Corrija problemas “it works on my machine” na configuração para dev, staging e prod
Corrija problemas “it works on my machine” com separação clara entre dev, staging e prod, validação de env vars e checagens simples que evitam surpresas em runtime.
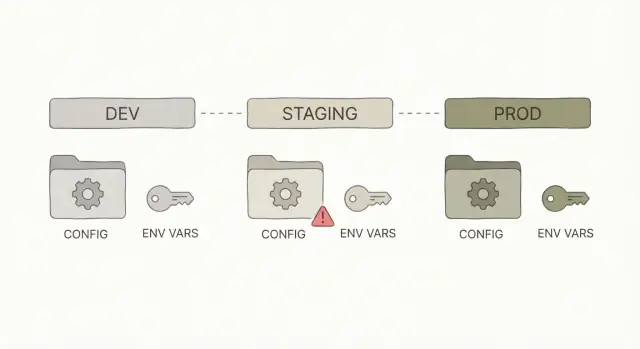
O que “it works on my machine” normalmente significa
Quando alguém diz “it works on my machine”, quer dizer que o app roda bem no laptop da pessoa, mas quebra depois do deploy. O código pode ser o mesmo, mas o ambiente ao redor é diferente.
Na maior parte das vezes, isso não é um “bug de lógica”. É configuração: o app recebe entradas diferentes dependendo de onde roda. Localmente, seu computador preenche as lacunas silenciosamente (logins salvos, arquivos locais, bancos seeded, tokens em cache). Em staging ou produção, essas muletas não existem.
Causas comuns:
- Variáveis de ambiente ausentes ou erradas (chaves de API,
DATABASE_URL, URL de callback de auth) - Serviços externos diferentes (SQLite local vs Postgres hospedado, Stripe sandbox vs Stripe live)
- URLs e redirects diferentes (localhost vs domínio real)
- Configurações de build e runtime diferentes (versão do Node, porta, feature flags)
- Segredos copiados no código ou em arquivos
.enve nunca definidos em produção
Problemas de config frequentemente aparecem como sintomas confusos: login funciona localmente mas falha após o deploy, pagamentos estouram timeout, imagens não são enviadas, ou jobs em background nunca rodam. O caminho de código é o mesmo, mas o app está apontando para o lugar errado ou falta um valor obrigatório.
O objetivo é runs repetíveis em todo ambiente. Dev, staging e prod podem usar valores diferentes, mas devem seguir as mesmas regras. Se uma variável é obrigatória em produção, trate-a como obrigatória em todo lugar. Se staging usa um banco diferente, ainda deve usar o mesmo esquema e o mesmo tipo de conexão.
Exemplo: um app gerado por IA é deployado e imediatamente lança “DATABASE_URL is undefined.” Localmente, o desenvolvedor tinha isso em um arquivo .env privado. Em produção, nunca foi definido. A correção não é caçar no código. É definir config obrigatória, validar na inicialização e setar em cada ambiente.
Dev vs staging vs prod: o que muda e o que não pode mudar
Dev, staging e prod são o mesmo app em três lugares diferentes.
- Dev é onde você constrói e testa rapidamente no laptop.
- Staging é um ensaio que deve se comportar como produção, mas sem clientes reais.
- Prod é o sistema ao vivo do qual as pessoas dependem.
Algumas coisas devem diferir entre ambientes porque apontam para serviços ou dados distintos. Outras devem permanecer idênticas para que você realmente teste o que vai entregar.
O que deve mudar
Mantenha o código do app igual, mas troque os valores ao redor:
- URLs de serviço (base URL da API, URL de callback OAuth, URL de webhook)
- Chaves e segredos (credenciais diferentes por ambiente)
- Fontes de dados (bancos e buckets separados, ou pelo menos schemas separados)
- Feature flags (padrões seguros em produção, mais toggles em dev)
- Nível de logs (mais detalhe em dev, menos ruído em prod)
O ambiente deve decidir esses valores, não a máquina local do desenvolvedor.
O que não pode mudar
O build e o runtime devem bater entre staging e produção: mesmas dependências, mesmo passo de build, mesmo comando de inicialização e mesma versão de runtime. Se staging roda node 20 e produção roda node 16, você está testando um app diferente.
Evite “só esse ajuste rápido” em produção, como editar um arquivo de config no servidor ou adicionar uma var de ambiente faltante manualmente sem registrar a mudança. Esses consertos pontuais criam falhas que você não consegue reproduzir depois. Um exemplo comum: alguém corrige rápido a URL de redirect de auth em produção, staging fica desatualizado, e no próximo deploy o login quebra.
Variáveis de ambiente 101 (sem jargão)
Uma variável de ambiente (env var) é um ajuste que seu app lê quando inicia. Ela vive fora do código, geralmente fornecida pelo terminal, pelo provedor de hospedagem ou pela ferramenta de deploy.
Pense em env vars como inputs para seu app. Trate-as como requisitos, não sugestões. Se um valor estiver faltando, o app deve falhar rápido com uma mensagem clara, não mancar e quebrar depois.
Uma forma simples de decidir o que vai onde:
- Env vars: valores que mudam por ambiente ou são sensíveis. Exemplos:
DATABASE_URL,JWT_SECRET,STRIPE_API_KEY,S3_BUCKET,APP_ENV. - Código: defaults e lógica que devem ser iguais em todo lugar. Exemplo: “sessões expiram após 7 dias.”
- Arquivos de config (no git): configurações não secretas que você quer revisar e versionar. Exemplo: feature flags seguras, rótulos da UI, origens CORS permitidas (somente se não forem sensíveis).
A nomeação é onde times se perdem. Escolha uma convenção e mantenha: tudo em caps, palavras separadas por underscores, e um prefixo se você tiver múltiplos serviços. Evite quase-duplicatas como DB_URL, DATABASE e DATABASE_URL espalhadas pelo app.
Uma armadilha comum são env vars “opcionais” que desativam features silenciosamente. Por exemplo, um app gerado por IA pode envolver envio de email em if (process.env.SMTP_PASSWORD) e nunca avisar quando está faltando. O resultado: signups funcionam localmente, mas resets de senha não chegam após o deploy.
Regra melhor: se uma feature está habilitada naquele ambiente, suas env vars obrigatórias devem estar presentes, ou o app deve parar e dizer o que está faltando.
Passo a passo: criar uma estrutura de config simples e consistente
A maioria dos bugs “it works on my machine” acontece porque a config está espalhada. Uma pessoa define valores em um arquivo local, outra define no dashboard do host, e o app escolhe silenciosamente o que encontrar primeiro. Decida uma estrutura e mantenha-a.
1) Escolha uma fonte única de verdade
Para a maioria dos apps web, a regra mais limpa é: variáveis de ambiente são a fonte de verdade. Um .env local pode ser uma conveniência para desenvolvimento, mas seu código deve ler a config da mesma forma em todo lugar.
Se você precisar suportar tanto arquivo de config quanto env vars, defina uma prioridade clara (por exemplo: env vars sobrescrevem valores do arquivo) e documente para não haver surpresas.
2) Adicione uma flag de ambiente explícita
Faça o app anunciar em qual ambiente acha que está rodando. Use uma variável como APP_ENV com três valores permitidos: development, staging, production. Evite adivinhar por domínio ou “se debug é true”.
Quando o ambiente é explícito, você pode fazer escolhas seguras por padrão, como logs verbosos em dev e mais silenciosos em prod.
Uma configuração prática para a maioria dos times:
- Mantenha um arquivo template com commit como
.env.exampleque liste todas as variáveis requeridas (sem segredos reais). - Use um
.envlocal para conveniência e mantenha-o fora do versionamento. - Armazene valores de staging e produção nas configurações de ambiente do provedor de hospedagem.
- Carregue a config em um único lugar (um módulo de config) e importe onde for preciso.
3) Torne os padrões seguros
Defaults são aceitáveis para desenvolvimento (como uma URL de banco local). Em produção, evite defaults para qualquer coisa sensível. Um DATABASE_URL ausente em produção deve falhar rápido, não cair silenciosamente em algo não intencional.
4) Documente o que os colegas precisam para rodar o app
Coloque as variáveis necessárias em um lugar só (normalmente .env.example mais uma nota curta no README). Isso importa ainda mais para apps gerados por IA, onde a config tende a crescer aleatoriamente e acabar espalhada entre código, arquivos e dashboards.
Valide env vars na inicialização para evitar surpresas
Muitos problemas “it works on my machine” acontecem porque o app inicia com configurações faltantes ou erradas, e só falha mais tarde quando um usuário alcança uma página específica. Uma correção simples é validar variáveis de ambiente uma vez, logo na inicialização da aplicação, e recusar rodar se algo estiver errado.
Falhe rápido com checagens claras
Trate a config como dados de entrada. Se valores obrigatórios estiverem faltando, pare o app e logue um erro que diga exatamente o que setar (sem vazar segredos).
O que vale a pena validar cedo:
- Presença: valores obrigatórios como
DATABASE_URL,AUTH_SECRET,PORT - Tipo:
PORTé número,DEBUGé booleano, timeouts são inteiros - Formato: URLs parecem URLs, emails parecem emails
- Regras entre campos: se
FEATURE_X=true, também exigirFEATURE_X_KEY - Valores permitidos:
APP_ENVdeve ser um dedevelopment,staging,production
Após a validação, registre um breve resumo de inicialização como nome do ambiente, versão do app e quais features opcionais estão habilitadas. Não imprima segredos, strings de conexão completas ou tokens. Se precisar confirmar, registre apenas que um valor está definido, ou uma impressão segura (por exemplo, os últimos 4 caracteres).
Adicione um comando de self-test de config
Um autoteste leve de config torna deploys mais seguros porque você pode rodá-lo antes de iniciar o servidor.
Por exemplo:
config:testcarrega env vars, valida e sai com código 0/1- Imprime erros acionáveis (chaves faltantes, tipos errados, URLs inválidas)
- Pode confirmar conectividade onde for seguro (por exemplo, consegue alcançar o host do banco) sem vazar credenciais
Mantenha segredos fora do código (e fora dos logs)
Um “segredo” é qualquer coisa que dá acesso: chaves de API, segredos de cliente OAuth, chaves de assinatura de sessão, senhas de banco, chaves privadas de criptografia, segredos de assinatura de webhook e tokens internos. Se alguém o obtiver, pode se passar por você ou pelo seu app.
Apps gerados por IA frequentemente vazam segredos em dois lugares: no código e nos logs. Uma chave é hardcoded “só para testar”, uma string de conexão cai num commit, ou alguém imprime process.env para debugar e esquece de remover antes de subir.
Regras que evitam a maioria dos incidentes:
- Nunca commite segredos ao repositório, nem mesmo “temporários”.
- Nunca envie segredos ao navegador ou ao cliente móvel. Se o usuário pode ver, não é segredo.
- Nunca logue segredos ou cabeçalhos completos. Redija tokens e senhas.
- Prefira tokens de curta validade quando possível.
Se suspeitar que uma chave foi exposta, trate-a como comprometida. Roteie-a, e depois confirme que o valor antigo está realmente inválido (muitas plataformas mantêm chaves antigas ativas até você desativá-las). Verifique também histórico de deploys, logs e qualquer screenshot ou relatório compartilhado.
Use credenciais separadas por ambiente. Dev, staging e prod não devem compartilhar o mesmo usuário de banco, chave de API ou segredo de assinatura. Assim, um vazamento em staging não desbloqueia produção.
Faça staging se comportar como produção (o suficiente para ser útil)
Staging é onde você pega problemas que só aparecem depois do deploy, mas só funciona se se comportar como produção nas partes que importam.
Comece com builds repetíveis. Se staging roda Node 20 e produção Node 18, ou um ambiente instala versões diferentes de dependência, você não está testando o mesmo app. Trave a versão do runtime e das dependências (pin versions, commite o lockfile e use o mesmo comando de build em todo lugar). Evite passos de instalação específicos de ambiente que mudem o comportamento ou pulem checagens.
Mantenha staging próximo de prod nos caminhos críticos: mesmo tipo de banco, mesmo cache ou fila se você usa um, e a mesma sequência de inicialização (migrations, seed, workers). Não precisa ter escala total ou dados reais, mas deve usar os mesmos serviços e a mesma ordem de operações.
Health checks são seu sistema de aviso precoce. Um deploy em staging deve falhar rápido se não consegue conectar ao banco, se migrations estão pendentes ou se variáveis obrigatórias estão faltando.
Um padrão simples:
- Mesmo runtime e lockfile de dependências em dev, staging e prod
- Mesmo artefato de build promovido de staging para prod (não reconstruído de forma diferente)
- Mesmos passos de startup (migrar, então iniciar o processo web, depois os workers)
- Um health check básico que verifica conexão com DB e alguns endpoints-chave
- Uma impressão registrada da “impressão digital” de config por deploy (quais nomes de env var foram setados, feature flags on/off), sem valores
Erros comuns que causam falhas em runtime
A maioria dos bugs “funcionava ontem” não é aleatória. Geralmente vem de drift de configuração: alguém mudou um ajuste, aplicou um hotfix, ou mexeu em um segredo em um lugar e esqueceu de documentar. Uma semana depois, um deploy reverte o código mas não as configurações, e o app quebra de forma que parece misteriosa.
Outro problema clássico é depender de arquivos locais que não existirão em produção. Seu laptop pode ter uma pasta uploads/ com permissões permissivas, um SQLite local, ou um .env que nunca sobe pro servidor. Em produção, o filesystem pode ser read-only, containers podem reiniciar a qualquer momento, e “aquele arquivo” simplesmente não existe.
Erros que frequentemente viram outages:
- Tratar warnings como aceitáveis: env vars faltantes, defaults de fallback, ou configurações “opcionais” que depois viram obrigatórias
- Misturar variáveis de cliente e servidor em apps web, expondo segredos ou quebrando builds quando o browser não consegue ler valores que deveriam ser só do servidor
- Esquecer de registrar URLs de callback OAuth ou de pagamento para um ambiente
- Assumir que paths locais existem em todo lugar (uploads, diretórios temporários, DB local, certificados)
- Fazer mudanças emergenciais na dashboard do host e não sincronizar essa mudança na documentação compartilhada
Pequeno exemplo: um founder tem um protótipo gerado por IA que roda bem em um ambiente dev hospedado, mas login em produção falha. A causa raiz é simples: o app caiu para um callback dev porque a variável de produção está ausente. Sem erro claro, só um loop de redirect.
Checklist rápido antes de enviar um release
Uma rotina pré-ship curta pega os problemas de config mais comuns antes dos usuários.
Execute-a no ambiente exato que você vai liberar (staging como ensaio, produção para o release real).
- Confirme que todas as variáveis obrigatórias estão setadas (e não vazias). Verifique valores que diferem por ambiente: base URLs, chaves de API, configurações de email.
- Verifique se o app aponta para o banco e armazenamento corretos (host/nome do DB, bucket de storage, fila, cache). Um valor errado pode mandar tráfego de produção pra staging.
- Cheque configurações de auth end to end: URLs de redirect, domínio de cookie, settings de sessão, origens CORS permitidas.
- Rode validação de config na inicialização antes do release. O app deve recusar iniciar se algo crítico estiver faltando ou obviamente errado.
- Faça um fluxo realista end-to-end em staging: signup, login, reset de senha, pagamento, upload, export, convidar um colega.
Se os testes em staging passam mas o login em produção falha, a causa frequentemente é básica: redirect aponta pro domínio errado, domínio do cookie incorreto, ou um segredo de auth obrigatório não está setado.
Exemplo: limpeza real de configuração em um app gerado por IA
Um founder tinha um app gerado por IA que parecia ok localmente, mas falhava logo após o deploy. O problema não era complexo. Em produção havia nomes de variáveis diferentes, um segredo faltando e uma URL ainda apontando para localhost.
O que quebrou depois do deploy
Usuários conseguiam abrir o site, mas o login falhava. Os sintomas variavam: às vezes tela em branco, às vezes erro 500 genérico.
Causas raiz:
- URL de callback OAuth ainda configurada como
http://localhost:3000/... - Um segredo de auth obrigatório (usado para assinar sessões ou tokens) não definido em produção
- Um
DATABASE_URLde staging sendo usado por engano em produção
Como consertamos (sem chute)
Primeiro auditamos variáveis de ambiente: todo valor que a app lê, de onde vem e qual ambiente precisa dele. Padronizamos nomes e separamos valores claramente entre dev, staging e prod.
Também adicionamos guardrails para que falhas apareçam imediatamente:
- Validar variáveis obrigatórias na inicialização e listar as ausentes
- Validar formatos (por exemplo, URLs devem ser HTTPS em produção, segredos devem ter tamanho mínimo)
- Bloquear defaults inseguros em produção (sem callbacks localhost, sem chaves placeholder)
- Logar apenas dicas seguras (nunca imprimir segredos)
Depois disso, os deploys ficaram previsíveis. Staging passou a se comportar como produção onde importava, e problemas surgiam na inicialização em vez de durante o login de um usuário.
Próximos passos: endureça sua configuração sem travar o time
Não tente consertar tudo de uma vez. Escolha uma mudança pequena que reduza surpresas imediatamente, verifique localmente e após o deploy, e faça uma passada curta de follow-up antes do próximo release.
Boas vitórias de “hoje”:
- Adicione um
.env.exampleque liste todas as variáveis obrigatórias (com valores placeholder seguros) - Adicione validação na inicialização para que o app falhe rápido quando uma variável estiver faltando ou malformada
- Remova chaves hardcoded, URLs e flags de debug do código e mova-os para config de ambiente
- Pare de imprimir segredos nos logs (mesmo logs de debug “temporários”)
- Renomeie variáveis confusas para que reflitam o que realmente fazem
Depois, faça uma passada de endurecimento com limite de tempo:
- Compare nomes de variáveis entre dev, staging e prod e garanta que só os valores mudem
- Recheque configurações de auth por ambiente (redirect URLs, domínios de cookie, callbacks OAuth)
- Confirme que segredos estão no cofre de segredos da sua plataforma de deploy, não no repo
- Faça um deploy limpo do zero para pegar variáveis e suposições faltantes
Se você herdou um repositório bagunçado gerado por IA, comece por uma auditoria de config e segredos antes de tocar em features. É geralmente aí que ficam defaults ocultos, vazamentos e falhas só no deploy.
Se estiver travado, FixMyMess (fixmymess.ai) se especializa em diagnosticar e reparar apps gerados por IA, incluindo drift de config, falhas de auth, segredos expostos e prontidão para deploy. A auditoria de código gratuita pode ajudar a ver o que falta e o que consertar primeiro.
Perguntas Frequentes
O que “it works on my machine” realmente quer dizer?
Normalmente significa que o código está correto, mas o ambiente mudou depois do deploy. Algo que seu laptop fornecia automaticamente (variáveis de ambiente, arquivos locais, tokens em cache, dados seed, um banco diferente) não está presente em staging ou produção, então a aplicação quebra apesar do repositório não ter mudado.
O que devo checar primeiro quando uma app quebra só depois do deploy?
Comece checando a configuração, não a lógica de negócio. Compare variáveis de ambiente, versões de runtime (como Node) e endpoints de serviço entre o local e o ambiente deployado, e então reproduza o problema com os mesmos inputs que o servidor recebe.
Qual é o erro de configuração mais comum que causa falhas no deploy?
Variáveis de ambiente faltando ou incorretas são a causa mais comum. Um sinal típico é um erro como “DATABASE_URL is undefined”, ou funcionalidades que falham silenciosamente porque uma chave não foi definida em produção.
O que deve ser diferente entre dev, staging e produção?
Mantenha uma única aplicação com três conjuntos de valores. Dev é para velocidade, staging é um ensaio que deve se comportar como produção, e produção é o sistema ao vivo; altere URLs de serviço, segredos e fontes de dados por ambiente, mas mantenha build, versão do runtime e passos de inicialização consistentes.
O que deve ficar em env vars versus código versus arquivos de configuração?
Trate variáveis de ambiente como inputs que mudam por ambiente ou são sensíveis. Coloque regras de negócio e defaults que nunca mudam no código, e mantenha configurações não secretas em arquivos versionados apenas quando for seguro expô-las.
Como evito comportamento confuso do tipo “em qual ambiente estou?”?
Adicione uma única flag explícita como APP_ENV e aceite apenas valores reconhecidos, por exemplo development, staging e production. Não tente adivinhar pelo domínio ou por um toggle de debug, porque isso cria diferenças ocultas de comportamento difíceis de reproduzir.
Como faço para problemas de env vars falharem rápido em vez de falharem depois?
Valide tudo na inicialização e recuse rodar quando valores obrigatórios estiverem ausentes ou malformados. Assim você pega problemas antes que usuários reais encontrem uma página quebrada, e a mensagem de erro pode dizer exatamente o que definir sem vazar segredos.
Vale a pena adicionar um comando config:test ao meu app?
Sim. Um pequeno auto-teste de configuração é um dos passos pré-deploy mais seguros. Ele carrega a configuração, valida tipos e formatos, e sai com código 0/1 com erros acionáveis, para que você possa interromper um release ruim antes do servidor web iniciar.
Como evito vazamento de segredos em apps gerados por IA?
Mantenha segredos fora do repositório, fora do código do cliente e fora dos logs. Se suspeitar que um segredo foi exposto, roteie-o imediatamente e garanta credenciais separadas por ambiente para que um vazamento em staging não dê acesso à produção.
Qual a forma mais rápida de estabilizar um app gerado por IA que não roda em produção?
Comece pela estrutura de configuração: centralize o carregamento, padronize nomes de variáveis e adicione validação na inicialização. Se herdou um repositório gerado por IA que falha após o deploy, FixMyMess pode rodar uma auditoria grátis de código e ajudar a reparar drift de configuração, problemas de autenticação e prontidão para deploy rapidamente.