Contadores confiáveis sob concorrência: evite a deriva nas métricas
Saiba como manter contadores confiáveis sob concorrência usando atualizações atômicas, chaves de idempotência e gravações em lote para que as métricas permaneçam precisas em produção.
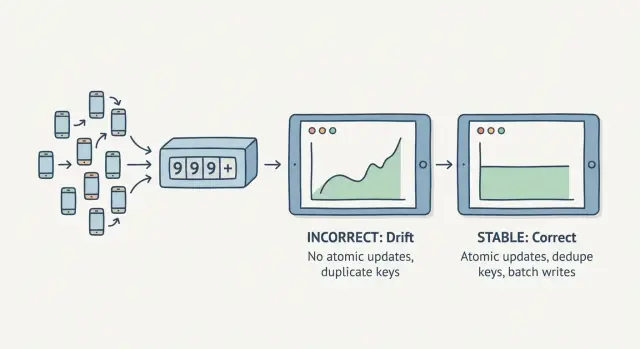
Por que os contadores derivam quando o tráfego chega ao mesmo tempo
Um contador deriva quando você não consegue confiar que ele permaneça consistente. Você atualiza um painel e o total muda mesmo que nada novo tenha acontecido. Ou o número pula depois de um pico curto. Isso é difícil de pegar em testes porque geralmente precisa de concorrência real.
A deriva costuma se manifestar assim:
- O mesmo relatório mostra totais diferentes a cada atualização.
- Contagens pulam depois de um surto de tráfego ou de um deploy.
- Totais em um lugar (banco de dados) não batem com outro (analytics).
A causa usual é uma condição de corrida: muitas requisições tentam atualizar o mesmo número ao mesmo tempo. Se seu código faz “ler o valor atual, somar 1, gravar de volta”, duas requisições podem ler 10, ambas somam 1 e ambas gravam 11. Um incremento some.
Por isso frequentemente aparece só depois do lançamento. No laptop ou em um ambiente de staging quieto, as requisições chegam uma a uma. Depois de uma campanha, um recurso popular ou jobs em background rodando em paralelo, essas atualizações colidem.
Também há um trade-off entre precisão e atualidade. Atualizar um contador a cada requisição pode ser preciso, mas só se a atualização for realmente segura sob concorrência. Muitas equipes escolhem quase tempo real: coletar eventos rapidamente e depois atualizar totais em pequenos lotes a cada poucos segundos. O número fica um pouco atrasado, mas geralmente é mais estável e mais fácil de tornar correto.
Um exemplo simples: dois usuários clicam em “Comprar” no mesmo segundo. Se ambas requisições calcularem e gravarem o total separadamente, seu contador de compras pode subcontar mesmo que ambos os pedidos tenham sido processados.
Escolha o tipo certo de métrica antes de codar
Muitos “problemas de contador” são, na verdade, “problemas de definição”. Se você escolher o tipo de métrica errado, consertar apenas o incremento não deixará sua análise estável.
Quando alguém diz que quer “um contador”, geralmente quer um destes:
- Contador: quantas vezes algo aconteceu (visualizações de página, cliques em botões)
- Soma: valor total através de eventos (receita, minutos assistidos)
- Contagem única: quantos usuários/itens distintos fizeram algo (cadastros únicos, compradores únicos)
- Taxa: uma razão ao longo do tempo (cadastros por hora, taxa de conversão)
Um simples +1 frequentemente é suficiente para eventos de baixo impacto e alto volume, como visualizações de página. Um pouco de ruído por duplicatas geralmente não importa.
Mas no momento em que dinheiro, estado do usuário ou mensagens estão envolvidos, você precisa de uma definição mais rígida de “verdade”. Cadastros, compras, e-mails de redefinição de senha, convites e eventos de “início de trial” são reexecutados mais do que se espera (clientes, jobs em background, provedores de pagamento). Contar retries como novos eventos é como os painéis ficam inflacionados.
Uma forma prática de decidir é escolher sua fonte da verdade:
- Eventos append-only: armazene cada evento uma vez e depois compute totais a partir dos eventos.
- Totais armazenados: mantenha um número corrido e atualize à medida que os eventos acontecem.
Logs de eventos são mais fáceis de auditar e recomputar. Totais armazenados são mais rápidos de ler, mas só funcionam se as atualizações estiverem corretas e duplicatas forem bloqueadas.
Exemplo: um checkout recebe payment_succeeded duas vezes porque a primeira resposta do webhook expirou. Se sua métrica “compras” for um contador simples, ela pula em 2. Se sua verdade for “uma compra por payment_id”, você mede IDs de pagamento únicos, não entregas brutas de webhook.
Atualizações atômicas: a forma mais segura de incrementar
Quando você precisa de contadores confiáveis sob concorrência, use atualizações atômicas. “Atômico” significa que a mudança acontece como uma única operação: ela é aplicada uma vez, ou não é. Sem estado parcial, sem duas requisições se sobrepondo.
O bug clássico é ler-modificar-gravar: ler 100, somar 1 no código da aplicação, gravar 101. Duas requisições podem ler 100 e ambas gravar 101.
Atualizações atômicas fazem o incremento dentro do banco ou armazenamento, onde pode ser aplicado com segurança mesmo quando muitas requisições chegam ao mesmo tempo:
UPDATE counters
SET value = value + 1
WHERE name = 'signups';
INCR signups
Uma checagem rápida: se sua aplicação lê o valor do contador apenas para incrementá-lo, você provavelmente voltou ao território de ler-modificar-gravar.
Incrementos atômicos não são gratuitos. Se uma única linha/chave é atualizada constantemente (uma “hot key” como um contador global de pageviews), você pode enfrentar:
- Contenção de locks ou atualizações mais lentas
- Maior latência durante picos
- Atraso de replicação se você lê de réplicas
- Timeouts que disparam retries
Chaves de dedupe: pare de contar duas vezes por retries e replays
Idempotência significa que submeter a mesma ação duas vezes tem o mesmo efeito que submetê-la uma vez. Para contadores, é a diferença entre “quase certo” e confiável.
Duplicatas são comuns:
- Um usuário clica duas vezes em “Pagar agora”.
- Um cliente mobile perde a conexão e tenta novamente.
- Um provedor de webhooks reenvia após um 500.
- Uma fila reentrega um job.
Uma chave de dedupe geralmente é um event_id que identifica de forma única o evento do mundo real que você está contando. Pode vir de um ID de webhook do provedor, um UUID gerado pelo cliente, um ID gerado pelo servidor ou uma chave determinística verdadeiramente única como order_id + event_type.
Depois de ter event_id, armazene-o e recuse contar o mesmo mais de uma vez. A regra básica é: insira o event_id primeiro e então incremente, ou faça ambos em uma transação.
Opções comuns de armazenamento:
- Uma tabela no banco de dados de eventos processados com uma restrição UNIQUE em
event_id - Um índice UNIQUE na sua tabela de analytics/eventos
- Um cache (como Redis) com TTL para janelas de dedupe de curta duração
Exemplo: chega um webhook de compra, seu handler expira e o provedor o reenvia. Sem dedupe, você registra duas compras e incrementa a receita duas vezes. Com um event_id único, a segunda tentativa vira um no-op.
Gravações em lote: menos acessos ao banco, analytics mais estáveis
Sob carga, gravações de linha única podem se acumular. Isso aumenta o tempo de lock, deixa as respostas mais lentas e eleva a chance de timeouts ou falhas parciais. Batching reduz as idas ao banco e pode tornar a análise mais estável.
Um modelo mental simples: capture eventos rapidamente e depois escreva resumos em menos atualizações, porém maiores. Abordagens comuns incluem buffer com flush a cada N segundos, enfileirar eventos e agregar em workers, rollups agendados (hora/dia) ou um híbrido (contadores pequenos em tempo real mais backfills periódicos).
O trade-off é a atualidade. Seu painel pode atrasar segundos ou minutos, mas normalmente você verá menos gravações falhas e menos picos causados por tempestades de retries.
Escolha a janela de batch segundo o uso da métrica:
- Segundos: feeds ao vivo, rate limiting, widgets de “ativos agora”
- Dezenas de segundos: dashboards de marketing e funis de cadastro
- Minutos: receita e a maioria dos relatórios administrativos
- Horas/dias: relatórios financeiros e auditorias
Um padrão seguro para contadores e analytics
Trate cada incremento como resultado de um evento específico. O contador é apenas um resumo.
Um padrão que aguenta carga:
-
Nomeie o evento e escolha um id único estável. Use algo que permaneça o mesmo em retries (por exemplo:
order_id,payment_intent_idou umevent_idgerado passado pelo fluxo). -
Registre o evento (ou uma linha leve de dedupe) primeiro. Armazene o id em uma tabela
eventsoudedupecom uma restrição única. -
Incremente com uma atualização atômica. Use uma única instrução de incremento, não “ler, somar, gravar”. Se possível, mantenha a escrita do evento e a atualização do contador em uma única transação.
-
Torne os retries seguros. Se a inserção de dedupe falhar porque a chave já existe, trate como sucesso e pule o incremento.
-
Faça batch quando fizer sentido, sem quebrar as regras. Bufferize incrementos e faça flush periodicamente, mas só depois que o registro do evento/dedupe estiver salvo com segurança.
Exemplo: um usuário clica em “Comprar”, seu servidor cria um evento purchase_completed com chave de dedupe order_123. Se o provedor de pagamento reenviar o webhook, a segunda inserção bate na restrição única e você não conta uma segunda compra.
Retries, timeouts e filas de mensagens sem inflar contagens
Muitos sistemas entregam eventos com garantia de “at-least-once”. Em bom português: a mesma mensagem pode aparecer duas vezes.
Timeouts são a versão mais sorrateira. Um cliente chama sua API, espera, dá timeout e tenta novamente. Mas o servidor pode ter terminado e cometido a atualização do contador. Agora você tem duas tentativas “bem-sucedidas” para uma ação real.
A regra: só retry trabalho que é idempotente.
Um padrão prático de fila:
- A API cria um evento com um
event_idúnico (por exemplo,purchase-<order_id>) e enfileira. - Um worker processa o evento e escreve duas coisas em uma transação: (1) marca
event_idcomo processado, (2) incrementa o contador. - Se a mensagem for redeliverada, o worker vê
event_idjá processado e pula o incremento.
Para depurar incidentes, mantenha logs simples e consistentes:
event_id- timestamps (recebido e commitado)
- origem (API, fila, cron)
- resultado (processado, pulado como duplicado, falhou)
- contador de retries
Erros comuns que causam deriva nas métricas
Esses problemas se repetem entre produtos.
Erro 1: Ler e depois escrever incrementos
Duas requisições podem ler o mesmo valor e gravar o mesmo novo valor. Use um incremento atômico no banco para que a atualização aconteça em uma operação.
Erro 2: Contar antes da ação realmente ter sucesso
Se você incrementa quando a requisição começa, vai contar a mais quando a ação falhar depois (pagamento recusado, envio de e-mail falhou, transação revertida). Conte depois de ter um sinal real de sucesso.
Erro 3: Chaves de dedupe sem enforcement
Uma chave de dedupe só funciona se você fizer cumprir a unicidade no nível do banco (constraint/index UNIQUE). Sem isso, duplicatas ainda passam com retries e workers paralelos.
Erro 4: Gravações em lote que perdem dados
Batching reduz carga, mas buffers em memória podem desaparecer em reinícios. Torne o comportamento de flush explícito: flush por tempo, por tamanho e um flush no shutdown.
Erro 5: Fronteiras de dia quebradas em rollups
Métricas diárias derivam quando serviços discordam sobre fusos ou limites de dia. Escolha um padrão (geralmente UTC), armazene timestamps consistentemente e mantenha eventos brutos tempo suficiente para recomputar rollups.
Checagens rápidas para verificar se seus contadores são confiáveis
Se você não consegue explicar um incremento, não consegue provar que ele está correto. Mesmo uma tabela simples de eventos brutos é suficiente para checagens pontuais.
Um scan de sanidade rápido:
- Você consegue traçar cada incremento até um
event_idarmazenado com o evento bruto? - Você aplica unicidade para chaves de dedupe (índice/constraint UNIQUE)?
- Os contadores são atualizados com operações atômicas (uma única instrução), não ler-modificar-gravar no código da aplicação?
- Você reconcilia totais contra eventos brutos (mesmo uma checagem diária)?
- Você alerta sobre resets súbitos ou saltos incomuns?
Um teste prático: escolha uma métrica como “novos cadastros”, puxe 50 event_ids recentes e verifique se cada um mapeia exatamente para um incremento. Depois reexecute a mesma requisição/mensagem algumas vezes e confirme que o contador não se move.
Exemplo: corrigindo contadores de cadastro e compra em um app real
Um app pequeno de assinaturas rastreia cadastros, compras e “e-mail de boas-vindas enviado”. Durante semanas o painel parece normal. Aí o tráfego cresce e o suporte começa a ouvir “Fui cobrado duas vezes” ou “Cliquei uma vez”. Totais se afastam dos relatórios de pagamento.
O que está acontecendo: cliques duplos, retries do cliente após timeouts e webhooks de pagamento reprocessados. Se seu código incrementa primeiro e pergunta depois, as métricas derivam.
Uma correção estável combina três medidas:
- Dedupe por ação:
signup:<user_id>,purchase:<payment_event_id>,email:<message_id>, armazenadas com constraint única. - Incrementos atômicos: substitua ler-modificar-gravar por um único incremento no banco.
- Batch em atualizações de alto volume: mantenha em tempo real onde precisa, faça batch onde não precisa.
Um plano simples de rollout:
- Reproduza o mesmo payload de webhook 5–10 vezes em staging e confirme que os contadores não mudam após a primeira vez.
- Lance por trás de uma feature flag e ative para uma pequena porcentagem do tráfego.
- Rode um job de reconciliação para comparar eventos brutos vs contadores e preencher diferenças.
- Monitore “dedupe hits” para confirmar que retries estão sendo capturados.
Próximos passos: estabilizar métricas sem reescrever tudo
Geralmente você não precisa de uma reconstrução completa. Precisa de um mapa claro de onde as contagens são criadas, onde retries podem acontecer e onde duplicatas entram.
Comece com um inventário básico:
- Onde cada contador mora (banco, cache, ferramenta de analytics)
- Onde os eventos se originam (endpoints, jobs em background, webhooks)
- Cada caminho de retry (retries do cliente, retries de fila, redelivery de webhook)
- Como você identifica um evento (
event_id,request_id,order_id) - Onde as gravações acontecem (um lugar vs muitos)
Depois conserte nesta ordem:
- Pare a contagem dupla (chaves de dedupe e tratamento idempotente nas rotas mais quentes)
- Torne incrementos atômicos
- Melhore performance (batching, processamento assíncrono)
- Adicione checagens contínuas (reconciliação de eventos brutos vs contadores, alerta em saltos estranhos)
Se você herdou uma base de código gerada por IA, assuma que a lógica de contadores foi copiada e implementada de forma ligeiramente diferente em vários lugares. Unificar esses caminhos em uma função ou serviço compartilhado frequentemente é a maneira mais rápida de fazer as correções ficarem permanentes.
Se quiser uma segunda opinião, FixMyMess (fixmymess.ai) foca em diagnosticar e reparar problemas como atualizações não atômicas, falta de idempotência e webhooks sensíveis a replays em apps gerados por IA. Uma auditoria de código gratuita pode rapidamente destacar os poucos pontos que causam mais deriva sob tráfego real.