Disjuntores para provedores instáveis para prevenir falhas em cascata
Saiba como disjuntores para provedores instáveis evitam falhas em cascata usando timeouts, retries limitados, fallbacks e recuperação segura quando dependências se estabilizam.
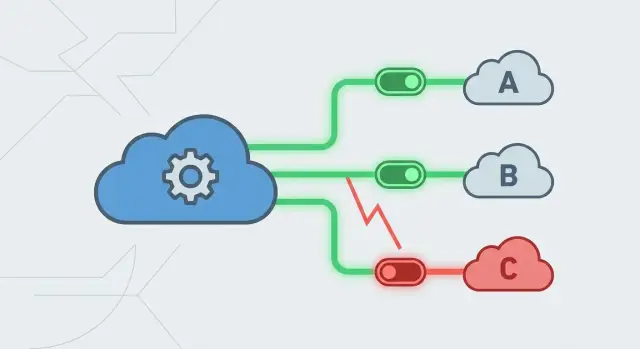
Por que provedores instáveis podem derrubar um app que por si só é bom
Um app pode ser sólido e ainda assim cair porque algo de que ele depende começa a falhar. Uma gateway de pagamentos fica lenta, um serviço de e-mail retorna erros, ou um proxy de banco de dados dá um pico. Se seu app continua chamando essa dependência como se nada estivesse errado, um problema pequeno se espalha rápido.
Essa reação em cadeia é uma falha em cascata: uma dependência lenta ou com erro faz as requisições esperarem, as requisições esperando se acumulam e logo partes saudáveis do app não conseguem mais respirar. Threads travam, pools de conexão enchem, filas acumulam e tudo parece “fora do ar” mesmo quando a maior parte do seu código está bem.
Isso geralmente começa com gatilhos comuns:
- Timeouts muito longos, então cada requisição espera muito mais do que o usuário aceita.
- Limites de taxa, seguidos por retries que empurram ainda mais tráfego para o throttle.
- Quedas parciais onde algumas chamadas funcionam e outras pendem, o que é mais difícil de detectar.
- “Sucesso lento” onde respostas eventualmente dão certo mas demoram 10x mais e entopem recursos.
Retries sem proteções só pioram. Se cada ação do usuário dispara três retries e você tem centenas de usuários batendo no mesmo provedor, você cria seu próprio pico de tráfego. Por isso disjuntores importam: eles impedem que seu app toque no fogão quente repetidamente.
Do ponto de vista do usuário, é simples e doloroso. Botões giram para sempre, páginas atualizam em erro e as pessoas clicam de novo porque nada parece acontecer. Isso leva a ações duplicadas (pedidos em dobro, cobranças duplicadas, múltiplos tickets). Pior ainda: os usuários não sabem se os dados foram salvos ou se o pagamento passou.
Esse modo de falha aparece muito em apps herdados gerados por IA: timeouts ausentes, retries agressivos e tratamento de erro apenas para o “caminho feliz” podem transformar um piscar do provedor em uma queda total. A correção começa tratando falhas de dependência como normais, não excepcionais.
Disjuntores em um minuto: o que fazem e por quê
Um disjuntor é uma proteção em torno de uma chamada externa. Quando uma dependência começa a falhar, você para de chamá‑la por um tempo curto. Isso evita mais tráfego, mais erros e mais threads bloqueadas. Em vez de cada requisição travar, você falha rápido e troca para um fallback.
Disjuntores geralmente passam por três estados:
- Fechado: as chamadas fluem normalmente e você acompanha os resultados.
- Aberto: o provedor parece não saudável, então chamadas são bloqueadas imediatamente e você retorna uma resposta controlada.
- Meio-aberto: após um cooldown, você permite um pequeno número de chamadas de teste para ver se o provedor se recuperou.
Isso não é o mesmo que “adicione retries e timeouts”. Um timeout limita quanto tempo você espera, mas ainda é possível acumular muito trabalho pendente quando um provedor está lento. Retries podem multiplicar o tráfego justamente no momento errado. Um disjuntor adiciona uma regra de nível superior: você viu falhas suficientes, então pare de tentar por agora.
Quando bem configurado, o resultado é propositalmente sem drama:
- Usuários recebem uma resposta rápida, mesmo que degradada (dados em cache, trabalho enfileirado ou um “tente novamente em breve” claro).
- Seus servidores permanecem responsivos porque não ficam presos esperando um provedor com problema.
- Incidentes ficam contidos porque uma dependência instável não dispara uma reação em cadeia.
Exemplo: se seu fluxo de cadastro envia um e-mail de confirmação e a API de e-mail começa a timing out, um disjuntor pode parar as tentativas de envio por alguns minutos e enfileirar os e‑mails para depois. Usuários ainda conseguem criar conta em vez de assistir a página girar e falhar.
Codebases geradas por IA frequentemente esquecem esse padrão ou o conectam errado. FixMyMess costuma ver timeouts longos junto com retries agressivos, o que transforma um soluço do provedor em um outage. Um disjuntor é uma das formas mais rápidas de tornar falhas de dependência previsíveis.
Onde colocar disjuntores primeiro (locais de maior impacto)
Comece onde uma dependência pode travar todo o app. Os melhores alvos iniciais não são “funcionalidades raras”. São chamadas em telas de alto tráfego e fluxos críticos.
Uma forma simples de priorizar é pensar em duas dimensões:
- Risco: o provedor falha, fica lento ou aplica rate limits com frequência.
- Raio de impacto: uma chamada lenta bloqueia muitas requisições, ocupa threads de workers ou quebra uma jornada core do usuário.
Escolha dependências que falham alto (e frequentemente)
Serviços terceirizados no caminho crítico merecem proteção primeiro: pagamentos, email/SMS, provedores de autenticação e APIs de LLM. Eles estão fora do seu controle e podem degradar sem aviso.
Se só puder proteger uma coisa, escolha a dependência que pode interromper dinheiro ou acesso. Um checkout que travar é pior do que um recibo atrasado. Um timeout de login é pior do que analytics faltando.
Foque em endpoints ligados a ações críticas
Disjuntores importam mais em endpoints onde usuários tentam completar algo: login, cadastro, onboarding, checkout, reset de senha e qualquer ação de “enviar” que precise retornar rápido.
Para escolher os primeiros pontos de chamada, faça isto:
- Identifique seus endpoints principais por tráfego e impacto de negócio.
- Mapeie as chamadas externas que cada endpoint faz.
- Marque chamadas síncronas dentro do caminho request/response.
- Decida o que significa “falha” (timeouts e 5xx, mas também payloads ruins ou incompletos).
- Confirme o que acontece hoje quando a dependência está lenta (spinners, acúmulo em filas, exaustão de threads).
Times frequentemente se surpreendem com o que conta como falha. Um provedor pode retornar HTTP 200 com um payload quebrado, campos ausentes ou um token que você não pode usar. Trate isso como falha também, ou o disjuntor não vai abrir quando deveria.
Exemplo: se o onboarding chama um LLM para gerar uma mensagem de boas‑vindas e essa chamada leva 20 segundos, usuários assumem que o cadastro quebrou. Coloque o disjuntor em volta dessa chamada, defina um timeout claro e retorne uma mensagem padrão simples.
Code gerado por IA que você herdou pode dificultar isso porque chamadas a dependências estão misturadas em handlers e rotas. Um movimento prático inicial é isolar cada provedor atrás de uma fronteira limpa para você poder adicionar timeouts, disjuntores e fallbacks sem reescrever tudo.
Os botões que importam: timeouts, thresholds e janelas de reset
Um disjuntor é tão bom quanto suas configurações. Muito frouxo, e usuários ainda sentem o outage. Muito rígido, e você bloqueia tráfego saudável.
Timeouts: decida quanto tempo você está disposto a esperar
Escolha um timeout por requisição baseado no que o usuário está fazendo. Para um botão “Salvar”, esperar 10 segundos parece quebrado. Para sincronização em background, você pode tolerar mais.
Uma regra útil: o timeout deve ser menor que o tempo que seu app pode se dar ao luxo de ficar preso. Se for alto demais, requisições se acumulam, workers entopem e uma pequena lentidão do provedor vira uma queda do app.
Retries ajudam apenas quando falhas são breves e o provedor não está sobrecarregado. Retentar após timeouts frequentemente piora porque duplica tráfego justamente quando a dependência está lutando.
Thresholds e recuperação: quando abrir, quando testar
Você precisa de três números: quando abrir, quanto tempo esperar e como testar a recuperação.
Um ponto de partida prático:
- Abra após um pico claro, por exemplo 5 falhas nas últimas 20 chamadas.
- Espere 30 a 60 segundos antes de testar novamente.
- No meio‑aberto, permita 1 a 3 chamadas de teste, não uma enchente.
- Mantenha retries em 0 ou 1, e só para requisições seguras e idempotentes.
- Defina timeouts por endpoint, frequentemente 1 a 3 segundos para ações voltadas ao usuário.
Probes meio‑abertos são o “dedo no pé d’água”. Após a janela de reset, você deixa passar um pequeno número de requisições controladas. Se elas tiverem sucesso de forma consistente, você fecha o circuito. Se falharem, você abre de novo.
Exemplo: se um provedor de email envia códigos de login e começa a dar timeout, use um timeout curto para que a UI não fique pendurada, abra o disjuntor após algumas falhas e probe a cada minuto. Usuários recebem um próximo passo claro em vez de spinners sem fim.
Se você herdou uma base gerada por IA com loops acidentais de “retry para sempre”, ajustar essas configurações muitas vezes é uma das mudanças de maior alavancagem que você pode fazer.
Passo a passo: implementar um disjuntor sem overengineering
A forma mais rápida de obter valor é manter centralizado. Não espalhe checagens por todo lugar. Coloque o comportamento em um só lugar para você ajustar depois sem caçar em dezenas de arquivos.
Um fluxo simples que funciona na maioria dos apps
Crie um wrapper de “client do provedor” para cada dependência externa (pagamentos, email, IA, auth, envio). Toda chamada passa por ele. Esse wrapper é dono dos timeouts, retries, estado do disjuntor e logging.
Uma implementação direta costuma ser assim:
- Centralize chamadas em um módulo com uma interface única.
- Normalize erros em um pequeno conjunto que seu app entende (timeout, indisponível, bad request).
- Monitore resultados recentes em uma janela deslizante e abra o circuito quando falhas cruzarem seu limiar.
- Quando aberto, falhe rápido e retorne um fallback seguro.
- Após um cooldown, probe com cuidado e só feche após sucesso real.
O que “fallback seguro” significa na prática
Um fallback não deveria fingir que tudo deu certo. Deve manter o usuário em movimento sem piorar a situação.
Se o email está falhando, aceite o envio do formulário, mostre confirmação e enfileire o email para depois. Se uma API de preços está fora, mostre preços em cache com um carimbo “a partir de” e uma nota clara se podem estar desatualizados. Se uma chamada estiver ligada a dinheiro ou segurança, seja explícito sobre a incerteza.
Mantenha decisões de fallback perto do wrapper. O resto do app deve chamar sendEmail() ou chargeCard() e receber um resultado claro.
Uma falha comum em protótipos herdados é a API terceirizada sendo chamada de múltiplas rotas com comportamentos de retry diferentes. Funciona em testes, então dá timeout em produção e dispara retries em todo lugar. Um wrapper com timeout real, falha rápida e cooldown para quando o provedor está ruim para de acumular requisições e protege seu banco e filas.
Projetando fallbacks que os usuários aceitam
Disjuntores param o sangramento. Fallbacks mantêm os usuários em movimento. Um bom fallback é honesto, seguro e fácil de explicar.
Comece nomeando o objetivo do usuário para cada chamada a dependência. Se o objetivo for “ver meu saldo”, um fallback pode ser “mostrar o último saldo conhecido com timestamp”. Se o objetivo for “finalizar checkout”, um fallback pode ser “salvar o pedido e confirmar depois”, não “fingir que foi processado”.
Tipos de fallback úteis incluem dados em cache, trabalho enfileirado, UI degradada, revisão manual e provedores alternativos (só quando realmente equivalentes). A regra mais importante: não minta. As pessoas perdoam “Confirmaremos em breve” muito mais do que perdoam cobranças duplicadas.
Decida quando mostrar uma mensagem vs degradar silenciosamente com base no impacto. Se o usuário pode tomar uma decisão errada (dinheiro, segurança, prazos), mostre uma mensagem clara e o próximo passo. Se for cosmético, um fallback silencioso pode ser OK.
Torne observável (para corrigir rápido)
Fallbacks sem logs transformam incidentes em adivinhação. Capture contexto suficiente para entender o que aconteceu:
- O que o usuário tentou fazer (e entradas chave que você pode armazenar com segurança)
- Status do provedor (timeout, 500, rate limit, circuito aberto)
- Um ID de correlação entre requisição, chamada ao provedor e caminho de fallback
- O resultado (enfileirado, em cache, revisão manual criada)
- A mensagem mostrada ao usuário
Apps gerados por IA às vezes têm fallbacks, mas ninguém sabe qual caminho rodou. A correção é simples: faça cada fallback explícito, rastreável e verdadeiro.
Um exemplo realista: provedor de pagamentos começa a falhar ao meio‑dia
São 12:10 numa terça. Seu checkout está saudável, mas depende de uma API de pagamentos. O provedor começa a dar timeout. Não erro hard, só fica pendurado por 10 a 20 segundos.
Sem proteção, o problema se espalha. Cada checkout espera, depois retenta. Requisições presas se acumulam, ocupando workers e conexões de banco. Clientes atualizam e clicam “Pagar” de novo. Algumas requisições passam, outras não, e você acaba com páginas lentas, tentativas duplicadas e um suporte cheio de “Fui cobrado?”.
Com um disjuntor, a história muda rápido. Após uma sequência curta de timeouts, o disjuntor abre para o client de pagamentos. O checkout para de esperar 20 segundos para aprender o óbvio. Ele falha rápido e mostra uma mensagem clara como: “Pagamentos temporariamente indisponíveis. Seu pedido foi salvo. Tente novamente em alguns minutos.”
Em vez de disparar mais chamadas de pagamento, o app registra a intenção (carrinho, total, usuário, ID de pedido pendente). Se possível, enfileire uma tentativa de pagamento para depois ou ofereça um método alternativo. O essencial é que usuários recebam um resultado rápido e honesto, e o sistema permaneça responsivo.
Quando o disjuntor abre, você também ganha sinais mais limpos: “dependência de pagamentos caída” em vez de lentidão vaga em toda parte. A recuperação não exige herói. Após a janela de reset, o circuito vai para meio‑aberto, envia um pequeno número de probes e fecha se o provedor estiver saudável de novo.
Erros comuns que pioram os outages
Outages geralmente pioram porque o app continua empurrando, esperando e bloqueando até que tudo se encha. Disjuntores ajudam, mas só se você evitar algumas armadilhas.
Retries imediatos e infinitos são um amplificador clássico. Se um provedor sai do ar e milhares de clientes retentam de uma vez, você cria seu próprio pico de tráfego e mantém o provedor mais tempo fora do ar.
Timeouts ausentes são outro problema. Sem um timeout claro, requisições ficam penduradas, filas crescem, servidores desaceleram e logo até partes saudáveis do app parecem quebradas.
Também cuide do escopo do disjuntor. Um disjuntor global compartilhado entre features não relacionadas é perigoso. Um outage de pagamentos não deve bloquear login ou leitura de dados do usuário. Escopo o disjuntor para uma única dependência e um único tipo de chamada.
Cinco sinais de alerta rápidos:
- Retries que disparam instantaneamente e sem fim (sem backoff, sem limite)
- Timeouts ausentes ou tão longos que requisições se acumulam
- Um disjuntor compartilhado por muitas dependências ou endpoints
- Um fallback que reporta “sucesso” quando a ação não aconteceu
- Um circuito que abre mas nunca faz probes para recuperação
Fallbacks que não mentem
O fallback mais danoso esconde a falha. Se um usuário clica “Pagar agora”, o provedor falha e o app mostra “Pagamento concluído”, você terá disputas e clientes revoltados.
Um fallback mais seguro é honesto e específico: “Não foi possível processar o pagamento. Seu pedido foi salvo. Tente novamente em alguns minutos.” Quando possível, mantenha o usuário avançando: salve o progresso, ofereça acesso apenas leitura ou forneça um fluxo alternativo.
Checagens rápidas que você pode fazer hoje
Algumas verificações rápidas podem evitar o dia em que “um provedor está instável e tudo derrete”.
Comece com suas três principais dependências externas (pagamentos, auth, email/armazenamento) e inspecione os caminhos de código que as atingem:
- Cada chamada outbound tem um timeout real que você escolheu de propósito.
- Retries são limitados e intencionais. Não retente nada que possa causar cobranças duplicadas ou escritas duplicadas a menos que você tenha idempotência.
- Cada dependência crítica tem um plano B que o usuário entende.
- Mudanças de estado do disjuntor são visíveis em logs (e idealmente em um dashboard).
- A recuperação é automática via probes meio‑abertos seguros.
Para testar rápido, simule a falha de um provedor por cinco minutos em um ambiente seguro. Faça a chamada falhar (rede bloqueada, 500 forçado), confirme que os usuários têm um resultado previsível (mensagem, cache ou trabalho enfileirado), confirme que o disjuntor abre e então restaure o provedor e verifique que ele se recupera sem supervisão manual.
Próximos passos: torne falhas de dependência chatas, não catastróficas
Anote suas dependências principais e os fluxos de usuário exatos que elas tocam: “Checkout”, “Login”, “Reset de senha”, “Enviar convite”. Depois decida o que é “bom o suficiente” se cada uma estiver fora. Às vezes a resposta certa é simplesmente falhar rápido com uma mensagem clara e tentar depois com segurança.
Depois disso, adicione uma camada wrapper por provedor para que timeouts, retries, o padrão de disjuntor e o logging morem em um só lugar. Se só puder fazer uma coisa esta semana, escolha a dependência ligada à receita ou ao acesso.
Se você está herdando um app gerado por IA que desmorona sob tráfego real, FixMyMess (fixmymess.ai) pode rodar uma auditoria de código gratuita e apontar timeouts ausentes, loops de retry arriscados e tratamento fraco de falhas de dependência. Frequentemente é possível estabilizar as integrações piores rapidamente adicionando wrappers limpos, padrões sensatos e fallbacks honestos.
Perguntas Frequentes
O que é uma falha em cascata, em termos simples?
Uma falha em cascata acontece quando um provedor lento ou com erro faz seu app esperar, e essas requisições em espera se acumulam até que partes saudáveis fiquem sem threads, conexões ou capacidade de fila. A correção é parar de esperar para sempre e parar de chamar repetidamente o serviço com problema para que o resto do app permaneça responsivo.
Como um disjuntor é diferente de apenas adicionar timeouts e retries?
Um disjuntor é uma regra em torno de uma chamada externa que impede que requisições atinjam um provedor quando ele está claramente instável. Em vez de ficar pendurado, seu app falha rápido e retorna um resultado controlado (como dados em cache ou “tente novamente em breve”), o que evita que seus servidores fiquem entupidos.
Como escolho um timeout sensato para uma requisição voltada ao usuário?
Comece pela tolerância do usuário: para um clique de botão ou carregamento de página, vise um timeout curto que mantenha a interface responsiva (geralmente alguns segundos, não 20). Se a chamada for opcional, faça o timeout ainda menor e degrade com elegância; se for crítica, falhe rápido com uma mensagem clara em vez de deixar requisições se acumularem.
Quando devo evitar retries e quando eles são seguros?
Evite retries por padrão (ou no máximo um) para qualquer coisa que possa causar efeitos colaterais duplicados, como cobranças, envios ou escritas. Retries são mais seguros para leituras idempotentes, e mesmo nesses casos você deve usar backoff e manter o tempo total limitado para não amplificar um outage.
Onde devo adicionar disjuntores primeiro para obter o maior impacto?
Coloque disjuntores em chamadas síncronas que estejam no caminho crítico: login/verificações de autenticação, checkout/pagamentos, envio de email/SMS para códigos e qualquer API que as telas principais precisem para renderizar. O maior impacto vem onde uma dependência pode bloquear muitas requisições e esgotar recursos compartilhados como pools de conexão.
O que os estados fechado, aberto e meio-aberto realmente significam?
“Fechado” significa que as chamadas fluem normalmente enquanto você acompanha falhas. “Aberto” significa que você bloqueia temporariamente as chamadas e retorna imediatamente uma resposta controlada. “Meio-aberto” significa que, após um período de cooldown, você permite um pequeno número de chamadas de teste para ver se a dependência voltou a ficar saudável antes de fechar o circuito por completo.
Qual é um bom fallback quando um provedor está indisponível?
Um bom fallback mantém o usuário em movimento sem fingir que a ação foi bem-sucedida. Por exemplo, se o envio de email está fora do ar, aceite o cadastro e coloque o email em fila; se uma API de preços estiver indisponível, mostre o último valor conhecido com um aviso de data/hora dizendo que pode estar desatualizado. Para dinheiro ou segurança, seja explícito sobre o que aconteceu e o que não aconteceu.
Devo usar um disjuntor global para tudo?
Faça o escopo do disjuntor corresponder à dependência e ao tipo de chamada, não ao seu app inteiro. Um outage de pagamentos não deveria bloquear a leitura de perfil, e uma falha de email não deveria quebrar o login. Se você escopar demais, um provedor instável pode desabilitar recursos não relacionados de forma desnecessária.
Como posso testar disjuntores sem causar um outage real?
Simule a falha da dependência por alguns minutos em um ambiente seguro e verifique três coisas: as requisições falham rápido, os usuários veem um resultado previsível e o sistema permanece responsivo sob carga. Depois restaure a dependência e confirme que o circuito passa por probes meio-abertos e se recupera automaticamente sem intervenção manual.
Por que apps gerados por IA falham tanto com provedores instáveis, e o que a FixMyMess pode fazer?
Código gerado por IA frequentemente é “apenas caminho feliz”: timeouts longos ou ausentes, loops de retry agressivos e chamadas a provedores espalhadas por várias rotas. Se você herdou um protótipo que desmorona sob tráfego real e não é técnico, FixMyMess (fixmymess.ai) pode rodar uma auditoria gratuita de código e estabilizar as integrações mais problemáticas adicionando wrappers limpos, timeouts sensatos e fallbacks honestos, muitas vezes em 48–72 horas.