Cache e paginação para páginas de lista lentas: padrões práticos
Aprenda cache e paginação para páginas de lista lentas com padrões práticos de paginação por cursor, desenho de chaves de cache e alternativas mais seguras a APIs que "carregam tudo".
Por que páginas de lista ficam lentas à medida que os dados crescem
Uma página de lista normalmente parece OK com 200 linhas, e de repente começa a ficar ruim com 20.000. Usuários veem rolagem lenta, indicadores que nunca param, e filtros que demoram segundos para responder. Às vezes a página pisca um estado vazio porque a requisição expira ou o cliente desiste e renderiza nada.
O problema central é simples: cada registro extra faz o sistema trabalhar mais. O banco de dados precisa encontrar as linhas, ordená-las e aplicar filtros. A API precisa transformá-las em JSON. A rede precisa mover esses dados. Depois o navegador (ou app móvel) precisa parsear, alocar memória e renderizar.
Para onde vai o tempo
À medida que seu conjunto de dados cresce, as lentidões geralmente vêm de uma mistura desses pontos:
- Trabalho no banco de dados: grandes varreduras, joins caros e ordenação de muitos resultados.
- Tamanho do payload: retornar centenas ou milhares de linhas por requisição.
- Custo de renderização: a UI tentando pintar muitos itens de uma vez.
- Consultas repetidas: a mesma lista solicitada várias vezes sem cache.
Ordenação e filtragem têm um custo oculto porque frequentemente forçam o banco a tocar muito mais dados do que você espera. Por exemplo, filtrar por “status = open” é barato com o índice certo, mas “buscar por nome contém” ou “ordenar por última atividade” pode ficar caro rapidamente. Pior ainda, usar paginação por OFFSET (página 2000) pode fazer o banco percorrer milhares de linhas só para chegar à próxima página.
O objetivo não é “deixar rápido uma vez”. O objetivo é tempo de resposta previsível conforme os dados crescem. Isso geralmente significa retornar menos registros por requisição, usar paginação que não fica mais lenta em páginas profundas e armazenar em cache respostas de lista para que visitas repetidas não paguem sempre o custo completo.
Evite endpoints de lista que "carregam tudo"
Uma razão comum para páginas de lista ficarem lentas é uma API que retorna a tabela inteira porque era fácil na fase de protótipo. Frequentemente parece com isto:
GET /api/orders
200 OK
[
{ "id": 1, "customer": "...", "notes": "...", "internalFlags": "...", ... },
{ "id": 2, ... }
]
Isso falha em escala porque multiplica o trabalho em três lugares ao mesmo tempo: o banco precisa escanear e ordenar mais linhas, o servidor precisa construir e enviar um JSON enorme, e o navegador precisa parsear e renderizar uma lista longa. Mesmo que você depois adicione cache e paginação, um endpoint “me dá tudo” ainda é caro de gerar e de enviar.
Mobile e redes instáveis sentem isso primeiro. Uma resposta JSON de 5–10 MB pode ser tolerável em Wi‑Fi do escritório, mas pode expirar em 4G, drenar bateria e fazer o app parecer quebrado. Também torna erros mais difíceis de recuperar: se uma requisição falha, o usuário perde a página inteira em vez de apenas a próxima fatia.
Aqui vai uma regra simples para se manter honesto: envie apenas o que o usuário pode ver agora. Isso geralmente significa uma página pequena (por exemplo, 25–100 linhas) e apenas os campos necessários para a visão da lista.
Quando equipes nos trazem um painel administrativo gerado por AI, muitas vezes encontramos endpoints de lista retornando registros completos (incluindo campos de texto grandes) sem limite. A vitória rápida é retornar uma forma compacta de “item de lista” e buscar detalhes somente quando alguém abre uma linha. Essa mudança sozinha pode reduzir o tempo de consulta, o tamanho da resposta e o tempo de renderização do cliente sem mexer no design da UI.
Paginação por cursor em linguagem simples
Muitos endpoints de lista começam com paginação por offset: “me dê a página 3” significa “pule as primeiras 40 linhas e retorne as próximas 20.” Parece simples, mas fica mais lento conforme sua tabela cresce porque o banco ainda precisa pular todas as linhas ignoradas.
A paginação por offset também fica estranha quando os dados mudam enquanto alguém está navegando. Se linhas novas são inseridas ou antigas deletadas, a próxima página pode mostrar duplicatas ou pular itens. Você pediu “página 3”, mas “página 3” não é algo estável.
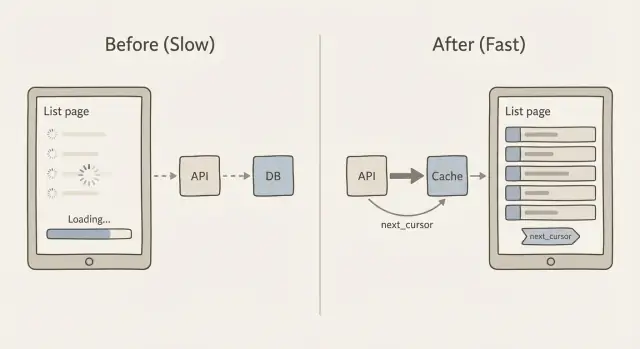
A paginação por cursor resolve isso usando um marcador em vez de um número de página. O cliente diz: “me dê os próximos 20 itens depois deste último item que vi.” Esse valor “depois” é o cursor. Esta é a ideia central por trás de cache e paginação para páginas de lista lentas: mantenha cada requisição pequena, previsível e rápida.
O que o cursor realmente é
Um cursor costuma ser um pequeno pacote de valores do último registro na resposta atual. Para torná-lo estável, sua lista precisa de uma ordem de ordenação consistente que nunca dê empates. Um padrão comum é ordenar por created_at com id como desempate (por exemplo: mais recentes primeiro, e se duas linhas tiverem o mesmo timestamp, ordenar por id).
Essa ordenação estável importa porque garante que “depois deste item” sempre aponte para exatamente um lugar na lista.
Como next_cursor funciona
Conceitualmente, o servidor retorna:
- Os itens desta requisição (digamos 20)
- Um
next_cursorque representa o último item desse conjunto
Se não houver mais itens, next_cursor vem vazio ou ausente. O cliente guarda e envia de volta para buscar a próxima fatia. Sem contar páginas, sem grandes saltos, e bem menos surpresas quando a lista está mudando.
Passo a passo: implementar um endpoint paginado por cursor
A paginação por cursor é o padrão de trabalho por trás de cache e paginação para páginas de lista lentas. Mantém páginas estáveis e rápidas, mesmo quando novas linhas são adicionadas.
1) Escolha uma ordenação estável
Escolha uma ordem que nunca mude para uma determinada linha. Uma escolha comum é created_at desc, id desc. O desempate por id importa quando muitas linhas compartilham o mesmo timestamp.
2) Defina as formas de requisição e resposta
Mantenha a requisição pequena e previsível: um limit, um cursor opcional e quaisquer filtros que você já suporte (status, proprietário, busca).
Uma forma simples de resposta é:
{
"items": [/* results */],
"next_cursor": "opaque-token",
"has_more": true
}
3) Codifique e decodifique o cursor com segurança
Não coloque SQL cru ou um offset de banco de dados no cursor. Faça dele um token opaco que contenha somente o que você precisa para retomar a paginação, como o created_at e id do último item.
Um formato prático é JSON codificado em base64, opcionalmente assinado (para que clientes não possam adulterá‑lo). Exemplo de payload dentro do token: { "created_at": "2026-01-10T12:34:56Z", "id": 123 }.
4) Consulte usando o cursor (e lide com inserções)
Com created_at desc, id desc, sua query da próxima página deve buscar linhas “antes” do cursor:
created_at < cursor_created_atOR (created_at = cursor_created_atANDid < cursor_id)
Isso mantém a paginação estável mesmo se novos itens forem inseridos no topo enquanto o usuário navega.
5) Adicione guardrails
Defina um limite padrão (como 25) e um máximo rígido (como 100). Valide o cursor, limit e filtros. Se o cursor for inválido, retorne um erro 400 claro. Em muitos endpoints gerados por AI que vemos, esses guardrails frequentemente faltam, e por isso páginas de lista desmoronam sob tráfego real.
Desenhando chaves de cache para respostas de lista
Fazer cache de páginas de lista parece fácil até você lembrar quantas “listas diferentes” seu app pode produzir. Um endpoint pode suportar busca, filtros, opções de ordenação, tamanhos de página diferentes e paginação por cursor. Se sua chave de cache ignorar um desses inputs, você corre o risco de mostrar resultados errados para a pessoa errada.
Uma boa chave de cache é simplesmente uma impressão única da resposta exata da lista. Inclua tudo que muda quais linhas aparecem ou em que ordem. Tipicamente isso significa:
- Escopo: público vs por usuário vs por organização (e o id real)
- Inputs de consulta: filtros, texto de busca e ordenação
- Paginação: cursor (ou marcador de “primeira página”) e limit
- Versão: uma tag de esquema ou “list-v2” para mudar formatos com segurança
Mantenha a chave legível. Um padrão simples que funciona bem é:
resource:scope:filters:sort:cursor:limit
Por exemplo: tickets:org_42:status=open|q=refund:created_desc:cursor=abc123:limit=25. Normalize os inputs para que diferentes grafias não criem misses inúteis (remova espaços em branco, ordene parâmetros de filtro e use um separador consistente).
Decida o que você está cacheando. Muitas equipes cacheiam apenas a primeira página porque ela é a mais acessada e mais beneficiada por um TTL curto. Cachear todas as páginas também ajuda, mas explode o número de chaves e aumenta o trabalho de invalidação quando os dados mudam.
Não faça cache quando for provável que esteja errado mais vezes do que útil: listas altamente personalizadas (como “recomendado para você”), listas que mudam a cada poucos segundos, ou listas que incluem checagens de permissão difícieis de codificar com segurança na chave.
Se estiver trabalhando em cache e paginação para páginas de lista lentas em um app gerado por AI, atenção a endpoints que tratam o “cursor” como opcional e voltam a “retornar tudo”. Isso é um problema comum que encontramos e consertamos apertando padrões de paginação e fazendo as chaves de cache incluir o contexto completo da query.
Mantendo listas em cache frescas sem complicar demais
A maioria das páginas de lista não precisa de frescor perfeito e instantâneo. Precisam parecer rápidas e ser “recentes o suficiente” para o objetivo do usuário. Essa é a chave para fazer cache e paginação funcionarem sem transformar invalidação de cache em um segundo produto.
TTL vs invalidação baseada em eventos (em palavras simples)
Um TTL (time to live) é a opção mais simples: armazene a lista por, digamos, 30–120 segundos e depois atualize. É fácil e confiável, mas pode mostrar dados ligeiramente antigos.
Invalidação por evento tenta ser exata: quando um registro muda, você deleta as listas em cache afetadas imediatamente. Pode ser muito fresco, mas complica porque uma mudança pode afetar muitos filtros e ordens.
Um meio-termo prático é stale-while-revalidate: sirva a lista em cache mesmo que esteja um pouco velha e então atualize em segundo plano. Usuários recebem páginas rápidas e o cache se cura rapidamente após mudanças.
Invalidação direcionada que continua gerenciável
Em vez de “deletar tudo”, invalide apenas o que você consegue descrever claramente:
- Por usuário ou tenant (somente as listas deles)
- Por tipo de recurso (orders vs customers)
- Por grupo de filtros (status=open, tag=vip)
- Por “versão de coleção” (um contador que você incrementa nas escritas)
A última opção costuma ser a mais simples: inclua collection_version na chave de cache. Quando algo muda, incremente a versão e entradas antigas deixam de ser usadas.
Carimbos de cache (cache stampedes) acontecem quando muitas requisições perdem o cache ao mesmo tempo e todas o reconstroem. Duas proteções simples ajudam:
- Adicione jitter no TTL (aleatório +/- 10–20%)
- Coalescência de requisições (um construtor, os outros esperam)
- Sirva stale por uma janela curta de graça
Por fim, decida qual consistência você realmente precisa. Para a maioria de páginas administrativas e feeds, “atualizações aparecem em 1–2 minutos” é suficiente. Para movimentação de dinheiro ou permissões, não faça cache na lista, ou mantenha TTL muito curto e valide na página de detalhe.
Padrões de paginação no cliente que permanecem rápidos
A maioria de telas de lista tem um padrão claro de tráfego: as pessoas caem na página 1 muito mais do que em qualquer outra. Faça cache da primeira página no cliente (memória ou local storage) com um TTL curto e mostre-a imediatamente enquanto você atualiza em segundo plano. Isso sozinho resolve a sensação de “tela em branco” que faz a lista parecer lenta.
Quando usar paginação por cursor, trate o cursor como parte da identidade da página. Mantenha um pequeno mapa tipo cursor -> rows para que voltar não dispare novas requisições e sua UI continue responsiva mesmo em redes instáveis.
Prefetch da próxima página ajuda, mas só se feito com cuidado. Uma abordagem segura é prefetch quando o usuário está perto do fim (ou depois de pausar a rolagem) e cancelar a requisição se ele mudar filtros ou ordenação.
- Prefetch apenas uma página à frente
- Debounce do gatilho (por exemplo, 200–400ms)
- Bloquear prefetch enquanto uma requisição estiver em andamento
- Não prefetch para filtros caros (como busca full-text)
- Pare de prefetch quando a aba estiver oculta
Estados de carregamento importam mais do que se imagina. Use um indicador de carregamento “suave” (mantenha as linhas existentes visíveis) e um botão de retry óbvio para falhas. No retry, anexe resultados somente depois de confirmar que pertencem à mesma query (mesmos filtros, ordenação e cursor), caso contrário você terá linhas duplicadas ou misturadas.
Deduplicação no cliente é sua rede de segurança. Sempre mescle linhas por um ID estável (como id), não por índice de array ou timestamp. Se receber a mesma linha duas vezes, substitua no lugar para que a lista não salte.
Scroll infinito nem sempre é melhor. Pode ser pior para telas administrativas onde as pessoas precisam saltar, ordenar e comparar. Se usuários frequentemente dizem “eu estava na página 7”, use navegação paginada com tamanho de página claro e reserve scroll infinito para feeds onde a posição exata não importa. Esse é um conserto comum que aplicamos ao reparar UIs geradas por AI que acidentalmente martelam a API e ficam lentas.
Noções básicas de banco de dados e payload que ajudam o cache
Cache ajuda, mas não apaga queries lentas. Uma resposta em cache ainda precisa ser gerada ao menos uma vez, e misses de cache acontecem mais do que se espera (novos filtros, novos usuários, chaves expiradas, deploys). Se a query no banco for frágil, o sistema todo fica instável.
Índices são o primeiro lugar a olhar. Para páginas de lista, o padrão vencedor é simples: seu índice deve casar com como você filtra e como você ordena. Se seu endpoint faz WHERE status = 'open' e ORDER BY created_at DESC, o banco deve ter um caminho que suporte ambos.
Uma regra prática para queries de lista:
- Indexe as colunas que você usa em
WHEREcom mais frequência. - Inclua a coluna que você ordena (
ORDER BY) no mesmo índice quando possível. - Se você sempre filtra por tenant ou usuário, essa coluna geralmente deve vir primeiro no índice.
- Prefira chaves de ordenação estáveis (tempo de criação, id) para que paginação e cache permaneçam previsíveis.
- Verifique os índices depois que adicionar novos filtros, não meses depois.
Próximo: pare de enviar dados extras. Muitas páginas lentas são lentas porque movem muito JSON, não porque o banco está morrendo. Evite SELECT *. Escolha os campos que você realmente mostra na tabela. Se a UI só precisa de id, name, status e updated_at, retorne apenas esses. Você ganha queries mais rápidas, payloads menores e maiores taxas de hit no cache porque respostas ficam mais baratas de armazenar e servir.
Tome cuidado com ordenação em campos computados, como "full_name" (first + last), "last_activity" de uma subquery, ou "relevance" de uma fórmula customizada. Esses costumam forçar scans, planos com muitos joins ou ordenação grande em memória. Quando possível, pré-compute o valor em uma coluna real ou ordene por um campo mais simples e calcule o valor fancy na UI.
Antes de optimizar mais, meça dois números:
- Tempo de query (p50 e p95, não só uma execução)
- Tamanho do payload para uma única página
- Linhas examinadas vs linhas retornadas
- Taxa de hit do cache para o endpoint de lista
- O filtro + ordenação mais lentos que os usuários realmente clicam
Isso é especialmente comum em apps gerados por AI que vemos: endpoints de lista “funcionam” em demo, mas quando dados reais chegam, índices faltando e payloads grandes fazem o cache parecer "não estar funcionando". Conserte os básicos primeiro, então cache vira um multiplicador em vez de um band-aid.
Exemplo: consertando uma página de lista administrativa lenta em um app em crescimento
Uma história comum: um dashboard admin começou como protótipo gerado por AI. Funcionava com 200 linhas. Seis meses depois tem 200.000, e a lista “Users” expira ou demora 10–20 segundos para carregar. Pessoas atualizam, filtros parecem aleatórios e a CPU do banco dispara.
A versão ruim normalmente parece com isto: o cliente chama um endpoint que retorna tudo (ou usa paginação por offset com offsets enormes), a resposta inclui campos pesados (profiles, settings, audit history) e cada scroll dispara outra query cara. Não há cache, então a mesma primeira página é recalculada para cada admin.
Aqui está um conserto prático para cache e paginação em páginas de lista lentas que mantém o comportamento previsível.
O que mudamos
Mantivemos a UI igual, mas mudamos o contrato da API:
- Use paginação por cursor: retorne
items,nextCursore sempre solicite comlimit. - Ordene por uma chave estável (por exemplo,
created_atmaisid) para que cursors não pulem ou repitam. - Cacheie apenas a primeira página para visões comuns (como “All users, newest first”), porque essa página é a mais requisitada.
- Restrinja filtros a campos seguros e indexados (status, role, created date). Rejeite buscas por “contains” em colunas de texto grandes a menos que tenha suporte de busca.
- Reduza o payload: a lista retorna somente o que a tabela precisa. Detalhes carregam na página do usuário.
Uma forma de resposta simples:
{ "items": [{"id": "u_1", "email": "[email protected]", "createdAt": "..."}], "nextCursor": "createdAt:id" }
O que os administradores notaram
A primeira tela aparece rápida e a rolagem fica estável porque cada requisição é limitada. Atualizar a lista para de martelar o banco porque a primeira página vem do cache. Filtros parecem consistentes porque a ordenação e regras de cursor são claras.
Para liberar com segurança, coloque o novo endpoint atrás de uma feature flag para admins internos primeiro, compare lado a lado e registre erros de cursor (duplicatas, linhas faltando). Se você herdou um protótipo quebrado de ferramentas como Bolt ou Replit, times como FixMyMess costumam começar com uma auditoria rápida para achar endpoints “carregam tudo” e as queries que devem ser consertadas primeiro.
Erros comuns e armadilhas a observar
A maioria das correções de “página de lista lenta” falha por motivos simples: paginação pouco confiável, cache inseguro ou endpoint abusável. Se estiver trabalhando em cache e paginação para páginas de lista lentas, estas são as armadilhas que causam mais dor depois.
Paginação por offset é a armadilha clássica. Parece OK com poucos dados, mas se você ordenar por um campo não único (como created_at), novas linhas podem deslizar para o meio enquanto o usuário navega. Isso causa duplicatas, itens pulados ou uma página que “salta”. Paginação por cursor evita isso, mas só se sua ordem de ordenação for estável (por exemplo: created_at mais um id único como desempate).
Cursors em si podem ser um problema de segurança e corretude. Se você colocar IDs crus, fragmentos SQL ou expressões de filtro dentro do cursor, corre o risco de usuários adivinharem valores, quebrar a decodificação ou forçar queries caras. Um padrão mais seguro é: codifique só os últimos valores de ordenação vistos e valide-os no servidor antes de consultar.
Cache traz outra classe de erros. O maior é esquecer escopo. Se sua chave de cache não incluir usuário, tenant, papel e filtros, você pode vazar dados entre contas. Também preste atenção na história de “frescor”: mudanças de status e deleções são as primeiras coisas que usuários notam quando listas em cache ficam defasadas.
Um exemplo rápido: uma página admin “Orders” mostra pedidos pagos e pendentes. Se a chave de cache ignorar o filtro status=pending, um admin pode ver uma lista misturada que parece errada, e o cache pode até ser compartilhado com visões de não-admin.
Aqui estão cinco guardrails que evitam a maioria dos incidentes:
- Sempre adicione um
limitmáximo e aplique no servidor. - Use uma ordenação estável com um desempate único.
- Faça cursors opacos e valide valores decodificados.
- Construa chaves de cache a partir de escopo do usuário + filtros + ordenação + tamanho de página.
- Decida quanto tempo dados defasados são aceitáveis e invalide ou reduza o TTL para listas de alta mudança.
Se você herdou um app gerado por AI com paginação instável, chaves de cache inseguras ou endpoints sem limites, FixMyMess pode auditar o caminho de código e apontar os modos de falha exatos antes de você liberar.
Checklist rápido e próximos passos
Use isto como revisão final quando estiver melhorando cache e paginação em páginas de lista lentas. Pequenos detalhes aqui decidem se sua lista fica rápida com 1.000 linhas e com 10 milhões.
Construa com segurança (API e cache)
- Defina um limite máximo rígido (e um padrão sensato) para que ninguém peça 50.000 linhas por acidente.
- Use ordenação estável (por exemplo, created_at + id) para que a paginação não remexer itens entre requisições.
- Mantenha o cursor opaco. Trate-o como um token, não algo que o cliente edita.
- Confirme que a query usa índices que casam com seus filtros e ordenação.
- Escopo as chaves de cache para o que muda a resposta: usuário ou tenant, filtros, ordenação, tamanho de página e cursor.
Cache funciona melhor quando a primeira página é fácil de reutilizar, então comece por aí. Escolha um TTL que combine com a frequência com que a lista realmente muda e adicione proteção básica contra stampedes (lock, coalescência de requisições ou servir stale enquanto revalida) para que picos de tráfego não derretam seu banco.
Prove que funciona (testes e operação)
- Crie novos itens enquanto estiver navegando e confirme que não vê duplicatas ou itens faltando.
- Mude filtros no meio da rolagem e confirme que o cliente reseta o estado em vez de misturar páginas antigas e novas.
- Simule rede lenta e verifique que o cliente deduplica resultados e ignora respostas fora de ordem.
- Monitore tempo de query, taxa de hit do cache, taxa de erro e tamanho do payload após o lançamento.
- Logue os endpoints de lista mais lentos com seus filtros para que você possa mirar os verdadeiros culpados.
Próximos passos: se seu protótipo gerado por AI tem endpoints de lista lentos ou quebrados, FixMyMess pode rodar uma auditoria de código gratuita para identificar problemas de paginação, cache e segurança antes de você liberar.