Boas práticas de tratamento de erros de API para mensagens claras ao usuário
Aprenda boas práticas de tratamento de erros de API para formatos de erro consistentes, mensagens seguras e um método simples para mapear falhas do servidor a estados de UI claros.
Por que erros de API pouco claros frustram os usuários
Quando um app falha, os usuários não veem “uma exceção”. Eles veem uma tarefa bloqueada. Se a mensagem for vaga ou alarmante, podem achar que perderam dados, fizeram algo errado ou até que foram invadidos. A maioria não tentará debugar. Vai sair, apertar o botão de novo ou contatar o suporte.
Erros confusos também parecem aleatórios. Uma tela pode dizer “Algo deu errado”, outra mostra um longo stack trace do servidor e uma terceira não retorna nada. Essa inconsistência faz as pessoas hesitarem porque não conseguem saber o que esperar. Mesmo que o problema seja pequeno, a experiência parece pouco confiável.
Para sua equipe, erros inconsistentes geram ruído. Chamados de suporte ficam maiores porque os usuários não conseguem descrever o que aconteceu. A analytics se enche de falhas “desconhecidas”. Engenheiros perdem tempo reproduzindo problemas porque a forma da resposta muda entre endpoints, ou porque um 500 é usado para tudo.
Quando os erros não são claros, os usuários costumam fazer uma de três coisas: tentar de novo várias vezes (o que pode gerar requisições duplicadas e, às vezes, cobranças duplicadas), abandonar o fluxo (especialmente checkout, cadastro e recuperação de senha) ou contatar o suporte com capturas de tela em vez de detalhes úteis.
Um tratamento de erros claro corrige isso padronizando três pontos:
- Uma forma de erro consistente (para que todo endpoint falhe do mesmo jeito)
- Texto seguro (para que o usuário saiba o próximo passo sem expor detalhes internos)
- Comportamento de UI previsível (para que cada erro mapeie para um estado conhecido como “tentar de novo”, “corrigir dados” ou “entrar novamente”)
O que um bom erro deve fazer (para usuários e para sua equipe)
Um bom erro não é só “algo deu errado”. Ele ajuda uma pessoa real a se recuperar e ajuda sua equipe a achar a causa rapidamente.
Para os usuários, um erro precisa de três coisas: o que aconteceu (em palavras simples), o que fazer a seguir (um passo claro) e se os dados estão seguros. “Seu cartão foi recusado. Tente outro cartão ou ligue para o banco. Nenhuma cobrança foi feita” acalma e é acionável. “Pagamento falhou: 402” não é.
Para sua equipe, o mesmo erro deve trazer identificadores estáveis e contexto útil. Isso normalmente significa um conjunto pequeno de códigos de erro confiáveis entre endpoints, mais campos consistentes para que logging, alertas e tratamento na UI não quebrem quando um endpoint muda. Quando um usuário reporta um problema, o suporte deve conseguir pegar um request ID na UI e um engenheiro achar o trace exato.
O que nunca deve chegar à UI
Alguns detalhes são úteis para depuração, mas inseguros (ou apenas confusos) para usuários. Mantenha estes fora das mensagens visíveis:
- Segredos (chaves de API, tokens, senhas, strings de conexão)
- Stack traces e caminhos internos de arquivos
- SQL bruto, parâmetros de query e payloads completos de requisição
- Nomes de serviços internos e infraestrutura
- Regras de validação detalhadas que ajudam atacantes a adivinhar entradas
Uma regra simples: retorne mensagens seguras e amigáveis ao usuário, e mantenha os detalhes afiados nos logs vinculados a um código estável e a um request ID.
Escolha alguns estados de UI que você vai suportar em todo lugar
Se cada tela inventa seu próprio comportamento de erro, os usuários ficam perdidos. Combine um pequeno conjunto de estados de UI que toda página, modal e formulário possam usar, e então mapeie erros de API para esses estados da mesma forma sempre.
Para a maioria dos apps, um vocabulário curto compartilhado é suficiente: loading, success, empty, needs action (o usuário precisa alterar algo), try again (problema temporário) e blocked (não conseguem continuar sem suporte ou outro plano).
Defina o que cada estado significa em palavras simples. Por exemplo, “empty” significa que a requisição funcionou, mas não há nada a mostrar, enquanto “try again” significa que a requisição falhou e uma nova tentativa pode dar certo.
Decida o que é retryable versus não retryable. Um timeout, limite de taxa ou sobrecarga de servidor geralmente é retryable. Falta de permissão, entrada inválida ou conta expirada geralmente não são retryable até que algo mude.
Uma regra rápida ajuda:
- Try again: temporário, seguro tentar de novo
- Needs action: o usuário pode corrigir (editar, entrar, confirmar email)
- Blocked: o usuário não consegue consertar sozinho
Também planeje sucessos parciais. Isso acontece quando uma ação em lote salva 8 itens e 2 falham. A UI deve continuar mostrando o que teve sucesso, apontar claramente o que precisa de ação e permitir que o usuário reenvie apenas os itens com falha.
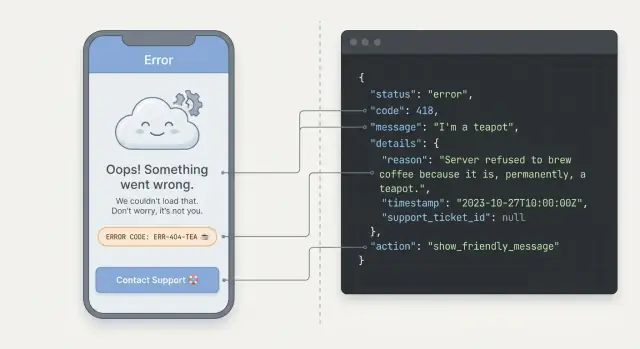
Projete uma forma de erro consistente (um formato para todos os endpoints)
Se cada endpoint retorna erros de forma diferente, sua UI terá que adivinhar o que aconteceu. Uma forma de erro previsível é uma das práticas mais práticas porque permite construir um único conjunto de regras de UI e reutilizá-lo em todo lugar.
Um formato JSON simples
Escolha uma estrutura JSON e retorne-a para todas as falhas (validação, auth, limites de taxa, bugs do servidor). Mantenha-a pequena, mas com espaço para detalhes.
{
"error": {
"code": "AUTH_INVALID_CREDENTIALS",
"message": "Email or password is incorrect.",
"details": {
"fields": {
"email": "Not a valid email address"
}
},
"developerMessage": "User not found for email: [email protected]"
},
"requestId": "req_01HZX..."
}
Use códigos de erro estáveis e não trate o texto da message como contrato. A UI deve mapear códigos para o estado correto, enquanto a mensagem permanece legível para humanos.
Frequentemente ajuda manter duas mensagens: uma mensagem para o usuário que é segura para exibir e uma mensagem opcional para desenvolvedores que ajuda na depuração, mas que também não deve expor segredos.
Para formulários, reserve um lugar claro para erros por campo para destacar inputs específicos sem precisar parsear texto.
Algumas regras que evitam caos depois:
- Sempre inclua
error.codeerequestId. - Mantenha
error.messagesegura e clara. - Coloque questões ao nível de campo sob
details.fields. - Mantenha os códigos estáveis mesmo se a redação mudar.
- Nunca vaze stack traces ou credenciais.
Mensagens de erro seguras que os usuários entendem
Bons erros ajudam as pessoas a se recuperar. Erros ruins fazem-nas repetir o mesmo passo ou abandonar o fluxo. Seja específico sobre o que o usuário pode fazer a seguir, sem revelar como seu sistema funciona internamente.
Uma mensagem segura explica o resultado e o próximo passo, sem vazar detalhes como nomes de tabela, stack traces, respostas de fornecedores, chaves secretas ou se um endereço de email existe no sistema.
Mantenha duas mensagens: uma para usuários e outra para desenvolvedores. A mensagem para o usuário deve ser curta e calma. A interna pode incluir a razão técnica, o serviço que falhou e um trace completo (mas apenas nos logs, não na resposta de API mostrada ao usuário final).
Padrões que funcionam bem:
- Diga o que aconteceu em palavras simples: “Não conseguimos salvar suas alterações.”
- Diga o que fazer em seguida: “Tente novamente em um minuto” ou “Verifique os campos destacados.”
- Evite culpabilizar e jargões: não use “invalid payload” ou “unauthorized.”
- Use o mesmo tom em todo lugar para que os erros pareçam familiares, não assustadores.
Códigos de erro ajudam, mas trate-os como identificadores para suporte, não enigmas. Se ajudar o suporte, mostre um código curto e estável (por exemplo, “Erro: AUTH-102”) e mantenha-o consistente ao longo do tempo.
Exemplo: cadastro falha porque o banco de dados expirou. Uma mensagem segura para o usuário é: “Não conseguimos criar sua conta agora. Por favor, tente novamente.” Seus logs internos podem registrar: “DB timeout on users_insert, requestId=...”.
Se você herdou um backend gerado por IA, essa separação costuma faltar. FixMyMess frequentemente vê exceções cruas retornadas aos usuários. Uma das primeiras correções é mover o detalhe técnico para os logs enquanto mantém a mensagem UI clara e consistente.
Mapear erros do servidor para estados de UI (uma tabela simples que funciona)
Usuários não pensam em códigos de status. Eles pensam em resultados: “Posso consertar isso”, “Preciso entrar de novo” ou “Algo está fora do ar”. Escolha um pequeno conjunto de estados de UI e mapeie cada falha para um deles.
Um mapeamento simples que você pode reutilizar
Use o mesmo mapeamento em web, mobile e ferramentas administrativas para que o comportamento permaneça consistente.
| O que aconteceu | Código típico | Estado da UI | O que a UI deve fazer |
|---|---|---|---|
| Requisição inválida (sua app enviou algo errado) | 400 | Entrada corrigível | Destaque o campo ou mostre uma mensagem clara. Não sugira retry. |
| Não logado / sessão expirada | 401 | Re-autenticação necessária | Envie para login, mantendo o trabalho do usuário quando possível. |
| Logado, mas sem permissão | 403 | Sem permissão | Explique que o acesso está bloqueado; ofereça “contatar admin” ou trocar de conta. |
| Não encontrado | 404 | Recurso ausente | Mostre “não encontrado” e ofereça navegação de volta. |
| Conflito (já existe, versão incompatível) | 409 | Resolver conflito | Ofereça atualizar, renomear ou “tentar de novo” após sincronizar. |
| Validação falhou | 422 | Entrada corrigível | Mostre mensagens por campo e mantenha o estado do formulário. |
| Limitado por taxa | 429 | Esperar e tentar | Diga para aguardar, desative o botão brevemente e então permita retry. |
| Bug/queda do servidor | 500 | Falha temporária | Peça desculpas, permita retry e mostre opção de suporte. |
Falhas de rede e timeouts são separadas de respostas do servidor. Trate-as como “offline/conexão instável”: mantenha o usuário na mesma tela, mostre um botão de retry e evite afirmar “sua senha está errada” quando a requisição sequer foi completada.
Uma regra prática: se o usuário pode consertar, mantenha-o no contexto (o formulário permanece preenchido). Se não pode, mude para um estado seguro (re-login, leitura apenas ou contato com suporte).
Passo a passo: implemente erros consistentes sem reescrever tudo
Você não precisa reconstruir toda a API para melhorar os erros. Adicione uma camada fina e consistente em cima do que já existe.
Comece decidindo um pequeno conjunto de códigos de erro que vocês vão suportar em todo lugar. Mantenha definições curtas e claras para que backend e frontend os usem da mesma forma.
Implemente a mudança em um único ponto de cada lado:
- Escolha 8–15 códigos de erro (como
AUTH_REQUIRED,INVALID_INPUT,NOT_FOUND,RATE_LIMITED,CONFLICT,INTERNAL). Escreva o que cada um significa e o que o usuário deve ver. - Adicione um formatador de erros no servidor (middleware/filter) que retorne a mesma forma JSON para todos os endpoints, mesmo quando a exceção for inesperada.
- Adicione um tratador de erros no cliente que leia essa forma e a mapeie para seus estados de UI (erro por campo, banner, toast, página inteira).
- Migre gradualmente: atualize primeiro os fluxos mais usados (login, cadastro, checkout, salvar). Deixe o resto para quando você os tocar.
- Trave a forma com alguns testes para que alterações futuras não quebrem clientes.
Uma abordagem prática de migração é suportar ambos os formatos por um tempo: se um endpoint já retorna JSON customizado, passe-o; caso contrário, envolva-o no novo formato. Isso reduz riscos.
Exemplo: corrija o login primeiro. O servidor para de retornar stack traces crus e passa a retornar um código estável com uma mensagem segura. O cliente vê INVALID_CREDENTIALS e mostra uma mensagem inline perto do campo de senha. Se receber INTERNAL, mostra um banner genérico e oferece retry.
Isso é especialmente útil em bases geradas por IA onde cada endpoint lança erros de forma diferente. Um formatador central e um mapeador central podem fazer o app parecer consistente rapidamente.
Fluxos comuns e como apresentar erros na UI
Pessoas não vivenciam “um erro de API”. Vivenciam um formulário que não envia, uma sessão que expira ou um pagamento que não conclui. Se sua UI tratar toda falha do mesmo jeito, os usuários adivinham, tentam de novo às cegas ou desistem.
Formulários: validação deve parecer local
Quando o servidor diz que um input é inválido, mostre a mensagem ao lado exato desse campo. Um banner no topo dizendo “Algo deu errado” faz o usuário vasculhar e reescrever.
Padrões bons:
- Destaque o campo, mantenha os valores digitados e foque o primeiro input inválido.
- Use linguagem simples como “A senha deve ter pelo menos 12 caracteres” em vez de códigos.
- Se houver um erro geral (por exemplo, “Email já em uso”), mostre próximo ao botão de envio.
Autenticação: seja claro sobre o que o usuário pode fazer
Para sessões expiradas, decida uma regra e siga-a. Se você consegue renovar silenciosamente em background, faça isso uma vez e continue. Se não (refresh falha ou a ação é sensível), mostre um prompt claro: “Faça login novamente para continuar.” Evite largar o usuário em uma tela de erro em branco.
Pagamentos e conflitos precisam de cuidado extra. Diga o que aconteceu e qual ação é segura: “Seu cartão não foi cobrado. Tente novamente.” Para conflitos (alguém alterou os dados), explique o próximo passo: “Este item foi atualizado em outro lugar. Atualize para ver a versão mais recente.”
Uploads de arquivo devem responder a uma pergunta: o que deu certo e o que não deu? Mostre o progresso, mantenha a lista dos arquivos enviados com sucesso e ofereça retry simples para os que falharam. Se reenviar puder criar duplicatas, avise antes do clique.
Cenário exemplo: um erro de login tratado do jeito certo
Um usuário abre seu app após alguns dias e tenta entrar. O token salvo expirou, então o servidor não aceita mais. Isso é normal, mas a experiência depende de como você relata.
Aqui uma resposta simples que segue boas práticas e é segura:
{
"error": {
"code": "AUTH_TOKEN_EXPIRED",
"message": "Your session expired. Please sign in again.",
"requestId": "req_7f3a1c9b2d"
}
}
Use um status HTTP claro (frequentemente 401 Unauthorized para token expirado ou ausente). O code permanece estável para a UI e suporte. A message é escrita para um humano e não expõe detalhes como qual parte da autenticação falhou ou qual biblioteca foi usada.
No cliente, mostre um próximo passo calmo: “Sua sessão expirou. Faça login novamente.” Adicione um único botão que leve à tela de login. Não mostre stack traces, JSON cru ou termos assustadores como “invalid signature.” Se o usuário estava editando algo, preserve o trabalho e só re-autentique quando ele tentar submeter de novo.
Para o suporte, exiba um detalhe curto ou um botão de copiar com o requestId (ou código de erro). Isso dá algo acionável: “Por favor, informe o requestId req_7f3a1c9b2d”, que pode ser rastreado nos logs.
Logging e monitoramento que correspondem aos seus códigos de erro
Se sua API retorna um código de erro claro, mas seus logs não, você perde o principal benefício. A regra mais simples é logar o mesmo error.code que você envia ao cliente, sempre.
Uma boa entrada de log é pequena, porém completa. Capture o suficiente para debugar sem despejar dados sensíveis:
error.codee status HTTP (ex:AUTH_INVALID_PASSWORD, 401)requestId(correlation ID) para seguir uma requisição de ponta a ponta- contexto seguro do usuário (userId, não email ou tokens)
- a tela ou ação (nome da rota, endpoint, método)
- detalhes internos para desenvolvedores (stack trace, erro upstream), mantidos só no servidor
Gere um requestId na borda (ou aceite um do cliente) e retorne-o na resposta. Quando um erro bloqueia um usuário, mostre uma mensagem curta mais “Reference ID: X” para que o suporte encontre o log exato rapidamente.
O monitoramento é principalmente contar e agrupar, mas deve combinar com como a UI funciona. Monitore por código e por tela para identificar padrões como “PAYMENT_DECLINED acontece principalmente no checkout” ou “RATE_LIMITED aumentou após um release.”
Decida antecipadamente o que vai alertar para evitar ruído:
- picos súbitos em erros 500 (falhas de servidor)
- repetidas falhas de autenticação (pode ser bug ou abuso)
- aumento de erros de rate limit (capacidade ou bug de cliente)
- um código de erro dominando um endpoint ou tela específica
Times que consertam backends gerados por IA frequentemente encontram códigos desencontrados e request IDs faltantes. Arrumar isso primeiro acelera todas as correções futuras.
Erros comuns e armadilhas a evitar
Muita UX ruim vem de pequenas inconsistências. Mesmo que cada endpoint esteja “correto” isoladamente, o produto parece aleatório quando erros são bagunçados ou inseguros.
Armadilhas comuns:
- Retornar formas de erro diferentes em endpoints distintos. O frontend vira uma coleção de casos especiais (
messageaqui,errorali,errors[0]em outro lugar). - Usar o texto da mensagem como “código”. Funciona até alguém editar a redação por clareza, tom ou tradução, aí a lógica da UI quebra.
- Vazamento de stack traces, trechos de SQL, IDs internos ou valores secretos. Usuários não agem com esses dados, e atacantes podem.
- Tratar todo erro como um toast genérico “Algo deu errado.” Se o usuário pode consertar, diga como. Se não pode, diga o que fazer a seguir.
- Repetir automaticamente ações inseguras. Repetir uma leitura geralmente é seguro. Repetir uma escrita pode criar duplicatas ou cobranças duplas.
Times frequentemente enfrentam esses problemas com backends gerados por IA. No FixMyMess, vemos endpoints com vários formatos e exposição acidental de segredos. Normalmente o ganho rápido é formatar centralmente e remover respostas pontuais.
Checklist rápido antes de lançar
Faça isso antes do release. Captura as pequenas falhas que viram tickets irritados.
Verificações de saída da API
Confirme que todos os endpoints falam a mesma “língua de erro”. Mesmo que a causa varie, a resposta deve parecer familiar ao cliente e ser fácil de logar.
- Cada endpoint retorna a mesma forma de erro no topo (por exemplo:
error.code,error.message,requestId)? - Os códigos de erro são estáveis (não vão mudar semana que vem) e documentados em palavras simples?
- Há sempre uma mensagem segura para o usuário, mais detalhes internos quando necessário (nos logs)?
- Cada erro inclui um
requestIdpara que o suporte encontre rápido?
Verificações de comportamento da UI
Assegure que o app reage de forma consistente. Usuários memorizam padrões.
- O cliente mapeia erros do servidor para um pequeno conjunto de estados de UI (validação, auth requerida, não encontrado, conflito, tentar mais tarde)?
- Cada mensagem evita detalhes internos (stack traces, SQL, nomes de provedores) e dá um próximo passo claro?
- Quando um erro é acionável, a UI aponta para o campo ou passo que precisa ser corrigido?
- Quando não é acionável (servidor caiu, timeout), a UI informa que o problema está do lado do servidor e oferece retry?
Se seu projeto é um protótipo gerado por IA, essas bases costumam faltar ou ser inconsistentes entre endpoints. FixMyMess pode auditar o código e tornar o tratamento de erros previsível sem reescrever tudo.
Próximos passos (e quando pedir ajuda para consertar o código)
Escolha um fluxo crítico e torne-o seu “padrão ouro” primeiro. Login, checkout ou onboarding são boas escolhas porque tocam autenticação, validação e chamadas a terceiros.
Antes de mudar qualquer coisa, reúna cerca de 10 exemplos reais de erro da produção (ou de logs e relatórios de bugs). Reescreva-os para bater com seu novo padrão: mesmos campos, mesma nomenclatura, mesmo nível de detalhe. Isso cria um alvo claro e evita debates intermináveis.
Um caminho prático que costuma funcionar:
- Adicione um formatador compartilhado no servidor que transforme qualquer erro lançado na sua forma padrão.
- Adicione um mapeador compartilhado no cliente que converta essa forma nos estados de UI que vocês suportam (retry, corrigir entrada, entrar de novo, contatar suporte).
- Atualize apenas o fluxo escolhido de ponta a ponta, incluindo testes e alguns “falsos” failures.
- Aplique o padrão endpoint por endpoint em vez de tentar arrumar tudo de uma vez.
- Mantenha um conjunto curto de regras de mensagens (o que usuários podem ver, o que deve ficar interno).
Peça ajuda quando os erros estiverem ligados a problemas mais profundos: fluxos de autenticação quebrados, segredos expostos, riscos de SQL injection ou “funciona localmente mas falha em produção”. FixMyMess (fixmymess.ai) foca em diagnosticar e reparar codebases geradas por IA, incluindo tratamento de erros, fortalecimento de segurança e preparo para deploy.
Se só fizer uma coisa essa semana, torne um fluxo consistente e mensurável. É assim que erros mais claros viram menos tickets de suporte e usuários mais tranquilos.
Perguntas Frequentes
O que toda resposta de erro de API deve incluir?
Um bom padrão inclui um código de erro estável, uma mensagem curta segura para o usuário e um request ID. O código permite que a UI reaja de forma consistente, a mensagem diz ao usuário o que fazer a seguir e o request ID ajuda o suporte a encontrar o registro de log exato.
Devo confiar nos códigos de status HTTP ou em códigos de erro personalizados?
Mantenha os códigos de status HTTP significativos, mas não dependa só deles. Use o status para categorias amplas (autenticação, validação, falha de servidor) e um error.code próprio para casos específicos, assim a UI não precisa adivinhar.
Como faço para que os erros pareçam consistentes em todo o app?
Escolha um pequeno conjunto de estados de UI e mapeie cada código de erro para um deles. Assim, quando o mesmo problema ocorrer em telas diferentes, o app responderá da mesma forma, com o mesmo tom e próximo passo.
Como escrevo mensagens de erro que os usuários realmente entendam?
Explique o que aconteceu em linguagem simples, indique o próximo passo e tranquilize o usuário quando for relevante (por exemplo, se houve cobrança). Evite jargões como “unauthorized” e evite culpar o usuário.
Quais detalhes nunca devem aparecer em erros visíveis ao usuário?
Não mostre stack traces, caminhos internos de arquivos, SQL bruto, segredos, tokens ou nomes detalhados de serviços internos. Esses detalhes confundem usuários e criam risco de segurança; mantenha-os nos logs do servidor vinculados ao request ID.
Qual a melhor maneira de tratar erros de validação em formulários?
Trate validação como “precisa de ação” e mostre as mensagens ao lado dos campos específicos. Mantenha o formulário preenchido, foque o primeiro campo inválido e evite banners genéricos que forçam o usuário a procurar o que ajustar.
Como meu app deve lidar com sessões expiradas (erros 401)?
Para sessões expiradas, exiba um aviso claro para o usuário fazer login novamente e tente preservar o trabalho dele. Use uma regra única em todo o app para que os usuários saibam o que esperar e não mostre textos técnicos assustadores como falhas de token ou assinatura.
Como devo lidar com limites de taxa (429) e tentativas de retry?
Diga ao usuário para esperar brevemente e tentar novamente, e considere um pequeno cooldown na UI para evitar repetições rápidas. Não sugira retry para problemas que o usuário precisa corrigir, como entrada inválida ou falta de permissão.
Quando é seguro reenviar automaticamente uma requisição que falhou?
Considere que retries podem criar duplicatas para operações de escrita, a não ser que você tenha idempotência projetada. Se não for possível garantir segurança, não reenvie automaticamente; ofereça uma opção clara para o usuário reenviar e explique o que acontecerá.
Como posso melhorar o tratamento de erros sem reescrever toda a API?
Comece adicionando um formatador no servidor que force todos os endpoints ao mesmo formato de erro, depois implemente um manipulador no cliente que mapeie esses códigos para estados de UI. Se o backend for inconsistente por ter sido gerado por IA, FixMyMess pode auditar e corrigir exceções expostas, fluxos de autenticação quebrados e respostas instáveis.