Desligamento gracioso em servidores Node: evite 502s aleatórios
Aprenda desligamento gracioso em servidores Node para drenar conexões keep-alive, finalizar requisições em andamento, fechar pools de BD e evitar 502s aleatórios durante deploys.
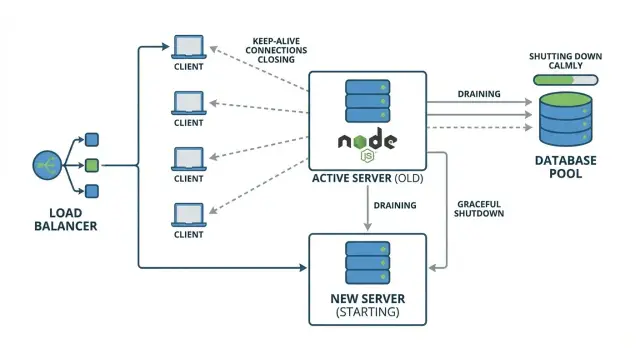
Por que deploys podem causar 502s aleatórios
Um “502 aleatório” durante um deploy normalmente significa que seu proxy reverso ou balanceador de carga enviou uma requisição para uma instância do app que já estava em processo de desligamento. Por um breve momento o proxy pode ainda considerar a instância disponível, ou pode reutilizar uma conexão existente que já não tem um servidor saudável do outro lado.
Parece aleatório porque depende do timing. A maioria dos usuários acerta instâncias que ainda estão rodando e obtém uma resposta normal. Um grupo menor pega a janela azarada: a requisição chega exatamente quando o processo sai, quando o servidor para de escutar, ou logo depois que uma conexão é cortada.
Keep-alive pode piorar isso. Clientes e proxies reutilizam conexões TCP para múltiplas requisições, então durante um deploy você pode ter conexões de longa duração ainda enviando requisições para uma instância que está sendo substituída. Se o app fecha o servidor imediatamente, essas conexões reaproveitadas falham de maneiras confusas, e o proxy frequentemente registra como 502.
A ideia central é desligamento gracioso: parar de aceitar novo trabalho, terminar o trabalho já em andamento e então sair.
Um exemplo simples: você faz deploy de uma nova versão, seu orquestrador envia um sinal de parada e o Node sai imediatamente. Um usuário está no meio de um checkout (uma requisição em andamento). O navegador de outro usuário reutiliza uma conexão keep-alive para buscar a próxima página. Ambas requisições são interrompidas. Todo mundo roteado para outras instâncias nem percebe.
Um desligamento que drena conexões e espera brevemente pelas requisições em andamento evita essas falhas “aleatórias” e torna os deploys previsíveis.
O que você realmente está desligando
Um servidor Node não é só “um processo que para”. É um processo no meio de uma conversa com clientes, segurando recursos como sockets, timers e conexões de banco de dados. Desligamento gracioso é, na maior parte, encerrar essas conversas na ordem correta.
O ciclo típico de uma requisição é: um cliente conecta, envia uma requisição, seu app executa código (frequentemente chamando o banco de dados ou outra API), então o servidor envia uma resposta e a requisição termina. Se você matar o processo no meio, o cliente recebe uma resposta quebrada, e seu balanceador pode reportar como 502.
“Requisições em andamento” são requisições que começaram mas não terminaram. São as que mais correm risco de serem cortadas durante deploys. Mesmo requisições curtas podem se tornar em andamento se o banco de dados estiver lento, uma API downstream travar, ou o event loop estiver ocupado.
Keep-alive adiciona outra camada. Uma conexão TCP pode transportar muitas requisições ao longo do tempo. Durante o shutdown você quer parar de aceitar novas requisições, mas pode ainda ter sockets keep-alive abertos que estão ociosos ou esperando a próxima requisição.
Alguns trabalhos ficam “em andamento” por mais tempo e precisam de cuidado extra: uploads (arquivos grandes, clientes lentos), exportações/geração de relatórios, respostas em streaming e Server-Sent Events (SSE), e WebSockets (não são “requisições” no sentido usual, mas continuam sendo conexões ativas).
Portanto você está desligando três coisas: novo tráfego de entrada, requisições em andamento e qualquer conexão de longa duração que mantenha o processo ocupado mesmo quando ele parece ocioso.
Sinais e tempo: como o shutdown é acionado
A maioria dos problemas de deploy começa do mesmo jeito: seu processo Node recebe a ordem para parar, mas ninguém sabe ao certo quando, ou quanto tempo ele tem para terminar.
No Linux, dois sinais importam mais:
- SIGTERM: “Por favor saia agora, mas limpe antes.” É o que plataformas enviam durante uma parada normal ou deploy.
- SIGINT: “Pare porque um humano pediu.” É o que você recebe com Ctrl+C no terminal.
Gerenciadores de processo e containers normalmente seguem uma sequência simples: um deploy começa, a instância antiga recebe SIGTERM, e uma contagem regressiva inicia (frequentemente chamada de período de graça). Se o app sai a tempo, ótimo. Se não, a plataforma envia um kill forçado (SIGKILL) e o processo desaparece instantaneamente.
Se você não fizer nada, o Node continuará rodando até ser forçado a sair. Isso significa que sockets keep-alive podem ser cortados no meio de uma requisição, trabalho em andamento pode nunca terminar e conexões de banco podem ficar penduradas. O resultado aparece como “502s aleatórios”, mesmo que os logs do app pareçam normais.
Torne o comportamento de shutdown consistente, não um esforço por tentativa. Decida desde o início qual sinal você trata (normalmente SIGTERM), quanto tempo você vai esperar antes de forçar a saída, e o que para primeiro (novo tráfego) versus o que você tenta finalizar (requisições em andamento).
Quando o shutdown é previsível, deploys deixam de ser questão de sorte.
Passo a passo: pare de aceitar novo tráfego com segurança
Um deploy não deveria parecer puxar o cabo de força. O objetivo é simples: pare o novo tráfego primeiro, depois finalize o que já está em andamento.
Comece adicionando uma única flag draining no seu app. Quando ela vira true, o servidor ainda está vivo, mas está se preparando para sair.
Uma ordem segura para a maioria das APIs HTTP:
- Vire
draining = trueassim que receber o sinal de shutdown. - Faça sua verificação de readiness falhar, para que o load balancer pare de enviar novas requisições para essa instância.
- Para qualquer nova requisição que ainda chegar, retorne um
503 Service Unavailableclaro com uma mensagem curta. - Diga ao servidor HTTP para parar de aceitar novas conexões.
- Mantenha o processo rodando enquanto as requisições existentes terminam (com um timeout, coberto abaixo).
Um exemplo pequeno (estilo Express) fica assim:
let draining = false;
app.get('/ready', (req, res) => {
if (draining) return res.sendStatus(503);
res.sendStatus(200);
});
app.use((req, res, next) => {
if (draining) return res.status(503).send('Server is restarting, try again');
next();
});
process.on('SIGTERM', () => {
draining = true;
server.close(); // stop accepting new connections
});
Mantenha os health checks honestos. Durante o shutdown, você quer que o “ready” fique vermelho rapidamente, mas ainda quer uma checagem básica de “alive” verde até a saída real. Isso ajuda a evitar que a plataforma mate o processo cedo demais e crie exatamente os 502s que você está tentando evitar.
Drene conexões keep-alive sem derrubar usuários
Keep-alive significa que o navegador (ou um load balancer) pode reutilizar a mesma conexão TCP para múltiplas requisições. Isso é bom para velocidade, mas surpreende durante deploys: você para de aceitar novas conexões, porém sockets keep-alive antigos permanecem abertos e podem enviar outra requisição para um processo que está drenando.
O server.close() do Node para novas conexões, mas não fecha automaticamente sockets keep-alive existentes. Para drenar com segurança, rastreie os sockets conforme eles conectam, então feche gentilmente os ociosos enquanto deixa requisições ativas terminarem.
Um padrão simples:
- Mantenha um
Setde sockets a partir do eventoconnectiondo servidor. - Marque sockets como “ocupados” enquanto uma requisição está em progresso.
- No shutdown, chame
server.close(), entãosocket.end()para sockets ociosos. - Após um prazo,
socket.destroy()em qualquer coisa que ainda esteja aberta.
Aqui está um exemplo compacto:
const sockets = new Set();
const busy = new Set();
server.on('connection', (socket) => {
sockets.add(socket);
socket.on('close', () => { sockets.delete(socket); busy.delete(socket); });
});
server.on('request', (req, res) => {
busy.add(req.socket);
res.on('finish', () => busy.delete(req.socket));
});
async function shutdown() {
server.close();
for (const s of sockets) if (!busy.has(s)) s.end();
setTimeout(() => { for (const s of sockets) s.destroy(); }, 10_000);
}
Esse prazo para fechar à força importa. Sem ele, um cliente travado pode manter a instância antiga viva e transformar um rollout em uma mistura de timeouts e erros intermitentes do proxy.
Finalize requisições em andamento com um timeout claro
Quando um deploy começa, você quer que as requisições existentes terminem normalmente, mas também precisa de um limite rígido para que o processo antigo não fique pendurado para sempre. A abordagem mais simples é rastrear requisições ativas e usar a flag draining.
Aqui vai um padrão pequeno que funciona com a maioria dos frameworks HTTP do Node:
let draining = false;
let active = 0;
app.use((req, res, next) => {
if (draining) return res.status(503).set('Connection', 'close').send('Server restarting');
active += 1;
res.on('finish', () => { active -= 1; });
res.on('close', () => { active -= 1; });
next();
});
function beginShutdown() {
draining = true;
}
Enquanto estiver drenando, evite criar novo trabalho que sobreviva à requisição. Um erro comum é deixar uma requisição enfileirar tarefas em background (e-mails, relatórios, limpeza) depois que você já decidiu desligar. Se precisar enfileirar, proteja com a mesma flag draining e pule durante o shutdown.
Defina um timeout de shutdown que combine com seu tráfego. Muitas equipes começam com 10 a 30 segundos e depois ajustam com base em endpoints realmente lentos.
O fluxo é direto: comece a drenar e pare de aceitar novas requisições, espere até que active === 0, e se o timer estourar, force o fechamento das conexões restantes e saia.
Se uma requisição chegar depois do início do draining, retorne 503 Service Unavailable e adicione Connection: close. Isso informa a clientes e balanceadores para não manterem o socket aberto, o que reduz as falhas estranhas de keep-alive (meio-fechado) que frequentemente aparecem como 502s.
Feche pools de BD e outros recursos limpos
Fechar seu servidor HTTP não é o mesmo que deixar o processo Node sair. Um pool de banco de dados mantém sockets TCP abertos (e às vezes timers), então o event loop ainda tem trabalho a fazer. Por isso um deploy pode parecer “concluído” enquanto o processo antigo fica rondando, até que seja morto e gere erros.
“Fechar o pool” normalmente significa: parar de emprestar novas conexões, fechar as ociosas e esperar até que queries ativas terminem. Exemplos comuns:
- PostgreSQL (
pg):await pool.end() - MySQL (
mysql2):await pool.end() - Mongoose:
await mongoose.connection.close()(e parar novas operações)
A ordem importa. Pare de aceitar novo tráfego primeiro (para não iniciar novo trabalho no DB), deixe as requisições em andamento terminarem, então feche o pool de BD. Depois disso, desligue o resto.
Queries pendentes e transações precisam de uma regra clara. Durante o shutdown, bloqueie novas requisições que iniciem writes, deixe as atuais terminarem até um timeout e depois falhe rápido. Se você tem transações longas, procure finalizá-las rapidamente e fazer rollback se atingir o prazo.
async function shutdown() {
server.close(); // stop new HTTP connections
await Promise.race([
waitForInFlightToFinish(),
sleep(10_000),
]);
await dbPool.end();
await redis?.quit();
await queue?.close();
}
Outros recursos que mantêm um processo vivo incluem clientes Redis, filas de trabalho, conexões Kafka/Rabbit, cron timers e handles de arquivo abertos. Fechá-los explicitamente transforma o shutdown em algo confiável.
Jobs em background: não esqueça o trabalho escondido
O tráfego HTTP é só metade da história. Muitos servidores Node rodam trabalho em background no mesmo processo: consumidores de fila, tarefas cron, atualizações agendadas e loops de worker. Durante um deploy, esses podem manter o processo vivo por mais tempo que o esperado, ou continuar mexendo no banco após o início do shutdown.
A primeira regra: assim que o shutdown começa, pare de iniciar novo trabalho em background. Pause consumo de filas, pare polling e impeça cron de disparar novas execuções. Se estiver usando uma biblioteca, procure por um método real de pause/stop (não apenas disconnect), porque desconectar pode disparar retries e ruído extra.
Depois de parar novos jobs, deixe os jobs atuais terminarem, mas apenas até um limite claro. Caso contrário um job travado pode atrasar o shutdown até a plataforma matar o processo, e é aí que os erros disparam.
Cancelar de forma segura vs esperar
Escolha baseado no que o job faz:
- Esperar para trabalhos com limite conhecido (enviar um e-mail, redimensionar uma imagem).
- Cancelar jobs longos com fim incerto (importações grandes, chamadas de terceiros que travam).
- Cancelar qualquer coisa segurando uma transação DB aberta.
- Esperar jobs que podem salvar ponto e continuar depois.
- Cancelar jobs que, se executados duas vezes, causariam dano (cobrar duas vezes, reembolsos duplicados).
Se for cancelar, faça de propósito: defina um flag isShuttingDown, pare de puxar novas mensagens e deixe os jobs verificarem o flag em pontos seguros para saírem limpos.
O que logar para saber o que impediu a saída
Logue o suficiente para responder “o que ainda estava rodando?” Capture o tempo de início do shutdown e o sinal, contagens de jobs ativos (por nome de fila), a idade do job mais antigo e IDs, qual subsistema ainda está aberto (cliente de fila, cron, timers) e se você atingiu o prazo de shutdown e forçou algo a parar.
Casos especiais: WebSockets, streaming e uploads
O shutdown é mais simples quando as requisições são curtas. O problema começa quando conexões ficam abertas por minutos.
WebSockets: fechar sem surpreender usuários
WebSockets são de longa duração por design, então não apenas mate o processo. Durante o shutdown, pare de aceitar novas conexões de socket, depois notifique clientes ativos e dê uma janela curta para que se reconectem.
Um padrão prático: envie um evento “server restarting”, pare novas mensagens e feche com um código de fechamento normal (não um erro). Se você tem um load balancer, garanta que ele pare de rotear novas conexões para a instância antes de começar a fechar sockets.
Streaming, SSE e long polls
SSE e outros endpoints em streaming podem parecer “ociosos” para proxies mesmo quando estão funcionando. Durante o shutdown, termine streams de forma limpa para que o cliente consiga reconectar, e defina um tempo máximo de drenagem para não esperar para sempre.
Com long polling, clientes re-tentam rápido. Retornar uma resposta clara de “tente novamente” é melhor do que deixar a conexão morrer e aparecer como 502.
Uma abordagem prática: pare de aceitar novas conexões primeiro, marque a instância como draining no health check, envie uma mensagem final e feche streams/sockets graciosamente, dê uploads um curto período de graça e depois aborte, e use um timeout único para tudo para que os deploys terminem.
Uploads de arquivos em andamento
Se um cliente está enviando um upload, matar a conexão pode corromper o arquivo e desperdiçar minutos. Prefira uploads resumíveis quando possível. Se não, escreva em um arquivo temporário e só "commit" quando o upload completar.
Também verifique timeouts do proxy reverso (Nginx, ALB, etc.). Um idle timeout menor que seu stream ou upload pode parecer um 502 relacionado a deploy mesmo quando seu código está correto.
Erros comuns que ainda causam 502s
A maioria dos “502s aleatórios” durante deploys não é aleatória. Acontecem quando o shutdown ocorre na ordem errada, ou quando o load balancer continua roteando requisições para um processo que já está indo embora.
Um erro de timing é esperar tempo demais para parar novo tráfego. Se você só começa a drenar depois de começar a fechar coisas, cria uma janela onde requisições novas chegam mas recursos críticos (como conexões DB) já não estão disponíveis. O resultado parece uma rede instável.
Outro problema clássico é fechar o pool de banco primeiro. Requisições que já passaram pelo roteamento ainda precisam de queries, sessões ou transações. Se o pool sumiu, essas requisições falham no meio.
Ambientes de deploy normalmente enviam SIGTERM, não SIGINT. Se você só testou com Ctrl+C localmente, seu handler de shutdown pode nunca rodar em produção. Isso aparece muito em código Node gerado por ferramentas: roda bem até o primeiro deploy real, então a plataforma mata porque não respondeu ao sinal esperado.
Os problemas que mais quebram o shutdown são simples: não entrar no modo drain cedo, não ter um prazo de shutdown (ou um tão curto que corta usuários ativos), manter readiness verde enquanto drena de modo que o tráfego continue chegando, fechar sockets keep-alive agressivamente em vez de drená-los, e esquecer que trabalho em background pode manter o processo vivo depois que o servidor HTTP foi fechado.
Se só puder corrigir uma coisa, corrija os health checks. Assim que o draining começa, a instância deve parar de parecer pronta rapidamente para que o tráfego vá para outro lugar antes de você desmontar qualquer coisa.
Checklist rápido antes de deployar
Faça um dry run em staging pouco antes de um release. Quando o processo é avisado para parar, ele deve parar de aceitar novo trabalho, terminar o que começou e não deixar pontas soltas.
Uma checklist rápida:
- Envie um sinal real de shutdown (SIGTERM) e confirme que o app reage imediatamente: uma linha clara de log, readiness vira, e o servidor para de aceitar novas conexões.
- Enquanto estiver drenando, confirme que novas requisições recebem uma resposta controlada (por exemplo, 503 com mensagem curta) em vez de ficarem pendurando até o timeout do balanceador.
- Crie uma requisição lenta (sleep, query pesada ou render grande) e confirme que ela consegue terminar. Também confirme que você tem um timeout rígido para o processo sair a tempo se algo travar.
- Verifique cleanup: pool de banco fecha, clientes de fila desconectam e timers param. Após a saída, o processo não deve continuar vivo por handles abertos.
- Revise logs de shutdown fim a fim: tempo de início, quando begins draining, contagem de requisições ativas e uma linha final “shutdown complete”.
Uma forma simples de detectar problemas é rodar dois curls ao mesmo tempo: um request longo e outro logo depois de mandar SIGTERM. Se o longo terminar e o novo receber uma resposta rápida e previsível, você está perto.
Se seu servidor foi gerado por uma ferramenta de IA (Lovable, Bolt, v0, Cursor, Replit), esses hooks muitas vezes faltam ou estão meio quebrados. Corrigi-los cedo evita a sensação de “502s aleatórios” durante deploys.
Exemplo: rolling deploy sem perder requisições
Imagine um setup de produção pequeno: duas instâncias Node API (A e B) atrás de um load balancer. Clientes usam keep-alive, então uma aba do navegador pode reutilizar a mesma conexão TCP para a instância A por minutos.
Durante um rolling deploy, o load balancer começa a enviar novas requisições para B enquanto A está sendo substituída. O problema é o keep-alive: mesmo que o balanceador pare de escolher A para novas conexões, alguns clientes ainda têm uma conexão aberta para A e continuarão enviando requisições por ela.
É daí que vêm os 502s intermitentes. Se A recebe SIGTERM e sai rápido, essas conexões reutilizadas apontam para um processo que não existe mais. A próxima requisição nesse socket falha e o proxy reporta 502.
Um shutdown gracioso evita isso fazendo três coisas em ordem:
- parar de aceitar novas conexões em A
- drenar conexões keep-alive existentes
- esperar requisições em andamento até um timeout claro, então fechar pools de BD e sair
Para testar localmente ou em staging: adicione um endpoint lento (por exemplo, rota que espera 10 segundos), envie requisições repetidas com keep-alive habilitado e então reinicie apenas uma instância. Se o drain funcionar, a requisição lenta termina e você não vê 502s intermitentes.
Próximos passos: torne deploys chatos de novo
O desligamento gracioso só ajuda se você conseguir ver ele funcionando sob tráfego real. Adicione logs de shutdown que mostrem a ordem dos eventos: sinal recebido, readiness toggle, parada de aceitar novas requisições, contagem de requisições ativas, drain de keep-alive, pool de BD fechado, saída do processo.
Antes do próximo release, rode um teste de “requisição lenta” em staging: torne um endpoint intencionalmente lento (10–20 segundos), então faça um deploy enquanto essa requisição está em andamento. Você quer dois resultados: a requisição lenta termina com sucesso, e novas requisições vão para a instância nova sem erros.
Se a base de código estiver bagunçada ou gerada por IA e os deploys continuarem imprevisíveis, uma auditoria focada pode ser mais rápida do que ajustes aleatórios. FixMyMess (fixmymess.ai) ajuda equipes a diagnosticar caminhos de shutdown, drenagem de conexões e problemas de limpeza em apps Node herdados gerados por IA para que rollouts parem de produzir 502s surpresa.