Confiabilidade de webhooks: pare de perder eventos do Stripe, GitHub e Slack
Confiabilidade de webhooks: evite eventos perdidos ou duplicados do Stripe, GitHub e Slack adicionando assinaturas, idempotência, retries e tratamento dead-letter.
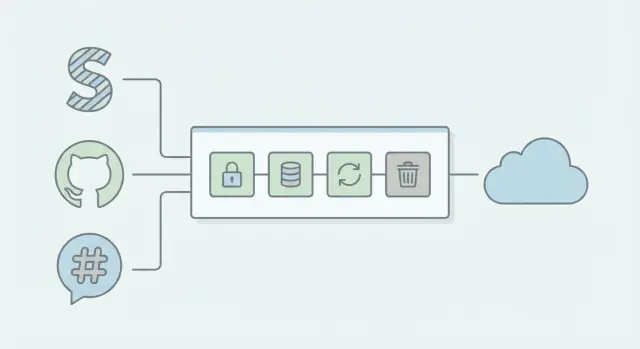
Por que manipuladores de webhook falham na prática
Um webhook é um callback: um sistema envia ao seu servidor uma requisição HTTP quando algo acontece, como um pagamento, um push ou uma nova mensagem.
No papel isso parece simples. Em produção, a confiabilidade se rompe porque redes são bagunçadas e provedores se protegem com retries. O mesmo evento pode chegar duas vezes, chegar atrasado ou parecer que nunca chegou.
Equipes normalmente esbarram em alguns modos de falha recorrentes:
- Eventos perdidos: seu endpoint deu timeout, travou ou ficou brevemente indisponível.
- Duplicatas: o provedor reentregou e você processou o mesmo evento de novo.
- Entrega fora de ordem: o evento B chega antes do A, mesmo que A tenha ocorrido primeiro.
- Processamento parcial: você gravou no banco, falhou antes de responder e houve retry.
A maioria dos provedores promete apenas "pelo menos uma vez", não "exatamente uma vez". Eles tentam entregar, mas não podem garantir timing perfeito, ordenação perfeita ou entrega única.
Então o objetivo não é fazer webhooks se comportarem perfeitamente. O objetivo é fazer seus resultados ficarem corretos mesmo quando requisições chegam duas vezes, chegam atrasadas ou fora de ordem. O resto deste guia foca em quatro defesas que cobrem a maior parte das falhas do mundo real: idempotência, verificação de assinatura, retries sensatos e um caminho dead-letter para que falhas fiquem visíveis em vez de silenciosas.
O que Stripe, GitHub e Slack farão com seu endpoint
Provedores de webhook são educados, mas não pacientes. Eles enviam um evento, esperam um curto período e, se seu endpoint não responder como esperado, tentam de novo. Isso é comportamento normal.
Assuma que o seguinte acontecerá mais cedo ou mais tarde:
- Timeouts: seu endpoint demora demais, então eles tratam como falha.
- Retries: eles reenviam o mesmo evento, às vezes várias vezes.
- Picos: um dia tranquilo vira 200 eventos em um minuto.
- Falhas temporárias: seu servidor retorna 500, um deploy reinicia um worker, ou o DNS dá um problema.
- Atrasos na entrega: eventos chegam minutos depois do esperado.
A entrega duplicada pega muitas equipes de surpresa. Mesmo que seu código tenha feito a coisa certa, o provedor pode não saber disso. Se seu handler der timeout, retornar um não-2xx ou fechar a conexão cedo, o mesmo evento pode voltar. Se você tratar cada entrega como nova, pode cobrar duas vezes, aplicar upgrade duas vezes, enviar e-mails duplicados ou criar registros duplicados.
A ordenação também não é garantida. Você pode ver "subscription.updated" antes de "subscription.created", ou uma edição de mensagem do Slack antes da mensagem original, dependendo de retries e caminhos de rede. Se sua lógica assume uma sequência limpa, você pode sobrescrever dados mais novos com dados antigos.
Isso piora quando seu handler depende de trabalho lento downstream como gravação no banco, envio de e-mail ou chamada a outra API. Uma falha realista parece com isto: seu código espera por um provedor de e-mail por 8 segundos, o remetente do webhook dá timeout em 5 segundos, reenvia, e agora duas requisições competem para atualizar o mesmo registro.
Um bom handler trata webhooks como entregas não confiáveis: aceite rápido, verifique, dedupe e processe de maneira controlada.
Idempotência: a correção que evita processamento duplo
Idempotência significa isto: se o mesmo evento de webhook atingir seu servidor duas vezes (ou dez), seu sistema acaba no mesmo estado que teria se você o tivesse tratado uma vez. Isso importa porque retries são normais.
Na prática, idempotência é deduplicar com memória. Quando um evento chega, você checa se já o processou. Se sim, retorna sucesso e não faz mais nada. Se não, processa e registra que fez.
O que você precisa para deduplicar
Você não precisa de muito, mas precisa de algo estável:
- ID do evento do provedor (melhor quando disponível)
- Nome do provedor (Stripe vs GitHub vs Slack)
- Quando você o viu pela primeira vez (útil para limpeza e debug)
- Status de processamento (recebido, processado, falhou)
Armazene isso em algum lugar durável. Uma tabela de banco é o padrão mais seguro. Um cache com TTL pode servir para eventos de baixo risco, mas pode esquecer durante reinícios ou evicções. Para dinheiro ou mudanças de acesso, trate o registro de dedupe como parte dos seus dados.
Por quanto tempo manter as chaves? Mantenha mais do que a janela de retries do provedor e mais do que seus próprios retries atrasados. Muitas equipes mantêm de 7 a 30 dias e então expiram registros antigos.
Efeitos colaterais a proteger
Idempotência protege suas ações de maior risco: cobrar duas vezes, enviar e-mails duplicados, aplicar upgrade de papel duas vezes, emitir reembolso duplo ou criar tickets duplicados. Se fizer apenas uma melhoria de confiabilidade nesta semana, faça esta.
Verificação de assinatura sem pegadinhas
A verificação de assinatura impede que tráfego aleatório da internet finja ser Stripe, GitHub ou Slack. Sem ela, qualquer um pode chamar sua URL de webhook e disparar ações como "marcar fatura como paga" ou "convidar usuário para o workspace." Eventos falsos podem parecer válidos o bastante para passar por checagens básicas de JSON.
O que você verifica normalmente é o mesmo entre provedores: o corpo bruto da requisição (bytes exatos), um timestamp (para bloquear replays), um segredo compartilhado e o algoritmo esperado (frequentemente um HMAC). Se qualquer uma dessas entradas mudar mesmo um pouco, a assinatura não casará.
A pegadinha que quebra integrações reais com mais frequência: parsear JSON antes de verificar. Muitos frameworks parseiam e re-serializam o corpo, o que muda espaços em branco ou a ordem das chaves. Seu código então verifica uma string diferente daquela que o provedor assinou, e você rejeita eventos reais.
Outras armadilhas comuns:
- Usar o segredo errado (teste vs produção, ou o segredo do endpoint errado).
- Ignorar tolerância de timestamp e então rejeitar eventos válidos quando o relógio do seu servidor deriva.
- Verificar o header errado (alguns provedores enviam múltiplas versões de assinatura).
- Retornar 200 mesmo quando a verificação falha, o que torna o debug difícil.
O tratamento de erro seguro é simples: se a verificação falhar, rejeite rápido e não execute lógica de negócio. Retorne um erro claro (comum é 400, 401 ou 403 dependendo do provedor). Registre apenas o que ajuda a diagnosticar: nome do provedor, ID do evento (se presente), um motivo curto como "assinatura inválida" ou "timestamp muito antigo" e seu próprio request ID. Evite logar corpos brutos ou headers completos porque podem conter segredos.
Uma arquitetura simples de webhook que se mantém estável sob carga
O padrão mais confiável é entediante: faça o mínimo possível na requisição HTTP, depois passe o trabalho real para um worker em background.
O caminho de requisição seguro e rápido
Quando Stripe, GitHub ou Slack chama seu endpoint, mantenha o caminho curto e previsível:
- Verifique assinatura e headers básicos (rejeite rápido se inválido)
- Registre o evento e uma chave única de evento
- Enfileire um job (ou grave uma linha de "inbox")
- Retorne um 2xx imediatamente
Retornar 2xx rapidamente importa porque remetentes de webhook reencaminham em timeouts e erros 5xx. Se você fizer trabalho lento (fan-out no banco, chamadas a APIs, envio de e-mail) antes de responder, aumenta retries, entregas duplicadas e tráfego de "thundering herd" durante incidentes.
Separe ingestão de processamento
Pense nisso como dois componentes:
- Endpoint de ingestão: checagens de segurança, validação mínima, enfileirar, 2xx
- Worker: lógica de negócio idempotente, retries e atualizações de estado
Essa separação mantém seu endpoint estável sob carga porque o worker pode escalar e re-tentar sem bloquear novos eventos. Se o Slack enviar um pico de eventos durante uma importação de usuário, o endpoint continua rápido enquanto a fila absorve o estouro.
Para logging, capture o necessário para debugar sem vazar segredos ou PII: tipo de evento, remetente (Stripe/GitHub/Slack), ID de entrega, resultado da verificação de assinatura, status de processamento e timestamps. Evite despejar headers completos ou corpos de requisição nos logs; armazene payloads apenas em um repositório de eventos protegido se realmente precisar.
Passo a passo: um padrão de handler de webhook que você pode copiar
A maioria dos bugs de webhook acontece porque o handler tenta fazer tudo dentro da requisição HTTP. Trate a requisição recebida como um passo de recibo e mova o trabalho real para um worker.
O handler de requisição (rápido e rígido)
Esse padrão funciona em qualquer stack:
- Valide a requisição e capture o corpo bruto. Verifique método, caminho esperado e content-type. Salve bytes brutos antes de qualquer parsing de JSON para que checagens de assinatura não quebrem.
- Verifique a assinatura cedo. Rejeite assinaturas inválidas com uma resposta 4xx clara. Não tente "adivinhar" o que o payload queria dizer.
- Extraia um ID de evento e construa uma chave de idempotência. Prefira o ID de evento do provedor. Se não existir, construa uma chave a partir de campos estáveis (origem + timestamp + ação + ID do objeto).
- Grave um registro de idempotência antes de efeitos colaterais. Faça um insert atômico como "event_id não visto antes." Se já existir, retorne 200 e pare.
- Enfileire o trabalho e retorne 200 rapidamente. Coloque o evento (ou um ponteiro para o payload armazenado) na fila. A requisição web não deve chamar APIs de terceiros, enviar e-mails ou fazer trabalho pesado.
O worker (efeitos colaterais seguros)
O worker carrega o evento enfileirado, executa sua lógica de negócio e atualiza o registro de idempotência para um estado claro como processing, succeeded ou failed. Retries pertencem aqui, com backoff e um teto.
Exemplo: um webhook de pagamento do Stripe chega duas vezes. A segunda requisição encontra o mesmo event ID, vê o registro de idempotência existente e sai sem aplicar o upgrade do cliente novamente.
Retries que ajudam em vez de piorar
Retries são úteis quando a falha é temporária. Eles são prejudiciais quando transformam um bug real em um pico de tráfego, ou quando repetem uma requisição que não deveria ter sucesso.
Re-tente apenas quando houver boa chance de a próxima tentativa funcionar: timeouts de rede, resets de conexão e respostas 5xx das suas dependências. Não re-tente respostas 4xx que significam "sua requisição está errada" (assinatura inválida, JSON inválido, campos obrigatórios faltando). Também não re-tente quando você já sabe que o evento é duplicado e foi tratado com idempotência.
Um conjunto simples de regras:
- Re-tentar: timeouts, 429 rate limits, 500-599, erros DNS/conexão temporários
- Não re-tentar: 400-499 (exceto 429), assinatura inválida, validação de esquema falhou
- Tratar como sucesso: evento já processado (replay idempotente)
- Parar rápido: dependência está fora do ar para todos (use um circuit breaker)
- Sempre: limite de tentativas e tempo total
Use backoff exponencial com jitter. Em termos simples: espere um pouco, depois espere mais a cada tentativa, e adicione um pequeno atraso aleatório para que retries não atinjam tudo de uma vez. Por exemplo: 1s, 2s, 4s, 8s, com mais ou menos até 20% de variação.
Defina tanto um número máximo de tentativas quanto uma janela máxima de retry total. Um ponto de partida prático é 5 tentativas em 10 a 15 minutos. Isso evita loops de retry infinitos que escondem problemas até explodirem.
Torne chamadas downstream seguras. Coloque timeouts curtos em chamadas ao banco e às APIs, e adicione um circuit breaker para parar de chamar um serviço em falha por um minuto ou dois.
Por fim, registre o motivo do retry: timeout, 5xx, 429, nome da dependência e quanto tempo demorou. Essas tags transformam "às vezes perdemos webhooks" em um problema consertável.
Dead-letter handling: como parar de perder eventos para sempre
Você precisa de um plano para os eventos que não processam mesmo após retries. Uma dead-letter queue (DLQ) é uma área de retenção para entregas de webhook que continuam falhando, para que não desapareçam em logs ou fiquem presas re-tentando eternamente.
Um bom registro de DLQ guarda contexto suficiente para debugar e re-executar sem adivinhação:
- Payload bruto (como texto) e JSON parseado
- Headers necessários para verificação e rastreio (assinatura, event ID, timestamp)
- Mensagem de erro e stack trace (ou um motivo curto de falha)
- Contador de tentativas e timestamps de cada tentativa
- Seu status interno de processamento (criou usuário, atualizou plano, etc.)
Então faça o replay seguro. Replays devem passar pelo mesmo caminho idempotente que o webhook ao vivo, usando uma chave de evento estável (geralmente o ID do evento do provedor). Assim, reexecutar um evento duas vezes não faz nada na segunda vez.
Um workflow simples ajuda times não técnicos a agir rápido sem tocar em código. Por exemplo, quando um evento de pagamento falha por uma queda temporária do banco, alguém pode re-executá-lo depois que o sistema estiver saudável.
Mantenha o fluxo mínimo:
- Auto-rotear falhas repetidas para a DLQ após N tentativas
- Mostrar uma mensagem curta "o que falhou" mais um resumo do payload
- Permitir replay (com idempotência aplicada)
- Permitir "marcar como ignorado" com nota obrigatória
- Escalar para engenharia se o mesmo erro se repetir
Defina retenção e alertas. Mantenha itens da DLQ tempo suficiente para cobrir fins de semana e férias (frequentemente 7 a 30 dias) e alerte um dono claro quando a DLQ crescer além de um pequeno limiar.
Exemplo: prevenindo upgrades duplicados a partir de um webhook de pagamento do Stripe
Um fluxo comum do Stripe: um cliente paga, Stripe envia um evento payment_intent.succeeded e seu app aplica o upgrade na conta.
Veja como isso quebra. Seu handler recebe o evento, tenta atualizar o banco e chamar uma função de billing. O banco fica lento, a requisição dá timeout e seu endpoint retorna 500. Stripe assume que a entrega falhou e reenvia. Agora o mesmo evento te atinge de novo e o usuário é promovido duas vezes (ou recebe dois créditos, duas faturas marcadas como pagas, ou dois e-mails de boas-vindas).
A correção é em camadas:
Primeiro, verifique a assinatura do Stripe antes de qualquer outra coisa. Se a assinatura estiver errada, retorne 400 e pare.
Em seguida, torne o processamento idempotente usando event.id do Stripe. Armazene um registro como processed_events(event_id) com uma constraint de unicidade. Quando o evento chegar:
- Se
event_idfor novo, aceite. - Se
event_idjá existir, retorne 200 e não faça nada.
Depois separe recebimento do trabalho: validar + gravar + enfileirar, então deixe um worker executar o upgrade. O endpoint responde rápido, então timeouts raramente acontecem.
Finalmente, adicione um caminho dead-letter. Se o worker falhar por um erro de banco, salve o payload e a razão da falha para replay seguro. Reexecutar deve rodar o mesmo código do worker, e a idempotência garante que não haverá double-upgrade.
Depois dessas mudanças, o usuário vê um único upgrade, menos atrasos e muito menos tickets de suporte "paguei duas vezes".
Erros comuns que criam bugs silenciosos em webhooks
A maioria dos bugs de webhook não é barulhenta. Seu endpoint retorna 200, dashboards parecem normais e semanas depois você percebe upgrades perdidos, e-mails duplicados ou registros fora de sincronia.
Um erro clássico é quebrar a verificação de assinatura por acidente. Muitos provedores assinam o corpo bruto da requisição, mas alguns frameworks parseiam JSON primeiro e mudam whitespace ou a ordem das chaves. Se você verificar contra o corpo parseado, boas requisições podem parecer adulteradas e serem rejeitadas. A correção: verifique usando os bytes brutos exatamente como recebidos, depois parseie.
Outra falha silenciosa acontece quando você retorna 200 cedo demais. Se você reconhecer o webhook e então seu processamento falhar (gravação no banco, chamada a API, enfileiramento), o provedor não reentenderá porque você já disse que funcionou. Acknowledge somente depois de gravar o evento de forma recuperável (ou enfileirá-lo).
Fazer trabalho lento dentro da thread de requisição também mata a confiabilidade. Remetentes de webhook costumam ter timeouts curtos. Se fizer lógica pesada ou chamadas de rede antes de responder, você terá retries, duplicatas e eventos perdidos ocasionais.
Bugs de dedupe podem ser sutis também. Se você dedupe pela chave errada como user ID ou repository ID, vai descartar eventos reais. Dedupe deve ser baseada no identificador único do evento (e às vezes no tipo de evento), não em quem o evento descreve.
Por fim, cuidado com logs. Despejar payloads inteiros pode vazar segredos, tokens, e-mails ou IDs internos. Logue contexto mínimo (event ID, tipo, timestamps) e redacte campos sensíveis.
Checklist rápido: sua integração de webhook está segura agora?
Um handler de webhook é "seguro" quando permanece correto durante duplicatas, retries, bancos lentos e requisições ocasionalmente ruins.
Comece com o básico que previne fraude e duplo processamento:
- Verifique a assinatura usando o corpo bruto da requisição (antes de parsear JSON ou qualquer transformação do corpo).
- Crie e grave um registro de idempotência antes de efeitos colaterais. Salve o ID do evento (ou chave calculada) primeiro, depois faça o trabalho.
- Retorne um 2xx rápido assim que a requisição for verificada e enfileirada com segurança.
- Defina timeouts claros em todos os lugares. Handler, chamadas ao banco, chamadas a APIs externas.
- Tenha retries com backoff e limite de tentativas. Retries devem desacelerar com o tempo e parar após um limite.
Depois verifique que você pode recuperar quando algo ainda falhar:
- Existe armazenamento dead-letter que inclui payload, headers necessários, razão do erro e contador de tentativas.
- Replay funciona de verdade. Você pode reexecutar um evento da DLQ com segurança depois de corrigir o problema, e a idempotência evita efeitos duplicados.
- Monitoramento básico está presente: contagens de recebidos, processados, re-tentados e dead-lettered, mais um alerta quando a DLQ cresce.
Cheque rápido: se seu servidor reiniciar no meio de uma requisição, você perderia o evento ou o processaria duas vezes? Se não tiver certeza, corrija isso primeiro.
Próximos passos se seus webhooks já são frágeis
Se você já tem eventos perdidos ou duplicatas estranhas, trate isso como um pequeno projeto de reparo, não um patch rápido. Escolha uma integração (Stripe, GitHub ou Slack) e corrija-a end-to-end antes de tocar nas outras.
Ordem prática de operações:
- Adicione verificação de assinatura primeiro e torne falhas óbvias nos logs.
- Torne o processamento idempotente (grave um ID de evento e ignore repetições).
- Separe "receber" de "processar" (ack rápido, trabalho em background).
- Adicione retries seguros com backoff para falhas temporárias.
- Adicione tratamento dead-letter para que eventos falhos sejam salvos para revisão.
Então escreva um pequeno plano de testes que você possa executar sempre que mudar código:
- Entrega duplicada: envie o mesmo evento duas vezes e confirme que aplica só uma vez.
- Assinatura inválida: confirme que a requisição é rejeitada e nada é processado.
- Eventos fora de ordem: confirme que o sistema permanece consistente.
- Downstream lento: simule um timeout para confirmar que retries ocorrem de forma segura.
Se você herdou código de webhook gerado por uma ferramenta de AI e ele parece frágil (difícil de seguir, efeitos colaterais surpreendentes, segredos em lugares estranhos), uma passagem de remediação focada costuma ser mais rápida do que perseguir sintomas. FixMyMess (fixmymess.ai) ajuda equipes a transformar protótipos gerados por AI em código pronto para produção, diagnosticando problemas de lógica, endurecendo segurança e reconstruindo fluxos de webhook frágeis num padrão ingest-and-worker mais seguro.
Perguntas Frequentes
Why do I get the same webhook event more than once?
Trate duplicatas como normais, não como um caso extremo. A maioria dos provedores entrega webhooks pelo menos uma vez, então um timeout ou um breve erro 500 pode fazer o mesmo evento ser enviado novamente mesmo que seu código já tenha sido executado.
When should my webhook endpoint return 200?
Retorne um 2xx somente depois de verificar a assinatura e registrar o evento com segurança (ou enfileirá-lo) de maneira que você possa recuperar. Se você retornar 200 e então a gravação no banco ou a colocação na fila falharem, o provedor assumirá que deu certo e não reempreenderá, o que gera perda silenciosa de dados.
How do I prevent double-charging or double-upgrading from retries?
Use idempotência baseada em uma chave única estável, idealmente o ID do evento do provedor. Armazene essa chave em armazenamento durável com uma restrição de unicidade; se aparecer de novo, saia cedo retornando sucesso para que as retries parem.
How do I handle out-of-order webhook events without corrupting state?
Não presuma ordenação, mesmo dentro do mesmo provedor. Faça atualizações condicionais com versão, timestamps ou verificando o estado atual para que um evento antigo não sobrescreva dados mais novos, e projete handlers para que cada evento seja seguro de aplicar mesmo que chegue atrasado.
Why does signature verification fail even when the secret is correct?
Verifique contra os bytes brutos do corpo da requisição exatamente como recebidos, antes de qualquer parse de JSON ou re-serialização. Muitos frameworks mudam whitespace ou a ordem das chaves durante o parse, e essa pequena mudança é suficiente para que uma assinatura correta pareça inválida.
Should my webhook handler do the business logic in the request thread?
Um bom padrão é verificar a assinatura, escrever um registro de inbox/idempotência, enfileirar o trabalho e responder imediatamente. Trabalho lento como envio de e-mail, chamadas a APIs de terceiros ou grande fan-out no banco pertence a um worker para que o provedor não dê timeout e reenvie.
Which failures should I retry, and which should I not retry?
Re-tente quando a falha for provavelmente temporária, como timeouts, erros de rede, limites 429 ou respostas 5xx de dependências. Não re-tente assinaturas inválidas ou payloads malformados; sempre limite o número de tentativas e o tempo total de retry para que falhas fiquem visíveis em vez de looparem para sempre.
What should I store for deduplication, and how long should I keep it?
Grave uma chave de dedupe, quando você a viu pela primeira vez, e um status de processamento para distinguir recebido de concluído ou com falha. Para qualquer coisa envolvendo dinheiro ou mudanças de acesso, mantenha o registro de dedupe durável e por tempo suficiente para cobrir janelas de retry do provedor e seu próprio reprocessamento atrasado.
What is a dead-letter queue and when do I need one?
Uma dead-letter path é onde eventos vão depois que as retries se esgotam para que não desapareçam. Armazene contexto suficiente para entender a falha e re-executar com segurança, e garanta que o replay siga o mesmo caminho idempotente para que replays não gerem efeitos duplicados.
My webhooks are brittle and were generated by an AI tool—what’s the fastest way to fix them?
Normalmente falta uma das camadas de segurança: verificação de assinatura, idempotência, confirmação rápida com processamento em background, retries controlados ou visibilidade via dead-letter. Se o código foi gerado por uma ferramenta de AI e é difícil de entender, FixMyMess pode auditar o fluxo de webhook, corrigir lógica e segurança, e reconstruir em um padrão ingest-and-worker rapidamente.