CI/CD para código de protótipo herdado: um blueprint simples de pipeline
CI/CD para código de protótipo herdado simplificado: um pipeline prático com lint, testes, checagens de build, deploy previews e releases de produção mais seguros.
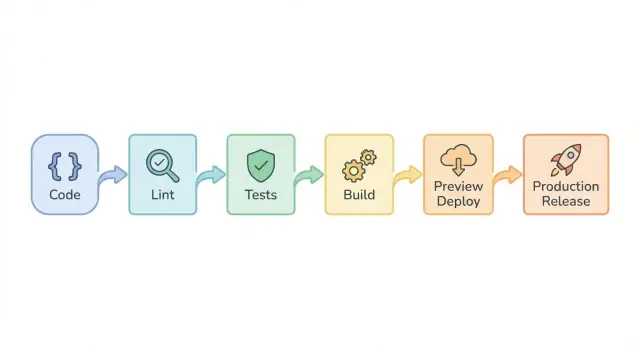
Por que protótipos herdados precisam de uma abordagem diferente de CI/CD
Código de protótipo herdado costuma ser uma mistura de experimentos rápidos, trechos copiados e recursos pela metade. Normalmente tem estrutura fraca, responsabilidade pouco clara e atalhos "temporários" que viraram permanentes. Se ferramentas de IA ajudaram a montá‑lo, você também pode ver padrões inconsistentes, falta de tratamento de erros e lógica que parece correta até usuários reais encontrarem casos limites.
Por isso ele pode rodar num laptop e desabar em produção. A configuração original pode depender de arquivos locais escondidos, uma versão de runtime específica, um banco de dados pré‑popular ou variáveis de ambiente que ninguém documentou. Um colega roda com cache aquecido; outro instala do zero e vê uma tela em branco. Produção traz segurança mais rígida, condições de rede diferentes e volume real de dados, o que expõe problemas como autenticação quebrada, segredos expostos e consultas de banco frágeis.
Uma abordagem melhor de CI/CD aqui não é tentar engenharia perfeita no dia um. É reduzir alarmes. Um pipeline simples pega falhas comuns cedo, torna releases repetíveis e dá um jeito mais seguro de mudar as coisas sem precisar reescrever tudo primeiro.
Este blueprint foca em guardrails práticos: linting básico, um conjunto pequeno de testes importantes, builds confiáveis, deploy previews para revisão e releases em produção com caminho de rollback.
Se a base estiver gravemente quebrada (por exemplo, autenticação emaranhada, padrões de consulta inseguros ou falhas de segurança como SQL injection), você terá mais valor com um diagnóstico curto e reparos direcionados antes. Depois, o CI/CD ajuda a impedir que os mesmos problemas voltem.
Defina o objetivo: o que significa "seguro o suficiente para lançar"
Protótipos herdados falham de maneiras imprevisíveis. O objetivo do seu pipeline não é perfeição. É feedback mais rápido, menos deploys quebrados e releases que você repete sem segurar a respiração.
Escreva o que "seguro o suficiente" significa para seu app neste mês, não a versão dos sonhos daqui a seis meses. Uma promessa prática inicial é simples: toda mudança roda os mesmos checks, toda vez. Sem exceções de "hotfix rápido", porque exceções viram a nova normal.
Uma definição que o time pode repetir
Uma alteração está "pronta" quando duas coisas são verdadeiras:
- O pipeline está verde.
- Ele produz algo que você realmente pode lançar (um artefato deployável), não apenas código que compila num laptop.
Se os checks passam mas você não consegue fazer o deploy, o pipeline não está completo.
Mantenha a definição curta. Para a maioria dos times, já basta exigir: linting e um conjunto básico de testes, um build limpo em CI, um deploy de preview ou staging para revisão e um release em produção que siga o mesmo caminho com uma etapa explícita de aprovação.
O que adiar (de propósito)
Tentar consertar tudo no dia um é a forma mais rápida de abandonar o CI/CD. É aceitável adiar cobertura completa de testes e grandes refactors enquanto você coloca portões confiáveis no lugar.
Se o login às vezes quebra, não comece reescrevendo a autenticação. Comece fazendo "seguro o suficiente" significar: login tem um smoke test automatizado, segredos não estão expostos e o build produz um artefato liberável. Quando os releases pararem de falhar, você pode ampliar a cobertura e refatorar com menos risco.
Prepare o repositório: branches, ambientes e segredos
Antes de ligar o CI/CD, torne o repositório previsível. A maior parte da dor em protótipos vem de configurações misteriosas: branches em que ninguém confia, variáveis de ambiente espalhadas por chats e segredos cometidos por acidente.
Mantenha branches sem surpresas
Normalmente você precisa de um branch de longa vida e branches de trabalho curtos:
maindeve estar sempre deployável.- Mudanças acontecem em branches de feature curtos que voltam para
mainrapidamente.
Evite mega‑branches (como um dev que fica semanas em drift). Tagueie releases no main para poder voltar a um ponto conhecido bom.
Torne ambientes e segredos explícitos
Escolha uma única fonte de verdade para configuração. Um padrão simples é: local usa um arquivo .env.example, CI usa o cofre de segredos do próprio CI e produção usa as configurações de env do provedor de hospedagem. O importante é consistência: os mesmos nomes de variáveis em todos os lugares.
Essenciais mínimos:
- Mantenha uma lista documentada das env vars necessárias (o que fazem, valores padrão seguros).
- Tenha um
.env.exampleapenas com nomes, nunca valores reais. - Remova segredos cometidos e roteie qualquer coisa que foi exposta.
- Mantenha chaves e URLs fora do código.
Um bom reality check: se um colega novo não consegue rodar o app sem pedir "o .env certo", seu pipeline também será frágil.
Adicione também uma nota curta no README com comandos copy‑paste para rodar lint, testes e build localmente. Se for ruim localmente, será pior no CI.
Portões de qualidade que pegam a maioria dos problemas cedo
Código de protótipo tende a quebrar de maneiras previsíveis: formatação bagunçada, suposições de runtime escondidas e "funciona na minha máquina". Portões de qualidade são os checks que seu pipeline roda em cada mudança para que problemas apareçam minutos após um commit, não numa madrugada de deploy.
Comece com um formatador e um linter, e torne‑os obrigatórios. Consistência importa mais que perfeição. Checks automáticos acabam com debates de estilo e impedem que pequenos problemas escondam bugs reais.
Adicione checagens de tipo leves onde fizer sentido. Você não precisa reescrever tudo para obter valor. Mesmo checagens básicas de tipo podem pegar argumentos errados, campos ausentes e tratamento inseguro de null antes que virem erros em produção.
Para testes, mantenha a barra realista. Defina um conjunto mínimo que deve sempre passar, mesmo que o restante da suíte ainda cresça. Um mínimo prático geralmente cobre os fluxos que mais te custam tempo:
- Login e gerenciamento de sessão (incluindo logout)
- Um "happy path" central para a funcionalidade principal
- Um endpoint de API crítico (ou job background) que faça uma chamada real ao banco
- Checagens básicas de permissão (usuários não veem dados de outros)
- Um smoke test que o app inicia sem erros
Por fim, torne builds reproduzíveis. Trave a versão do runtime (Node, Python, etc.), use lockfiles e faça instalações limpas no CI. Assim você testa o que vai, de fato, enviar.
Blueprint passo a passo do pipeline (lint -> test -> build)
O objetivo do pipeline é falhar rápido e dizer o que consertar.
Rode‑o em todo pull request, mantenha‑o consistente e rápido o suficiente para que as pessoas não tentem pular etapas.
Uma ordem simples que funciona
-
Formate e lint primeiro. Auto‑formatar reduz diffs barulhentos. Linting pega problemas fáceis cedo (variáveis não usadas, imports errados, padrões inseguros) e ajuda o código a ficar legível enquanto você corrige.
-
Rode os testes com saída clara. Faça falhas óbvias: qual teste falhou, mensagem de erro e onde aconteceu. Revisores não devem ter que vasculhar logs.
-
Build como se fosse produção. Use o mesmo comando de build e a mesma versão de runtime que espera em produção. Use a mesma forma de variáveis de ambiente (mas nunca segredos reais). Este passo pega assets faltando, config errada e surpresas do tipo "funciona na minha máquina".
-
Adicione uma checagem rápida de segurança. Mantenha leve: escaneie dependências por pacotes vulneráveis conhecidos e por segredos acidentalmente cometidos. Código assistido por IA é especialmente propenso a tokens hardcoded ou credenciais de exemplo.
-
Publique artefatos de build. Salve o output do build (e relatórios de teste) para que passos de deploy os reutilizem em vez de reconstruírem.
Deploy previews: revisar mudanças sem arriscar produção
Um deploy preview é uma cópia temporária do seu app que roda exatamente o código de um pull request. Ele se comporta como o produto real, mas está isolado. Isso ajuda revisores não técnicos a clicar pelos fluxos reais sem instalar nada.
Previews são uma das formas mais rápidas de pegar problemas do tipo "funciona na minha máquina". Também mostram issues de UI, redirects quebrados, env vars faltando e páginas lentas antes de qualquer coisa chegar à produção.
Crie previews para todo PR por padrão. Pule só quando não agregam valor (por exemplo, mudanças só na documentação). Consistência importa: revisores aprendem que toda mudança tem um lugar seguro para testar.
Torne os previews realistas (sem copiar produção)
Se previews começam com um banco vazio, muitas páginas vão parecer quebradas mesmo com o código certo. Planeje dados seed simples:
- Crie um pequeno conjunto de usuários fake e registros de exemplo no deploy.
- Adicione um banner claro de "demo mode".
- Forneça uma ou duas contas pré‑feitas para revisão (nunca contas reais).
Mantenha previews seguros
Ambientes de preview nunca devem usar dados reais de clientes ou segredos de produção. Trate‑os como uma sandbox pública.
Boas práticas: chaves e bancos separados para preview, desabilitar jobs destrutivos (cobranças, emails, webhooks) e expirar previews automaticamente após curto período.
Releases seguros em produção: aprovações, rollbacks e monitoramento
Um processo de release seguro torna riscos ocultos visíveis e fáceis de desfazer.
Faça cada release em produção rastreável. Use tags de versão (por exemplo, v1.8.0) para que você possa responder: qual código está rodando agora, quem aprovou e o que mudou desde o último release.
Mesmo em times pequenos, adicione uma etapa manual de aprovação antes da produção. O CI pode rodar checks, mas um humano deve confirmar que o preview parece certo, verificar notas de release e garantir que há plano de rollback. Em codebases herdadas, uma pequena mudança pode quebrar um fluxo crítico.
Rollbacks devem ser rápidos e rotineiros. Antes de precisar de um, garanta que você consegue redeployar a tag anterior em uma ação, trate mudanças de banco com cuidado (ou evite migrations arriscadas durante releases), restaure configurações de ambiente sem adivinhação e confirme sucesso com um smoke check rápido.
Se quiser segurança extra, use rollout progressivo (canary ou por percentuais). Liberte para uma pequena fração do tráfego, observe problemas e então libere para todos. Se os erros subirem, pare ou faça rollback enquanto a maioria dos usuários não foi afetada.
Após um release, monitore os sinais que mostram se o app está utilizável:
- erros no servidor e no frontend (picos, novos tipos de erro)
- taxa de sucesso de login e cadastro
- pagamentos ou finalização de checkout (se relevante)
- performance (páginas lentas, timeouts)
- jobs importantes em background (emails, webhooks, filas)
Quando faltam testes ou são instáveis: um caminho prático
Protótipos herdados muitas vezes não têm testes ou têm testes que falham "às vezes". Você ainda precisa de confiança, mas também de progresso. O objetivo são sinais previsíveis em que você confia.
Teste instável ou bug real?
Um teste flaky costuma falhar em lugares diferentes sem nenhuma mudança de código. Um bug real tende a falhar da mesma forma até ser corrigido.
Formas rápidas de distinguir:
- Reexecute o mesmo commit 3‑5 vezes. Passagens aleatórias indicam flakiness.
- Olhe o erro. Timeouts, "element not found" e problemas de rede costumam indicar flakiness.
- Procure estado compartilhado: testes dependentes de ordem, bancos reutilizados, sessões em cache.
- Compare local vs CI. Falhas só no CI muitas vezes significam problemas de timing ou configuração ausente.
Não ignore flakiness. Quarentena o teste (marque como não‑bloqueante) e abra uma tarefa para consertá‑lo para que o pipeline continue útil.
Sem testes ainda? Comece por smoke tests
Se você não tem nenhum teste, comece com um pequeno conjunto de smoke que proteja os caminhos mais importantes:
- App sobe e a página inicial carrega
- Login funciona (happy path)
- Uma ação crítica de create/read funciona
- Usuários deslogados não acessam página privada
- Um health check de API retorna 200
Mantenha‑os rápidos (alguns minutos) e faça‑os bloqueantes.
Para estabilizar sem atrasar todo mundo, divida testes em níveis: smoke bloqueiam merges; testes E2E mais longos rodam agendados ou antes do release. Limite retries a um, e trate "retry passou" como aviso, não sucesso.
Para cobertura, estabeleça uma meta que cresça devagar: comece com 10–20% do core logic e aumente com o tempo.
Erros comuns que tornam CI/CD doloroso
A forma mais rápida de ter um pipeline em que ninguém confia é torná‑lo "perfeito" no dia um. Com código herdado (especialmente gerado por IA), mire em progresso repetível, não numa parede de checks vermelhos que todo mundo aprende a ignorar.
Uma armadilha comum é tornar os portões tão rígidos que cada execução falha por questões de estilo menores. Linting é útil, mas se bloquear todo o trabalho, as pessoas começam a burlar o CI ou a mergear sem corrigir nada. Comece com regras que peguem bugs reais e aperte com o tempo.
Outro erro é auto‑deployar para produção em todo merge sem botão de pausa. Isso transforma um pequeno erro em incidente para clientes. Mantenha produção monótona: aprovação antes do release, rollback claro e um jeito de parar um release se algo parecer errado.
Previews também podem dar problema. Um preview que lê seu banco de produção ou usa chaves de produção não é "seguro" — é produção com menos olhos. Use credenciais separadas e banco de preview (ou serviços mockados) para que revisões não arrisquem dados ou dinheiro.
Outros causadores frequentes de dor:
- Buildar de um jeito no CI e de outro em produção (runtime diferente, env vars, flags).
- Adiar atualizações de dependências até uma falha de segurança forçar um upgrade apressado.
- Pular checks básicos porque "funcionou na minha máquina."
Checklist rápido: seu pipeline é confiável?
Um pipeline vale confiança quando responde duas perguntas sempre: "Quebrou algo?" e "Conseguimos dar rollback rápido se quebrou?"
Procure estes sinais mínimos:
- Linting e formatação rodam automaticamente em cada mudança e falham rápido.
- Testes rodam de forma confiável e em tempo razoável.
- O build é reproduzível e produz um artefato deployável.
- Deploy previews estão isolados (sem dados reais de clientes, sem segredos de produção).
- Releases em produção exigem aprovação explícita e têm um plano de rollback documentado.
Se só puder fazer uma coisa esta semana, torne previews seguros. Use um banco de teste, chaves de pagamento falsas e emails stubados para que revisores possam clicar sem enviar mensagens reais ou tocar em registros reais.
Depois, foque na primeira hora após o release:
- Tracking de erros está ligado e você sabe onde olhar.
- Alertas existem para picos de 500s, falhas de login e requisições lentas.
- Um health check rápido confirma fluxos centrais (sign in, criar registro, salvar, sign out).
- Logs são pesquisáveis e não incluem segredos.
- Alguém está designado para monitorar.
Exemplo: transformar um protótipo frágil criado por IA em um app liberável
Você herda um protótipo feito em Lovable (ou Bolt/v0) que funcionou numa demo e depois quebra quando tenta deployar. Logins falham, variáveis de ambiente estão hardcoded e o build passa num laptop mas não no CI. É aqui que um pipeline simples para de adivinhar e torna mudanças mais seguras.
A primeira semana deve ser pequena e sem glamour, por design. Você não tenta consertar tudo. Você tenta tornar cada mudança visível, testável e reversível.
Um plano prático para a semana um:
- Dia 1: Obter uma instalação limpa e um único comando de build no CI
- Dia 2: Adicionar checks de lint/format e falhar em erros óbvios
- Dia 3: Adicionar 2–5 smoke tests para caminhos críticos (login, uma rota API chave, uma página principal)
- Dia 4: Habilitar deploy previews para cada pull request
- Dia 5: Adicionar uma gate simples de release (aprovação manual) para produção
Deploy previews mudam a conversa com stakeholders. Em vez de "acho que consertei", você envia um preview e a aprovação vira um claro sim/não.
Se previews revelarem problemas profundos como autenticação quebrada, segredos expostos, consultas inseguras ou arquitetura que torna mudanças arriscadas, pause o trabalho de pipeline e conserte os fundamentos primeiro.
Se você herdou uma base de código gerada por IA que é difícil de estabilizar rapidamente, uma auditoria focada e uma passagem de reparo ajudam. FixMyMess (fixmymess.ai) começa com uma auditoria gratuita de código e depois faz correções direcionadas como reparo de lógica, hardening de segurança, refactor e preparação para deploy para que seu pipeline tenha algo sólido para proteger.