Estratégia de retentativas para jobs em segundo plano: backoff, limites e alertas
Estratégia de retentativas para jobs em segundo plano que torna falhas visíveis: adote backoff, limite de tentativas, DLQ e alertas para que os jobs se recuperem com segurança.
Por que “não rodou” é uma maneira arriscada de descobrir falhas
Jobs em background são as pequenas tarefas que seu app roda nos bastidores para que o produto principal continue rápido. Eles enviam e-mails, importam CSVs, sincronizam dados, processam pagamentos e entregam webhooks. Usuários raramente veem o job em si — eles só notam o resultado.
Por isso a falha mais comum é assim: funcionou nos testes, então parou silenciosamente em produção. Ninguém vê uma página de erro. Nada cai de forma óbvia. Você só descobre dias depois quando um cliente diz “não recebi o e-mail” ou falta uma exportação.
Falhas silenciosas são piores que falhas visíveis porque corroem confiança enquanto escondem a causa. Falhas visíveis forçam uma resposta. As silenciosas criam um acúmulo de promessas quebradas: e-mails não enviados, dados não sincronizados, onboarding travado, reembolsos não processados. Quando você nota, está consertando o job e limpando a bagunça que ele deixou.
Um bom plano de retry não é “tentar para sempre”. Deve fazer quatro coisas:
- Recuperar de problemas temporários (timeouts, quedas breves, limites de taxa).
- Fazer backoff sob pressão para não bombardear seu banco ou uma API externa.
- Parar após um número razoável de tentativas.
- Tornar as falhas óbvias para que um humano intervenha.
Se um provedor de e-mail retorna um 503 temporário, tentar de novo depois faz sentido. Mas se o job falha por uma variável de template errada ou autenticação quebrada, retries só gastam tempo e dinheiro sem resolver nada.
Isso aparece muito em protótipos gerados por IA. O app “funciona na maior parte”, mas o trabalho em background falha silenciosamente porque faltam secrets, o tratamento de erros é frágil ou a lógica do job está enredada. O primeiro passo é tornar as falhas barulhentas, limitadas e recuperáveis.
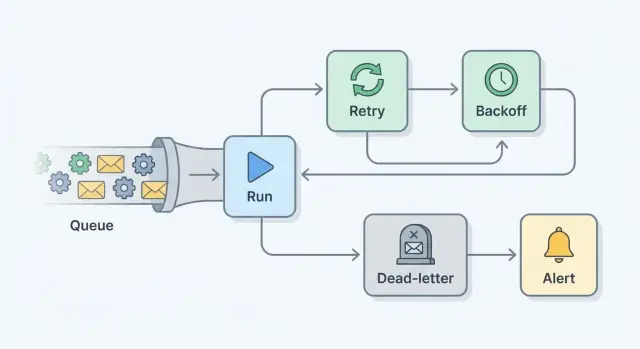
Pedaços centrais: retries, backoff, tentativas máximas, dead-letter, alertas
Um plano de retry é na prática um conjunto de pequenas proteções que transforma falhas silenciosas em trabalho visível e recuperável.
Um retry roda o mesmo job novamente após uma falha. Isso ajuda quando a falha é temporária, como uma chamada de rede instável.
Backoff é a pausa entre tentativas. Em vez de tentar instantaneamente (e criar um efeito de manada), você espera cada vez mais, muitas vezes com alguma aleatoriedade.
Tentativas máximas é o limite rígido. Depois de N tentativas, você para para que um job ruim não fique em loop para sempre.
Uma dead-letter queue (DLQ) (ou tabela de jobs falhos) é onde os jobs vão depois que você desiste. Nada se perde. Você pode inspecionar o que aconteceu, corrigir a causa raiz e então reexecutar o job intencionalmente.
Alertas são como os humanos ficam sabendo. O objetivo não é notificar a cada retry. É notificar quando algo precisa de atenção, como quando um job atinge o máximo de tentativas ou o volume da DLQ começa a subir.
Uma ideia que evita muita dor: idempotência
Um job é idempotente se é seguro rodá-lo duas vezes.
“Definir o status da fatura como PAGO” é mais seguro que “cobrar o cartão”. Quando não é possível tornar a ação totalmente idempotente, adicione uma proteção: uma chave única, uma flag “já processado” ou um token de idempotência do provedor.
Falhas transitórias vs permanentes
Falhas transitórias normalmente se resolvem sozinhas: timeouts, quedas breves, linhas bloqueadas. Falhas permanentes não: registros ausentes, endereços de e-mail inválidos, uma chave de API errada.
Retries reduzem incidentes, mas não eliminam todas as falhas. O objetivo é conter o raio do impacto, expor problemas reais rapidamente e dar um lugar seguro (DLQ) para recuperar.
Saiba o que você está retryando: erros transitórios vs permanentes
Um plano de retry começa com uma decisão: essa falha tende a desaparecer sozinha, ou vai falhar sempre até alguém mexer? Se você tenta tudo, terá filas barulhentas, contas maiores e atrasos que escondem o problema real.
Erros transitórios são temporários. Tentar de novo (com backoff) costuma ajudar porque o ambiente muda: a rede estabiliza, o serviço se recupera, o lock é liberado ou a janela de limite de taxa se reinicia.
Erros permanentes não se consertam sozinhos. Repeti-los só queima tempo enquanto usuários esperam. Normalmente são problemas de dados, permissões, migrações faltantes ou bugs.
Rotular errado importa. Trate um erro permanente como retryable e você pode construir um backlog que bloqueia trabalho saudável. Também torna incidentes mais difíceis de ver porque o sistema parece “ocupado” em vez de “quebrado”.
Uma regra simples: retry apenas quando você consegue nomear uma condição realista que mudará sem ação humana. Se o job provavelmente daria certo ao rodar de novo em 1 a 10 minutos, é provavelmente retryable. Se falharia da mesma forma amanhã, pare, envie para DLQ e alerte.
Backoff que se comporta bem sob pressão
Quando um job falha, a pior coisa é retryar em um loop apertado. Se a falha vem de uma queda parcial, limite de taxa ou banco lento, retries imediatos aumentam a carga exatamente quando o sistema já está sofrendo.
Backoff exponencial é um padrão mais saudável: cada retry espera mais que o anterior. Um padrão simples pode ser 5s, 15s, 45s, 2min, depois 5min.
Adicione jitter (um pouco de aleatoriedade) a cada delay. Sem ele, workers que falharam juntos vão retryar juntos, criando picos. Com jitter, uma espera planejada de 2 minutos pode virar 1m30s a 2m30s. Essa pequena dispersão suaviza os retries.
O backoff deve combinar com o job. Um e-mail de redefinição de senha e um relatório noturno não precisam do mesmo ritmo. Como ponto de partida, jobs voltados ao usuário podem retryar rápido com um cap curto, enquanto jobs pesados e APIs externas rígidas exigem caps mais longos e jitter a cada tentativa.
Defina tentativas máximas e condições claras de parada
Retries ilimitados parecem seguros, mas transformam uma falha em um loop sem fim. O job continua rodando, acumula tempo na fila e custos de API, e esconde um bug real porque nada vira uma falha “final”.
Há também um risco prático: retries repetidos podem causar danos. Você pode enviar o mesmo e-mail muitas vezes, criar registros duplicados ou cobrar um cartão novamente se o job não for idempotente.
Escolha tentativas máximas com base no impacto. Ações de alto risco como pagamentos devem falhar rápido (geralmente 1 a 3 tentativas). Notificações seguras do usuário podem permitir mais tentativas. Para APIs lentas de terceiros, mais tentativas podem ser aceitáveis desde que o backoff seja conservador.
Também adicione um limite de tempo total, não apenas um contador. Por exemplo: “Tentar até 5 vezes, mas parar depois de 2 horas.” Isso evita que um job arraste por dias.
Quando um job atinge o máximo, trate isso como um evento real. Grave dados suficientes para depurar e reprocessar com segurança: o último erro, o tipo de erro, timestamps das tentativas e o payload (ou uma versão redigida). Capture IDs externos (user_id, order_id) que ajudem a traçar o que foi afetado.
Use uma dead-letter queue para que falhas sejam recuperáveis
Retries servem para problemas temporários. Alguns jobs nunca vão ter sucesso sem uma mudança. Uma DLQ é o lugar seguro para colocar esses jobs depois que atingem o máximo, para que parem de queimar recursos e fiquem visíveis para um humano.
Pense na DLQ como uma caixa “precisa de atenção”. Em vez de perder trabalho ou entrar em loop, você captura detalhes suficientes para diagnosticar, consertar e reexecutar intencionalmente.
O que armazenar em um registro de dead-letter
Uma entrada de DLQ deve responder duas perguntas: o que o job tentava fazer e por que falhou?
Mantenha pequeno, mas completo: nome do job (e versão, se houver), payload de entrada (ou referência se for grande), mensagem e tipo de erro (mais stack trace se disponível), contagem de tentativas com timestamps e IDs de correlação (user ID, order ID, request ID) para ligar às logs.
Cuidado com secrets. Se payloads podem incluir tokens ou senhas, redija antes de salvar.
Como reenfileirar com segurança
Reenfileirar deve ser deliberado, não um loop automático. Conserte a causa raiz, então retry o job a partir de uma tela admin ou um pequeno script.
Adicione uma trilha de auditoria mínima: quando reenfileirar, zere o contador de tentativas e registre quem reenfileirou e por quê. Se a falha é por input inválido que nunca vai validar, permita marcar como “não vai retryar” com uma nota curta.
A retenção também importa. Mantenha itens da DLQ tempo suficiente para notar padrões e lidar com correções lentas, mas não tanto que dados sensíveis fiquem expostos.
Alertas que são úteis, não barulhentos
Alertas devem responder rapidamente: “O que quebrou, quem é afetado e o que devo fazer a seguir?” Se falhas ficam escondidas por horas, você só descobrirá por um cliente.
Comece com gatilhos que representam dor real, não cada tentativa falha. Sinais úteis incluem falhas repetidas do mesmo tipo de job, aumento na DLQ, tempo de fila longo (jobs esperando mais que sua promessa ao usuário), quedas bruscas em throughput e picos de erro para um job específico.
Roteie alertas para quem pode agir. Em times iniciais, normalmente o on-call ou o fundador. Inclua contexto suficiente para não perder 20 minutos procurando: nome do job, ambiente, hora da primeira falha, última mensagem de erro, quantos jobs estão afetados e se mensagens estão indo para a DLQ.
Para evitar ruído, use três controles: thresholds (alertar após N falhas), agrupamento (um alerta por tipo de job por janela de tempo) e janela de cooldown (não reenviar alerta por 15 minutos, a menos que piore).
Se precisar escalar, mantenha simples: notifique o on-call primário, depois um backup após curto delay, e então um canal mais amplo com resumo de impacto se continuar crescendo.
Torne falhas visíveis com logs e métricas básicas
Um plano de retry só funciona se você consegue ver o que acontece. Caso contrário, você acaba com o mesmo relatório toda vez: “o job não rodou.” O objetivo é simples: cada tentativa deixa um rastro claro, e alguns números básicos mostram se as coisas pioram.
Para logs, mantenha campos consistentes para que uma falha seja fácil de traçar entre tentativas. Cada tentativa deve incluir um job ID (ou correlation ID), número da tentativa, início e fim, e resultado. Em caso de falha, logue uma classe de erro (timeout, auth, validation) mais uma mensagem curta. Também ajuda incluir o nome da fila e do worker.
Mantenha logs seguros. Não registre tokens, senhas, chaves de API, headers completos ou dados pessoais crus. Use IDs internos ou valores mascarados.
Para métricas, você não precisa de muito para ter valor. Monitore taxa de sucesso por tipo de job, retries por job (média e p95), contagem e taxa da DLQ, e tempo até sucesso (quanto tempo jobs passam em retries).
Durante um incidente, um pequeno dashboard deve responder: a DLQ está subindo, um tipo de job está dominando os retries e as falhas começaram em um horário específico (sugestão de deploy ou queda externa).
Exemplo: um job de e-mail que falha e se recupera com segurança
Um job comum é enviar um e-mail de onboarding após cadastro. Funciona por semanas, então o suporte relata: “alguns usuários não receberam o e-mail.” Se você só procura “não rodou”, perde a história real: ele rodou, falhou e desapareceu.
O que acontece quando as falhas começam
Às 9:02, o job tenta enviar um e-mail, mas o provedor dá timeout. Isso é transitório, então o worker retrya com backoff exponencial. Espera 30s, depois 2min, depois 10min. O backoff reduz a pressão no provedor e no seu sistema.
Na 5ª tentativa ainda falha. O job atinge as tentativas máximas e para. Em vez de sumir, vai para a DLQ com detalhes úteis: user ID, tipo de e-mail (onboarding), último erro, contagem de tentativas e quando as falhas começaram.
Um alerta dispara uma vez, não 50 vezes: “OnboardingEmailJob: 12 mensagens na DLQ nos últimos 15 minutos. Erro principal: timeout.” O on-call vê que é real, está crescendo e precisa ação.
Como consertar e reenfileirar com segurança
Você investiga e acha a causa raiz: a chave da API foi rotacionada, mas o worker ainda usa o secret antigo. Isso é comum em codebases iniciais onde secrets são codificados ou carregados de forma inconsistente.
Depois de atualizar o secret e redeployar, você reenfileira as mensagens da DLQ. Antes de fechar o incidente, confirma que a contagem na DLQ está caindo, novos cadastros recebem e-mail no tempo normal, alertas se apagam e ficam quietos por uma janela completa de retry, e os logs mostram envios bem-sucedidos sem timeouts repetidos.
A falha vira visível, contida e recuperável, e nenhum usuário fica pulado silenciosamente.
Erros comuns que causam incidentes repetidos
Incidentes repetidos geralmente não são “azar”. Vêm de alguns padrões que transformam uma pequena falha em backlog.
Um dos maiores é retryar um job que não é idempotente. Se “rodar duas vezes” significa “cobrar duas vezes” ou “enviar dois e-mails”, retries podem criar problemas para clientes mesmo quando o erro original foi pequeno. Adicione uma chave única, verifique o estado atual antes de agir e grave resultados para que uma segunda execução vire um no-op.
Outra armadilha é capturar todo erro e retryar para sempre. Parece seguro, mas esconde bugs reais (dados ruins, lógica quebrada, permissões faltando) e consome capacidade.
As fontes mais comuns de dor repetida são:
- Sem tentativas máximas ou condição de parada, então falhas ficam em loop até alguém notar.
- Sem DLQ, então não é possível revisar e recuperar jobs falhos.
- Alertas sem dono, ou tão barulhentos que são silenciados.
- Secrets ou dados pessoais em payloads e logs, transformando depuração em problema de segurança.
- Reexecuções manuais sem saber o que já teve sucesso, gerando duplicados.
Um exemplo realista: um job de recibo de pagamento dá timeout depois que a cobrança já foi feita, então retrya e envia dois recibos. Semanas depois, alguém reexecuta um lote “só por garantia” e clientes recebem spam novamente.
Checklist rápido antes de subir para produção
Antes de ligar um novo worker ou fila em produção, decida como é uma “falha segura”.
- Defina o que é retryable (timeouts, 503s, limites de taxa) vs o que deve falhar rápido (input ruim, registro ausente, erro de permissão).
- Use backoff com jitter e um cap sensato para que uma queda não gere uma pilha gigante de retries.
- Configure tentativas máximas e limite de tempo (por exemplo, “parar após 10 minutos no total”), então marque como falha.
- Habilite uma DLQ (ou tabela de jobs falhos) e confirme que você pode reenfileirar com segurança sem duplicados.
- Torne falhas observáveis: logue job ID, número da tentativa, nome da fila, mensagem de erro e contexto seguro (IDs internos, não secrets).
Depois teste o ciclo completo uma vez. Escolha um job (como enviar um recibo), force uma falha transitória (retorne um 502 falso uma vez) e confirme que ele retrya com o atraso esperado, tem sucesso na próxima tentativa e produz exatamente um e-mail.
Próximos passos: melhore um job, depois escale o padrão
Escolha um job que importa todo dia e que dói quando falha. Bons candidatos são envio de recibos, sincronização de pagamentos ou geração de faturas. Se você conseguir fazer um job falhar de forma segura, se recuperar automaticamente e avisar quando não consegue, você criou um template reaplicável.
Comece pequeno: classifique erros e retry apenas os transitórios. Adicione backoff, limite de tentativas e um caminho DLQ para o que continuar falhando. Adicione um alerta acionável quando um job atingir o máximo ou cair na DLQ. Mantenha uma linha de log clara por tentativa com job ID, número da tentativa e o último erro.
Se você herdou um codebase gerado por IA onde workers “às vezes falham”, evite refatorações grandes no começo. Envolva os jobs com guardrails (controle de tentativas, backoff, condições de parada), então limpe a lógica quando as falhas estiverem visíveis.
Se não tem confiança para mexer no código com segurança, FixMyMess (fixmymess.ai) pode rodar uma auditoria de código gratuita para achar problemas na lógica de jobs, retries, tratamento de secrets e prontidão para produção, e então entregar correções verificadas prontas para deploy, frequentemente em 48 a 72 horas.
Perguntas Frequentes
O que é uma “falha silenciosa” em um job em background?
Falhas silenciosas acontecem quando um job roda em segundo plano, falha e ninguém percebe. Os usuários só notam o resultado ausente mais tarde, como um recibo não recebido ou uma exportação que nunca apareceu.
Qual é um plano de retry padrão adequado para a maioria dos jobs em background?
Não tente repetir para sempre por padrão. Tente apenas erros que provavelmente se resolvem sozinhos, use backoff para não sobrecarregar sistemas, pare após um limite fixo e torne a falha final visível para que um humano corrija a causa.
Como identificar erros transitórios vs permanentes?
Erros transitórios se resolvem sem mudanças de código ou dados: timeouts, quedas breves, limites de taxa, ou locks temporários. Erros permanentes são normalmente dados inválidos, registros ausentes, credenciais inválidas ou bugs; retry só adia a correção real.
Por que usar backoff exponencial e jitter em vez de tentar imediatamente?
Backoff exponencial espaça as tentativas cada vez mais, reduzindo carga quando algo já está com problemas. Adicione jitter para que muitos workers não tentem no mesmo instante e causem novos picos.
Por que tentativas ilimitadas são uma má ideia?
Retries sem limite escondem bugs reais e podem acumular tempo na fila, custos de API e efeitos duplicados. Um limite de tentativas força um momento claro de “isso precisa de atenção” e evita que um job quebrado trave trabalho saudável.
Quantas tentativas devo permitir e por quanto tempo devo tentar?
Comece pelo impacto e pelo risco. Ações de alto risco (pagamentos) devem falhar rápido; notificações de baixo risco podem permitir mais tentativas, mas sempre com um limite de tempo para não ficar tentando por dias.
O que é uma dead-letter queue e por que eu preciso de uma?
Uma dead-letter queue (ou tabela de jobs falhos) é onde um job vai depois de atingir o máximo de tentativas. Ela preserva o trabalho, captura contexto para depuração e permite rerun intencional após corrigir a causa raiz.
Como reenfileirar jobs falhos com segurança sem causar duplicação?
Reenfileire apenas depois de corrigir a causa da falha e garanta que o job não gere duplicados se rodar duas vezes. Registre quem reencaminhou e por quê, e evite reenfileirar inputs que nunca vão validar.
O que significa “job idempotente” e quando isso importa?
Idempotência significa que rodar o job duas vezes não cria um segundo pagamento, um segundo e-mail ou registros duplicados. Use operações de “definir estado” quando possível, ou uma chave única / token de idempotência do provedor para que repetições sejam no-ops.
Em que devo alertar e o que devo logar para jobs em background?
Alerta quando o job vira algo acionável, como atingir o máximo de tentativas ou cair na DLQ, não a cada retry. Logue cada tentativa com um job ID e tipo de erro, e monitore métricas simples como crescimento da DLQ e taxa de retries para notar problemas antes dos clientes.