Auditoria de custos para protótipos criados com IA: corte gastos com API e BD
Uma auditoria de custos para protótipos criados com IA ajuda a identificar endpoints, consultas e jobs em segundo plano que inflacionam a fatura e mostra como corrigir os maiores problemas rapidamente.
O que está realmente impulsionando sua fatura?
Muitos protótipos criados com IA ficam caros por um motivo simples: funcionam bem em demos, mas desperdiçam dinheiro nos bastidores. Geradores de código frequentemente duplicam chamadas, pulam cache e adicionam polling “útil” que nunca para. Você só percebe quando usuários reais chegam, ou alguns testadores deixam o app aberto o dia todo.
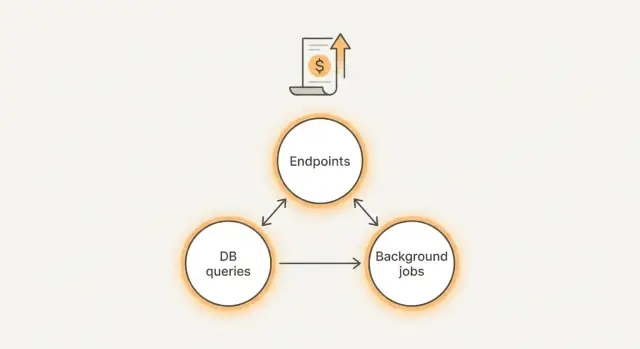
A maior parte do gasto surpresa vem de três lugares:
- Endpoints: uma tela dispara chamadas demais à API, retries ou respostas gigantes.
- Consultas: queries lentas ou sem limites que varrem muito mais dados do que o necessário.
- Tarefas em segundo plano: cron jobs, workers de fila e webhooks que rodam com muita frequência ou não param.
Gasto “bom” é chato. É previsível e acompanha atividade real do produto. Se você tem 10x mais usuários ativos, os custos podem subir, mas a alta faz sentido. Gasto “ruim” cresce quando ninguém está fazendo nada, ou quando um recurso dispara centenas de chamadas sem aviso.
Se você só tem 30 minutos, meça as poucas coisas que revelam problemas rapidamente:
- Principais endpoints por contagem de requisições e tamanho médio de resposta
- Consultas de banco mais lentas e mais frequentes
- Jobs em segundo plano por frequência de execução e tempo médio de execução
- Chamadas a APIs de terceiros por endpoint e taxa de erro/retry
- Gasto base durante horas de “ninguém usando o app”
Um cheque de realidade rápido ajuda: abra o app, faça uma ação normal (como carregar um dashboard) e observe o que dispara. Se essa única ação aciona 20 requisições, três queries longas e um pico na fila de jobs, você já achou por onde começar.
Relacione gasto a funcionalidades reais (não a 'uso' vago)
Dashboards que mostram “chamadas de API” ou “leituras do BD” não dizem o que consertar. Isso fica mais fácil quando você traduz gasto em ações reais que um usuário faz.
Faça um mapa simples de custos
Anote o punhado de ações que têm permissão para custar dinheiro e trate todo o resto como suspeito até que se prove necessário. Para muitos protótipos:
- Cadastro e login (email, SMS, OAuth)
- Busca e filtros
- Chat ou geração de conteúdo
- Relatórios e exportações
- Uploads de arquivos e processamento
Atribua uma expectativa aproximada a cada ação: 'uma mensagem de chat deve custar menos que X', ou 'uma execução de relatório deve levar menos que Y segundos'. Você não precisa de números perfeitos. Precisa de metas que deixem o desperdício óbvio.
Depois, separe custos acionados pelo usuário dos sempre ligados.
Custos acionados pelo usuário acontecem só quando alguém clica um botão. Custos sempre ligados rodam mesmo quando ninguém está usando o app: cron jobs, workers, polling em background, auto-retries e 'health checks' que batem endpoints caros. Custos sempre ligados costumam ser a vitória mais rápida porque queimam dinheiro 24/7.
Verifique também qual ambiente está gastando dinheiro. Apps criados com IA frequentemente apontam dev ou staging para os mesmos serviços pagos da produção, ou deixam workers de teste rodando durante a noite. Se você não consegue dizer claramente 'este custo é prod', suponha que parte dele não seja.
Defina sua meta antes de mexer no código:
- Cortar 20% esta semana (desligar o maior desperdício)
- Cortar 80% este mês (refazer arquitetura, cache e acesso a dados)
Um padrão comum: uma funcionalidade de "relatório" é usada uma vez por dia, mas um job em segundo plano a gera a cada 5 minutos para cada conta. O dashboard mostra "alto uso de BD", mas o problema real é um recurso que ninguém pediu rodando constantemente.
Passo a passo: inventário de endpoints, queries e jobs
O objetivo é parar de adivinhar. Você quer um mapa de todo lugar em que seu app gasta dinheiro, ligado a requisições reais e trabalho real.
Escolha um dia normal de tráfego e trate-o como sua linha de base. Se você ainda não tem muito tráfego, use um dia de testes internos onde você exercita os fluxos principais (cadastro, checkout, busca, chat, uploads). Salve essa base para poder comparar depois das mudanças.
Construa um inventário de uma página
Percorra o app em três blocos: endpoints, consultas ao banco e trabalho em segundo plano.
- Endpoints
- Liste todas as rotas de API (incluindo rotas internas) e anote quem as chama: browser, app móvel, cron job, webhook ou outro serviço.
- Adicione volume aproximado e latência. Números exatos são ótimos, mas 'alto/médio/baixo' e 'rápido/lento' já bastam para identificar os primeiros problemas.
- Consultas
- Para cada endpoint, registre as principais consultas ao banco que ele dispara.
- Amostre a partir de logs, tracing ou a visão de consultas lentas do seu BD, e descreva o formato da query (tabelas tocadas, filtros, joins).
- Trabalho em segundo plano
- Anote todo job agendado, handlers de webhook e workers de fila.
- Inclua com que frequência rodam e o que fazem (sincronizar, enviar email, embeddings, limpeza).
Mantenha tudo ligado ao seu dia-base para estimar custo por 1.000 requisições ou por usuário ativo.
Com essa lista, padrões aparecem: um endpoint é chamado em toda carga de página, uma query 'pequena' varre uma tabela grande, ou um job roda a cada minuto mesmo quando nada mudou.
Endpoints que ficam caros silenciosamente
Alguns dos maiores vazamentos se escondem em endpoints 'normais' chamados o dia todo. Frequentemente o backend não é caro por requisição; é caro porque a mesma requisição acontece centenas ou milhares de vezes.
Um culpado comum é o polling: o frontend verifica atualizações a cada poucos segundos, mesmo quando nada muda. Loops de refresh também aparecem por acidente, por exemplo quando uma página re-renderiza e dispara outro fetch, ou quando dois componentes chamam o mesmo endpoint sem saber. Se usuários mantêm uma aba aberta, esse loop silencioso vira um gasto constante.
Outro padrão é um endpoint que faz trabalho demais por requisição. Código gerado por IA pode agrupar múltiplas buscas, joins extras ou processamento de arquivos em uma única rota 'por conveniência'. Funciona em demo, mas cada chamada dispara uma cadeia de consultas e chamadas a APIs de terceiros.
Rotas com muitas leituras ficam caras quando não há cache. Se um endpoint retorna os mesmos dados para muitos usuários (preços, configurações, lista de templates), você paga repetidamente por leituras idênticas.
Retries multiplicam custos rápido. Se timeouts são curtos demais, ou faltam limites de taxa, clientes podem re-tentar agressivamente. Você acaba pagando duas (ou mais) vezes pela mesma ação.
Alguns sinais de que um endpoint merece atenção imediata:
- É chamado em um timer (polling) ou a cada pressionamento de tecla
- Dispara várias chamadas downstream (BD mais APIs externas)
- Retorna a mesma resposta com frequência mas não tem cache
- Dá timeout às vezes e clientes fazem retry automático
- Não tem limite de taxa, então rajadas viram picos caros
Exemplo: um endpoint /messages em um protótipo de chatbot é chamado a cada 2 segundos para checar novas respostas. Além disso, recalcula o contexto da conversa e consulta o banco várias vezes. Corrigir a frequência das chamadas e mover trabalho pesado para fora da requisição pode cortar gasto imediatamente.
Consultas que disparam custo no banco
O gasto com banco frequentemente vem de poucas queries que rodam muito mais do que você imagina. Código gerado por IA também pode esconder ineficiência atrás de um ORM, então o app parece ok em testes, mas fica caro com tráfego real.
Um dos maiores culpados é o padrão N+1: você busca uma lista de itens e o código silenciosamente busca dados relacionados linha a linha dentro de um laço. Uma página com 50 pedidos pode virar 51 queries (ou 201 se cada pedido puxa cliente e itens), e toda atualização repete o trabalho.
Índices faltando são outro multiplicador comum. Se você filtra por campos como user_id, created_at ou status, ou faz join em chaves estrangeiras, o banco não deveria varrer a tabela toda. Quando falta o índice, o custo sobe conforme os dados crescem.
Também fique de olho em queries que puxam demais. Selecionar todas as colunas, carregar JSONs grandes ou retornar milhares de linhas quando a UI mostra só as primeiras 20 desperdiça CPU, memória e rede. Busca, feeds de atividade e tabelas administrativas são culpados frequentes, especialmente quando paginação é esquecida.
Cinco verificações que geralmente encontram os piores picos:
- Procure leituras repetidas dentro de loops (N+1) em logs ou traces
- Verifique se existem índices para filtros e chaves de join comuns
- Selecione apenas as colunas necessárias, não
SELECT * - Adicione paginação e limites rígidos para scroll e busca
- Confirme que pooling de conexões está configurado, para não abrir uma conexão nova por requisição
Exemplo: um protótipo de chatbot armazena mensagens e 'carrega as últimas 5.000' a cada visualização de página para construir contexto. Mudar para buscar as últimas 30 mensagens, indexar conversation_id e agrupar buscas relacionadas pode reduzir a carga do banco rapidamente.
Tarefas em segundo plano que rodam mais do que você pensa
Jobs em segundo plano são uma razão comum pela qual um protótipo de IA parece barato em teste e caro em produção. Eles rodam quando ninguém está usando o app e frequentemente tocam nas partes mais caras da sua stack: APIs externas, banco de dados e armazenamento de arquivos.
Comece listando todo job que roda em um timer e escreva a agenda em linguagem simples. 'A cada minuto' e 'a cada 5 minutos' são assassinos de orçamento, especialmente quando o job chama APIs pagas ou varre tabelas grandes.
Depois, procure jobs que rodam mesmo quando não há trabalho. Um exemplo típico é um job de 'sync' que checa por novos dados mas ainda assim busca milhares de linhas ou chama uma API mesmo quando nada mudou. Guardas simples antes das partes caras geralmente são suficientes para estancar o vazamento.
Comportamento de fan‑out é outro multiplicador silencioso. Um job agendado pode enfileirar um job por usuário, workspace ou registro. Se roda a cada hora e você tem 2.000 usuários, de repente você roda 48.000 jobs por dia.
Algumas correções que costumam reduzir gasto rapidamente:
- Adicione um cheque de 'sem trabalho' (tamanho da fila, timestamp da última atualização ou uma contagem barata) antes de qualquer query ou chamada API cara
- Limite o fan‑out com batching (processe 100 registros por vez) e backoff quando o sistema estiver ocupado
- Torne jobs idempotentes para que retries não repitam trabalho caro (use uma chave única de job ou um marcador de processado)
- Coloque contagens e durações nos logs: itens processados, chamadas a APIs, linhas varridas, tempo total de execução
Como escolher as poucas correções que cortam gasto rápido
Uma auditoria só importa se virar um plano curto e focado. O objetivo não é deixar tudo perfeito. É remover os hotspots que geram a maior parte da fatura.
Para cada mudança candidata, anote duas coisas: quão difícil ela é e quanto pode economizar. Mantenha leve para decidir rápido.
- Adicionar limites de requisição a endpoints caros (baixo esforço, alta economia)
- Cachear respostas com muitas leituras por 60 segundos (baixo esforço, economia média a alta)
- Adicionar um índice de BD à query principal (esforço médio, alta economia)
- Reduzir frequência de polling no worker ou UI (baixo esforço, economia média a alta)
- Refatorar um módulo inteiro (alto esforço, economia incerta)
Priorize correções que reduzam um destes motores:
- Número de chamadas API (menos requisições, menos retries, respostas menores)
- Linhas varridas (consultas mais rápidas, menos scans completos)
- Frequência de jobs (menos polling, menos execuções agendadas)
Guardrails rápidos costumam vencer primeiro. Coloque limites em padrões abusivos (rate limits, timeouts, tamanho máximo de página). Adicione cache onde os dados não mudam a cada segundo. Para trabalho em segundo plano, mude de 'checar a cada minuto' para 'rodar quando necessário' ou para uma agenda mais longa.
Use uma regra clara de parada: entregue 2–3 mudanças e re-meça por um dia (ou um ciclo normal de negócio). Se você não ver uma queda significativa, volte ao inventário. Grandes rewrites são tentadores, mas frequentemente erram o principal motor de custo.
Exemplo: se um chatbot protótipo reenvia toda a conversa a cada mensagem, uma mudança pequena como resumir mensagens antigas ou limitar o histórico pode cortar gasto com tokens mais rápido que reconstruir o recurso inteiro.
Exemplo: um protótipo de chatbot com custos fora de controle
Um caso comum: um protótipo Lovable ou Bolt com uma tela de chat simples mais um dashboard de 'uso' e 'histórico'. Funciona em demos, mas a fatura cresce mais rápido que o número de usuários.
Padrão típico: cada carregamento de página dispara várias chamadas de IA 'só por precaução' (resumos, prompts sugeridos, sentimento, geração de título). Ao mesmo tempo, o dashboard roda scans completos para reconstruir estatísticas do zero. Alguns testadores ativos geram centenas de chamadas por hora, e o banco começa a fazer leituras pesadas parecendo picos aleatórios.
Muitas vezes há um culpado principal: um endpoint de chat que repete trabalho de embedding a cada mensagem, às vezes mais de uma vez por requisição. Pode embedar o texto do usuário, re-embedar as últimas N mensagens e re-embedar os mesmos blocos de base de conhecimento porque nada está em cache. Se o endpoint também armazena tudo e logo em seguida consulta 'todas as mensagens deste usuário' sem limites, o custo de consulta cresce com cada conversa.
Correções que cortam gasto tendem a ser chatas, mas eficazes:
- Debounce nos gatilhos da UI para que uma ação do usuário gere uma requisição, não cinco
- Cachear embeddings e reutilizá-los quando o texto não mudou
- Adicionar paginação e limites ao histórico de mensagens e tabelas do dashboard
- Mover trabalho 'agradável de ter' de IA (títulos, resumos) para jobs agendados que rodem menos vezes
- Colocar guardrails: timeouts, máximo de tokens e rate limits por usuário
O resultado esperado é menos chamadas por ação do usuário e uma curva de custo mais plana. Depois dessas mudanças, você deveria prever gasto a partir dos usuários ativos, em vez de ser pego de surpresa por uma tarde ocupada.
Erros comuns a evitar durante uma auditoria de custos
Uma auditoria pode descarrilar se você tratá‑la como exercício de planilha em vez de caça aos poucos itens que geram a maior parte da fatura. O objetivo não é medição perfeita. É economia rápida e segura.
Uma armadilha é coletar muitas métricas e perder o óbvio. Equipes monitoram todas as rotas, todas as tabelas, todos os dashboards e depois não agem sobre os piores culpados. Na prática, seus top 5 endpoints e top 5 queries frequentemente explicam a maior parte do gasto.
Outro erro é otimizar a camada errada. Você pode acelerar uma query lenta, mas se um job em segundo plano a chama a cada minuto (ou roda duas vezes por retries), a fatura não muda. Sempre confirme o que dispara o trabalho: ações do usuário, cron schedules, webhooks, retries ou workers.
Fique atento a estes padrões de falha:
- Você desabilita uma feature para cortar custo, mas o problema real era um loop de chamadas ou um cliente que polleia demais
- Você ajusta uma query enquanto um job de exportação ou sync roda a mesma query milhares de vezes
- Você busca economia e acaba quebrando correção (dados parciais, escritas faltando, cache muito obsoleto)
- Você pula checagens básicas de segurança e expõe segredos, auth fraca ou riscos de injeção
- Você 'resolve' custo reduzindo limites sem tratar por que o app atinge esses limites
Exemplo: um recurso de 'notificações' parece caro, então é desligado. Depois descobre-se que o culpado real era um worker que reenviava o mesmo lote porque o job nunca salvava seu checkpoint.
Checklist rápido: antes e depois de mudar algo
Trate isso como um pequeno experimento: meça primeiro, mude uma coisa, meça de novo. Caso contrário, você pode 'economizar' no papel enquanto quebra login, deixa páginas lentas ou causa retries que saem mais caros.
Escolha um dia-base (ou uma janela típica de 24 horas) e anote seus números em um lugar: gasto total de API, gasto de BD e gasto de workers, mais alguns principais culpados.
Antes de mudar código, confirme:
- Quais são os 3 principais endpoints por custo e por volume (requisições)?
- Quais são as 3 principais queries por tempo total ou linhas varridas?
- Você tem a lista completa de jobs agendados, filas e tarefas cron, e com que frequência rodam?
- Registrou números 'antes' para uma janela base (gasto, latência, taxa de erro, retries)?
- Sabe o que 'bom' significa para seus usuários (tempo de carregamento, tempo para primeira resposta, taxa de checkout ou login bem-sucedidos)?
Depois das mudanças, re-verifique a mesma janela e acrescente dois cheques: retries e experiência do usuário. Um erro comum é reduzir computação por requisição e introduzir 500s, timeouts ou falhas de auth que disparam retries automáticos. Um endpoint quebrado pode dobrar tráfego e custo sem novos usuários.
Também confirme que você não apenas moveu o custo para outro lugar (por exemplo: menos chamadas API mas queries de BD mais pesadas, ou menos leituras de BD mas mais jobs em segundo plano).
Próximos passos se seu protótipo gerado por IA for difícil de desembaraçar
Se sua auditoria disser 'tudo está caro', o problema geralmente é o código, não a nuvem. Projetos gerados por IA frequentemente chegam com roteamento emaranhado, lógica copiada e retries escondidos. Antes de otimizar linha a linha, faça um diagnóstico curto para mapear o que realmente roda em produção e como as requisições fluem.
Comece encontrando hotspots. Se você tem só 1–3 culpados claros (um endpoint barulhento, uma query lenta, um job hiperativo), patchar é geralmente a vitória mais rápida. Se você encontra uma dúzia de problemas médios espalhados por muitos arquivos, você gastará tempo perseguindo sintomas em vez de resolver a causa, e um pequeno refactor costuma sair mais barato.
Uma regra prática:
- Patch quando a correção for isolada e testável (rate limit num endpoint, adicionar cache, corrigir um N+1)
- Refactor quando o mesmo padrão de bug se repete (carregamento de dados copiado, múltiplos endpoints fazendo o mesmo trabalho, jobs que disparam uns aos outros)
- Rebuild quando o básico está quebrado (auth pouco confiável, segredos expostos, arquitetura que impede mudanças seguras)
Se você trouxer ajuda externa, a entrega importa mais que longas explicações. Traga um dia-base (24 horas normais de tráfego) e um pacote curto de fatos:
- Lista de endpoints com contagens de requisições e piores culpados
- Top queries com tempo médio e frequência
- Lista de jobs em segundo plano com agendas e contagens reais de execução
- Notas de deploy recentes (o que mudou quando o gasto disparou)
Se o código veio de ferramentas como Lovable, Bolt, v0, Cursor ou Replit e estiver difícil rastrear o que chama o quê, FixMyMess (fixmymess.ai) pode fazer uma auditoria de código gratuita para mapear endpoints, queries e jobs antes de você tocar em qualquer coisa. A partir daí, o foco é remediação direta: correção de lógica, endurecimento de segurança, refactor e preparação para deploy para que o protótipo passe a se comportar como software de produção, não uma demo.
Perguntas Frequentes
Minha fatura do protótipo de IA está alta — o que devo checar primeiro?
Comece verificando o que continua gastando quando ninguém está usando o app. Compare uma janela tranquila durante a noite com uma hora de maior uso e procure um pequeno conjunto de pontos críticos: alguns endpoints com contagem de requisições muito alta, algumas consultas ao banco de dados que dominam o tempo total, e qualquer job em segundo plano que rode em cronograma apertado. Se os custos não caem durante horas de 'ninguém usando', a vitória mais rápida costuma ser trabalho sempre ligado, não funcionalidades de usuário.
Como eu defino uma base de referência antes de começar a mudar código?
Escolha um período de 24 horas representativo e registre números que você possa checar novamente depois: gasto total com API, gasto com banco de dados e gasto com workers em segundo plano, além dos principais culpados por volume e latência. O objetivo não é contabilidade perfeita; é ter um instantâneo 'antes' para saber se suas mudanças realmente reduziram custo em vez de apenas mover ele para outro lugar.
Como eu relaciono gasto na nuvem com uma funcionalidade real em vez de métricas vagas?
Traduza 'uso' em ações reais do usuário: carregar um dashboard, enviar uma mensagem no chat, gerar um relatório ou fazer upload de um arquivo. Depois observe o que cada ação dispara em produção: requisições, consultas, picos de jobs e chamadas a terceiros. Quando uma ação simples dispara uma cadeia surpreendente de trabalho, você achou o que precisa consertar.
Por que polling faz os custos explodirem mesmo com poucos usuários?
Polling parece inofensivo porque cada requisição é pequena, mas roda constantemente e se multiplica entre abas abertas e usuários. Se a interface consulta a cada poucos segundos por atualizações que raramente mudam, os custos sobem mesmo com produto 'ocioso'. A solução comum é reduzir ou eliminar polling: buscar somente quando algo muda ou quando o usuário pede atualização.
Como retries e timeouts aumentam meu gasto silenciosamente?
Retries podem dobrar ou triplicar sua fatura porque você paga pelo mesmo trabalho várias vezes. Isso acontece quando timeouts são muito agressivos, erros não são tratados corretamente ou clientes re-executam automaticamente sem limites. Normalmente a solução é usar timeouts sensatos, adicionar limites de taxa, tornar requisições idempotentes e garantir que falhas não disparem trabalho caro repetidamente.
O que é o problema de consulta N+1 e como eu o identifico?
O padrão N+1 ocorre quando seu código busca uma lista e depois busca dados relacionados uma linha por vez dentro de um laço. Pode parecer ok com dados pequenos, mas escala terrivelmente e fica caro rápido. A correção prática é agrupar essas buscas para que um carregamento de página não gere dezenas ou centenas de consultas separadas.
Quando adicionar um índice no banco é a melhor solução para reduzir custo?
Se você filtra ou faz join por campos como user_id, created_at ou status e o banco está escaneando a tabela inteira, você terá consultas lentas que pioram conforme os dados crescem. Adicionar o índice certo geralmente reduz diretamente o tempo de consulta e o uso de CPU. O importante é indexar o que os endpoints principais realmente filtram e fazem join, não o que 'parece' importante.
Por que jobs em segundo plano causam gasto 'ocioso' durante a noite?
Porque elas rodam mesmo quando ninguém está usando o app e normalmente tocam as partes mais caras do sistema: banco de dados, APIs pagas e armazenamento. Um job que roda a cada minuto vira um vazamento 24/7, especialmente se ele varre muitas linhas ou faz fan‑out por usuário. Um simples cheque de 'sem trabalho' e parar a fan‑out desnecessária corta gasto rápido sem mexer nas funcionalidades do usuário.
Como decidir entre patchar, refatorar ou reconstruir?
Comece por mudanças fáceis de testar que reduzam um driver claro como contagem de requisições, linhas varridas ou frequência de jobs. Aplique patch quando o conserto for isolado e testável (limitar um endpoint, adicionar cache, corrigir um N+1). Refatore quando o mesmo padrão ruim se repetir em vários arquivos. Refaça quando fundamentos estiverem quebrados (auth instável, segredos expostos, arquitetura que impede mudanças seguras).
O que devo entregar se eu pedir ajuda para consertar uma base de código gerada por IA?
Traga um dia-base (24 horas normais de tráfego) e um resumo simples do que está caro: quais endpoints são ruidosos, quais consultas são lentas e frequentes, e quais jobs rodam demais. Se o código veio de ferramentas como Lovable, Bolt, v0, Cursor ou Replit e é difícil rastrear o que chama o quê, FixMyMess pode iniciar com uma auditoria de código gratuita e depois remediar os pontos críticos com verificação humana. A maioria dos projetos é concluída em 48–72 horas, com taxa de sucesso de 99%, e o objetivo é transformar código de demo em comportamento pronto para produção sem faturas surpresa.