Verificações sintéticas para cadastros quebrados: detecte falhas cedo
Verificações sintéticas para cadastros quebrados identificam falhas no login, onboarding e checkout a partir da internet pública e alertam antes que usuários reais cancelem.
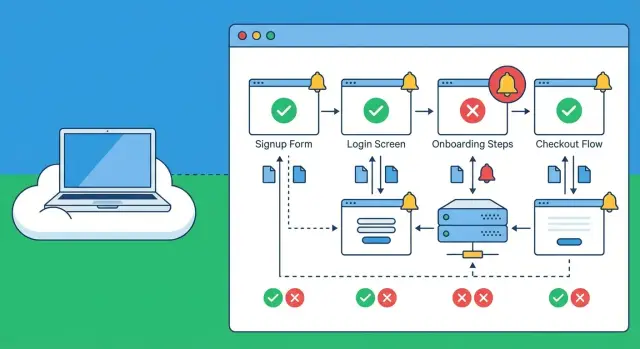
Por que cadastros quebrados passam despercebidos e como os usuários sentem isso
Um cadastro quebrado raramente parece um grande apagão. Para uma pessoa real, parece que o site simplesmente não funciona: um botão que não faz nada, um spinner que não para, um vago “Algo deu errado” ou um formulário que é enviado e então, silenciosamente, a redireciona de volta para a tela de login.
Às vezes a interface diz “Verifique seu email”, mas o email nunca chega. Ou chega tarde demais, o link expira e o usuário desiste. No mobile, um passo extra (como um CAPTCHA que não carrega) pode ser o suficiente para matar o fluxo.
Essas falhas passam despercebidas porque as equipes geralmente testam o caminho feliz dentro do próprio ambiente. Verificações internas podem confirmar que o servidor está no ar e que o banco responde, mas isso não garante que a jornada funcione desde a internet pública. Problemas que costumam aparecer apenas externamente incluem:
- Problemas de CDN ou cache servindo um bundle JavaScript antigo
- Provedores terceiros de autenticação ou email bloqueados ou limitados por região
- Cookies, redirecionamentos ou CORS mal configurados que se comportam diferente fora da rede
- Um deploy que funciona para administradores logados mas quebra contas novas
O impacto no negócio é direto e rápido. Um cadastro quebrado significa cliques pagos sem conversão, carrinhos abandonados no checkout e mais tickets de suporte começando com “Não consigo criar conta.” Pior: muitas pessoas não reclamam. Elas simplesmente vão embora.
Verificações sintéticas para cadastros ajudam porque atuam como um cliente real. Elas executam repetidamente os mesmos passos (cadastro, verificação, primeiro login) e alertam quando a jornada falha. Não substituem feedback real de usuários, analytics ou suporte, mas reduzem o tempo entre “quebrou” e “você sabe que quebrou”.
O que são verificações sintéticas (e o que não são)
Verificações sintéticas são scripts agendados que se comportam como um usuário real. Eles abrem seu site ou app, clicam nos passos-chave, preenchem dados e confirmam um “momento de sucesso” (por exemplo: uma nova conta chega a uma página de boas‑vindas, ou o primeiro painel carrega). Pense nelas como um cliente confiável e repetível que aparece a cada poucos minutos e relata o que aconteceu.
“De fora da sua rede” significa que a verificação roda pela internet pública, não pelo Wi‑Fi do escritório, VPN ou rede interna em nuvem. Isso importa porque muitas falhas de cadastro aparecem só no mundo real: problemas de DNS, borda de CDN, cookies bloqueados, roteamento regional ou scripts de terceiros que se comportam diferente fora do ambiente.
Checks básicos de uptime respondem a uma pergunta: “A homepage responde?” Verificações sintéticas para cadastros vão além e seguem toda a jornada fim a fim. Um site pode estar “no ar” enquanto o cadastro está silenciosamente quebrado por um erro JavaScript, uma resposta de API errada ou um segredo expirado.
Verificações sintéticas são boas para capturar problemas de UI (botões não clicáveis, formulários travados, páginas que não carregam), falhas de API (500s, bugs de validação, autenticação quebrada), outages de terceiros (pagamentos, captcha, scripts que derrubam a página) e etapas lentas que estouram timeout.
O que elas não conseguem provar sozinhas é se um humano recebeu e usou um link de email. Você pode checar que um email foi solicitado, mas a entrega na caixa varia. Uma abordagem comum é validar o evento de backend (“email de verificação criado”) e tratar a entrega em caixa como uma checagem separada.
Escolha as jornadas que importam: cadastro, onboarding, checkout
A maioria das equipes tenta monitorar tudo e acaba não monitorando nada bem. Comece escolhendo de 2 a 4 jornadas do usuário que afetam diretamente receita ou carga de suporte. Para a maioria dos produtos, verificações de cadastro dão retorno mais rápido porque falhas pequenas (um email faltando, um spinner travado) podem reduzir novos usuários pela metade.
Escolha jornadas que representem uma pessoa real tentando se tornar cliente, não caminhos administrativos internos ou telas raramente usadas. Um conjunto inicial sólido é:
- Criar conta (email ou social)
- Login (incluindo uma tentativa de “senha errada”)
- Onboarding (primeira ação relevante, como criar um workspace)
- Checkout (do carrinho até o recibo)
- Redefinição de senha (solicitar e confirmar)
Para cada jornada, escreva um sinal de sucesso que você possa verificar. Não confie em “página carregada”. Use um momento claro que prove que o fluxo funcionou, como um redirecionamento para a página de boas‑vindas, uma mensagem visível de “Você está dentro” ou uma tela de recibo com número de pedido.
Decida onde o script para. O melhor ponto de parada é o primeiro momento-chave de sucesso, não todos os casos de borda. Uma verificação de cadastro que confirma a tela de boas‑vindas costuma ser suficiente. Deixe casos mais profundos (vários planos, cupons, formatos de endereço) para depois, ou você vai gerar alertas ruidosos.
Faça o script se comportar como um visitante novo: sessão limpa do navegador, sem cookies e tamanho de viewport normal. É aí que aparecem problemas ocultos, como redirecionamentos de auth quebrados, problemas com cookies de terceiros ou um passo de onboarding que só falha quando o storage local está vazio.
Exemplo: você testa checkout estando logado como um usuário antigo, mas novos usuários precisam verificar email primeiro. Seu script sintético deve seguir o caminho de usuário novo, senão vai perder a falha.
Dados e contas de teste: mantenha realista sem ser arriscado
Verificações sintéticas só ajudam se se comportarem como um cliente real. Isso significa telas reais, emails reais, redirecionamentos reais e às vezes até um passo de pagamento real. Mas nunca use dados reais de clientes para isso.
Comece com usuários de teste dedicados. Deixe‑os óbvios (como synth_signup_01) e marque‑os no banco de dados, se possível, para que suporte e analytics não os confundam com clientes reais. Use endereços de email apenas para teste e um método de pagamento sandbox do seu provedor, ou um produto/valor de baixo risco se precisar rodar em produção.
Email e códigos de uso único são o maior ponto de dor. Você tem algumas opções seguras: mantenha uma caixa de teste que o script possa ler, permita um código de teste conhecido apenas para usuários sintéticos, ou adicione um caminho de verificação separado que funcione só com uma flag sintética. O objetivo é testar o mesmo fluxo que os clientes usam, sem transformar seu sistema de auth em alvo fácil.
Staging é bom para checagens rápidas, mas muitas equipes também rodam verificações de cadastro em produção porque é lá que acontecem falhas reais: limites de taxa, outages de terceiros, redirecionamentos mal configurados ou um segredo expirado. Se monitorar em prod, mantenha o script de baixo impacto: uma execução, um usuário, uma compra (ou uma autorização $0) e limpe depois.
Credenciais agora fazem parte do produto, então trate‑as assim:
- Armazene credenciais de teste em um gerenciador de segredos, não no script ou repo.
- Use o menor nível de acesso possível (uma role de teste, não um admin).
- Rode senhas, chaves de API e cartões de teste em uma programação de rotação.
- Restrinja o acesso da caixa de teste ao sistema de monitoramento apenas.
- Registre todo login sintético para detectar abuso.
Onde e com que frequência rodar checagens fora da sua rede
Se seu script sintético roda apenas do IP do escritório (ou na mesma nuvem onde seu app vive), ele pode perder falhas que usuários reais veem. Rode checagens pela internet pública, de mais de um lugar, para pegar problemas causados por roteamento, DNS, borda de CDN ou outages regionais de terceiros.
Uma configuração simples é 2 a 4 regiões que combinem com onde seus usuários estão. Se a maioria vem dos EUA e Europa, rode uma verificação de US East, uma de US West e uma da Europa Ocidental. Isso ajuda a detectar problemas de “funciona pra mim”, como um provedor de auth que dá timeout só em uma região.
Cadência: com que frequência é “suficiente”?
Frequência é um trade‑off entre velocidade, ruído e custo. Escolha uma cadência por jornada, não um único ritmo para tudo:
- A cada 1 minuto: checkout e pagamentos, ou cadastros de alto tráfego durante um lançamento
- A cada 5 minutos: cadastro e login core para um produto estável
- A cada 15 minutos: etapas de onboarding que mudam raramente
- Após deploys: execute uma rodada extra imediatamente após release
Deixe falhas fáceis de ler definindo timeouts por etapa. Use limites separados para carregamento de página, resposta de API e tela de confirmação. Se “Criar conta” nunca mostrar a mensagem de sucesso dentro de 20 segundos, o alerta deve dizer isso claramente, e não apenas “teste falhou”.
Capture provas quando quebrar
Quando algo falha às 3h, você quer evidência, não suposições. Configure suas verificações para salvar uma captura de tela no passo de falha, logs do console e erros de rede, a etapa exata e o timeout que disparou, e um pequeno trace das requisições chave (signup, troca de token, confirmação).
Passo a passo: construa um script sintético que realmente reflita a realidade
Uma verificação útil lê como uma história de usuário real. Finja que você é um visitante de primeira vez com conexão lenta, sem cookies, vindo de fora da rede do escritório. Seu script deve seguir esse caminho, não o caminho que você já decorou.
Uma ordem prática de construção
Comece simples e vá apertando até que o script flagre as falhas que os clientes enfrentam.
- Escreva a jornada em passos simples primeiro, depois automatize: abra a página pública, espere carregar, preencha os mesmos campos que o usuário vê, envie e confirme que chegou ao estado esperado (por exemplo, “Bem‑vindo” mais um cabeçalho logado).
- Use seletores estáveis e esperas previsíveis. Prefira atributos que você controla (como
data-testid) em vez de IDs aleatórios ou cadeias CSS frágeis. Espere por um elemento específico que sinalize que a página está pronta, não por um sleep fixo. - Valide o resultado certo, não apenas “não travou”. Uma tela de sucesso pode ser forjada por bugs no front end. Quando possível, confirme também a realidade do servidor, como “registro de usuário criado” ou “cookie de sessão definido” via checagem de API.
- Adicione retries com cuidado. Repetir um carregamento de página é aceitável. Repetir uma ação de negócio (criar conta, submeter um pedido, cobrar um cartão) pode criar duplicatas e esconder erros reais.
- Capture evidência na falha. Salve screenshot, logs do console e erros de rede para que quem está de plantão veja o que quebrou sem reproduzir localmente.
Torne resistente a falsos positivos
Verificações de cadastro sintéticas frequentemente falham porque testam só a UI. Um exemplo comum: o formulário é enviado, você vê uma mensagem de sucesso, mas a autenticação está quebrada e a próxima página volta ao login. Adicione um passo final “posso acessar a página da conta?” para provar que a sessão realmente funciona.
Alertas e triagem: detectar falhas sem gerar ruído
Alertas devem responder duas perguntas rápido: “Isso é real?” e “Quem precisa agir?” Se não responderem, as pessoas começam a ignorar e o próximo outages real passa batido.
Comece definindo thresholds que batam com a instabilidade normal da internet. Uma execução isolada pode ser um pico (provedor temporário, perda momentânea). Falhas consecutivas costumam indicar uma quebra real no fluxo.
Uma abordagem simples que funciona:
- Disparar alerta em 2 falhas consecutivas da mesma localização
- Criar ticket ou mensagem na primeira falha se for checkout ou pagamento
- Auto‑resolver somente após 1 a 2 execuções bem‑sucedidas
- Adicionar um resumo diário de “quase falhas” para ver padrões sem ruído
Roteamento importa tanto quanto detecção. Um passo de cadastro quebrado pode ser responsabilidade de produto (texto ou consentimento), engenharia (API ou auth) ou um parceiro (deploy recente). Se você não sabe quem é dono de cada etapa, decida isso primeiro e documente.
Deixe alertas acionáveis incluindo contexto que responda às primeiras perguntas: qual etapa falhou, o que o script esperava, o que viu em vez disso, de onde rodou e quando funcionou por último. Inclua última hora de sucesso e um trecho curto do erro (código de status, texto da UI ou mensagem de validação). “Cadastro falhou” é ruído. “Falhou na verificação de email: campo para código não aparece; último sucesso 03:12 UTC; US‑East” é útil.
Mantenha um runbook curto para triagem consistente:
- Reexecutar uma vez de outra localização para confirmar
- Checar deploys recentes, feature flags e status de terceiros (email/SMS, pagamentos)
- Tentar o mesmo fluxo em uma janela anônima com conta de teste
- Capturar a etapa exata e o texto do erro antes de escalar
- Escalar ao responsável com todo o contexto anexo
Erros comuns que tornam verificações sintéticas inúteis (ou perigosas)
Verificações sintéticas só ajudam se se comportarem como um cliente real e falharem pelos mesmos motivos. Alguns atalhos comuns podem deixar checks “verdes” enquanto usuários estão presos, ou pior, causar dano real em produção.
Um erro fácil é testar só o caminho feliz. Um cadastro que termina em “Conta criada” pode ainda estar quebrado se a verificação por email nunca chegar, o link de verificação falhar ou o primeiro login após a verificação der erro. O mesmo vale para reset de senha. Muitas equipes não scriptam isso, então nunca notam que o template de email de reset está quebrado ou o token expira instantaneamente.
Outra armadilha é rodar checks apenas dentro da sua rede. Se o script roda na sua VPC, ele pode contornar exatamente as coisas que os clientes dependem: resolução DNS, comportamento de CDN, regras de WAF, geofencing ou um redirect mal configurado na borda. O app pode parecer ok internamente enquanto usuários reais levam timeouts, requests bloqueadas ou assets em cache ruins.
Scripts instáveis também são autoinfligidos. Se a verificação clica em um botão que se move, espera um spinner adivinhando tempos, ou mira um seletor que muda a cada build, você tem fadiga de alertas. Espere por sinais estáveis da página (um cabeçalho claro ou uma resposta de API conhecida) e escolha seletores feitos para testes.
Cuidado com retries “úteis”. Repetir um submit pode criar usuários duplicados, inscrições de teste duplicadas ou até cobranças duplas se seu backend não for idempotente. Se precisar de retries, repita passos seguros (como carregar página), não compras ou criação de conta.
Uma checklist rápida de segurança:
- Cubra verificação e reset, não só o cadastro inicial
- Rode de fora da sua rede em pelo menos uma região real
- Use seletores estáveis e esperas confiáveis
- Evite reenviar ações que criam dados
- Mantenha credenciais fora do código e dos logs
Por fim, trate segredos como dados de produção. Contas de teste devem ter permissões mínimas e credenciais devem viver em um cofre de segredos, não no repo do script ou nos payloads de alerta.
Checklist rápido: seu monitoramento cobre a dor real do usuário?
Se seu monitoramento só checa que a homepage carrega, vai perder as falhas que realmente cortam receita. Use esta checklist para validar se seu monitoramento de cadastro acompanha o que um cliente novo faz, na ordem certa, com provas acionáveis.
Um bom check termina em um sinal claro de sucesso. “200 OK” não basta. Você quer ver a primeira tela que confirma que o usuário está realmente dentro (por exemplo: página de boas‑vindas, dashboard ou uma etapa “verifique seu email” que só aparece após submit bem‑sucedido).
Aqui está uma checklist simples de passa/falha que corresponde à dor real do usuário:
- Um usuário novo pode submeter o formulário de cadastro e chegar à primeira tela de sucesso (não um redirect genérico).
- O login funciona logo após o cadastro em uma sessão nova (feche e reabra o contexto do navegador para não depender de auth em cache).
- O onboarding realmente muda o estado do app (por exemplo: um campo de perfil é salvo, ou o primeiro workspace/projeto é criado e visível após refresh).
- O checkout chega a um estado de confirmação sem retries e não gera uma segunda cobrança ao atualizar a página.
- Quando algo falha, o alerta inclui uma captura de tela e a etapa exata que quebrou (qual botão, qual URL, qual texto de erro).
Um cheque de realidade: imagine que o formulário de cadastro aparenta sucesso, mas a próxima página trava só para usuários de primeira vez porque um registro “time default” não foi criado. Testes locais podem nunca ver isso porque sua conta já tem dados. Uma execução sintética que cria um usuário novo a cada vez vai detectar isso rápido.
Cenário exemplo: o cadastro funciona para você mas falha para clientes
Um fundador lança na segunda‑feira. O tráfego está saudável, mas novas contas despencam. A equipe checa uptime e tudo parece bem: homepage carrega, API responde e não há erros de servidor.
O problema é simples: o fundador (e a equipe) continua testando o cadastro a partir da rede do escritório em um país, em um navegador, enquanto usuários reais vêm de múltiplas regiões e dispositivos.
Eles adicionam verificações sintéticas que rodam de fora da rede. Uma checagem roda dos EUA, outra da UE e outra da Ásia. EUA e UE passam, mas a execução da Ásia falha sempre logo após o botão “Continuar com Google”.
O alerta é útil porque inclui o que uma pessoa real veria:
- Uma captura de tela de um loop de redirecionamento entre o app e o provedor de identidade
- Um erro curto do console como “redirect_uri_mismatch” e a URL final que se repete
- A etapa exata que falhou (após auth, antes da criação da conta)
Descobre‑se que a URL de callback de auth estava mal configurada. O app tinha um callback que funcionava no domínio principal, mas uma borda regional ou um domínio alternativo na Ásia gerava uma URL de redirecionamento ligeiramente diferente. Do laptop do fundador isso nunca aparecia.
A correção é pequena: atualizar as URLs de callback permitidas no provedor de auth e garantir que o app sempre retorne um alvo de redirect consistente. Depois, reexecutar o script sintético de todas as regiões, confirmar que todas chegam à tela “Conta criada” e fechar o incidente.
Antes de seguir, adicione uma checagem de regressão: rode o mesmo script de cadastro após cada deploy, de pelo menos uma localização externa, e alerte só se falhar duas vezes seguidas.
Próximos passos: implemente suas primeiras verificações e estabilize o app
Comece pequeno e coloque algo funcionando esta semana. Um script para cadastro e outro para checkout já pega a maioria dos momentos “não funciona nada”. Escolha primeiro o caminho feliz mais simples, depois adicione variações (planos diferentes, códigos promocionais, métodos de pagamento, novo usuário vs retornando).
Rode seus dois primeiros scripts como um release de produto:
- Escreva uma jornada de cadastro e uma de checkout que reflitam o que um cliente faz, de fora da sua rede.
- Grave uma linha de base: taxa de sucesso e tempo médio para completar cada jornada.
- Adicione regras claras de sucesso/falha (por exemplo: conta criada, tela de boas‑vindas exibida, pagamento confirmado).
- Defina um alerta por jornada e roteie para quem pode agir.
- Reveja os resultados semanalmente e só amplie cobertura quando o básico ficar estável.
Depois que as checagens estiverem ativas, acompanhe os números por alguns dias. Uma pequena queda na taxa de sucesso pode ser tão importante quanto um outage completo. Também acompanhe tempo para completar. Se seu cadastro de repente passa a levar o dobro do tempo, algo provavelmente está pela metade quebrado (API lenta, spinner travado, atraso na entrega de email) antes de falhar totalmente.
Se as falhas forem frequentes, pause e estabilize o app antes de aumentar o monitoramento. Culpados comuns são edge cases de autenticação, etapas de onboarding frágeis e falta de tratamento de erro (uma única resposta ruim ou campo vazio quebra o fluxo). Conserte a causa raiz e então aperte o script para verificar as mensagens e mudanças de estado corretas.
Se você herdou uma base de código gerada por IA e não sabe se o script está errado ou o app, uma passagem de remediação focada pode economizar tempo. FixMyMess (fixmymess.ai) se concentra em diagnosticar e reparar problemas como autenticação quebrada, roteamento confuso, segredos expostos e lacunas de segurança para que seu monitoramento de cadastro reflita a saúde real do usuário em vez de alertas constantes.
Perguntas Frequentes
Why does signup work for us but fail for real users?
Porque a maioria das equipes testa o “caminho feliz” no próprio ambiente, onde DNS, bordas de CDN, cookies e provedores terceiros se comportam de forma diferente. Usuários reais acessam pela internet pública, então problemas como JavaScript antigo em cache, cookies mal configurados ou limites regionais podem quebrar o cadastro sem aparecer internamente.
What’s the difference between uptime monitoring and a synthetic signup check?
Uma verificação de uptime só diz se uma página respondeu. Uma verificação sintética de cadastro percorre todo o fluxo e confirma um momento real de sucesso, como alcançar a tela de boas‑vindas ou carregar o primeiro painel depois de criar uma conta nova.
Which user journeys should we monitor first?
Comece com as 2–4 jornadas que afetam diretamente receita ou carga de suporte. Para a maioria dos produtos isso significa criar conta, primeiro login, reset de senha e checkout, porque são caminhos que os usuários abandonam rapidamente quando algo falha.
What’s a good success signal for a signup synthetic check?
Escolha uma única “prova” de que a jornada realmente funcionou, não apenas que uma página carregou. Um bom padrão é verificar se o usuário consegue acessar uma tela autenticada em uma sessão nova, assim você evita um falso positivo vindo só da interface.
How do we test email verification if inbox delivery is unreliable?
A forma mais simples é verificar o evento no backend de que o email foi gerado e enfileirado, tratando a entrega na caixa de entrada como uma checagem separada. Se precisar validar o link ponta a ponta, use uma caixa de email de teste dedicada que o script possa ler e mantenha esse acesso restrito.
What’s the safest way to handle test accounts and credentials?
Use usuários de teste dedicados, claramente identificados e separados de clientes reais, e evite dados de clientes reais. Armazene credenciais de teste em um gerenciador de segredos, mantenha permissões mínimas e rotacione as credenciais usadas pelo script para que não vire um ponto fraco de longa duração.
Where should synthetic checks run from to catch real-world failures?
Execute a partir da internet pública e de mais de uma região; caso contrário você perde problemas de DNS/CDN em borda e falhas regionais de provedores terceiros. Um padrão prático é 2–4 regiões que reflitam onde seus usuários estão, para pegar casos de “funciona aqui, falha lá”.
How often should we run signup checks without creating alert noise?
Para produtos estáveis, a cada 5 minutos para cadastro e login é um bom ponto de partida, com uma execução extra logo após deploys. Aumente a frequência durante lançamentos ou para checkout, e defina timeouts por etapa para que o alerta diga exatamente onde travou.
How do we prevent flaky scripts and false passes?
Use seletores estáveis que você controla, como data-testid, e espere por sinais de prontidão específicos em vez de sleeps fixos. Evite reenviar ações que criam dados (como criar conta ou fazer pedido), pois retries podem esconder erros reais e gerar duplicatas.
What if our app is AI-generated and signup is already unstable?
Se você vê quebras repetidas e não sabe se o script ou o app estão errados, conserte primeiro o fluxo subjacente. FixMyMess (fixmymess.ai) pode auditar uma base de código gerada por IA, reparar autenticação quebrada, roteamento confuso e problemas de segurança, ajudando a tornar o fluxo de cadastro estável para que o monitoramento seja confiável.