso bem‑sucedido.
Qual é o erro de OAuth mais comum em apps gerados por IA?
Provedores OAuth exigem URLs de callback e comportamento de redirect exatos. Uma pequena diferença entre ambientes pode fazer o provedor indicar “Success” enquanto seu app nunca conclui a sessão corretamente, levando o usuário de volta à tela de login.
Por que os e-mails funcionam para mim mas os clientes nunca os recebem?
Enviar não é o mesmo que entregar. Se o seu domínio não estiver configurado com SPF, DKIM e DMARC, muitos provedores filtrarão ou rejeitarão mensagens, então e-mails de verificação e redefinição nunca aparecem para os clientes, mesmo que o app diga que foram enviados.
O que devo checar nos templates de e-mail antes do lançamento?
Frequentemente há artefatos de staging: links apontando para localhost ou um domínio de teste, ou identidade do remetente que aciona filtros de spam. Mesmo quando o e-mail chega, um link quebrado ou ambiente errado transforma-o em beco sem saída.
Por que pagamentos funcionam no sandbox mas falham com cartões reais?
O sandbox é permissivo; bancos reais não. Há bloqueios extras como 3D Secure, checagens AVS/CVC e recusas inesperadas. Seu app precisa tratar esses ramos sem corromper o estado e não presumir que a página de checkout igual a pagamento confirmado.
Quais são os maiores erros com webhooks que causam caos na cobrança?
Webhooks são a fonte de verdade em produção e podem chegar atrasados, duplicados ou não chegar se o endpoint estiver mal configurado. Sem idempotência e tratamento consistente, você verá cobranças duplicadas, usuários pagos sem acesso ou acesso concedido sem pagamento confirmado.
Que problemas de segurança se escondem dentro de falhas “aleatórias” na produção?
Protótipos gerados por IA costumam expor segredos no frontend ou em logs e frequentemente têm autorização mal implementada, permitindo que usuários acessem dados alheios. Esses problemas parecem bugs aleatórios, mas são falhas de segurança que podem ficar sérias rápido.
Quando devo corrigir, refatorar ou reconstruir, e quem pode ajudar?
Capture detalhes suficientes para responder o que falhou, para qual usuário e por quê, e reproduza o problema end‑to‑end. Se você estiver preso em correções repetidas ou o código estiver muito emaranhado, uma auditoria focada mapeia sintomas para causas‑raiz e prioriza correções por impacto; FixMyMess pode ajudar a transformar isso em um plano claro, muitas vezes em 48–72 horas após o diagnóstico.