Checklist de Paridade do Ambiente de Staging: Previna Problemas em Produção
Use este checklist de paridade de staging para igualar auth, webhooks, storage, cron e flags, fazendo com que falhas em staging reflitam produção antes do release.
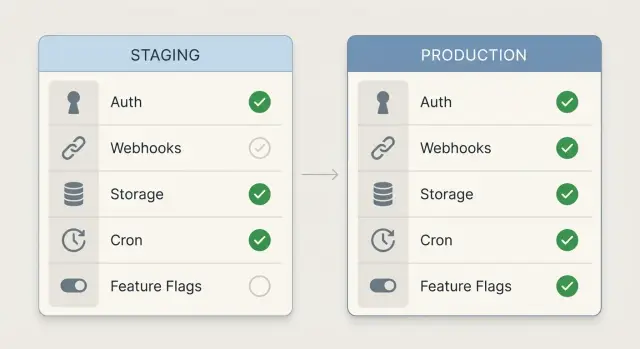
Por que staging não prevê produção por padrão
Paridade é simples: staging deve se comportar como produção nas formas que podem quebrar um release. Se a mesma requisição, ação do usuário ou job em background roda em staging, ela deveria falhar ou ter sucesso pelos mesmos motivos que teria em produção.
Staging “passa” quando você está, sem querer, testando um mundo diferente. Talvez o staging use um app OAuth distinto, configurações de cookie relaxadas, remetentes de webhook falsos, um bucket de armazenamento aberto ou jobs de background que nunca rodam. Tudo parece ok até o tráfego real bater em serviços reais com regras reais.
Falhas em produção que escapam do staging geralmente vêm de alguns culpados recorrentes: diferenças de domínio e redirect (callbacks OAuth), assinaturas e retries de webhooks, permissões de armazenamento e drift de CORS, workers desabilitados e feature flags que não coincidem.
Paridade não significa copiar dados de produção para staging. Você pode manter staging seguro usando usuários de teste, pagamentos falsos e registros amostrados e anonimizados. O objetivo é igualar configuração e comportamento, não expor informações de clientes.
Um exemplo comum: a equipe testa login no staging com um app OAuth que permite qualquer redirect URL. Produção é estrita, então o mesmo fluxo de login falha para usuários reais.
Comece pelo básico: versões, configs e domínios
A maioria das surpresas em staging acontece por um motivo chato: você não está rodando o mesmo app.
Primeiro, confirme que a versão implantada e as configurações de build batem. Times frequentemente testam um commit novo em staging enquanto produção ainda está no build da semana passada, ou usam flags de build diferentes que mudam o comportamento (modo debug, seleção de base URL da API, minificação).
Trate variáveis de ambiente da mesma forma. Você não precisa dos mesmos valores secretos, mas precisa dos mesmos nomes e formatos de variável. Um nome só em staging como STRIPE_KEY_TEST pode esconder a falta de STRIPE_SECRET_KEY até o dia do release.
Domínios são outra divisão silenciosa. Se produção está em app.example.com e staging está em um host aleatório, redirects e cookies podem se comportar de forma diferente, especialmente com HTTPS e configurações de segurança estritas. Garanta que redirects, TLS e callback URLs apontem para o domínio correto em cada ambiente, com as mesmas regras.
Por fim, verifique diferenças de runtime que mudam resultados sem alterar o código: versões de Node/Python, imagens base do SO, versões de banco de dados e configurações de região. Isso pode afetar tratamento de datas, caminhos de arquivo e latência.
Uma checagem rápida de “básicos”:
- Mesmo commit git (ou tag de release) e mesmo comando de build
- Mesmas chaves e tipos de variáveis de ambiente (string vs JSON), com valores diferentes permitidos
- Mesmos padrões de domínio, comportamento HTTPS e regras de redirect
- Mesmas versões de runtime e imagem base do container
- Mesmas configurações de região (fuso horário, locale) onde importam
Paridade de auth: provedores, redirects, cookies e sessões
Auth é onde “funciona no staging” mais frequentemente se quebra. Trate o login como um sistema completo, não como um botão que abre um popup.
Equalize os provedores de identidade que você suporta. Se o staging só tem Google habilitado, mas a produção também tem GitHub ou Auth0, você não está testando o app real. Diferenças de provedor mudam campos de perfil, comportamento de verificação de email e regras de refresh de token.
Depois compare configurações OAuth uma por uma. Redirect URIs e origins permitidos devem coincidir exatamente, incluindo protocolo e subdomínio. Falhas comuns incluem:
- Staging permite
http://localhostmas produção exige HTTPS - Um mismatch entre www e sem-www bloqueia o callback
- O provedor ainda tem redirect URIs antigos salvos de um domínio de staging anterior
Cookies e sessões também precisam de configurações de segurança idênticas. Pequenas flags mudam tudo: Secure, HttpOnly, SameSite, domínio do cookie e tempo de vida da sessão. Se staging está em HTTP simples ou em um domínio de nível diferente, o comportamento dos cookies pode parecer “ok” enquanto produção quebra após o login.
Antes de um release, rode uma checagem de auth que pareça uso real:
- Faça login com cada provedor que você suporta, depois atualize a página e confirme que permanece logado
- Complete reset de senha e verificação por email ponta a ponta (incluindo o link no email)
- Teste em janela anônima e no Safari mobile (regras de cookie diferem)
- Confirme que logout limpa sessão e tokens, não só o estado da UI
- Gere tentativas repetidas para atingir rate limits e confirme que o erro é tratado
Não esqueça proteções só de produção: bloqueios por IP, regras de WAF, detecção de bots e limites de provedores. Staging não avisará sobre isso a menos que você teste.
Paridade de webhooks: endpoints, assinaturas e retries
Webhooks são outro lugar onde o staging pode “mentir”. No staging, o provedor pode estar apontando para a URL errada, usando um segredo diferente ou enviando um conjunto de eventos distinto do de produção. Então pagamentos, cadastros ou notificações falham para usuários reais.
Comece listando cada remetente de webhook e os eventos exatos dos quais seu app depende (Stripe, GitHub, Slack, Zapier, serviços internos). Puxe isso dos dashboards dos provedores e do código, não da memória.
Garanta que cada provedor tenha o endpoint de staging registrado e ativo. Um erro comum é “URL de staging adicionada”, mas o endpoint antigo ainda está selecionado, desabilitado ou configurado para um conjunto de eventos diferente.
Trate assinaturas como um contrato estrito. Staging deveria verificar assinaturas do mesmo jeito que produção: mesmo nome de header, mesmo algoritmo de hash, mesmo tratamento do corpo cru. Muitos frameworks quebram a verificação se analisarem JSON antes de verificar. Se o staging pula a verificação “para acelerar”, você está testando um app diferente.
Uma checagem prática de webhook:
- Reative um payload real de produção (com dados sensíveis removidos) no staging e compare status HTTP e tempo de resposta
- Confirme que o segredo de assinatura em staging corresponde ao usado pelo provedor para o endpoint de staging
- Force uma falha (retorne 500) e confirme que o provedor reenvia conforme esperado
- Verifique idempotência: o mesmo evento entregue duas vezes não deve cobrar, criar ou enviar email em duplicidade
- Logue um request ID estável para rastrear duplicatas através de retries
Exemplo: o Stripe reenvia um webhook payment_succeeded após timeout. O app cria dois pedidos porque o handler não tem checagem de idempotência. A correção muitas vezes é pequena, mas o impacto em produção não é.
Paridade de storage: permissões, CORS e fluxos de arquivos
Se seu app manipula arquivos, storage é um lugar fácil para o staging enganar você. Um build que funciona com disco local e permissões abertas pode falhar no momento em que atinge um bucket real com regras mais rígidas.
Alinhe o tipo de storage e o modelo de acesso. Se produção usa S3 ou GCS com objetos privados, staging também deve usar. Diferenças em políticas de bucket, papéis IAM ou configurações de acesso público frequentemente aparecem como erros 403 “aleatórios” que parecem bugs do app.
CORS é a próxima armadilha. Um upload que funciona em um ambiente pode falhar no outro se origins permitidos, headers ou métodos diferirem. Garanta que ambos ambientes permitam os mesmos domínios e o mesmo fluxo de upload (direto para o bucket vs via sua API).
Teste também o fluxo, não só permissões. Use tamanhos e tipos de arquivo reais, não imagens de demonstração minúsculas. Muitas falhas vêm do tratamento de MIME, limites do servidor ou regras de storage que rejeitam certas extensões.
Uma checagem rápida de storage:
- Faça upload de um arquivo grande e confirme que a UI lida com progresso e timeouts
- Baixe pelo mesmo caminho de UI que os usuários usarão (não um atalho de dev)
- Exclua e confirme que o registro e o objeto são removidos
- Gere um link expirável e confirme que ele expira quando deveria
- Rode qualquer processamento (thumbnails, OCR, antivírus) ponta a ponta
Cron e jobs em background: agendamentos, runners e alertas
Trabalhos agendados frequentemente falham silenciosamente. Um checkout pode parecer ok no navegador, mas se o job de fatura noturno, tarefa de limpeza ou remetente de email se comporta diferente, produção quebra depois e parece aleatório.
Liste cada job agendado e o que o dispara: cron schedules, workers de fila e timers “roda a cada X minutos” dentro do app. Se um job existe em produção mas não em staging, o staging não pode prever a falha.
Configurações de tempo são uma armadilha clássica. Alinhe fuso horário, comportamento de horário de verão e o que “meia-noite” significa. Um job que roda às 00:05 em produção pode rodar em outro horário local no staging, processando dados diferentes e criando edge cases.
Confirme que o runner de jobs está realmente ligado no staging. Muitas equipes deployam o web app mas esquecem de habilitar o scheduler, dyno de worker ou container. O resultado é sucesso silencioso: nenhum erro, porque nada rodou.
Antes de um release:
- Liste cada job, seu schedule e o fuso horário que usa
- Confirme que o processo de scheduler/worker está habilitado e tem as mesmas env vars
- Force-run jobs chave em staging com volume de dados parecido com produção
- Quebre um job de propósito para confirmar que retries, backoff e alertas disparam
- Cheque dependências externas: filas, email/SMS, APIs de pagamento e limites de taxa
Feature flags: defaults, regras e fallback iguais
Feature flags ajudam até o staging e produção discordarem sobre o que está “on”. Trate flags como código: mesma fonte, mesmas regras e mesmo comportamento em falha.
Inventarie cada flag que seu app lê e seu default pretendido. Times costumam inverter defaults em staging para demos e depois esquecem. É assim que um release “seguro” vira um lançamento surpresa.
Compare como as flags são avaliadas: targeting por usuário, por organização, rollouts percentuais e “só habilitado para emails internos”. Conjuntos de usuários menores no staging podem acidentalmente pular caminhos importantes.
Cheque também o encanamento. Staging deve usar o mesmo serviço de flags e a mesma versão do SDK que produção. Versões de SDK diferentes podem mudar cache, ordem de avaliação e como usuários anônimos são tratados.
Uma checagem sólida de flags:
- Compare estados atuais e defaults das flags em ambos ambientes
- Compare regras de targeting (usuários, orgs, segmentos, rollouts percentuais)
- Confirme que o mesmo provedor e versão do SDK estão implantados
- Simule uma queda (bloqueie o serviço de flags) e verifique que o app se comporta de forma segura
- Busque no código por overrides do tipo “if staging then…” hardcoded
Decida o comportamento de fallback de propósito. Para pagamentos, auth ou ferramentas admin, “falhar aberto” (feature habilitada) pode ser arriscado.
Como rodar uma checagem de paridade passo a passo
Checagens de paridade funcionam melhor quando staging é um ensaio, não um palpite.
Escolha uma jornada crítica do usuário que toque mais sistemas. Para muitos apps é: cadastro, verificar email, upgrade, depois logout e login novamente.
Rode essa jornada em staging com contas novas e navegadores reais. Conforme avança, observe cada chamada externa que puder: auth, pagamentos, email, storage, webhooks, analytics, feature flags. Confirme que cada dependência tem um equivalente em staging (ou um sandbox seguro) com configurações que batem, não “próximas o bastante”.
Depois do teste, capture alguns detalhes enquanto estão frescos: qual provedor de auth foi usado, quais URLs de redirect foram acionadas, se checagens de assinatura de webhook rodaram e quais jobs em background foram disparados depois.
Uma vitória típica de paridade: cadastro no staging funciona, mas o “upgrade” nunca libera recursos. Anotações mostram que o webhook de pagamento aponta para um endpoint antigo de staging, então o evento nunca chega ao app.
Erros comuns de paridade que causam rollbacks à noite
A maioria dos rollbacks começa com uma pequena discrepância que parecia inofensiva em staging.
Falhas de autenticação são frequentemente “quase iguais”: um app OAuth diferente, redirect URLs faltando, domínios de cookie que não batem ou um caminho de callback que difere por um caractere. Tudo funciona localmente, staging parece ok, então produção falha com loop de redirect ou sessão que não persiste.
Webhooks causam um tipo diferente de dano. Staging às vezes aponta para produção por acidente, enviando eventos de teste para dados reais. Mesmo quando endpoints estão corretos, segredos de assinatura ou configurações de retry podem diferir, fazendo com que produção se comporte mais agressivamente que o staging.
Segredos são outro clássico de noite de release. Uma chave de protótipo conveniente acaba no código cliente, no build ou nos logs. Conforme o tráfego em produção aumenta, esses logs se espalham e o alcance do vazamento cresce.
Cinco erros que escapam das revisões:
- Redirects de auth e configurações de cookie diferem por domínio ou protocolo
- Staging acidentalmente bate em webhooks, filas ou bancos de produção
- Valores secretos são impressos em logs ou incluídos no frontend
- Cron e jobs em background estão desligados em staging, então bugs de tempo nunca aparecem
- Defaults ou regras de targeting de feature flags diferem silenciosamente entre ambientes
Checklist rápido de paridade que você pode copiar numa nota de release
Release parity checks (staging corresponde à produção):
- Build + runtime iguais: mesmas versões de runtime, mesmo modo de build, mesmas chaves de env var presentes (valores podem diferir) e mesmo padrão de domínio/subdomínio.
- Fluxos de login verificados ponta a ponta: redirects/callback URLs registrados, configurações de cookie iguais (Secure, SameSite, domínio), sessões sobrevivem a refresh e reset de senha ou magic-link completam.
- Webhooks se comportam como em produção: provedor aponta ao endpoint correto de staging, verificação de assinaturas ligada, retries não criam duplicatas e entregas falhadas são visíveis.
- Armazenamento de arquivos funciona sob regras reais: limites de upload batem, permissões batem (público vs privado), CORS permite a origem exata do frontend e links de download comportam-se igual.
- Trabalho em background previsível: schedules batem, fuso horário confirmado, workers habilitados, falhas alertam alguém e flags têm defaults/regras iguais com fallback seguro.
Um exemplo realista: o release que quebrou no primeiro dia
Um fundador envia um protótipo SaaS gerado por IA (construído em Cursor e Replit) que parecia perfeito em staging. Na manhã do lançamento, os cadastros disparam e chega a primeira mensagem de suporte: “Não consigo entrar”.
O login em staging funcionava sempre, mas usuários em produção eram redirecionados de volta à homepage após o callback OAuth. O bug foi simples: produção usava um domínio diferente, mas o provedor de auth ainda tinha o redirect URI antigo salvo do staging. Para piorar, cookies em produção foram configurados com uma regra SameSite mais estrita, então as sessões não persistiam após o redirect.
Enquanto a equipe corre, surge outro problema. Pagamentos aparecem como “bem-sucedidos”, mas ninguém ganha acesso. O provedor de pagamento está enviando webhooks, mas o app não os processa porque o endpoint de produção nunca foi registrado. Testes em staging passaram porque a equipe usou um toggle manual de “marcar como pago” em vez de eventos reais de webhook.
Depois, uploads de arquivo quebram só para clientes reais. No staging, uploads iam para um bucket permissivo com CORS amplo. Em produção, o papel de storage não tinha permissão de escrita e origens permitidas não incluíam o domínio ao vivo, então o navegador bloqueou o request de upload.
Um ensaio de paridade curto teria pego os três problemas: verificação de redirect URIs e comportamento de cookie, registro e checagem de assinatura de webhooks, e permissões de bucket mais CORS.
Próximos passos para manter staging e produção sincronizados
Paridade é mais fácil de manter quando você documenta, automatiza uma checagem simples e atribui alguém para consertar o drift.
Mantenha uma única fonte de verdade para variáveis de ambiente e integrações. Uma tabela simples basta: nome, propósito, onde está configurado e o que significa “válido” em staging vs produção.
Adicione um smoke test repetível que rode em cada release: logar, disparar um webhook, fazer upload de um arquivo e confirmar que um job em background rodou. Se algo falhar em staging, pare e corrija antes de aprender a mesma lição em produção.
Uma forma prática de decidir o que deve ser real vs sandbox em staging:
- Auth: provedor real, app/cliente separado, domínio de callback de staging
- Pagamentos/email/SMS: sandbox quando possível, com contas de teste claras
- Webhooks: assinatura e comportamento de retry reais, apontando para endpoints de staging
- Storage: regras reais de bucket e CORS, mas um bucket de staging
- Cron/jobs: schedules reais, mas dados e destinatários seguros
Se você herdou uma base gerada por IA e a paridade continua falhando, o problema costuma ser mais profundo que uma configuração perdida: URLs hardcoded, segredos expostos, handlers de webhook frágeis ou workers em background nunca conectados corretamente. FixMyMess (fixmymess.ai) ajuda equipes a transformar protótipos gerados por IA em software pronto para produção, diagnosticando e corrigindo problemas como misconfigurações de auth, confiabilidade de webhooks e defaults inseguros.